1. はじめに
本記事は【Python/AWS】の第2回として前回に引き続き、
AWSのサービスを利用した一連のデータ分析の続きとなります。
▼前回の記事はこちら▼
私自身、AWSのサービスを触るのは初めてなので、
細かい説明など不足する点はあるかと思いますが、
大まかな流れをこちらで解説していきたいと思います。
本分析の全体像は以下のようになります。
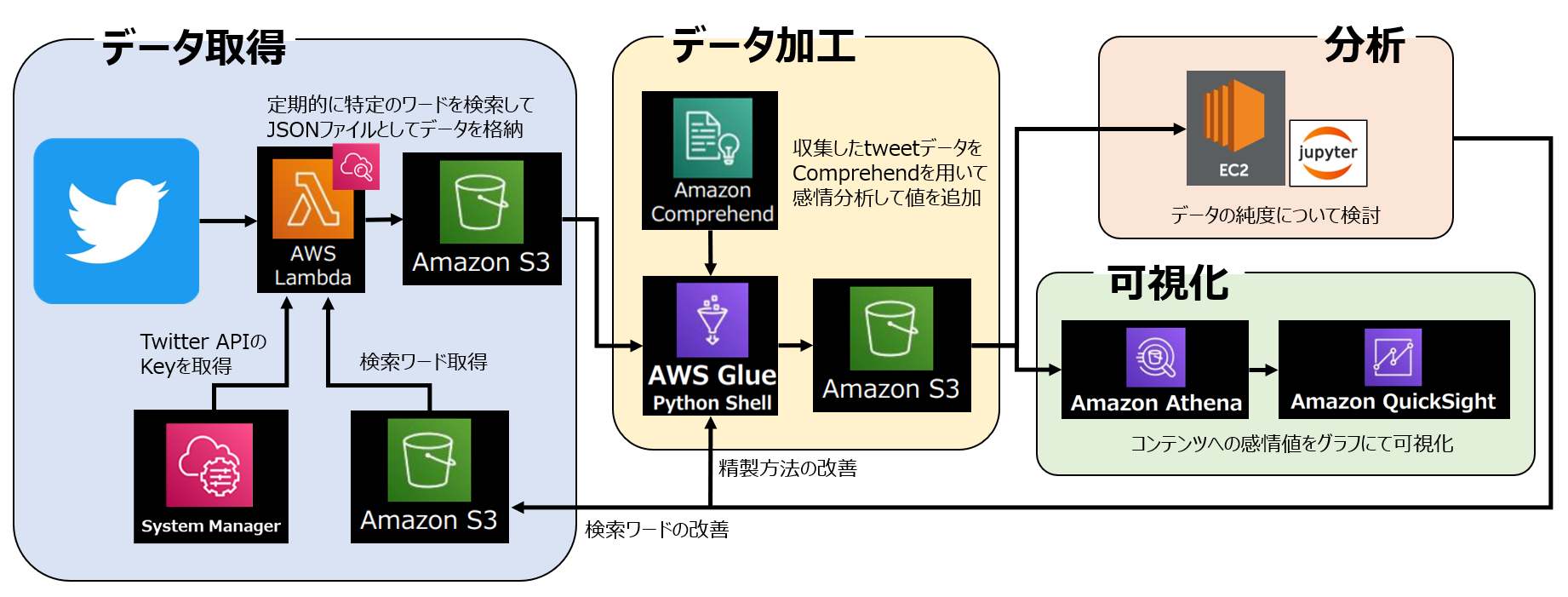
全体の分析目的は以前の分析から継続/発展して、
「Splatoon3」におけるコンテンツのユーザー満足度調査 です。
収集したデータから項目ごとに感情分析を行い、
ポジティブ/ネガティブの値を可視化することが最終目的です。
▼以前の記事はこちら▼
1-1. 本記事の概要と目標
今回のテーマは 「LambdaからS3へのデータ出力」 ということで、
Twitterから収集したツイートのデータをJSON形式にて、
S3バケットへ自動で格納してくれる仕組みを作ります。
今回作成するパートのイメージはこのような形です。
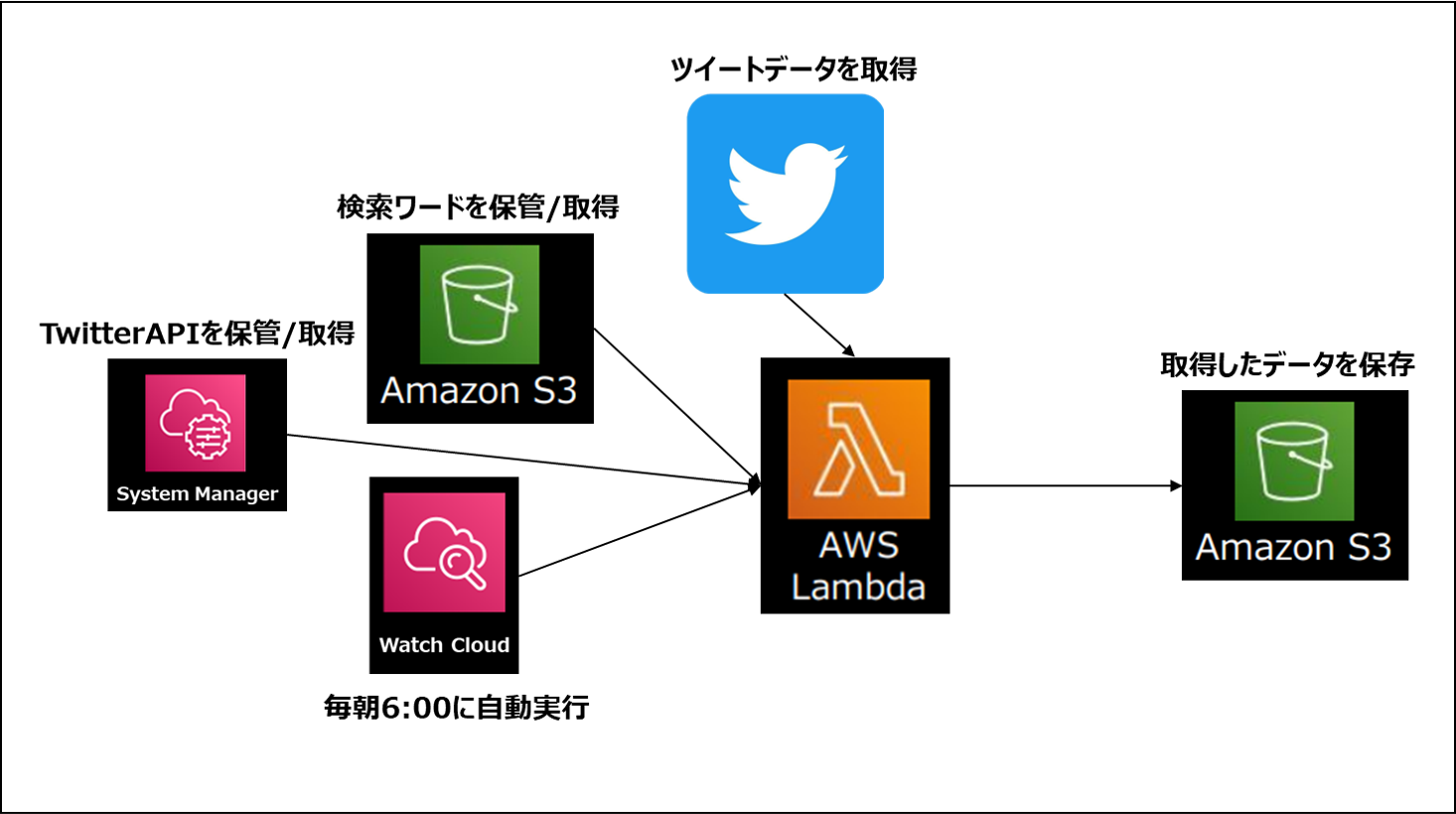
使用するサービスとそれぞれの役割は以下の通りです。
System Maneger: TwitterAPIのkey/tokenなどを安全に保管する
Watch Cloud: Lambdaを実行するタイミングをコントロールする
AWS Lambda: Pythonスクリプトを実行するためのサービス
Amazon S3: 様々な形式のデータを保管できるストレージ
なお本記事ではAWSの登録方法や初期設定、
S3以外のサービスの詳細はあまり取り上げていません。
必要に応じて前回の記事、または以下の記事を参考にして下さい。
1-2. 全体の流れ
自動実行の順番、流れとしては以下の通りです。
1.Watch Cloudにて毎日00:00にLambdaを起動
2.System Manager/S3からwitterAPI_key/検索ワードを取得
3.Twitterにて指定されたワードを検索
4.取得したJSONファイルをS3バケットへ格納
2. Amazon S3の準備
まずは今回使用するS3の準備をしていきます。
Amazon S3はAWSの高機能ストレージサービスです。
一度準備してしまえば簡単に他サービスと
スムーズな連携が可能なので今回から利用します。
▼Amazon S3の概要▼
2-1. バケットの作成
まずは今回メインで使用するバケットを作成します。
