はじめに
CNNベースの高速な物体検出の先駆けであるFast R-CNN1やFaster R-CNN2、最新のMask R-CNN3では、まず物体の候補領域をregion proposalとして検出し、そのregion proposalが実際に認識対象の物体であるか、認識対象であればどのクラスかであるかを推定します。
Fast R-CNN系の手法のベースとなったR-CNN4では、region proposalの領域を入力画像から切り出し、固定サイズの画像にリサイズしてからクラス分類用のCNNにかけるという処理を行っていたため、大量のregion proposalを0からCNNにかける必要があり、非常に低速でした。
 [^1]より引用。
[^1]より引用。
これに対し、Fast(er) R-CNNでは、ある程度畳み込み処理を行ったfeature mapから、region proposalにあたる部分領域をうまく「固定サイズのfeature map」として抽出するRoI Poolingを行うことで、前段の畳込み処理を共通化し、高速化を実現しています。
しかしながら、RoI Poolingの対象となっているfeature mapは入力画像と比較して解像度が低いため、RoI Poolingされた領域が実際に対応している画像領域が、元々のregion proposalの画像領域とずれてしまうという問題がありました。
最新のMask R-CNN3では、この問題を解決するRoI Alignが提案されています。
何気にRoI AlignやRoI Poolingについて、あまり詳細な説明を見たことがない(英語でも雑なのが多い)ので、本稿ではこれらの処理について細かく説明したいと思います。
RoI Pooling
RoI Poolingでは、ある程度畳み込み処理を行ったfeature mapから、region proposalにあたる部分領域をうまく「固定サイズのfeature map」として抽出します。
ここでは説明のため、入力画像サイズを320x480とし、これを解像度が1/32になるCNNにかけることで、10x15のfeature mapが得られたとし、RoI Poolの結果として3x3のfeature mapを抽出したいとします(通常RoI Poolingの出力としては7x7のfeature mapが利用されますが、説明のため3x3としています)。

上記の図のように、元画像のregion proposalの領域を、feature map上に投影してみると、当然feature mapとサブピクセルレベルのずれが発生します。
RoI Poolingでは、このずれを丸め込みながらPoolingを行います。

具体的にはまず、region proposalの座標を整数値に丸め、上記の赤い外接矩形を得ます。この時点で、最大0.5ピクセルのずれが発生します。これは、元画像ではCNNのstrideの半分に相当し、今回の例では32/2=16ピクセルのずれに相当します。
その後、その外接矩形をfeature mapのサイズと同じビン数(ここでは3x3)に等分割します。そして、feature mapのRoI内のピクセルを、それぞれ3x3つのビンのいずれかに割り当て、割り当てられたビンの中でmaxやaverageを取ることで、RoI Poolingの出力を得ます。
上図では、市松模様でfeature mapの各ピクセルの割り当てを表現しています。丸め方やピクセルの割り当て方は色々な方法が考えられます(切り捨ててしまうとか)が、上記の図のような形が誤差を小さくできるのではないでしょうか。
(こちらの動画では、RoIの取得時や、3x3の分割時に切り捨てを行う説明になっているので、かなり誤差があるように見えてしまいますが、オリジナルの論文でも"round"という表記をしています)
何れにせよ、RoIの取得と、ピクセルの割り当て時に丸め誤差が発生し、これがセグメンテーションなどの位置ずれがあまり許されないアプリケーションでは問題になります。
RoI Align
上記のRoI Poolingの問題を解決するのがRoI Alignです。こちらのほうがstraight forwardでアルゴリズムとして分かりやすいです。
RoI Alignでは、まずregion proposalの領域をそのまま3x3に等分割します。
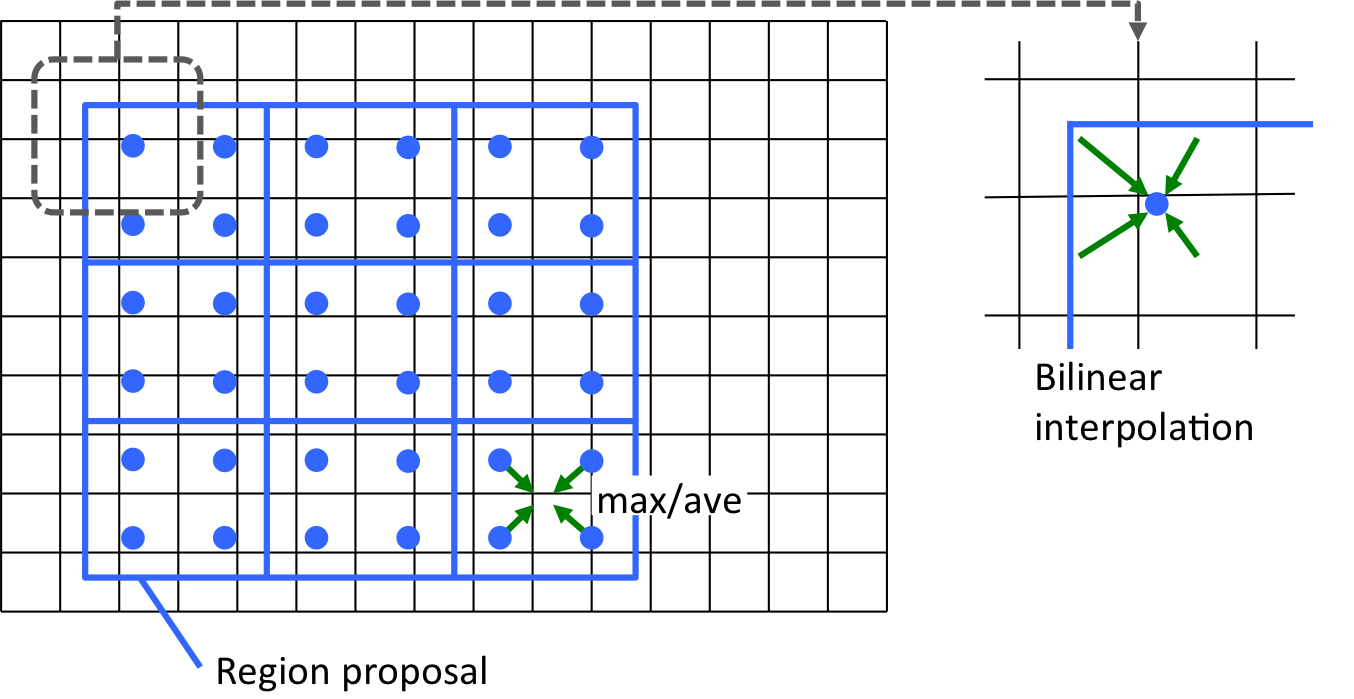
