はじめに
xv6とはUnix V6のx86(32bit)実装の教育用OSです。第一回目の記事でxv6のソースコードリーディングをお勧めしたのですが、前回のboot処理に引き続きソースコードの解説をしたいと思います! 本記事はswitchingがどう実装されているかの解説記事です。
目次
- 何がOS実装の理解を難しくしているのか
- xv6実装の詳解
- boot処理編: segmentationとpagingを中心に
- マルチタスク処理編
- switching <= 本記事はココ
- interrupt
Note) switchingの記事、2018/11時点ではあんまり需要なさそうので、この次のinterruptについての記事はcontribution数が相当増えない限り、多分公開しない予定です。 -> (2019/3) 簡単にまとめました http://cstmize.hatenablog.jp/entry/2019/03/20/xv6%E3%81%AE%E5%A0%B4%E5%90%88%E3%81%AEException%E3%81%A8Interrupt%E3%81%AE%E6%8C%99%E5%8B%95
準備
https://github.com/mit-pdos/xv6-public の準備をしておきます。
# -*- mode: ruby -*-
# vi: set ft=ruby :
Vagrant.configure("2") do |config|
config.vm.box = "ubuntu/trusty32"
config.vm.synced_folder ".", "/home/vagrant/shared"
end
のち、vagrant up && vagrant sshでubuntuに入ったのち、
# バージョン固定せずにかなりラフにinstallしても動くようだ。本記事ではqemuは使用しないので、インストールしていない
$ sudo apt-get install build-essential gdb libgmp3-dev libmpfr-dev libmpfr4 libmpfr4-dbg mpc
$ git clone https://github.com/mit-pdos/xv6-public
$ cd shared/xv6-public
# もし、動作確認したければ、以下のようにする
$ sudo apt-get install qemu
# Makefile参考に
$ make qemu
あと、kernel実行バイナリを得るために以下のコマンドでファイルを生成します:
# Makefile使用する
make kernel
# objdump -S kernel > xv6_kernel.asm
readelf -s kernel > kernel_readelf_s.log
make kernelの出力結果と、kernel_readelf_s.logは kernel_readelf_s.logは https://gist.github.com/knknkn1162/09e9a8c12e0a4ea0db07deb1d7bb4c19 に置いときました。
参考リンク
-
Intel® 64 and IA-32 Architectures Software Developer’s Manual(SDM) vol.3 (Order Number: 325384-067US May 2018) (公式) 本記事では
Intel SDM vol.3と略します -
%eipと%espレジスタの挙動について(第一回目の記事) -
The Linux Programming Interface(TLPI) .. ch.14 file system関連での参考文献としてあげました
マルチタスク処理とswitchingとinterruptの関係
マルチタスク処理とは複数のprocessをあたかも同時並行に動かす処理です。実際には、1~10ms単位でCPUが複数のprocessを切り替えることで、OS使用者にとって同時に動いているように見せます。
この切り替わるタイミングですが大きく分けて二つあります:
-
RUNNINGの状態のprocessが
waitやexitすることにより、状態が切り替わるとき -
timerによるinterruptで強制的に別のprocessに切り替えるとき
前者は、別のRUNNBALEの状態のprocessを動かしたいので、スループット向上のため、現行のprocessを左記のprocessに切り替えます。
後者は、もし同じprocessのままで、いつまでも切り替わらなかった場合、そのprocessが終了するまで、OS使用者は他のアクションができずに待たされることになります(カーソルが![]() マークになる) これでは不便なので、ある一定の時間が経過したら強制的に(といっても今までの設定を保存して)別のprocessの作業に切り替えます。
マークになる) これでは不便なので、ある一定の時間が経過したら強制的に(といっても今までの設定を保存して)別のprocessの作業に切り替えます。
雑に言うと、この切り替わりの動作のことをswitchingと言い、別の要因(この例だとtimer)による中断をinterruptと言います。
switchingする際には、ざっくり
- 古い方のprocessの設定を保存し、
- 新しい方のprocessの設定を復元する(中断したものが再開するので)
必要があります。なので、init processが動作するまでをゴールに
- switchingする前はなにがどうなっているのか
- switchingする直前と直後はどうなっているのか(registerの内容の保存、復元を行うわけですが..)
- switchingした後はどうなるのか
と言う感じで、その時歴史が動いた的なストーリーでお話ししたいです![]()
interruptについては、APIC(Advanced Programmable Interrupt Controller)の話からする必要がありそうで、かなり長くなりそうなので、別の記事にまとめたいと思います!
全体の流れ
この記事では、特にswtch関数から、%eipと%espが活躍しまくります。
この2つのregisterの意味合いについて把握していないと、ほとんど意味不明になってしまいますので、あまりよくわかっていない方は第一回目の%espと%eipの記事に目を通しておいてください。(完全に理解していても多分初見では混乱すると思います...)
entry.S:
- (scheduler processの)stack領域と%espを設定
main.c:
kinit2():
- 2GB+4MB~のkernel spaceを使用可能(free)にしておく
seginit():
- kernel spaceとuser spaceを権限的に分けたいのでGDTを再設定し、その先頭アドレスをレジスタ(GDTR)にロード
userinit():
allocproc():
- process tableから使用されていないprocessを選択(これがinitcode.Sを実行するためのprocessとなる)
- 上のprocessをprocAと呼ぶことにする。
- procAのstack領域(4096byte)を確保
上で確保したstack領域のconfiguration:
- swtch()からforkret()に飛べるような細工をする
- forkret()からtrapret()に飛べるような細工をする
setupkvm():
- procAのkernel領域のpagingの設定
inituvm():
- procAのためにinitcodeのバイナリを展開させておく
procAのconfiguration:
- ここで、trapret()からinitcode()に飛べるような細工をしている
- procAの状態をRUNNABLEにしておく
mpmain():
scheduler():
- realmodeの最初からOFFにし続けていたinterruptを有効にしておく
- process tableのうちRUNNABLEの状態のprocessを選択
- procAが選択されたとする
switchuvm():
interrupt(主に`int $T_SYSCALL`)が生じた場合のkernel modeへのrestore設定:
- TSS(Task State Segment) DescriptorをGDTのentry内に設定
- TSSの設定
- TSSをTR(Task Register)にロード
- procAのpaging設定を`%cr3`にロード
- procAの状態をRUNNINGにしておく
- (*ZZ) swtchが呼ばれる(call)直前、swtch関数の直後のaddressがstackに積まれることに注意)
swtch():
- registerの保存(scheduler processのstack領域にpush)
- %espをscheduler processのstack領域からprocAのstack領域内に移動させる
- procAのstack領域で保存されていた値をregisterに復元(pop)させる
- `ret` instruction実行でforkretに飛ぶ
forkret():
- (inodeのinitialization)
- returnの直前の%espはtrapretのaddressが入っているので、関数のreturnでtrapretにjump
trapret():
- 保存されていたregister(%es, %fs, %gs, %ds)を復元しておく
- `iret`intruction実行で%eip(initcode関数のaddress), %cs, %eflags, %esp, %ssが復元され、initcodeにjump
initcode():
- sys_execを実行するために、(`exec("init", ["init", 0]`となるように)引数を設定
- `int $T_SYSCALL(=60)`の実行
=> (ここからはinterruptの記事で解説しますが、init processの実行までを[`initcode.S`の`int $T_SYSCALL`が実行された後]の節にて見届けてます
「細工」と言っているのはstack領域に関数へのpointerを積むことで、数ステップ後のreturn時にその積まれた関数が発動するので、そう呼んでいます(専門用語ではない)
ソースコードを追っていくと実感するのですが、ぷよぷよの不定形連鎖っぽく繋がっていく感じです![]()
initcode.Sのint $T_SYSCALLが実行された後
initcode.Sのint $T_SYSCALLが実行された後はinterruptの記事で詳しくするつもりですが、ざっくり追っておくと、
1. int呼び出しによるhardware処理 (https://pdos.csail.mit.edu/6.828/2018/xv6/book-rev11.pdf のCh.3 X86 protectionを参照のこと)
2. alltraps
3. trap
4. syscall
5. sys_exec
6. exec
7. execがreturn
8. sys_execがreturn
9. syscallがreturn
10. trapがreturn
11. 3が終了したので、alltrapsの最後(`iret`)までを実行
12. init program codeのentry pointにジャンプ
で、init processが動き出します。後は、initがforkして、
-
親プロセスがZOMBIE状態のprocessを処理
-
子プロセスがexecを介してshell実行
すると言う流れです。この部分はinterrupt の回の時にお話したいです!
scheduler関数の再開
その後、wait()やexit()やTimerによるinterruptなどでsched関数が呼ばれ、(*ZZ)の影響で、schedulerを実行している関数に飛びます:
- (schedが呼び出される前にprocessの状態がRUNNING以外の状態となっている)
sched():
- swtchを呼び出し
swtch():
- registerの保存
- %espをscheduler processのstack領域からprocAのstack領域内に移動させる
- (*ZZ) のため、`ret` instruction実行でschedulerのswtch実行直後に飛ぶ
schedulerのswtichkvm():
- schedulerのprocessのpage directoryを`%cr3`(page directoryの場所を格納しておくためのregister)にロード
- schedulerのforが終わる
- schedulerがprocess tableからprocessがRUNNABLEのprocessを選択する(これをprocBとしよう)
- swtch実行
swtch():
- registerの保存
- %espをscheduler processのstack領域からprocAのstack領域内に移動させる
- `ret` instruction実行でprocBに飛ぶ
となります。(ここは本記事で(interruptを避けつつ)紹介します!)
