はじめに
Amazon Athena とは、AWSのS3上のデータをSQLでクエリできる機能です。
ELB(Elastic Load Balancing)のアクセスログの検索で使われることが多いですが、それ以外にも、データファイルやログの形式に沿ってテーブルを定義することで、検索することも可能です。
ELBのアクセスログの検索については、公式ドキュメント(Application Load Balancer ログのクエリ)で記載されているので、そちらにお任せして、ここでは、CSVファイルの内容をAthenaで解析する方法をまとめます。
データベース、テーブル作成方法
Athenaで解析するためのデータベースおよびテーブル作成について、公式ガイドが提供されています。
データセットをダウンロード
今回は、KaggleのDatasetsから、CSVのサンプルとして使えそうなものとして、COVID-19 dataset in Japanで提供されているデータを使用します。
そちらのサイトから、covid_jpn_prefecture.csvをダウンロードします。
更に、複数ファイルを一度にクエリで検索できることを確認するため、covid_jpn_prefecture.csvを年月ごとにファイルを分割し、
covid_jpn_prefecture.YYYY-MM.csv(covid_jpn_prefecture.2020-03.csv~covid_jpn_prefecture.2021-09.csv)を作成します。
S3へCSVファイルをアップロード
まず、AWSのマネジメントコンソールにログインします。
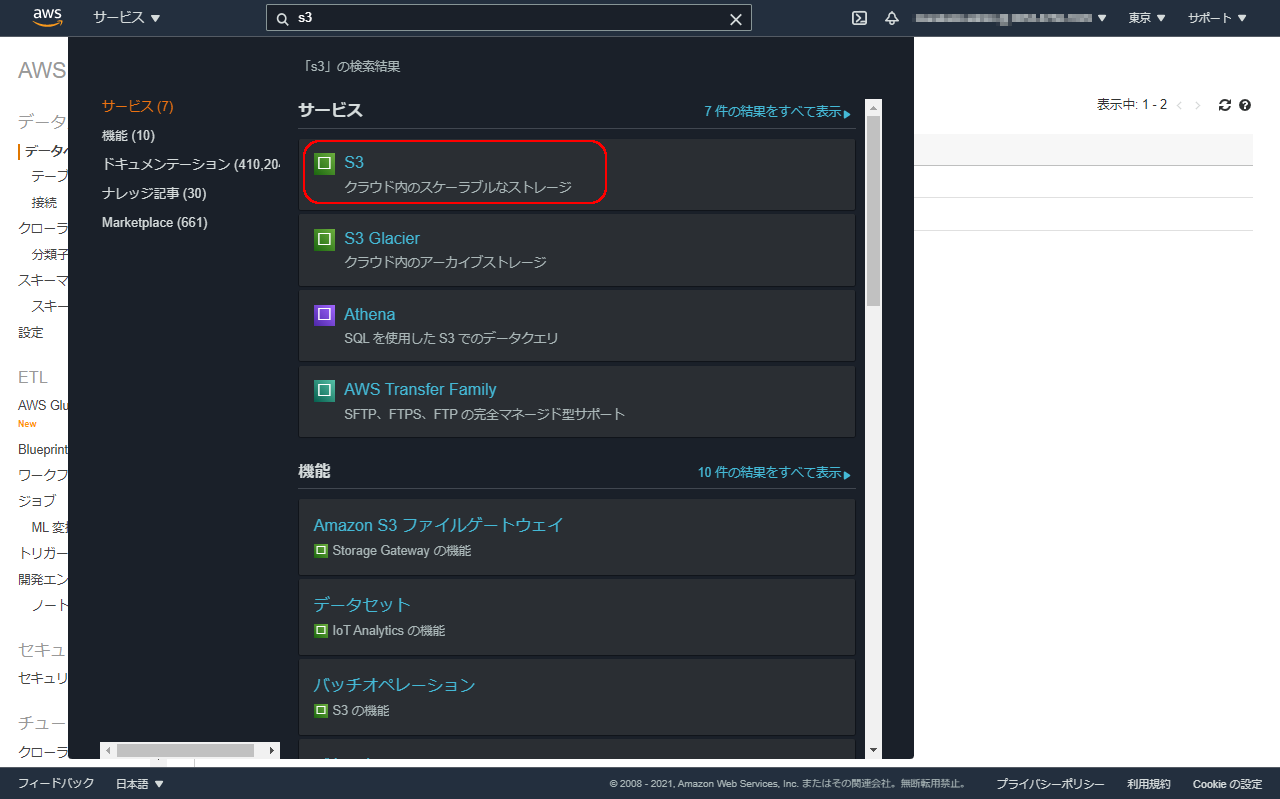
機能名の検索ボックスにS3と入力し、表示された中からS3を選択します。
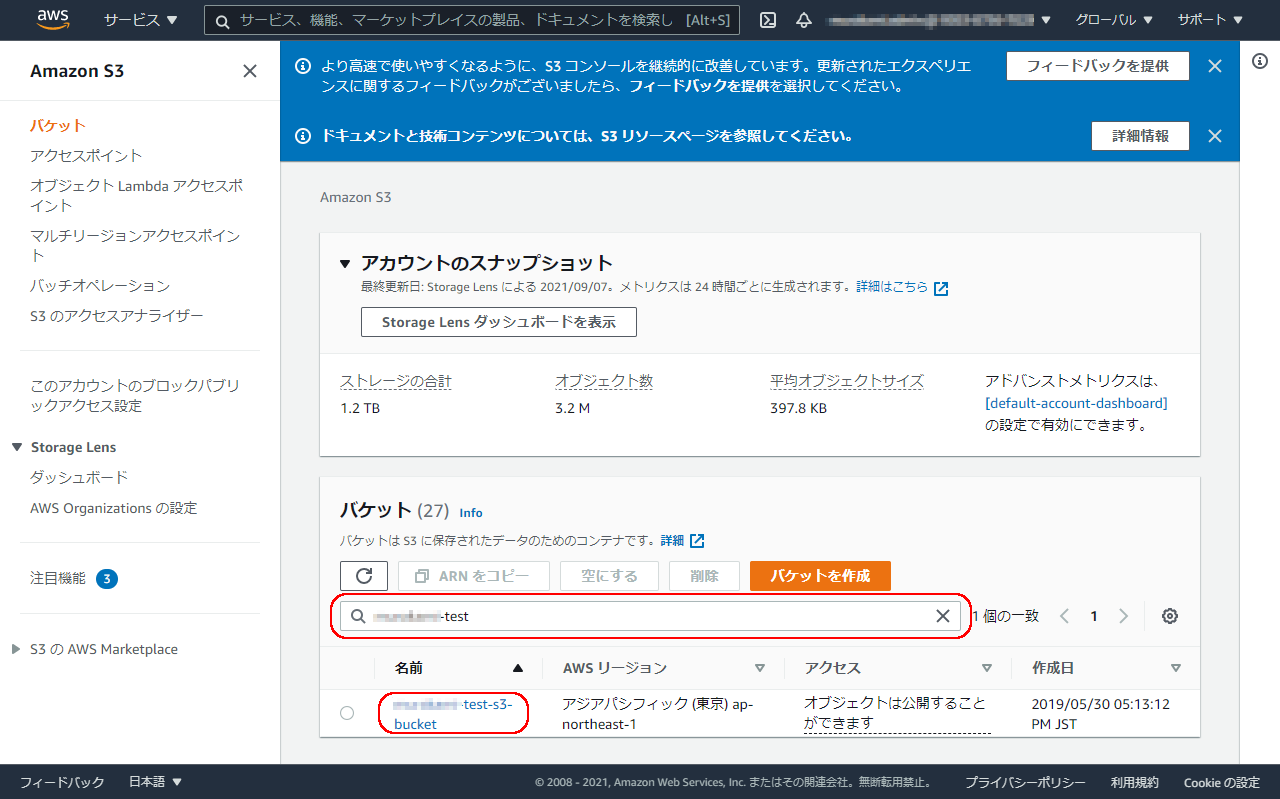
アップロードする先のバケット名を指定します。
※バケットが多い場合は、バケット名で絞り込みます。
※バケットがない場合は、バケットを作成ボタンでバケットを作ります。
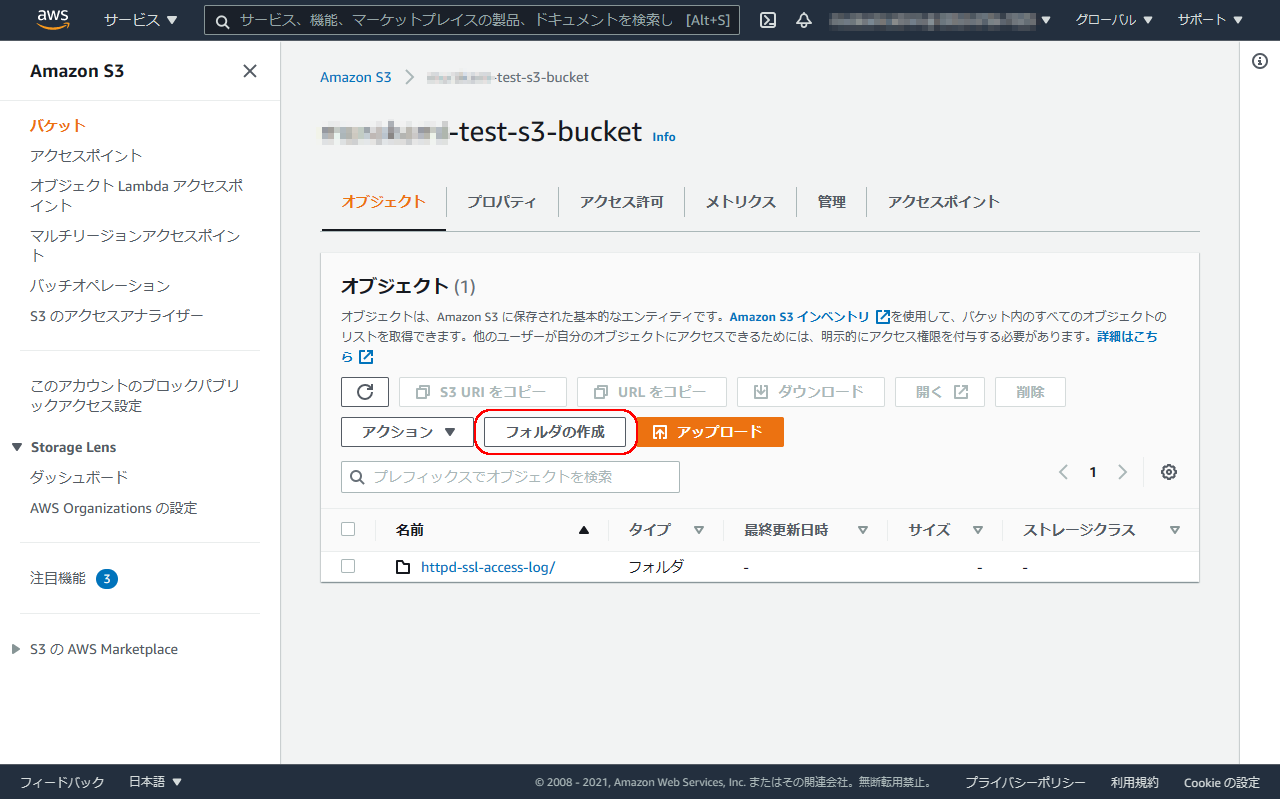
フォルダの作成へ移ります。

CSVデータを入れるフォルダを作成します。
ここでは、covid19-prefecture-csvというフォルダを作って、そこにCSVを入れることとしています。

作成したフォルダをクリックして移動します。

アップロードするCSVファイルをドラッグ&ドロップしてS3へアップロードします。

アップロードするファイル、送信先を確認し、問題なければアップロードボタンをクリックし、アップロードを実行します。
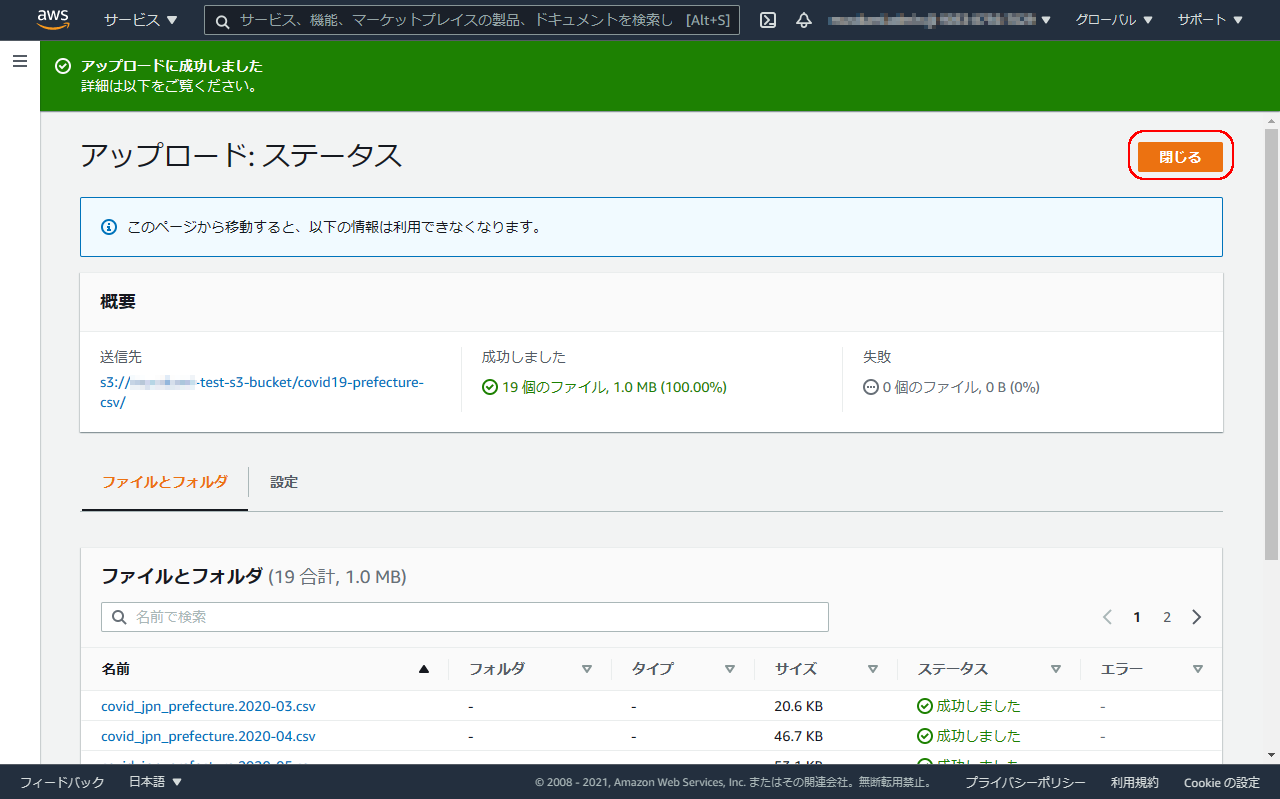
しばらくしてアップロードが完了すると、成功した旨表示されるので、閉じるボタンをクリックします。
Athena起動、データベース作成
AWSのマネジメントコンソールの操作を続けます。
機能名の検索ボックスにAthenaと入力し、表示された中からAthenaを選択します。
初回はこのようにAthenaの機能の説明ページが表示されるので、Get Startedボタンをクリックします。
