きっかけ
「AI開発チームが「餅つき」をする理由」を紹介されたので、将棋AIで学んだ次の一歩を物体検出に決めました。
テレビ放送は見てないのでニュアンスは知りませんが記事から「正解をたくさん教え込まなければならないってエキスパートシステム作ってた人の発想か、GAN以前からDLの流れを追い損ねてね?」と印象を受けた。
技術調査@Qiita記事
道具と対象
- Chainer
- 将棋AIのときに環境整えたし、いまのところ評判良いからChainer
- 使用フレームワークに制約がないお勉強なら日本製を応援する価値があると思うからChainer
- SSD
- chainer+BoundingBoxでググったら一番めYOLO、二番目SSDだった
- 学習が速そうだからSSD
- 論文を和訳してみたありがたい方がいらっさるからSSD
- ChainerCV
- 以上を踏まえてchainer+SSDでググったらchainercvにsampleがありました
- 学習データは手書きの記号にしてみる
- Pascal VOCの学習済モデルはchainercvのexampleに公開されてるので
- ひとまずお米と☆を参考に手作りデータでやってみたい
やること
- chainercvインストール
- デモを動かしてみる
- 学習データをつくる
- アノテーションつける←ここを沢山はやりたくない
- 学習する
環境
再掲
ハード
CPU:i7-4770S @ 3.10GHz
GPU:GeForce GTX 750 Ti ドライバーのバージョン391.24
ソフト
Microsoft Windows 10 Pro (x64)
Visual Studio Community 2017
CUDA9.0
cuDNN7.1.2
python3.6.4(Anaconda3 5.1.0)
chainer3.5.0
cupy2.5.0
さきに結果
- ネットワーク構造の見直しなしです。
- 今回覚えさせた3図形に反応します。
- 転移学習がやり方をちゃんと知らないまま出来ちゃったという感じです
- ソースはこちらです
- google colab向けnotebookはこちらです
試行錯誤と手順
chainercvインストール
- 参考:本家(Linux版のみ)
- ChainerCVをダウンロード(git|zip)してルートディレクトリへ移動
cd chainercvしておく
chainercvインストール
>conda env create -f environment.yml
>conda activate chainercv
>pip install -e .
デモを動かしてみる
- 適当な画像を用意しておく(仮にa.jpgとしてコマンド実行する)
- pixabayでとんかつとかプチトマトとか検索しとけばよいかと
- 残念ながらダイニングテーブル、鉢植えなどざっくりした分類しか学習していない
a.jpgに対してデモ実行
>python examples\ssd\demo.py --gpu 0 a.jpg
【参考】トレーニング実行
愛機ではOutOfMemory
>python examples\ssd\train.py --model ssd300 --batchsize 32 --gpu 0
代わりにgoogleにやらせる
