はじめに
Amazon Athenaは、S3を始めとした各種ストレージサービスに対して、AWS Glueデータカタログによる接続を通じて柔軟なクエリを実現するサービスです。
ざっくり言うと、「データベース以外のストレージにもSQLでクエリを実行できるサービス」と呼べるでしょう。
Athenaはログ解析やストレージを安価なDB代わりに使用したい場合に威力を発揮しますが、一方で日本語の記事は充実しているとは言えない状況です。そこで今回、その操作法をざっくりまとめたいと思います。
なおAthenaとその他のS3へのクエリサービス(データレイクサービス)との比較は、以下の記事を参照ください。
前準備
Athenaを使用するために必要な環境を構築します。
使用するデータ
本記事では、こちらの記事で取得したIoTデータを、年ごとにフォルダ分けし、月ごとにCSVファイルにまとめて以下のフォルダ構成 (プレフィックス)でS3バケットに格納して使用します。
実際の使用時は、好きなCSVファイルやテキストファイルをバケット内に格納してください。ただし詳細はパーティションの項で解説しますが、Athenaを使用するS3バケットは年、月、日、時のように時間を表すフォルダで分けると、コストや速度面においてメリットを得ることができます。
バケット名
└──sensors
└──per_month
├─2020
│ ├─202008.csv
│ :
│ └─202012.csv
├─2021
│ ├─202101.csv
│ :
│ └─202012.csv
└─2022
├─202101.csv
:
└─202008.csv
コンソールでの表示例
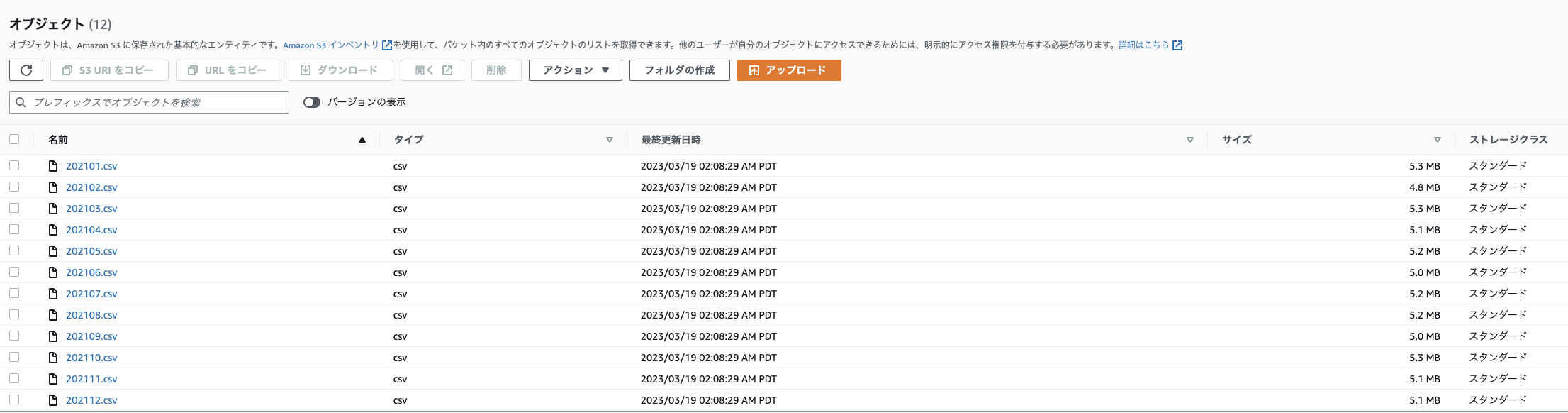
CSVファイルの中身は以下のようになっています (参考)
_id,Date_Master,Date_ScanStart,no01_DeviceName,no01_Date,no01_Temperature,no01_Humidity,no01_Light,no01_Human_last,no01_HumanMotion,no01_TempSetting,no01_AirconMode,no01_AirVolume,no01_AirDirection,no01_AirconPower,no01_CumulativeEnergy,no01_Watt,no02_DeviceName,no02_Date,no02_Temperature,no02_Humidity,no02_Light,no02_Pressure,no02_Noise,no02_eTVOC,no02_eCO2,no03_DeviceName,no03_Date,no03_Temperature,no03_Humidity,no04_DeviceName,no04_Date,no04_Temperature,no04_Humidity,no05_DeviceName,no05_Date,no05_Temperature,no05_Humidity,no05_Light,no05_UV,no05_Pressure,no05_Noise,no05_BatteryVoltage,no06_DeviceName,no06_Date,no06_Temperature,no06_Humidity,no07_DeviceName,no07_Date,no07_Temperature,no07_Humidity,no07_BatteryVoltage,no08_DeviceName,no08_Date,no08_HumanLast,no08_HumanMotion,_partition
5f359f60de55bc0802637080,2020-08-14 05:15:00.000,2020-08-14 05:15:03.891,Nature_Remo_1,2020-08-14 05:15:06.167,28.2,64.0,143.0,2020-08-13T20:08:42Z,0.0,28.0,cool,1,auto,power-on,2957.17,548.0,Omron_USB_1,2020-08-14 05:15:07.093,27.48,71.54,111,1005.229,58.29,289,1650,Inkbird_IBSTH1_1,2020-08-14 05:15:10.068,27.91,68.21,Inkbird_IBSTH1_2,2020-08-14 05:15:12.706,31.49,63.15,Omron_BAG_1,2020-08-14 05:15:17.748,32.18,62.48,6.0,0.01,1006.3,39.8,2.96,Inkbird_IBSTH1mini_1,2020-08-14 05:15:21.384,26.53,75.28,SwitchBot_Thermo_1,2020-08-14 05:15:26.413,31.7,65.0,100.0,Sony_MeshHuman_1,2020-08-14 05:15:28.835,2020-08-13T20:14:14.000Z,1,Project HomeIoT
