何がOS実装の理解を難しくしているのか
OS内部どうなってんのか知っといた方がいいんだろうなぁ、と思っている人向けになんか書きたいなぁ、と思って書きました。
OSを理解しようとすると、初回は挫折感をあじわって退場するのですが、原因いろいろあると思います。
- C言語、アセンブリ(gnu assembly)、ELF, linker scriptの知識
- boot処理時(の登場人物)で混乱する
- マルチタスク処理(switching, interrupt)がわからん
- OS自作しようぜ、みたいなはじめから強い本が多い
まぁ、最後のは冗談として(自分は凡人なので..)、 https://github.com/mit-pdos/xv6-public (Unix V6のx86(32bit) implementation。以下xv6と呼びます) と https://pdos.csail.mit.edu/6.828/2018/xv6.html がとてもよかったので、これをソースコードリーディングすることで、自分が詰まったand他人も詰まりそうなところをピックアップする感じで解きほぐしていきたい。
と思ったのですが、すべてのトピックを扱うと分量あまりに多くなったので、本記事では、枕の部分(モチベーションおよび、C言語、アセンブリ(gnu assembly)、ELF, linker scriptの知識、特に、GNU assemblyについては個別に)についてだけに言及し、本編はいくつかに分けました:
目次
- 何がOS実装の理解を難しくしているのか
- xv6ソースコードリーディングの勧めとGNU assemblyのポイント <= 本記事はココ
- xv6実装の詳解
OSの内部実装を知ってよかったこと、あるいはOSを学ぶモチベーション
得体の知れないものを「これ、いつか役立つんや~」って思いながら、自身の時間を割いてやるのは、精神衛生上よろしくないと思うので、最初に自分がOSの内部実装を知って一番よかったことを述べますと、
「ハードウェア今まで全然知らんかったなぁ」
と気づいたことです。
今まで自明だと思って動かしていたものが、ハードウェアとの連携でいろんな動作が実現されているのがわかり、実は全然混沌としていて自明でなかった![]() 、という気づきが何回もあり、視野がかなり広がったな、という感じがします。
、という気づきが何回もあり、視野がかなり広がったな、という感じがします。
あとは、プログラム動作時のメモリの配置のイメージがかなりはっきり見える感じがします。お給料あがるかどうかはちょっとよくわかりません。(上がれば![]() なんですけどね~)
なんですけどね~)
xv6のソースコードリーディングをおすすめする理由
自分自身、実ははじめてのOSコードリーディングという本を買った後でxv6の存在を知りました。「はじめてのOSコードリーディング」とは、UNIX V6という古のカーネルを題材にして挙動を理解しようというコンセプトの本です。その本によれば、初心者におすすめできる理由がいくつかあるとのことで、
-
一万行のソースコードで全体が把握しやすい(linux kernelはその数千倍くらいあります)
-
ロジックがシンプル
-
OSの基本となるアイデアが詰まっている
が挙げられます。しかしながら、
-
古のOSで、ANSI C以前のC言語らしきもので書かれており、若干文法が異なる。
-
プロセッサが古すぎ -> qemuとかで動作しない
-
大部分の人がいままで触れたことのない、プロセッサ(PDP-11)の仕様書を参照する必要がある
という欠点があります。xv6はMITがUNIX v6をx86仕様に書き直した教育用OSで、上記の利点を受け継ぎつつ、
-
普通のC言語(C99)で書かれている
-
Intel x86上(32bit)で動く(x86-64(64bit)とx86は多少の相違点はあれど、だいたい同じです) -> qemuなどのメジャーなエミュレータで動作する!
