モデル更新しました
Generatorのモデルを更新したので、この記事を見ながら読んで貰えれば。
やりたいこと
・使いやすいKerasを使ってボイチェンしたい。
・パラレルデータ用意するの面倒だし、ノンパラOKなCycleGANを使いたい。
・というより、結月ゆかりになりたい。
理論とか
環境
Win10
Python3.6
PyCharm
Keras
GANとは
簡単に言うと、画像とか音声とかまー色々自動生成できるようになるすごい技術。
・本物かどうかを判断するDiscriminator(ディスクリミネータ、識別器)
・識別器を騙せるようなデータを生成するGenerator(ジェネレータ、生成器)
この2つを学習させることで、本物っぽいデータを生成できるようになる。偽札を作る技術(Generator)と、それを見分ける技術(Discriminator)、みたいな。
詳しくは今さら聞けないGAN(1) 基本構造の理解とかを見ればなんとなく分かるかと。
CycleGANとは
上記GANを応用したもの。データA,データBの2種類を用意して学習させる。このとき、普通はそれぞれ対応してるデータ(パラレルデータ)を用意する必要があるが、CycleGANならその必要がない(ノンパラレルデータ)。
で、AをBに、BをAに変換することを学習させるのが目的。要はこんな感じの理論。
基本的に上記GANと同じだけど、変換を上手くやるために色々とLossを考えてやる必要があるっぽい。
①今までどおり、Discriminatorの識別Loss
②今までどおり、Generatorがどれだけ騙せたかのLoss
これらに加えて、
③A→B→Aのように復元させるLoss
④B→AのGeneratorにAを入れたとき、変換させずに出力させるLoss
が必要。
それぞれ図で表すならこんな感じ。
・Loss①(識別時のLoss)

・Loss②(騙すときのLoss)

・Loss③(復元Loss)

・Loss④(変換させたくないLoss)

上図4枚について、
・GenAはB→Aを行うGenerator
・GenBはA→Bを行うGenerator
・DiscBは入力されたデータが本物のBかどうかを識別するDiscriminator
となっている。
音声の扱いとか
今回は画像ではなく音声を扱う。で、音声は変換する必要がある。(そのまま入れても上手く行かなかった。よく分からん)。 ということで、音声関係に興味のある人らなら聞いたことはあるだろうFFT、もといSTFTを行う。概要とかは上記先駆者さんの記事とかへどうぞ。コードの実装はこちらのページをほぼそのまま使用しました。
ただ、このままだと複素数の形($2+j6$みたいなの。直交座標系)になってしまって、Kerasだと上手く学習できないっぽい。予想だけど、実部と虚部という2つの属性を一つとして学習させるのが無理。そもそも虚数の学習が無理。
ということでもうひと手間加える。既に勘付いてる人もいると思うが、極形式 $Z(cosθ+jsinθ)$ に変換する。こうすることで、実数形式の大きさZと偏角θを学習させるだけで済む。
ということで実装について
現状のコード全部はこっち。
使用した音源はaxfcに上げてます。DLパスは「4649」。
使用する音源は、女声がVOICEROIDの結月ゆかり。男声はAudacityを使って自分の声を録音した。
読み込みと保存
特に言うことがないくらい単純なコード。
読み込みコード
def get_data_from_wave(self, path):
sample_rate, data = wavfile.read(path)
return sample_rate, data
保存コード
def save_wave(self, path, sample_rate, data):
wavfile.write(path, sample_rate, data.astype(np.int16))
音声変換
まずはこれで音声をSTFTして複素数の形にする。
def stft(self, x, window, step):
length = len(x)
N = len(window)
M = int(sp.ceil(float(length - N + step) / step))
new_x = np.zeros(N + (M - 1) * step).astype(np.float32)
new_x[:length] = x
X = np.zeros([M, N], dtype=np.complex64)
for m in range(M):
start = step * m
X[m, :] = np.fft.fft(new_x[start:start + N] * window)
return X
次に極形式に変換するコード。
def to_polar(comp):
if len(comp.shape) > 2:
sys.exit("The input array shape is too large. Please put it in two dimensions.")
