RTX 2080Tiを2枚買ったので、どれぐらいの性能が出るかColabのTPUと対決させてみました。さすがにRTX 2080Tiを2枚ならTPU相手に勝てると思っていましたが、意外な結果になりました。
スペック
GPU側
- GPU : RTX 2080Ti 11GB Manli製×2 SLI構成
- CPU : Core i9-9900K
- メモリ : DDR4-2666 64GB
- CUDA : 10.0
- cuDNN : 7.5.1
- TensorFlow : 1.13.1
GPUだけで30万円以上はします。2019年5月現在、ディープラーニングの環境構成としては相当強い部類です。GPUは1個250Wなので、GPU2枚をフルに動かしただけで500W近い電力消費が加算されます。
GPUの場合は、「ELSA GPU Monitor」を使って、GPUのロードや消費電力をモニタリングします(5秒ごとCSV出力)。
GPUの場合は、GPU1枚使う場合(そのまま訓練させる場合)、マルチGPUに対応させる場合(model = keras.utils.multi_gpu_model(model, gpus=2))の両方計測します。
TPU側
- TPU:TPUv2
- CPU : Xeon @ 2.30GHz x 2(型番不明)
- メモリ:13GB RAM
- TensorFlow : 1.13.1
Google Colaboratoryで使える無料のTPUです。TPUの電力消費はGoogleが負担してくれるので、使用側はただブラウザをつけているだけの電気代で済みます。デバイス自体のTPUの消費電力は40Wだそうです。
TPUv2の公称スペックは180TFLopsですが、FP32での数値ではない(内部的にはbfloat16)ので注意が必要です。また、データの転送やその他のボトルネックがあると、GPUよりも公称性能通りにはならないことが多いです。公称の180TFlopsを出すにはかなり条件を限定しないといけません。通信速度の「最大○○Mbps」程度に割り引いて考えておくと期待外れがないかもしれません。
勝負条件
CIFAR-10の分類。畳み込みニューラルネットワーク(CNN)。2種類のニューラルネットワークと、異なるバッチサイズで処理時間を比較します。
ニューラルネットワークの条件
10層CNN
VGGライクのConvが9層+FCが1層の10層構造です。パラメーター数は1.9Mと小型なモデルです。
| 解像度 | チャンネル数 | カーネル | 繰り返し |