5f35a09092376c3d5d76612c,2020-08-14 05:20:00.000,2020-08-14 05:20:04.054,Nature_Remo_1,2020-08-14 05:20:06.294,28.2,62.0,143.0,2020-08-13T20:08:42Z,0.0,28.0,cool,1,auto,power-on,2957.22,360.0,Omron_USB_1,2020-08-14 05:20:07.249,27.45,68.86,108,1005.284,46.18,280,1638,Inkbird_IBSTH1_1,2020-08-14 05:20:12.872,27.93,66.46,Inkbird_IBSTH1_2,2020-08-14 05:20:17.417,31.4,63.06,Omron_BAG_1,2020-08-14 05:20:22.446,32.24,62.63,13.0,0.02,1006.3,38.61,2.96,Inkbird_IBSTH1mini_1,2020-08-14 05:20:25.224,26.51,74.69,SwitchBot_Thermo_1,2020-08-14 05:20:30.252,31.9,64.0,100.0,Sony_MeshHuman_1,2020-08-14 05:20:32.635,2020-08-13T20:20:14.000Z,1,Project HomeIoT
5f35a1ba291e40c5ea258ee3,2020-08-14 05:25:00.000,2020-08-14 05:25:04.460,Nature_Remo_1,2020-08-14 05:25:06.701,28.2,64.0,143.0,2020-08-13T20:08:42Z,0.0,28.0,cool,1,auto,power-on,2957.25,580.0,Omron_USB_1,2020-08-14 05:25:07.458,27.32,70.51,106,1005.352,44.38,259,1615,Inkbird_IBSTH1_1,2020-08-14 05:25:09.629,27.95,68.14,Inkbird_IBSTH1_2,2020-08-14 05:25:11.219,31.4,62.94,Omron_BAG_1,2020-08-14 05:25:21.290,32.15,62.87,25.0,0.03,1006.3,39.02,2.96,Inkbird_IBSTH1mini_1,2020-08-14 05:25:23.063,26.53,73.39,SwitchBot_Thermo_1,2020-08-14 05:25:28.090,31.8,65.0,100.0,Sony_MeshHuman_1,2020-08-14 05:25:30.343,2020-08-13T20:24:14.000Z,1,Project HomeIoT
5f35a2e24098c6e9f618daa4,2020-08-14 05:30:00.000,2020-08-14 05:30:03.594,Nature_Remo_1,2020-08-14 05:30:05.794,28.2,64.0,143.0,2020-08-13T20:08:42Z,0.0,28.0,cool,1,auto,power-on,2957.29,428.0,Omron_USB_1,2020-08-14 05:30:06.555,27.25,73.02,106,1005.377,43.66,265,1623,Inkbird_IBSTH1_1,2020-08-14 05:30:09.387,27.92,68.94,Inkbird_IBSTH1_2,2020-08-14 05:30:12.162,31.49,62.93,Omron_BAG_1,2020-08-14 05:30:17.203,32.14,62.77,32.0,0.02,1006.5,39.22,2.96,Inkbird_IBSTH1mini_1,2020-08-14 05:30:18.825,26.53,75.26,SwitchBot_Thermo_1,2020-08-14 05:30:23.865,31.7,65.0,100.0,Sony_MeshHuman_1,2020-08-14 05:30:26.573,2020-08-13T20:30:15.000Z,1,Project HomeIoT
5f35a41a90393b85364a6c71,2020-08-14 05:35:00.000,2020-08-14 05:35:04.370,Nature_Remo_1,2020-08-14 05:35:06.617,28.2,64.0,143.0,2020-08-13T20:34:01Z,1.0,28.0,cool,1,auto,power-on,2957.32,456.0,Omron_USB_1,2020-08-14 05:35:07.443,27.45,74.21,104,1005.468,57.8,244,1598,Inkbird_IBSTH1_1,2020-08-14 05:35:10.129,28.07,69.8,Inkbird_IBSTH1_2,2020-08-14 05:35:12.960,31.47,62.75,Omron_BAG_1,2020-08-14 05:35:18.000,32.06,62.93,48.0,0.02,1006.6,39.22,2.96,Inkbird_IBSTH1mini_1,2020-08-14 05:35:25.717,26.62,76.67,SwitchBot_Thermo_1,2020-08-14 05:35:35.787,31.7,65.0,100.0,Sony_MeshHuman_1,2020-08-14 05:35:38.204,2020-08-13T20:34:15.000Z,1,Project HomeIoT
:
アクセス権限の付与
Athenaを使用するためには、適切なアクセス権限をIAMで作成して付与する必要があります。
IAMポリシーの作成
公式ではAmazonAthenaFullAccessポリシーの使用が推奨されていますが、Python SDKではget_query_execution()メソッドでPermission denied on S3 pathというエラー()が発生してうまく動作しませんでした。