作成に伴う操作自体はとても簡単です。
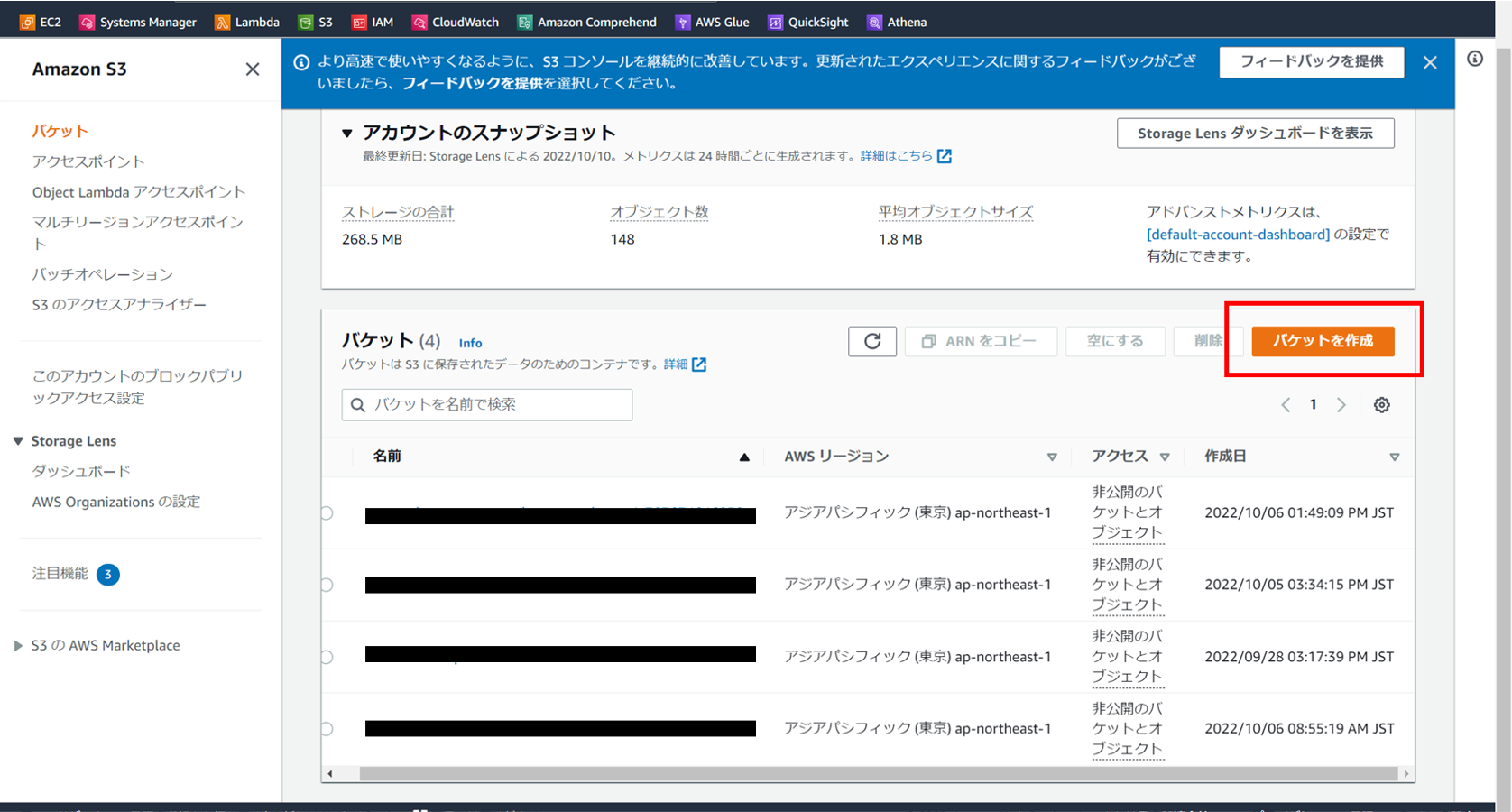
自身のAWSのコンソール画面へログインし、
「s3 → バケットを作成 → 名前記入/リージョン選択」
の順で必要な項目を埋めていくだけで作成は完了です。
▼バケット作成の参考▼
2-2. 権限の設定
次にIAMの権限を設定していきます。
Lambdaからs3のデータにアクセスするには、
適用したIAMに適切な権限を付与する必要があります。
IAMのロール設定から「許可を追加」→「ポリシーをアタッチ」を選択。
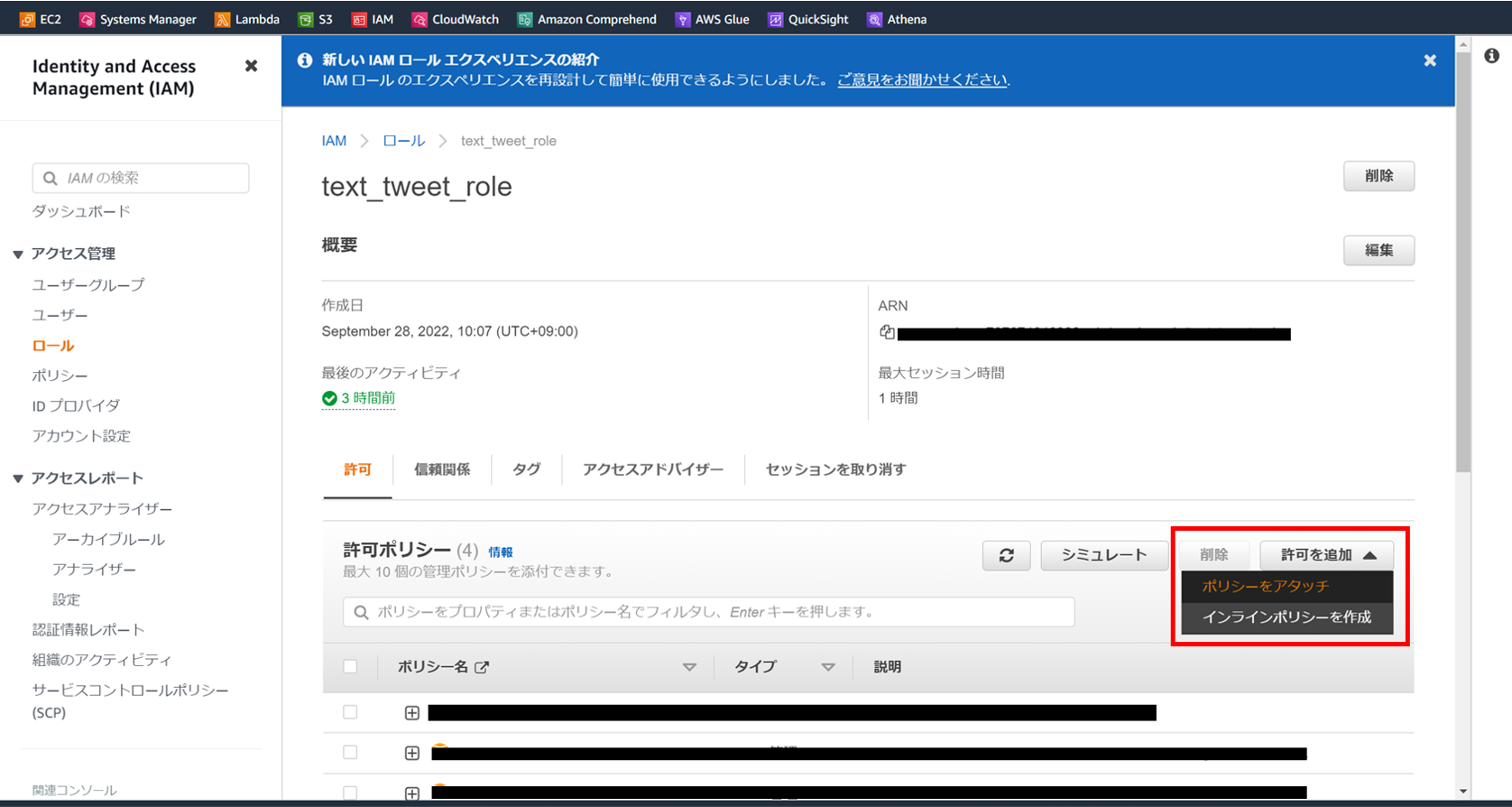
今回は「AmazonS3FullAccess」を検索して選びます。
(必要に応じてReadOnly等を選択します)
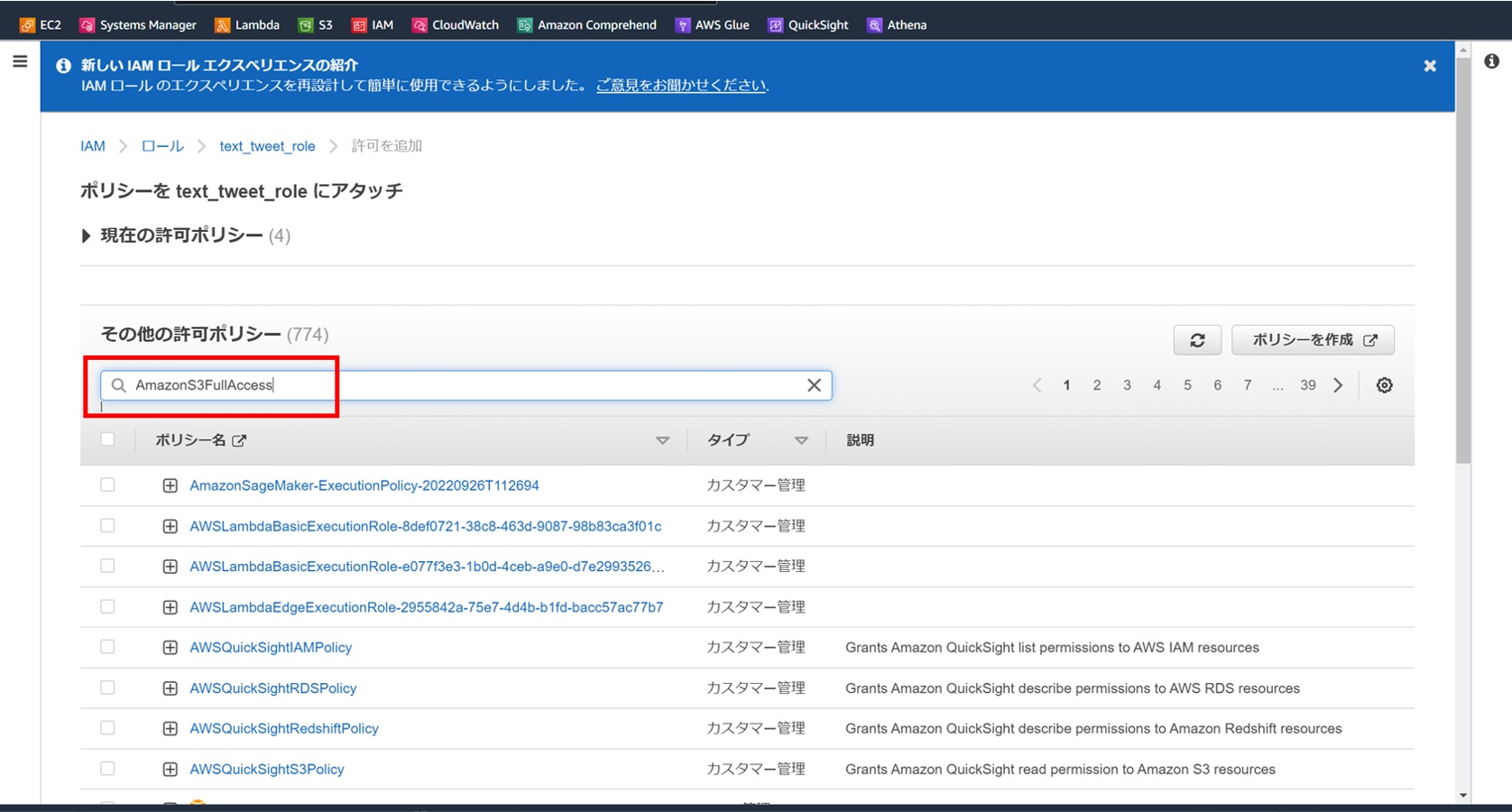
この設定を行うことで、LambdaからS3にアクセスし、
データの読み書きを自由に行えるようになります。
▼IAMロールの作成方法▼
3. 検索ワードの準備
次にツイートのデータを収集する際に、
検索したいワードを格納したJSONファイルを準備します。
本来はこの検索ワードもトピック分析などを用いて、
検索するべきワードを自動で抽出したかったのですが、
今回はワードをベタ打ちで設定していきます。
トピック分析からの抽出を断念した理由は、
Twitter上では分析対象に無関係のツイートを大量に
拾ってしまい、適切なワードを抽出できなかったためです。
まずはドメイン知識を使って網羅的にワードを設定し、
その後にワードを精査、またはクラスタリングを用いて
関係ないツイートを除く作業を検討することにしました。
3-1. JSONファイルの作成
まずは検索ワードをJSONファイルとして作成します。
ゲームに関わるツイートで使用されるであろう
ワードを洗い出したところ、300個を超えてしまいました。
300個をそのまま並べて検索してしまうと、
Lambdaの稼働限界の15分を超えてしまう可能性があるため、
全体を2つに分割した状態で格納しておきます。
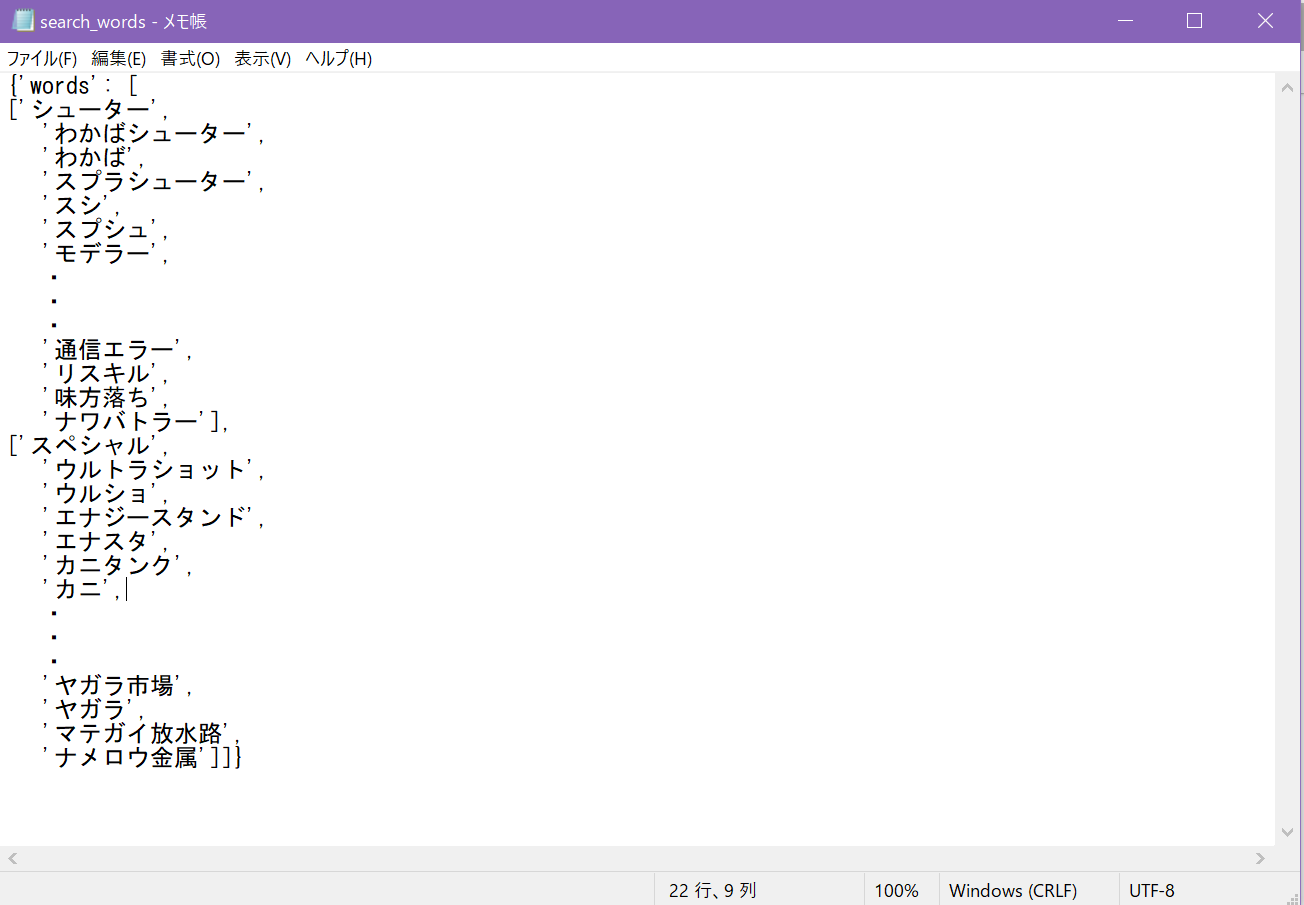
jsonファイルの作成にはwindowsのメモ帳を使いました。
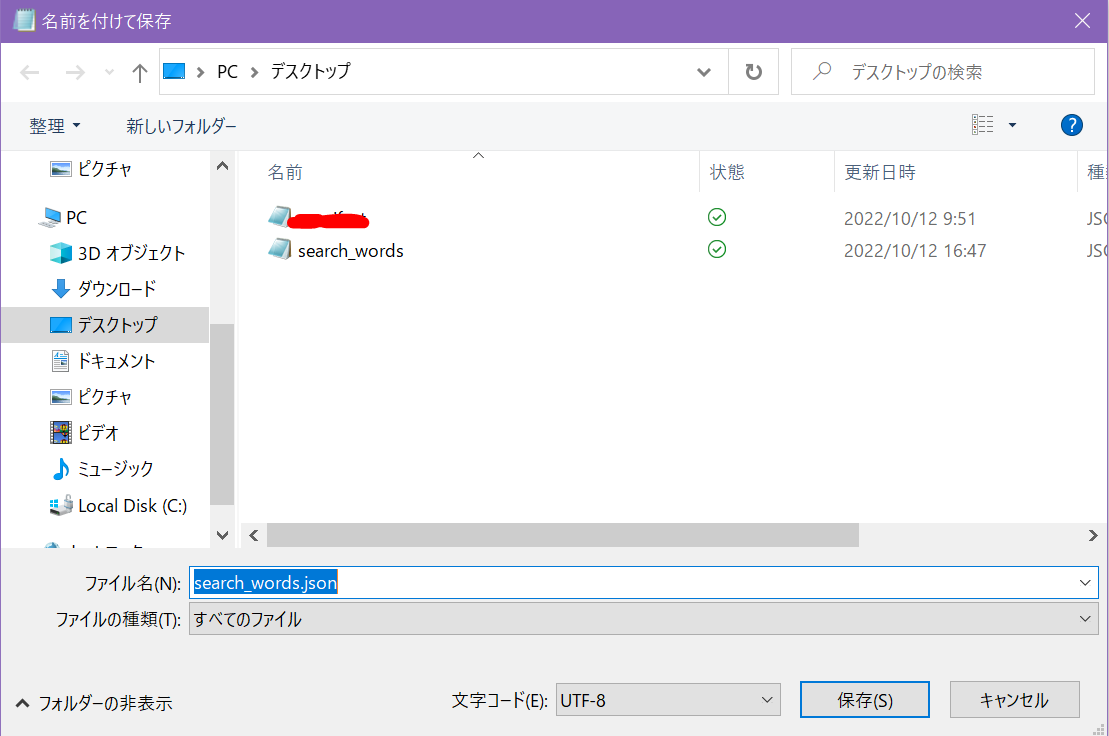
名前の後ろに「.json」を付けて保存しておきます。