|---|---|---|---|
| 32x32 | 64 | 3 | 3 |
| 16x16 | 128 | 3 | 3 |
| 8x8 | 256 | 3 | 3 |
WideResNet 28-10
WideResNet 28-10(もどき)です。パラメーター数は36.5Mと大型なモデルです。10層CNNよりも、デバイスの計算能力が支配的になります。
ただここで扱うのは時間短縮のために条件をいい加減にしているので、WRN本来の精度は出ません。あくまで訓練時間を求めるためのものと思ってください。
学習率について
どちらのネットワークでもバッチサイズ128で学習率0.1のモメンタム(モメンタム係数は0.9)を基準とします。そして、Google BrainのDon't Decay the Learning Rate, Increase the Batch Sizeの論文の結論を用いて、バッチサイズと初期学習率を比例させます。例えば、バッチサイズ512なら、バッチサイズが4倍になっているので、初期学習率は0.4になります。
100エポック訓練させ、50エポックと80エポックで学習率をそれぞれ1/10にします。WRNは本来の精度が出る設定ではないので参考にしないでください。
バッチサイズの条件
バッチサイズを、128, 256, 512, 1024, 2048と変化させます。GPUではOOM(Out of Memory)となるケースも存在しますがそのまま進めます。
GPU 1枚の場合の結果
10層CNN
| バッチ | 1エポック[s] | 2~中央値[s] | 訓練時間 | 精度 |
|---|---|---|---|---|
| 128 | 18.69 | 11.68 | 0:19:34 | 0.8960 |
| 256 | 12.92 | 11.10 | 0:18:32 | 0.8940 |
| 512 | 13.45 | 10.64 | 0:17:44 | 0.8849 |
| 1024 | 15.33 | 10.35 | 0:17:20 | 0.8597 |
| ※バッチサイズ2048はOOM(Out Of Memory) |
GPUでも最初の1エポックは若干時間がかかります。2エポック目以降は、時間が短くなりそれぞれ10~11秒/エポックで訓練できています。10層CNNの精度はこんなものです。
初期のバッチサイズを増やすと時間は短くなります。これは、ミニバッチの切り替わりや転送によるオーバーヘッドが少なくなるからです。ただし、バッチサイズを上げすぎると精度が落ちます。これはDon't Decay~の論文の結論の通りなので、そういうものと思ってください。
