はじめに
目的と概要
本記事の目的は、AWSのS3、Athena、Glueを用いたサーバーレスETLパイプラインの構築方法を理解し、実際に設定および実行するためのガイドを提供することです。ETL(Extract, Transform, Load)プロセスは、データの抽出、変換、およびロードの一連の作業を指します。これにより、異なるデータソースからデータを収集し、適切な形式に変換し、最終的に分析やレポート作成のためにデータウェアハウスやデータレイクにロードします。
AWSのS3、Athena、Glueを利用することで、従来のオンプレミス環境や自己管理型のETLツールと比べて、スケーラビリティ、コスト効率、運用の容易さが大幅に向上します。本記事では、これらのAWSサービスを組み合わせて、効率的かつスケーラブルなサーバーレスETLパイプラインを構築する手順を詳述します。
以下が作成したディレクトリです。
ETLとは?
ETLとは、データ処理の三つの主要なステップであるExtract(抽出)、Transform(変換)、Load(ロード)の略です。このプロセスは、以下のように進行します。
- Extract(抽出): データソースから必要なデータを収集します。データソースには、データベース、ファイル、APIなどが含まれます。
- Transform(変換): 抽出されたデータを、必要な形式や構造に変換します。このステップでは、データのクリーニング、正規化、集計、フィルタリングなどが行われます。
- Load(ロード): 変換されたデータをデータウェアハウスやデータレイクにロードし、分析やレポート作成に利用できるようにします。
ETLプロセスは、データ統合とデータ管理の中核をなす重要な部分であり、ビジネスインテリジェンスやデータ分析の基盤となります。
アーキテクチャの概要

使用するAWSサービスの紹介
本記事では、以下のAWSサービスを使用してサーバーレスETLパイプラインを構築します。
- S3 (Simple Storage Service): スケーラブルで耐久性のあるオブジェクトストレージサービス。データの保存、バックアップ、アーカイブに最適です。
- Glue: 完全マネージドのETLサービス。データのカタログ化、抽出、変換、ロードを行うためのツールを提供します。
- Athena: サーバーレスのインタラクティブなクエリサービス。標準SQLを使用してS3に保存されたデータを直接クエリできます。
S3、Athena、Glueの役割
- S3 (Simple Storage Service): データのストレージとして機能します。元データのCSVファイルを保存し、GlueやAthenaがアクセスできるようにします。
- Glue: ETLプロセスの中心となるサービスです。S3に保存されたデータをスキャンし、データカタログを作成します。
- Athena: データのクエリと分析を担当します。Athenaを使用して、Glueによってカタログ化されたデータに対して標準SQLクエリを実行し、データの分析結果を取得します。
これらのサービスを組み合わせることで、スケーラブルで効率的なサーバーレスETLパイプラインを構築できます。次章からは、実際にこれらのサービスを設定し、パイプラインを構築する手順を詳述します。
実装方法
データの準備
元データのCSVファイルの構造と内容
元データとして使用するCSVファイルは、以下のような構造と内容を持っています。このファイルには、ユーザーのアクションに関する情報が記録されています。
name,path,action,timestamp
David Lee,/,index,2024-07-04T01:43:58.701Z
Emma Brown,/about,about,2024-07-04T01:44:07.321Z
David Lee,/,index,2024-07-04T01:44:10.293Z