私はこの一連の分析フローの作成時、
JSONファイルの扱いが全く分からず苦労していました。
記録として自分が参考にさせて頂いたページを載せておきます。
▼JSON関連の参考ページ▼
3-2. コンソールでアップロード
では作成したJSONファイルをS3に格納していきます。
検索ワードをLambdaにベタ打ちするのではなく、
わざわざファイルを別にした理由としては、
今後の検索ワード精査の際に管理しやすくするためです。
まずコンソール画面から直接アップロードする方法です。
この後説明する方法よりも圧倒的に簡単です。
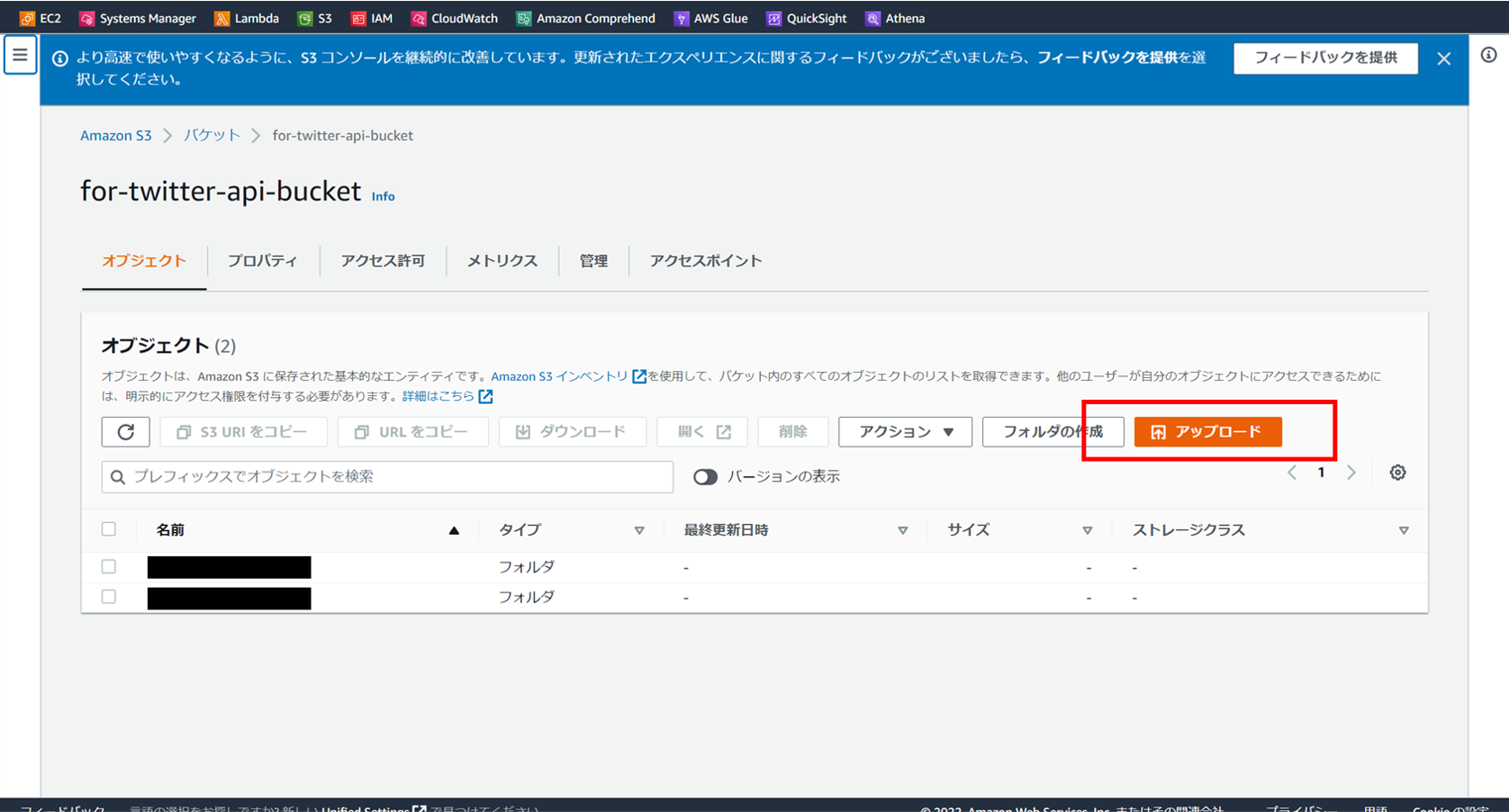
作成したバケットのメニューから「アップロード」を押し、
「ファイル」を選択するとフォルダから選ぶことができます。
コンソールからのアップロードは以上で完了です。
3-3. ローカル環境からアップロード
今回は上記の方法が簡単ですが、
ローカル環境からアップロードすることも可能です。
この方法は次回の記事でも必要になります。
import boto3
import json
s3_client = boto3.client("s3", "ap-northeast-1",
aws_access_key_id='*key_idを入力*',
aws_secret_access_key='*secret_keyを入力*')
search_word= {"words":[["あああ",
"いいい",
"ううう"],
["えええ"],
["おおお"]]}
key = "*格納先s3のフォルダ名*"
bukcet = "*s3のバケット名*"
body = json.dumps(search_word)
s3_client.put_object(Key=key, Bucket=bucket, Body=body)
boto3のクライアントを"s3"で作成し、
"Key","Bucket","Body"の3つを指定しています。
またLambdaからの出力時には必要ありませんが、
ローカル環境からs3へデータをアップロードするには、
AWSの"acceess_key_id"と"secret_acceess_key"が必要です。
▼access_keyの取得方法▼
4. 実装
大まかなと説明の流れとして、
1.パラメータの取得
2.検索ワードの取得
3.ツイートの検索
4.s3バケットへの格納
の4段階に分けて確認をしていきます。
以下がコードの全体像です。
import sys