ということでみたらわかるのですが、今回の記事も死ぬほど詳しく書きましたので、めっちゃ長いです![]()
switchingする前はなにがどうなっているのか
この章ではentry.Sからmain > mpmain > scheduler > swtch関数の直前まで追っていきたいと思います。
entry.S
# # Entering xv6 on boot processor, with paging off.
# .globl entry
# entry:
# Set up the stack pointer.
# mov $0x801020c0,%esp
movl $(stack + KSTACKSIZE), %esp
mov $main, %eax
jmp *%eax
// declares a common symbol named symbol. (static allocation which size is KSTACKSIZE=0x1000=4096byte)
.comm stack, KSTACKSIZE
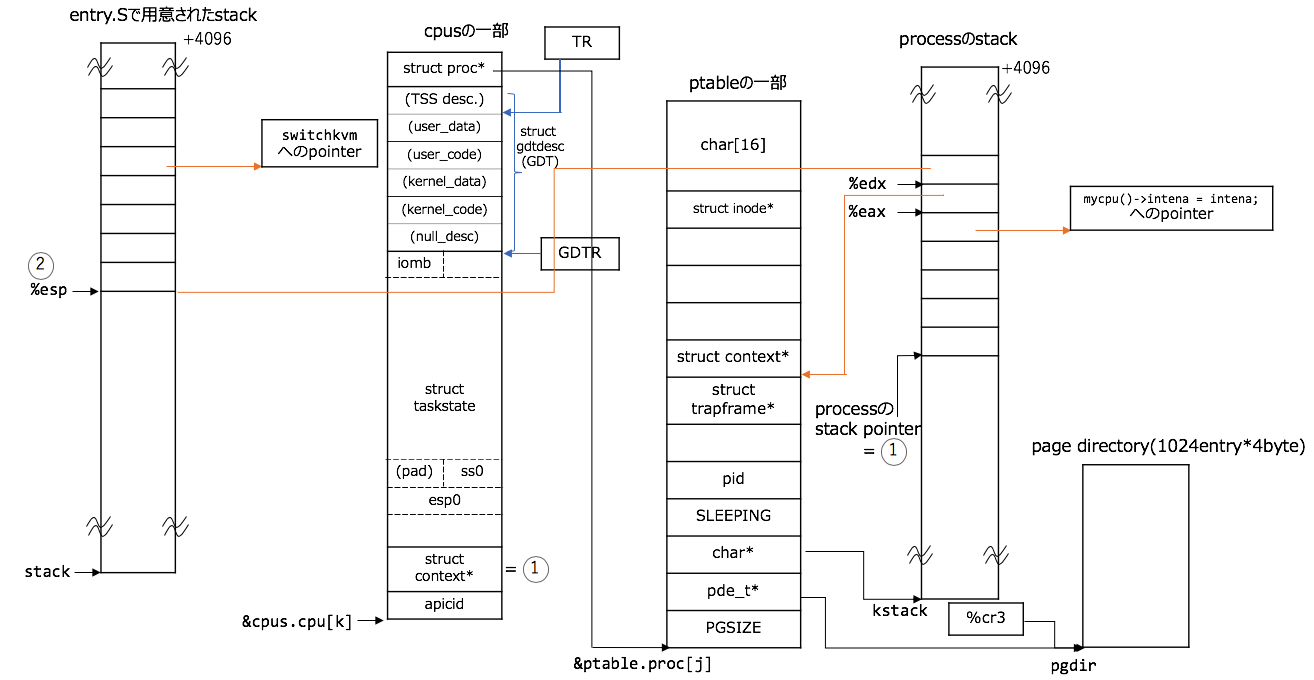
どこからスタート? なんですが、stack領域が用意されて、stackの一番上のaddressの値%esp registerに格納されるところから、スタートです。このstackが後のschedulerを実行させるときのstack領域となります。

main()
kinit2()
この関数では、2GB+4MB~のkernel spaceを使用可能状態にします。
kinit1()では、page directoryやpage tableの領域確保のために必要と思われる領域だけを使用可能状態にしていたのですが、各種初期設定が完了しているので、使用可能な領域を広げます。(page directoryなどに関しては前の記事にて詳しく説明しているので、参照してください)
seginit()
seginitに関しては、 https://qiita.com/knknkn1162/items/cb06f19e1f999bf098a1#seginit で説明しているので、そちらをご覧ください(独立して読める話になっています)
図としてはこんな感じ:
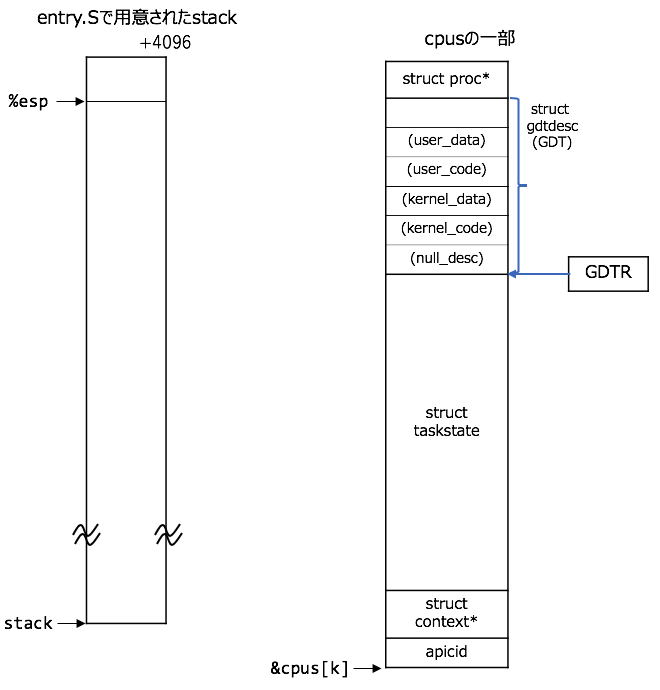
(%espの位置については、entry.Sで用意されたstack領域内にあること以外は、どの位置にあるかの関心は現状あまりないので、適当につけています。cpus[k]のkは適当な添字)
図には示しませんが、%csや%ds registerは1<<3, 2<<3となります。(%cs, %ds registerについては、 https://qiita.com/knknkn1162/items/cb06f19e1f999bf098a1#cscode-segment-register-dsdata-segment-register%E3%82%92%E8%A8%AD%E5%AE%9A を参照してください)
cpusはstruct cpu cpus[NCPU];と定義されていて、global変数です。
以下、模式図と言うことで、相対的な長さ、縮尺に関しては気にしないでください![]()
userinit()
userinitは
userinit(void)
{
struct proc *p;
extern char _binary_initcode_start[], _binary_initcode_size[];
p = allocproc();
// static struct proc *initproc;
initproc = p;
// ASet up kernel part of a page table.
if((p->pgdir = setupkvm()) == 0)
panic("userinit: out of memory?");
// B. Load the initcode into address 0 of pgdir.
inituvm(p->pgdir, _binary_initcode_start, (int)_binary_initcode_size);
// configure procA
// 省略
acquire(&ptable.lock);
p->state = RUNNABLE;
release(&ptable.lock);
}
なので、以下の小節では、
-
_binary_objfile_startと_binary_objfile_sizeについて -
allocproc -
setupkvm -
// configure procA以下のコード -
procAの状態を
RUNNABLEに切り替える
部分についての説明をしたいと思います!
_binary_objfile_startと_binary_objfile_sizeについて
userinitにある_binary_initcode_startや_binary_initcode_sizeという謎の変数が急に登場しています。externなので、どこか外部から引っ張ってきているみたいです。
準備の節で作成した、kernel_readelf_s.logを見ると、
-
_binary_initcode_startは https://gist.github.com/knknkn1162/09e9a8c12e0a4ea0db07deb1d7bb4c19#file-kernel_readelf_s-log-L451 に -
_binary_initcode_sizeは https://gist.github.com/knknkn1162/09e9a8c12e0a4ea0db07deb1d7bb4c19#file-kernel_readelf_s-log-L472 に
あるようです。
さらに、make kernelの出力を見て見ると、
gcc -fno-pic -static -fno-builtin -fno-strict-aliasing -O2 -Wall -MD -ggdb -m32 -Werror -fno-omit-frame-pointer -fno-stack-protector -nostdinc -I. -c initcode.S
ld -m elf_i386 -N -e start -Ttext 0 -o initcode.out initcode.o
# -S: Do not copy relocation and symbol information from the source file.(strip-all)
# -O: Write the output file using the object format bfdname. objcopy can be used to generate a raw binary file by using an output target of binary (e.g., use -O binary).
objcopy -S -O binary initcode.out initcode
ld -m elf_i386 -T kernel.ld -o kernel entry.o bio.o console.o exec.o file.o fs.o ide.o ioapic.o kalloc.o kbd.o lapic.o log.o main.o mp.o picirq.o pipe.o proc.o sleeplock.o spinlock.o string.o swtch.o syscall.o sysfile.o sysproc.o trapasm.o trap.o uart.o vectors.o vm.o -b binary initcode entryother
とあり、objcopy -S -O binary initcode.out initcodeからinitcode raw binaryを抜き出しています。と言うことで、最後の行のld -o kernel -b binary initcodeで、_binary_initcode_startや_binary_initcode_size を生成していることがわかります。
_binary_objfile_startや_binary_objfile_sizeの記述はman ldにはなく、objcopy -Bにあるようで、man objcopyによれば、
-B bfdarch
--binary-architecture=bfdarch
Useful when transforming a architecture-less input file into an object file.
In this case the output architecture can be set to bfdarch.
This option will be ignored if the input file has a known bfdarch.
You can access this binary data inside a program by referencing the special symbols that are created by the conversion process.
These symbols are called _binary_objfile_start, _binary_objfile_end and _binary_objfile_size.
e.g. you can transform a picture file into an object file and then access it in your code using these symbols.
