RTX2080Tiを2枚使って、PyTorchでMixed Precision、FP16による訓練の高速化、精度とのトレードオフを計測してみました。高速化はできましたが、GPUのチューニングがかなり奥深くて大変だったことがわかりました。
前回までの記事
今回やること
Mixed-PrecisionとFP16による訓練を使って、FP32よりどの程度高速化するのかを計測します。PyTorchで訓練します。前回までと同じで、(1)10層CNN1GPU、(2)10層2GPU、(3)WRN28-10 1GPU、(4)WRN 2GPUの4ケースをバッチサイズを変えて比較します。
Apexを使ったMixed Precision、FP16訓練
PyTorchでは、Mixed Precisionを簡単に使うためのライブラリとしてApexがあります。使い方はとても簡単で、
import torch
from apex import amp
def train(batch_size, network, use_device):
# 中略
# model にモデルを入れる
optimizer = optim.SGD(model.parameters(), lr=initial_lr, momentum=0.9)
model, optimizer = amp.initialize(model, optimizer, opt_level="O1") # ここを追加
if use_device == "multigpu":
model = torch.nn.DataParallel(model)
for epoch in range(100):
# train
train_loss = 0.0
for i, (inputs, labels) in enumerate(train_loader):
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
#loss.backward()
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward() # ここを変更
optimizer.step()
train_loss += loss.item()
train_loss /= i+1 # per batch loss
このように、amp.initializeでモデルとオプティマイザをコンバートして、Back-propのところでsclaed_loss.backward()とするだけです。opt_levelが浮動小数点数の精度を表し、
- O0: 完全FP32
- O1: Mixed Precision(推奨)
- O2: Almost FP16なMixed Precision
- O3: 完全FP16
となります。Mixed PrecisionならO1が推奨で、今回もMixed Precisionと言ったときはこのO1を使いました。
FP16での訓練は本来はO2やO3でできますが、複数GPU時にこのissueのようなエラーが出てきたので、別な方法にしました。
FP16の訓練はApexのコードのfp16util.pyを使い、
from fp16util import network_to_half
def train(batch_size, network, use_device):
# 中略
model = network_to_half(model)
としました。これで複数GPUでも動きました。インポートはfp16utilをディレクトリにコピーしたので、Apexの中からインポートするときはパスが変わるかもしれません。