※初回でのアクセスでない場合など、この画面ではなく、次のQuery editorの画面が表示されることもあります。
sampledbというデータベースがありますが、専用にデータベースを作成します。
Data sourcesのリンクで先へ進みます。
AwsDataCatalogのデータソース名をクリックすると、新しいタブが開きます。
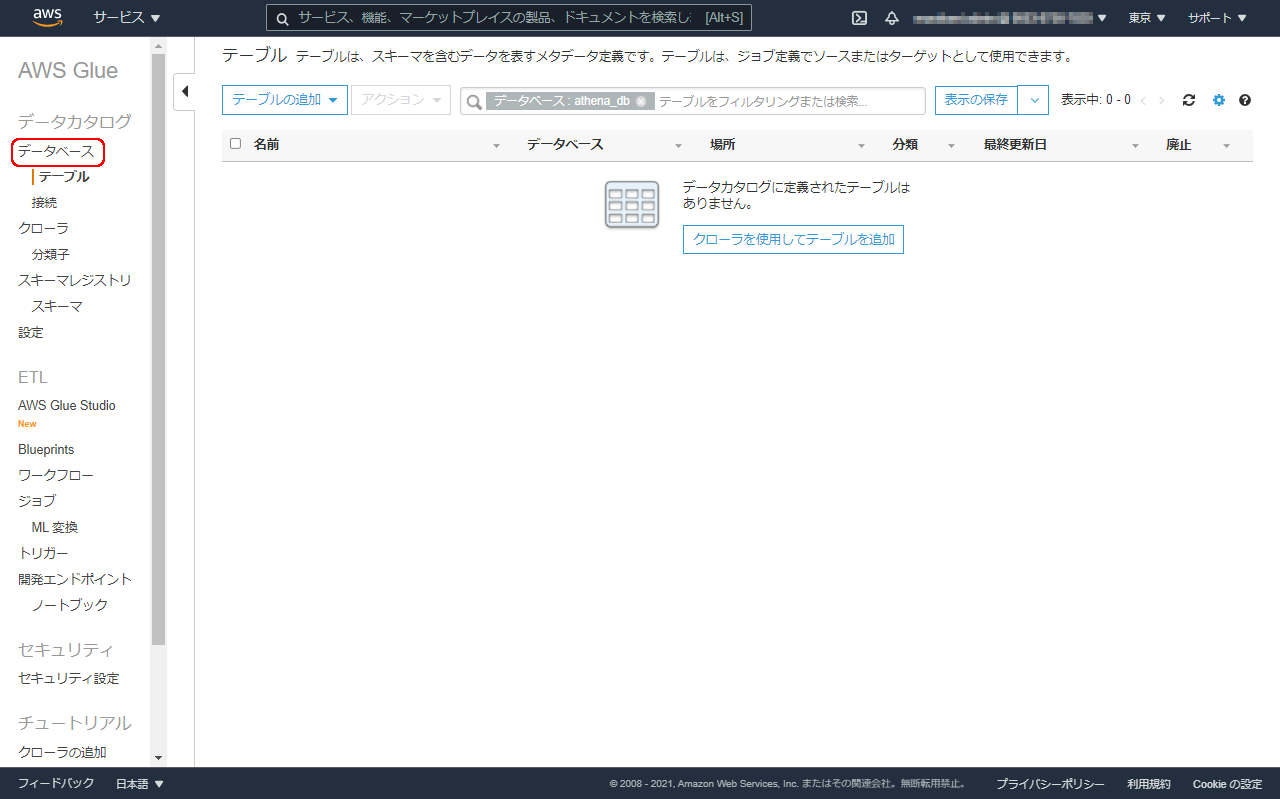
テーブル作成画面が開きますが、まず、データベースを作成しますので、左のペインからデータベースをクリックします。
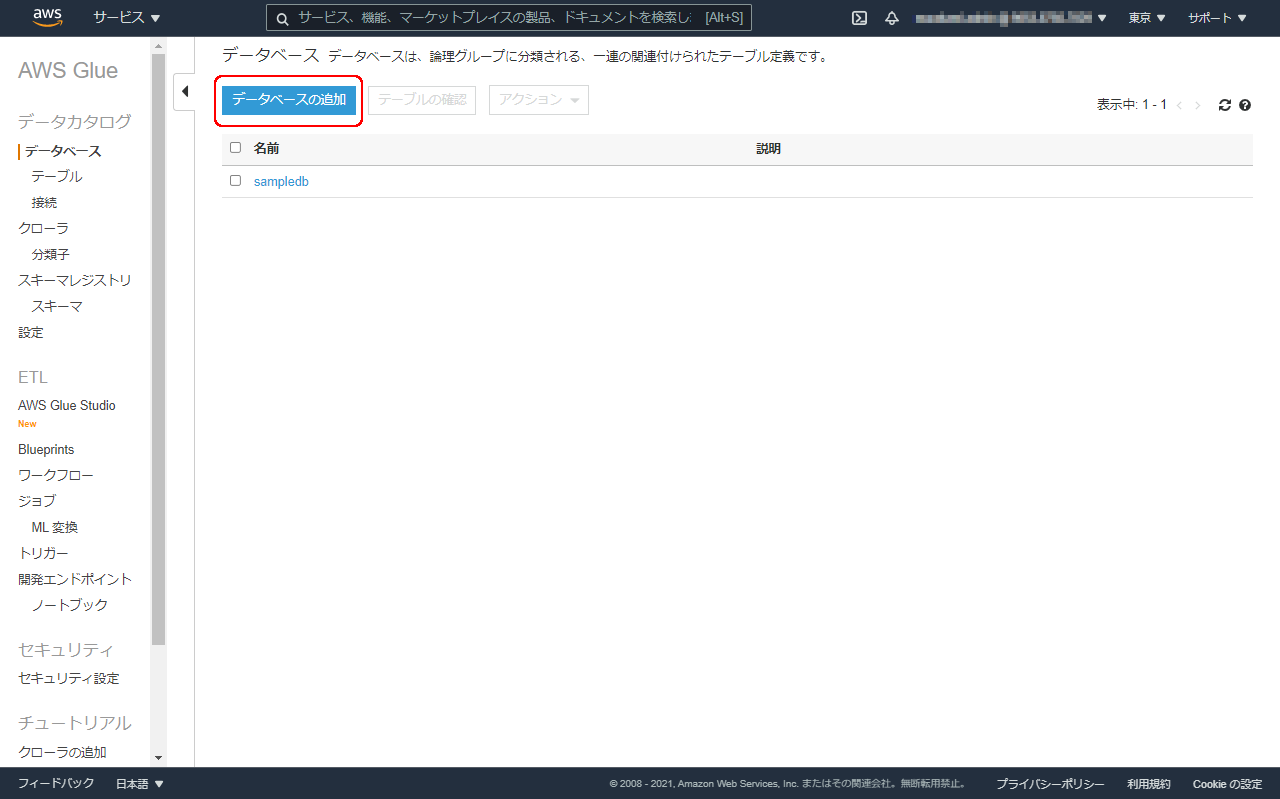
データベースの追加をクリックします。
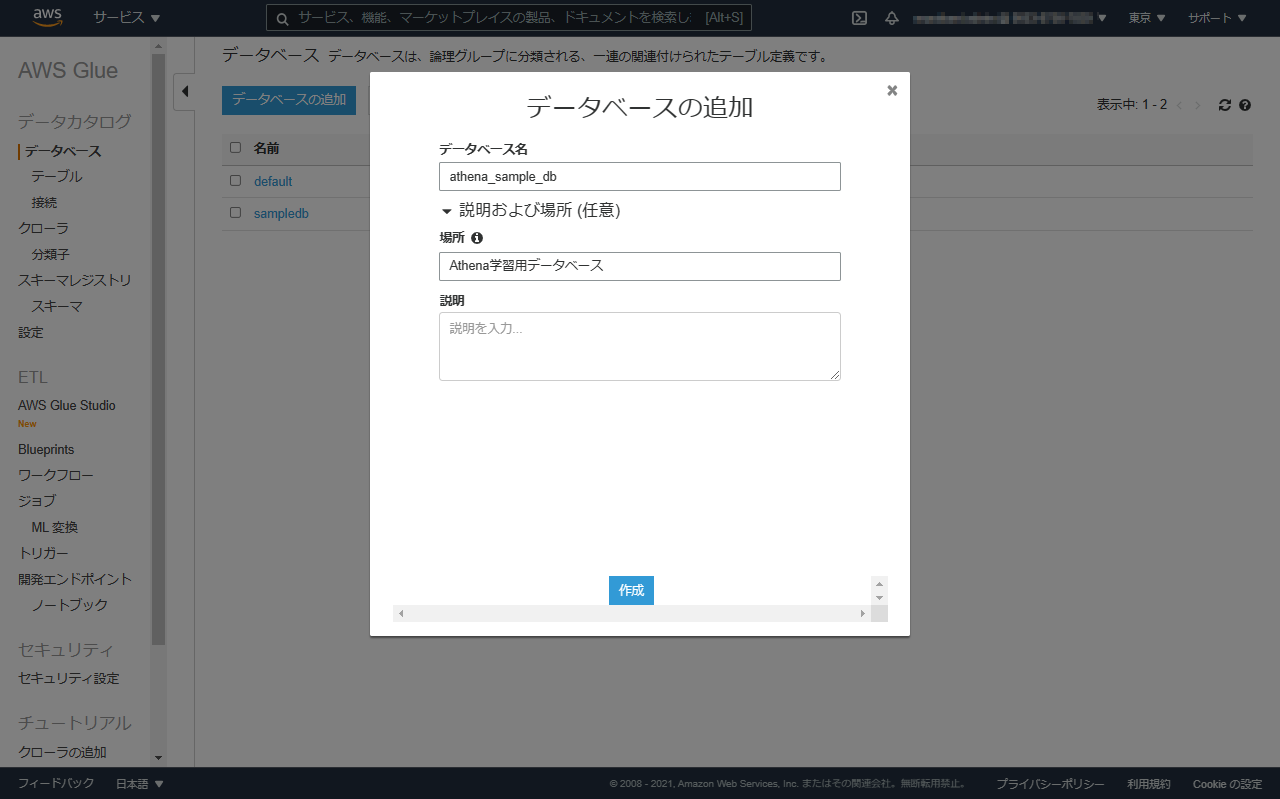
データベース名を入力して作成します。
※必要に応じて、他の項目も入力します。
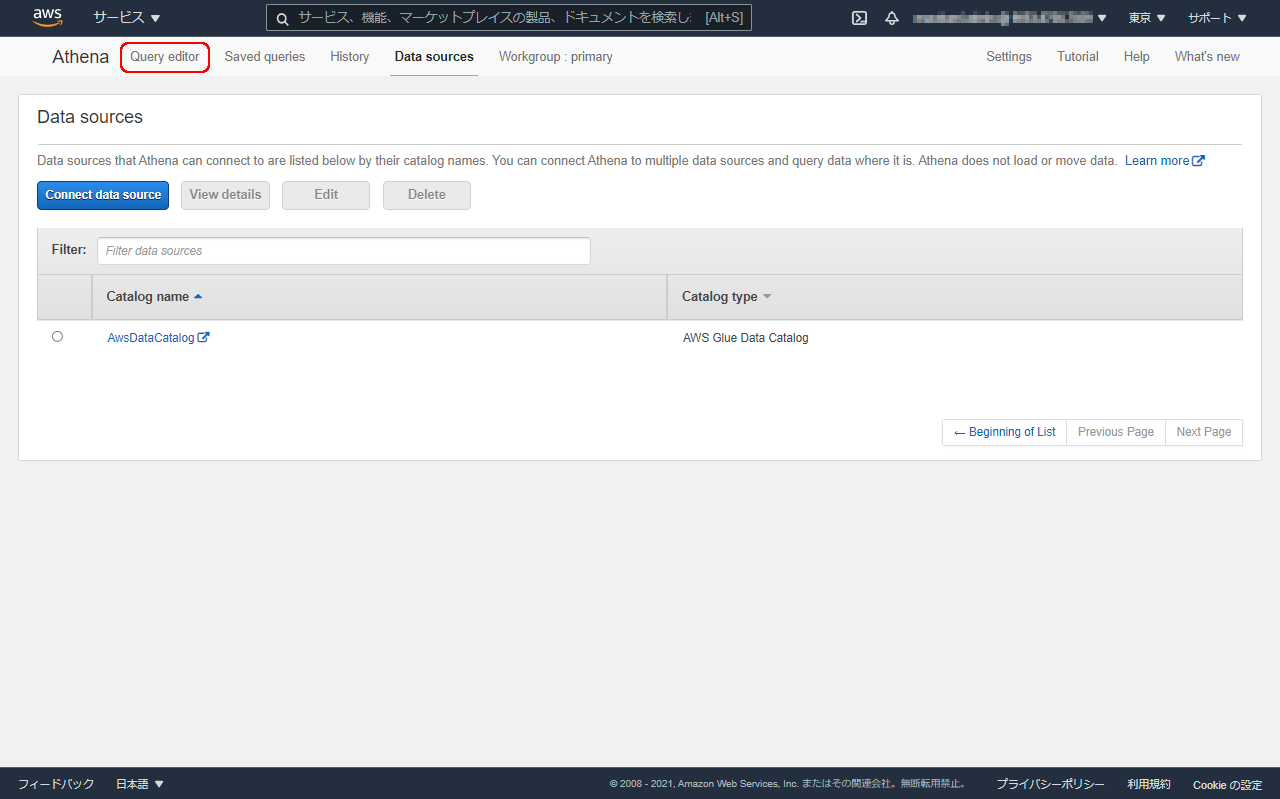
AthenaのData sourcesを開いたタブに戻り、Query editorをクリックします。

Databaseから、先ほど作成したデータベースを選択します。
テーブル作成
作成クエリの例(ELBアクセスログ)
Athena でのテーブル作成 の公式ページによると、ELBアクセスログを検索するテーブルの定義として、下記のようなものが定義されています。