!apt -y install libcusparse8.0 libnvrtc8.0 libnvtoolsext1
!ln -snf /usr/lib/x86_64-linux-gnu/libnvrtc-builtins.so.8.0 /usr/lib/x86_64-linux-gnu/libnvrtc-builtins.so
!pip install 'cupy-cuda80==4.0.0rc1' 'chainer==4.0.0rc1'
!pip install -U numpy
!pip install chainercv
!git clone https://github.com/chainer/chainercv.git
!python chainercv/examples/ssd/train.py --model ssd300 --batchsize 32 --gpu 0
学習データをつくる
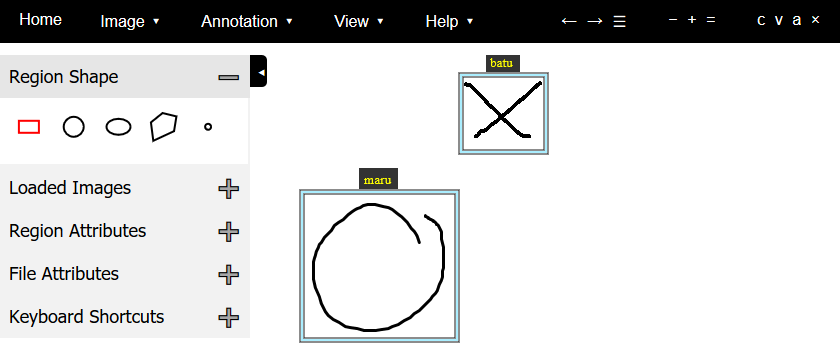
- ペイントで丸、三角、バツを書く
- バウンディングボックスにアノテーションをつける
- VGG Image Annotatorツール
- 導入が一番簡単でHTMLファイル1つで構成されています
- Region Shapeがいろいろ選べるのですが、PASCAL VOCに寄せてRectangleにしておく
- 出力がCSV|JSON、できたらXML(PASCAL VOC format)がよかった
学習する
- 【コード改変】trainとdatasetを変更する
- アノテーションの記録、読み取り方法:XML→JSON(ツールの都合)
- ラベル:車とか人とか12種類のなんか→丸、三角、バツの3種
- PASCAL VOCからダウンロードする→用意した画像を読む
- 画像がJPG→PNG
- アノテーションのファイル数:画像ファイルと同じ→ひとファイル(ツールの都合)
- 学習しようとするとOutOfMemoryになる
- バッチサイズを小さくしてみる
バッチサイズ指定
>python train.py --gpu 0 --batchsize 6
- やっぱりgoogleにやらせる
- ソースと画像はzipにしてgoogle driveにuploadしておく
driveからソースと画像を取得する
# さっきの続き
!pip install -U -q PyDrive
from google.colab import auth
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from oauth2client.client import GoogleCredentials
auth.authenticate_user()
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)
id = 'ファイルの共有をしてIDを確認する、ここは内緒'
downloaded = drive.CreateFile({'id':id})
downloaded.GetContentFile('chainer-bbox.zip')
!mkdir chainer-bbox
!unzip chainer-bbox/chainer-bbox.zip -d chainer-bbox
