1. はじめに
本記事は【Python/AWS】の第4回として前回に引き続き、
AWSのサービスを利用した一連のデータ分析の続きとなります。
▼前回の記事はこちら▼
私自身、AWSのサービスを触るのは初めてだったので、
細かい説明など不足する点はあるかと思いますが、
大まかな流れをこちらで解説していきたいと思います。
本分析の全体像は以下のようになります。
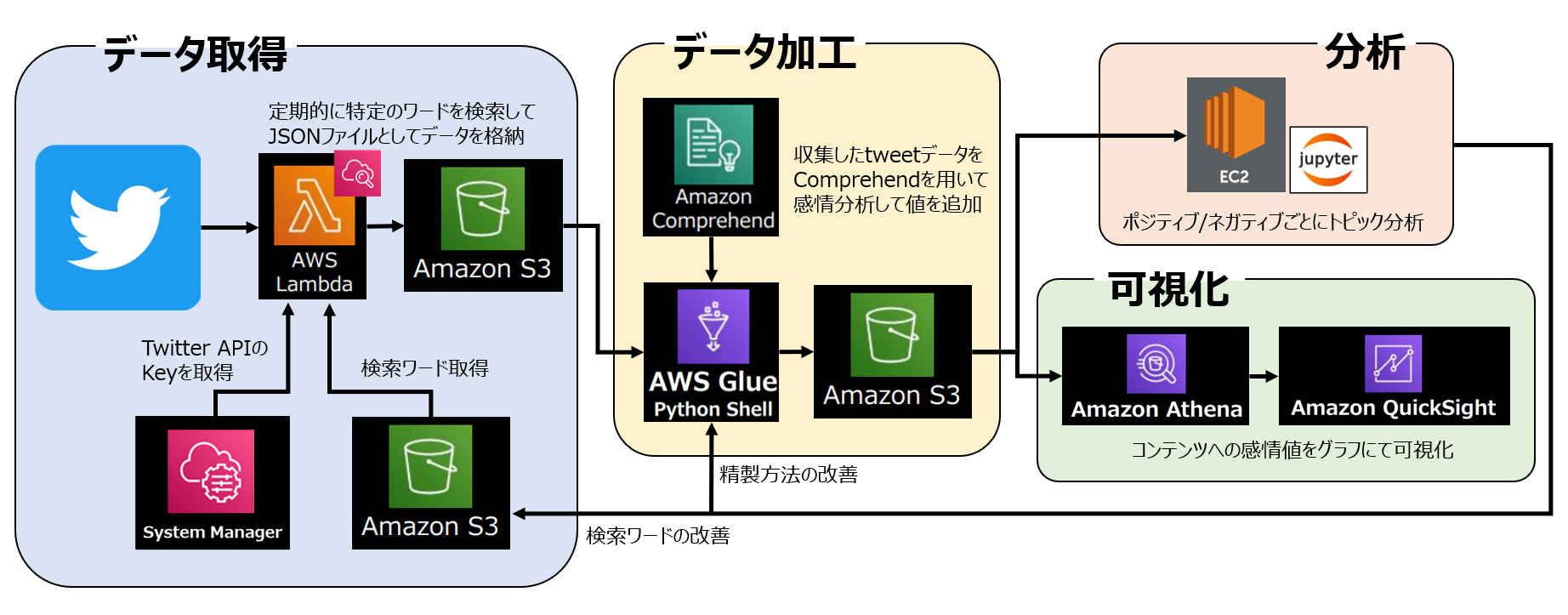
全体の分析目的は以前の分析から継続/発展して、
「Splatoon3」におけるコンテンツのユーザー満足度調査 です。
収集したデータから項目ごとに感情分析を行い、
ポジティブ/ネガティブの値を可視化することが最終目的です。
▼以前の記事はこちら▼
1-1. 本記事の概要と目標
今回のテーマは 「AWS Glueによるデータの加工」 ということで、
前回取り扱った感情分析を含んだ内容となっています。
初回、第2回ではデータの収集などにLambdaを使いましたが、
今回はとある理由から "AWS Glue" を使っていきます。
前回に引き続き、今回作成するパートのイメージはこのような形です。

使用するサービスとそれぞれの役割は以下の通りです。
Amazon S3: 様々な形式のデータを保管できるストレージ
Amazon Comprehend: テキストから洞察を見つける自然言語処理サービス
AWS Glue: データの検出/結合を簡単に行えるサーバーレスデータ統合サービス
なお本記事ではAWSの登録方法や初期設定、
Glue以外のサービス詳細については取り上げていません。
必要に応じて前回以前の記事、または以下を参考にして下さい。
1-2. 全体の流れ
自動実行の順番、流れとしては以下の通りです。
1.Glueのトリガーによる朝10時に実行
2.S3からJSONファイルをCSVとして読み込む
3.ツイートを感情分析して値を追加
4.新しいデータフレームをCSVとしてS3に出力
2. AWS Glueについて
2-1. AWS Glueとは
AWS GlueはAmazonが提供するサーバーレスで
データを検出、準備、移動、統合できるサービスです。
今回は様々ある機能の中から、 AWS Glue Studio という
機能を使って多量のデータの加工をしていきます。
今回は使用しませんが、保管している多種多様なデータを
効率的に管理するような機能も持っているようです。
▼AWS Glueの公式紹介▼
2-2. Lambdaとの違い
下の参考ページのリンク先でも解説されていますが、
Lambdaとの違いの一つとして稼働時間があります。
Lambdaの稼働限界が15分であるのに対して、
Glueは48時間という長い時間稼働することが可能 です。
今回行う作業は1万を超えるツイートのデータに対して、
データ読み込み、加工、CSVの出力を行うため、
Lambdaでは稼働時間を超えてエラーが出てしまいました。
性能やできることに関して大きな差はないようですが、
・時間のかかる作業は膨大な作業はGlue
・すぐに終わる軽量な作業はLambda
といった認識で良さそうです。
▼Lambdaとの違いに関する参考ページ▼
2-3. Glue使用の準備
上記のリンクからGlueのホーム画面に移動したら、
左側のメニューから [Jobs] を選択します。
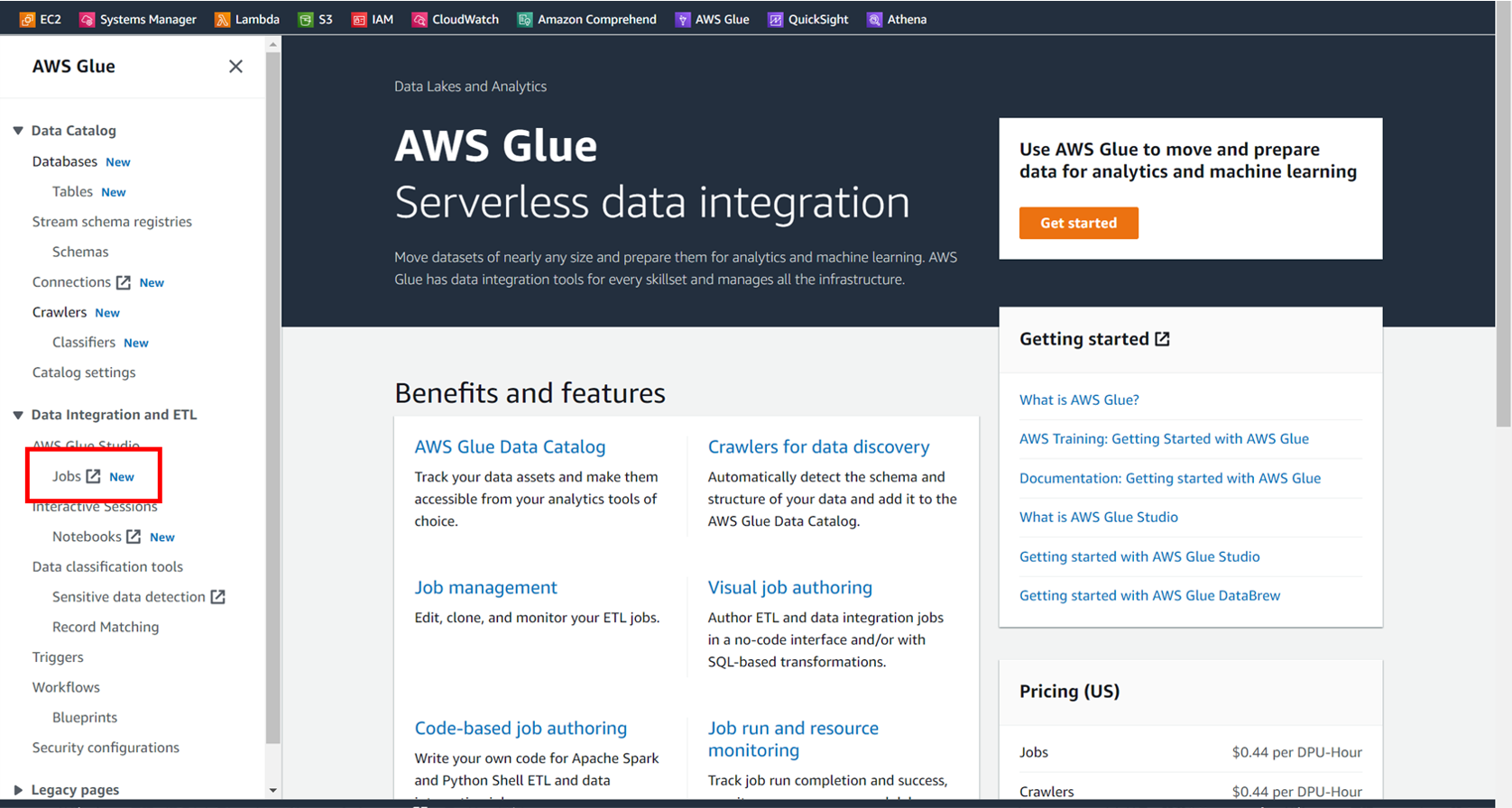
画像のように [Python Shell script editor] を選択し、
今回は [Create a new Script] の方を選んでいきます。
(初回同様にpyファイルを準備する場合は下を選ぶ)
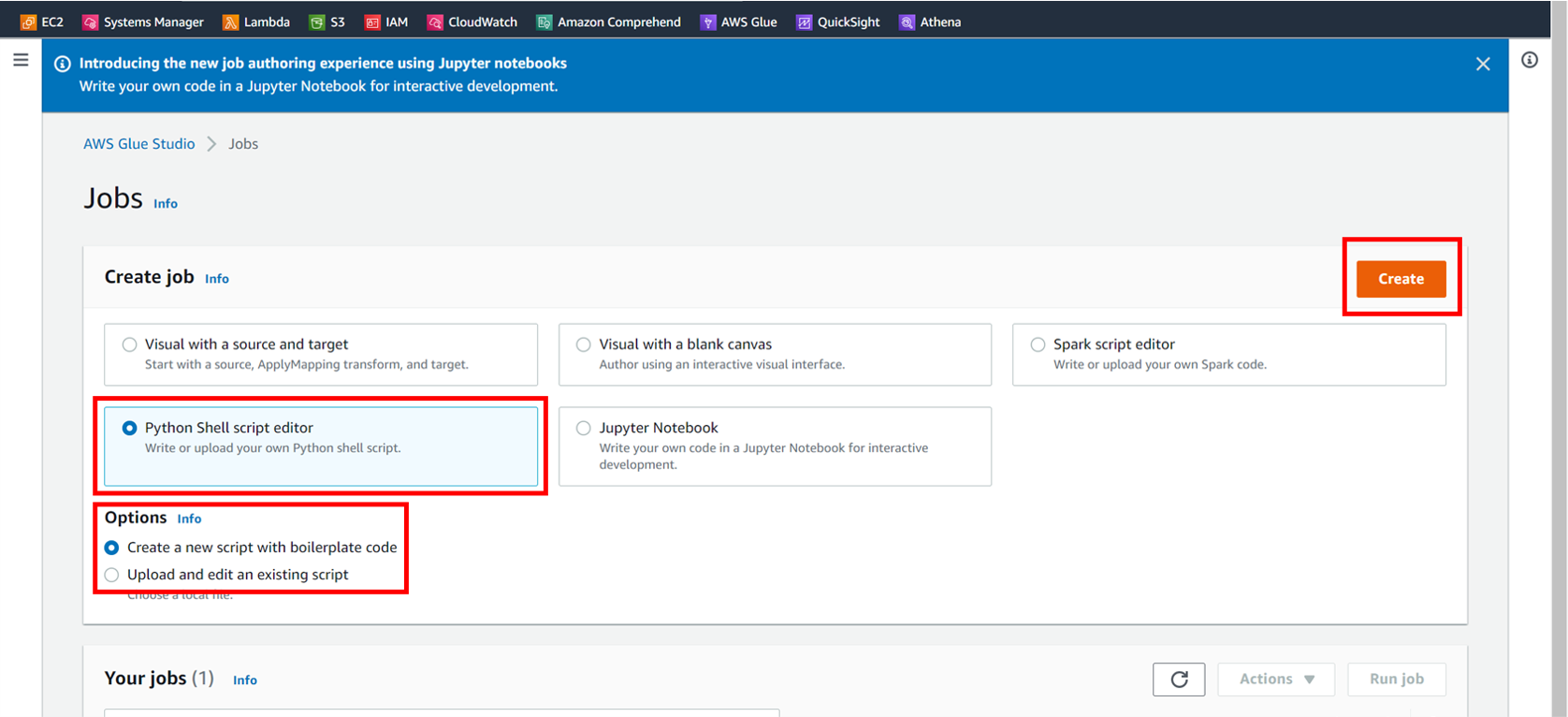
直接打ち込む場合は画像の赤枠に書きます。
こまめに右上の [Save] をしておきます。
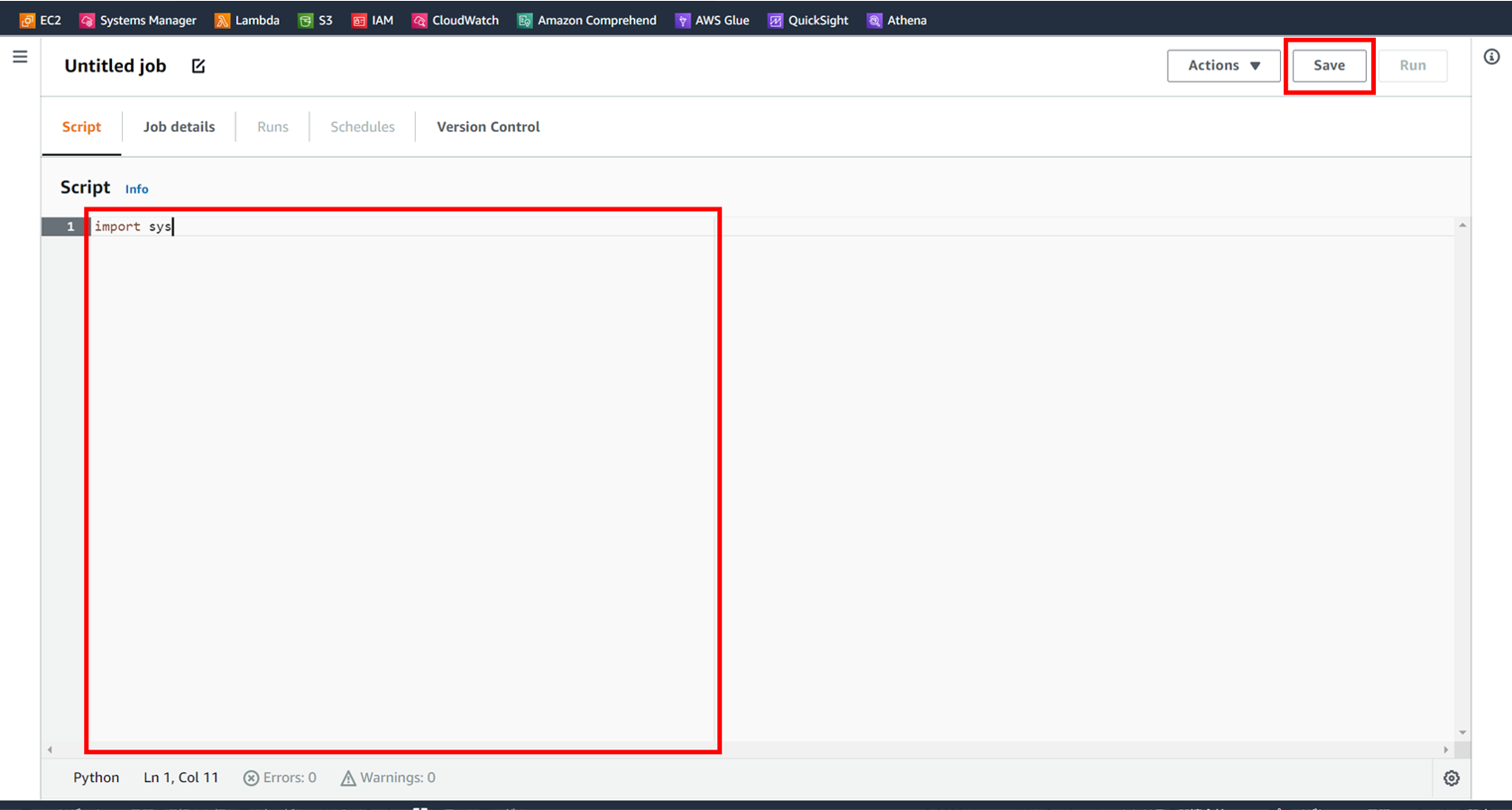
[Job details] で詳細を設定します。