ではGPUのログを見てみましょう。こういったログが見れるのはローカルGPU特有の面白さですよね。左側が1枚目のGPU、右側が2枚目のGPUです。
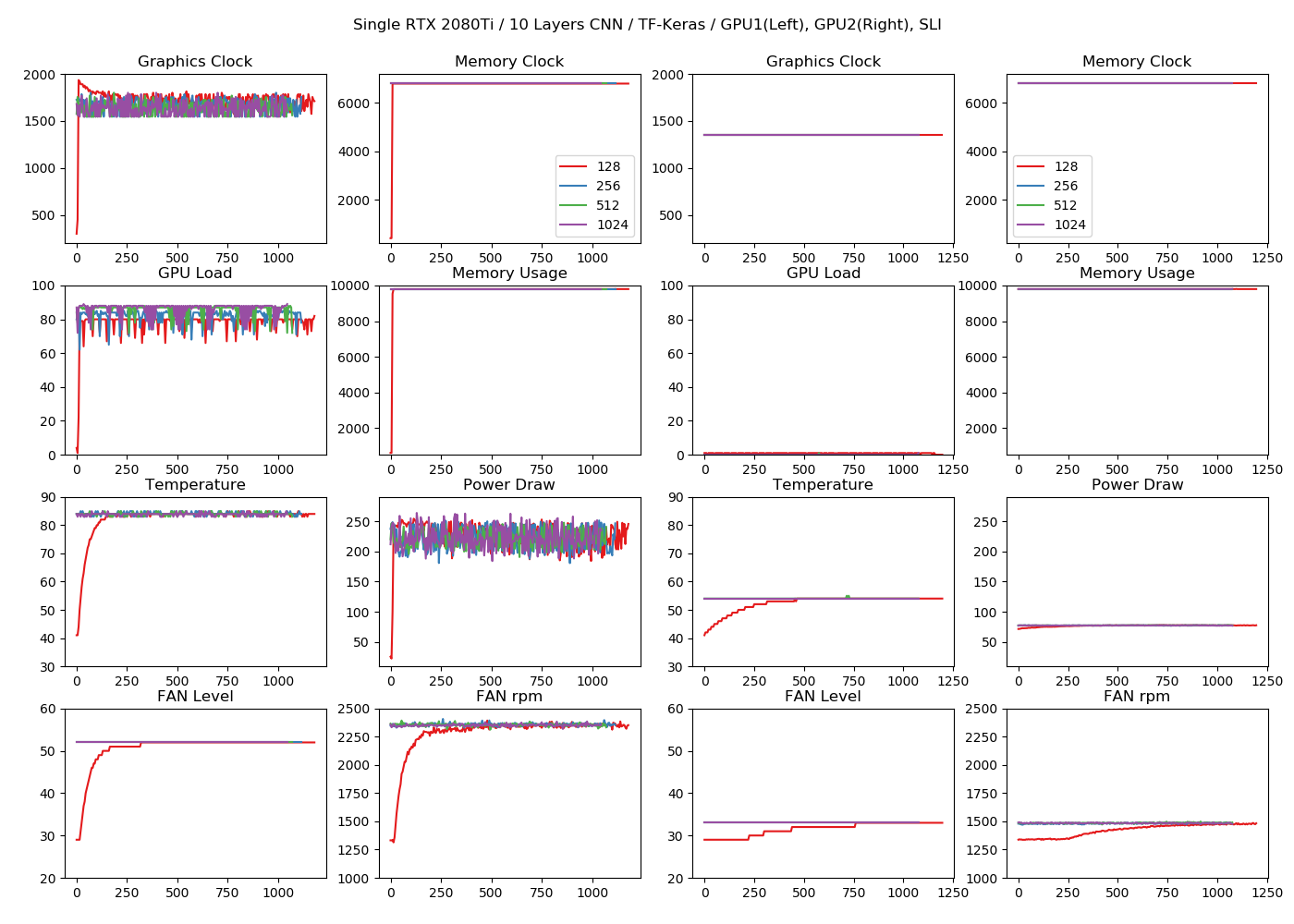
個々の項目を見ていきましょう。Graphics ClockはRTX 2080Tiのクロックが1350MHz, ブーストクロックが1545MHzなので、1枚目のGPUはブーストクロックかそれ以上の周波数が出ているのがわかります。2枚目のGPUはベースクロックの1350MHzで安定しているのがわかります。アイドル時はもっと低い(300MHz程度)なので、これはSLIの影響かもしれません。
Memory Clockは1枚目も2枚目も6800MHzで安定します。これはバッチサイズによりません。
GPU Loadの項目が面白いです。GPU1枚でも、バッチサイズ128だとGPUロードが70~80%でまだ遊びがあるのがわかります。バッチサイズを大きくするとGPUロードが90%近くなるので、効率よく計算されているのが確認できます。逆に、なぜバッチサイズが少ないとGPUが遊んでしまうのかというと、データの転送やバッチの切り替えにオーバーヘッドがあるからです。バッチサイズを上げるほど演算効率がよくなるというのはGPU/TPU共通です(TPUのほうが顕著です)。2枚目のGPUは演算をやっていないので、GPUロードは0%で安定しています。でも、2枚目でもメモリを確保しに行ってるのは謎。
Memory Usageは訓練が始まると10GB程度のGPUメモリを確保しに行きます。確保するメモリの量はデフォルトのままですが、実際に使っている量はもっと少ないでしょう。ただし、バッチサイズ2048だとOOMになるので、1024ぐらいだといい感じに使っているのかもしれません。
TemperatureはGPUの温度です。ロードしている1枚目は85度ぐらいになっています。部屋の気温が上がっているのが体感でわかるレベルでした。温度が上がりすぎることによるパワーリミットが動いているかは、かなり微妙なラインですが、Fan Levelや回転数、Clockを見ると多分まだ大丈夫ではないかと思います(詳しくないんで確証なし)。ちなみに、ロードが周期的にがくんと落ちているところはエポックの切り替わりです。2枚目のGPUはロード発生していないですが、ベースとメモリのクロックが上がっている影響で、55度ぐらいになっています。