!ls chainer-bbox
学習実行
import os
os.chdir('chainer-bbox')
!python train.py --gpu 0
- モデル保存が随時のsnapshotでもいいけど回数ついてるし扱い面倒いので最終的なモデルをnpzシリアライズ追加
- あとgoogleでも長いこと終わらないのでイテレート回数減
- で改めて学習開始
検証する
- 【コード改変】demo.pyでつかうラベルの名前を丸、三角、バツにする
- いったん、学習データを丸だけに絞ってみる。かつひとファイルにひと丸だけにしてみる。
- で検出。
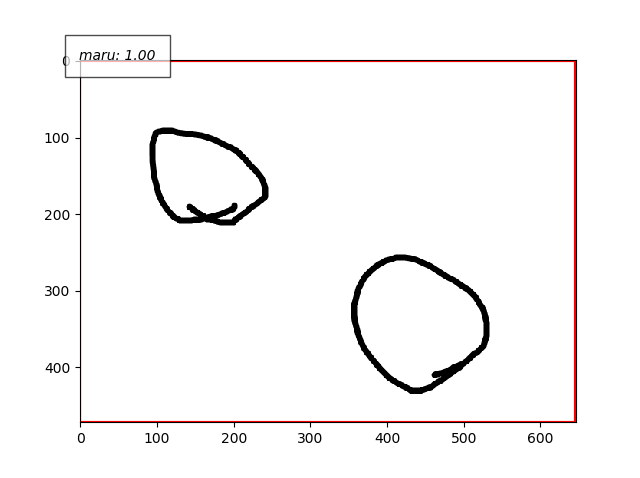
- これ失敗してます。原因は思い当たってます。やはり、学習データのつくりの問題。アノテーションで与えたバウンディングボックス領域が大きすぎました。
- で再度学習やりなおし。
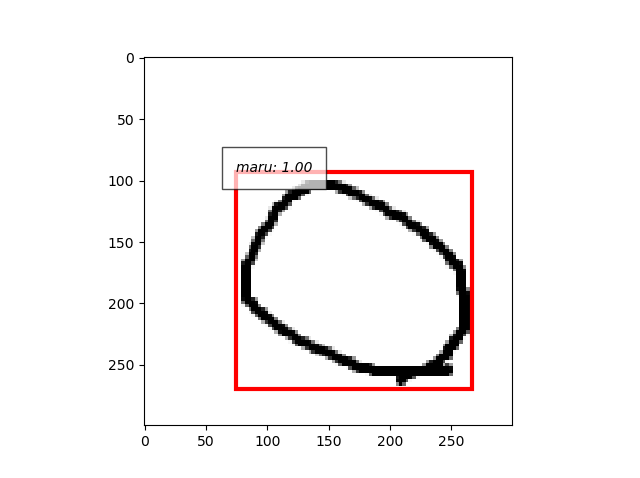
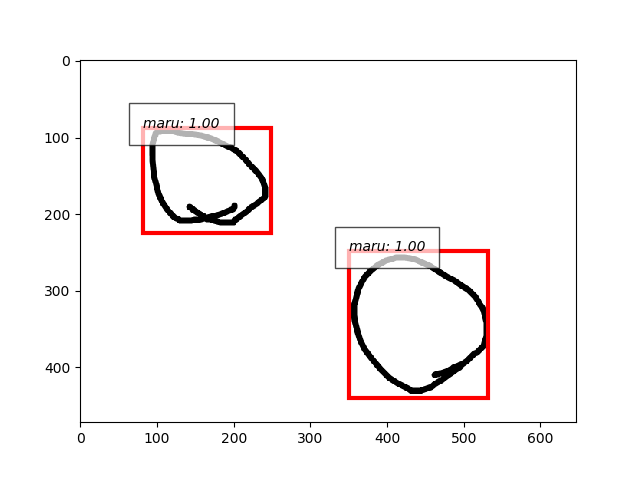
- よし、できた。。。丸だけ。
- 丸の学習データ12枚、検証用4枚の計16枚。ここまで餅つきはしてない。
学習データを餅つきする(準備のみ)
- 使わなくなったけど学習の待ちの間に餅つきのスクリプト書いたので公開します。
- 使い方:バッチファイルにPNGファイルをドロップする。
- または
for /f %%a in ('dir /b *.png') do call _rotate %%aで一括処理できる。とおもう。 - 結果:元画像を90度、180度、270度、および水平反転で8倍に増やしてくれます。
_rotate.bat
if "x"=="x%1" goto usage
call :write_ps %1
call :run_ps
call :del_ps
goto :eof
:write_ps
>%~dpn0.ps1 echo ^
[void][Reflection.Assembly]::LoadWithPartialName("System.Drawing"^);^
$image = New-Object System.Drawing.Bitmap("%1"^);^
$image.RotateFlip("Rotate90FlipNone"^);^
$image.Save("%~dpn1_r90%~x1", [System.Drawing.Imaging.ImageFormat]::Png^);^
$image.RotateFlip("Rotate90FlipNone"^) ;^
$image.Save("%~dpn1_r180%~x1", [System.Drawing.Imaging.ImageFormat]::Png^);^
$image.RotateFlip("Rotate90FlipNone"^);^
$image.Save("%~dpn1_r270%~x1", [System.Drawing.Imaging.ImageFormat]::Png^);^
$image.RotateFlip("Rotate90FlipX"^);^
