追記
2019/07/11 (木):今思うと機械学習のこと何も理解していなかったんだなと思う。戒めとして、この記事は消さずに残しておくことにします。
やろうとしたこと
Deep Learning を使って石原さとみ検出器(ISD: Ishihara Satomi Detector)を作る

環境
OS: Windows 10
GPU: GeForce GTX 950M
Python: 3.5.4
Tensorflow-GPU: 1.5.0
ISD作成の流れ
- 石原さとみの画像収集
- アノテーション
- モデル構築
- Training
- Test(ここで絶望した、、、)
Data収集
-
SeleniumとChromedriverを使用 - Google Image Search で
satomi ishiharaで検索をかける - スクロールと「結果をもっと表示」ボタンのクリックを繰り返す
- 画像の表示枚数が上限に達した段階で
HTML Sourceを保存 -
BeautifulSoupでimg tagからsrcを抽出 -
requestsを使用して、srcから画像をダウンロード(参考)
↓プログラムが動いている様子
アノテーション
今回行うのは物体検出なので、画像 &「どこに石原さとみが写っているか」という2種類の情報が必要。このチュートリアルを参考に、matplotlibを利用したアノテーションツールを作成
matplotlibにこんな使い方があるとは知らなかった、、、

アノテートした領域のLeft TopとRight Bottomの座標を含む以下のようなXMLファイルが出力される
<annotaion>
<folder>satomi_ishihara\original</folder>
<filename>fc5350cadb3c41ee8881503bea0c009a0b41fce78c394bc6aac5011d7ede9f08.jpg</filename>
<src>https://i.pinimg.com/originals/e3/c4/7d/e3c47d5b15cab638aef7248780c9aebc.jpg</src>
<segmented>0</segmented>
<size>
<width>474</width>
<height>474</height>
<depth>3</depth>
</size>
<object>
<name>satomi_ishihara</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>117</xmin>
<ymin>33</ymin>
<xmax>348</xmax>
<ymax>291</ymax>
</bndbox>
</object>
</annotaion>
以上の作業を繰り返して、教師データ(画像とXMLファイルのセット)を作成
Train: 240セット
Test: 60セット
モデル構築
このチュートリアルを参考にモデルを構築。今回、使用したモデルはTensorflow detection model zooのfaster_rcnn_inception_v2_coco。検出するクラスが1種類(石原さとみ)しか無いので、それに合わせてファイルを書き換える必要があり、少々面倒だった
Training
localization_lossが急上昇している点がある、、、
Trainingを開始してから約2時間(約14000 step)でロスが落ち着いてきた(?)ので終了
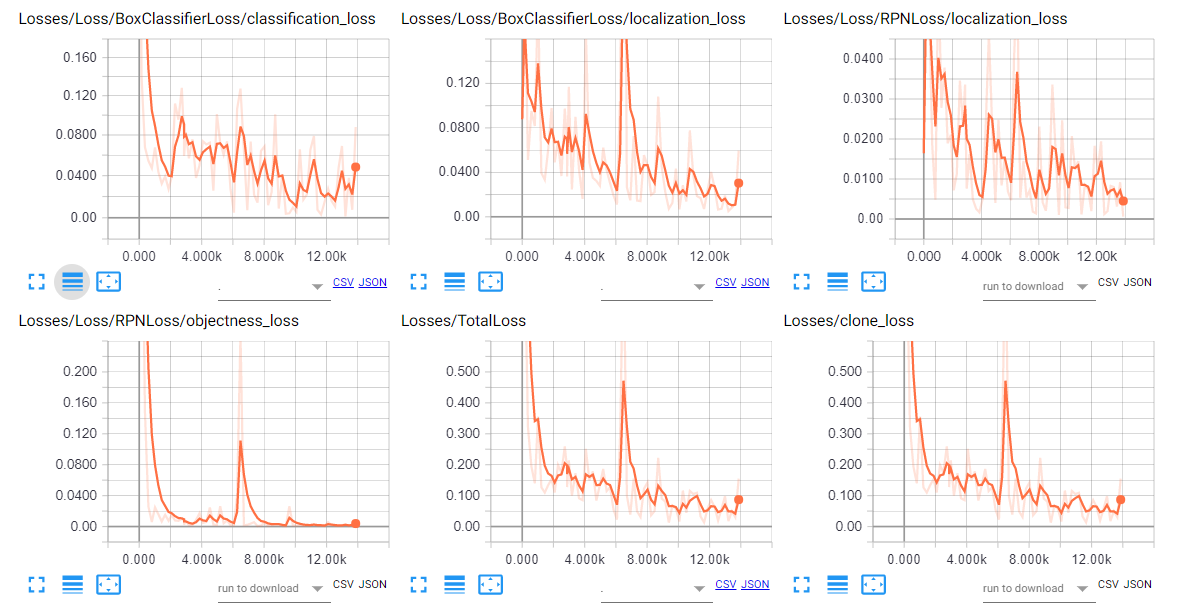
Test(ここで絶望した、、、)
以下がモデルの出力結果、石原さとみ以外の人物も石原さとみと認識されてしまっている・・・


何が問題だったのか?
Training Dataのほとんどが石原さとみのソロ写真だったことが原因だと考えられる。モデルは、石原さとみの顔の特徴ではなく、人間の顔の特徴を学習してしまい、単なる顔検出器と化してしまった
今後の方針
- Training Dataに「石原さとみ + 他の誰か」という構成の写真を追加してみる
- 石原さとみ以外のクラスを追加してみる
乞うご期待