TensorFlow/Kerasのデフォルトはchannels_lastですが、channels_firstに変更するとGPUの訓練が少し速くなるというのをRTX2080Tiで実際に計測してみました。
前回までの記事
対決!RTX 2080Ti SLI vs Google Colab TPU ~Keras編~
きっかけ
前回の記事を書いたら、Twitter上で「channels_first」にすると速くなるよ!と指摘をいただいたので、確かめてみました。
最初、自分は「TensorFlowのデフォルトはChannels lastだからそんなの逆に遅くなるでしょ」と疑ってしまって、申し訳ないことしてしまったなと反省しています。結果は、確かに速くなりました。少しでもTensorFlowの速度を上げたいときに使えるテクニックではないかと思います。指摘をしてくださった長谷川はしびろこうさんありがとうございました。
公式ドキュメントでは
cuDNNを使いNVIDIAのGPUで訓練する際は、channels_firstにするのが最適であることが明言されています。
Within TensorFlow there are two naming conventions representing the two most common data formats:
NCHWor channels_firstNHWCor channels_last
NHWCis the TensorFlow default andNCHWis the optimal format to use when training on NVIDIA GPUs using cuDNN.
N, C, H, Wは次の英語に対応します。
- N : the Number of images in batch(ミニバッチの画像数)
- C : Channel(チャンネル)
- H : Height(高さ)
- W : Width(幅)