名前、説明、使用するロール、バージョンを選択します。
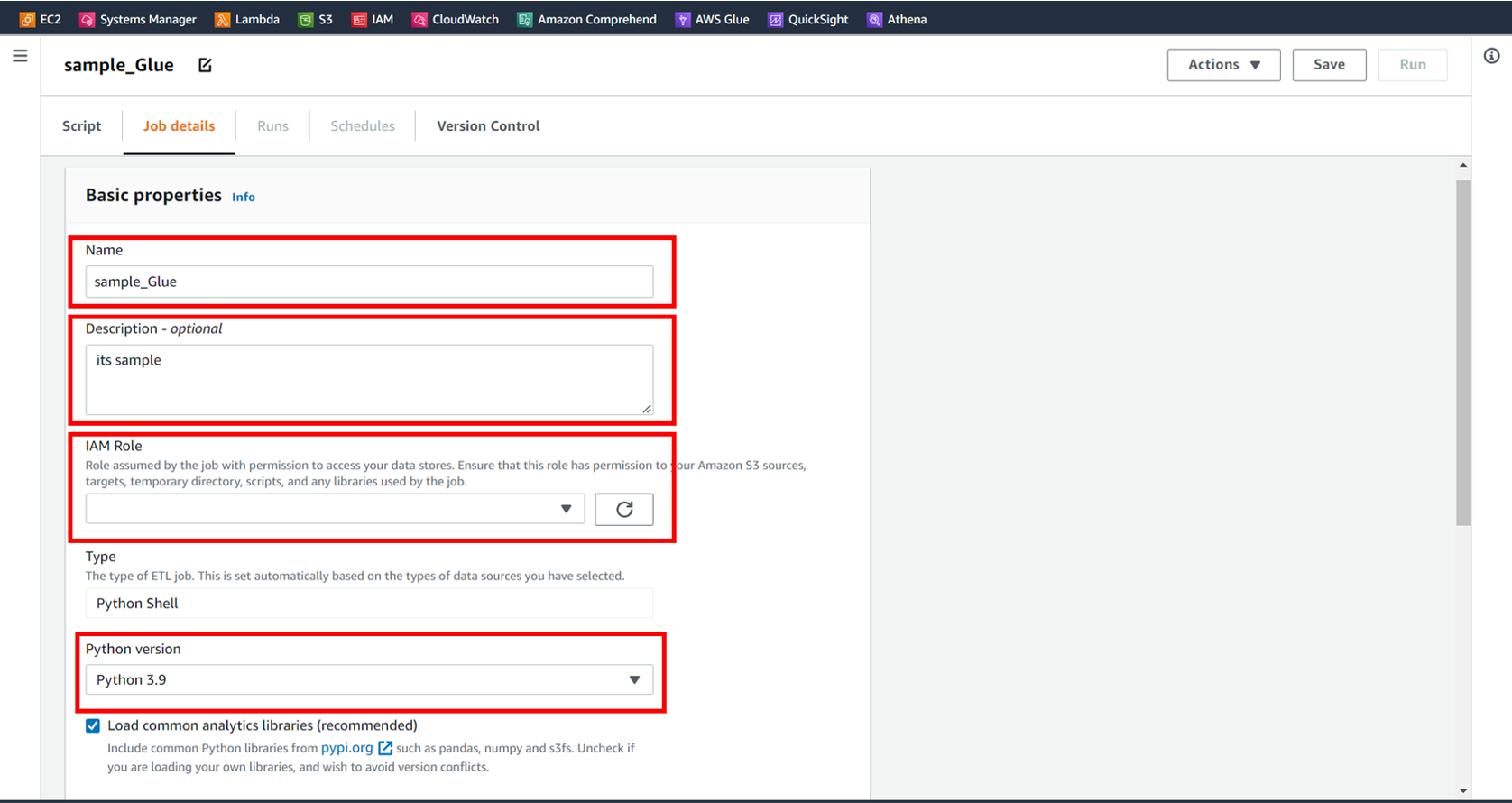
今回使用するGlueのロールには少なくとも
以下の2つの権限が必要になるので付与しておきます。
権限の追加についてはこちらで解説しています。

2-3. パッケージの使用
スクリプト内でパッケージを使用する際に、
外部から準備する方法もLambdaとは違いがあります。
今回はGlueで元から準備されているもの以外の
パッケージも使用するため、その準備をしていきます。
[Job details] ページの下部にある
[Advanced properties] を開きます。
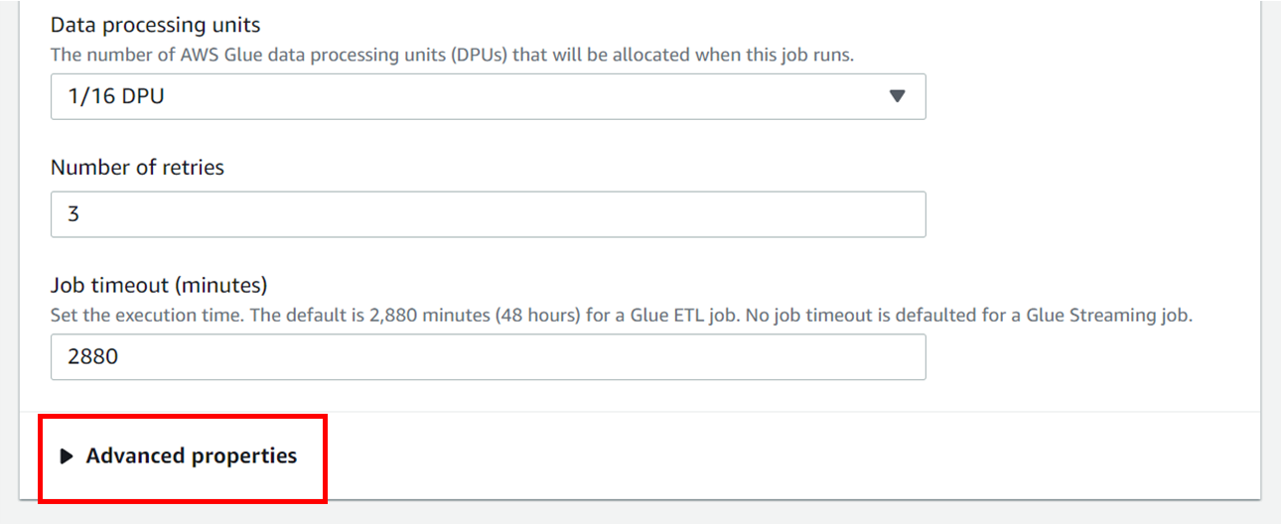
さらにページ下部の [Add new parameter] を開きます。
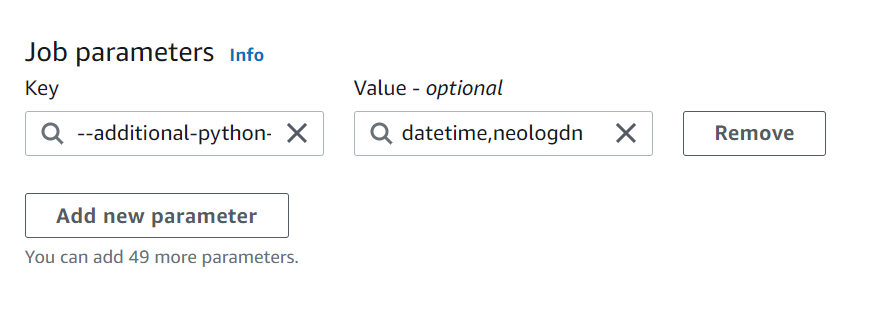
[Job parameters] の "Key" に 「--additional-python-modules」
"Value" に 「datetime,neologdn」 のようにカンマ区切りで
importしたいパッケージを入力しておきます。
Glueで元から使用できるパッケージについては、
以下の参考ページで一覧を確認することができます。
▼パッケージ仕様に関する参考ページ▼
3. 実装
大まかなと説明の流れとして、
1.データの準備
2.データ取得/データフレーム作成
3.データの加工
4.感情分析の値を追加
5.csvでデータを出力
の5段階に分けて確認をしていきます。
以下がコードの全体像です。
import json
import boto3
import pandas
import datetime
import re
import neologdn
#--------------------------------------準備--------------------------------------
#クライアント準備
s3_client = boto3.client("s3", "ap-northeast-1")
#テキストクレンジングの関数
def cleansing_text(text):
tmp = re.sub(r"#[^\s]*", "", text, 10)
tmp = re.sub(r"52", "ごーにー", tmp)
tmp = re.sub(r"96", "きゅーろく", tmp)
tmp = neologdn.normalize(tmp.lower())
cleansed_text = re.sub(r"[^ぁ-んァ-ン一-龥ー]+", "", tmp)
return cleansed_text
#テキスト内のスプラワード(検索ワード)の個数をカウントする関数
def count_key_word(text):
num = 0
for word in words:
if word in text:
num += 1
return num
#"created_at"を日本時間に変更する関数
def UTC_to_JTS(date):
delta_9 = datetime.timedelta(hours=9)
str_UTC = re.sub("T", " ", date[:19])
JTS = datetime.datetime.strptime(str_UTC, "%Y-%m-%d %H:%M:%S") + delta_9
str_JTS = datetime.datetime.strftime(JTS, "%Y-%m-%d %H:%M:%S")
return str_JTS
#ツイート検索の際にキーワードを格納したjsonファイルを読み込み
words_response = s3_client.get_object(Key="tweets_data_json/search_words.json", Bucket="for-twitter-api-bucket")
