RTX 2080Tiを2枚使って頑張ってGPUの訓練を高速化する記事の続きです。TensorFlowでは複数GPU時に訓練が高速化しないという現象がありましたが、PyTorchを使うとRTX 2080Tiでもちゃんと高速化できることを確認できました。これにより、2GPU時はTensorFlowよりも大幅に高速化できることがわかりました。
前回までの記事
ハードウェアスペック
- GPU : RTX 2080Ti 11GB Manli製×2 SLI構成
- CPU : Core i9-9900K
- メモリ : DDR4-2666 64GB
- CUDA : 10.0
- cuDNN : 7.5.1
- PyTorch : 1.1.0
- Torchvision : 0.2.2
前回と同じです。「ELSA GPU Monitor」を使って、GPUのロードや消費電力をモニタリングします(5秒ごとCSV出力)。
結果
10層CNN
10層CNNの詳細は初回の記事を参照してください。縦軸に訓練時間、横軸にバッチサイズを取ったものです。
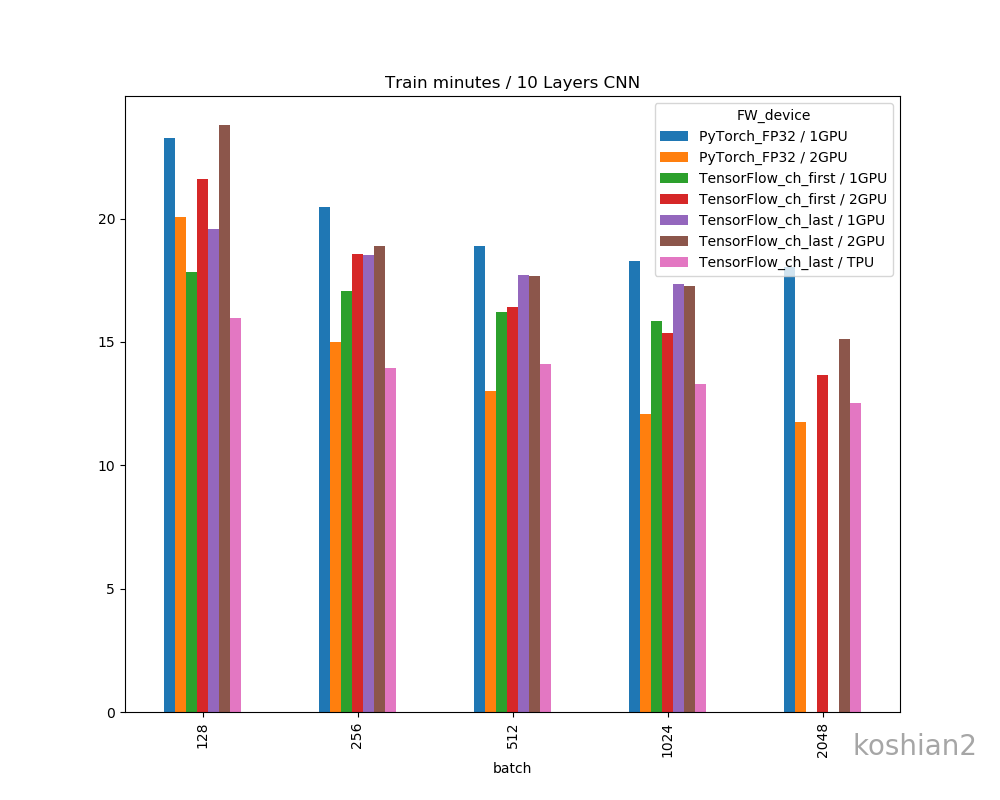