NHWC, NCHWというのはこれらの順番を表します。つまり、チャンネルが2番目にくるのがchannels_first、チャンネルが4番目にくるのがchannels_lastというわけです。PyTorch、Chainerなどのフレームワークはchannels_firstです。TensorFlowや、TensorFlowバックエンドはKerasはデフォルトでchannels_lastです。ただし、TensorFlowバックエンドではないKerasではchannel_firstとして使うこともあります(MXNetバックエンドなど)。TensorFlowバックエンドでも、KerasのAPIを使えばchannels_firstとして簡単に書くことができるので1、今回はそれを試してみます。
TensorFlowでのChannels firstへの切り替え方
全体のコードは末尾にあります。ポイントのみ解説します。
データはnp.transposeなどで軸を入れ替える
keras.datasetsで読めるデータはchannels_lastで定義されているので、NHWCがNCHWになるように変更します。
(X_train, y_train), (X_test, y_test) = keras.datasets.cifar10.load_data()
X_train, X_test = X_train/255.0, X_test/255.0
X_train, X_test = np.transpose(X_train, [0, 3, 1, 2]), np.transpose(X_test, [0, 3, 1, 2])
Conv2D, Poolingなどはdata_format="channels_first"を指定
Channelが2番目にあるか4番目にあるかで処理が異なるようなレイヤー(Conv2DやMax/Average/Global Average Pooling)などは**data_format="channels_first"**の引数を指定します。