Tensorコアを使う ≠ MixedPrecision
ApexにおけるMixedPrecision(O1)とは、あくまでホワイトリストに登録された操作をFP16で、ブラックリストに登録された操作をFP32で計算し、損失のスケーリングを加えてBackPropするというものです(公式ドキュメント)。
したがって、MixedPrecisionを使うということと、Tensorコアを使うことは同義ではないようです。例えば、TensorコアがないGPUでもMixedPrecisionを使うことは可能です1。Tensorコアとは、あくまでFP16の計算を高速化するためのチップという位置づけで、MixedPrecisionでFP16を使うということは、その解放条件を満たすということにすぎません。FP16を使えばあとはフレームワークやライブラリ側で自動的にTensorコアを使ってくれるからです。
ハードウェアスペック
- GPU : RTX 2080Ti 11GB Manli製×2 SLI構成
- CPU : Core i9-9900K
- メモリ : DDR4-2666 64GB
- CUDA : 10.0
- cuDNN : 7.5.1
- PyTorch : 1.1.0
- Torchvision : 0.2.2
前回と同じです。「ELSA GPU Monitor」を使って、GPUのロードや消費電力をモニタリングします(5秒ごとCSV出力)。
訓練時間の比較
グラフ
縦軸に100エポックあたりの訓練時間(分)、横軸にバッチサイズを取ったものです。
順に、(1)10層1GPU、(2)10層2GPU、(3)WRN1GPU、(4)WRN2GPUで書いています。比較用にTensorFlow+TPUの例をおいています。TPUの場合はbfloat16化はしていません。
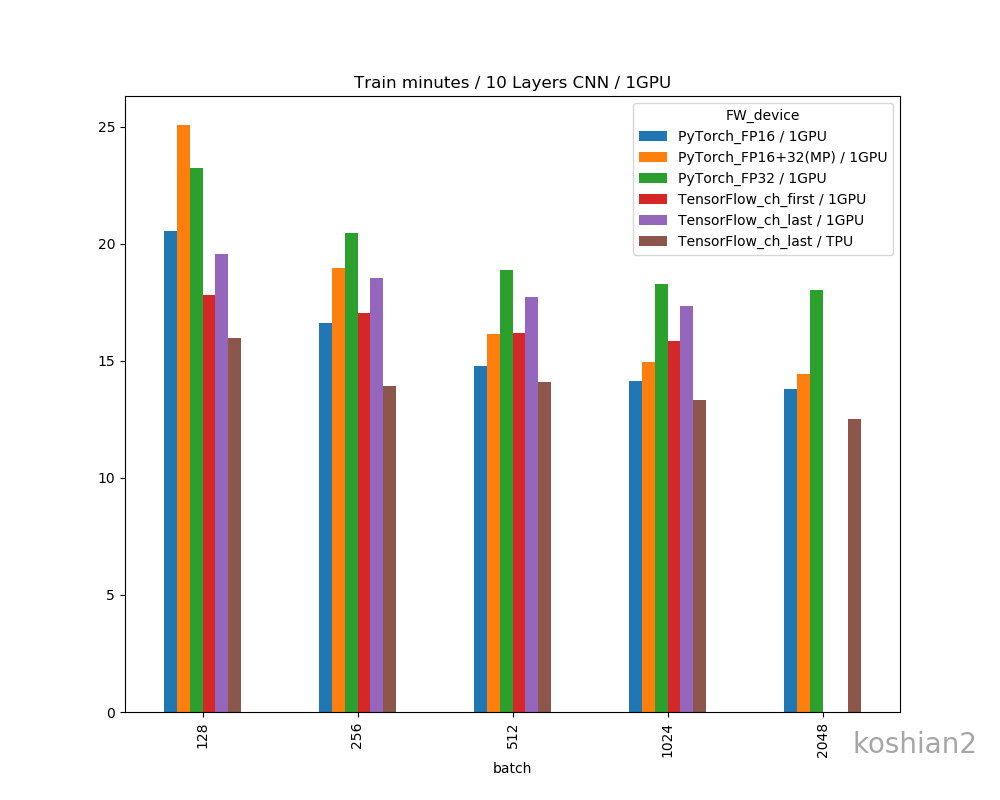
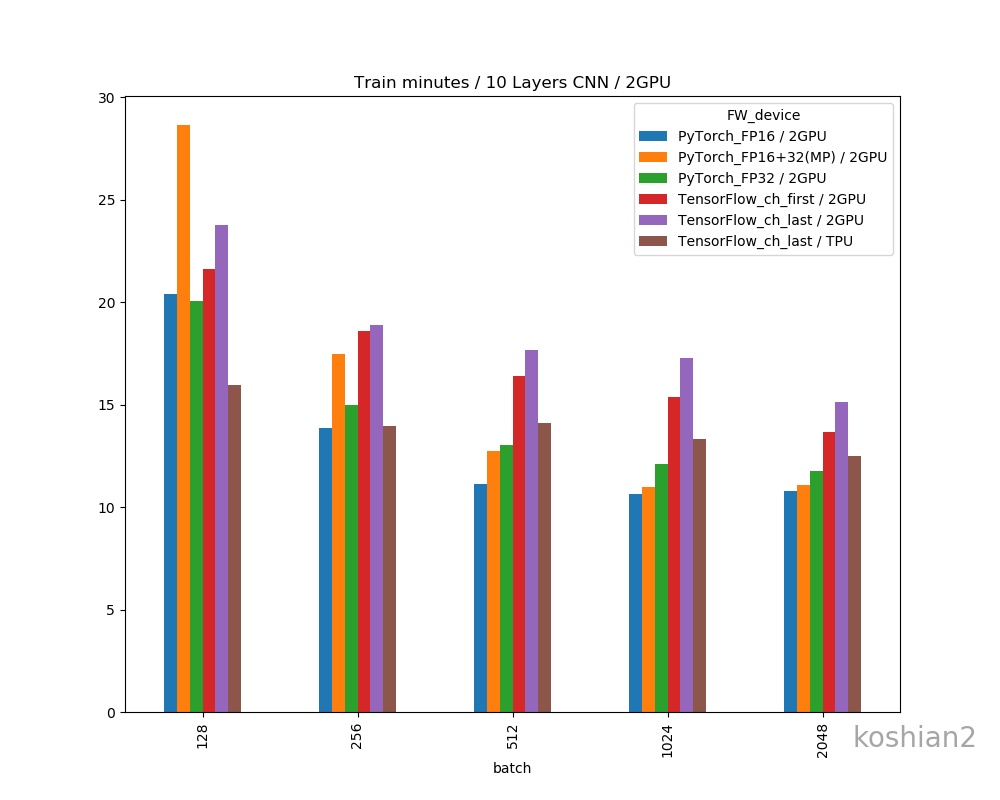
MixedPrecisionの場合は、小さいバッチサイズ(1GPUでは128、2GPUでは256以下)で逆に低速化するという現象がありますね。FP32とFP16の切り替えにボトルネックがあるのでしょう。この現象はBatchNormalizationをFP32で計算したFP16のケース(図ではFP16と書いていますが)では確認できませんでした。
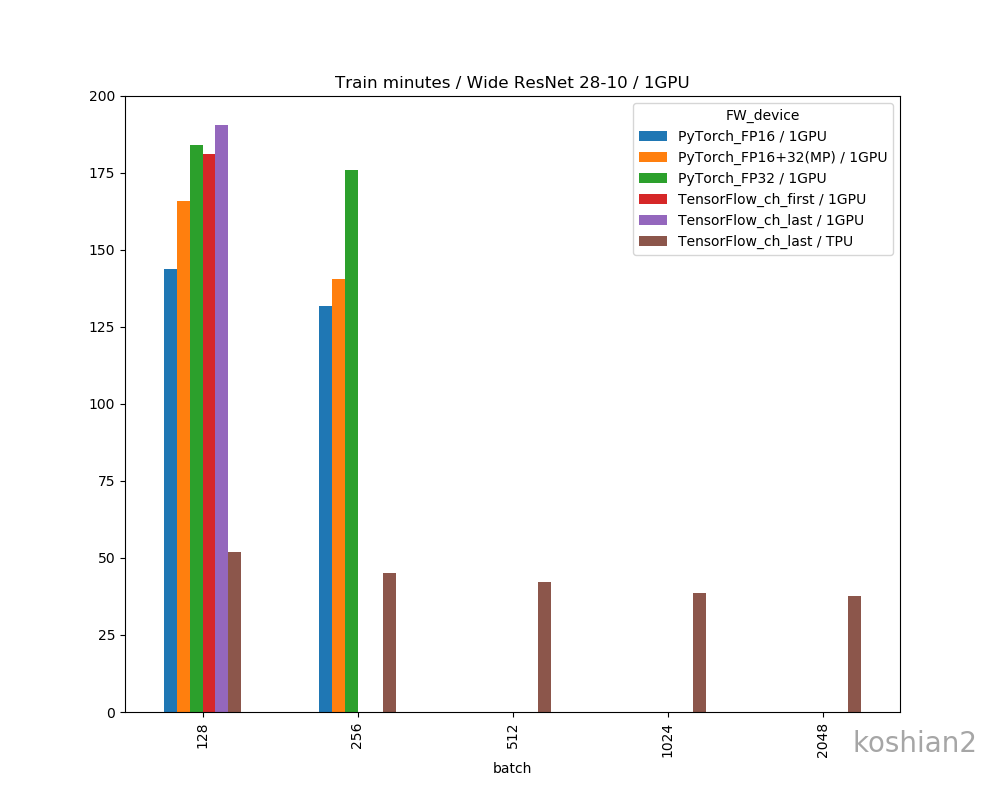
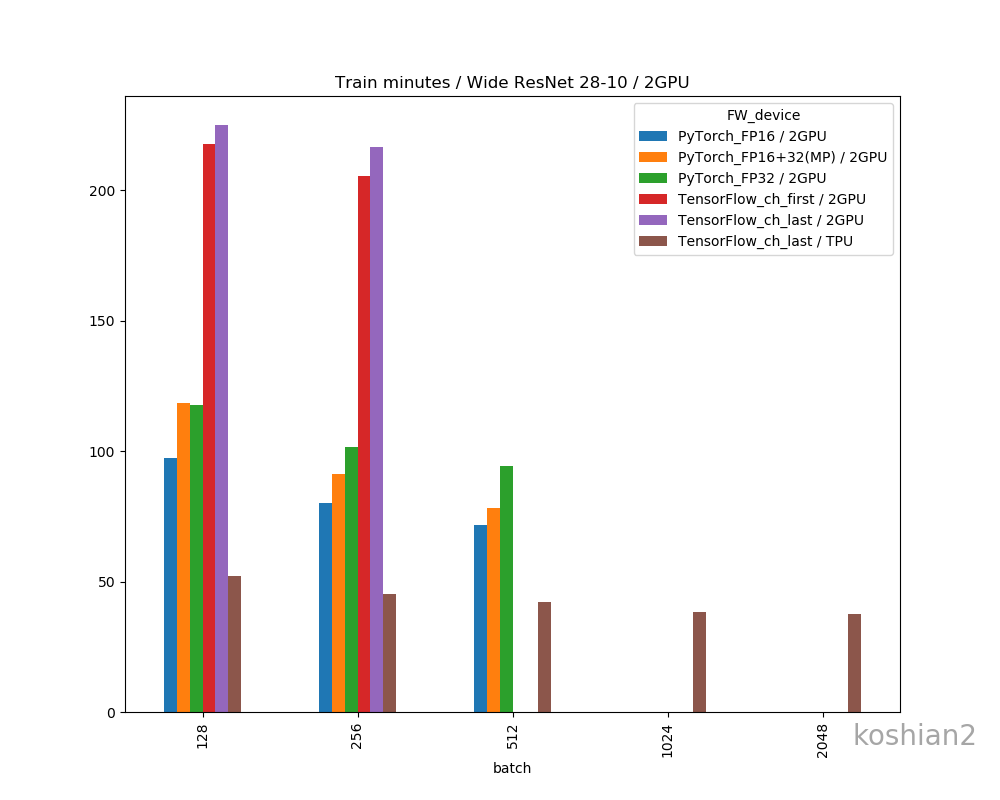
特にTensorFlowでグラフがないケースはOOMになってしまって測定できなかった例です(FP16だともう少しメモリサイズが少なくなるので、訓練できるバッチサイズは大きくなりますが計測するのを忘れていました)。WRNみたいな大きなネットワークだと、速度はFP16>FP32+16(Mixed Precision)>FP32というわかりやすい傾向になりました。
モデル、デバイス数間の高速化
TensorFlowの例は除外して、PyTorchのGPUだけの例で考えます。FP32を基準にしてどれだけ高速化しているかを計算します。
(1)10層1GPU
| batch |
128 |
256 |
512 |
1024 |
2048 |
| PyTorch_FP16 |
13.2% |
23.3% |
27.7% |
29.2% |
31.0% |
