はじめに
こちらで紹介されていたDiscoGAN(Discover Cross-Domain Relations with Generative Adversarial Networks)
https://arxiv.org/abs/1703.05192
が「教師なし」でイメージ変換ができるということで、前にやってた検出・カウントを教師なしで試してみました。
ChainerでDiscoGANをすでに実装している方がいらっしゃったので、ほぼ使わさせていただきました。
「chainerのtrainer機能を使ってDiscoGANを実装した」
やっていること
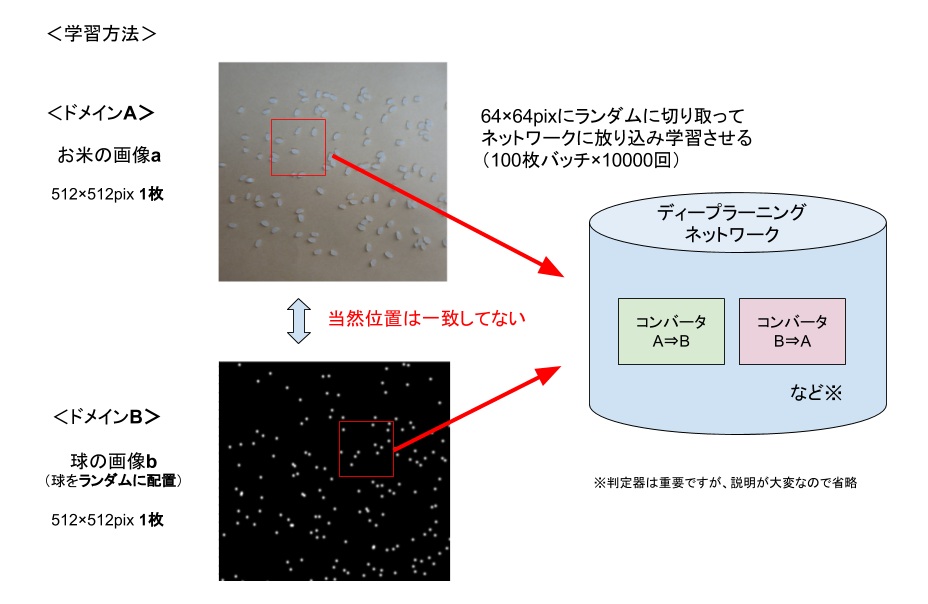
お米の数を数えるために、数えやすい形の画像に変換する「コンバータA⇒B」をつくります。
(これくらいの画像ならば、通常の画像処理を組み合わせれば簡単にカウントできますが、それは置いといて)
いままでと違うポイントは「ランダムに配置」した球の画像を1枚用意するだけで、学習ができます。
球の数は適当に決めましたが、お米の数とオーダはそれなりに合わせてあります。
お米の画像aを1枚、球の画像bを1枚を使って、学習させました。GTX1070で一晩ほどになります。
学習結果
DiscoGANでは「コンバータA⇒B」と「コンバータB⇒A」をオートエンコーダを使って学習するので、位置の情報を保持したまま変換ができるようになってくれます。
お米⇒球、球⇒お米の変換にて、そこそこ位置があったまま変換できているようになっています。

検出・カウント
今回お米の数を数えるので、球変換後の画像abの極大値の位置を抽出して、極大点の画像を作成しています。極大点の抽出にはMaxploolingを使ってます(参考)。元の画像に対し、極大点の位置に赤円を描画してみると、少し位置がずれているのと一粒に2点検出されている部分があるので、まだまだ調整が必要なところです。

おわりに
ディープラーニングでは大量のデータが必要といわれることがありますが、今回も元画像は1枚(米106粒)で学習ができているので、形状が似ているものであればそれくらいのオーダで学習は可能なようです。
今回はとりあえず試しただけでしたが、この他、一部にヒントを与えたり、配置する球の間隔や数を調整することで、狙ったものを検出することもできると思います。また、今回は球は白のみですが、色を複数にすることで、複数の種類のものを同時に検出することも可能かもしれません。さらに、DiscoGANではそもそもドメインBの部分が「画像」である必要性はないはずなので、直接ほしいベクトル(例えばお米の中心点など)に変換することもできるのかもしれません。
また、作成したプログラムはこちらに置いておきます。細かいところは変更するかもしれません。
※GAN系は不安定なことが多いですが、これも何回か試すと学習に失敗することが結構あります。
https://github.com/samacoba/DiscoGAN_counter