words_body = words_response["Body"].read()
search_words = json.loads(words_body.decode())["words"]
#「前日の日付文字列」+「ファイル名」をkeyに指定
t_delta = datetime.timedelta(hours=15)
yesterday = str(datetime.datetime.now() - t_delta)[:10]
wepsys = "tweets_data_json/" + yesterday + "_wepsys.json"
ssgoth = "tweets_data_json/" + yesterday + "_ssgoth.json"
bucket = "for-twitter-api-bucket"
#for文用にリストへ格納
key_list = [wepsys, ssgoth]
#-------------------------------------jsonデータをdataframeへ------------------------------------
#data_frame作成用のリスト
user_id = []
tweet_id = []
created_at = []
search_word = []
text = []
rt_count = []
rp_count = []
lk_count = []
qt_count = []
for i in range(2):
#前日のjsonファイル(tweet_data)を取得
json_response = s3_client.get_object(Key=key_list[i], Bucket=bucket)
json_body = json_response["Body"].read()
json_data = json.loads(json_body.decode())
#取得したtweet_dataの中身をリストに全て格納
for word in search_words[i]:
try:
for d in json_data[word]:
user_id.append(d["author_id"])
tweet_id.append(d["id"])
created_at.append(d["created_at"])
search_word.append(word)
text.append(d["text"])
rt_count.append(d["public_metrics"]["retweet_count"])
rp_count.append(d["public_metrics"]["reply_count"])
lk_count.append(d["public_metrics"]["like_count"])
qt_count.append(d["public_metrics"]["quote_count"])
except:
pass
#data_frameを作成
df_list=list(zip(user_id, tweet_id, created_at, search_word, text, rt_count, rp_count, lk_count, qt_count))
df = pandas.DataFrame(data=df_list, columns=["user_id", "tweet_id", "created_at","search_word", "text", "rt_count", "rp_count", "lk_count", "qt_count"])
#--------------------------------データの加工(時間変更、不要ツイート削除)-------------------------------------
#日本時間に変更
df["created_at"] = df["created_at"].map(lambda x : UTC_to_JTS(x))
#ツイート文章をクレンジング