| PyTorch_FP16+32(MP) |
-7.2% |
7.8% |
16.9% |
22.3% |
24.9% |
このパーセンテージの計算式は、「FP32の時間÷各時間-1」をパーセント表記しています。例えばこの元データは、
| batch |
128 |
256 |
512 |
1024 |
2048 |
| PyTorch_FP16 |
20.53 |
16.60 |
14.78 |
14.15 |
13.78 |
| PyTorch_FP16+32(MP) |
25.07 |
18.98 |
16.15 |
14.95 |
14.45 |
| PyTorch_FP32 |
23.25 |
20.47 |
18.88 |
18.28 |
18.05 |
であり、FP16の128の13.2%は「23.25÷20.53-1=0.132」と計算したものです。パーセンテージは同一バッチサイズ間で計算しており、異なるバッチサイズ間では比較していません(バッチサイズを大きくすれば速くなるのは浮動小数点数の精度にかかわらず当たり前だから)。
(2)10層2GPU
| batch |
128 |
256 |
512 |
1024 |
2048 |
| PyTorch_FP16 |
-1.7% |
8.2% |
16.7% |
13.6% |
8.8% |
| PyTorch_FP16+32(MP) |
-29.9% |
-14.0% |
2.2% |
10.0% |
6.0% |
1GPUではFP16で最大31.0%、MixedPrecisionでは24.9%も高速化したのに、2GPUではFP16でも16.7%止まりとなってしまいました。GPU数が増えてもデバイス間の同期が大変ということでしょうか。
(3)WRN1GPU
| batch |
128 |
256 |
| PyTorch_FP16 |
27.9% |
33.6% |
| PyTorch_FP16+32(MP) |
11.0% |
25.3% |
1GPUの場合、ネットワークを大きくしても、FP16で最大33.6%、MixedPrecisionで最大25.3%高速化しました。これは10層CNNのケースと変わりません。
(4)WRN2GPU
| batch |
128 |
256 |
512 |
| PyTorch_FP16 |
20.6% |
26.8% |
31.5% |
| PyTorch_FP16+32(MP) |
-0.7% |
11.0% |
20.3% |
WRNのようにネットワークが大きくなると、10層CNNのときのようにあった、デバイス間の同期のボトルネックは軽減されます。これは、ネットワークが大きい故に畳込みの計算がまだ支配的だから、同期がそこまで問題にならないということでしょうか。
ここまでのまとめ
異なるニューラルネットワーク、異なる精度を比較したところ次のようなことがわかりました。
- RTX2080Tiは、MixedPrecisionで最大25%程度、FP16にすると最大30-35%高速化する
- 速度は、FP16>FP16+32のMixedPrecision>FP32
- FP16とFP32の計算の切り替えにはボトルネックがあり、特にMixed-Precisionでは小さいネットワークに対して逆に遅くなってしまうことも
- GPUの数が増えると、デバイス間の同期がボトルネックとなり、特に小さいネットワークで高速化効果は逓減することも
こんなものなの?
公称スペックを見るともっと速さが出そうに見えます。