とのことです1。
allocproc()
process tableから使用されていないprocessを選択
struct {
struct spinlock lock;
// #define NPROC 64 // maximum number of processes
struct proc proc[NPROC];
} ptable;
static struct proc*
allocproc(void)
{
struct proc *p;
char *sp;
acquire(&ptable.lock);
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++)
if(p->state == UNUSED)
goto found;
release(&ptable.lock);
return 0;
found:
// in the early stages of growth
p->state = EMBRYO;
p->pid = nextpid++;
ここの部分は、UNUSEDの状態のprocessを選択する部分です。ptableはglobal変数なので、静的に領域が確保されています。
ここで、選択されたprocess(変数p)を以下procAと呼ぶことにします。(struct procの内容は、https://github.com/mit-pdos/xv6-public/blob/b818915f793cd20c5d1e24f668534a9d690f3cc8/proc.h#L37-L52 のような感じ。)
ちなみにEMBRYOというのは胎芽、胚という意味みたいです(very early stage of the process)。
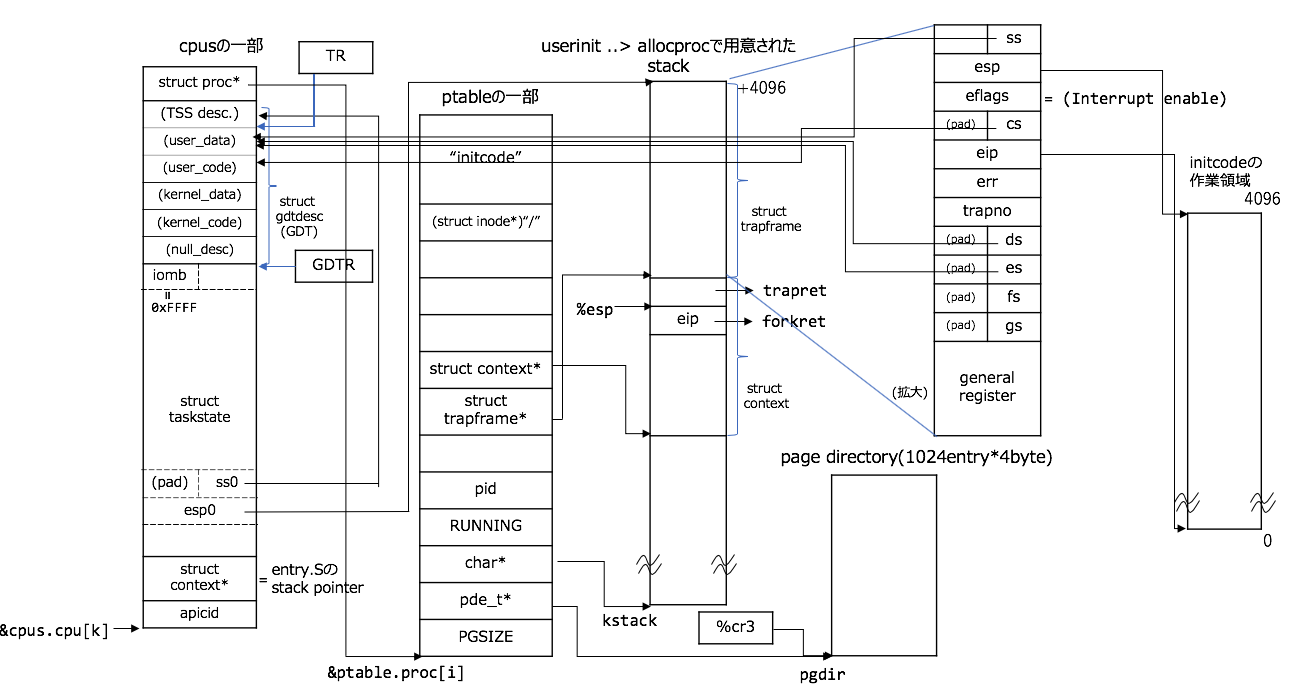
procAのstack領域の構成
ここから、procAのstack領域の構成です。図とコードの対応関係は以下のような感じ(図の番号がコード内の番号に対応しています):
1: kallocでprocAのstack領域を確保する
2: procAのstack領域の最上部にstruct trapframeを配置する
3: 2の下にtrapret(コレはtrapasm.Sで定義された関数のaddress)を設定する。(ここで、forkret()からtrapret()に飛べるような細工をしている。)
4: 3の下にstruct contextを配置する。
5: ここで、swtch()からforkret()に飛べるような細工をする
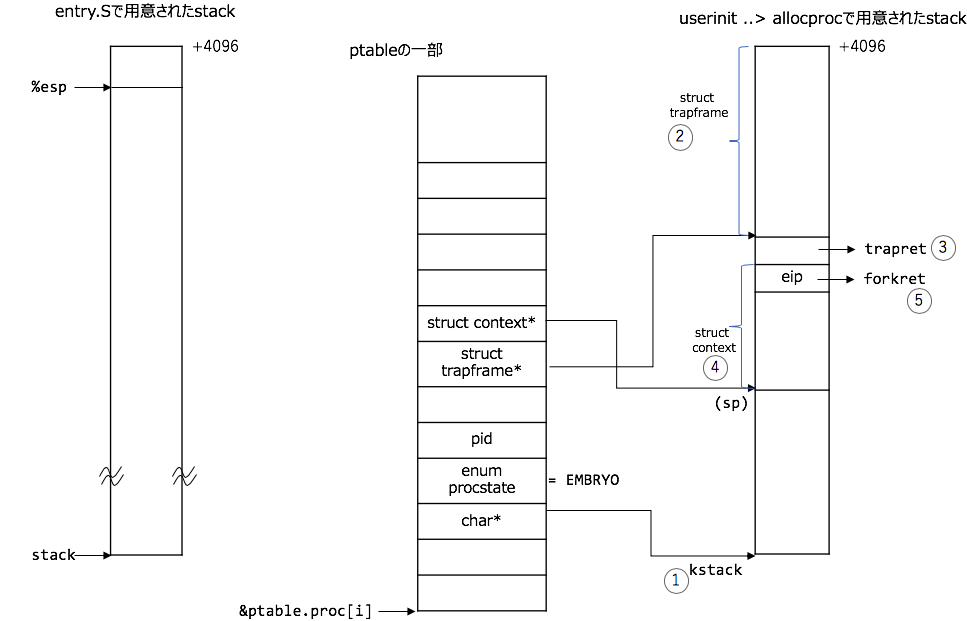
ptableはglobal変数で、以下のような構造をしています(変数iは適当な添字です):
struct {
struct spinlock lock;
// #define NPROC 64 // maximum number of processes
struct proc proc[NPROC];
} ptable;
2~4は変数spの移動によりstruct trapframeやstruct contextの配置を実現していることがポイントです。
// allocproc()の続き
// Allocate kernel stack.
// 1. kallocでprocAのstack領域を確保する
if((p->kstack = kalloc()) == 0){
p->state = UNUSED;
return 0;
}
sp = p->kstack + KSTACKSIZE;
// Leave room for trap frame.
sp -= sizeof *p->tf;
// 2. procAのstack領域の最上部にstruct trapframeを配置する
p->tf = (struct trapframe*)sp;
// Set up new context to start executing at forkret,
// which returns to trapret.
sp -= 4;
// 3. 2の下にtrapret(コレはtrapasm.Sで定義された関数のaddress)を設定する。
// ここで、forkret()からtrapret()に飛べるような細工をしている。
*(uint*)sp = (uint)trapret;
sp -= sizeof *p->context;
// 4. 3の下にstruct contextを配置する。
p->context = (struct context*)sp;
memset(p->context, 0, sizeof *p->context);
// 5. ここで、swtch()からforkret()に飛べるような細工をする
p->context->eip = (uint)forkret;
return p;
}
細工の部分については、その段になったら説明しますが、2週目にこの記事を読むときはちょっと気を払う感じで。
setupkvm()
この関数は実は、boot処理の kvmalloc()で登場しているのですが、再度説明します。
page tableやpage directoryなどの用語に関しては、説明なく使っていきますので、よくわからない方は、前の記事の https://qiita.com/knknkn1162/items/cb06f19e1f999bf098a1#4mbyte%E3%81%AEpaging%E3%82%92%E8%A8%B1%E5%8F%AF から読み始めるか、適宜ほかのサイトを確認してください。
今の所、kvmallocで反映した4K-Byte pagingが反映されています:
Intel SDM vol.3 ch.4 Pagingより引用
userinitのsetupkvmでやることは、procAに関するkernel spaceのpagingを設定することです。そのために、page directoryを作成します。
(その後、CPUがこのプロセスをRUNNINGさせる直前(main > scheduler > switchuvm関数内にある)に%cr3 register(Page Directory Base Register(PDBR))を再設定します。
注意) 現在のpagingは、main > kvmalloc > setupkvmがswitchkvm();(%cr3にロード)によって、設定されている点に注意してください。
pde_t*
setupkvm(void)
{
pde_t *pgdir;
struct kmap *k;
// // Allocate one 4096-byte page of physical memory.
// At that time,
if((pgdir = (pde_t*)kalloc()) == 0)
return 0;
この部分で、page directoryの領域(4*1024byte)を確保します。
// setupkvm(void)の続き:
memset(pgdir, 0, PGSIZE);
// #define DEVSPACE 0xFE000000 // Other devices are at high addresses
// #define PHYSTOP 0xE000000 // Top physical memory
if (P2V(PHYSTOP) > (void*)DEVSPACE)
panic("PHYSTOP too high");
for(k = kmap; k < &kmap[NELEM(kmap)]; k++)
// mappages(pde_t *pgdir, void *va, uint size, uint pa, int perm)
if(mappages(pgdir, k->virt, k->phys_end - k->phys_start,
(uint)k->phys_start, k->perm) < 0) {
freevm(pgdir);
return 0;
}
return pgdir;
}
後半のmappages(walkpgdirが本質的な仕事をしている)で、paging設定の作成を行います。kmapは
static struct kmap {
void *virt;
uint phys_start;
uint phys_end;
int perm;
/*
0x80101000 . = ALIGN (0x1000)
[!provide] PROVIDE (data = .)