df["text"] = df["text"].map(lambda x : cleansing_text(x))
#クレンジング後に空白になってしまった行、重複している行を削除
df = df[df["text"] != '']
df = df.drop_duplicates(subset=['text'])
#テキスト内でカウントしたいワードリストの準備
words = search_words[0] + search_words[1]
words += ["ごーにー", "きゅーろく", "ガロン"]
#関数を使って新しい列を追加
df["num_key_word"] = df["text"].map(lambda x : count_key_word(x))
#検索ワードの出現回数が6回以上のツイートデータ
n = 6
n_words = df[df["num_key_word"] >= n][["user_id","text"]]
#ワードの出現回数6回以上のツイートを期間内に3回以上しているuser_id
n_appearance = n_words.value_counts("user_id")
n_appearance = n_appearance[n_appearance >= 3]
del_id = list(n_appearance.index)
#定型文を流すbotなどの可能性が高いためアカウントごと除外する
df = df[~df["user_id"].map(lambda x : x in del_id)]
#ワードの出現回数が0回のツイート
del_tweet = df[df["num_key_word"] == 0]["tweet_id"].values
#こちらはツイート単位で削除する
df = df[~df["tweet_id"].map(lambda x : x in del_tweet)]
#----------------------------------------感情分析パート-----------------------------------------
#comprehendのインスタンスを作成
comprehend = boto3.client("comprehend", "ap-northeast-1")
#ツイートデータの感情分析の結果を取得
sentiment = df["text"].map(lambda x : comprehend.detect_sentiment(Text=x, LanguageCode="ja"))
#必要な値を一度リストに格納
sm = []
ps = []
ng = []
nt = []
mx = []
for s in sentiment:
sm.append(s["Sentiment"])
ps.append(s["SentimentScore"]["Positive"])
ng.append(s["SentimentScore"]["Negative"])
nt.append(s["SentimentScore"]["Neutral"])
mx.append(s["SentimentScore"]["Mixed"])
#dataframeに列として追加
df["sentiment"] = sm
df["positive"] = ps
df["negative"] = ng
df["neutral"] = nt
df["mixed"] = mx
#--------------------------------csv出力-------------------------------------
#csvに変換
csv = df.to_csv(index=False, line_terminator="\n")
#csvデータをs3へ格納
csv_key = "csv_data/" + yesterday + ".csv"
s3_client.put_object(Key=csv_key, Bucket=bucket, Body=csv)
3-1. データの準備