「TensorFlow_ch_first」はこちらで書いたTensorFlowかつchannels_firstとしたケースです。「TensorFlow_ch_last」はchannels_lastのケースで、TensorFlow/Kerasのデフォルトの設定はchannels_lastになります。
「1GPU, 2GPU」はRTX2080Tiの数で、2GPUの場合は、TensorFlowはmulti_gpu_modelを使い、データパラレルとして並列化させています。PyTorchの場合は、
if use_device == "multigpu":
model = torch.nn.DataParallel(model)
このように同じくデータパラレルで並列化させています。大きいバッチでデータのないところは、OOMになってしまうため測っていない場所です。
このグラフから以下のことがわかります。
- 小さいCNNかつ1GPUでは、必ずしもPyTorchが最速とは限らない。むしろTensorFlow、特にchannels_firstにしたTensorFlowのほうが速いことがある。
- TensorFlowとPyTorchの差は、小さいCNNではバッチサイズを大きくすると縮まっていく。
- ただし、PyTorchでは2GPUにしたときは明らかにTensorFlowよりも速くなる。バッチサイズ512以降では、Colab TPUよりもFP32で既に速い。
- PyTorchのほうが大きいバッチサイズを出しやすい。TensorFlowの場合は、1GPUではバッチサイズが2048のケースがOOMで訓練できなかったが、PyTorchの場合は1GPUでバッチサイズ2048を訓練できる。
Wide ResNet 28-10
こちらはWide ResNet 28-10の訓練時間を比較したものです。
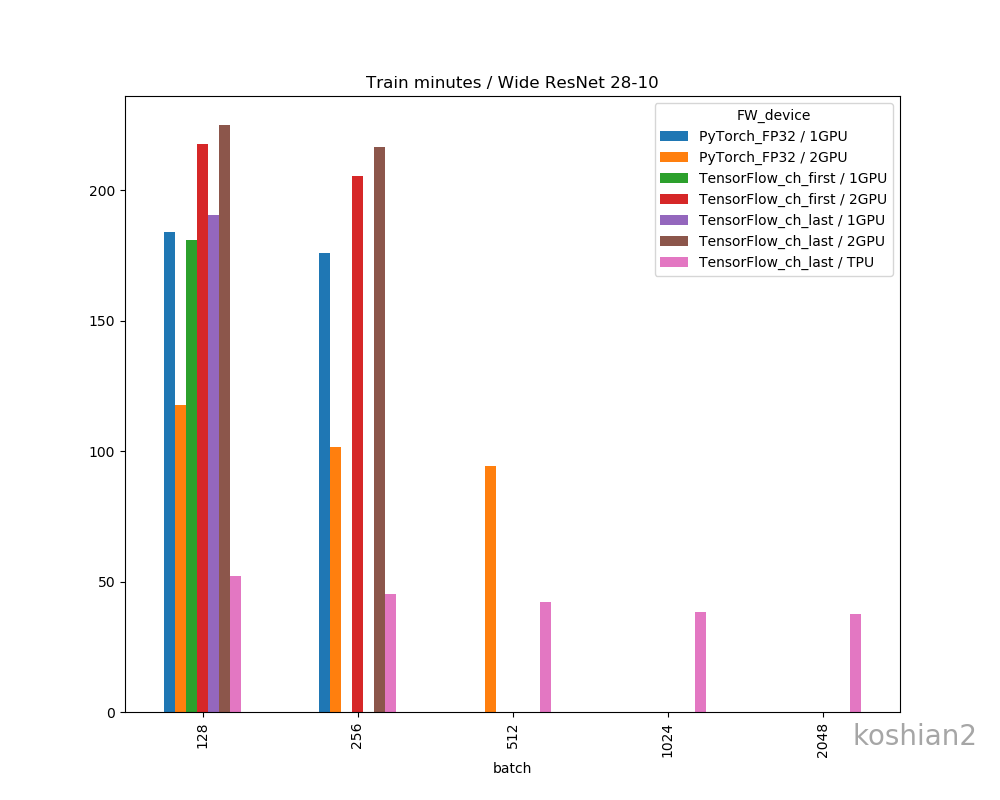
- 大きいCNNかつ1GPUでは、PyTorchとTensorFlowの訓練時間の差はほとんどない。特にTensorFlowでChannels firstにすればPyTorchかそれ以上の速さは出せる。
- しかし、複数GPUになると、明らかにPyTorchのほうが速くなる。TensorFlowのGPU並列化が何かおかしい。