from tensorflow.keras import layers
x = inputs
x = layers.Conv2D(ch, 3, padding="same", data_format="channels_first")(x)
x = layers.AveragePooling2D(2, data_format="channels_first")(x)
x = layers.GlobalAveragePooling2D(data_format="channels_first")(x)
Global Average Poolingは忘れやすいので注意(自分は忘れて調べ直しになりました)。
Batch Normalizationでは「axis=1」を指定
Batch Normalizationのデフォルトは、Normalizationする軸がchannels_last向けに「axis=-1」(NHWCだから)になっています。これを「axis=1」と指定します。
x = layers.BatchNormalization(axis=1)(x)
想定通りの実装になっているかは、model.summary()で確認するのをおすすめします。
ハードウェアスペック
- GPU : RTX 2080Ti 11GB Manli製×2 SLI構成
- CPU : Core i9-9900K
- メモリ : DDR4-2666 64GB
- CUDA : 10.0
- cuDNN : 7.5.1
- TensorFlow : 1.13.1
前回と同じです。「ELSA GPU Monitor」を使って、GPUのロードや消費電力をモニタリングします(5秒ごとCSV出力)。
GPUの場合は、GPU1枚使う場合(そのまま訓練させる場合)、マルチGPUに対応させる場合(model = keras.utils.multi_gpu_model(model, gpus=2))の両方計測します。