Power Drawは消費電力です。1枚目は200~250W、2枚目は70~80W消費しているのがわかります。RTX 2080TiをSLIで動かすと、1枚だけ使っても訓練時に実測で270~330Wの電力消費がプラスされることがわかります(モニターやCPUなどの電源は加味していないので実際の消費電力はもっと多いです)。
WRN 28-10
| バッチ | 1エポック[s] | 2~中央値[s] | 訓練時間 | 精度 |
|---|---|---|---|---|
| 128 | 121.90 | 114.04 | 3:10:21 | 0.8416 |
| ※バッチサイズ256以降はOOM |
ちょっとWRNとしては精度が低すぎますが、自分の設定がガバガバなだけでGPUやTensorFlowが悪いというわけではないと思います。訓練時間は100エポックで3時間オーバー。だいぶ長いですね。
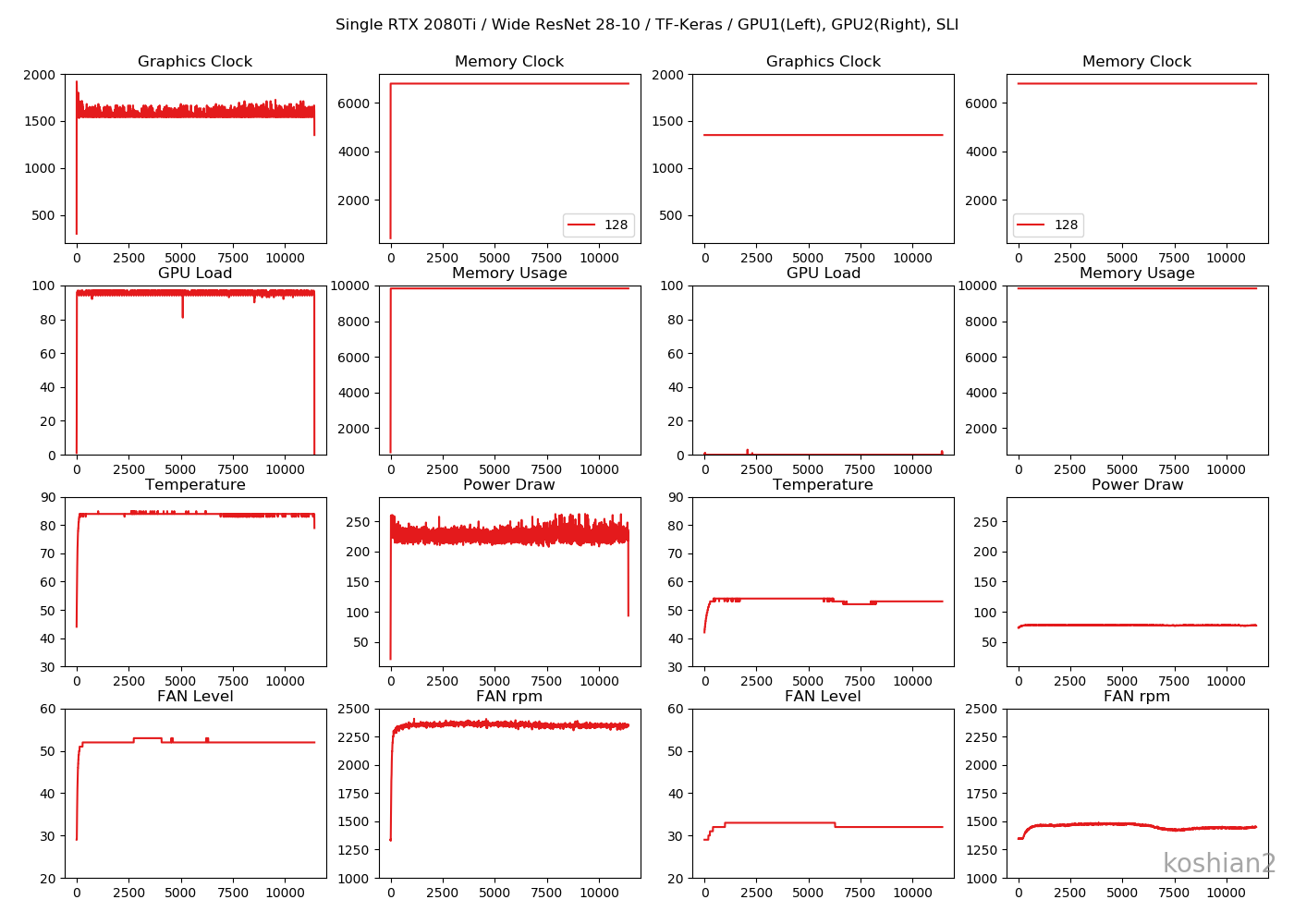
WRNは係数が35Mもある巨大なネットワークなので、畳み込み計算が支配的になり、バッチサイズ128でもGPUロードが100%近くになってくれます。10層CNNより若干クロックが下振れしているので、もしかしたら排熱の問題が出ているかもしれませんが、ブーストクロックの近傍でグラフィッククロックが推移しています。
仕様上の消費電力は250Wですが、瞬間的にはGPU1個で300W近く食っているので、特にブレーカーでぎりぎりの容量はきついかもしれません。
GPU 2枚の場合の結果
次に、multi_gpu_modelの関数を使い、複数GPU対応のモデルに変換してから使います。
10層CNN
| バッチ | 1エポック[s] | 2~中央値[s] | 訓練時間 | 精度 |
|---|---|---|---|---|
| 128 | 20.01 | 14.22 | 0:23:47 | 0.9003 |
| 256 | 13.69 | 11.27 | 0:18:53 | 0.8926 |
| 512 | 13.96 | 10.59 | 0:17:41 | 0.8853 |
| 1024 | 15.07 | 10.33 | 0:17:17 | 0.8541 |
| 2048 | 13.65 | 9.03 | 0:15:08 | 0.8457 |
実はGPU1枚からそれほど速くなっていません。むしろ遅くなっている可能性すらあります。1枚と2枚の訓練時間を比較してみましょう。