そこで、このエラーを回避できる以下のこちらのポリシーを作成します。
管理者ユーザーでログインして、コンソールからIAM画面に入り、
左側のタブから「ポリシー」→「ポリシーの作成」をクリックします

「JSON」タブをクリックし、JSONでの編集モードに入ります

以下のようなポリシーを記述します
(例えば、AthenaPolicyというポリシー名を付けます。"Resource"の部分を"*"から対象のバケットのみに絞るとセキュリティ強度がさらに強まりますが、利便性とのバランスで判断してください)
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:Get*",
"s3:List*",
"s3:PutObject",
"athena:*",
"glue:GetTable"
],
"Resource": "*"
}
]
}
名前と説明を記載し、「ポリシーの作成」をクリックすれば作成完了です
ここからは
で操作が変わります。
1.コンソールを使用する場合 or ローカルPCからスクリプトを使用する場合
コンソールを使用する場合、ユーザーに対してポリシーに基づくアクセス権限を与えます
ローカルPCからスクリプトを使用する場合、上記のユーザーから作成したアクセスキーをPCに登録します。
IAMユーザーの作成
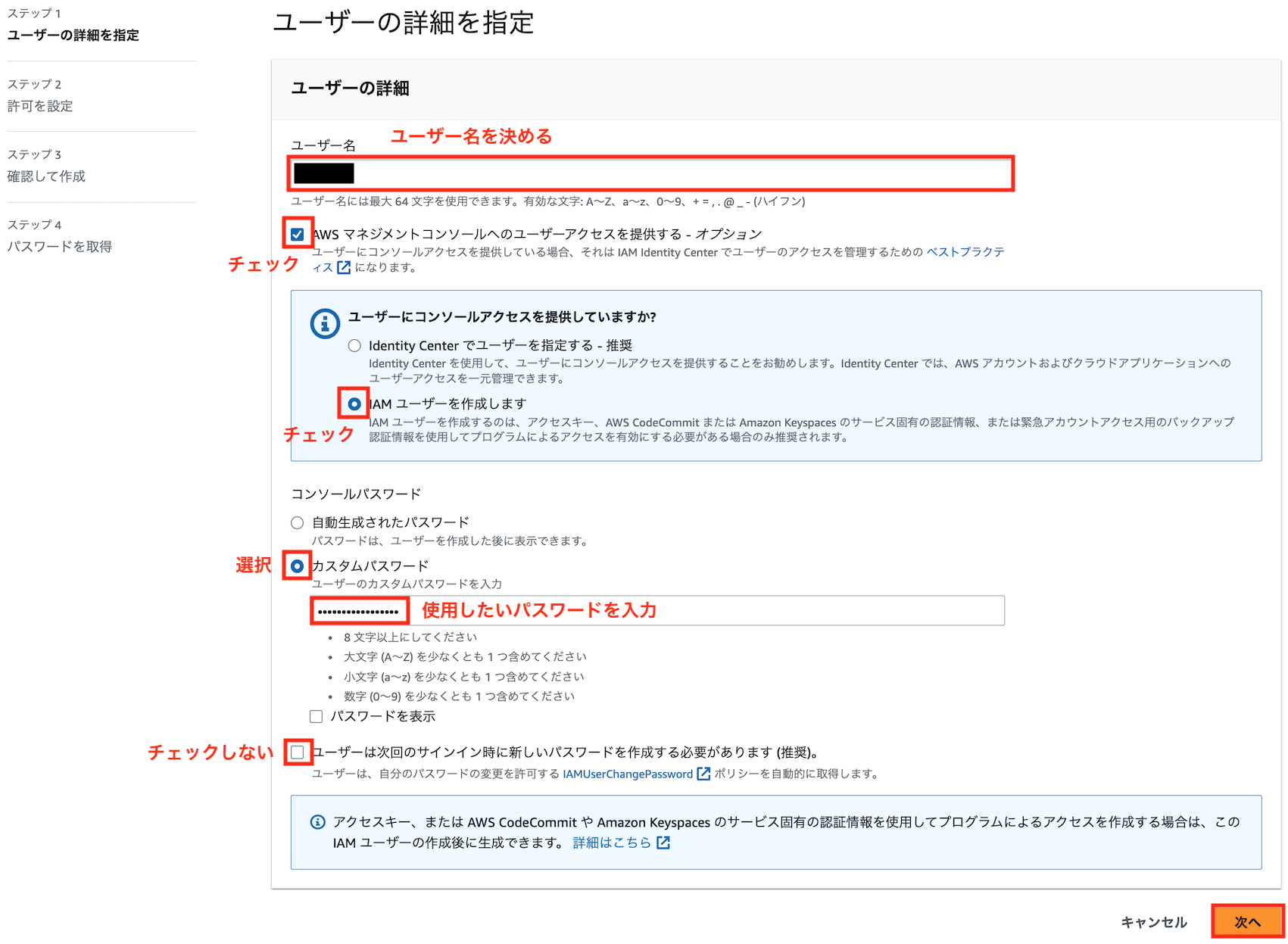
上記ポリシーを付与するためのIAMユーザを作成します。
管理者ユーザーでログインして、コンソールからIAM → ユーザーと進み、「ユーザを追加」をクリックします

好きなユーザ名とパスワードを入力し、以下のようにユーザーを作成します
先ほど作成したポリシーをアタッチします
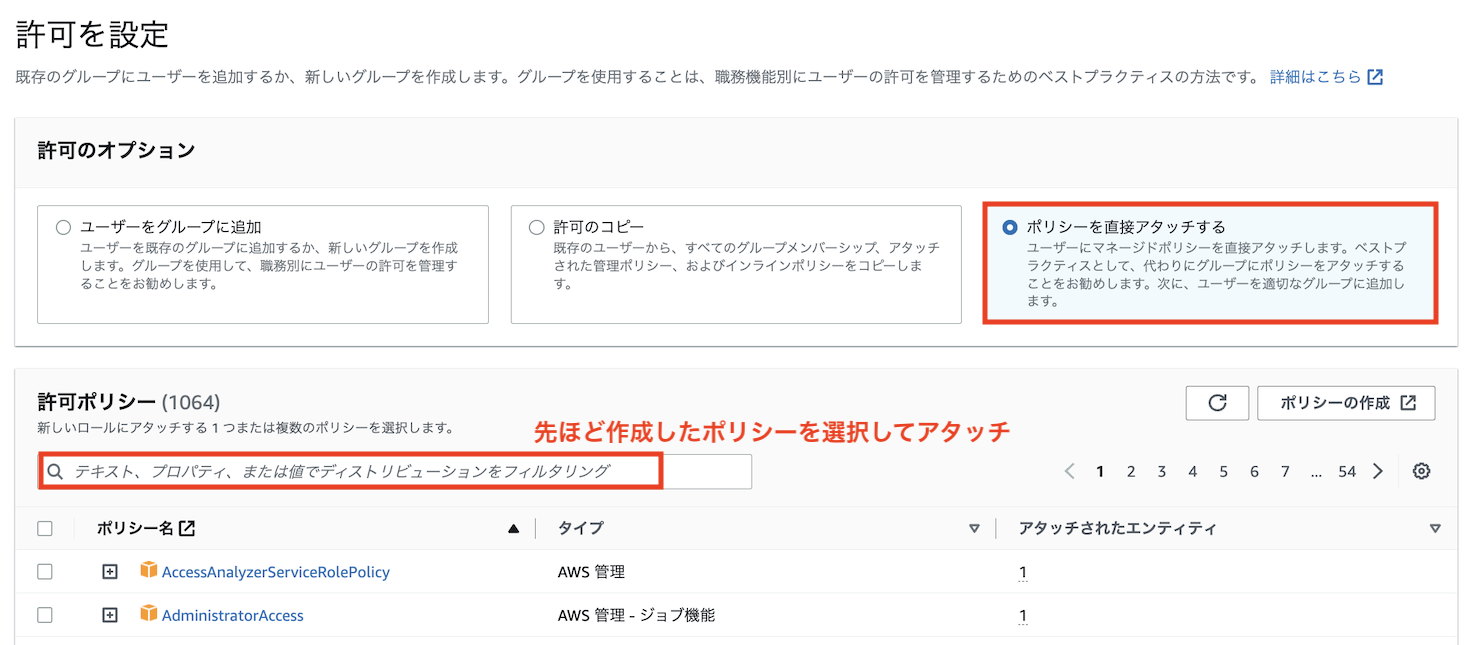
コンソールを使用する場合は、このユーザーでログインすることでAthenaの操作が可能となります。
ローカルPCからスクリプトを使用する場合、以下の処理を進めてアクセスキーを登録する必要があります。
アクセスキーの作成(ローカルPCからスクリプトを使用する場合)
作成したIAMユーザでコンソールにログインし、IAM → ユーザ → 先ほど作成したユーザ → 「セキュリティ認証情報」タブに移動し、「アクセスキーの作成」をクリックします。

アクセスキーを作成して出てきたアクセスキーIDとシークレットアクセスキーをメモします。
アクセスキーのCLIへの登録(ローカルPCからスクリプトを使用する場合)
AWSをコマンドラインから操作するためのAWS CLIを、クライアントPCに以下を参考にインストールしてください
インストールが完了したら、ターミナル(Windowsの場合Powershell)から以下のコマンドを打ち
aws configure
以下のように入力します
AWS Access Key ID [None]: [アクセスキーID]
AWS Secret Access Key [None]: [先ほどメモしたシークレットアクセスキー]
Default region name [None]: ap-northeast-1
Default output format [None]: [空欄でOK]
「~/.aws/credentials」と「~/.aws/config」に入力したクレデンシャル情報(アクセスキーやリージョン)が生成していれば成功です。
2. EC2等のAWSリソースからスクリプトを使用する場合
EC2やFargate、Lambda等のAWSリソースからPython SDKを通じてAthenaを使用する場合、先ほど作成したポリシーを付与したロールを、対象のリソースにアタッチする必要があります。以下の「AWS内サービスへの権限付与」を参照ください。
Athenaの使用法
Athenaは、コンソール、CLI、REST API、SDKを利用してS3内のデータをクエリする事ができます。
本記事ではは、このうち使用頻度が高いと思われるコンソール、SDKによる操作方法を紹介します。
類似サービスであるS3 Selectと比べて一般的なデータベース(RDB)に近い操作となり、具体的には以下の手順でクエリを実行します
- ステップ1: データベースの作成
- ステップ2: テーブルの作成
- ステップ3: クエリの実行
コンソールからの使用法
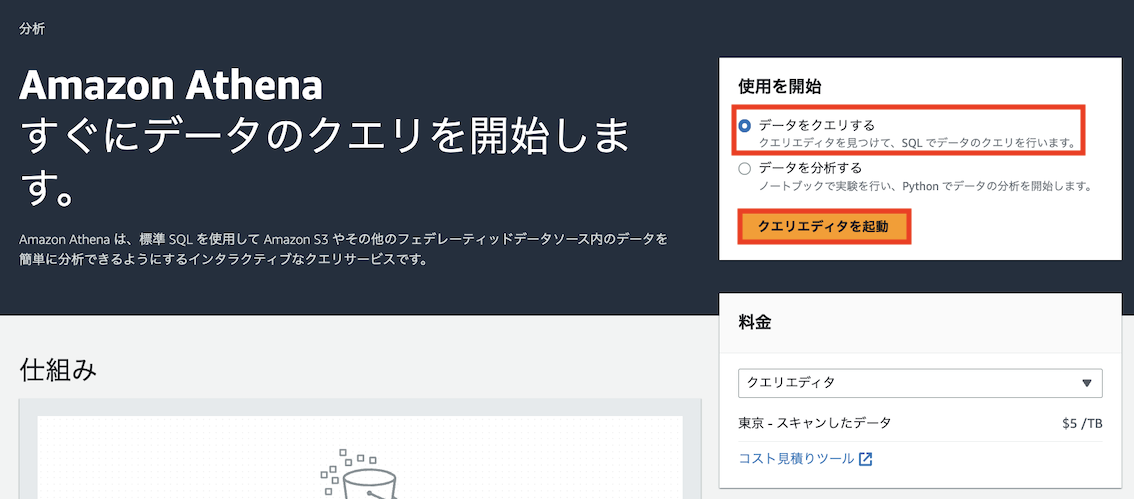
コンソールからAthenaを使用するためには、まず以下リンクからAthenaコンソールを開きます(AWSコンソールから"Athena"と検索して移動してもOKです)
以下のようにクエリエディタを起動します
ステップ1: データベースの作成
Athenaでクエリを実行するためには、まずクエリの実行基盤となる「データベース」を作成する必要があります。
「エディタ」タブ→「設定を編集」で、以下のようにクエリ結果の保存先バケットを指定します(結果の暗号化の有無等も指定できます)

「エディタ」タブに戻り、以下のようにCREATE DATABASE データベース名というクエリを記入して「実行」ボタンを押します
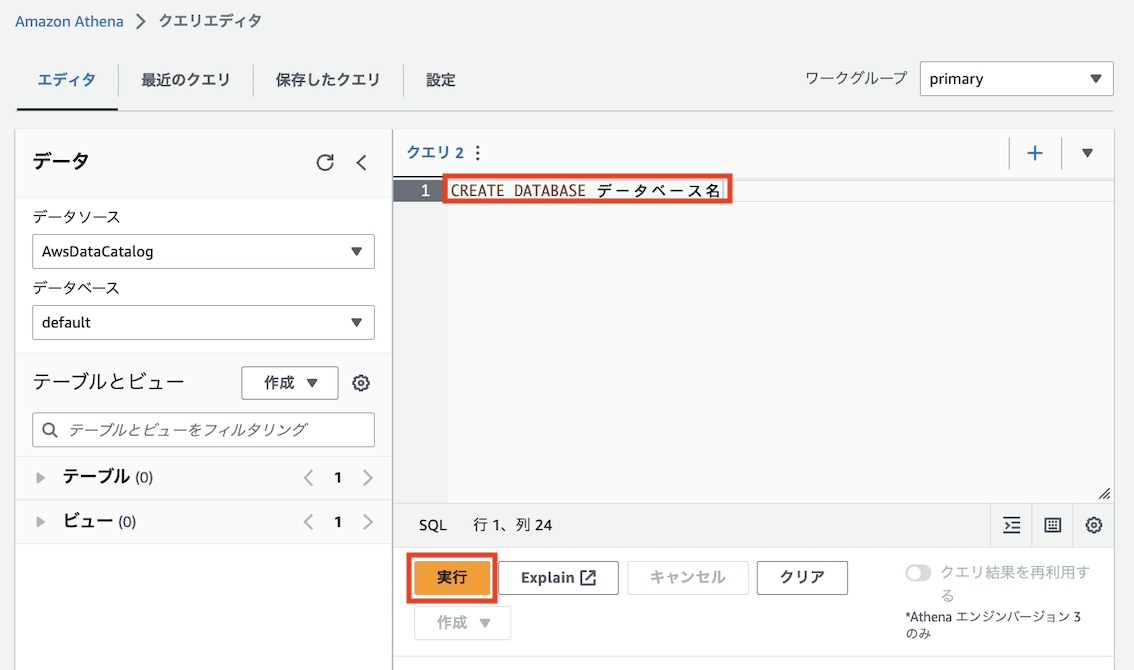
作成したデータベースが「データベース」タブに追加されるので、選択します

ステップ2: テーブルの作成
前記で作成したデータベース内に、S3バケットとAthenaを結び付けるための「テーブル」を作成します。
テーブルと結びつくのは基本的にS3バケット内のフォルダ(プレフィックス)となり、テーブルを作成すればフォルダ内のファイル全てに一括でクエリを実行する事ができます。