channels_lastとchannels_firstの比較(結果)
channels_lastとchannels_firsのトータルの訓練時間、精度を比較します。
1GPU、10層CNN
L=Channels Last(前回の結果)、F=Channels First(今回の結果)を示します。
| バッチ | L訓練時間 | L精度 | F訓練時間 | F精度 | 時間比 |
|---|---|---|---|---|---|
| 128 | 0:19:34 | 0.8960 | 0:17:50 | 0.8929 | 91.2% |
| 256 | 0:18:32 | 0.8940 | 0:17:04 | 0.8919 | 92.1% |
| 512 | 0:17:44 | 0.8849 | 0:16:12 | 0.8850 | 91.3% |
| 1024 | 0:17:20 | 0.8597 | 0:15:52 | 0.8726 | 91.5% |
時間比で10%弱の高速化になりました。精度は差はないと言っていいでしょう。
1GPU、WRN28-10
| バッチ | L訓練時間 | L精度 | F訓練時間 | F精度 | 時間比 |
|---|---|---|---|---|---|
| 128 | 3:10:21 | 0.8416 | 3:01:00 | 0.815 | 95.1% |
こちらは5%弱の高速化となりました。係数が多い高価なモデルでは、畳み込みの計算量が支配的であるため、Channels Firstによる恩恵は小さいと言えるでしょう。
2GPU、10層CNN
Kerasのmulti_gpu_modelを使い、データパラレル方式の複数GPU化をします。
| バッチ | L訓練時間 | L精度 | F訓練時間 | F精度 | 時間比 |
|---|---|---|---|---|---|
| 128 | 0:23:47 | 0.9003 | 0:21:36 | 0.8948 | 90.8% |