*/
} kmap[] = {
// #define EXTMEM=0x00100000
// ##define KERNBASE 0x80000000 // First kernel virtual address
{ (void*)KERNBASE, 0, EXTMEM, PTE_W}, // I/O space (0x80000000 ~ 0x80100000)
// #define KERNLINK (KERNBASE+EXTMEM)=0x80100000 // Address where kernel is linked
{ (void*)KERNLINK, V2P(KERNLINK), V2P(data), 0}, // kern text+rodata (0x80100000 ~ 0x80102000)
{ (void*)data, V2P(data), PHYSTOP, PTE_W}, // kern data+memory (0x80102000 ~ 0x8E000000)
// #define DEVSPACE 0xFE000000 // Other devices are at high addresses
{ (void*)DEVSPACE, DEVSPACE, 0, PTE_W}, // more devices (0xFE000000 ~ 0xFFFFFFFF)
};
以下のような変数です。kernel spaceでのpaging設定はkmapという変換式に基づいており、全てのprocessで共通なのですが、user spaceではprocessごとにpagingの設定が異なります。この点については、 https://qiita.com/knknkn1162/items/cb06f19e1f999bf098a1#kernel-space%E3%81%A8user-space%E3%81%AEpaging を参照してください。
結局、p->pgdir = setupkvm()のように格納された状態の図は以下のようになります(といっても、前回との差分はprocAに上記で設定したpagingの設定を結びつけているだけです):
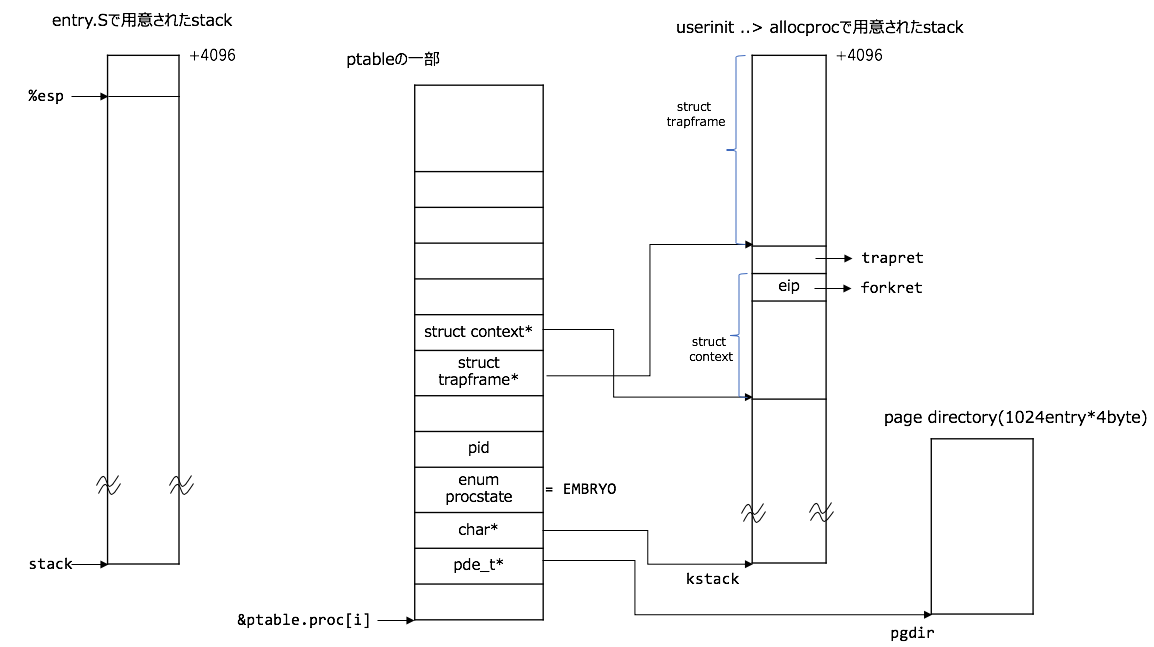
inituvm()
主にやることは2つあり、
-
mappages(pgdir, 0, PGSIZE, V2P(mem), PTE_W|PTE_U);でvirtual addressのuser space[0~4096byte)をphysical addressの[V2P(mem), V2P(mem)+4096)にmappingさせるようにpagingを設定する -
memmove(mem, init, sz);でvirtual addressのkernel space[mem, mem+4096)に_binary_initcode_start~_binary_initcode_start + _binary_initcode_sizeまでのbinaryをmoveしておく。
です。
1.のmemはmem = kalloc()で動的に確保した領域で4096byteです。
2で、virtual address: [mem, mem+4096)はkernel領域なので、physical addressでは、[V2P(mem), V2P(mem)+4096)に対応しており、1番のmappingの設定と一貫性があります。また、initcode.Sを見てもらえればわかるのですが、100行以内のassemblyで明らかに4096byteに収まる(実際には44byteでした2)ので、1page分の使用で十分です。
procAのconfiguration
これは図とコードを対応させた方が良いかなと思います。こんな感じ:
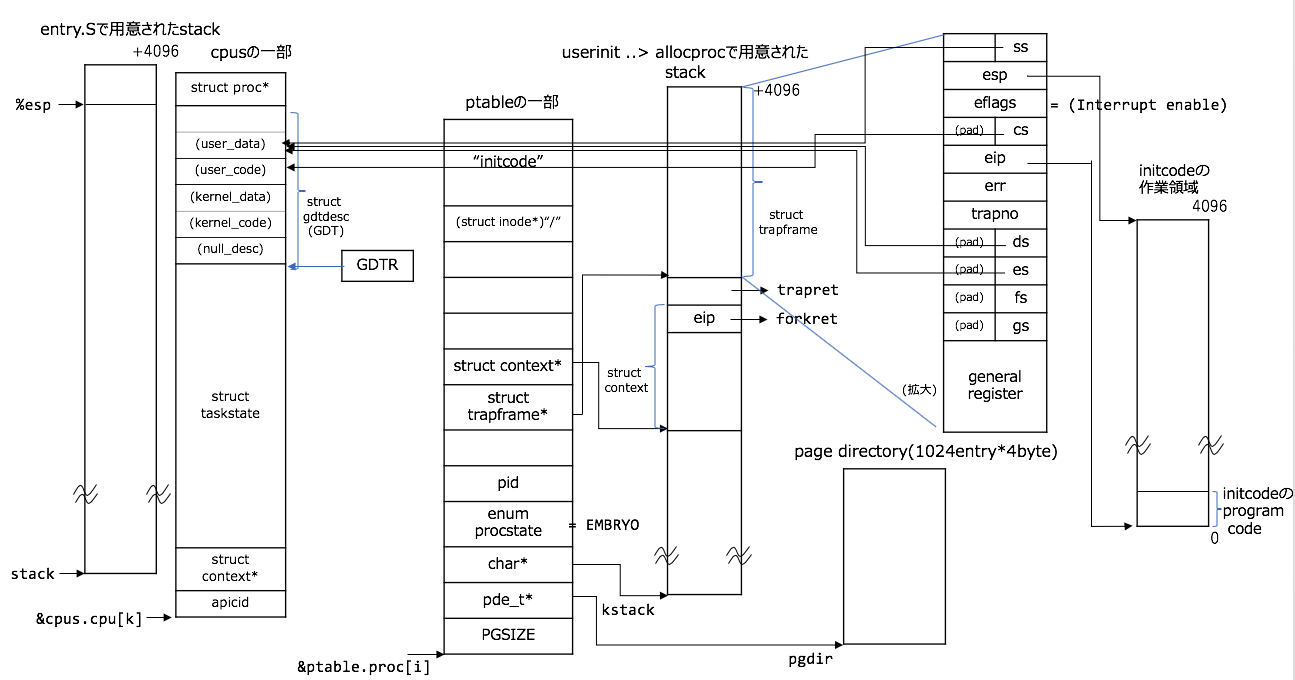
// userinit(void)の続き
p->sz = PGSIZE;
memset(p->tf, 0, sizeof(*p->tf));
p->tf->cs = (SEG_UCODE << 3) | DPL_USER;
p->tf->ds = (SEG_UDATA << 3) | DPL_USER;
p->tf->es = p->tf->ds;
p->tf->ss = p->tf->ds;
// #define FL_IF 0x00000200 // Interrupt Enable
p->tf->eflags = FL_IF;
p->tf->esp = PGSIZE;
p->tf->eip = 0; // beginning of initcode.S
safestrcpy(p->name, "initcode", sizeof(p->name));
p->cwd = namei("/");
general registerとは、%eaxとか%ebxとかのことでこの領域はまだ0で初期化されたままです。
cpusについては、seginit()で登場しました。
initcodeの0~4096と言うのは、virtual adddressなので、物理memoryの0~4096でないことに注意してください。(inituvm()の小節の参照のこと)
procAの状態をRUNNABLEに
acquire(&ptable.lock);
p->state = RUNNABLE;
release(&ptable.lock);
最後にprocAの状態をRUNNABLEにすることで、main > mpmain > scheduler関数の
void
scheduler(void)
{
struct proc *p;
// 中略
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++){
if(p->state != RUNNABLE)
continue;
// このあとswitching処理
で拾ってもらえるようにしてます。
排他処理を行う理由
![]() ここのトピックはやや難しいです。
ここのトピックはやや難しいです。
p->state = RUNNABLE;の前後でacquireとlockで包んでいるのは、排他処理する必要があるからですが、
// this assignment to p->state lets other cores
// run this process. the acquire forces the above
// writes to be visible, and the lock is also needed
// because the assignment might not be atomic.
acquire(&ptable.lock);
と言うのが理由です。ですが、ちょっと自明ではないので、次の2点について深掘りして見ます。
-
他のCPUは何をしていて、どう競合が起こる可能性があるのか?
-
なぜ、
p->state = RUNNABLE;はmight not be atomic.なのか?
他のCPUは何していて、どう競合が起こる可能性があるのか?
xv6は https://qiita.com/knknkn1162/items/cb06f19e1f999bf098a1#%E5%85%A8%E4%BD%93%E3%81%AE%E6%B5%81%E3%82%8C のNote の部分でも触れたように、MultiProcessorに対応しています。
他のCPUのboot処理からの挙動については、 https://qiita.com/knknkn1162/items/cb06f19e1f999bf098a1#%E5%85%A8%E4%BD%93%E3%81%AE%E6%B5%81%E3%82%8C のNote)に書いておきましたがざっくり言うと、
1: (BIOSのbootstrap処理前に)BIOSやOSのbootstrap処理が走るCPU(BootStrap Processor: BSPという)が選択される。選択されなかったCPU(Application Processor: APという)は待機。
2-1: main > startothers > lapicstartapのlapicw(ICRLO, STARTUP | (addr>>12));にて、APがentryother.Sを実行してOSのbootstrap処理を行う
2-2: BSPはhttps://github.com/mit-pdos/xv6-public/blob/1d19081efbb9517d07c7e6c1a8393c6343ba7817/main.c#L92-L93 にて待機する
3: APは2-1の続きでmpmain > xchg(&(mycpu()->started), 1);を実行し、2-2で待機していたBSPを起こす。APはそのまま、止まることなく、mpmain > schedulerに突入する
上記の3から、AP(Application Processor)はmpenter > mpmain > schedulerの
// scheduler(void)
// Loop over process table looking for process to run.
acquire(&ptable.lock);
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++){
if(p->state != RUNNABLE)
continue;
// Switch to chosen process. It is the process's job
// to release ptable.lock and then reacquire it
// before jumping back to us.
c->proc = p;
switchuvm(p);
p->state = RUNNING;
まで突入している可能性があります。この場合、以下の競合が起こる可能性があります。とりあえず、p->state = RUNNABLE;はatomicでないのを前提とします。(atomicでない確認は次節で)
1. BSPがuserinitの`p->state = RUNNABLE;`を処理し始める
2. APが`p->state != RUNNABLE`でfalseを返し、continueする
3. APが`p->state = RUNNING`を実行する
4. BSPがuserinitの`p->state = RUNNABLE;`を処理し終わり、p->stateにRUNNABLEが代入される
もし、こういうことが起こると、pの状態がRUNNABLEにも関わらず、CPUによってprocessが実行するため、予期せぬ動作をするでしょう。
実際には、2と3の間にswitchuvm(p)が挟まれているため、上記のようなことが起こる可能性は限りなく低いのですが、可能性のある限りlockは必要です。
なぜ、p->state = RUNNABLE;はmight not be atomic.なのか?