__なお、この記事では、CSVのクエリを行うため、この方法は使いませんが、__参考のため、どのようにテーブルを定義しているのか、見ていきましょう。(ほかの形式のログをクエリするときに、参考になると思います。)
CREATE EXTERNAL TABLE IF NOT EXISTS cloudfront_logs (
`Date` Date,
Time STRING,
Location STRING,
Bytes INT,
RequestIP STRING,
Method STRING,
Host STRING,
Uri STRING,
Status INT,
Referrer STRING,
OS String,
Browser String,
BrowserVersion String
) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "^(?!#)([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+[^\(]+[\(]([^\;]+).*\%20([^\/]+)[\/](.*)$"
) LOCATION 's3://athena-examples-MyRegion/cloudfront/plaintext/';
Athenaでの独自の仕様があるので、軽く説明します。
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
この部分は、SerDe(シリアライザー/デシリアライザー)として、正規表現を使用する旨、規定しています。
WITH SERDEPROPERTIES (
"input.regex" = "^(?!#)([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+([^ ]+)\\s+[^\(]+[\(]([^\;]+).*\%20([^\/]+)[\/](.*)$"
)
この部分が、正規表現で各項目の取得を定義している部分です。
- 先頭の
^(?!#)・・・#で始まる行を除外 -
([^ ]+)・・・各項目を取得する部分 -
\\s+・・・スペース1文字以上(\sの\をエスケープ)
LOCATION 's3://athena-examples-MyRegion/cloudfront/plaintext/';
この部分が、ログファイルを置いているS3のパス(バケット、パス)を定義する部分です。
SerDe(シリアライザー/デシリアライザー)とは?
Athenaでは、前述のアクセスログのような書式を正規表現で規定できるほか、CSVやTSVなど、様々なデータ形式に対応し、そのデータ形式をSerDe(シリアライザー/デシリアライザー)として定義しています。
詳しくは、サポートされる SerDes とデータ形式のページをご参照ください。
CSVファイル解析用テーブル作成
今回処理するCSVについては、引用符で囲まれた値がデータに含まれていないので、LazySimpleSerDeを使用します。
詳しくは、CSV、TSV、およびカスタム区切りファイルの LazySimpleSerDeのページをご参照ください。