| 256 | 0:18:53 | 0.8926 | 0:18:35 | 0.8908 | 98.4% |
| 512 | 0:17:41 | 0.8853 | 0:16:24 | 0.8869 | 92.7% |
| 1024 | 0:17:17 | 0.8541 | 0:15:23 | 0.8753 | 89.0% |
| 2048 | 0:15:08 | 0.8457 | 0:13:39 | 0.8341 | 90.3% |
Channels Lastの場合と比較すると1GPUと同様に10%弱速くなっていますが、相変わらず1GPUのときよりは遅いという現象は変わりありません。バッチサイズ1024のときのみ1GPUよりわずかに速くなっている程度です。1GPUのときのバッチサイズ2048はOOMになりました。
2GPU、WRN28-10
| バッチ | L訓練時間 | L精度 | F訓練時間 | F精度 | 時間比 |
|---|---|---|---|---|---|
| 128 | 3:44:47 | 0.8257 | 3:37:40 | 0.8334 | 96.8% |
| 256 | 3:36:33 | 0.8165 | 3:25:30 | 0.8314 | 94.9% |
WideResNetでも同様の結果となりました。1GPUのときのバッチサイズ256はOOMになりました。
TensorFlow/Kerasでchannels_firstにしたときのGPUログ
1GPU、10層CNN
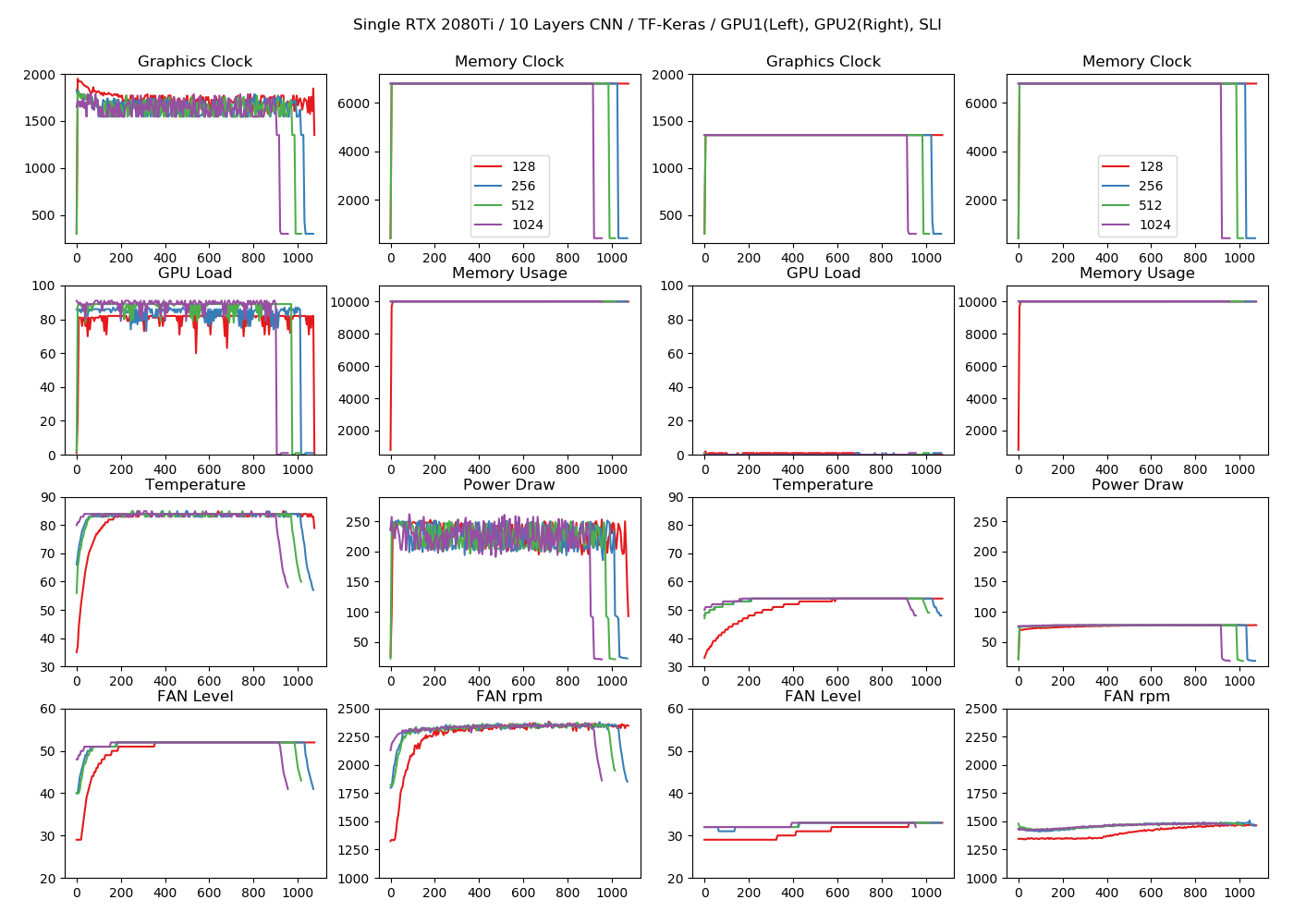
今回から訓練の終わりに1分のクールダウンを入れたので末端の大きく下がっているところは、Channels Firstによる影響ではありません。またこのクールダウンによる高速化の影響は軽微です(すぐ85℃近くになってしまうため)。
1GPU、WRN28-10
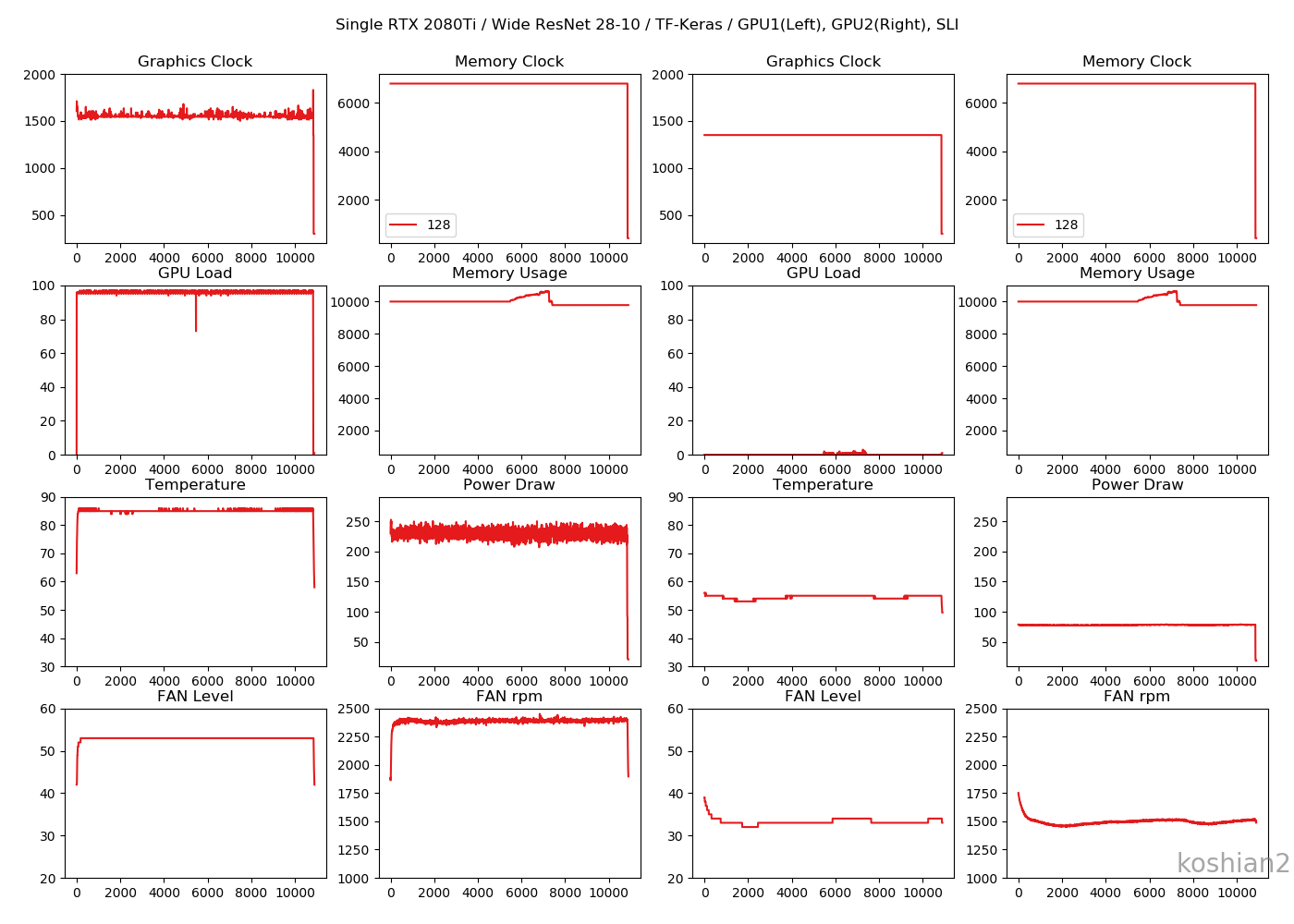