- ただし、WRNのような大きなCNNのでは、PyTorch+2GPU+FP32ではまだColab TPUに勝てなかった
- PyTorchの場合、TensorFlowのできなかった1GPUでのバッチサイズ256、2GPUのバッチサイズ512を訓練することができた。なぜかPyTorchのほうが訓練できるバッチサイズが大きい。
PyTorch個別の結果
今回やったPyTorchだけの結果を表します
1GPU・10層CNN
| バッチ | 1エポック[s] | 2~中央値[s] | 訓練時間 | 精度 |
|---|---|---|---|---|
| 128 | 15.86 | 13.90 | 0:23:15 | 0.8915 |
| 256 | 12.72 | 12.29 | 0:20:28 | 0.8900 |
| 512 | 13.60 | 11.33 | 0:18:53 | 0.8837 |
| 1024 | 16.52 | 10.93 | 0:18:17 | 0.8860 |
| 2048 | 15.50 | 10.80 | 0:18:03 | 0.8639 |
1GPU・WRN
| バッチ | 1エポック[s] | 2~中央値[s] | 訓練時間 | 精度 |
|---|---|---|---|---|
| 128 | 111.89 | 110.42 | 3:03:57 | 0.8743 |
| 256 | 105.71 | 105.47 | 2:55:48 | 0.8011 |
2GPU・10層CNN
| バッチ | 1エポック[s] | 2~中央値[s] | 訓練時間 | 精度 |
|---|---|---|---|---|
| 128 | 16.07 | 11.92 | 0:20:04 | 0.8896 |
| 256 | 8.96 | 9.00 | 0:15:00 | 0.8912 |
| 512 | 8.74 | 7.80 | 0:13:01 | 0.8816 |
| 1024 | 9.52 | 7.24 | 0:12:05 | 0.8814 |
| 2048 | 8.34 | 7.05 | 0:11:45 | 0.8688 |
2GPU・WRN
| バッチ | 1エポック[s] | 2~中央値[s] | 訓練時間 | 精度 |
|---|---|---|---|---|
| 128 | 72.75 | 70.58 | 1:57:38 | 0.8559 |