#インストール元のディレクトリ相対パスを指定する
sys.path.append('./python_package')
import json
import tweepy
import boto3
import datetime
ssm_client = boto3.client('ssm', "ap-northeast-1")
s3_client = boto3.client('s3', "ap-northeast-1")
def lambda_handler(event, context):
#twitterAPIのキーをssmから取得
response = ssm_client.get_parameters(Names=["/credentials/twitter"], WithDecryption=True)
params = json.loads(response['Parameters'][0]['Value'])
bearer_res = ssm_client.get_parameters(Names=["bearer_token"], WithDecryption=True)
#twitterAPIのclientを作成
tw_client = tweepy.Client(consumer_key = params["consumer_key"],
consumer_secret = params["consumer_secret"],
access_token = params["access_token"],
access_token_secret = params["access_token_secret"],
bearer_token = bearer_res["Parameters"][0]["Value"]) #文字列が長いとjsonファイルの読み込みでエラーになるため
#ツイート取得メソッドのstart_timeが確実に日本時間前日の0時になるように定義
t_delta = datetime.timedelta(hours=15) #UTCから"+9h"で日本時間、かつ"-24h"で確実に前日に変換
yesterday = str(datetime.datetime.now() - t_delta)[:10] #前日の日付文字列("YYYY-MM-DD")
start_time = yesterday + "T00:00:00Z" #日本時間で前日の00:00に変換
#s3とのデータ連携に必要な変数を定義
