ロジスティック回帰分析の考え方
- 参考にしたもの:機械学習のエッセンスの第05章「機械学習アルゴリズム」
- 回帰、サポートベクターマシンは別ページ
ロジスティック回帰分析とは
- 二値分類に使われるアルゴリズム。(=ラベルが2種類の教師あり訓練データ)
- 例1:ある人のデータから、病気が発症しているorしていないの判定
- 例2:商品のデータ(大きさ、形、キズなど)から、その商品が合格or不合格の判定
ロジスティック回帰モデル
- $y$:コレが「0になるのか」「1になるのか」で、ラベルがどちらか予測したい
- $\mathbf{x}=(x_1, x_2, \cdots, x_n)$:コレを使って、$y$が0なのか1なのかを予測したい
- $P(Y=0|X=\mathbf{x})$:$\mathbf{x}$をもとに計算される、$y$が0になる確率。コレが0.5(50%)を超えるとき、「$y=0$」と予測する
- $P(Y=1|X=\mathbf{x})$:$\mathbf{x}$をもとに計算される、$y$が1になる確率。コレが0.5(50%)を超えるとき、「$y=1$」と予測する
- ※今回は、2パターンしかないので「$P(Y=0|X=\mathbf{x}) + P(Y=1|X=\mathbf{x}) = 1$」となる
今回は「yが0になる確率」または「yが1になる確率」を使ってyを予測したい。
しかし確率は必ず0~1 (0%~100%)であるのに対し、通常の重回帰分析は
f(\mathbf{x}) = w_0 + w_1x_1 + w_2x_2 + \cdots + w_nx_n = w_0 + \sum_{i=1}^{n} w_ix_i = \mathbf{w}\mathbf{\tilde{x}} \\
\mathbf{\tilde{x}} = (1, x_1, x_2, \cdots, x_n)
と表され、予測結果が0~1の範囲から飛び出る可能性があり、確率の予測に向いてない。
そのため、シグモイド関数を使って0~1に収まるように変換する。
※シグモイド関数:
\sigma(\xi)= \frac{1}{1+e^{-\xi}}
↓こんなの($\lim_{\xi \to \infty}$で1に、$\lim_{\xi \to -\infty}$で0に近づく)
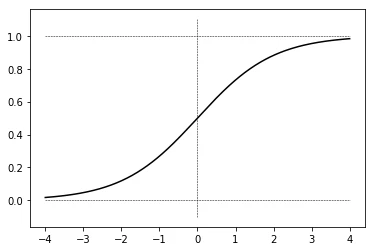
コレの$\xi$に$f(\mathbf{x})$を放り込んで、「yが1になる確率」を
P(Y=1|X=\mathbf{x}) = \sigma(f(\mathbf{x})) = \sigma(\mathbf{w}\mathbf{\tilde{x}})
と表し、訓練データの正答率が一番高くなるような、パラメータ$\mathbf{w}=(w_0, w_1, w_2, \cdots, w_n)$を求める。
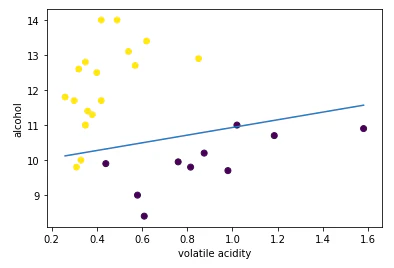
サンプル
winequality-red( http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality のwinequality-red.csv)に適用した例
- 簡単に図を作るため、↓を行っている
- quality(=目的変数)が3と8のものだけ考える
- 説明変数は"volatile acidity"と"alcohol"の2つだけで考える
- 点 = 実際のデータ(教師データ)
- 新しいデータに対しては、境界線のどちらに居るかで予測する
- 図を作ったコードはココ( https://github.com/kzy611/qiita/blob/master/LogisticRegression_winequality-red.ipynb )
パラメータ(係数)の求め方
今回、$P(Y=0|X=\mathbf{x})$は「$P(Y=1|X=\mathbf{x})$ではない確率」なので、
\begin{align}
P(Y=0|X=\mathbf{x}) &= 1-P(Y=1|X=\mathbf{x}) \\
&= 1-\sigma(\mathbf{w}\mathbf{\tilde{x}})
\end{align}
$y=0$の場合と$y=1$の場合を合体させると、↓のようになり
P(Y=y|X=\mathbf{x}) = \left\{
\begin{array}{ll}
\sigma(\mathbf{w}\mathbf{\tilde{x}}) & (y = 1) \\
1-\sigma(\mathbf{w}\mathbf{\tilde{x}}) & (y = 0)
\end{array}
\right.