| 256 | 58.43 | 60.83 | 1:41:22 | 0.8109 |
| 512 | 59.01 | 56.49 | 1:34:14 | 0.7695 |
精度比較
一応、フレームワークやデバイス間で精度の差があるか確認しておきましょう。
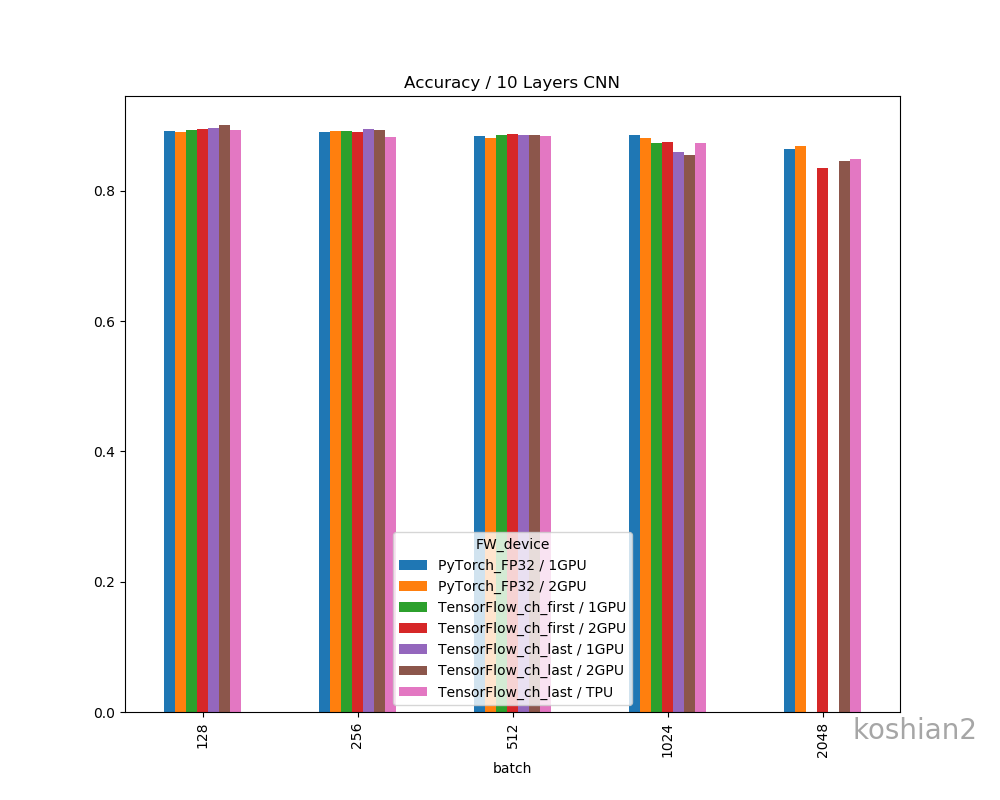
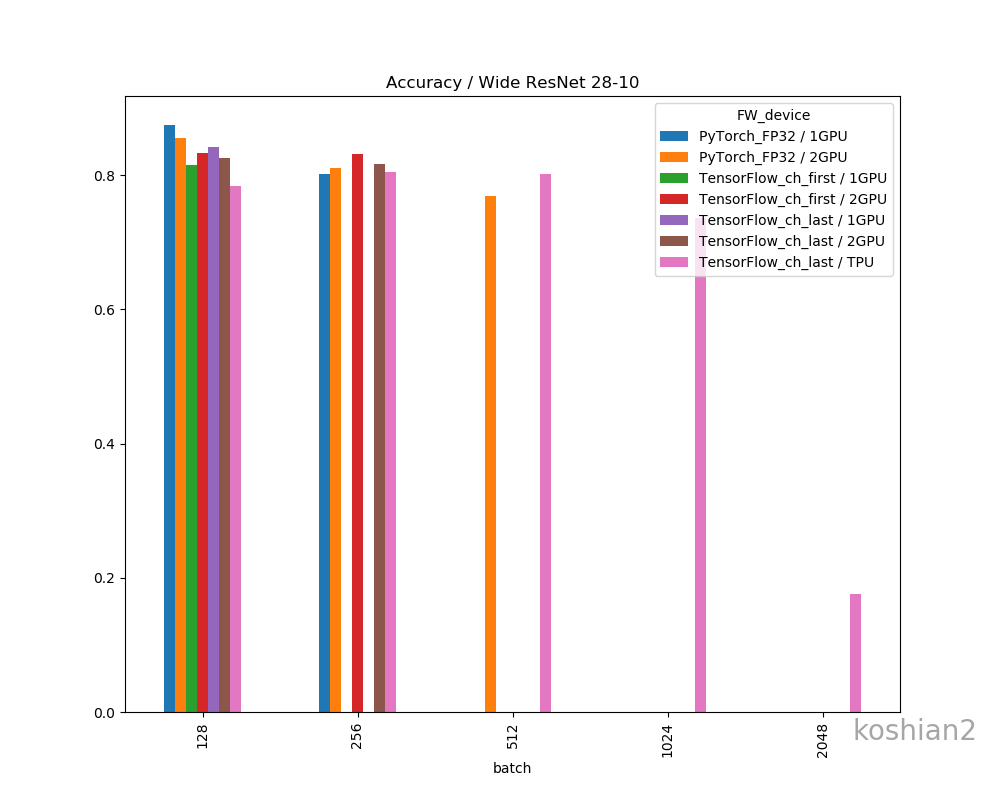
精度の明確な差はこのデータだけではなさそうに思えます。明確に議論するならケースごとにもう少し試行回数を増やして精査しないといけません。
GPUログ
1GPU・10層CNN
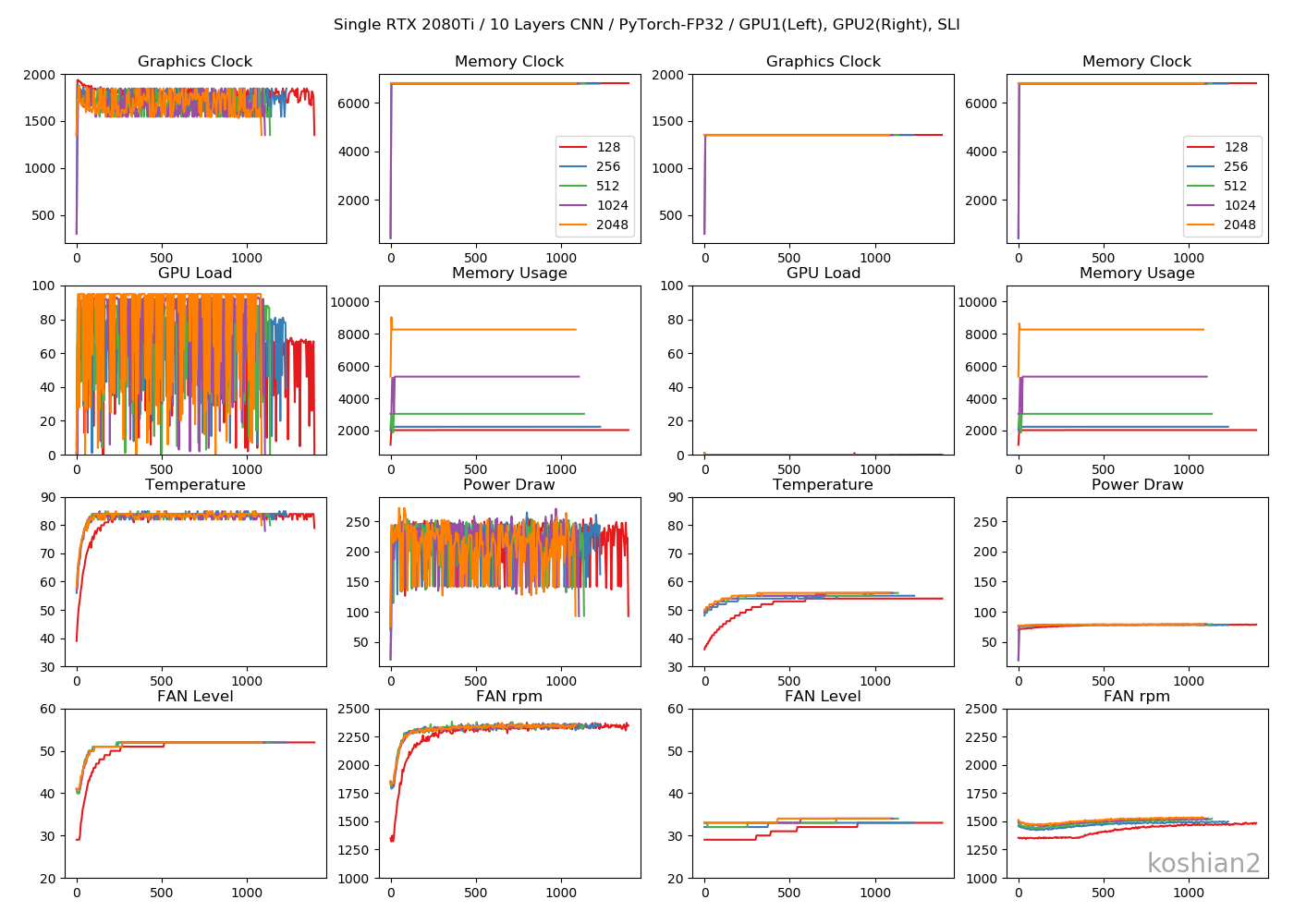
目につくのは「Memory Usage」です。TensorFlowのケースではモデルが大きかろうが小さかろうが、確保できるだけめいいっぱいメモリ確保しているのに対し、PyTorchではモデルに見合ったサイズしかメモリ確保していません。TensorFlowのGPU最適化やっぱりおかしいんじゃ。
1GPU・WRN