ニューラルネットワークの大小にかかわらず、相変わらずMAXまでメモリを確保しに行っているのがちょっと奇妙。
2GPU、10層CNN
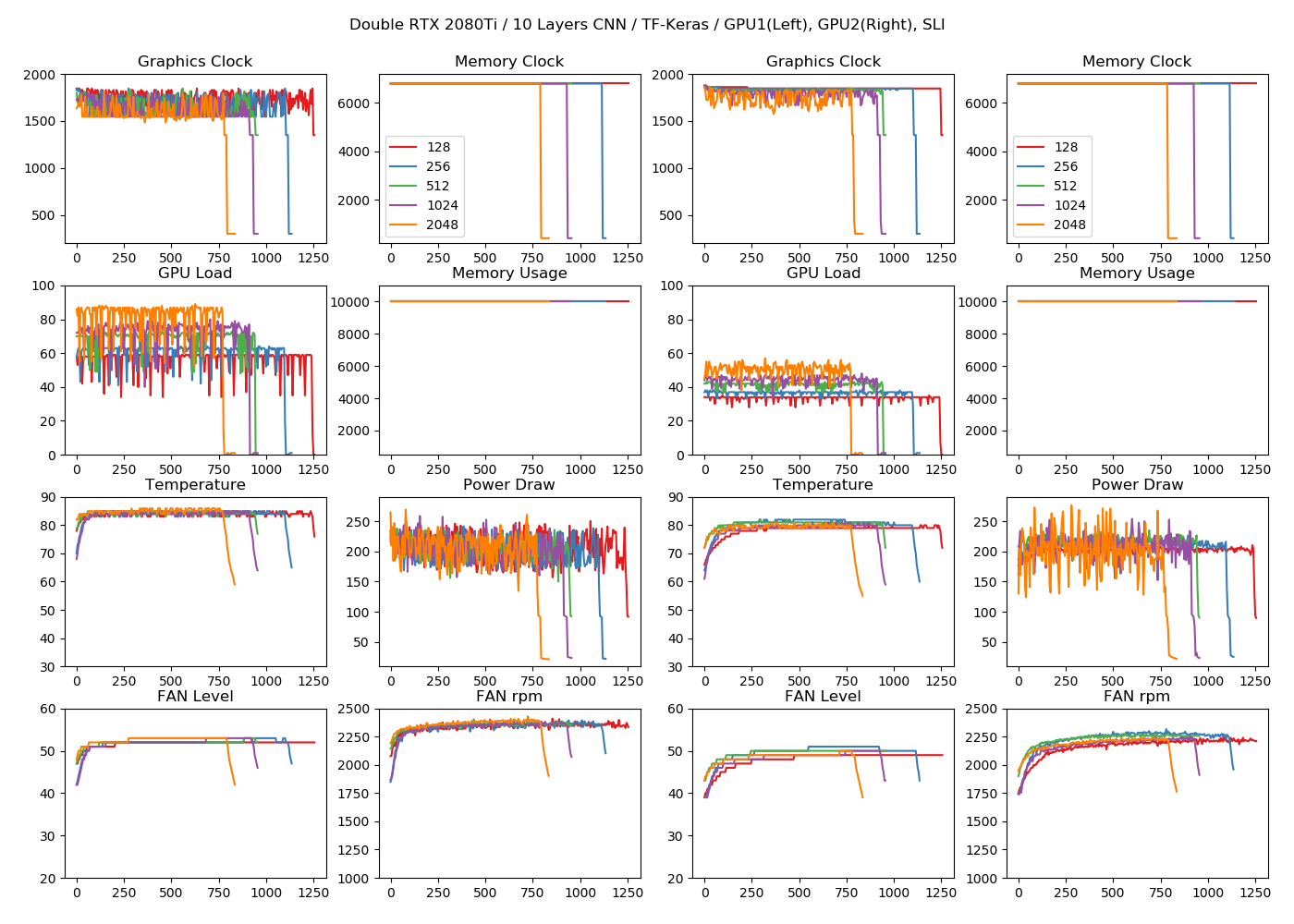
2GPU、WRN28-10
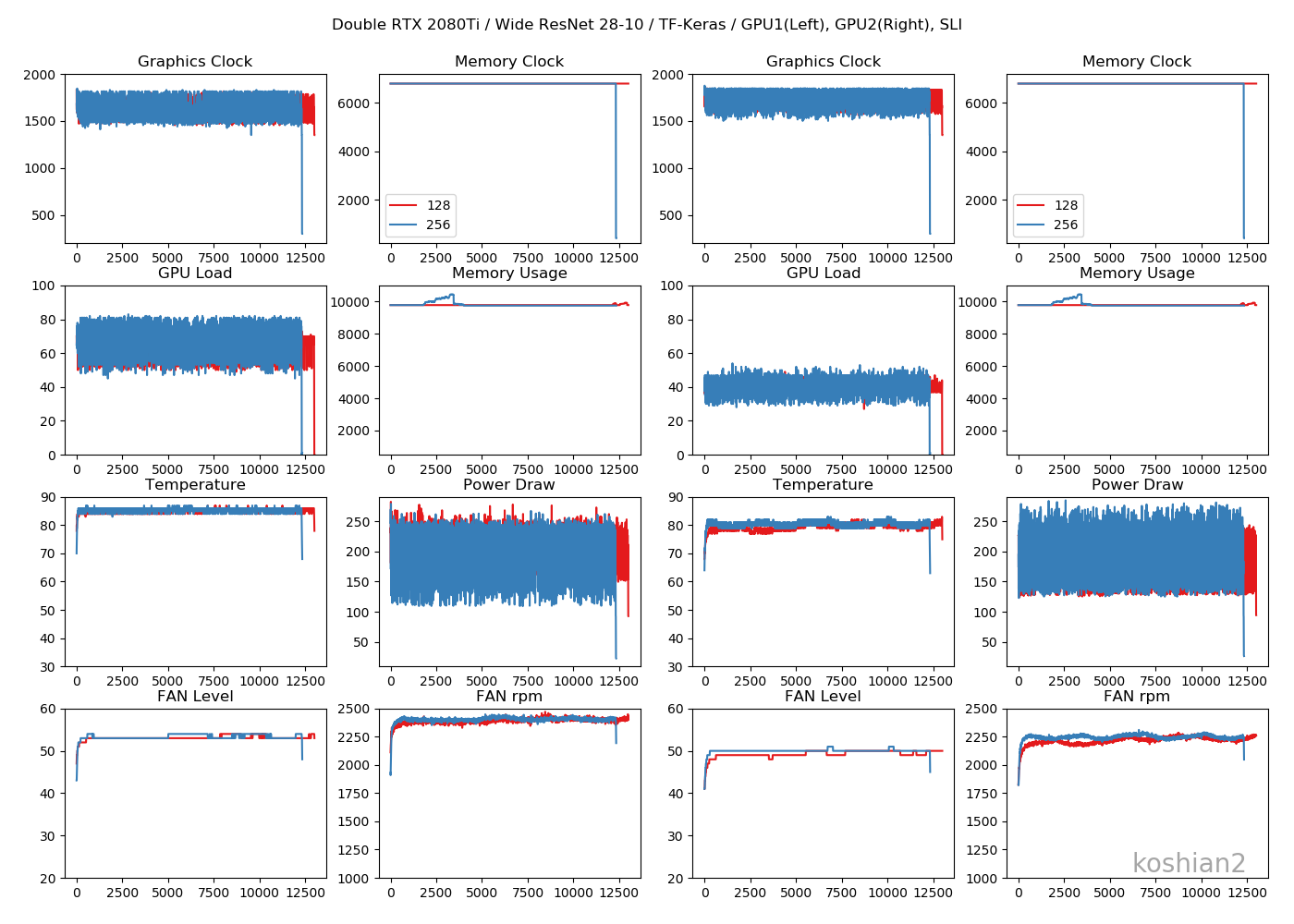
特にChannels Firstにしたからといって、GPUのログが変わるということはなかったです。
まとめ
- TensorFlow/Kerasでchannels_firstにするとGPUによる訓練が数%~10%程度高速化される。
- 複数GPU使ったときに逆に遅くなる現象は解決されなかった(ちなみにPyTorchだと解決されました)
Channels Firstにすると、TPUの訓練も高速化されるという記事もあるので、TensorFlowを使ったGPU最適化は不十分かもしれません。ぶっちゃけちゃうと、GPUを本当に高速化させたいんだったらPyTorchを使うべきです。しかし、2019年5月現在ではまだPyTorchはTPU対応していないので、TPUの最適化のときには使える議論ではないかと思います。
PyTorchを使ったGPUの訓練の高速化はまた次回書きたいと思います。
コード
-
歴史的にはKerasがあり、KerasがTensorFlowに吸収されて、TensorFlowのKerasがあります。KerasはもともとTensorFlowやCNTKなど異なるフレームワークを同一のAPIを通じてコーディングすることを目的として作られたもので、吸収前のKerasにとってTensorFlowはバックエンドの1つでしかありませんでした。しかし、吸収後のKerasはTensorFlowのAPIとなったために、TensorFlowとKerasは1つのバックエンドを越えた密接な関係になりました。そのAPIを通じてchannels first/lastを簡単に切り替えることができます。 ↩