やること
書籍「将棋AIで学ぶディープラーニング」マイナビ出版刊(ISBN978-4-8399-6541-9)
のプログラムコードを動かす。
- サンプルコードが公開されてるけど、学習の実行コマンドのコピペコードがないので本記事に書き起こします
- 学習済モデルもダウンロードできるから要らないっちゃ要らないのですが
- ネットワークをいじくったりして結果にどう差が出るかとか学習したいときにあると良いですよね
- ひとまず手っ取り早く動かして、エラー対処とか改善とかして手法と実装を学ぶ。(0から1のとこでなく、1から10のとこ)
おそくなりましたが書籍紹介
- マイナビBooks:出版元(サポートサイト)
- Amazon:人工知能カテゴリ新着ランキングで1位の流行にのりたい

大筋
-
第Ⅰ部 導入編第とII部 理論編は読む
-
第III部 実践編 『第6章 ディープラーニングフレームワーク』に相当するPythonのインストールとか環境構築は別記事でどうぞ
-
プログラムコードをダウンロード
-
棋譜データをダウンロード
--ここ以降にコマンド実行あり、別章わけます-- -
『第7章 方策ネットワーク(policy network)』で方策を学習する ※メモ
-
『第8章 将棋AIの実装』はディープラーニングでなくゲームAIの実装の話なので省略、本のとおりにやりプログラムの強さ(まだ弱さ?)を実感する
- 将棋所をダウンロード
- 『第9章 学習テクニック』効率化テクニックを学ぶ ※メモ
- 『第10章 価値ネットワーク(value network)』で局面を評価する
- 『第11章 学習テクニック その2』で精度をあげる
- 『第12章 モンテカルロ木探索』はゲームAIの実装の話なので省略
- 『第13章 さらに発展させるために』を読み仕上げる
環境確認
環境確認
>python
Python 3.6.4 |Anaconda, Inc.| (default, Jan 16 2018, 10:22:32) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import cupy
>>> cupy.__version__
'2.5.0'
>>> import cupy.cudnn
>>> import chainer
>>> chainer.__version__
'3.5.0'
>>>quit()
第7章 ネットワーク学習のお初は方策
- ダウンロードした棋譜データwdoor2016.7zを解凍する
- kifulist_train_1000.txtとkifulist_test_100.txtのパスに合わせる。
- 私はDドライブがないので
subst D: path\to\wdoor2016とした - Dドライブがあるなら
pushd d:\ & mklink /d 2016 path\to\wdoor2016\2016でもよさそう - 逆に解凍したパスに合わせてkifulist_*.txtを編集してもいいけど、面倒い
- 私はDドライブがないので
- dlshogiのインストールとshogiのインストールと学習
dlshogiのインストールとshogiのインストールと学習
>cd path\to\python-dlshogi
>pip install --no-cache-dir -e .
>pip install python-shogi
>python train_policy.py kifulist_train_1000.txt kifulist_test_100.txt --eval_interval 100 --log log
- ログを確認
- 実行7分くらい、、グラフはこんな感じ、本と似てる?
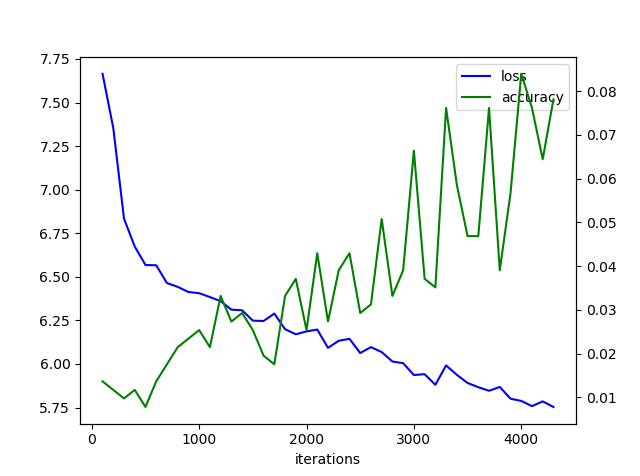
- 実行7分くらい、、グラフはこんな感じ、本と似てる?
全ての棋譜の学習
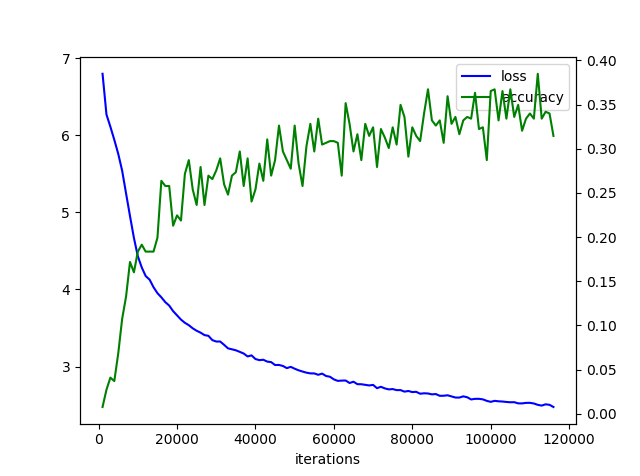
>python train_policy.py kifulist_train.txt kifulist_test.txt --log log2
- 再びログを確認
- 実行3時間くらい、、著者は52分と本に記載がありま。えっ、私の環境遅すぎ
- グラフはこんな感じ、本と似てる?
第9章 効率化のテクニック
第10章 局面を評価する
- 10.2章,10.3章の層の追加について解説をなるほどと読んで学習開始する
学習
>python train_value.py kifulist_train.txt kifulist_test.txt --log log_v
- こちらも実行3時間くらい
- policy v.s. value
- policyが勝つた
- 10章末にも1手のみの探索では強くないと書いてます
- いいのかな?次章に期待
第11章 効率と精度が一挙両得ってホントですか
書籍P188のままだとmodelファイルパスが合わないので注意
>python utils\transfer_policy_to_value.py model\model_policy model\model_value_transferred
こちらも書籍P190に対してmodelパス合わせてます
>python train_value.py kifulist_train.txt kifulist_test.txt -m model\model_value_transferred --log log_v_t
マルチタスク学習
>python train_policy_value.py kifulist_train.txt kifulist_test.txt --log log_p_v
ResNet
>python train_policy_value_resnet.py kifulist_train.txt kifulist_test.txt --log log_res
第12章 モンテカルロ木探索
おしまい