| バッチ | GPU 1枚 | GPU 2枚 |
|---|---|---|
| 128 | 0:19:34 | 0:23:47 |
| 256 | 0:18:32 | 0:18:53 |
| 512 | 0:17:44 | 0:17:41 |
| 1024 | 0:17:20 | 0:17:17 |
| 2048 | OOM | 0:15:08 |
ほとんど速くなってない!? 1枚のときにSLIの効果があって、2枚目ではほとんど効果がなかったのかもしれませんが、2枚目の効果はバッチサイズを上げられるという容量上の効果がメインでした。
不思議なのは、multi_gpu_modelで変換した場合では、2枚目のロードもちゃんと上がっているにもかかわらず、遅くなっているということなんですよね。
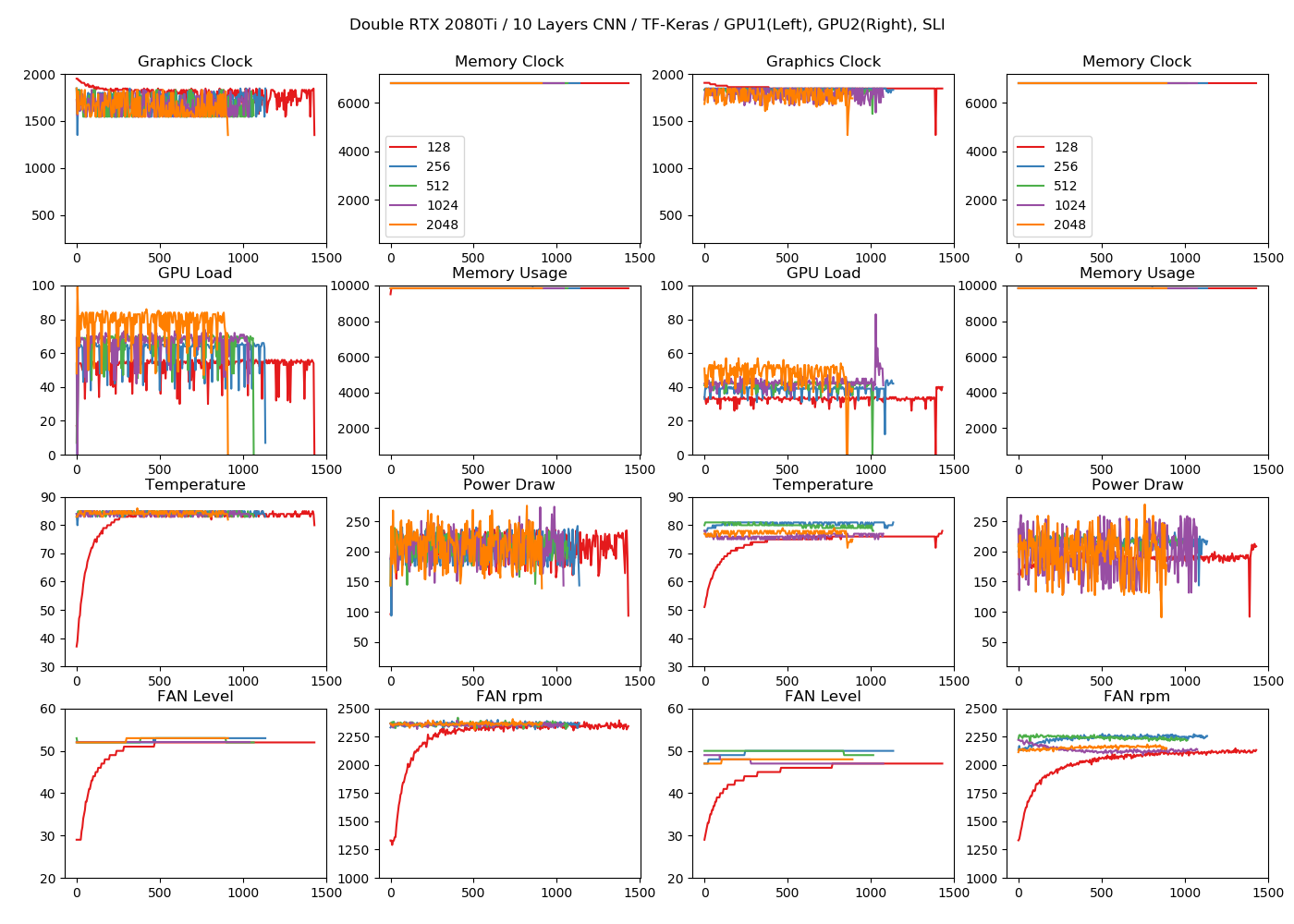
1枚目のロードは若干減りましたが(20~30%程度)、その分2枚目のロードが30~60%発生しており、2枚目も演算に参加しているのがわかります。しかし、モデルが軽すぎるのか、あるいはGPU間のデータ転送や同期でボトルネックが発生しているのか(これはよく聞く話なので有り得そう)、排熱面でまだ余裕がある2枚目のロードが1枚目より上がらないという現象が確認されました。
にもかかわらず、2枚目の電力はきっちり1枚目と同じぐらい消費しているので(300~500W)、大して速くならないのに消費電力だけ増えるという割と最悪な状態になっている可能性はあります。もし、速度が出ないのが転送や同期のボトルネックによるものなら、もしかするとmulti_gpu_modelを使って1つのモデルを複数GPU対応させるデータ並列化ではなく、別々のモデルを個々のGPUに展開するデバイス並列化(公式ドキュメントより)のほうが効果が高いかもしれません。2つのモデルを同時に訓練する場合に有効でしょう。
WRN 28-10
| バッチ | 1エポック[s] | 2~中央値[s] | 訓練時間 | 精度 |
|---|---|---|---|---|
| 128 | 144.09 | 134.79 | 3:44:47 | 0.8257 |
| 256 | 138.26 | 129.92 | 3:36:33 | 0.8165 |
2枚使うと1枚のときはOOMになってしまったバッチサイズ256の訓練に成功しました。データ並列化なので、訓練できるバッチサイズが2倍になったということでしょう。