# z = np.sqrt(pow(comp.real, 2) + pow(comp.imag, 2)).astype(np.float32)
# z = np.abs(comp)
# angle = np.angle(comp).astype(np.float32)
z = []
angle = []
for c in comp:
for _c in c:
_z, _a = cmath.polar(_c)
z.append(_z)
angle.append(_a)
z = np.array(z, dtype=np.float32).reshape(comp.shape)
angle = np.array(angle, dtype=np.float32).reshape(comp.shape)
return z, angle
一応、これはnumpyでもできるんだけど、極形式を直交座標系に戻すのはnumpyじゃできないってんでcmath使ってる。どっちでも問題ないと思うんで、なんとなく残してる。
そして極座標を直交座標系に変換するコード。
def to_rect(z, angle, target_shape):
comp = []
for (Z, Angle) in zip(z, angle):
for (_z, _angle) in zip(Z, Angle):
comp.append(cmath.rect(_z, _angle))
comp = np.array(comp, dtype=np.complex64).reshape(target_shape)
return comp
最後に、複素数をもとの波形に戻す(逆STFT)コード。
def istft(self, X, window, step):
M, N = X.shape
length = (M - 1) * step + N
x = np.zeros(length, dtype=np.float32)
wsum = np.zeros(length, dtype=np.float32)
for m in range(M):
start = step * m
x[start:start + N] = x[start:start + N] + np.fft.ifft(X[m, :]).real * window
wsum[start:start + N] += window ** 2
pos = (wsum != 0)
x[pos] /= wsum[pos]
return x
モデル構築
このコードを参考に構築。
Kerasでのモデル構築には、Sequential、Functional API、の2つがある。前者はコードも分かりやすいし実装も楽なんだけど自由度が低い。後者はちょっと分かりにくいコードになるけど自由度が高い。レイヤーの使い回し(重みの共有)ができる。
まー詳しくは調べてくだせえ。
今回はFunctional APIを使った。
Generator
先駆者さんの記事に、
時間方向のために畳み込み層を、周波数方向のために全結合層を並列に導入してみました。
完全に自分の主観ですが、全結合層を導入したことで「本人らしさ」を激増したと思っています。畳み込み層だけの時は、声の高さこそそれっぽくなりましたが、こもった音だったり、本人だとは思いにくい声でした。全結合層を導入したことで、キズナアイさんのクリアな声が手に入ったと思います。
とあるので、こちらも同じように組んでみた。先駆者さんと同じようになっているかは分からん。
また、こちらのスライドの21枚目にResNetを使うと良いみたいに書いてるので、こちらのページを参考に実装したけど、リアルタイムで使うことを考えると時間かかっちゃうのかなぁってことで使ってない。いつでも使えるように残してはいる。
それと、今回は画像のような2次元の入力ではなく、1次元の入力なのでConv1Dとかを使用。2D用に変形しても良いんだろうけど、よく分からん。
大きさZのモデル
def build_generator_z(self, filters, summary=False):
def conv(layer, f, k_size=4, s_size=2):
c = Conv1D(filters=f,
kernel_size=k_size,
strides=s_size,
padding="same")(layer)
c = LeakyReLU(alpha=0.2)(c)
c = BatchNormalization()(c)
return c
def deconv(layer, f, drop_rate=0, k_size=4, s_size=1):
c = UpSampling1D(2)(layer)
c = Conv1D(filters=f,