John Smith,/faq,faq,2024-07-04T01:44:14.444Z
John Smith,/,index,2024-07-04T01:46:51.644Z
このCSVファイルは、以下のカラムを含んでいます:
- name: ユーザーの名前
- path: ユーザーがアクセスしたパス
- action: ユーザーが行ったアクション
- timestamp: アクションが発生した日時
S3にCSVファイルを配置
S3に元データのCSVファイルを配置するためには、S3バケットを作成し、ファイルをアップロードするプロセスを自動化します。
resource "aws_s3_bucket_versioning" "versioning" {
bucket = aws_s3_bucket.main.id
versioning_configuration {
status = "Enabled"
}
}
resource "aws_s3_bucket" "main" {
bucket = "main-${random_string.s3_unique_key.result}"
force_destroy = true
tags = {
Name = "${var.app_name}-main"
}
}
resource "random_string" "s3_unique_key" {
length = 10
upper = false
lower = true
numeric = true
special = false
}
作成したS3バケットにローカルのCSVファイルをS3に同期します。
resource "null_resource" "default" {
provisioner "local-exec" {
command = "aws s3 sync ${path.module}/src/ s3://${aws_s3_bucket.main.id}/${var.source_dir_name}"
}
depends_on = [aws_s3_bucket.main]
}
Glue ETLジョブの作成
ジョブの概要と役割
AWS Glue ETLジョブは、データの抽出(Extract)、変換(Transform)、ロード(Load)を自動化するための機能を提供します。これにより、データを一貫した形式に整え、データ分析やビジネスインテリジェンスのためにデータウェアハウスやデータレイクにロードすることができます。
このジョブの役割は、S3に保存されたCSVファイルを読み込み、必要な変換処理を行い、処理済みデータを適切な場所に保存することです。以下の手順で、Glueジョブの設定とスクリプトを作成します。
ジョブの設定とスクリプト作成
まず、GlueカタログデータベースとテーブルをTerraformで設定します。
Glueカタログデータベースの作成
Glueカタログデータベースは、データのメタデータを格納するためのコンテナです。
resource "aws_glue_catalog_database" "main" {
name = "main_db"
}
Glueカタログテーブルの作成
次に、Glueカタログテーブルを作成し、S3に保存されているCSVファイルのメタデータを登録します。
resource "aws_glue_catalog_table" "main" {
name = "main_table"
database_name = aws_glue_catalog_database.main.name
storage_descriptor {
columns {
name = "name"
type = "string"
}
columns {
name = "path"
type = "string"
}
columns {
name = "action"
type = "string"
}
columns {