$image.Save("%~dpn1_x0%~x1", [System.Drawing.Imaging.ImageFormat]::Png^);^
$image.RotateFlip("Rotate90FlipNone"^);^
$image.Save("%~dpn1_x90%~x1", [System.Drawing.Imaging.ImageFormat]::Png^);^
$image.RotateFlip("Rotate90FlipNone"^);^
$image.Save("%~dpn1_x180%~x1", [System.Drawing.Imaging.ImageFormat]::Png^);^
$image.RotateFlip("Rotate90FlipNone"^);^
$image.Save("%~dpn1_x270%~x1", [System.Drawing.Imaging.ImageFormat]::Png^);^
$image.Dispose(^);^
exit /b
:run_ps
powershell -NoProfile -ExecutionPolicy Unrestricted %~dpn0.ps1
exit /b
:del_ps
del %~dpn0.ps1
exit /b
:usage
echo usage: %~nx0 filepath
>nul pause
goto :eof
検証する、つづき
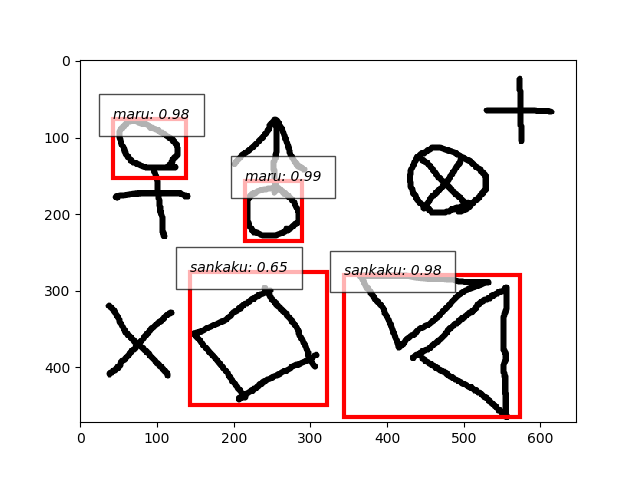
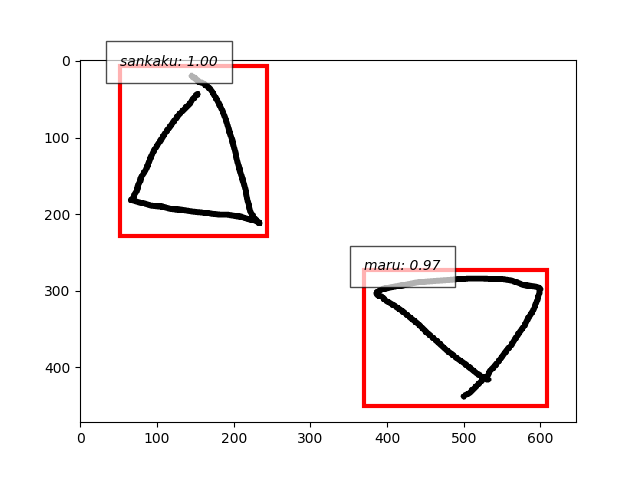
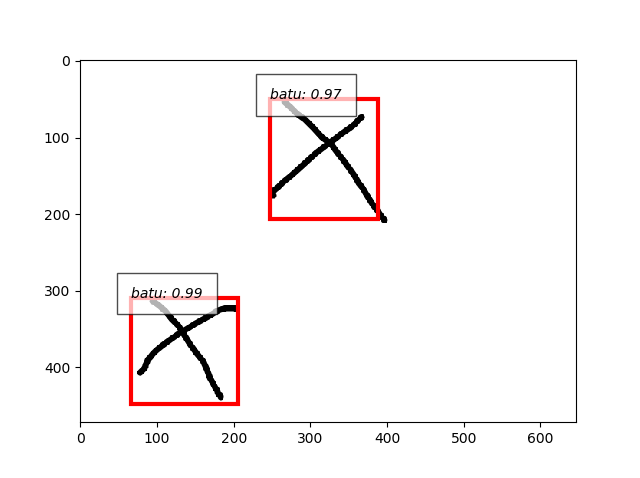
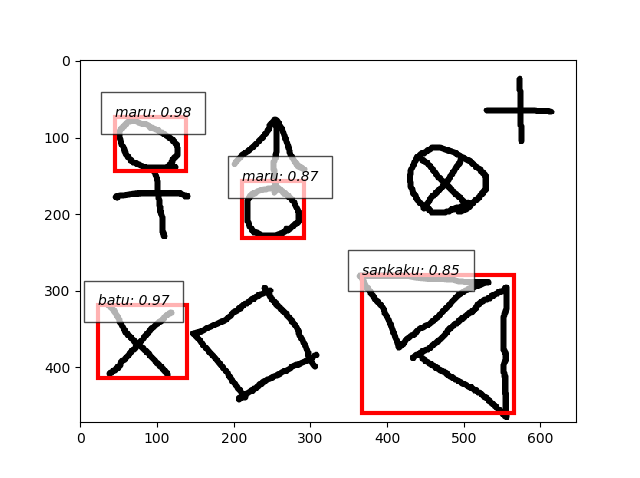
- よし、引き続き三角とバツもいってみます。それぞれtrain10枚、test5枚ずつ。
- 複合画像、丸を検出、三角は誤検出、バツを見逃し、重なった図形はだめ。
- 三角もバツも単独の画像ならいけますね。
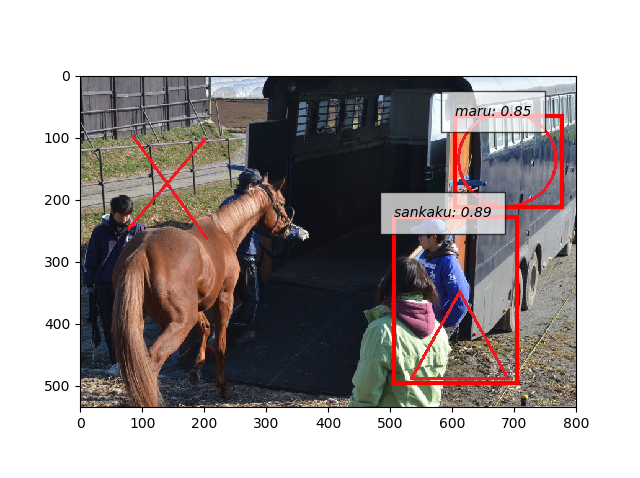
- なお元のモデルと追加学習したモデルで人と馬の写真を検出させると。これはヒドイ。
- 事前

- 事後

- 学習データにノイズを載せました。

- バツも検出できました。
- 写真に図形描画して検出できるようになりました。
- 手書きでもう一度

つぎの一歩
- 気になるキーワードGAN
技術調査
- GANでお米カウント
- DiscoGAN_counter
- DiscoGANのchainer実装※お米の記事で参照してるやつ
- 少ないデータで学習
- chainercvを用いたMask R-CNNの実装
- Chainer_Mask_R-CNN
- Mask R-CNNのRoI AlignとFast(er) R-CNNのRoI Poolingの違い
- 簡単にMask R-CNNを試す方法
どっちにしようDiscoGAN or MASK R-CNN
- どちらもChainer実装があるので愛機環境ですぐ動きそう
- githubの最終更新はDiscoGANは2017年、MASK R-CNNは5日前
- クラス分けまであるしMASK R-CNNをためします
それはまた別のお話
おわり