もし、atomicならば、1と4の2つの部分に処理がまたがることはありませんので、lockは不要ですが、実際にはatomicです。
Intel SDM vol.3 ch.8.1.1 Guaranteed Atomic Operations によれば、atomicであるためには32-bit 境界でのメモリの書き込み、読み込みが必要3ということで、今回の場合はその保証がないため、アトミックであることが保証できません。なので、might not be atomic.というわけでした。
以上2つのことから、p->state != RUNNABLEの前後ではacquire, lockが必要となります。よく考えてみれば意外とむずい部分でした![]()
Note) 「単一のinstructionである」 -> 「その命令はatomicである」、という命題は必ずしも 成り立たない ことに注意。上記の例だと、p->state != RUNNABLEはc7 43 0c 03 00 00 00 movl $0x3,0xc(%ebx)( https://gist.github.com/knknkn1162/9149a610070a8bd14486c5533def1876#file-kernel-asm-L9917-L9918 )で表現できますが、上の考察で見たようにこのinstruction自体は、atomicではありません。
userinit()部分がやっと終わったので、続いては少し飛んでmain > mpmain > scheduler関数を見ていきます!
mpmain()のscheduler()
部分部分確認していきます:
void
scheduler(void)
{
struct proc *p;
struct cpu *c = mycpu();
c->proc = 0;
for(;;){
// Enable interrupts on this processor.
sti();
stiはinterruptをONにする関数でsti instructionと同等です。あとは、Multiprocessor対応なので、struct cpu *c = mycpu();で、自身のCPUに対応したstruct cpuをとってきてます。
// scheduler(void)
// Loop over process table looking for process to run.
acquire(&ptable.lock);
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++){
if(p->state != RUNNABLE)
continue;
ここは何回か説明した通りですが、pの状態がRUNNABLEのprocessを探し出しています。このprocessを動作させるわけですね。今回は上記でみたinitcodeを動かすprocessを探してこれたとします4。
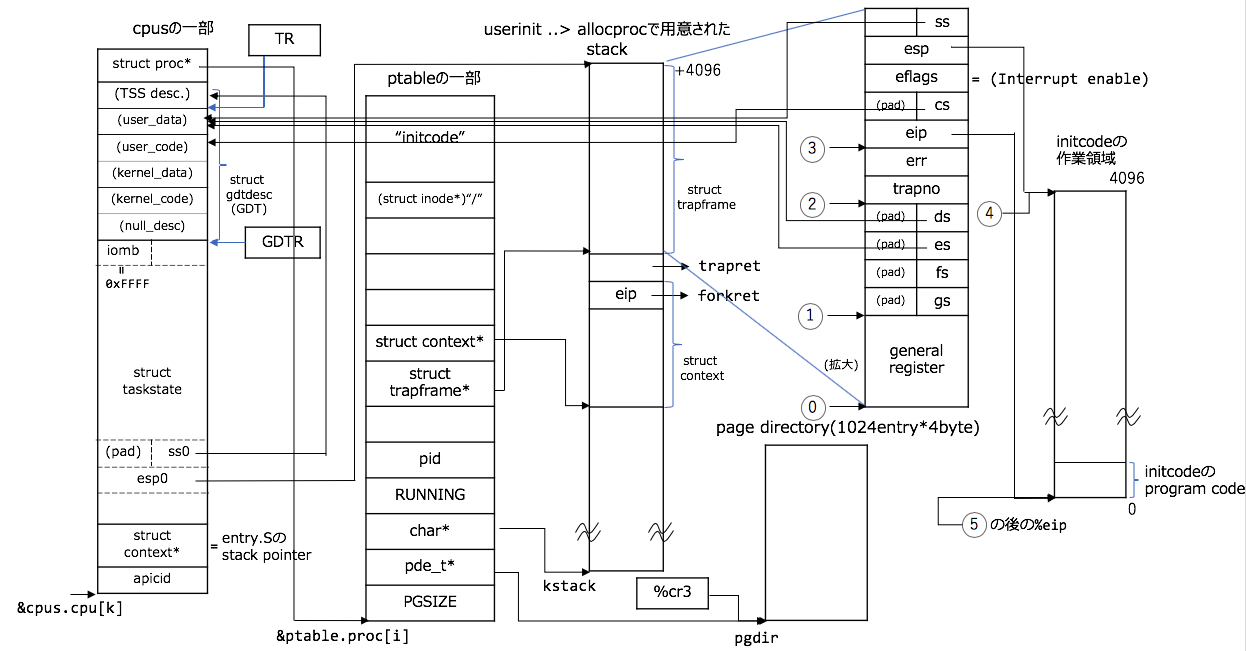
switchuvm()
また図とソースコードを対応づけておきます(さらに複雑ですが、ほとんどこれで仕掛けは終わりです![]() ):
):
1. cpuのproc構造体と先ほどまで構成していたprocAを結びつける
2. TSS(Task State Segment) DescriptorをGDTのentry内に設定
3. TSSの設定
4. TSSをTR(Task Register)にロード
5. procAのpaging設定を`%cr3`にロード
6. procAの状態をRUNNABLEからRUNNINGに切り替える
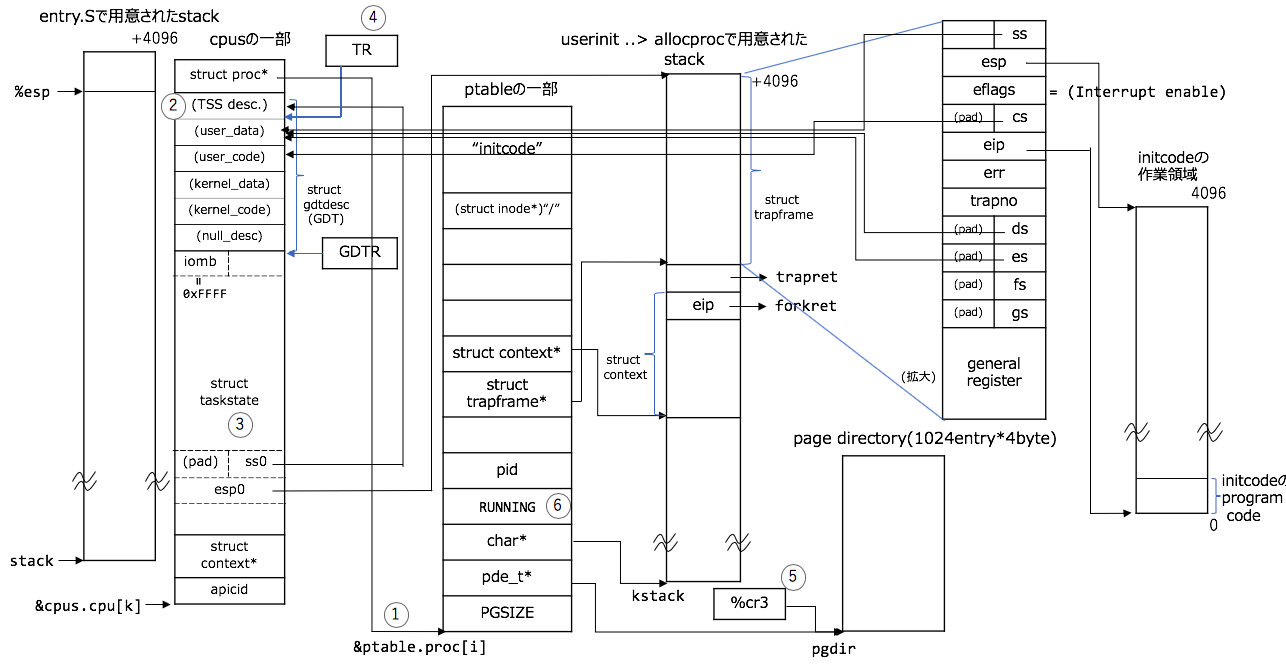
// schedulerの中身のつづき
// 1.cpuのproc構造体と先ほどまで構成していたprocAを結びつける
c->proc = p;
// 2~5: 下記を参照
switchuvm(p);
// 6. procAの状態をRUNNABLEからRUNNINGに切り替える
p->state = RUNNING;
switchuvm(struct proc *p)
{
if(p == 0)
panic("switchuvm: no process");
if(p->kstack == 0)
panic("switchuvm: no kstack");
if(p->pgdir == 0)
panic("switchuvm: no pgdir");
pushcli();
// 2. TSS(Task State Segment) DescriptorをGDTのentry内に設定
// #define SEG_TSS 5 // this process's task state
// #define SEG16(type, base, lim, dpl) (struct segdesc)
// #define STS_T32A 0x9 // Available 32-bit TSS
mycpu()->gdt[SEG_TSS] = SEG16(STS_T32A, &mycpu()->ts,
sizeof(mycpu()->ts)-1, 0);
// uint s : 1; // 0 = system, 1 = application
mycpu()->gdt[SEG_TSS].s = 0;
// 3. TSSの設定
// struct taskstate ts; // Used by x86 to find stack for interrupt
mycpu()->ts.ss0 = SEG_KDATA << 3;
// uint esp0; // Stack pointers and segment selectors
mycpu()->ts.esp0 = (uint)p->kstack + KSTACKSIZE;
// setting IOPL=0 in eflags *and* iomb beyond the tss segment limit
// forbids I/O instructions (e.g., inb and outb) from user space
mycpu()->ts.iomb = (ushort) 0xFFFF;
//0x101 << 3
// asm volatile("ltr %0" : : "r" (sel)); // Load Task Register
// The contents of Task register is segment selector. See Intel SDM vol.3 Fig2.6 and Ch2.4.4
// 4. TSSをTR(Task Register)にロード
ltr(SEG_TSS << 3);
// 5. procAのpaging設定を`%cr3`にロード
// asm volatile("movl %0,%%cr3" : : "r" (val));
lcr3(V2P(p->pgdir)); // switch to process's address space
popcli();
}
冒頭と最後のpushcli/popcliはcli, sti instructionの拡張です。 https://github.com/mit-pdos/xv6-public/blob/b818915f793cd20c5d1e24f668534a9d690f3cc8/spinlock.c#L100-L102 を参照すればまぁ良いんじゃないかと。
5. procAのpaging設定を%cr3にロードの部分はprocAのpagingの設定を%cr3(Page Directory Base Register(PDBR))に反映させている部分です。このregisterに関しては、前回の記事の https://qiita.com/knknkn1162/items/cb06f19e1f999bf098a1#page-directory%E3%81%AEaddress%E3%82%92%E3%83%AC%E3%82%B8%E3%82%B9%E3%82%BF%E3%81%AB%E3%83%AD%E3%83%BC%E3%83%89 に書いています。
その他の、2. TSS(Task State Segment) DescriptorをGDTのentry内に設定と、3. TSSの設定ですが、ここは、initcodeがint $SYS_CALLを呼び出したときに効いてくる部分なので、ここの部分はinterruptの記事に回します!(大事な箇所ではありますが...)