RTX2080Ti : FP32=11.8TFlops, FP16=108TFlops
単純Flopsを見ると、FP16だけ使えば9倍近くなります。FP32+16を混ぜてもせめて数倍出るかのように思ってしまいます。しかし、実測だとこんなものらしいです。
あくまで公称スペックは最大スループットが出せたときのベストエフォートであって、「実際の訓練がこれだけ高速化するよ」という値ではないことに注意しましょう。
また、似たような結果として、Cloud TPUでbfloat16(FP16とは異なる定義の16ビットの浮動小数点数)を使ったMixed Precisionがこちらになります。

https://cloud.google.com/tpu/docs/bfloat16?hl=ja
TPUのFP32→bfloat16でも高速化は最高で32%で、何倍にもはならなかったそうです。小数点の精度を変えたところで得られる改善率は、実測値としてはこんなものでしょう。
ただし、GPUのMixed-Precisionを使ったケースで、分類では訓練速度は50%程度しか上がらなくても、YOLO-v3だと2-3倍になったという声もあるので、実際のところは試してみないとよくわからないというのが実情となっています。訓練が数倍の高速化したという結果があったらぜひ教えてください。
精度について
次に精度を見ていきましょう。高速化の代償としてどの程度精度が落ちるのでしょうか。
実測値
PyTorchのケースでFP16,Mixed Precision、FP32のケースの精度の実測値を比較します。
(1)10層1GPU
| batch |
128 |
256 |
512 |
1024 |
2048 |
| PyTorch_FP16 |
89.03% |
88.23% |
87.53% |
83.55% |
41.71% |
| PyTorch_FP16+32(MP) |
88.75% |
89.29% |
88.52% |
87.94% |
87.28% |
| PyTorch_FP32 |
89.15% |
89.00% |
88.37% |
88.60% |
86.39% |
(2)10層2GPU
| batch |
128 |
256 |
512 |
1024 |
2048 |
| PyTorch_FP16 |
88.52% |
88.72% |
87.68% |
82.86% |
38.56% |
| PyTorch_FP16+32(MP) |
89.04% |
89.09% |
88.71% |
88.32% |
86.05% |
| PyTorch_FP32 |
88.96% |
89.12% |
88.16% |
88.14% |
86.88% |
(3)WRN1GPU
| batch |
128 |
256 |
| PyTorch_FP16 |
85.54% |
73.96% |
| PyTorch_FP16+32(MP) |
86.88% |
84.00% |
| PyTorch_FP32 |
87.43% |
80.11% |
(4)WRN2GPU
| batch |
128 |
256 |
512 |
| PyTorch_FP16 |
86.33% |
82.67% |
77.99% |
| PyTorch_FP16+32(MP) |
88.27% |
74.44% |
72.25% |
| PyTorch_FP32 |
85.59% |
81.09% |
76.95% |
差分