kernel_size=k_size,
strides=s_size,
padding="same",
activation="relu")(c)
if drop_rate:
c = Dropout(drop_rate)(c)
c = BatchNormalization()(c)
return c
def resnet(layer, f, num_fase=3, num_blocks=3):
x = layer
for i in range(num_fase):
for b in range(num_blocks):
if b % 3 == 0 and b != 0:
x = AveragePooling1D(2)(x)
f *= 2
if i % 3 == 0:
x = Conv1D(filters=f // 2,
kernel_size=5,
padding="same")(x)
shortcut = x
shortcut = BatchNormalization()(shortcut)
x = Conv1D(filters=f,
kernel_size=3,
padding="same")(x)
x = BatchNormalization()(x)
x = Activation("relu")(x)
x = Conv1D(filters=f // 2,
kernel_size=3,
padding="same")(x)
x = BatchNormalization()(x)
x = Add()([x, shortcut])
x = Activation("relu")(x)
return x
input = Input(shape=self.input_shape)
reshape = Reshape(target_shape=(-1, 1))(input)
c = conv(reshape, filters, k_size=5)
c = conv(c, filters * 2, k_size=5)
c = conv(c, filters * 4, k_size=5)
c = conv(c, filters * 8, k_size=5)
# c = resnet(c, filters * 8, num_fase=3)
c = deconv(c, filters * 4, k_size=5)
c = deconv(c, filters * 2, k_size=5)
c = deconv(c, filters, k_size=5)
c = UpSampling1D(2)(c)
output = Conv1D(filters=1,
kernel_size=5,
strides=1,
padding="same",
activation="sigmoid")(c)
output = Reshape(target_shape=(-1,))(output)
d = Dense(units=self.dim // 2)(input)
d = Dropout(0.5)(d)
d = LeakyReLU(alpha=0.2)(d)
d = Dense(units=self.dim // 4)(d)
d = Dropout(0.5)(d)
d = LeakyReLU(alpha=0.2)(d)
d = Dense(units=self.dim, activation="sigmoid")(d)
output = Add()([output, d])
model = Model(inputs=input, outputs=output)
if summary:
model.summary()
return model
偏角θのモデル
def build_generator_t(self, filters, summary=False):
def conv(layer, f, k_size=4, s_size=2):
c = Conv1D(filters=f,
kernel_size=k_size,
strides=s_size,
padding="same")(layer)
c = LeakyReLU(alpha=0.2)(c)
c = BatchNormalization()(c)
return c
def deconv(layer, f, drop_rate=0, k_size=4, s_size=1):
c = UpSampling1D(2)(layer)
c = Conv1D(filters=f,
kernel_size=k_size,
strides=s_size,
padding="same",
activation="relu")(c)
if drop_rate:
c = Dropout(drop_rate)(c)