クエリエディタから以下のようなコマンドを実行することで、テーブルを作成できます。
CREATE EXTERNAL TABLE IF NOT EXISTS テーブル名 (
カラム名1 型名1,
カラム名2 型名2,
:
中略
:
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY 'フィールドの区切り文字'
LINES TERMINATED BY 'レコードの改行文字'
LOCATION 's3://バケット名/プレフィックス/'
TBLPROPERTIES ('skip.header.line.count'='1');
指定できる型の種類はこちらを参照ください。
例えば、先ほど紹介したサンプルバケットのper_monthフォルダをテーブルの作成対象とする場合、フィールドの区切り文字は','(カンマ)、レコードの改行文字は'\n'、プレフィックスはsensors/per_month/となるので、以下のようなコマンドでテーブルを作成できます。
(テーブル名は"sample_table1"とします。また必ずしもファイル内の全ての列名を指定する必要はなく、一部の列のみ指定する事もできるので、今回はno01の列のみ選択します)
CREATE EXTERNAL TABLE IF NOT EXISTS sample_table1 (
`_id` STRING,
Date_Master DATETIME,
Date_ScanStart DATETIME,
no01_DeviceName STRING,
no01_Date DATETIME,
no01_Temperature FLOAT,
no01_Humidity FLOAT,
no01_Light FLOAT,
no01_Human_last STRING,
no01_HumanMotion FLOAT,
no01_TempSetting FLOAT,
no01_AirconMode STRING,
no01_AirVolume STRING,
no01_AirDirection STRING,
no01_AirconPower STRING,
no01_CumulativeEnergy FLOAT,
no01_Watt FLOAT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
LOCATION 's3://バケット名/sensors/per_month/';
TBLPROPERTIES ('skip.header.line.count'='1');
※よくある注意点
- 上の
_id列はバッククオート文字(`)でエスケープされていますが、これは"_id"という文字が予約語であるからです。 - フィールドの区切り文字がタブの場合、
FIELDS TERMINATED BY '\t'と指定します。 -
ROW FORMAT DELIMITEDの部分は、Athenaの解析にLazySimpleSerDeというデフォルトライブラリを使用し、直後にFIELDS TERMINATED BYとLINES TERMINATED BYを記述することで区切り文字を指定します。Regex SerDe等他のライブラリでより複雑な指定も可能なので、詳細は公式ドキュメントやこちらを参照ください。 -
TBLPROPERTIES ('skip.header.line.count'='1')は、1行目をヘッダ行として読み飛ばすことを表します(参考)1行目がヘッダ行でない場合は削除してください
作成がうまくいくと、以下のように「テーブル」に作成したテーブルが表示されます
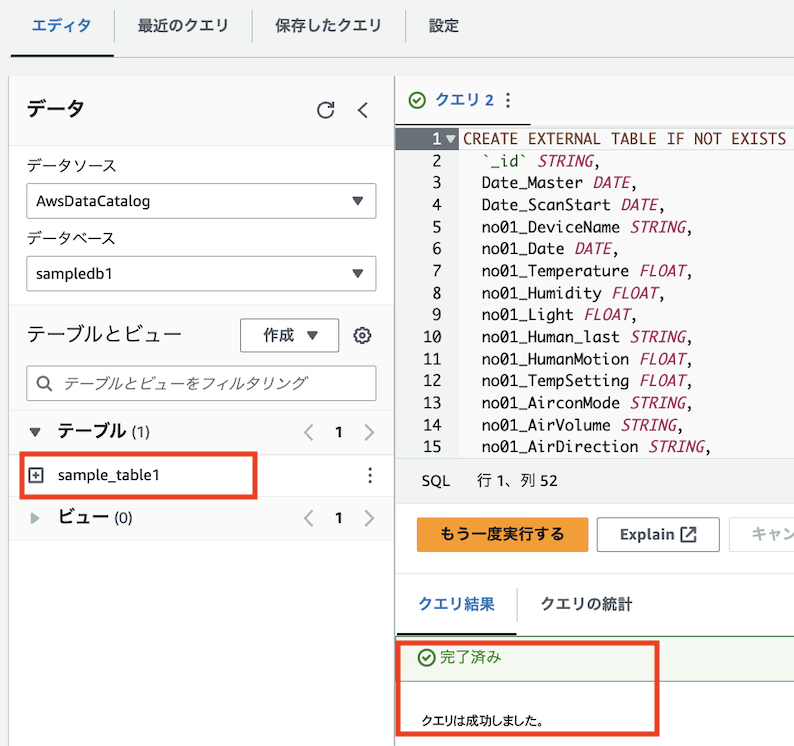
ステップ3: クエリの実行
ここまでで前準備が完了し、ここから実際にクエリを実行してS3からデータを取得する事ができます。
プラス (+) 記号をクリックして新しいクエリタブを開き、クエリペインに好きなSQL文を打ちます。例えば全ての列を取得したい場合は、以下のようにアスタリスク(*)を使用します(データ数が多い場合、料金に注意してください)
SELECT * FROM "データベース名"."テーブル名"
実行結果
# _id date_master date_scanstart no01_devicename no01_date no01_temperature no01_humidity no01_light no01_human_last no01_humanmotion no01_tempsetting no01_airconmode no01_airvolume no01_airdirection no01_airconpower no01_cumulativeenergy no01_watt
1 6016c60d6e23430d866f60bd 2021-02-01 00:00:00.000 2021-02-01 00:00:03.636 Nature_Remo_1 2021-02-01 00:00:05.886 21.8 42.0 149.0 2021-01-31T14:24:14Z 0.0 21.0 warm auto auto power-on 4029.68 468.0
2 6016c739b7382ac931f66146 2021-02-01 00:05:00.000 2021-02-01 00:05:04.164 Nature_Remo_1 2021-02-01 00:05:06.448 21.8 42.0 149.0 2021-01-31T15:02:36Z 1.0 21.0 warm auto auto power-on 4029.72 464.0