しかし、トータルでの時間はGPU1枚のときは3:10:21だったので、2枚のほうがかえって遅くなっているということがわかります。
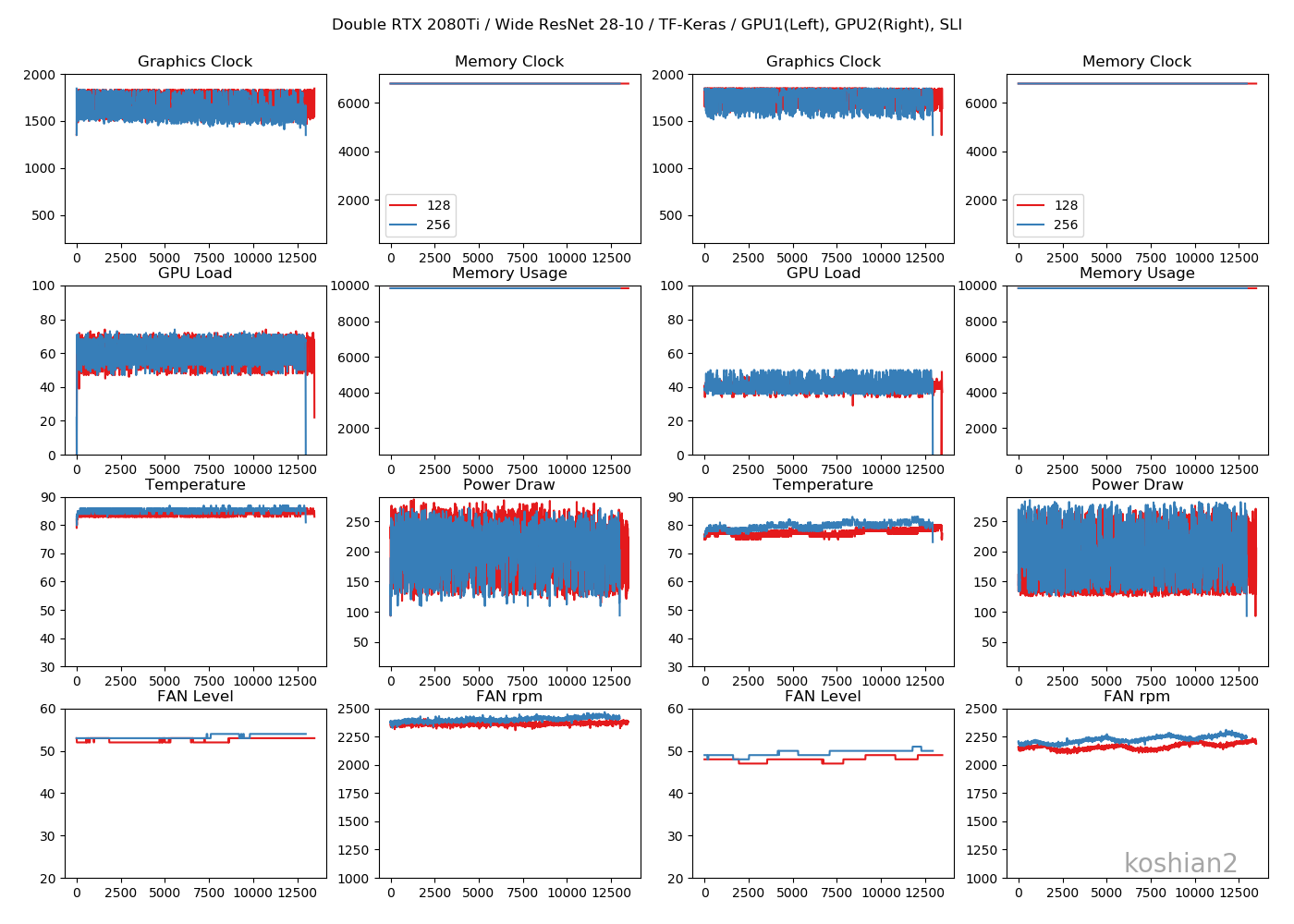
GPUのログを見てみると、ロードの振れ幅が相当あります。もしかすると、排熱問題が出ているのかもしれません。1枚のときは100%近くまで上がったロードが、60%+40%と中途半端な感じになってしまいました。排熱が原因なのか、データの同期が原因なのかは自分ではよくわかりませんでした。
GPUの場合は、計算性能よりもGPUメモリのOOMが問題になりやすいのかもしれません。
Colab TPUの場合の結果
では無料のColabTPUの場合はどうでしょう。なかなかエグい結果が出てきました。
10層CNN
| バッチ | 1エポック[s] | 2~中央値[s] | 訓練時間 | 精度 |
|---|---|---|---|---|
| 128 | 54.31 | 9.12 | 0:15:58 | 0.8933 |
| 256 | 53.87 | 7.75 | 0:13:57 | 0.8829 |
| 512 | 57.74 | 7.91 | 0:14:06 | 0.8839 |
| 1024 | 57.99 | 7.45 | 0:13:19 | 0.8729 |
| 2048 | 57.61 | 7.02 | 0:12:31 | 0.8489 |
TPUの場合は、1エポック目にモデルのコンパイルが入り、これが時間かかるので訓練時間が短いと不利になります。しかし、GPUの場合は速くて17分だったので、速度面ではTPUの完勝になりました。
精度面ではどうでしょう?2GPUのケースと比較してみました。
| バッチ | 2GPU時間 | 2GPU精度 | TPU時間 | TPU精度 |
|---|---|---|---|---|
| 128 | 0:23:47 | 0.9003 | 0:15:58 | 0.8933 |
| 256 | 0:18:53 | 0.8926 | 0:13:57 | 0.8829 |
| 512 | 0:17:41 | 0.8853 | 0:14:06 | 0.8839 |
| 1024 | 0:17:17 | 0.8541 | 0:13:19 | 0.8729 |
| 2048 | 0:15:08 | 0.8457 | 0:12:31 | 0.8489 |