こちらのページで、例が記載されているので、参考に、今回解析用のCSVファイルを解析するためのテーブルを作成します。
KaggleからダウンロードしたCSVの項目は
- Date
- Prefecture
- Positive
- Tested
- Discharged
- Fatal
- Hosp_require
- Hosp_severe
の8列となっています。
また、先頭1行はヘッダのため読み飛ばすこととします。
このデータを入れるテーブル名をcovid19_prefecture_csvとして、下記のようにテーブル定義のクエリを作成します。
CREATE EXTERNAL TABLE IF NOT EXISTS covid19_prefecture_csv (
`Date` Date,
`Prefecture` STRING,
`Positive` INT,
`Tested` INT,
`Discharged` INT,
`Fatal` INT,
`Hosp_require` INT,
`Hosp_severe` INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
ESCAPED BY '\\'
LINES TERMINATED BY '\n'
LOCATION 's3://{バケット名}/covid19-prefecture-csv/'
TBLPROPERTIES ("skip.header.line.count"="1");
この中で、
TBLPROPERTIES ("skip.header.line.count"="1");
が、先頭1行をヘッダとして読み飛ばすことを意味しています。


先ほどのテーブル定義のクエリを入力し、Run queryボタンをクリックします。

テーブル作成に少し時間がかかるので、待ちます。
作成が完了すると、ResultsにQuery Successful.と表示され、左のTablesの欄に作成したテーブル名のリンクが表示されます。
テーブル名のリンクをクリックすると、列名がリスト表示されます。


クエリ実行


(タブの部分の+部分)をクリックして新たなクエリのタブを作成します。
例1:まず、CSVのすべての内容を取得するSQLを作成します。
SELECT * FROM covid19_prefecture_csv;
このクエリを貼り付けて実行します。

例2:北海道のみに絞り、日付でソートします。
SELECT
*
FROM covid19_prefecture_csv
WHERE prefecture = 'Hokkaido'
ORDER BY date
;

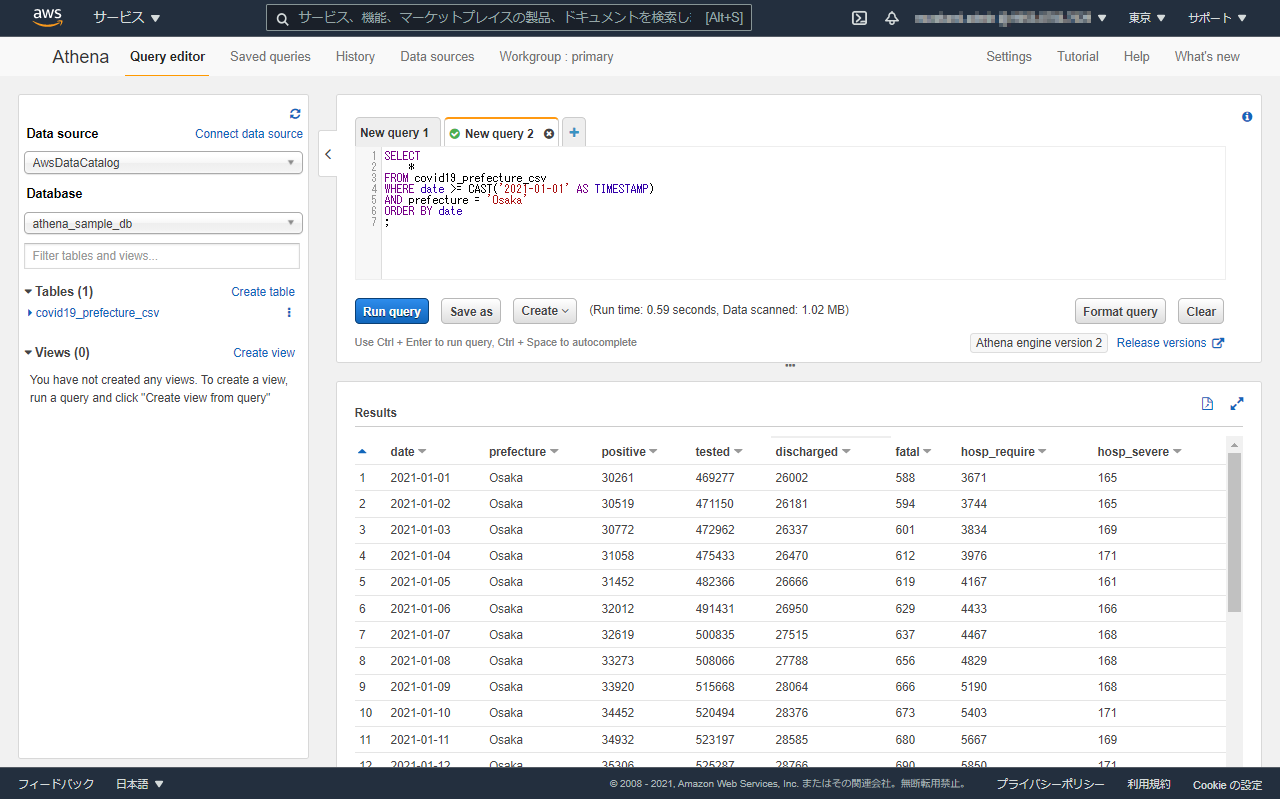
例3:大阪府、かつ、2021年以降の日付に絞り、日付でソートします。
SELECT
*
FROM covid19_prefecture_csv
WHERE date >= CAST('2021-01-01' AS TIMESTAMP)
AND prefecture = 'Osaka'
ORDER BY date
;
※MySQLなどと違い、日付はCASTが必要です。

Athenaの料金