準備が終わっていよいよswtch関数ですが、switchingの本質的な関数となります。
switchingする直前と直後はどうなっているのか
ここでは、%esp(stack pointer)がダイナミックに移動する部分ですので、特に%espに注目してください![]()
swtch
いよいよswtchです![]() とは言ってもここまで丁寧に追ってきたので、switching自体はむずくありません。ここから
とは言ってもここまで丁寧に追ってきたので、switching自体はむずくありません。ここからentry.Sで用意されたstackの挙動を追っていきます。
// scheduler関数の中身の続き
// void swtch(struct context **old, struct context *new);
swtch(&(c->scheduler), p->context);
switching前夜
swtch関数は引数ありなので、引数がstackに積まれます。詳しくは、このシリーズの最初の記事の https://qiita.com/knknkn1162/items/9bd54e165c6c9edca49b#%E5%BC%95%E6%95%B0%E3%82%92%E6%8C%81%E3%81%A4%E5%A0%B4%E5%90%88 に書いています。
重要なのが、switchkvm(); // switch page tableへのaddressをstackに積んでいることです。
これがあるため、scheduler関数の再開でもちらっとみたように、scheduler関数に戻れるのでした。詳しくはsched関数の呼び出し ~ swtch呼び出し ~ scheduler関数の再開までの章で解説します。
図とコードを対応させると、こんな感じ:
0. `swtch(&(c->scheduler), p->context);`で呼ばれるので、引数とreturn先のaddressがstackに積まれる
1. 第一引数を取り出す
2. 第二引数を取り出す
3. 現在のregisterを保存する
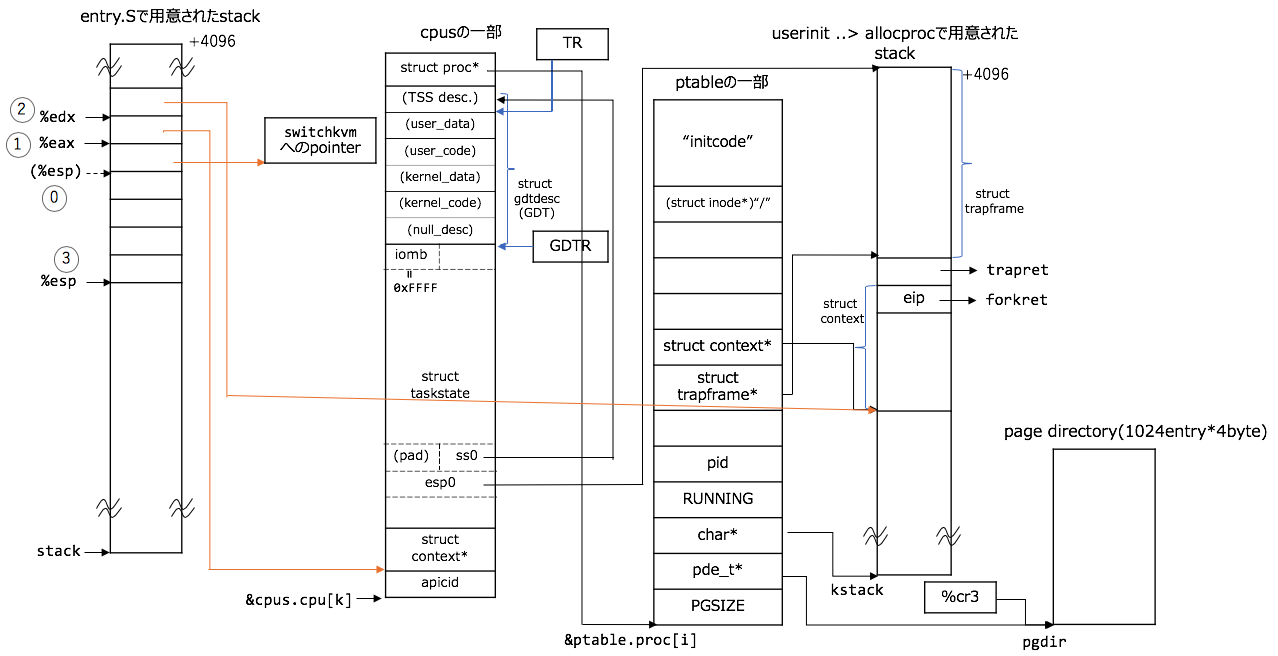
// 0. `swtch(&(c->scheduler), p->context);`で呼ばれるので、引数とreturn先のaddressがstackに積まれる
// # void swtch(struct context **old, struct context *new);
.globl swtch
swtch:
// 1. 第一引数を取り出す
movl 4(%esp), %eax
// 2. 第二引数を取り出す
movl 8(%esp), %edx
// 3. 現在のregisterを保存する
pushl %ebp
pushl %ebx
pushl %esi
pushl %edi
-
第一引数は
struct context**、第二引数はstruct context*なので、橙色で指し示した部分になります。
(第二引数の矢印の先に注意。もし、&procA->contextだと、型がstruct context**になってしまう) -
swtchuvmへのpointerをeipメンバと解釈すれば、上図の%espはstruct context*のアドレスにちょうど対応しています。というより、そうなるように、汎用registerをstackにpushしたのでした。 -
swtchを呼んだ(
callinstructionに対応)ので、以下のようにその次のinstructionへのpointer(下記でいうと、call swtichkvmを指し示すアドレス(0x801039e0))がstackに積まれています(sched関数の呼び出し ~ swtch呼び出し ~ scheduler関数の再開までの章でこの部分が重要になります):
// https://gist.github.com/knknkn1162/9149a610070a8bd14486c5533def1876#file-kernel-asm-L10302-L10306 より
// 中略
swtch(&(c->scheduler), p->context);
801039d4: 89 3c 24 mov %edi,(%esp)
801039d7: 89 44 24 04 mov %eax,0x4(%esp)
801039db: e8 0b 0b 00 00 call 801044eb <swtch>
switchkvm();
801039e0: e8 6b 2b 00 00 call 80106550 <switchkvm>
// 省略
switching
たった2行ですが、これも図とコードを番号で対応させましょう:
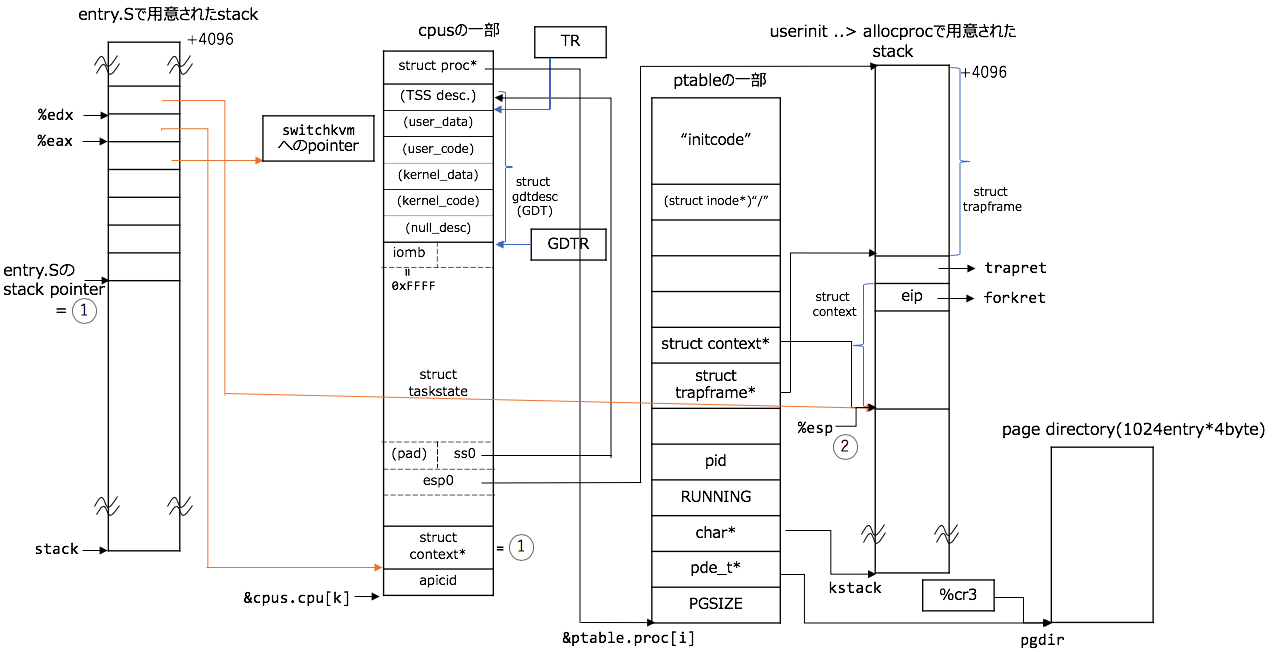
// swtch: の続き
# Switch stacks
// 1. entry.Sのstack pointerを自身のcpu構造体の`struct context *scheduler`に保存する
movl %esp, (%eax)
// 2. %esp registerをprocAのstack領域内のaddressに書き換える。
movl %edx, %esp
%espがuserinit > allocprocで用意されたstack領域内に移動しましたね? switchingがこれで完了しました!
自身のcpu構造体のstruct context *schedulerに古い方のstack pointerの値を保存しています。sched関数の呼び出し ~ swtch呼び出し ~ scheduler関数の再開までの章にて%espがこの保存されたstack pointerのaddressにrestoreします。
switching完了後
switchingは理解できたでしょうか。あとは、新しいprocessの%esp上のstack領域で、registerを復元しつつ、%espを 引き上げるだけです:
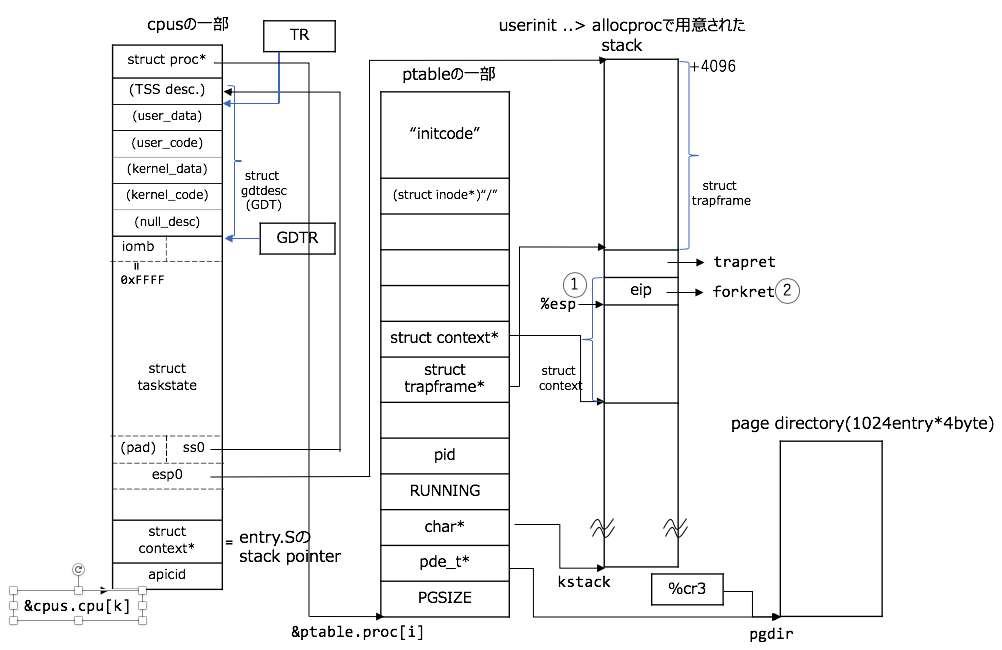
// swtch: の続き
// 1. registerを復元する(結果的に`%edi=%esi=%ebx=%ebp=0`となり、`0`に初期化される。
popl %edi
popl %esi
popl %ebx
popl %ebp
// 2. `%eip`に`forkret`関数へのaddressをpopして、`%eip`のaddress先(つまりforkret関数)にjump!!
ret
sched関数の呼び出し ~ swtch呼び出し ~ scheduler関数の再開までの章まで、entry.Sで用意されたstackは使用しないので、ご退場いただきました。retについては、一番目の記事のhelloの関数化の節の関数が呼ばれる仕組みを参照してください![]()
https://qiita.com/knknkn1162/items/9bd54e165c6c9edca49b#hello%E3%81%AE%E9%96%A2%E6%95%B0%E5%8C%96 の終わりの部分に書いたように、
%espが指し示している部分(forkretへのaddress)が%eipにpopされ、%eipがそのaddressにjumpするのでした。
これでswitching自体の挙動は説明したのですが、ここからの関数へのジャンプの仕方が、ぷよぷよでいう連鎖の本番なので、この後の挙動もみていきましょう![]()
ということで、forkretへと続きます...
switchingした後はどうなるのか
switchingし終わったので、procAのstack領域で作業していくことになります。forkretにjumpした直後はこんな感じの模式図になっています:
forkret()
forkretはあんまり大したことやっていなくて、inodeの初期化くらいです。inodeについては、The Linux Programming Interfaceのch.14 File Systemを読めば良いかと思います(こちらは、ext2 file systemの文脈ですが)
また、%eipにpopして、スタックポインタの%espが引き上がります。%eipはtrapret関数へのaddressなので、そこにjumpします!
trapret()
今回は、%espの移り変わりが重要なので、%espの移動と番号を図で対応させておきます:
.globl trapret
// 0. (現在の状態)
trapret:
// 1. general registerを復元(pop)する
popal
// 2. %es, %ds, %fs, %gs(segment register達)を復元(pop)する
popl %gs
popl %fs
popl %es
popl %ds
// 3. trapnoとerrは無視して、%espを引き上げる
addl $0x8, %esp # trapno and errcode
// 4. %eip, %cs, %eflags, %esp, %ssを復元する。
// 5. `%eip`はinitcodeへのprogram codeのentrypointであるので、jump!
iret
// 6. user 領域でprogram が実行されることになる。(今まで全てkernel領域で作業していた!!)