実測値だけではよくわからないので、FP32-それ以外のケースの精度の差分を取ってみます。この値が大きいほどFP32よりも悪くなる、逆にこの値がマイナスならFP32よりも良い精度であることを意味します。
(1)10層1GPU
| batch |
128 |
256 |
512 |
1024 |
2048 |
| PyTorch_FP16 |
0.12% |
0.77% |
0.84% |
5.05% |
44.68% |
| PyTorch_FP16+32(MP) |
0.40% |
-0.29% |
-0.15% |
0.66% |
-0.89% |
(2)10層2GPU
| batch |
128 |
256 |
512 |
1024 |
2048 |
| PyTorch_FP16 |
0.44% |
0.40% |
0.48% |
5.28% |
48.32% |
| PyTorch_FP16+32(MP) |
-0.08% |
0.03% |
-0.55% |
-0.18% |
0.83% |
10層CNNのケースではわかりやすい結果となりました。Mixed Precisionが誤差±1%程度でほぼノイズ挙動となっているのに対して、FP16だけのほうが明らかに精度が落ちます。特に大きいバッチサイズでの精度の落ち方が激しいです。
(3)WRN1GPU
| batch |
128 |
256 |
| PyTorch_FP16 |
1.89% |
6.15% |
| PyTorch_FP16+32(MP) |
0.55% |
-3.89% |
WRN1GPUの場合は10層CNNとほぼ同じ結果となりました。FP16での落ち方が激しいですね。
(4)WRN2GPU
| batch |
128 |
256 |
512 |
| PyTorch_FP16 |
-0.74% |
-1.58% |
-1.04% |
| PyTorch_FP16+32(MP) |
-2.68% |
6.65% |
4.70% |
2GPUの場合のケースが謎で、FP32よりもFP16のほうが良くなってきました。本来はこういうことは稀なはずです。精度のブレ幅が大きいのでしょう。
精度まとめ
-
FP16は明らかに精度が落ちる。FP32と比較して、良くて0.5~1%、数%~数十%精度が落ちることもある。
-
FP16は特に高バッチサイズの領域で落ちやすい。バッチサイズを上げることによる精度の急降下が、FP16だとより小さいバッチサイズ領域で出るのだと思われる。
-
Mixed Precisionはまだマシ。精度のブレ幅については議論の余地があるが、FP32とあまり変わらないと
見て良い
- この測定結果では、FP16が最大35%、Mixed Precisionが最大25%の高速化であったことを考えると、少なくとも本番の訓練ではMixed PrecisionやFP32を使うべき。
損失Nanについて
Apexを使ったMixed Precisionにおいて、訓練の最初の段階で次のようなメッセージが出たことがありました。
Defaults for this optimization level are:
enabled : True
opt_level : O1
cast_model_type : None
patch_torch_functions : True
keep_batchnorm_fp32 : None
master_weights : None
loss_scale : dynamic
Processing user overrides (additional kwargs that are not None)...