ということで、欠点が解消されています。また、解説も豊富で、
-
https://pdos.csail.mit.edu/6.828/2018/xv6/book-rev11.pdf (解説書)
-
http://www.cse.iitm.ac.in/~chester/courses/16o_os/syllabus.html (スライド集)
で十分に資料があります。仕様書を適宜参照するのもOSコードリーディングの際は非常に重要なのですが、referenceページにてすでにリンク集が用意されているので、仕様書を探す労力が省けます(この利点は非常に大きいと思います)
x86自体の資料については、
-
http://bochs.sourceforge.net/techspec/PORTS.LST (PORT I/O一覧)1
あたりが参考になります。(プロセッサ自体の仕様解説資料も大量にあるということを言いたかった)
ちなみに、Intelの公式のreference(Intel SDMと今後呼びます)はvol.1でなくvol.3を使用することがほとんどですので、お間違えなく。
あとは、自作するよりも(教育用でコメント付きの)ソースコードリーディングの方が消化不良に陥りにくいと思います。ということで、とっかかりにお勧めしたいです。
著者の力量について
ここは注釈みたいな感じなんですが、私自身は、Linux Kernel内部実装の解説、例えば、
- Linux Kernel Development (3rd Edition)
- Understanding the Linux Kernel: From I/O Ports to Process Management(3rd Edition)
- linux-insides
などをまだほとんど読んでいません。そのため、xv6と比べてlinuxの内部実装はこうだ、ということを言い切る自信がありませんので、ご了承くださいませ。(linux programmingのThe Linux Programming Interfaceはほぼ読んだのでユーザーランドの方はだいたいわかっていると思ってる) とはいえ、ベースは似たようなものじゃないかと思っています。
ということでめっちゃ詳しい方がいらっしゃいましたら、変なこと言っていたら突っ込んでくださると幸いです。
2019/8追記) Understanding the Linux Kernel: From I/O Ports to Process Management(3rd Edition)についてはしっかり理解しつつ、完走しました。パット見たかんじ、この本が一番詳細に解説しているのですが、バージョンは2.6.11でかなり古いです。個人的には、この本によってlinux kernelの未知のコードも自力で読めるだけの力量をつけられたので、未だ読む価値はあるんじゃないか、と思っています。
ちょっと前置きが長かったですが、ここからが本題です。
C言語、アセンブリ(gnu assembly)もろもろの知識
C言語から説明するわけにも行かないので、いくつか本や参考となるページを紹介します。
-
OS開発に関しては、C言語をお勧めします。C言語実装がOS開発においては一番情報量多いですし、boot処理のプログラムはlinker scriptの知識も必要になってくるので、gcc使うことを考えると、スクラッチOS実装したければCが無難です。ポインタだけ曖昧なら、エキスパートCプログラミングがお勧めです。
あとは、https://github.com/mit-pdos/xv6-public のコードがC実装なので。強くてニューゲームするときはGoでもRustでもなんでも良いんじゃないかと思います。 -
assemblyはnasmよりGNU assembly(gas)の方に慣れておきましょう。理由は上と関連しているのですが、gasの方がgccと相性が良いからです。あとは、両者、記法が結構違っていて(nasm: Intel記法、gas: AT&T記法)、例えば、srcとdstの位置が逆です。xv6ではgasです。OSのbootプログラムではふだんは使わないようなx86アセンブラ命令がたくさん出てくるのですが、その都度ググる感じで大丈夫です2。その他、重要なポイントについては次節で解説します。
-
unixプログラミングの知識に関しては、ふつうのLinuxプログラミングのfork, execあたりまでを理解していれば十分だと思います。知識を多く持っているに越したことはないって感じです。ちなみに、ここら辺を体系的に身につけたければ、The Linux Programming Interfaceが超おすすめです。