c = BatchNormalization()(c)
return c
def resnet(layer, f, num_fase=3, num_blocks=3):
x = layer
for i in range(num_fase):
for b in range(num_blocks):
if b % 3 == 0 and b != 0:
x = AveragePooling1D(2)(x)
f *= 2
if i % 3 == 0:
x = Conv1D(filters=f // 2,
kernel_size=5,
padding="same")(x)
shortcut = x
shortcut = BatchNormalization()(shortcut)
x = Conv1D(filters=f,
kernel_size=3,
padding="same")(x)
x = BatchNormalization()(x)
x = Activation("relu")(x)
x = Conv1D(filters=f // 2,
kernel_size=3,
padding="same")(x)
x = BatchNormalization()(x)
x = Add()([x, shortcut])
x = Activation("relu")(x)
return x
input = Input(shape=self.input_shape)
reshape = Reshape(target_shape=(-1, 1))(input)
c = conv(reshape, filters, k_size=5)
c = conv(c, filters * 2, k_size=5)
c = conv(c, filters * 4, k_size=5)
c = conv(c, filters * 8, k_size=5)
# c = resnet(c, filters * 8, num_fase=3)
c = deconv(c, filters * 4, k_size=5)
c = deconv(c, filters * 2, k_size=5)
c = deconv(c, filters, k_size=5)
c = UpSampling1D(2)(c)
output = Conv1D(filters=1,
kernel_size=5,
strides=1,
padding="same",
activation="sigmoid")(c)
output = Reshape(target_shape=(-1,))(output)
d = Dense(units=self.dim // 2)(input)
d = Dropout(0.5)(d)
d = LeakyReLU(alpha=0.2)(d)
d = Dense(units=self.dim // 4)(d)
d = Dropout(0.5)(d)
d = LeakyReLU(alpha=0.2)(d)
d = Dense(units=self.dim, activation="tanh")(d)
output = Add()([output, d])
model = Model(inputs=input, outputs=output)
if summary:
model.summary()
return model
ところで、Zのモデルの出力層がsigmoidになっているのだが、これはミスではない。というのも、Zの範囲を0~1に正規化する関係で、出力値の範囲もこれに合わせたかったから。一般的にGANのGenの出力層はtanhにしろってなってるんだけど、これだと-1~1になっちゃって変わってしまう。
実際、tanhでやってたときは音声だと判別できるようなのが生成されるまでに時間がかなりかかったし失敗ばかり。まーよく考えなくても、大きさが負数ってなんだよって話だしね。
ということで、sigmoidにしたらかなり改善されたって話。
偏角θの範囲は-1~1になるので、tanhで問題なし。
たぶん邪道だし正攻法じゃないって思うけど他の方法が思いつかん。
Discriminator
これはZもθも共通のモデル。
def build_discriminator(self, filters, summary=False):
def conv(layer, f, k_size=4, s_size=2, dropout=0.0, normalize=True):
c = Conv1D(filters=f,
kernel_size=k_size,
strides=s_size,
padding="same")(layer)
c = LeakyReLU(alpha=0.2)(c)
if dropout:
c = Dropout(dropout)(c)
if normalize:
c = BatchNormalization()(c)
return c
input = Input(shape=self.input_shape)
c = Reshape(target_shape=(-1, 1))(input)
c = conv(c, filters, normalize=False)
c = conv(c, filters * 2, k_size=3, dropout=0.5)
c = conv(c, filters * 4, k_size=3, dropout=0.5)
c = conv(c, filters * 8, k_size=3, dropout=0.5)
c = Flatten()(c)
c = Dense(units=128)(c)
c = LeakyReLU(0.2)(c)
output = Dense(units=1, activation="sigmoid")(c)
model = Model(inputs=input, outputs=output)
if summary:
model.summary()
return model
出力は本物か偽物か、の出力なので0,1になるように。
学習について
学習モデルの作成とコンパイル
最初の方に書いたLoss4種を、Z,θそれぞれに用意するので、計8個のモデルを作成することになる。両方やってることは同じなので載せるのはZのだけ。
self.gen = Generator(input_shape=self.input_shape)
self.disc = Discriminator(input_shape=self.input_shape)
""" [Z] """
# genuine_A -> fake_B
self.g_aB_z = self.gen.build_generator_z(filters=16)
# B -> genuine or fake
self.d_B_z = self.disc.build_discriminator(filters=16)
self.d_B_z.compile(loss="mse",
optimizer=self.d_optimizer,
metrics=["accuracy"])
# genuine_B -> fake_A
self.g_bA_z = self.gen.build_generator_z(filters=16)
# A -> genuine or fake
self.d_A_z = self.disc.build_discriminator(filters=16)
self.d_A_z.compile(loss="mse",
optimizer=self.d_optimizer,
metrics=["accuracy"])
input_a_z = Input(shape=self.input_shape)
input_b_z = Input(shape=self.input_shape)
# create fake data
fake_a_z = self.g_bA_z(input_b_z) # genuine_B -> fake_A
fake_b_z = self.g_aB_z(input_a_z) # genuine_A -> fake_B
# reconstruct
recon_b_z = self.g_aB_z(fake_a_z) # (genuine_B -> ) fake_A -> genuine_B
recon_a_z = self.g_bA_z(fake_b_z) # (genuine_A -> ) fake_B -> genuine_A
self.g_aBA_z = Model(inputs=input_a_z, outputs=recon_a_z)
self.g_bAB_z = Model(inputs=input_b_z, outputs=recon_b_z)
# not convert
nc_a_z = self.g_bA_z(input_a_z) # genuine_A -> genuine_A (gen: B -> A)
nc_b_z = self.g_aB_z(input_b_z) # genuine_B -> genuine_B (gen: A -> B)
self.nc_bA_z = Model(inputs=input_a_z, outputs=nc_a_z)
self.nc_aB_z = Model(inputs=input_b_z, outputs=nc_b_z)
self.d_A_z.trainable = False
self.d_B_z.trainable = False