s3_client = boto3.client("s3", "ap-northeast-1")
words_response = s3_client.get_object(Key="tweets_data_json/search_words.json", Bucket="for-twitter-api-bucket")
words_body = words_response["Body"].read()
search_words = json.loads(words_body.decode())["words"]
t_delta = datetime.timedelta(hours=15)
yesterday = str(datetime.datetime.now() - t_delta)[:10]
wepsys = "tweets_data_json/" + yesterday + "_wepsys.json"
ssgoth = "tweets_data_json/" + yesterday + "_ssgoth.json"
bucket = "for-twitter-api-bucket"
key_list = [wepsys, ssgoth]
まずは準備として検索ワードの整理をします。
検索ワードを格納したJSONファイルを読み込み、
この後for文で回すkey_listを作成します。
このGlueは日本時間の10:00に動きますが、
Lambdaと同様にUTC基準で時間を取得してしまうため、
前日のデータを取得できるように設定しています。
3-2. データ取得/データフレーム作成
user_id = []
tweet_id = []
created_at = []
search_word = []
text = []
rt_count = []
rp_count = []
lk_count = []
qt_count = []
for i in range(2):
json_response = s3_client.get_object(Key=key_list[i], Bucket=bucket)
json_body = json_response["Body"].read()
json_data = json.loads(json_body.decode())
for word in search_words[i]:
try:
for d in json_data[word]:
user_id.append(d["author_id"])
tweet_id.append(d["id"])
created_at.append(d["created_at"])
search_word.append(word)
text.append(d["text"])
rt_count.append(d["public_metrics"]["retweet_count"])
rp_count.append(d["public_metrics"]["reply_count"])
lk_count.append(d["public_metrics"]["like_count"])
qt_count.append(d["public_metrics"]["quote_count"])
except:
pass
df_list=list(zip(user_id, tweet_id, created_at, search_word, text, rt_count, rp_count, lk_count, qt_count))
df = pandas.DataFrame(data=df_list, columns=["user_id", "tweet_id", "created_at","search_word", "text", "rt_count", "rp_count", "lk_count", "qt_count"])
ここでツイートデータのJSONファイルを読み込み、
必要な項目をデータフレームに変換しています。
Lambdaの稼働時間の問題で検索ワードを
大きく2つに分けていたので、ここでのfor文も