ここでのポイントおよび難所はiretです。
iretについて理解するためには、2つの問いに答える必要があります:
-
iretとretはどう違うの? -
なぜ
trapretではret`を呼び出さないの?
iretとretはどう違う?
retがcallと対応関係にあるように、iretは、interrupt(or exception)呼び出しと対応関係にあります5 interruptの本格的な説明は次の記事あたりでお話ししたいのですが、iretと関係ある部分だけ説明します:
cliでinterruptがOFFでない限り、いつでもinterruptが呼び出されます6。interrupt呼び出しの直後はhardwareが自動的に以下のことを行います^interrupt:
1-1: 現状の%ss, %esp registerを一時的に退避させておく
1-2: TSS(Task State Segment)に保存されている%ssおよび%espを復元する(%espの変更により、user spaceからkernel spaceに移動している)
2: 1で退避させていた%ssと%espをstackに積む(%espは移動)
3: 現状のEFLAGS, %cs, %eip registerをstackに積む
4: (exceptionの場合)error codeがあればそれもstackに積む(今回はinterruptなので積まれない)
TSS(Task State Segment)に関しては本記事では説明していませんが、TSS領域内に%ssや%espが保存されています7。
上記の前後ではこんな感じになります:
Intel SDM vol.3 ch.6.12.1 Exception- or Interrupt-Handler Procedures の図より引用
iretはinterruptでやったことの逆をhardware側で自動的に行います。
つまり、interrupt前の状態に戻すため、積まれたstack内のregister(%eip, %cs, %eflags, %esp, %ss)の値を復元(pop)します。
なぜtrapretではretを呼び出さないの?
iretのセマンティクスについては理解したところで、なぜretを用いないの?という疑問が起こります。そもそも、interruptは起こっていないので、iretを使うのは一見すると変です。
まず、そもそものところから、解決すると、retがcallと対応関係にある と言いましたが、 https://qiita.com/knknkn1162/items/9bd54e165c6c9edca49b#ret-instruction%E3%81%AE%E5%BF%9C%E7%94%A8 でも書いたように、必ずしも対になって呼ばれる必要はありません。
これと同様に、interrupt呼び出しとiret instructionは必ずしも対になって呼ばれる必要はありません。かなり不思議な感じがしますが、こういう風に解釈できます。
callを呼ばずにretのみを呼び出したときのことは https://qiita.com/knknkn1162/items/9bd54e165c6c9edca49b#ret-instruction%E3%81%AE%E5%BF%9C%E7%94%A8 にて書いてありますが、コード部分を再掲します:
// https://qiita.com/knknkn1162/items/9bd54e165c6c9edca49b#ret-instruction%E3%81%AE%E5%BF%9C%E7%94%A8 の例を復元した
.text
.globl main
main:
movl $exit, %eax
pushl %eax
jmp hello
hello:
movl $0x04, %eax
movl $0x01, %ebx
movl $message, %ecx
movl $12, %edx # length
int $0x80
ret
exit:
# exit
movl $0x01, %eax
xorl %ebx, %ebx
int $0x80
message:
.ascii "Hello world\n"
jmp helloする前にpushl %eaxでstackに積む動作を行なっています。これはcall hello相当の必要な準備をhello関数の最後のretのためにする必要がある、という解釈ができます。
これをinterrupt呼び出しとiret instructionの場合に適用すると、iret呼び出しの前にinterrupt相当の必要な準備をtrapret関数の最後のiretのためにする必要がある、という解釈ができます。
まぁ、ちょっとまだ気持ち悪い感じはあると思いますが、ニュアンスは伝わったと思います(思いたい..)
そうなると、次の論点は、「interrupt相当の必要な準備」って何ですか?ということです。種明かしをすると、ここに仕込んでありました:
// userinit(void) の続き
memset(p->tf, 0, sizeof(*p->tf));
p->tf->cs = (SEG_UCODE << 3) | DPL_USER;
p->tf->ds = (SEG_UDATA << 3) | DPL_USER;
p->tf->es = p->tf->ds;
p->tf->ss = p->tf->ds;
// #define FL_IF 0x00000200 // Interrupt Enable
p->tf->eflags = FL_IF;
p->tf->esp = PGSIZE;
p->tf->eip = 0; // beginning of initcode.S
// (省略)
struct trapframe {
// registers as pushed by pusha
uint edi;
uint esi;
uint ebp;
uint oesp; // useless & ignored
uint ebx;
uint edx;
uint ecx;
uint eax;
// rest of trap frame
ushort gs;
ushort padding1;
ushort fs;
ushort padding2;
ushort es;
ushort padding3;
ushort ds;
ushort padding4;
uint trapno;
// below here defined by x86 hardware
uint err;
uint eip;
ushort cs;
ushort padding5;
uint eflags;
// below here only when crossing rings, such as from user to kernel
uint esp;
ushort ss;
ushort padding6;
};
上のコードにて、復元先の%eip, %cs, eflags, %esp, %ss registerを設定します。
最後の論点は、なぜ、retでなくiretなの? というところですが、これはkernel landからuser landへ移行できるinstructionがiret instructionしか存在しないから8です。trapretの直前まで、kernel landで動作していましたが、initcodeはuser landで動作するコードなので%csやEFLAGS registerの再設定が必要ということで、retでなくiretを使用します。
かなりむずいと思われますので、わからんかったら、とりあえず、initcodeまで飛べるんやな、と思っていただいて大丈夫です![]()
initcode
initcodeに突入した直後は図のようになります:
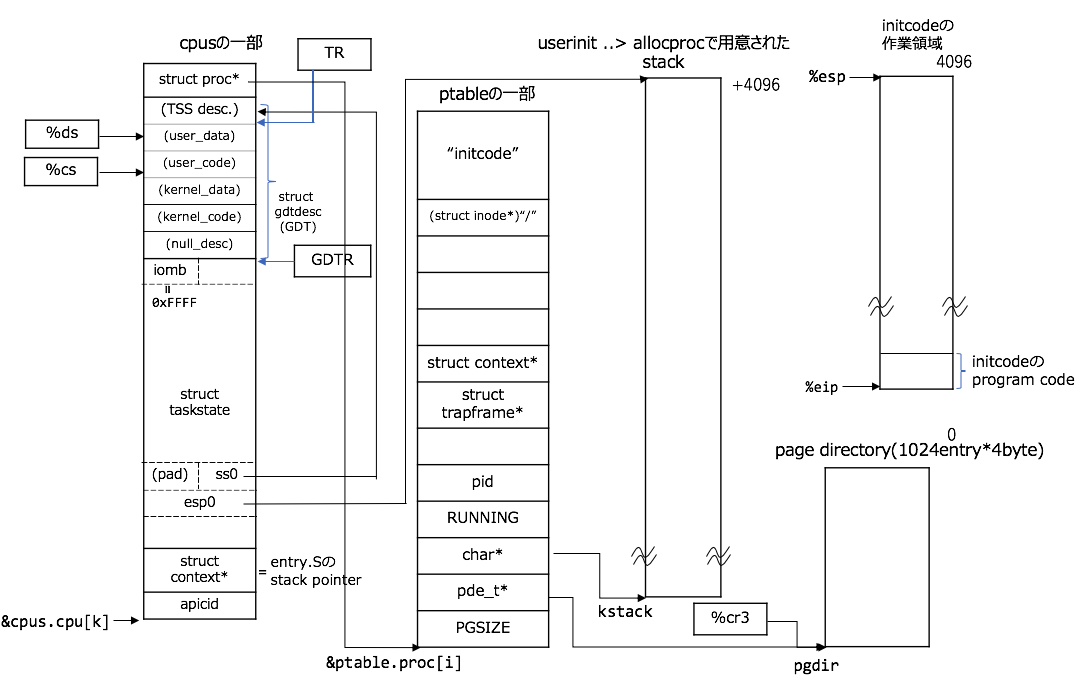
大きなポイントとしては、前節まではkernel landからuser landへ移動したことです! (とは言っても、すぐにint $T_SYSCALLにて、kernel landに引き戻されるのですが![]() )
)
.globl start
start:
pushl $argv
pushl $init
pushl $0 // where caller pc would be
movl $SYS_exec, %eax
int $T_SYSCALL
# for(;;) exit();
exit:
movl $SYS_exit, %eax
int $T_SYSCALL
jmp exit
# char init[] = "/init\0";
init:
.string "/init\0"
# char *argv[] = { init, 0 };
.p2align 2
argv:
.long init
.long 0
本記事でやるのはswitchingなので、int $T_SYSCALLの直前で一旦終わりです。pathが"/init"であるバイナリ(これは、init.cをコンパイル、リンクしたあとのELF形式のbinaryです)で、引数をunixのexitとおんなじように設定し、あとは、x86のint 0x80呼び出しと似たような感じでint $T_SYSCALLを呼び出します。
このあと、 `initcode.S`の`int $T_SYSCALL`が実行された後の節にもある通りになりますが、直後の動きとしては、struct cpu構造体のstruct taskstateに設定しておいた値がregisterに復元され... という流れになります。
詳細は、interruptが深く関わってくるので、別の記事でお話ししたいと思います![]() お楽しみに!!