key = "tweets_data_json/search_words.json"
bucket = "for-twitter-api-bucket"
#事前に設定した検索ワード(jsonファイル)をs3から取得
response = s3_client.get_object(Key=key, Bucket=bucket)
body = response["Body"].read()
spla_words = json.loads(body.decode())["words"][1]
#tweetsのデータを辞書型で格納する準備
tweets_dic = {}
#tweet取得
for word in spla_words:
tweets = tw_client.search_recent_tweets(query=word,
start_time = start_time,
max_results = 100,
tweet_fields = ["created_at", "public_metrics"],
expansions = "referenced_tweets.id.author_id",
user_fields = ["id", "username"])
tweets_dic[word] = tweets
#取得したデータをjson形式にする準備
json_dic = {}
for w in spla_words:
tmp_list= []
try:
for tweet in tweets_dic[w].data:
tmp_list.append(tweet.data)
json_dic[w] = tmp_list
except:
pass
#jsonに変換
json_contents = json.dumps(json_dic)
#s3格納の準備
file_name = "tweets_data_json/" + yesterday + "_ssgoth.json" #取得対象の日付("YYYY-MM-DD")でフォルダを作成
#s3への格納
s3_client.put_object(Body=json_contents, Bucket=bucket, Key=file_name)
4-1. パラメータの取得
ssm_client = boto3.client('ssm', "ap-northeast-1")
s3_client = boto3.client('s3', "ap-northeast-1")