そして、サブピクセル座標を持つ上記のグリッド点の値を、feature mapの近傍4ピクセルからbilinear interpolationを用いて算出します。最後に、各ビンに対応する4つのグリッド点の値をmaxまたはaverageでpoolingすることで、RoI Alignの出力を得ます。
なお、上記のグリッド点をどうとるかは論文中には明記されておらず、下記の記述からの推測になります。ここは実装を確認して情報をアップデートしたいと思います。
著者らの資料にグリッドの取り方があったので修正しました!
compute the exact values of the input features at four regularly sampled locations in each RoI bin
Ross Girshickさんの資料を見る限り、Mask R-CNNのRoIAlignは、14x14のbinの中央から値を取って、mask branchにはそのまま、検出にはpooling噛まして食わせれば良いだろうし、猫が可愛い https://t.co/FWFhpuxqZv pic.twitter.com/4hiyJQEgCi
— Yosuke Shinya (@shinya7y) 2017年10月3日
ちなみに、より単純には、各ビンの中心座標の値をbilinear interpolationし、その値をそのまま利用することも同じように有効だと本文には記載があります。RoIがfeature mapに対して小さい場合には、こちらのほうが良い気すらします。
しかし、この辺りの処理は、feature mapを画像だと見立てると、サブピクセルレベルの画像のリサイズの問題であり、画像処理屋さんからするともっと良いソリューションがあるかもしれません(back propできる処理である必要がありますが)。
ちなみにTensorFlow実装ではRoI Poolingの代わりにresizeが使われているらしいですが、リサイズのアルゴリズムによっては、RoI PoolingよりもRoI Align的な結果が得られ、精度的にも良いとかあるかもしれません。
tensorflow実装はroi poolingの代わりにresize使うんご〜,だってThis is much more efficient and has little impact on resultsンゴ. って書いてあった.
— k3nt0 (@K3nt0W) 2017年8月26日
まじかよ.
実装例
PyTorch実装
https://github.com/felixgwu/mask_rcnn_pytorch
roi_align_kernel.cu の実装を見る限り、「各ビンの中心座標の値をbilinear interpolationし、その値をそのまま利用する」を利用している。
TensorFlow実装
https://github.com/CharlesShang/FastMaskRCNN
こちらのIssue にある通り、tf.image.crop_and_resize を利用してリサイズを行っている。tf.image.crop_and_resize は補間方法としてbilinear interpolationを採用しているので、上記の手法と同じ結果になりそう。
Caffe実装
https://github.com/jasjeetIM/Mask-RCNN
roi_align_layer.cpp を見る限り、各ビンの中心座標を中心とした1ピクセル四方のグリッド上の4点をサンプルしている。本稿の例よりもこちらの実装のほうが適切かもしれない。
-
R. Girshick, "Fast R-CNN," in Proc. of ICCV, 2015. ↩
-
S. Ren, K. He, R. Girshick, J. Sun, "Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks," in Proc. of NIPS, 2015. ↩
-
Mask R-CNN, "K. He, G. Gkioxari, P. Dollar, and R. Girshick, in Proc. of ICCV, 2017. ↩ ↩2
-
R. Girshick, J. Donahue, T. Darrell, and J. Malik, "Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation," in Proc. of CVPR, 2014. ↩