key_list[i]で2回に分けて取得しています。
3-3. データの加工
def cleansing_text(text):
tmp = re.sub(r"#[^\s]*", "", text, 10)
tmp = re.sub(r"52", "ごーにー", tmp)
tmp = re.sub(r"96", "きゅーろく", tmp)
tmp = neologdn.normalize(tmp.lower())
cleansed_text = re.sub(r"[^ぁ-んァ-ン一-龥ー]+", "", tmp)
return cleansed_text
def count_key_word(text):
num = 0
for word in words:
if word in text:
num += 1
return num
def UTC_to_JTS(date):
delta_9 = datetime.timedelta(hours=9)
str_UTC = re.sub("T", " ", date[:19])
JTS = datetime.datetime.strptime(str_UTC, "%Y-%m-%d %H:%M:%S") + delta_9
str_JTS = datetime.datetime.strftime(JTS, "%Y-%m-%d %H:%M:%S")
return str_JTS
df["created_at"] = df["created_at"].map(lambda x : UTC_to_JTS(x))
df["text"] = df["text"].map(lambda x : cleansing_text(x))
df = df[df["text"] != '']
df = df.drop_duplicates(subset=['text'])
words = search_words[0] + search_words[1]
words += ["ごーにー", "きゅーろく", "ガロン"]
df["num_key_word"] = df["text"].map(lambda x : count_key_word(x))
n = 6
n_words = df[df["num_key_word"] >= n][["user_id","text"]]
n_appearance = n_words.value_counts("user_id")
n_appearance = n_appearance[n_appearance >= 3]
del_id = list(n_appearance.index)
df = df[~df["user_id"].map(lambda x : x in del_id)]
del_tweet = df[df["num_key_word"] == 0]["tweet_id"].values
df = df[~df["tweet_id"].map(lambda x : x in del_tweet)]
ここで行う作業は大きく4つです。
・時間表記の変更
・ツイートのクレンジング
・検索ワードのカウントデータを追加
・不要なツイートの除去
3-3-1. 時間表記の変更
def UTC_to_JTS(date):
delta_9 = datetime.timedelta(hours=9)
str_UTC = re.sub("T", " ", date[:19])
JTS = datetime.datetime.strptime(str_UTC, "%Y-%m-%d %H:%M:%S") + delta_9
str_JTS = datetime.datetime.strftime(JTS, "%Y-%m-%d %H:%M:%S")
return str_JTS
df["created_at"] = df["created_at"].map(lambda x : UTC_to_JTS(x))
Twitterではデフォルトの時間表記がUTC基準で