response = ssm_client.get_parameters(Names=["/credentials/twitter"], WithDecryption=True)
params = json.loads(response['Parameters'][0]['Value'])
bearer_res = ssm_client.get_parameters(Names=["bearer_token"], WithDecryption=True)
tw_client = tweepy.Client(consumer_key = params["consumer_key"],
consumer_secret = params["consumer_secret"],
access_token = params["access_token"],
access_token_secret = params["access_token_secret"],
bearer_token = bearer_res["Parameters"][0]["Value"])
まずはssmとs3のクライアントを作成して、
前回記事と同様にTwitterAPIのkey/tokenを取得、
その値を使ってtweepyのクライアントを作成します。
4-2. 検索ワードの取得
key = "tweets_data_json/search_words.json"
bucket = "for-twitter-api-bucket"
#事前に設定した検索ワード(jsonファイル)をs3から取得
response = s3_client.get_object(Key=key, Bucket=bucket)
body = response["Body"].read()
spla_words = json.loads(body.decode())["words"][0]
検索ワードファイルを格納したフォルダをkeyに指定し、
get_object()でファイルを取得します。
そのファイルのBodyをjson.loadsで読み込み、
["words"][0]でワード群の前半を検索に使います。
後半のワードは同様のLambdaをもう一つ作成し、
["words"][1]と指定して検索をするようにしています。
他にもっと良い方法があったかも知れません。
▼boto3.clientのドキュメント▼
4-3. ツイートの検索
t_delta = datetime.timedelta(hours=15)