お楽しみに!!
sched関数の呼び出し ~ swtch呼び出し ~ scheduler関数の再開まで
前章で scheduler関数 -> initのprocessが動作するまでを説明しました。ここでは、CPUがprocessからscheduler関数へと戻るまでの流れを説明します。ここでいうprocessはinit processでも良いし、他の動作しているprocessでも同じですが、以下のタイミングでswtch呼び出し ~ scheduler関数の再開されます:
-
RUNNINGの状態のprocessが
waitやsleep,exitなどにより、状態が切り替わるとき -
timerによるinterruptで強制的に別のprocessに切り替えるとき
本章では、前者の挙動をみます。後者はinterruptの記事で取り上げます。
wait, sleep, exitは関数を辿って行くと9、schedに落ち着きます:
wait -> sleep(状態がSLEEPINGに) -> sched
sleep -> sleep(状態がSLEEPINGに) -> sched
exit(状態がZOMBIEに) -> sched
3つの関数をみればわかるとおり、いままで RUNNINGだったprocessの状態が変化した後、sched関数に突入します:
void
sched(void)
{
int intena;
struct proc *p = myproc();
if(!holding(&ptable.lock))
panic("sched ptable.lock");
if(mycpu()->ncli != 1)
panic("sched locks");
if(p->state == RUNNING)
panic("sched running");
if(readeflags()&FL_IF)
panic("sched interruptible");
// Were interrupts enabled before pushcli?
intena = mycpu()->intena;
// save the current context in proc->context and switch to the sched context previously in cpu->scheduler
// both args are the type of `(struct context**, struct context*)`, which saves registers for kernel context switches.
swtch(&p->context, mycpu()->scheduler);
mycpu()->intena = intena;
}
大事なのが、swtchなので、その確認です。swtchはmain > scheduler > swtchで一度でてきたswitchingの部分の一番本質的なコードのあった関数でした。
swtch
.globl swtch
swtch:
# former context
movl 4(%esp), %eax
# latter context
movl 8(%esp), %edx
# Save old callee-saved registers
pushl %ebp
pushl %ebx
pushl %esi
pushl %edi
# Switch stacks
movl %esp, (%eax)
movl %edx, %esp
# Load new callee-saved registers
popl %edi
popl %esi
popl %ebx
popl %ebp
// now eip=forkret
ret
またこのコードに行き着きました。
switching前夜
また、図とコードを番号とともに対応させておきます:
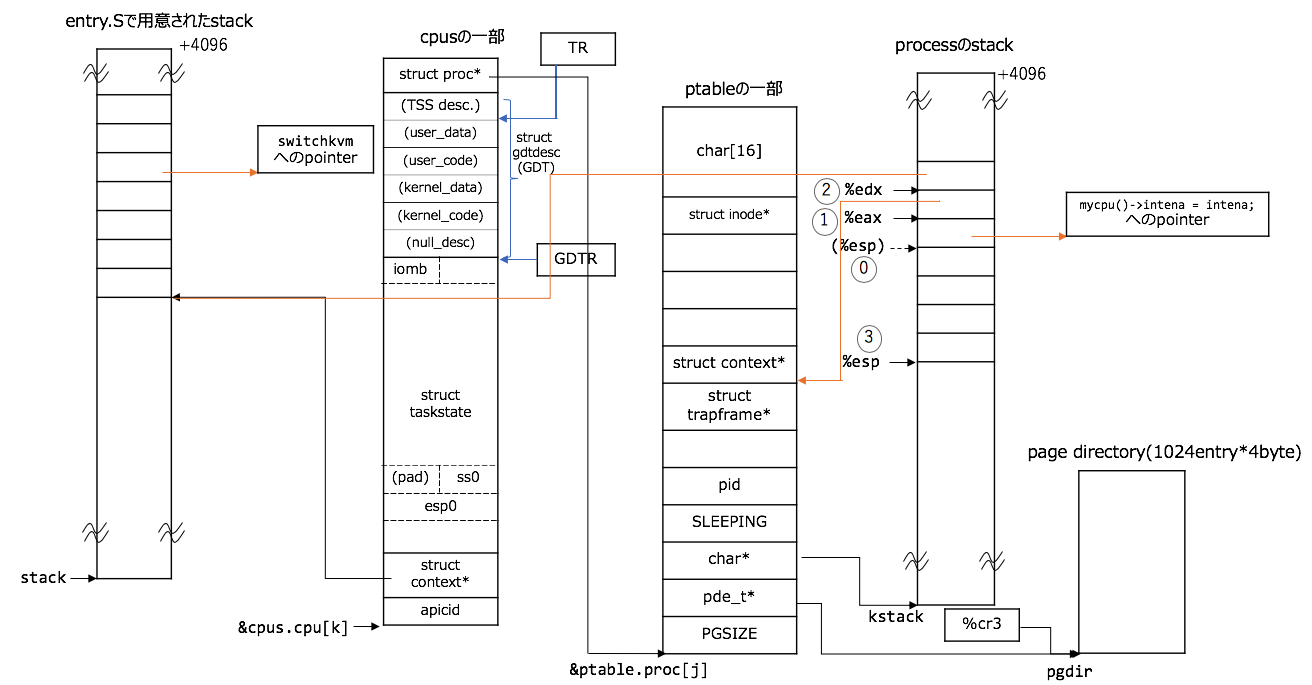
// 0. `swtch(&p->context, mycpu()->scheduler);`で呼ばれるので、引数とreturn先のaddressがstackに積まれる
// # void swtch(struct context **old, struct context *new);
.globl swtch
swtch:
// 1. 第一引数を取り出す
movl 4(%esp), %eax
// 2. 第二引数を取り出す
movl 8(%esp), %edx
// 3. 現在のregisterを保存する
pushl %ebp
pushl %ebx
pushl %esi
pushl %edi
第二引数と図との対応に注意しましょう。また、3の時点では前に述べたswitchingと同じように%espをstruct context*のaddressと解釈できます。
switching
同様に、図とコードを番号とともに対応させておきます:
// .globl swtch
// swtch:
# Switch stacks
// 1. procAのcontextを自身のcpu構造体の`struct context *scheduler`に保存する
movl %esp, (%eax)
// 2. %esp registerをscheduler processのstack領域内のaddressに書き換える。
movl %edx, %esp
switching完了後
後は同様に新しいprocess(scheduler process)の%esp上で、registerを復元しつつ、%espを 引き上げるだけです:
retの後は、switchingする前はなにがどうなっているのかの章の部分でもお話ししたように、switchkvm(); // switch page tableへのaddressにjumpします。
scheduler()からRUNNABLEのprocessにjump
scheduler関数の続き
for(;;) {
// 中略
// switch current context to next context
// void swtch(struct context **old, struct context *new);
swtch(&(c->scheduler), p->context);
switchkvm(); // switch page table
// Process is done running for now.
// It should have changed its p->state before coming back.
c->proc = 0;
}
release(&ptable.lock);
}
}
swtch関数の長旅(!!)が終わりました。ここからはpagingがscheduler processのものに変わりますので、switchkvm();にて%cr3にpage directoryを再ロードします。
いままでc->proc = pだったものがc->proc = 0;で終わり、for文が終わります。
// scheduler関数の続き
for(;;){
// Enable interrupts on this processor.
sti();
// Loop over process table looking for process to run.
acquire(&ptable.lock);
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++){
if(p->state != RUNNABLE)
continue;
// Switch to chosen process. It is the process's job
// to release ptable.lock and then reacquire it
// before jumping back to us.
c->proc = p;
switchuvm(p);
p->state = RUNNING;
// switch current context to next context
// void swtch(struct context **old, struct context *new);
swtch(&(c->scheduler), p->context);
ここの内容は、mpmain()のscheduler()の節でみた通り、
1: RUNNABLEのprocessを見つけ、
2: c->proc = pにて、CPU実行するprocessを結びつけて、
3: switchuvmにて
3-1: taskの作成、task registerへのdescriptorのロード
3-2: procAのpagingを%cr3(page directory base register (PDBR))に再ロード
を行い、swtchに突入した後は、switchingする直前と直後はどうなっているのかの章でみた通りです。swtchでswitching完了後はpを上記のprocessとしたときのp->tf->contextにあるforkretを実行します10 ただし、 https://github.com/mit-pdos/xv6-public/blob/b818915f793cd20c5d1e24f668534a9d690f3cc8/proc.c#L403 のとおり、firstはもはや011なので、早々とtrapretを実行し、p->tf->eip で格納された関数にジャンプし、関数を実行することになります。
長期出張から帰ってきて、また出張に出かけて行く船乗りのようなやつでした![]()
まとめ
xv6(OS)にて、
- switchingする前はなにがどうなっているのか
- switchingする直前と直後はどうなっているのか(設定内容の保存、復元を行うわけですが..)
- switchingした後はどうなるのか
を説明しました。随所随所でinterruptの部分を最低限拾いながら、死ぬほど詳しく解説したつもりです![]()
根本的に間違っているとか、ちょっと間違っているとかでもご指摘くだされば嬉しいです!
-
https://stackoverflow.com/a/29035523 あたりを参考にしました ↩
-
これは、で作成されたraw binaryファイル
initcodeのサイズです。詳しくは、_binary_objfile_startと_binary_objfile_sizeについての節を参照にしてください。 ↩ -
例外的に、
xchginstructionでオペランドの一つがmemory addressだった場合はlockがかかるため、atomicとなります。詳細は、Intel SDM vol.3 ch. 8.1.2.1 Automatic Lockingを参照のこと。 ↩ -
実際には、他のCPUが
mpenter > mpmain > schedulerときて、このprocessを獲得している場合があるので、bootasmから続いてきているCPUでこのprocessが見つからずに,他のRUNNBALEのprocessが訪れるまでfor(;;){の中身を繰り返す可能性があります。 ↩ -
Intel SDM vol.3 ch.6.12.1 Exception- or Interrupt-Handler Procedures に
To return from an exception- or interrupt-handler procedure, the handler must use the IRET (or IRETD) instruction.とある ↩ -
もちろん、APIC(Advanced Programmable Interrupt Controller)が適切に設定されているのを前提としてる ↩
-
TSS(Task State Segment)については、Intel SDM vol.3 Figure 7-2. 32-Bit Task-State Segment (TSS) に図があります ↩
-
http://jamesmolloy.co.uk/tutorial_html/10.-User%20Mode.html を参考にしました。
The x86 is strange in that there is no direct way to switch to user mode. The only way one can reach user mode is to return from an exception that began in user mode. The only method of getting there in the first place is to set up the stack as if an exception in user mode had occurred, then executing an exception return instruction (IRET).と書かれています。 ↩ -
wait, sleep, exitの他にも状態が変化する関数はあります。 ↩
-
fork関数と
userinit(これはboot時のみ)関数だけがprocessを作成(forkの場合は複製)する。両者、allocproc関数がp->tf->context = forkretと定めているので。いかなる場合でもforkretから実行されることになる。 ↩ -
ここまで理解しているなら補足不要だと思いますが、
static int first = 1;はfirst変数が一度のみ初期化されるという意味です。staticキーワードで調べてみるとわかると思います。 ↩