128, 256の場合はGPUのほうがいいですが、1024の場合はTPUが良かったりするので、誤差の範囲ではないと思われます。これだけでは試行回数が少ないので、TPU/GPUの精度の差を優劣は議論できないと思います。しかし、逆に言えばTPUを使っても目に見えた精度の落ち方はしない、ということがわかりました。
WRN 28-10
WRNの場合はもっとエグい結果になっています。バッチサイズ2048は大きすぎる関係で精度がガタ落ちしており意味がありません。
| バッチ | 1エポック[s] | 2~中央値[s] | 訓練時間 | 精度 |
|---|---|---|---|---|
| 128 | 217.59 | 29.28 | 0:52:03 | 0.7846 |
| 256 | 223.53 | 25.11 | 0:45:13 | 0.8047 |
| 512 | 241.29 | 23.11 | 0:42:15 | 0.8023 |
| 1024 | 220.91 | 20.99 | 0:38:29 | 0.7365 |
| 2048 | 220.55 | 20.45 | 0:37:33 | 0.1758 |
GPUのときは3時間~3時間半かかってましたよね?? WRNの2GPUはうまく行かなかったので1GPUと比較します。
| バッチ | 1GPU時間 | 1GPU精度 | TPU時間 | TPU精度 |
|---|---|---|---|---|
| 128 | 3:10:21 | 0.8416 | 0:52:03 | 0.7846 |
| 256 | OOM | OOM | 0:45:13 | 0.8047 |
| 512 | OOM | OOM | 0:42:15 | 0.8023 |
| 1024 | OOM | OOM | 0:38:29 | 0.7365 |
| 2048 | OOM | OOM | 0:37:33 | 0.1758 |
3倍~4倍の差でRTX 2080Tiをぶっちぎってしまいました。無料のTPUが15万円オーバーのGPU相手に速度面で完勝という買った本人が一番見ていて悲しくなってくる展開です。
TPUの精度が低めなのでもしかしたらFP32ではない影響が出ているかもしれませんが、Colab TPUでData Augmentationガンガン入れてWRN97%以上出せたので、TPUによる精度低下はあるのかもしれませんが、個人的にはかなり懐疑的です。
結果
30万円オーバーのRTX 2080Ti SLI(2枚)相手に、無料のColabのTPUが完勝したという結果になった。特に消費電力面でGPUは相当分が悪くて、Colabみたいな感覚で使ってると電気代がやばそう(公式発表だとTPUv2は40W)。