3 6016c865f1d9db87285f00ac 2021-02-01 00:10:00.000 2021-02-01 00:10:04.505 Nature_Remo_1 2021-02-01 00:10:06.766 21.8 42.0 149.0 2021-01-31T15:02:36Z 0.0 21.0 warm auto auto power-on 4029.76 764.0
4 6016c99185b736601f39e897 2021-02-01 00:15:00.000 2021-02-01 00:15:04.081 Nature_Remo_1 2021-02-01 00:15:06.290 21.8 42.0 149.0 2021-01-31T15:02:36Z 0.0 21.0 warm auto auto power-on 4029.8 520.0
5 6016cac1f288e5bed8349004 2021-02-01 00:20:00.000 2021-02-01 00:20:03.940 Nature_Remo_1 2021-02-01 00:20:06.139 21.8 40.0 149.0 2021-01-31T15:18:42Z 1.0 21.0 warm auto auto power-on 4029.85 508.0
6 6016cbefb4983a073a0e0a76 2021-02-01 00:25:00.000 2021-02-01 00:25:04.048 Nature_Remo_1 2021-02-01 00:25:06.251 21.8 40.0 149.0 2021-01-31T15:18:42Z 0.0 21.0 warm auto auto power-on 4029.89 508.0
7 6016cd13a45cd8cc8a952af3 2021-02-01 00:30:00.000 2021-02-01 00:30:03.655 Nature_Remo_1 2021-02-01 00:30:05.874 21.8 40.0 149.0 2021-01-31T15:28:20Z 1.0 21.0 warm auto auto power-on 4029.95 520.0
8 6016ce3ff0f15a18acb39c24 2021-02-01 00:35:00.000 2021-02-01 00:35:04.251 Nature_Remo_1 2021-02-01 00:35:06.479 21.8 40.0 149.0 2021-01-31T15:28:20Z 0.0 21.0 warm auto auto power-on 4029.99 516.0
9 6016cf6b35092f3abe95fc01 2021-02-01 00:40:00.000 2021-02-01 00:40:04.305 Nature_Remo_1 2021-02-01 00:40:06.575 21.8 40.0 149.0 2021-01-31T15:28:20Z 0.0 21.0 warm auto auto power-on 4030.04 520.0
10 6016d097f378ed61c589db1e 2021-02-01 00:45:00.000 2021-02-01 00:45:04.597 Nature_Remo_1 2021-02-01 00:45:06.810 21.8 40.0 149.0 2021-01-31T15:28:20Z 0.0 21.0 warm auto auto power-on 4030.08 512.0
:
Athenaのクエリの文法は以下のSQLリファレンスを参照ください
ここではいくつかの例を紹介します。
列に対してフィルタを指定したい場合は、以下のようにWHERE文を使用できます
SELECT Date_Master, no01_Temperature, no01_AirconPower FROM "データベース名"."テーブル名"
WHERE no01_Temperature > 28.5 AND no01_AirconPower = 'power-on'
# Date_Master no01_Temperature no01_AirconPower
1 2020-09-18 22:10:00.000 28.6 power-on
2 2020-09-18 22:15:00.000 28.6 power-on
3 2020-09-18 22:20:00.000 28.6 power-on
4 2020-09-18 22:25:00.000 28.6 power-on
5 2020-09-18 22:30:00.000 28.6 power-on
:
また、S3 Selectと異なり、ORDER BYやGROUP BYによる集計も可能となります
SELECT Date_Master, no01_Temperature, no01_AirconPower FROM "データベース名"."テーブル名"
WHERE no01_Temperature > 28.5 AND no01_AirconPower = 'power-on'
ORDER BY Date_Master
# Date_Master no01_Temperature no01_AirconPower
1 2020-08-14 13:35:00.000 30.0 power-on
2 2020-08-14 13:40:00.000 30.0 power-on
3 2020-08-14 13:45:00.000 30.0 power-on
4 2020-08-14 13:50:00.000 30.0 power-on
5 2020-08-14 13:55:00.000 29.400002 power-on