After processing overrides, optimization options are:
enabled : True
opt_level : O1
cast_model_type : None
patch_torch_functions : True
keep_batchnorm_fp32 : None
master_weights : None
loss_scale : dynamic
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 32768.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 16384.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 8192.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 4096.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 2048.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1024.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 512.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 256.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 128.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 64.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 32.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 16.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 8.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 4.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 2.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 0.5
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 0.25
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 0.125
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 0.0625
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 0.03125
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 0.015625
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 0.0078125
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 0.00390625
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 0.001953125
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 0.0009765625
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 0.00048828125
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 0.000244140625
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 0.0001220703125
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 6.103515625e-05
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 3.0517578125e-05
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.52587890625e-05
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 7.62939453125e-06
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 3.814697265625e-06
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.9073486328125e-06
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 9.5367431640625e-07
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 4.76837158203125e-07
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 2.384185791015625e-07
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.1920928955078125e-07
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 5.960464477539063e-08
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 2.9802322387695312e-08
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.4901161193847656e-08
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 7.450580596923828e-09
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 3.725290298461914e-09
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.862645149230957e-09
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 9.313225746154785e-10
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 4.656612873077393e-10
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 2.3283064365386963e-10
Epoch 1 loss = nan val_acc = 0.1033 | 83.74s
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.1641532182693481e-10
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 5.820766091346741e-11
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 2.9103830456733704e-11
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.4551915228366852e-11
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 7.275957614183426e-12
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 3.637978807091713e-12
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.8189894035458565e-12
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 9.094947017729282e-13
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 4.547473508864641e-13
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 2.2737367544323206e-13
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.1368683772161603e-13
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 5.684341886080802e-14
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 2.842170943040401e-14