ただし、2080Tiのためにフォローしておくと、まだGPU側は高速化のために切れるカード、その他優秀な点がいろいろあります。
- 2080TiにあるTensorコアを使う。これはTPUと同じ発想でFP16で計算するので大幅にスピードアップが期待できる。そもそもFP32のGPUとTPUが勝負するのがフェアじゃない理論。
- GPUをKerasではなくPyTorchで最適化する。以前自分がColabのGPUで調べたところ、KerasよりもPyTorchのほうが1.5倍から2倍程度速いという結果が出てきた(下図参照)ので、PyTorchを使えばもっと肉薄できるかもしれない。
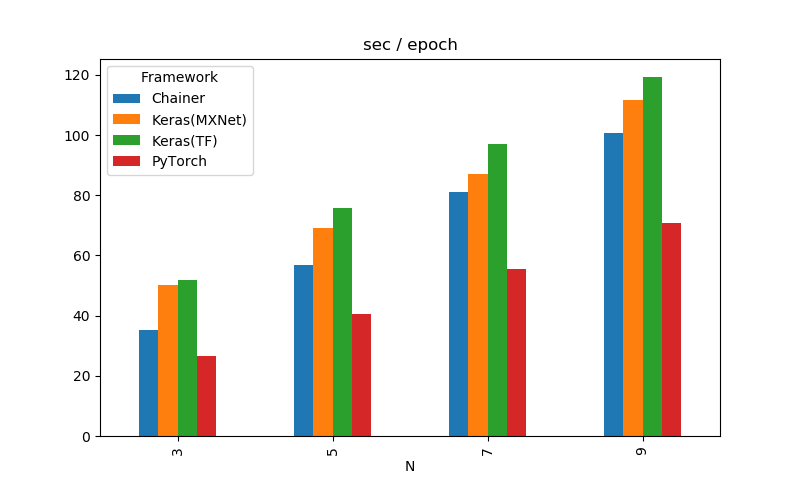
- GPU側はCPUの拡張性というメリットがある。例えば、前処理や画像の読み込みが重いケースでは、CPUの性能やコア数がボトルネックになることが往々にしてある。ColabではなくCloud TPUを使えばCPUの拡張はできるが、無料ではなくなる。
- TPUは同時に2つのモデルを訓練することが厳しい(2019/5現在無理?)ので、特にGANのケースでは、普通に出回っているKerasの書き方では訓練できない。GPUのほうが、複数のモデルを同時に訓練でき自由にコードを書ける。
- TPUはデバイス内の計算が行列計算ぐらいしかできないので、例えば訓練済み係数の読み込んで特徴量を取るようなケースで、GPUのコードのコピペ+変換ではうまくいかないことがある(スタイル変換など)。
- TPUではXGBoostやLightGBMは使えない。
ということでした。今回のようなCIFAR-10を分類して終わりのようなケースではTPUは強いですが、必ずしも汎用性があるというわけではありません。
PyTorchやTensorコアによるGPUの高速化の話は、次回以降やっていきたいと思います。
コード
お知らせ
技術書典6で頒布したモザイク本の通販を下記URLで行っています。会場にこられなかったけど欲しいという方は、ぜひご利用ください。
『DeepCreamPyで学ぶモザイク除去』通販
https://note.mu/koshian2/n/naa60d5c9ebba
ディープラーニングや機械学習における画像処理の基本や応用を学びながら、モザイク除去技術DeepCreamPyを使いこなし、自分で実装するまでを目指す解説書です(TPUの実装中心に書いています)。