:
SELECT no01_AirconPower, AVG(no01_Temperature) FROM "sampledb1"."sample_table1"
GROUP BY no01_AirconPower
# no01_AirconPower _col1
1 power-on 24.32105
2 power-on_maybe 26.037397
3 power-off 22.986347
S3 Selectと比べて、より通常のSQLに近い操作でS3内のデータをクエリできるようになった事がわかります。
Athenaのクエリのユースケースについては以下のドキュメントも参考になるので、SQLリファレンスと併せてご参照ください
Python SDKからの使用法
Athenaも、S3 Selectと同様にPython SDK(Boto3)からクエリでデータを取得する事ができます。
Boto3からAthenaを操作するためには、事前にコンソールから「ステップ1: データベースの作成」「ステップ2: テーブルの作成」を実行しておく必要があります。
またAthenaは一般的なクラウドDBの操作と同様、クエリの実行開始から結果の出力までにタイムラグが生じます(データ量が多いほど所要時間は長くなります)。よってこのタイムラグの間スクリプトが反応しなくなる事を防ぐため、基本的には以下の3段階に分けたクエリの実行が推奨されています(参考)
-
start_query_execution()メソッドでクエリ開始指示を送信 -
get_query_execution()メソッドでクエリ実行状況を確認 -
get_query_result()メソッドでクエリ実行結果を取得
例を交えて解説します。
スクリプト例
下の例では、コンソールでの実行例と同じクエリを実行してPandasのデータフレームに変換しています。
import boto3
import time
import pandas as pd
REGION = 'ap-northeast-1' # リージョン名
BUCKET_NAME = 'クエリ対象バケット名' # クエリ対象のバケット名
OUTPUT_BUCKET = 'クエリ結果の出力先バケット名' # クエリ結果の出力先バケット名
DATABASE = 'Athenaデータベース名' # コンソールで作成したAthenaデータベース名
TABLE_NAME = 'Athenaテーブル名' # コンソールで作成したAthenaテーブル名
COLNAMES = ['Date_Master', 'no01_Temperature', 'no01_AirconPower'] # クエリ取得対象の列名
# SQLクエリを記述
QUERY = f"SELECT {','.join(COLNAMES)} FROM {TABLE_NAME} WHERE no01_Temperature > 28.5 AND no01_AirconPower = 'power-on'"
# Athenaクライエント作成 (クライエントAPIを使用)
athenaclient = boto3.client('athena', region_name=REGION)
# 1. start_query_executionメソッドでクエリ開始指示を送信
response = athenaclient.start_query_execution(
QueryString=QUERY,
QueryExecutionContext={
'Database': DATABASE
},
ResultConfiguration={
'OutputLocation': f's3://{OUTPUT_BUCKET}/athena-query-results/' # クエリ結果出力先(プレフィックスは任意でOK)
}
)
query_execution_id = response['QueryExecutionId']
# 2. get_query_executionメソッドでクエリ実行状況を確認
start = time.time() # 時間計測用
# 実行完了まで問い合わせをループ実行
while True:
# クエリ実行状況を確認
response = athenaclient.get_query_execution(QueryExecutionId=query_execution_id)
status = response['QueryExecution']['Status']['State']
if status == 'SUCCEEDED': # 実行完了
break
elif status == 'FAILED' or status == 'CANCELLED': # 実行失敗
raise Exception(f"Query failed or was cancelled: {response}")
else:# 実行完了していないとき、規定秒だけ待って再度問い合わせ
time.sleep(0.5)
print(f'Waiting for query completion. Elapsed time={time.time() - start}')
# 3. get_query_resultメソッドでクエリ実行結果を取得
result_resoponse = athenaclient.get_query_results(
QueryExecutionId=query_execution_id
)
# 1行目をヘッダーとして使用
header = [col.get('VarCharValue', None) for col in result_resoponse['ResultSet']['Rows'][0]['Data']]