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.4210854715202004e-14
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 7.105427357601002e-15
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 3.552713678800501e-15
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.7763568394002505e-15
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 8.881784197001252e-16
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 4.440892098500626e-16
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 2.220446049250313e-16
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.1102230246251565e-16
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 5.551115123125783e-17
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 2.7755575615628914e-17
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.3877787807814457e-17
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 6.938893903907228e-18
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 3.469446951953614e-18
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.734723475976807e-18
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 8.673617379884035e-19
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 4.336808689942018e-19
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 2.168404344971009e-19
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.0842021724855044e-19
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 5.421010862427522e-20
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 2.710505431213761e-20
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.3552527156068805e-20
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 6.776263578034403e-21
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 3.3881317890172014e-21
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.6940658945086007e-21
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 8.470329472543003e-22
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 4.235164736271502e-22
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 2.117582368135751e-22
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.0587911840678754e-22
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 5.293955920339377e-23
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 2.6469779601696886e-23
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.3234889800848443e-23
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 6.617444900424222e-24
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 3.308722450212111e-24
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.6543612251060553e-24
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 8.271806125530277e-25
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 4.1359030627651384e-25
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 2.0679515313825692e-25
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.0339757656912846e-25
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 5.169878828456423e-26
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 2.5849394142282115e-26
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.2924697071141057e-26
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 6.462348535570529e-27
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 3.2311742677852644e-27
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.6155871338926322e-27
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 8.077935669463161e-28
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 4.0389678347315804e-28
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 2.0194839173657902e-28
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.0097419586828951e-28
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 5.048709793414476e-29
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 2.524354896707238e-29
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.262177448353619e-29
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 6.310887241768095e-30
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 3.1554436208840472e-30
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.5777218104420236e-30
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 7.888609052210118e-31
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 3.944304526105059e-31
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.9721522630525295e-31