name = "timestamp"
type = "string"
}
location = "s3://${var.s3_bucket_bucket}/${var.source_dir_name}"
input_format = "org.apache.hadoop.mapred.TextInputFormat"
output_format = "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat"
compressed = false
ser_de_info {
name = "main"
serialization_library = "org.apache.hadoop.hive.serde2.OpenCSVSerde"
parameters = {
"field.delim" = ","
"quoteChar" = "\""
"escapeChar" = "\\"
}
}
}
table_type = "EXTERNAL_TABLE"
parameters = {
"classification" = "csv"
"skip.header.line.count" = "1"
}
}
Athenaでのクエリ実行
データベースとテーブルの確認
まず、Athenaでクエリを実行するために、AWS Glueによって作成されたデータベースとテーブルが正しく設定されていることを確認します。これらのデータベースとテーブルは、Glueジョブを通じて生成されたメタデータに基づいています。
Glueで設定したデータベース名は「main_db」、テーブル名は「main_table」です。Athenaコンソールに移動し、これらのデータベースとテーブルが存在することを確認します。
- Athenaコンソールにアクセス: AWSコンソールにログインし、Athenaサービスに移動します。
- データベースの確認: 左側の「Database」セクションで「main_db」が表示されていることを確認します。
- テーブルの確認: データベース「main_db」を選択し、その中に「main_table」が表示されていることを確認します。
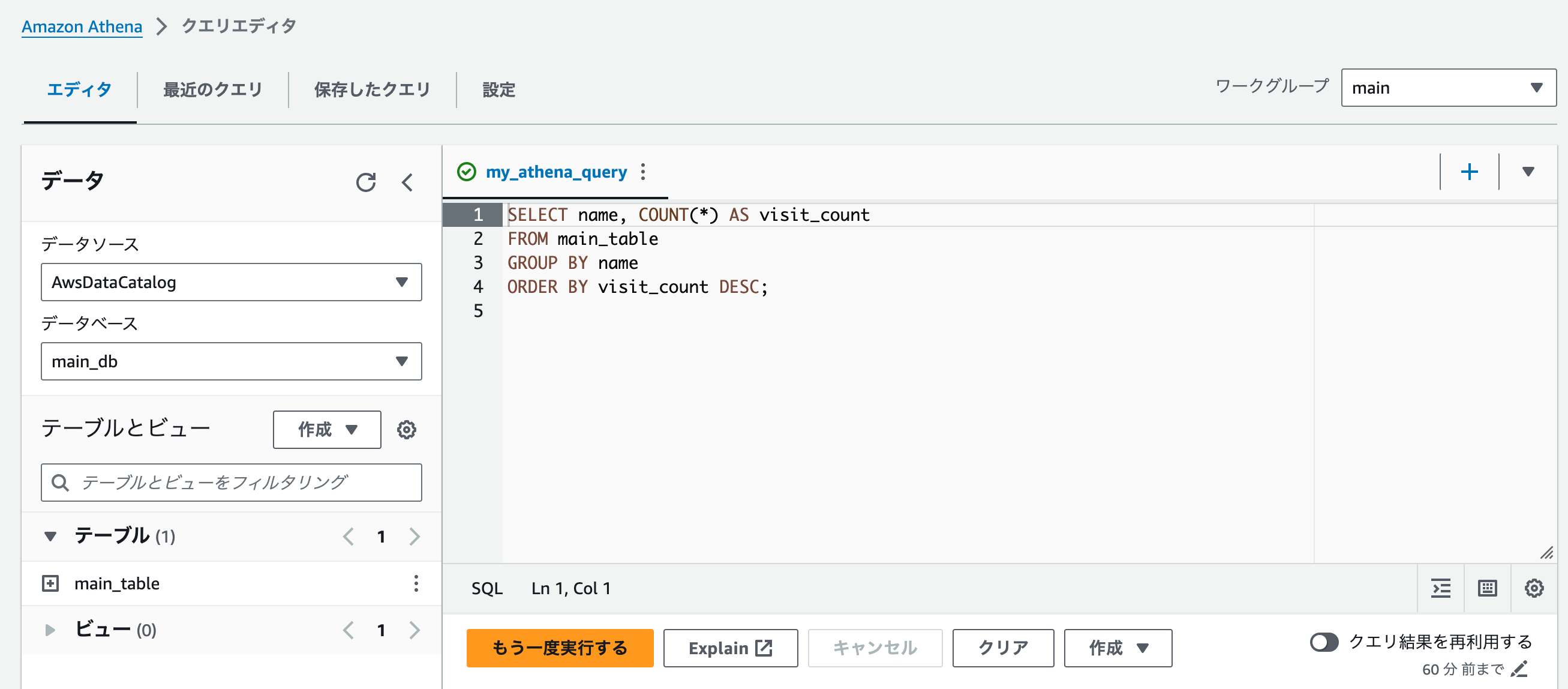
SQLクエリの作成と実行
次に、Athenaで実行するSQLクエリを作成します。この例では、ユーザーごとの訪問回数を集計し、訪問回数の多い順に並べ替えるクエリを実行します。
Athenaワークグループの設定
Athenaワークグループは、クエリの設定や実行結果の保存場所を管理するためのものです。
resource "aws_athena_workgroup" "main" {
name = "main"
configuration {
enforce_workgroup_configuration = true
publish_cloudwatch_metrics_enabled = true
result_configuration {
output_location = "s3://${var.s3_bucket_id}/${var.result_dir_name}/"
}
}
force_destroy = true
}
Athena名前付きクエリの設定
次に、名前付きクエリを設定します。このクエリは、Glueによって作成されたテーブルを参照します。
resource "aws_athena_named_query" "main" {
name = "my_athena_query"
database = var.glue_database_name
workgroup = aws_athena_workgroup.main.id
description = "This query selects all columns from the ${var.glue_table_name} table."