"YYYY-mm-ddTHH:MM:SSZ" のようになっています。
これを日本時間に直しつつ、見やすいように
"YYYY-mm-dd HH:MM:SS" に変換しています。
3-3-2. ツイートのクレンジング
def cleansing_text(text):
tmp = re.sub(r"#[^\s]*", "", text, 10)
tmp = re.sub(r"52", "ごーにー", tmp)
tmp = re.sub(r"96", "きゅーろく", tmp)
tmp = neologdn.normalize(tmp.lower())
cleansed_text = re.sub(r"[^ぁ-んァ-ン一-龥ー]+", "", tmp)
return cleansed_text
df["text"] = df["text"].map(lambda x : cleansing_text(x))
df = df[df["text"] != '']
df = df.drop_duplicates(subset=['text'])
クレンジングでは主に日本語で使われる
"ひらがな","カタカナ","漢字","ー" のみ取り出します。
不要なテキスト除去のために数字も排除していますが、
検索ワードの中には数字を含むワードもあります。
クレンジングの際に必要なワードが除去されないように
re.sub(r"52", "ごーにー", tmp)のように変換しておきます。
最後に空欄、重複したデータを除去します。
3-3-3. 検索ワードのカウントデータを追加
def count_key_word(text):
num = 0
for word in words:
if word in text:
num += 1
return num
words = search_words[0] + search_words[1]
words += ["ごーにー", "きゅーろく", "ガロン"]
df["num_key_word"] = df["text"].map(lambda x : count_key_word(x))
この部分では検索ワードをテキスト内に
いくつ含んでいるかの特徴量を追加しています。
この特徴量はこの後に行うデータの精製に使用します。
3-3-4. 不要なツイートの除去
n = 6
n_words = df[df["num_key_word"] >= n][["user_id","text"]]
n_appearance = n_words.value_counts("user_id")
n_appearance = n_appearance[n_appearance >= 3]
del_id = list(n_appearance.index)
df = df[~df["user_id"].map(lambda x : x in del_id)]
del_tweet = df[df["num_key_word"] == 0]["tweet_id"].values
df = df[~df["tweet_id"].map(lambda x : x in del_tweet)]
先ほど作成した特徴量を使ってデータを精製します。
ここでの考えは2点あります。
まず1点。
キーワードの出現が0回のツイートについては、
ハッシュタグで抽出された のちに除去された可能性が高く、
文章の意味の扱いが不安定になるので除去してしまう。
そしてもう1点。
キーワードの出現が6回以上で多すぎるツイート、
かつ1日の出現数が3回以上のユーザー は、
ゲームに関する情報を定期で配信するbotの可能性が高い。
ユーザーの意見を反映するツイートではないため、
ここでは除去することにしました。
ここの検討は実際にグラフを描画して確認したり、
各ユーザーを確認してbotの割合を見た上で判断しました。
この精製方法についてはいずれ検討する予定です。
3-4. 感情分析の値を追加
comprehend = boto3.client("comprehend", "ap-northeast-1")