yesterday = str(datetime.datetime.now() - t_delta)[:10]
start_time = yesterday + "T00:00:00Z"
tweets_dic = {}
for word in spla_words:
tweets = tw_client.search_recent_tweets(query=word,
start_time = start_time,
max_results = 100,
tweet_fields = ["created_at", "public_metrics"],
expansions = "referenced_tweets.id.author_id",
user_fields = ["id", "username"])
tweets_dic[word] = tweets
datetime.now() - timedelta(hours=15)としているのは、
Lambdaが基準とするUTC時間と日本時間の差である9hと合わせ、
合計で24h前の日本時間 の日付を取るためです。
start_timeで前日の0時以降を期間として指定し、
必要な項目を取得できるように諸々引数を設定しています。
▼seach_recent_tweetsのドキュメント▼
tweets_dic[word] = tweetsの箇所で
{"検索単語1":[検索結果100個], "検索単語2":[検索結果100個]...}
のような形の辞書ができている状態です。
【API利用における制限】
APIの個人利用ではツイート取得数に制限があるため、
定期的かつ対象の期間を限定して取得するようにしています。
4-4. jsonデータへの変換
#取得したデータをjson形式にする準備
json_dic = {}
for w in spla_words:
tmp_list= []
try:
for tweet in tweets_dic[w].data:
tmp_list.append(tweet.data)
json_dic[w] = tmp_list
except:
pass
#jsonに変換
json_contents = json.dumps(json_dic)
先ほど取得したレスポンスは不要なものも含みます。
ここでは各ツイートに付随する分析に必要なデータだけを
json_dicに格納するためのfor文を回してます。
検索ワードによっては検索結果が0件もあり得るため、
exceptでとりあえずエラーを回避しています。