Amazon Athena の料金をご参照ください。
こちらによると、クエリを実行して、スキャンされるデータ量によって課金されるとのことです。
東京リージョンでは、
スキャンされたデータ 1 TB あたり 5.00USD
とのことです。
ログの解析等程度では、せいぜいキロバイト、メガバイトくらいだと思うので、いきなり高額な請求が来ることはないと思いますが、念のため、
- 無駄にクエリを実行するのは控える
- LIMITでスキャンするデータの容量を抑えて実行する
といった注意は、しておいた方がいいと思います。
まとめ
- AWSでELB(ロードバランサ)を使うときは、アクセスログをAthenaでテーブルを作っておくと検索しやすいです。
- 確か、ELBの設定で、ログの出力先のS3を設定できたはず
- AthenaはELBのアクセスログ専用ではなく、たとえばApache HTTP Serverやnginxのアクセスログの解析にも使えるし、CSVみたいなファイルの解析にも使えます。
- ほかのクラウド(さくら)とかで構築したサイトでも、アクセスログを定期的にS3に上げておくと、後から解析しやすくなると思います。
- Athenaでは、解析対象ファイルのアップロード先を、S3のフォルダで設定できるので便利です。
- ファイルが増えても、勝手にいい感じに、追加されたファイルもクエリで引っ張ってきてくれます。
- Athenaでは、スキャンする容量によって課金されるので、無駄なクエリの実行を控えたり、LIMITでデータ量を抑えるなどの注意はしておいた方がいいです。