-
ELF(Executable and Linking Format) に関しては、http://www.cirosantilli.com/elf-hello-world および、https://qiita.com/knknkn1162/items/c67ae7c2ef71a713adf8 を読みましょう。手を動かして確かめるのを推奨します。用語集としてbinary hacksパラパラ見るのもお勧めです。
-
linker scriptに関しては、上のELFのリンクが十分に読めるなら、リンカ・ローダ実践開発テクニックはもう十分に読めるレベルになっているので、5章、6章あたりを読めばスッキリします。(が本記事で触れます)
-
その他の必要な部分に関しては、なるべく記事で確認していきます。
assemblyを読むポイント
基本的な事柄(レジスタやシステムコールとか)に関しては、x86_64 Linux Assemblyシリーズ(youtube)が良いかなと思いますので、そちらを参考にしてください。
Note) x86-64では%rax, %ripみたいな風になっていると思いますが、今回はx86(32bit)を見ていきますので、汎用レジスタはeax, ecx, edx, ebx, esp, ebp, esi, ediです。
本記事では、以下の点について解説していきたいと思います:
-
%espレジスタと%eipレジスタ - linker script
%espレジスタと%eipレジスタ
OS(xv6)内のassemblyのコードを読むためには、%espレジスタと%eipレジスタの正確な把握が非常に重要です。簡単にいうと、
-
%espレジスタは現在のスタックを指し示すポインタ(stack pointer)が格納されているレジスタ -
%eipレジスタは次のinstructionへのポインタ(program counter)が格納されているレジスタ
で、これら二つはプログラム実行時に目まぐるしく変化するわけですが、これら二つのレジスタをうまいこと動かすことで、特にマルチタスク(switching, interruptともに)処理を実現させているからです。real modeからprotect modeに移行する際のjump でも%eipの動作が暗黙的に関わってきます。
とは言っても基本はそんなに難しくありませんので、Hello worldプログラムを参考に見ていきます。GNU assemblyでx86アーキテクチャです。ということで、環境構築の後、数種類のサンプルを見ていきます。
環境構築
32bit OSの環境を作っていきます。
# -*- mode: ruby -*-
# vi: set ft=ruby :
Vagrant.configure("2") do |config|
config.vm.box = "ubuntu/trusty32"
config.vm.synced_folder ".", "/home/vagrant/shared"
end
$ vagrant up
$ vagrant ssh
$ cd shared
# gccはすでに入っているはず
$ sudo apt-get install gdb
なんのひねりもないHello world
.text
.globl main
main:
# sys_write(0x04)の呼び出し
movl $0x04, %eax
movl $0x01, %ebx # STDOUT_FILENO
movl $message, %ecx
movl $12, %edx # length
int $0x80
# sys_exit(0x01)の呼び出し
movl $0x01, %eax
xorl %ebx, %ebx
int $0x80
message:
.ascii "Hello world\n"
# -nostdlib: リンク時に標準システムスタートアップファイルや標準システムライブラリを使用しない
# -c: compileのみ
$ gcc -c -nostdlib hello0.S
# -emain: entry pointをmainにする(defaultは`_start`)
$ ld -emain hello0.o
# もしくは、`gcc -nostdlib -Wl,-emain hello0.S`
$ ./a.out
Hello world
$ objdump -d ./a.out
./a.out: file format elf32-i386