# deceive disc
deceive_A_z = self.d_A_z(fake_a_z)
deceive_B_z = self.d_B_z(fake_b_z)
self.c_aB_z = Model(inputs=input_a_z, outputs=deceive_B_z) # genuine_B -> fake_A -> Genuine(expected value)
self.c_bA_z = Model(inputs=input_b_z, outputs=deceive_A_z) # genuine_A -> fake_B -> Genuine(expected value)
self.c_aB_z.compile(loss="mse",
optimizer=self.g_optimizer,
metrics=["accuracy"])
self.c_bA_z.compile(loss="mse",
optimizer=self.g_optimizer,
metrics=["accuracy"])
self.g_aBA_z.compile(loss="mae",
optimizer=self.g_optimizer)
self.g_bAB_z.compile(loss="mae",
optimizer=self.g_optimizer)
self.nc_bA_z.compile(loss="mae",
optimizer=self.g_optimizer)
self.nc_aB_z.compile(loss="mae",
optimizer=self.g_optimizer)
self.model_save(self.g_aB_z, "g_ab_z.json")
self.model_save(self.d_B_z, "d_b_z.json")
self.model_save(self.g_bA_z, "g_ba_z.json")
self.model_save(self.d_A_z, "d_a_z.json")
学習用データの用意
音声データを読み込み、-1~1のレンジに正規化し、stftして、極形式にして、ここでも正規化。これをデータA,B両方に行う。載せてるのはAだけ。
Zの正規化のレンジは先に算出しておいた。用意したデータを一通り読み込み、Zの最大値を算出し、それに+1したものを使っている。+1はなんとなく。
θは-π~πのレンジってのが確定してるので、np.piで割っただけ。
fs_a, data_a = va.get_data_from_wave(file_a)
data_a = np.array(data_a, dtype=np.float32).copy()
data_a /= 32768.0
stft_a = va.stft(data_a, self.window, self.step)
stft_a_z, stft_a_theta = to_polar(stft_a)
stft_a_z /= 256.0
stft_a_theta /= np.pi
次に、モデルに入力するデータの選定を行う。別に全部入れても良いんだけど、最初の方にリンク書いたDCGANの記事は抽出してたし、それに合わせてみる。どうせ入力は1行ずつだから上下の関係はそこまで大事じゃないはずだし。
ということでコード。これもAだけ載せる。
idx_a = np.random.randint(0, stft_a.shape[0], batch_size)
input_a_z = stft_a_z[idx_a]
input_a_t = stft_a_theta[idx_a]
Lossの算出
以下の手順で行う。
- Gen.predictで偽物データを生成
- Discに「本物データと本物ラベル1」、「偽物データと偽物ラベル0」を入力して学習→Loss①
- Discに「偽物データと本物ラベル1」を入力して学習→Loss②
- 復元用Genに「本物データと本物ラベルとして本物データ」を入力して学習→Loss③
- 素通しGenに「本物データと本物ラベルとして本物データ」を入力して学習→Loss④
コードがこれ。ZのB→Aだけ載せる。
""" B -> A """
fake_a_z = self.g_bA_z.predict(input_b_z)
d_loss_real_ba = self.d_A_z.train_on_batch(input_a_z, real_label)
d_loss_fake_ba = self.d_A_z.train_on_batch(fake_a_z, fake_label)
d_loss_ba_z = 0.5 * np.add(d_loss_real_ba, d_loss_fake_ba)