query = <<EOF
SELECT name, COUNT(*) AS visit_count
FROM ${var.glue_table_name}
GROUP BY name
ORDER BY visit_count DESC;
EOF
}
クエリ結果の確認と分析
クエリが正常に実行された後、結果を確認して分析します。Athenaコンソールで実行結果を確認し、S3に保存された結果も確認できます。
- クエリの実行: Athenaコンソールに戻り、設定したワークグループ「main」を選択します。名前付きクエリ「my_athena_query」を実行します。
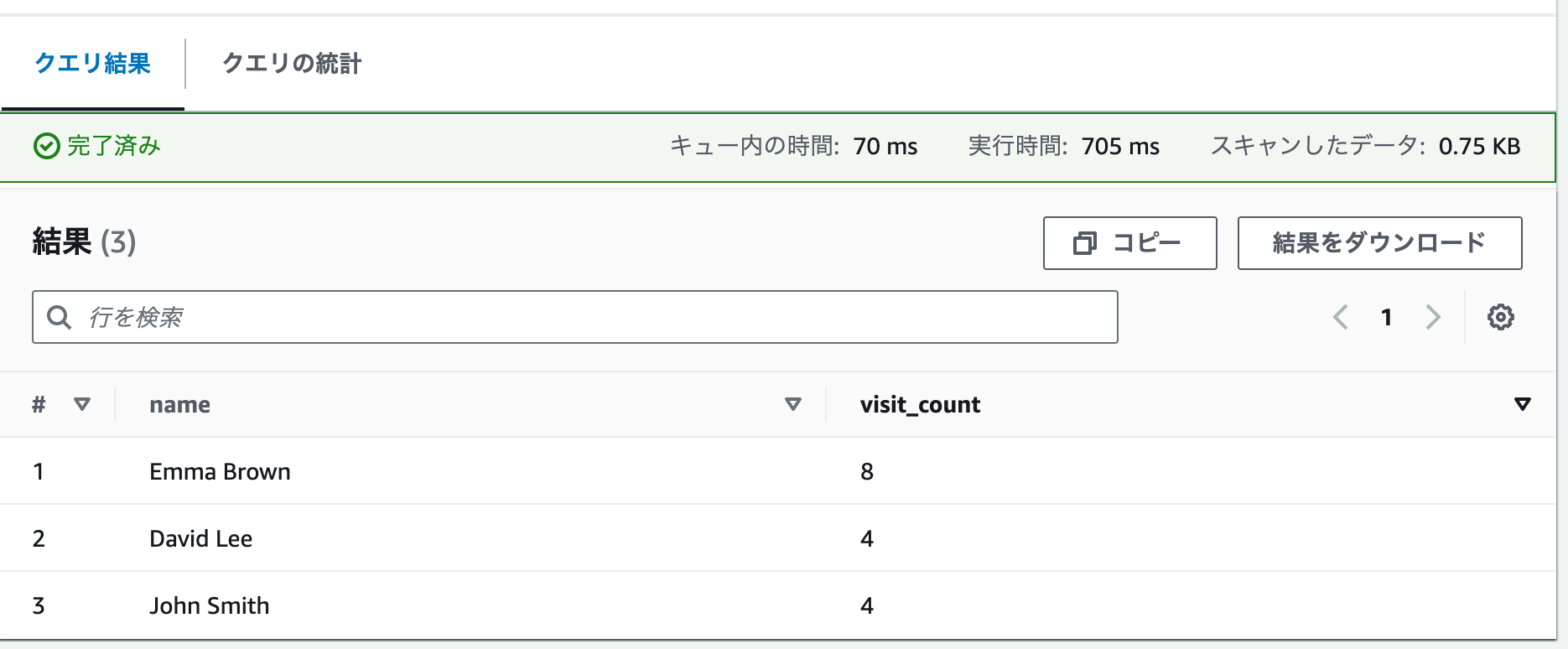
- 結果の確認: クエリ結果はAthenaコンソールで直接表示されます。また、クエリ結果はS3バケットに保存されます。指定されたS3バケットの「results」フォルダに移動し、結果ファイルを確認します。
- 結果の分析: クエリ結果を確認し、訪問回数の多いユーザーを特定します。結果は以下のような形式になります。
"name","visit_count"
"Emma Brown","8"
"David Lee","4"
"John Smith","4"
この手順により、Athenaでクエリを実行し、結果を確認して分析するプロセスが完了します。Athenaを使用することで、S3に保存されたデータに対して簡単にクエリを実行し、データ分析を行うことができます。
まとめ
AWSのS3、Glue、Athenaを組み合わせることで、スケーラブルで効率的なサーバーレスETLパイプラインを構築することができました。このパイプラインは、データの抽出、変換、ロードを自動化し、大規模なデータセットの処理を容易にします。また、サーバーレスアーキテクチャを採用することで、インフラストラクチャの管理が不要になり、コスト効率と運用の簡便性が向上します。
これにより、ビジネスインテリジェンスやデータ分析のためにデータを効果的に利用できるようになります。さらに、Athenaを使用することで、SQLを使ってS3に保存されたデータに対してインタラクティブなクエリを実行し、迅速に洞察を得ることができます。