最後にjson.dumps(json_dic)でjson形式に変換します。
4-5. S3バケットへの格納
file_name = "tweets_data_json/" + yesterday + "_ssgoth.json"
s3_client.put_object(Body=json_contents, Bucket=bucket, Key=file_name)
検索ワードをs3へ格納するときと同様です。
file_nameにはyesterdayを入れることで
保存されるファイル名に取得対象の日付を入れています。
Bucketは検索ワードを取得したバケットと同じ
bucketを引数として設定しています。
▼S3出力の参考ページ▼
5. デプロイ/テスト
前回同様にスクリプトのpyファイルとパッケージを
併せてzipに圧縮してからデプロイしています。
またトリガーの設定としてEventBridgeで
毎日0時に実行されるように設定をしています。
(詳細は前回の記事を参照)
使用したパッケージは以下の通りです。
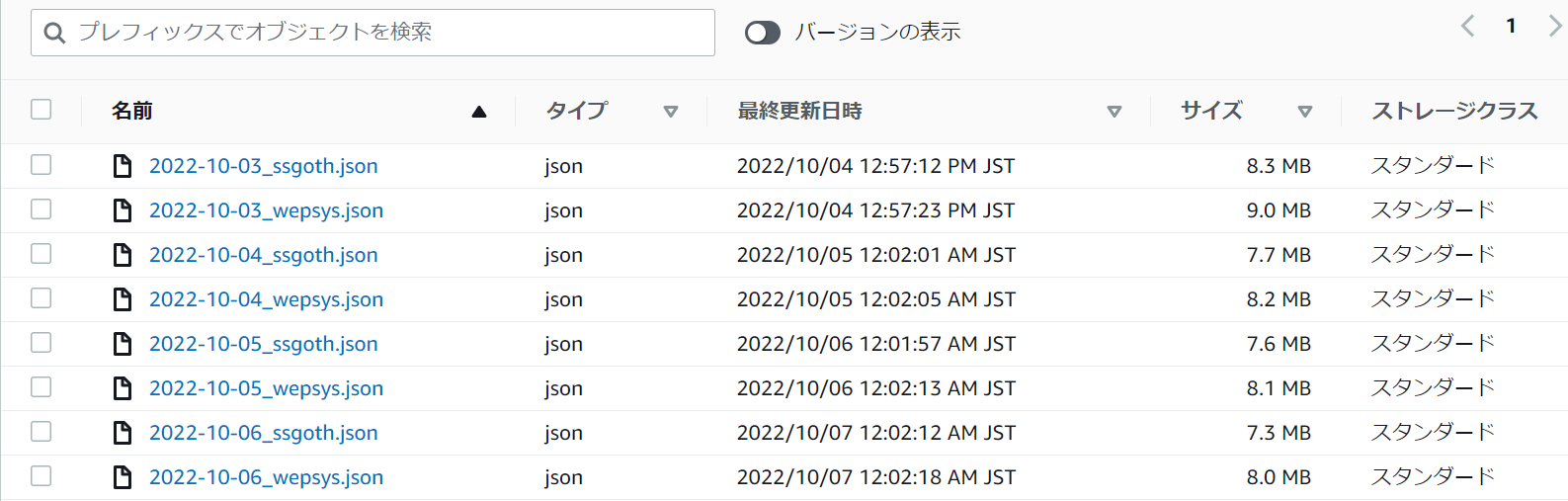
前回と同じようにテストを行うと指定ファイルに
日付が名前に入ったjsonファイルが確認できました。
これで指定した検索ワードについて、
毎日0時に前日分のツイートデータのjsonファイルを
指定のファイルに出力してくれるようになります。
6. 所感と今後の展望
6-1. 躓いた点
・put_object(Body=)
・Lambdaとローカルの違い
まだ作業当時はJSONへの理解が浅く、
put_object(Body=)にどのようなオブジェクトを
入れられるのかが分かりませんでした。
これに関しては何度もローカル環境で試して
挙動について確認して解決をしました。
またローカル環境で試すにあたって、
最初はAWS_idなどについて知らずに困りました。
これについては解説記事に助けられた次第です。
6-2. 今後の展望
今回はs3との連携でデータの自動取得を実現できました。
しかしまだデータは未整理の状態ですし、
不要なデータも多量に含んでいる状態です。
次回はGlueを使った大量のデータの整形、
簡易的なデータの精査をテーマに作業していきます。
今まで手元にあるデータの分析しかできなかったので、
AWSを使った作業の自動化には素直にワクワクしてます。
6-3. さいごに
本記事を読んで頂いてありがとうございました。
コメントや質問、お気軽に宜しくお願い致します。
次回の記事