# 2行目以降をデータとして使用
data = [[col.get('VarCharValue', None) for col in row['Data']]
for row in result_resoponse['ResultSet']['Rows'][1:]]
# 結果をPandas.DataFrameに格納
df_result = pd.DataFrame(data, columns=header)
print(df_result.head())
Date_Master no01_Temperature no01_AirconPower
0 2021-07-20 22:40:00.000 29.0 power-on
1 2021-07-20 22:45:00.000 29.0 power-on
2 2021-07-21 18:50:00.000 29.0 power-on
3 2021-07-26 19:25:00.000 29.0 power-on
4 2021-07-26 19:30:00.000 29.0 power-on
※よくある注意点
-
start_query_execution()メソッドのResultConfiguration['OutputLocation']引数で結果出力先のバケットを指定しないと、エラーが出ます -
get_query_execution()メソッド実行時のtime.sleep(0.5)の部分の待ち時間は適宜調整してください -
get_query_results()メソッドで出力できるレスポンスの構造は、以下のようになっています。リスト内包表記の部分のコードが少し複雑になっていますが、以下のレスポンスからヘッダーとデータを分離してテーブル構造のリストに変換する処理を実施しています
{
'UpdateCount': 0,
'ResultSet': {
'Rows': [
'Data': [
{'VarCharValue': '列名1'},
{'VarCharValue': '列名2'},
:
],
'Data': [
{'VarCharValue': '1行目1列目のデータ'},
{'VarCharValue': '1行目2列目のデータ'},
:
],
'Data': [
{'VarCharValue': '2行目1列目のデータ'},
{'VarCharValue': '2行目2列目のデータ'},
:
],
:
],
'ResultSetMetadata': {...}
},
'ResponseMetadata': {...}
}
- レスポンスのサイズが大きい場合、分割して返される場合もあります(デフォルトでは1000レコードごとに分割。参考)。この場合、こちらの記事のようにpaginetorを使用して、「3. get_query_resultメソッドでクエリ実行結果を取得」以降のコードを以下のように書き換えます
:
中略
:
# 3. get_query_resultメソッドでクエリ実行結果を取得
df_all = []
header = []
# paginatorを使用して分割レスポンスに対応
paginator = athenaclient.get_paginator('get_query_results')
# 分割レスポンスをループ実行
for i, page in enumerate(paginator.paginate(QueryExecutionId=query_execution_id)):
# 分割レスポンスの1個目のページのみ、1行目をヘッダーとして使用
if i == 0:
header = [col.get('VarCharValue', None) for col in page['ResultSet']['Rows'][0]['Data']]
# 2行目以降をデータとして使用
data = [[col.get('VarCharValue', None) for col in row['Data']]
for row in page['ResultSet']['Rows'][1:]]
# 結果をPandas.DataFrameに格納
df_result = pd.DataFrame(data, columns=header)
df_all.append(df_result)
print(f'Processing page {i}')
# 全てのページのDataFrameを合体
df_all = pd.concat(df_all, axis=0)
print(df_result.head())
実行してみると分かりますが、ページ分割数が増えると実行に時間が掛かります(主にpaginator.paginate()のイテレーションの実行に時間が掛かります)。パフォーマンス向上のためには、なるべくレコード数が少なくなるようクエリを工夫するのが良いでしょう。
Athena for Apache Spark
以下のように、2022/12にリリースされた新しい機能となります。
分散処理フレームワークであるApache Spark(詳細はEMRの項で解説します)を、Athenaでも使用できるようになりました。
本記事では割愛しますが、要望があれば調査して記事を作ろうと思います。
Athenaの高速化
Athenaの速度パフォーマンス向上には、以下の公式パフォーマンスチューニングTipsが参考になります
Athenaの料金
Athenaの料金は、以下の公式サイトに記載されています。
2023年4月現在、東京リージョンでは以下のような料金となっています。
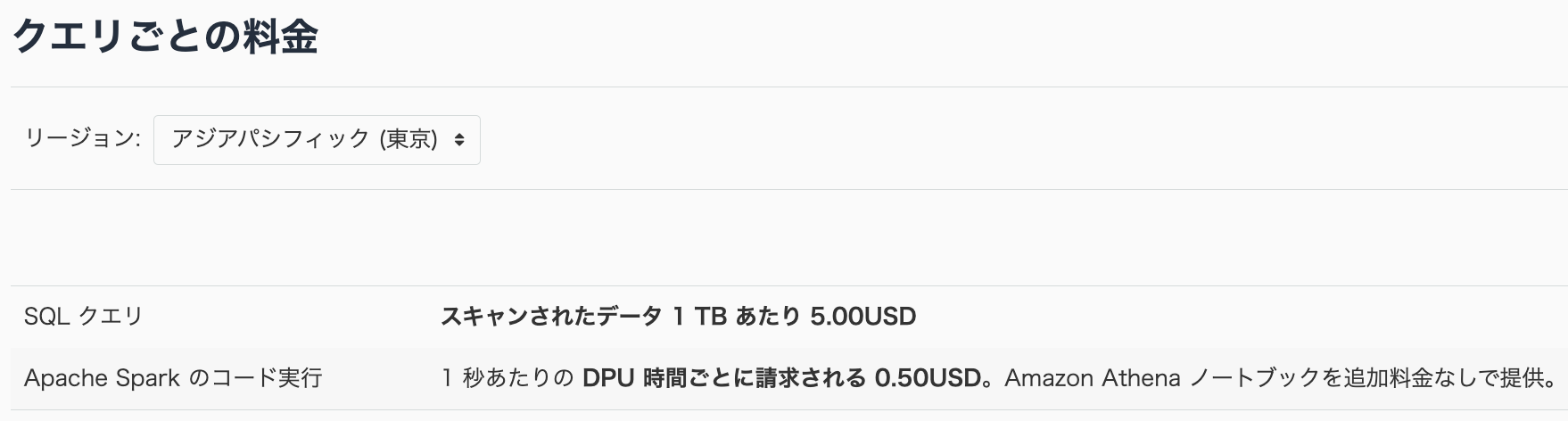
Athenaのコスト削減施策