1つの式で表そうとすると↓のようになる。($y=0, y=1$を入れてみると、不要なほうが0乗になって消える)
P(Y=y|X=\mathbf{x}) = \bigl(\sigma(\mathbf{w}\mathbf{\tilde{x}})\bigr)^y \bigl(1-\sigma(\mathbf{w}\mathbf{\tilde{x}})\bigr)^{1-y}
ここで、i番目のサンプルを$\mathbf{x_i}$とすると、n個の訓練データで全部正解する確率は
\prod_{i=1}^{n} P(Y=y|X=\mathbf{x_i}) = \prod_{i=1}^{n} \bigl(\sigma(\mathbf{w}\mathbf{\tilde{x_i}})\bigr)^y \bigl(1-\sigma(\mathbf{w}\mathbf{\tilde{x_i}})\bigr)^{1-y}
コレ(=訓練データを全部正解する確率)が最大となるようなパラメータ$\mathbf{w}$を求める。(=最尤法)
「関数が最小・最大となるパラメータ$\mathbf{w}$を求める」=「関数を微分したものが0になるパラメータ$\mathbf{w}$を求める」
が定石だが、掛け算・乗数がたくさんあると微分しづらい。
そのため、代わりに「対数をとってマイナスをかけたもの↓」を考え、コレを最小にするパラメータ$\mathbf{w}$を求める。
\begin{align}
E(\mathbf{w}) &= -\log \Bigl({ \prod_{i=1}^{n} \bigl(P(Y=y|X=\mathbf{x_i}) \bigr)} \Bigr) \\
&= -\log{\Bigl( \prod_{i=1}^{n} \bigl(\sigma(\mathbf{w}\mathbf{\tilde{x_i}})\bigr)^y \bigl(1-\sigma(\mathbf{w}\mathbf{\tilde{x_i}})\bigr)^{1-y}\Bigr)} \\
&= - \sum_{i=1}^{n} \Bigl(y \log{\sigma(\mathbf{w}\mathbf{\tilde{x_i}})} + (1-y) \log{\bigl(1-\sigma(\mathbf{w}\mathbf{\tilde{x_i}})\bigr)}\Bigr)
\end{align}
コレをwで微分したときの一階微分は↓のようになる、(途中計算は機械学習のエッセンスを参照して・・・)
\frac{\partial E(\mathbf{w})}{\partial \mathbf{w}} = \sum_{i=1}^{n} (\sigma(\mathbf{w}\mathbf{\tilde{x_i}})-y_i)\mathbf{\tilde{x_i}}
ココまでできれば、あとは一階微分が0になるパラメータ$\mathbf{w}$を求めれば完了。(機械学習のエッセンスでは、二階微分を使ってニュートン法によって求めてる)
パラメータ使って結果を予測する
↑で求めたパラメータ$\mathbf{w}$を使い、与えられた$\mathbf{x}$から$P(Y=0|X=x), P(Y=1|X=x)$を計算し、
- $P(Y=0|X=x)$が大きい(=0.5(50%)を超える)⇒「y=0」と予測⇒ラベルがどちらか予測
- $P(Y=1|X=x)$が大きい(=0.5(50%)を超える)⇒「y=1」と予測⇒ラベルがどちらか予測