sentiment = df["text"].map(lambda x : comprehend.detect_sentiment(Text=x, LanguageCode="ja"))
sm = []
ps = []
ng = []
nt = []
mx = []
for s in sentiment:
sm.append(s["Sentiment"])
ps.append(s["SentimentScore"]["Positive"])
ng.append(s["SentimentScore"]["Negative"])
nt.append(s["SentimentScore"]["Neutral"])
mx.append(s["SentimentScore"]["Mixed"])
df["sentiment"] = sm
df["positive"] = ps
df["negative"] = ng
df["neutral"] = nt
df["mixed"] = mx
前回の記事で利用したComprehendを使って
テキスト毎の感情分類の確信度 を追加しています。
3-5. csvでデータを出力
csv = df.to_csv(index=False, line_terminator="\n")
csv_key = "csv_data/" + yesterday + ".csv"
s3_client.put_object(Key=csv_key, Bucket=bucket, Body=csv)
最後にデータフレームをcsvに変換して、
Bodyに格納してs3へ出力しています。
のちにAthenaでクエリをする際に必要になるので、
line_terminator="\n"を指定しています。
これで一連の作業は完了です。
4. デプロイ
上記コードをpyファイルでアップロードするか、
コンソール画面にコピペしたらコードは完了です。
まずはコードが正しく動くかテストをします。
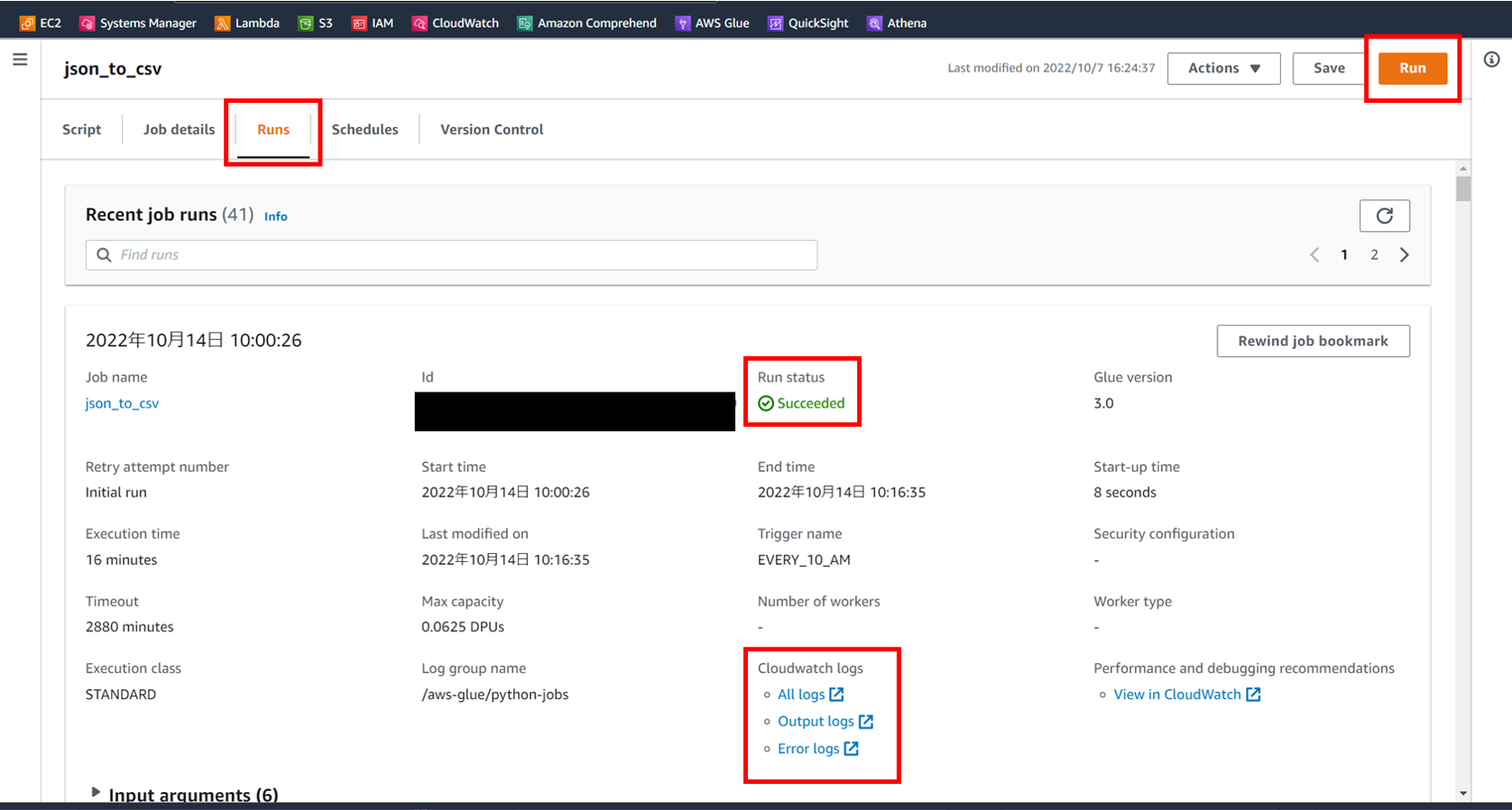
[Run] のボタンを押下するとコードが動きます。
[Runs] タブの [Cloudwatch logs] でログも確認可能で、
成功すると [Run status] に success と表示されます。
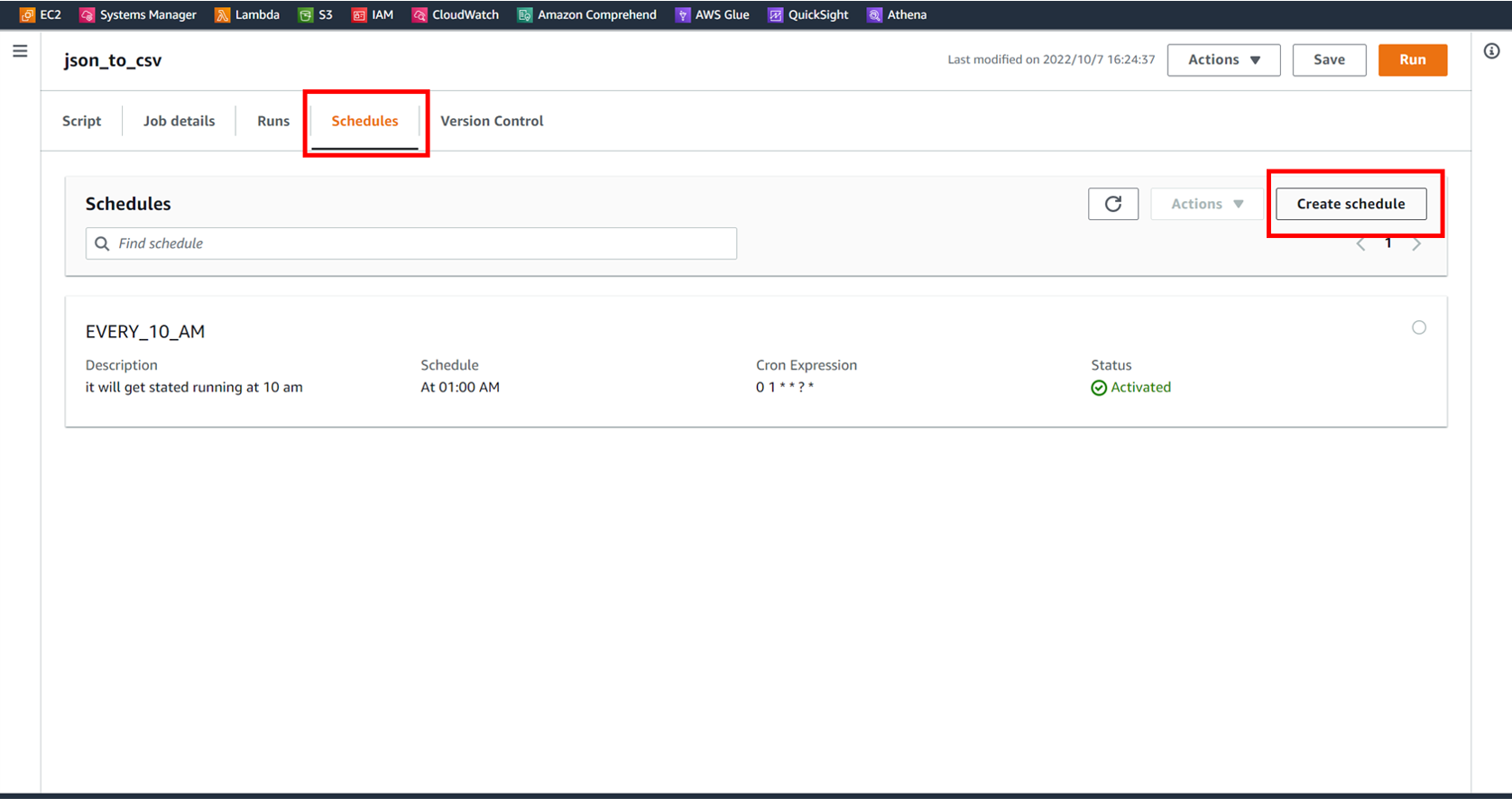
次に稼働スケジュールの設定をします。
[schedules] タブの [Create schedule] を選択します。
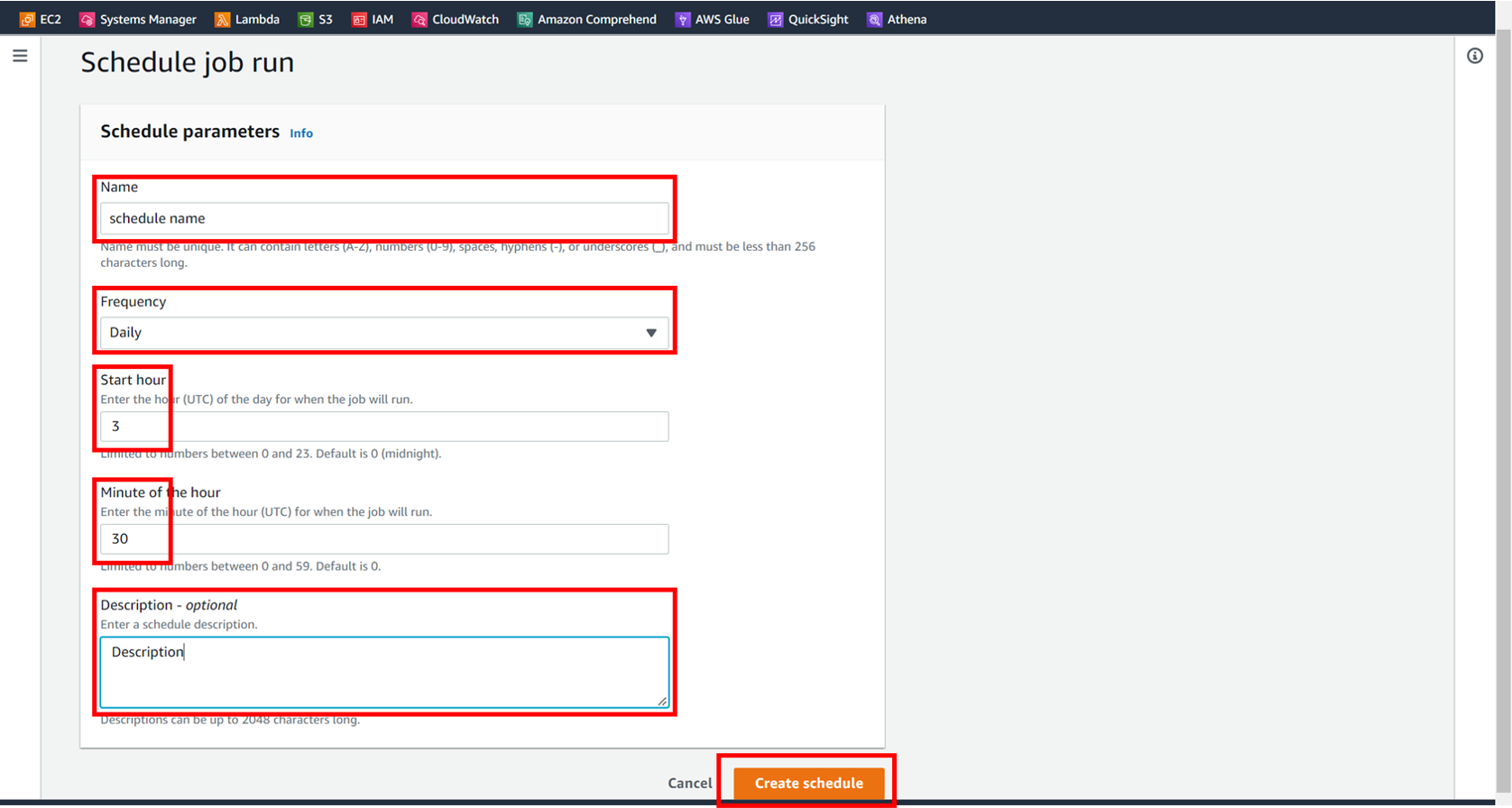
名前、頻度、時間、説明の欄を埋めていきます。
UTC基準なので画像の例だと昼の12:30に動きます。
最後に [Create schedule] を押せば設定も完了です。
5. 所感と今後の展望
5-1. 躓いた点
・Glueを使用する理由
・外部パッケージの利用
・データの精製
今回の記事でも取り上げましたが、
最初は Lambdaとの違いの理解が曖昧 で、
わざわざGlueを採用する必要があるのか迷いました。
結果的に作業時間が15分を超えることが分かったため
今回はGlueを使うこととなりました。
しかしコードの見直しなどによって処理を軽くして、
15分以内に収めるような工夫もあるのかも知れません。
外部パッケージの利用については調べて解決しました。
記事を上げて下さっている先駆者の方に感謝です。
データの精製 については今後の課題です。
今回の処理だけでも数百件のデータは除外していますが、
まだまだ精度は足りていないというのが個人の感想です。
5-2. 今後の展望
今回までで必要なデータを含むcsvファイルを
自動的に出力する仕組みができました。
次回はこのデータを使って可視化を行います。
またデータの精製はずっと課題になりそうです。
結果に正解がある作業ではないため、
有意性の検討に非常に頭を使う作業です。
5-3. さいごに
本記事を読んで頂いてありがとうございました。
コメントや質問、お気軽に宜しくお願い致します。
次回の記事