S3 Selectと同様、基本的には「スキャンされたデータ」はクエリ対象となったファイル全体のサイズ(今回使用したサンプルデータでは、CSVファイル全体のサイズ)を指し、ただクエリのWHEREやSELECTでデータを絞るだけではコスト削減にはつながりません。
一方で、
1. データの圧縮
2. 分割(パーティション分割)
3. 列形式への変換
を行うと、この「スキャンされたデータ」のサイズを減らすことができます。
それぞれ解説します。
コスト削減施策1: データの圧縮
S3に保存するデータを圧縮形式(GZIP等)にすると、スキャン対象のデータサイズを減らす事ができ、コスト削減に繋がります。
コスト削減施策2: パーティション分割
データを Apache Hive スタイルでパーティション分割することで、スキャン対象のデータサイズを減らす事ができ、パフォーマンス向上&コスト削減に繋がります。
少し複雑ですが、RedshiftやBigQuery等のDWHでもパーティション分割は重要な考え方となるため、覚えておいて損はないかと思います。
パーティションの分割単位として、一般的には年、月、日、時間等の時系列がよく用いられます。
こちらの記事に記載されているように、Hiveフォーマットを考慮したファイル構成としていれば、パーティションの分割が楽となりますが、多くの既存のバケットではそのようになっていない可能性が高いので、Hiveフォーマットを考慮していないファイル構成での例を紹介します。
このケースの注意点として、パーティションの分割単位を表すフォルダが存在する必要があります。すなわち、S3へのデータの蓄積段階で月ごとや日ごとにフォルダを分けておく必要があります。
例えば先ほどのテーブル作成において、年フォルダごとにパーティションを分割したい場合、
CREATE EXTERNAL TABLE IF NOT EXISTS sample_table1 (
`_id` STRING,
Date_ScanStart DATETIME,
no01_DeviceName STRING,
no01_Date DATETIME,
no01_Temperature FLOAT,
no01_Humidity FLOAT,
no01_Light FLOAT,
no01_Human_last STRING,
no01_HumanMotion FLOAT,
no01_TempSetting FLOAT,
no01_AirconMode STRING,
no01_AirVolume STRING,
no01_AirDirection STRING,
no01_AirconPower STRING,
no01_CumulativeEnergy FLOAT,
no01_Watt FLOAT
)
PARTITIONED BY (partition_year STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
LOCATION 's3://バケット名/sensors/per_month/';
というように、PARTITIONED BY (パーティション列名 STRING)で指定します(パーティション列名は好きな新規列名を指定します)
本例ではHiveフォーマットを考慮していないファイル構成となっているので、パーティション追加のために以下のクエリも実行する必要があります
ALTER TABLE sample_table1 ADD PARTITION (partition_year='2020') location 's3://iot-backup-data/sensors/per_month/2020/'
ALTER TABLE sample_table1 ADD PARTITION (partition_year='2021') location 's3://iot-backup-data/sensors/per_month/2021/'
ALTER TABLE sample_table1 ADD PARTITION (partition_year='2022') location 's3://iot-backup-data/sensors/per_month/2022/'
上記クエリを全てのパーティションについて手動実行する必要があるので、日毎に分割する場合のように分割数が多いケースでは骨が折れます。このようなケースではHiveフォーマットを使用するのが良いでしょう。
以下のように、パーティション列名でWHERE文を実行することで、スキャン対象のデータサイズを削減する事ができます
SELECT * FROM "sampledb1"."sample_table1"
WHERE partition_year='2022'
上記のケースではスキャンしたデータのサイズは40.17MBとなり、WHEREを指定せずに
SELECT * FROM "sampledb1"."sample_table1"`
とした場合のサイズ120.27MBと比べてデータサイズ、すなわちコストを低減できた事が分かります。
パーティション分割の詳細は以下の公式ドキュメントを参照ください。
コスト削減施策3: データの列形式への変換
S3に保存するデータをCSVではなく列指向のParquet形式にすると、SELECT文で指定した列のみが「スキャンされたデータ」に、クエリの工夫次第で大幅にコストを削減する事ができます。
列指向形式のデータでコスト(および処理時間)を削減したい場合、
SELECT * FROM "データベース名"."テーブル名"
のようにアスタリスクで全列を取得するのではなく、
SELECT 列名1, 列名2 FROM "データベース名"."テーブル名"
のように列名を具体的に指定し、必要な列のみを取得するようにしてください
また、CSV等をParquet形式に変換する方法は以下の公式ドキュメントを参照ください。