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 9.860761315262648e-32
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 4.930380657631324e-32
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 2.465190328815662e-32
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.232595164407831e-32
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 6.162975822039155e-33
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 3.0814879110195774e-33
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.5407439555097887e-33
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 7.703719777548943e-34
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 3.851859888774472e-34
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.925929944387236e-34
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 9.62964972193618e-35
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 4.81482486096809e-35
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 2.407412430484045e-35
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.2037062152420224e-35
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 6.018531076210112e-36
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 3.009265538105056e-36
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.504632769052528e-36
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 7.52316384526264e-37
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 3.76158192263132e-37
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.88079096131566e-37
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 9.4039548065783e-38
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 4.70197740328915e-38
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 2.350988701644575e-38
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.1754943508222875e-38
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 5.877471754111438e-39
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 2.938735877055719e-39
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.4693679385278594e-39
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 7.346839692639297e-40
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 3.6734198463196485e-40
これは損失関数にNanが発生した結果、勾配のスケール定数の探索に失敗し、訓練がうまく進まなかったログです。訓練の開始の段階ではこのような状況に注意すべきでしょう。特に問題なく訓練が進むこともあれば、このように失敗してしまうこともあるので、確実に発生する現象というわけではありません(つまりガチャ)。
GPUログを見てみる
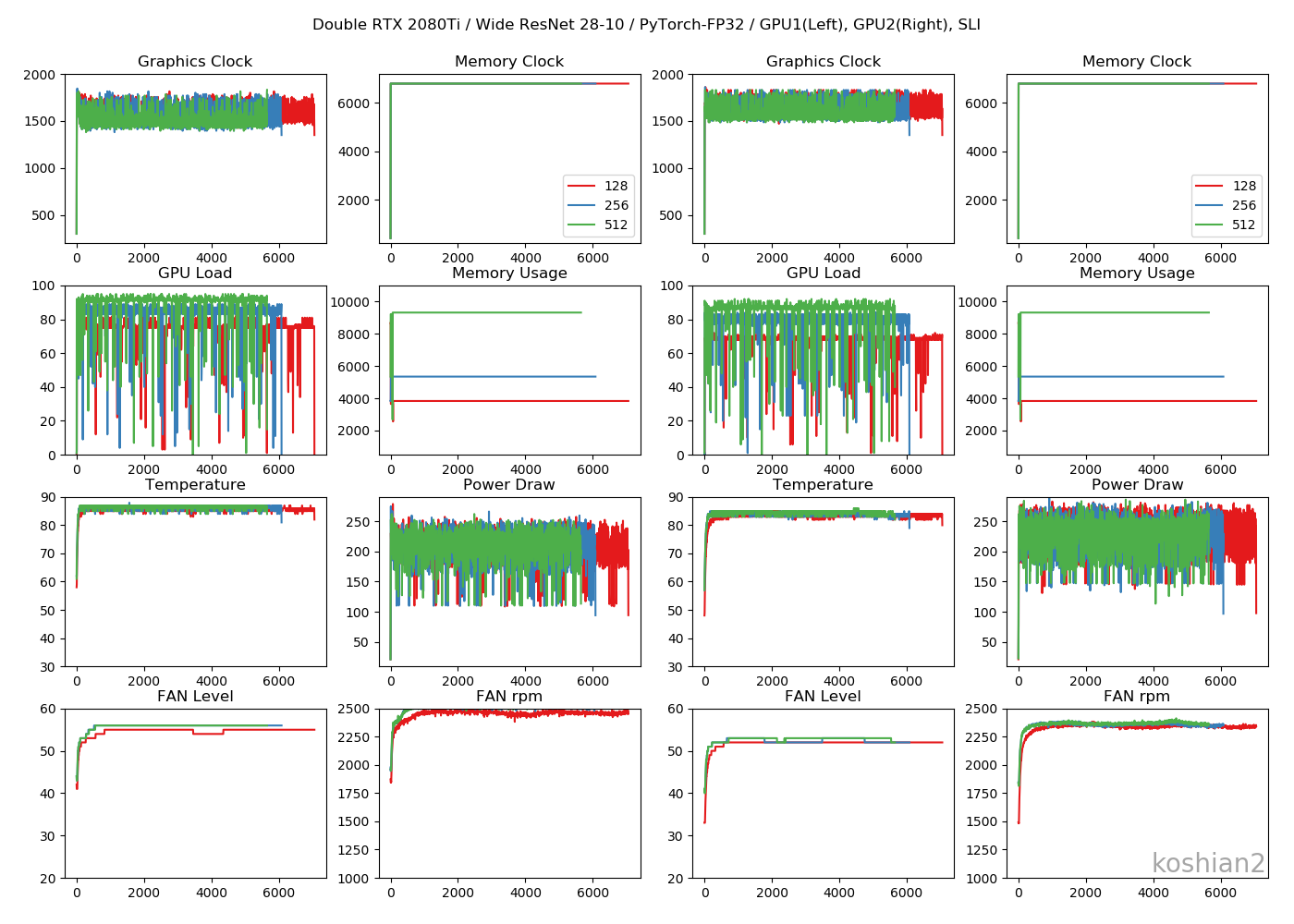
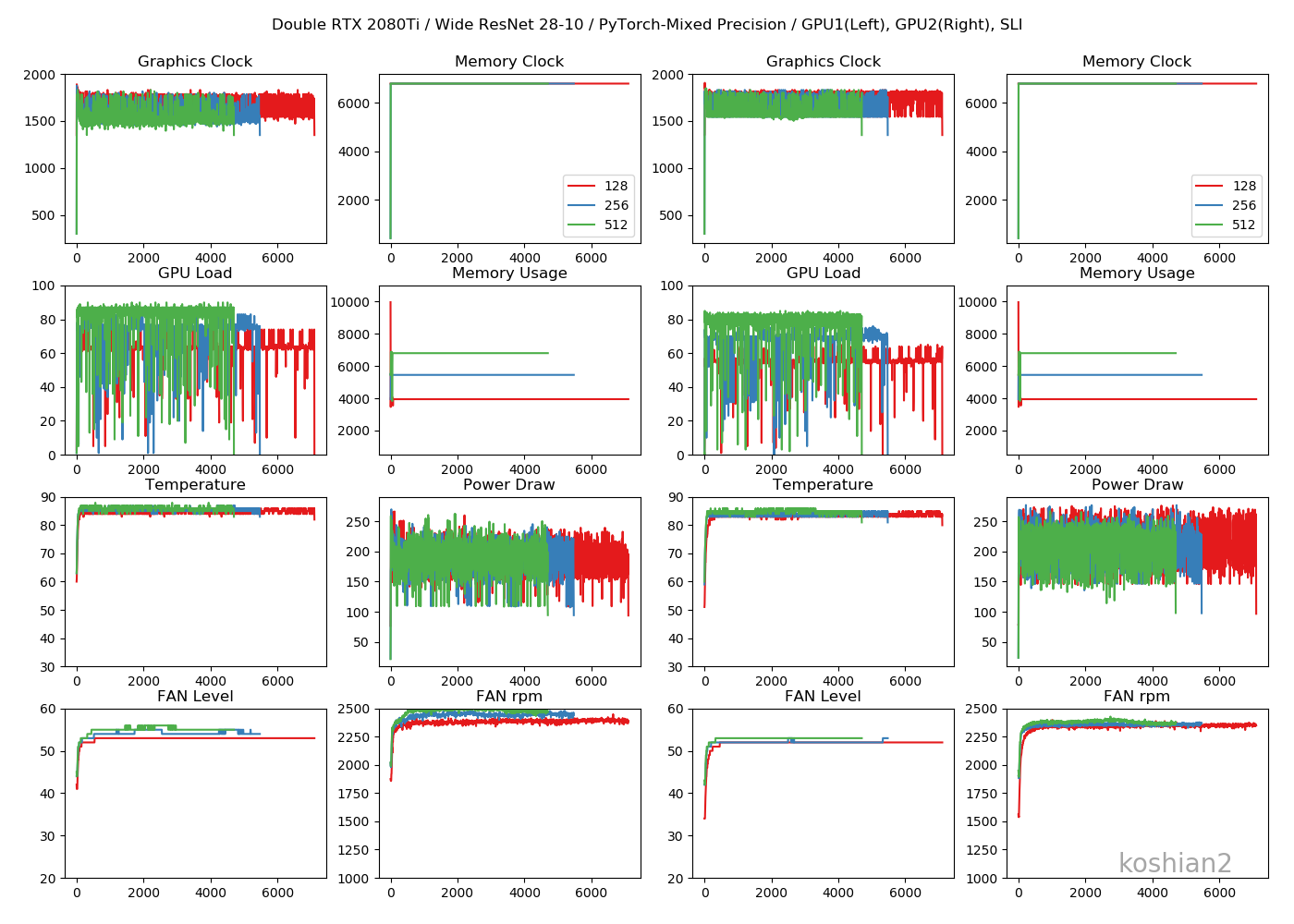
PyTorchのWideResNetかつ2GPUのログを、FP32、Mixed Precision、FP16で見てみます
FP32
Mixed Precision
FP16

考察
- グラフィッククロックはFP16≧Mixed Precision>>FP32。FP16寄りのほうが高い周波数を出しやすい
- GPUロードはFP32>>Mixed Precision≧FP16。バッチサイズが小さいFP16はまだロードに余裕があるので、これを100%に近づけられればもっと速度は出るはず。WRNでもバッチサイズが大きいほど改善率が高いのはこういう理由かと。
- GPUのメモリ消費はFP32>Mixed Precision>FP16。これは当たり前。
- 消費電力はFP32>Mixed Precision≧FP16だが、正直誤差の範囲内にしか見えないので、消費電力を下げる目的でMixed PrecisionやFP16を使うのはあまり好ましくなさそう。
- ファンレベルやファンの回転数はGPUロードに比例して、FP32のほうが高い回転を出している
特筆すべきメリットはメモリ消費量の削減でしょうね。メモリがOOMになってしまってバッチサイズを上げられないというのはよくあるケースなので、そこに効くのは嬉しいです。
まとめ
- PyTorchで比較した結果、速度面ではFP32と比較して、Mixed Precisionは最大25%、FP16は30-35%の高速化だった。ただし、バッチサイズが小さすぎるとMixed Precisionによる恩恵を受けられないことがある。
- 精度面では、Mixed PrecisionはFP32とほぼ変わらず、FP16は良くて0.5-1%のマイナス・ひどいと数十%のマイナスだった。FP16は大きいバッチサイズで精度が急降下する。
- ハードウェア面での大きなメリットはGPUメモリ消費の削減。他にもGPUロードに余裕を出しやすい等がある。
試してみた感想ですが、意外とGPUのチューニングが辛くて、一筋縄にはいかないなという印象でした。この記事では、2080Ti vs Colab TPUという形で書いていますが、総合して考えると、画像分類のような単純なケースではTPUのほうが勝っているのではないかなという感想でした。FP16/32のNan対策の切り替えが闇すぎるので、Nanを引き起こさないように指数部分をFP32の桁数を維持し、専用の型で定義したTPUのbfloat16(FP16の代用として使いますが)のほうがよりわかりやすくてシンプルです。反面ApexのようなFP16/32をホワイトリスト・ブラックリストで切り替えしているのでは、新しい研究が出てきたときに、リストの更新が追いつかなく全く太刀打ちができません。この点はGoogleの完勝だと思います。
ただし、TPUでは現状できるモデルが限定されているので、モデルの小回りが効くという点ではGPUが勝っている点があります。このような単純な画像分類ではない、複雑なモデルのコーディングでは、やはりGPUのほうが簡単です。「将来性のTPU、安定性のGPU」という感じです。そこらへんを総合的に考えると、2080Ti vs Colab TPUというのは65:35~55:45ぐらいで若干TPUのほうに軍配が上がるのではないかなと思います。TPUでハイパラを探して最後の本番はGPUのFP32でやるとかも全然ありだと思います。
逆に言えば、現時点で最新のGPUである2080Ti(1個15万円ぐらいします)に対して一泡吹かせられるようなデバイス、TPUをColabで無料で使用できるのですから、これを使わない手はありません。皆さんどんどんTPUを使っていきましょう。他にもGPUを「こうすると速くなるよ」みたいなケースがあればぜひ教えてください。
コード
全部まとめてこちら
https://gist.github.com/koshian2/20e613b9c81e3a62919e2f8a160d8906
お知らせ
技術書典6で頒布したモザイク本の通販を下記URLで行っています。会場にこられなかったけど欲しいという方は、ぜひご利用ください。
『DeepCreamPyで学ぶモザイク除去』通販
https://note.mu/koshian2/n/naa60d5c9ebba
ディープラーニングや機械学習における画像処理の基本や応用を学びながら、モザイク除去技術DeepCreamPyを使いこなし、自分で実装するまでを目指す解説書です(TPUの実装中心に書いています)。