c_loss_ba_z = self.c_bA_z.train_on_batch(input_b_z, real_label)
r_loss_ba_z = self.g_bAB_z.train_on_batch(input_b_z, input_b_z)
nc_loss_ba_z = self.nc_bA_z.train_on_batch(input_a_z, input_a_z)
学習結果の確認
Gen.predictに音声を丸々入力して、変換結果のZとθを取得。それを直交座標系に変換して、istftで音声波形に。それをwavファイルとして出力する。同時に、入力音声と生成音声の比較グラフも出力する。
コードがこれ。B→Aだけ載せる。
""" B -> A """
z = self.g_bA_z.predict(stft_b_z) * 256
t = self.g_bA_t.predict(stft_b_theta) * np.pi
data_bA = to_rect(z, t, stft_b.shape)
istft = va.istft(data_bA, self.window, self.step)
res = (istft * 32768.0).astype(np.int16)
p = self.res_path + "data_bA/" + os.path.basename(file_b)
p = p[:-4] + "_%d.wav" % epoch
va.save_wave(p, fs_a, res)
plt.figure()
plt.subplot(211)
plt.plot(data_b)
plt.subplot(212)
plt.plot(istft)
plt.ylim(-1, 1)
plt.savefig((self.res_path + "pic/data_bA/{}").format(
os.path.basename(file_a)[:-4] + "_%d.png" % epoch))
# plt.clf()
plt.close()
現状の変換状況
今はまだうまく行ってない。θのLossがなかなか減らない。
学習途中につき、このまま経過を観察する。
多少変化が見えてるっぽいもの
上段が入力音声、下段が生成音声。
・男声→女声
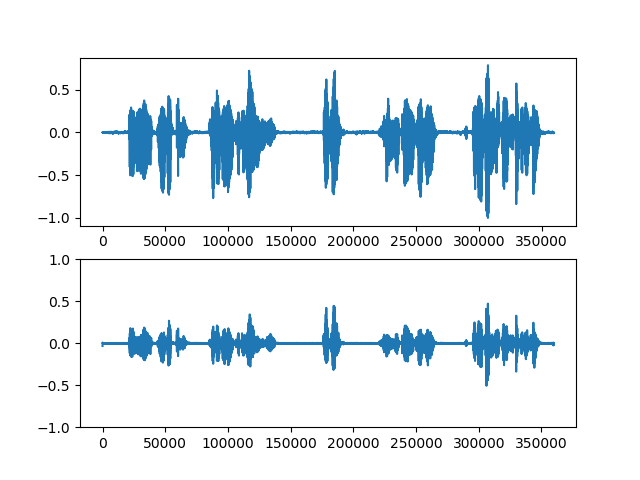
・女声→男声
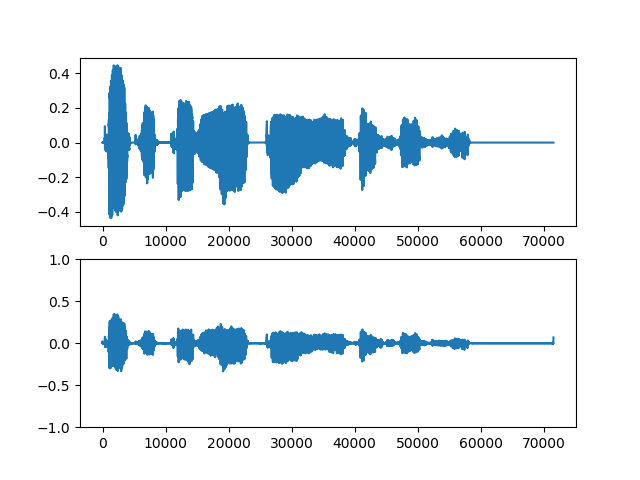
ぱっと見そこそこできてそうだけど、聞いてみるとそうでもない。むしろもとの音声そのままな感じ。
明らか失敗してるもの
上段が入力音声、下段が生成音声。
・男声→女声
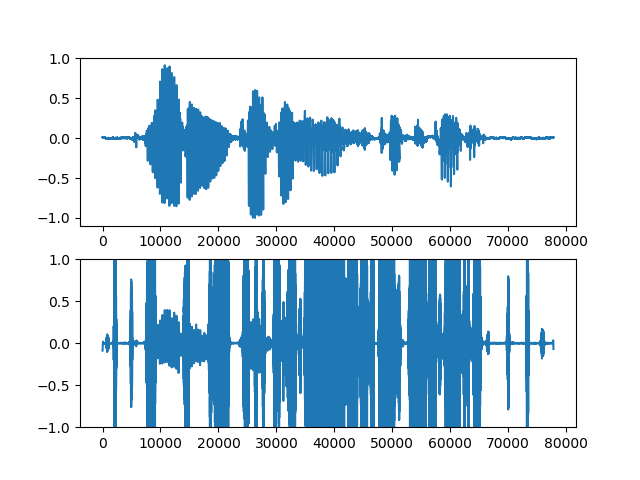
・女声→男声
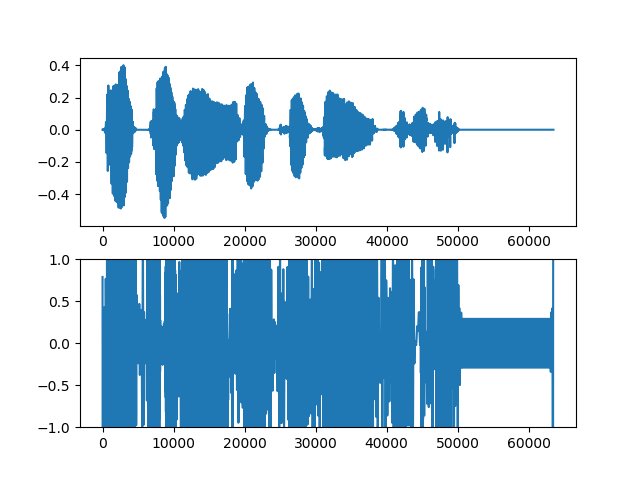
これでもまだマシな方。めちゃくちゃひどいのはこんな感じ。
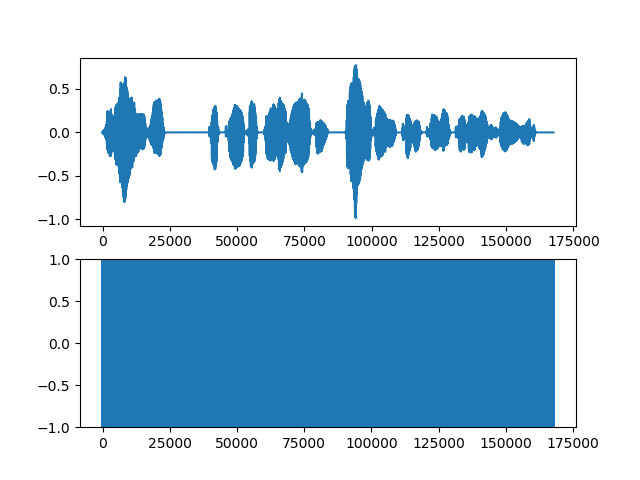
もはやなにがなんだか。この音声を聞いてもノイズにしかならない。
原因について
・FFTするときに長さ調節が入ってるから、それが原因なのかなぁって。並列が問題かと思ったけど、畳み込みだけにしたときも同じような生成になった。~~全結合だけは試してないけど、もっと悪くなるんじゃないかなって。~~全結合だけ、の方が変換が進んだ。詳しくはこっちに書いてます。
・ResNet使わないのも原因かもしれない。でも使ったときもそこまで変わった感じはなかった。そこまで影響があるとは思えない。
・そもそもsigmoidやtanhの選択が間違ってるのかも。sigmoidの代案としてはsoftplusとかhard_sigmoidがあるけど、tanhのはまだ考えてない。
・Conv1D使ってるけど、やっぱりConv2Dとかじゃないとダメな可能性もある。
・そもそも、もっと根本的な問題かもしれない。けれどそうなるとほんとに分からない。分かる人居たら教えてください。
参考リンクのまとめ
・先駆者さんの記事
・今さら聞けないGAN(1) 基本構造の理解
・CycleGAN
・Pythonで短時間フーリエ変換(STFT)と逆変換
・cyclegan.py
・CycleGANについて
・Res-Netsの有効性をCIFAR-10で確認する
追記
(2018/03/26)男声→女声の変換がそこそこ進んだように思う。なんか変換してます感のする、それっぽいものが聞こえだした。女声→男声はまだまだ。男声→女声がある程度完成したら変換が大きく進むのかなぁと考えてる。根拠はない。
(2019/05/04)Generatorのモデルを更新した。こっちのモデルの方が遥かに良い結果を得られるので、そっちをどうぞ。