Disassembly of section .text:
08048054 <main>:
# 0x08048054はアドレス(正確にはvirtual memory address)です。
# 本当はsegmentationとpagingを理解する必要があるのですが、boot処理で詳しく説明します。
8048054: b8 04 00 00 00 mov $0x4,%eax
8048059: bb 01 00 00 00 mov $0x1,%ebx
804805e: b9 73 80 04 08 mov $0x8048073,%ecx
8048063: ba 0c 00 00 00 mov $0xc,%edx
8048068: cd 80 int $0x80
804806a: b8 01 00 00 00 mov $0x1,%eax
804806f: 31 db xor %ebx,%ebx
8048071: cd 80 int $0x80
08048073 <message>:
# Note: ここはobjdumpによって強引にinstructionに変換されている部分なので、48: 'H', 65: 'e', ...0a: '\n'に相当します。
8048073: 48 dec %eax
8048074: 65 gs
8048075: 6c insb (%dx),%es:(%edi)
8048076: 6c insb (%dx),%es:(%edi)
8048077: 6f outsl %ds:(%esi),(%dx)
8048078: 20 77 6f and %dh,0x6f(%edi)
804807b: 72 6c jb 80480e9 <message+0x76>
804807d: 64 fs
804807e: 0a .byte 0xa
さて、%espと%eipレジスタの動きを追います。レジスタの値の確認はgdbで行うのが良いでしょう。
gdbの操作については、http://d.hatena.ne.jp/murase_syuka/20150912/1442021005 が
各種コマンドについては、http://d.hatena.ne.jp/Watson/20100318/1268887029 がわかりやすいです。
hello0.Sをコンパイル、リンクしたものをgdbで動かすとこんな感じになります。(3つパネルがあると思いますが、特に1つめのパネルに注目してください。真ん中のパネルの背景白になっている部分は次に進むべきinstructionを指し示しています。)

%eipはinstructionの実行ごとに次々に変化していることが重要です。というのも、%eipは次のinstructionへのレジスタをさしているからです。(.text section内に%eipがあります。一方、%espは(下方向にスタックが積まれるので)stack領域のbottommostです)
一方で、%espは0bffff750で全く変化していません。%espはstack pointerと言ってスタック領域の最下部にあります。特にhello0.sのプログラムではスタックに積むべきものがないからです。
全体のmemory mapを俯瞰して見ると、以下のような感じになります:
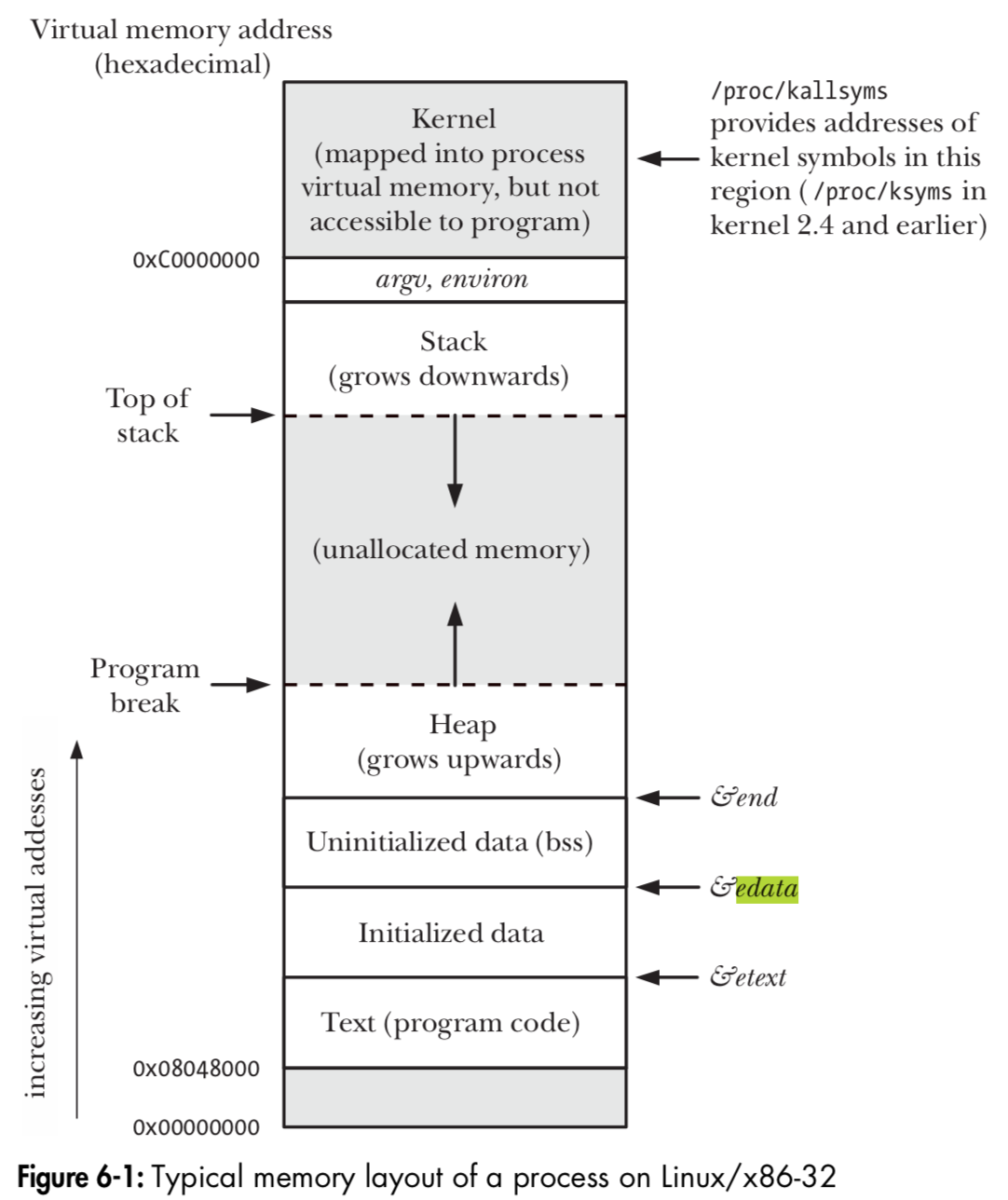
The Linux Programming Interface 2nd Ed.(Fig6.1)から引用
%eipレジスタは下図のText(program code)と書いているところの領域内のアドレスで、%espはtop of stackと書いてあるちょうどそのアドレスを指し示しています3。
helloの関数化
.text
.globl main
main:
call hello
call exit
hello:
movl $0x04, %eax
movl $0x01, %ebx
movl $message, %ecx
movl $12, %edx # length
int $0x80
ret
exit:
# exit
movl $0x01, %eax
xorl %ebx, %ebx
int $0x80
message:
.ascii "Hello world\n"
$ gcc -c -nostdlib hello_exit.S
$ ld -emain hello_exit.o
$ ./a.out
Hello world
$ objdump -d ./a.out
./a.out: file format elf32-i386
Disassembly of section .text:
08048054 <main>:
8048054: e8 05 00 00 00 call 804805e <hello>
8048059: e8 17 00 00 00 call 8048075 <exit>
0804805e <hello>:
804805e: b8 04 00 00 00 mov $0x4,%eax
8048063: bb 01 00 00 00 mov $0x1,%ebx
8048068: b9 7e 80 04 08 mov $0x804807e,%ecx
804806d: ba 0c 00 00 00 mov $0xc,%edx
8048072: cd 80 int $0x80
8048074: c3 ret
08048075 <exit>:
8048075: b8 01 00 00 00 mov $0x1,%eax
804807a: 31 db xor %ebx,%ebx
804807c: cd 80 int $0x80
0804807e <message>:
804807e: 48 dec %eax
804807f: 65 gs
8048080: 6c insb (%dx),%es:(%edi)
8048081: 6c insb (%dx),%es:(%edi)
8048082: 6f outsl %ds:(%esi),(%dx)
8048083: 20 77 6f and %dh,0x6f(%edi)
8048086: 72 6c jb 80480f4 <message+0x76>
8048088: 64 fs
8048089: 0a .byte 0xa
gdbで追いかけるとこんな感じ:
1分くらいで長いので、こちらのリンクも。
https://asciinema.org/a/aD89Pre6R7bls6wplOxi2eb6r

call helloを呼んだ直後、%espが変更されていることがわかるかと思います。
# call helloを呼んだ直後
(gdb) x/8xw $esp
0xbffff74c: 0x08048059 0x00000001 0xbffff87f 0x00000000
0xbffff75c: 0xbffff8a8 0xbffff8b9 0xbffff8cd 0xbffff8dd
stackはgrow downすることを踏まえると、0x08048059(call 804805e <hello>の次のinstruction)をスタックに積んで%espが0xbffff750から0xbffff74c(0xbffff750 - 4)に移動しているのが見て取れます。
hello 関数が終了した直後は
# hello 関数がretを呼んだ直後
(gdb) x/8xw $esp
0xbffff750: 0x00000001 0xbffff87f 0x00000000 0xbffff8a8
0xbffff760: 0xbffff8b9 0xbffff8cd 0xbffff8dd 0xbffff8fa
となり、%espが0xbffff74cから0xbffff750に移動しています。実のところ、ret instructionがその役割を果たしていて、
- アドレス
0x08048059を%eipにpopする。(%espはスタック領域+4移動する) - アドレス
0x08048059はcall 8048075 <exit>なので、そちらにジャンプする
みたいな挙動になっています。
Note) call関数のint $0x80が呼ばれた時点でプログラムが終了するため、call関数にはretをつけてません
以上、関数が呼ばれる仕組みは%eipと%espが重要な役割を果たしており、
-
call helloを実行する -
call exit(main関数内のcall hello直後のaddress)をスタックにpushして、%espを4byte分(pointerのサイズ分)decrementしておく - hello関数の先頭アドレスにjumpする
-
%eipにhello関数の2番目のinstructionを指し示すaddressを格納 - (hello関数の実行)
- stack領域をpopして、
call exit(call hello直後のaddress)を%eipに格納する。%espは4byte分(pointerのサイズ分)incrementされている -
%eipは次のinstructionへのaddressが格納されているregisterだったので、そのaddressにジャンプ -
call exitを実行する - 2からの流れと同様...