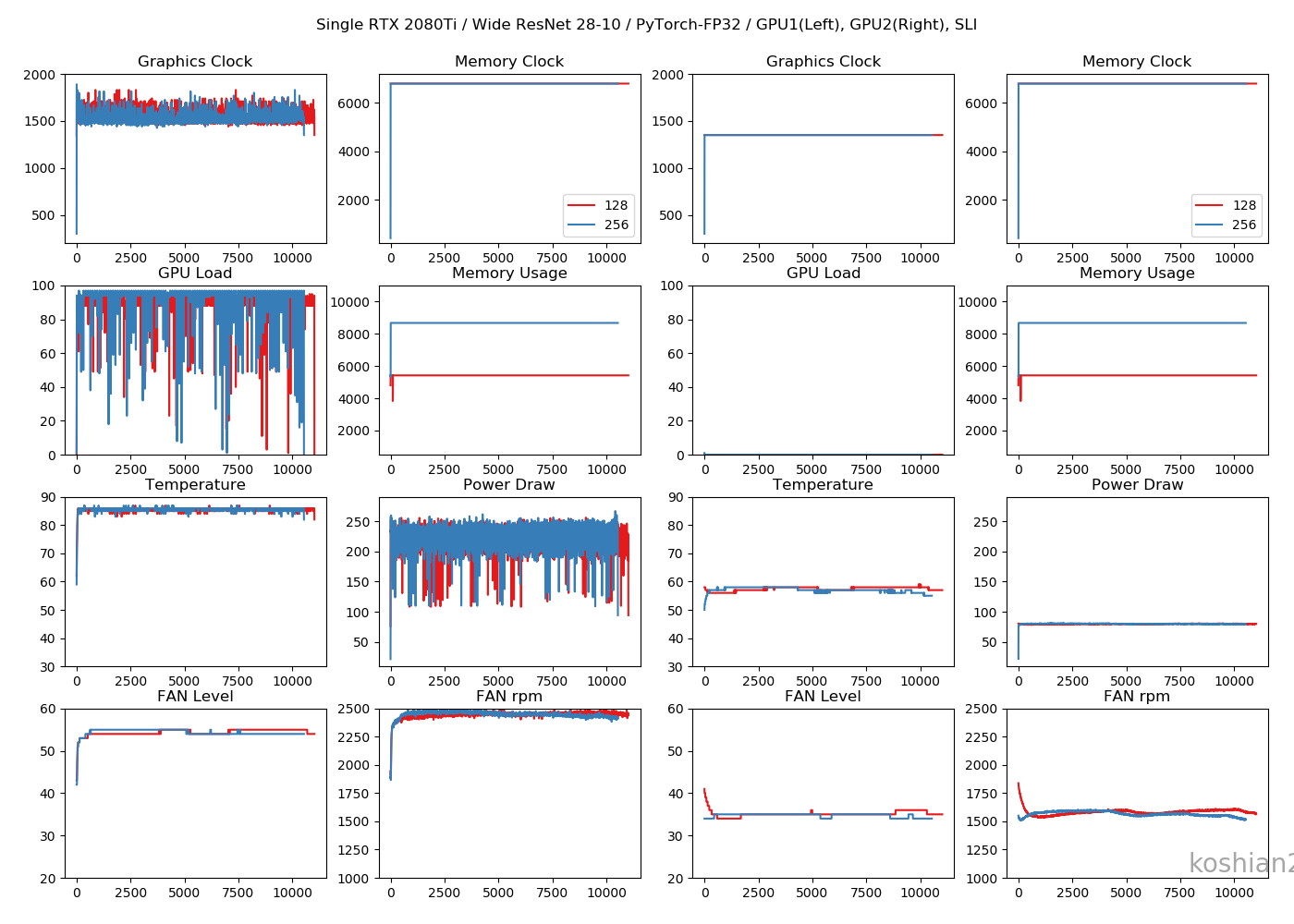
TensorFlowのケースよりGPUロードの振れ幅が大きくなっていますが、これはエポックの終わりで一瞬だけ計算しない時間があるからです。訓練ループを書いているせいもあるかもしれません。
2GPU・10層CNN
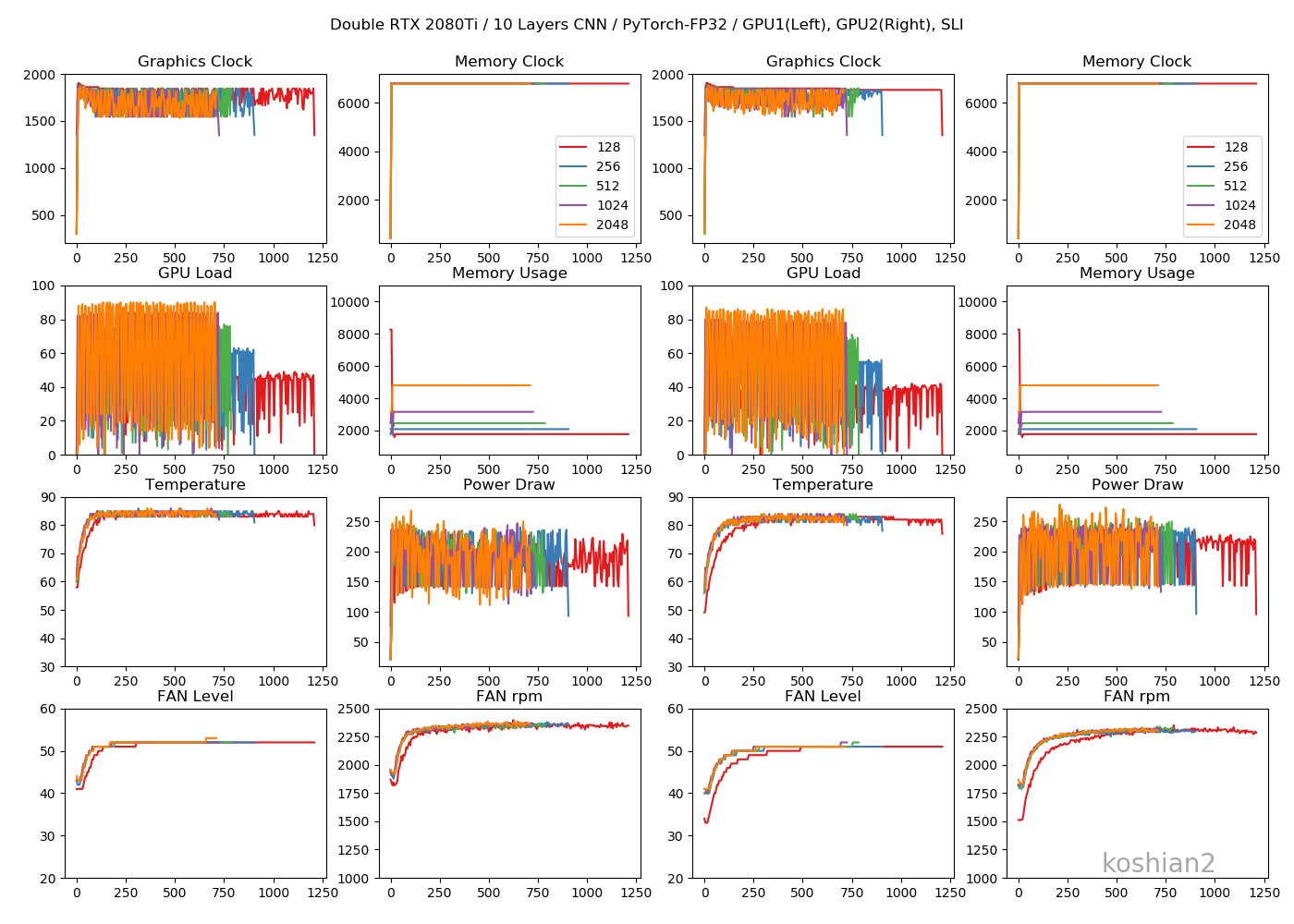
2GPUの場合は、GPUごとに同じ動きになっていてわかりやすいです。
2GPU・WRN
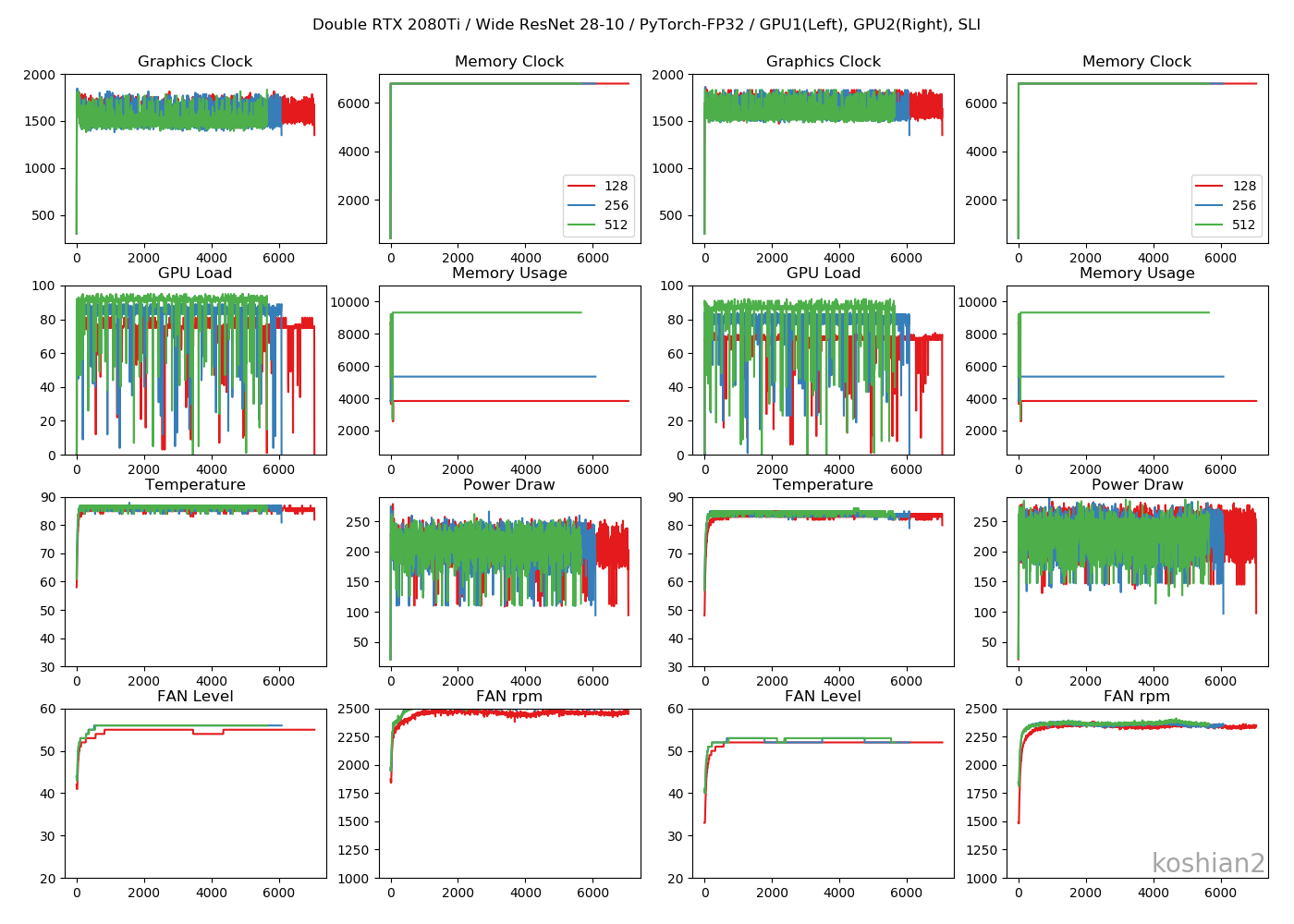
TensorFlowのときにあった、GPUロードの1枚目と2枚目の不均一性は解消されました。これなら自然ですし、速度も出るはずです。
まとめ
RTX 2080Ti SLI環境の場合、次のことがわかりました。
- FP32の精度では、1GPUの場合、TensorFlowとPyTorchの速さはあまり変わらない。TensorFlowでchannels_firstにするとPyTorchの速度を上回ることもある。
- ただし、2GPUにするとPyTorchの完勝になる。TensorFlowでは逆に遅くなってしまう。
- 10層CNNのような小さいモデルでは、2GPUのPyTorchにすると、FP32の精度を保ちながらColab TPUより高速化できる。
- ハードウェアが同一なのに、PyTorchのほうが大きなバッチサイズを訓練できることがある。
- PyTorchはモデルの大きさに応じてGPUメモリを専有する。TensorFlow/Kerasは大きいモデルだろうが小さいモデルだろうが、デフォルトでは確保できるだけ確保していて、GPUの最適化がおかしい。
PyTorch with テンソルコアでどれだけ速くなるかは次回に書きたいと思います。
コード
お知らせ
技術書典6で頒布したモザイク本の通販を下記URLで行っています。会場にこられなかったけど欲しいという方は、ぜひご利用ください。
『DeepCreamPyで学ぶモザイク除去』通販
https://note.mu/koshian2/n/naa60d5c9ebba
ディープラーニングや機械学習における画像処理の基本や応用を学びながら、モザイク除去技術DeepCreamPyを使いこなし、自分で実装するまでを目指す解説書です(TPUの実装中心に書いています)。