となります。スタックに関数へのaddressをpush/popすることで、main -> hello -> mainに戻るということを可能にしています。
ret instructionの応用
前節に関連してですが、実戦で重要なこと。call instructionとretが対となって呼ばれる必要はありません。どう言うことかと言うと、retは
- アドレスXXXを%eipレジスタにpopする。(%espレジスタは現在の場所+4になる)
- アドレスXXXにジャンプする(コレは%eip本来の挙動)
のような挙動をするのですが、call instructionを使わずともこのアドレスXXXをstack領域にうまいことはめこめば、retが実行された時にどこでもjumpできると言うわけです。
例えば、
.text
.globl main
main:
movl $exit, %eax
pushl %eax
jmp hello
hello:
movl $0x04, %eax
movl $0x01, %ebx
# (.. 省略)
でも問題なく動きます。(このコード自体はかなり作為的ですが)
またまたgdbでの動作

先ほどと違うところは、
-
pushl %eaxでstackにexit関数のaddressを積んでいるところ -
jmpでは次のinstructionへのアドレスをstackに積まない(callは次のinstructionへのアドレスをstackに積むのだった)
-
hello関数の
retの後、いきなり、exit関数の一番初めにjumpしている
ことです。1でstackに飛びたい関数へのポインタを積んでいるところがキモで、一見するとアクロバティックな飛び方をしています。
今回の例だと、[main] -> [print] -> [mainに(戻るべきところを)戻らず、exit関数にジャンプ] しています。
つまり、アセンブリの世界では関数呼び出しは必ずしも入れ子でよばれるとは限らないのです。(ここは普通の(CとかPythonとか)プログラミングとは異なるかなり独特な部分です。)
なんで紹介したかと言うと、xv6(OS)でこれ相当のことをやっているところが、trapretの部分: (1番相当のコード -> 3番相当のコード )とか、execでentrypointが切り替わる部分: (1番相当のコード -> 3番相当のコード )とか色々あるからです。RUNNABLEになったプロセスからschedulerのプロセスに移る際も同じようなことをしているのですがさらに複雑ですので、別の記事で紹介します。
と言うことで、stackに飛びたい関数へのアドレスを突っ込むことで関数のジャンプが自由にできると言うお話でした。
引数を持つ場合
上のhelloの場合、messageもlengthも埋め込まれてしまっているので、hello worldしか出力できない関数で融通が効かないです。ということで、hello関数を抽象化して、2つの引数を持つprint関数を作ってみます:
.text
.globl main
main:
pushl $message
pushl $size
call print
subl $8, %esp
call exit
print:
// save %ebp
pushl %ebp
// save current %esp address in %ebp as temporary value, because real %esp may change.
movl %esp, %ebp
movl 8(%ebp), %edx
movl (%edx), %edx
movl 12(%ebp), %ecx
movl $0x04, %eax
movl $0x01, %ebx
int $0x80
movl %ebp, %esp
// restore %ebp
popl %ebp
ret
exit:
addl $0x08, %esp
movl $0x01, %eax
xorl %ebx, %ebx
int $0x80
message:
.ascii "Hello world\n"
size:
.long size - message
$ gcc -c -nostdlib hello_print.s
$ ld -emain hello_print.o
$ ./a.out
$ objdump -d ./a.out
./a.out: file format elf32-i386
Disassembly of section .text:
08048054 <main>:
8048054: 68 92 80 04 08 push $0x8048092
8048059: 68 9e 80 04 08 push $0x804809e
804805e: e8 08 00 00 00 call 804806b <print>
8048063: 83 ec 08 sub $0x8,%esp
8048066: e8 1b 00 00 00 call 8048086 <exit>
0804806b <print>:
804806b: 55 push %ebp
804806c: 89 e5 mov %esp,%ebp
804806e: 8b 55 08 mov 0x8(%ebp),%edx
8048071: 8b 12 mov (%edx),%edx
8048073: 8b 4d 0c mov 0xc(%ebp),%ecx
8048076: b8 04 00 00 00 mov $0x4,%eax
804807b: bb 01 00 00 00 mov $0x1,%ebx
8048080: cd 80 int $0x80
8048082: 89 ec mov %ebp,%esp
8048084: 5d pop %ebp
8048085: c3 ret
08048086 <exit>:
8048086: 83 c4 08 add $0x8,%esp
8048089: b8 01 00 00 00 mov $0x1,%eax
804808e: 31 db xor %ebx,%ebx
8048090: cd 80 int $0x80
08048092 <message>:
8048092: 48 dec %eax
8048093: 65 gs
8048094: 6c insb (%dx),%es:(%edi)
8048095: 6c insb (%dx),%es:(%edi)
8048096: 6f outsl %ds:(%esi),(%dx)
8048097: 20 77 6f and %dh,0x6f(%edi)
804809a: 72 6c jb 8048108 <size+0x6a>
804809c: 64 0a 0c 00 or %fs:(%eax,%eax,1),%cl
0804809e <size>:
804809e: 0c 00 or $0x0,%al
...
print関数のpushl %ebpとmovl %esp, %ebpはespが刻々と変化するので,一時的に%ebpに退避させているだけです。
あとは、%espがどのような挙動になっているかを確認しましょう:
# 起動直後の$esp .. 0xbffff770
# print関数をcallした直後
(gdb) x/8xw $esp
# 0x08048063: `call 8048083 <exit>`へのアドレス(最終的にretでこのアドレスにjumpします)
# 0x0804809c: size(0x0c)へのアドレス
# 0x0804808f: messageへのアドレス
# その先はガラクタ
0xbffff764: 0x08048063 0x0804809c 0x0804808f 0x00000001
0xbffff774: 0xbffff898 0x00000000 0xbffff8be 0xbffff8cf
# print関数で`mov %esp,%ebp`した直後の%esp
(gdb) x/8xw $esp
# 0x00000000: %ebpの値
# 0x08048063: `call 8048083 <exit>`へのアドレス(最終的にretでこのアドレスにjumpします)
# ...
0xbffff760: 0x00000000 0x08048063 0x0804809c 0x0804808f
0xbffff770: 0x00000001 0xbffff898 0x00000000 0xbffff8be
それで、movl 8(%ebp), %edxでやっているのは、sizeとかmessageの取り出しです:
| %ebp | メモリアドレス | 中身 | |
|---|---|---|---|
| 12(%ebp)-> | 0xbffff76c | 0x0804808f | ->%ecx |
| 8(%ebp)-> | 0xbffff768 | 0x0804809c | ->%edx |
| 4(%ebp)-> | 0xbffff764 | 0x08048063 | |
| -> | 0xbffff760 | 0x00000000 |
みたいな風になり、あとはsys_writeシステムコールを呼んでいるだけです。最後にmain関数内のsubl $8, %espでstack pointerの場所を戻しています。
引数を渡す時の挙動については、https://vanya.jp.net/os/x86call/index.html も詳しいです。(ただし、このサイトではIntel 記法で書かれているので、srcとdstが逆であることに注意する)
linker script
linker scriptとは、メモリ割当を設定できるファイルです。linker scriptを通して、ロード時に展開する(virtual) addressが決定されます。
普段目にすることはないと思うのですが、gccのリンク時にも暗黙にlinker scriptが使われています。これはld --verboseで見れます。( https://gist.github.com/knknkn1162/48af994c2559a454f3caad03c2d1b34f においた )。リンカスクリプトはld -Tコマンドでも指定できます。
本シリーズでは、linker scriptを生のママで読むのは本当に必要な部分以外は避け、
-
objdumpコマンド(
objdump -d ./a.out)でdisassembleした出力と -
linker map(これは
-ld Mで出力される(MはMapの意味))
の2種類を用意することでメモリ割当の様相を掴むことにします。
例えば、一番最初のhello worldのコード
.text
.globl main
main:
# sys_write(0x04)の呼び出し
movl $0x04, %eax
movl $0x01, %ebx
movl $message, %ecx
movl $12, %edx # length
int $0x80
# sys_exit(0x01)の呼び出し
movl $0x01, %eax
xorl %ebx, %ebx
int $0x80
message:
.ascii "Hello world\n"
だと、linker script
# これは、ldのdefaultのlinker scriptをかなり簡略化したものです。
SECTIONS
{
/* location counter */
. = 0x08048000 + SIZEOF_HEADERS;
.text : { *(.text) }
PROVIDE(etext = .); /* Define the 'etext' symbol to this value */
.rodata : { *(.rodata) }
PROVIDE(data = .);
.data : { *(.data) }
/* Adjust the address for the data segment to the next page */
/*. = ALIGN(0x1000); */
PROVIDE(edata = .);
.bss : { *(.bss) }
PROVIDE(end = .);
/DISCARD/ : {
*(.eh_frame_hdr .note.gnu.build-id)
}
}
をそのまま読むよりも、linker map
$ ld -T hello.ld hello0.o -M
Memory Configuration
Name Origin Length Attributes
*default* 0x0000000000000000 0xffffffffffffffff
Linker script and memory map
0x0000000008048054 . = (0x8048000 + SIZEOF_HEADERS)
.text 0x0000000008048054 0x2b
*(.text)
.text 0x0000000008048054 0x2b hello0.o
0x0000000008048054 main
0x000000000804807f PROVIDE (etext, .)
.rodata
*(.rodata)
0x000000000804807f PROVIDE (data, .)
.data 0x000000000804807f 0x0
*(.data)
.data 0x000000000804807f 0x0 hello0.o
0x000000000804807f PROVIDE (edata, .)
.bss 0x000000000804807f 0x0
*(.bss)
.bss 0x000000000804807f 0x0 hello0.o
0x000000000804807f PROVIDE (end, .)
/DISCARD/
*(.eh_frame_hdr .note.gnu.build-id)
LOAD hello0.o
OUTPUT(a.out elf32-i386)
と実行ファイル(./a.out)をdisassembleしたもの
$ objdump -d ./a.out
./a.out: file format elf32-i386
Disassembly of section .text:
08048054 <main>:
8048054: b8 04 00 00 00 mov $0x4,%eax
8048059: bb 01 00 00 00 mov $0x1,%ebx
804805e: b9 73 80 04 08 mov $0x8048073,%ecx
8048063: ba 0c 00 00 00 mov $0xc,%edx
8048068: cd 80 int $0x80
804806a: b8 01 00 00 00 mov $0x1,%eax
804806f: 31 db xor %ebx,%ebx
8048071: cd 80 int $0x80
08048073 <message>:
8048073: 48 dec %eax
8048074: 65 gs
8048075: 6c insb (%dx),%es:(%edi)
8048076: 6c insb (%dx),%es:(%edi)
8048077: 6f outsl %ds:(%esi),(%dx)
8048078: 20 77 6f and %dh,0x6f(%edi)
804807b: 72 6c jb 80480e9 <message+0x76>
804807d: 64 fs
804807e: 0a .byte 0xa
を見た方がメモリアドレスの配置の雰囲気はなんとなくつかめるのではないでしょうか?
これと合わせて、「C言語、アセンブリ(gnu assembly)もろもろの知識」で紹介したリンク
ELF(Executable and Linking Format) に関しては、http://www.cirosantilli.com/elf-hello-world/ および、https://qiita.com/knknkn1162/items/c67ae7c2ef71a713adf8 を読みましょう。手を動かして確かめるのを推奨します。用語集としてbinary hacksパラパラ見るのもお勧めです。
も一緒に見ると、ELF, assembly, linker scriptの関係性が見えてくるかと思います。
boot処理のコードを読む際もこの節で紹介した手法を用いて読んでいきたいと思います~
補足
- xv6のmemory配置(0x00000000 ~ 0x7fffffffまで)
https://pdos.csail.mit.edu/6.828/2018/xv6/book-rev11.pdf のFigure2.2
0x80000000 ~ 0xffffffffまではkernel内部で扱うmemory領域になります。
-
bochsとはx86のエミュレータで外部とのやり取りをemulateしてくれるツールです。qemuに内蔵されています。リンク先見ると、
Do NOT consider this information as complete and accurate.みたいな風に書いてあるのですが、I/O port一覧としていろんなところで引用されており、信頼度高いと個人的に感じるので、レファレンスとして使っていきたいと思います。 ↩ -
自分はnasmから入って、x86_64 Linux Assemblyシリーズ(youtube)を推しているのですが、GNU aseembly入門で良いサイトなどがあれば教えてください
 ↩
↩ -
xv6のメモリ配置はstackの位置がlinux x86のそれとは若干異なりますので、注意してください。補足に図だけ載せてます。本記事では、あくまでlinuxでのメモリ配置について述べています。 ↩