
TensorFlow 2.xの対応
TensorFlow 2.xの場合は以下のページを参照ください。
「Object Detection API」で物体検出の自前データを学習する方法(TensorFlow 2.x版)
「Object Detection API」と「Object Detection Tools」に関して
ディープラーニングで物体検出を行う際に、GoogleのTensorFlowの「Object Detection API」を使用して、自前データを学習する方法です。
学習を簡単にするために、自作の「Object Detection Tools」というソフトを活用します。

「Object Detection API」と「Object Detection Tools」に関しては、以下記事を参照下さい。
TensorFlowの物体検出用ライブラリ「Object Detection API」を手軽に使えるソフト「Object Detection Tools」を作ってみた
「Object Detection Tools」は簡単なスクリプトの詰め合わせなので「Object Detection API」だけで学習するときの参考にもなる記事とは思います。
物体検出の自前データの学習方法
自前データの学習は、以下の4つのステップとなります。
- 教師データの準備
- アノテーション
- 学習
- テスト
順に説明していきます。
環境としてはMac環境を想定しています。Linux PCでも基本的にほぼ同じコマンドでOKです。Windows10でもできた人がいたようですが、パスの指定含め色々変えないとダメなようです。オススメはしません。
また、環境によってpythonをpython3にpipをsudo pip3に置き換える必要がありますので、適宜修正下さい。
教師データ準備
まずは教師データの準備をします。静止画か動画を準備しましょう。以下では動画を例にして説明しますが、基本的に静止画でもやることは同じです。
適当な動画がない方は、以下にフリー素材へのリンクを貼りますので、ご使用下さい。
提供元は「変デジ研究所」という素晴らしいサイト様です。カメラ好きの方は是非訪問しましょう。
アノテーション
アノテーション準備
アノテーションは、教師データにラベル付けしていく作業です。多くのソフトがありますが、ここでは、「Object Detection API」で使用されるTFRecordsという形式のファイルを直接エクスポートできることから、Microsoft社のVoTTという無料のソフトを使用します。
VoTTは、以下リンクからダウンロードできます。
OSに対応したバイナリファイルをダウンロードしましょう。私はMacなので、現状の最新バージョンのvott-2.1.0-darwin.dmgをダウンロードしました。Windowsならvott-2.1.0-win32.exeだと思います。
起動してNew Projectをクリックします。以下の表示がでます。
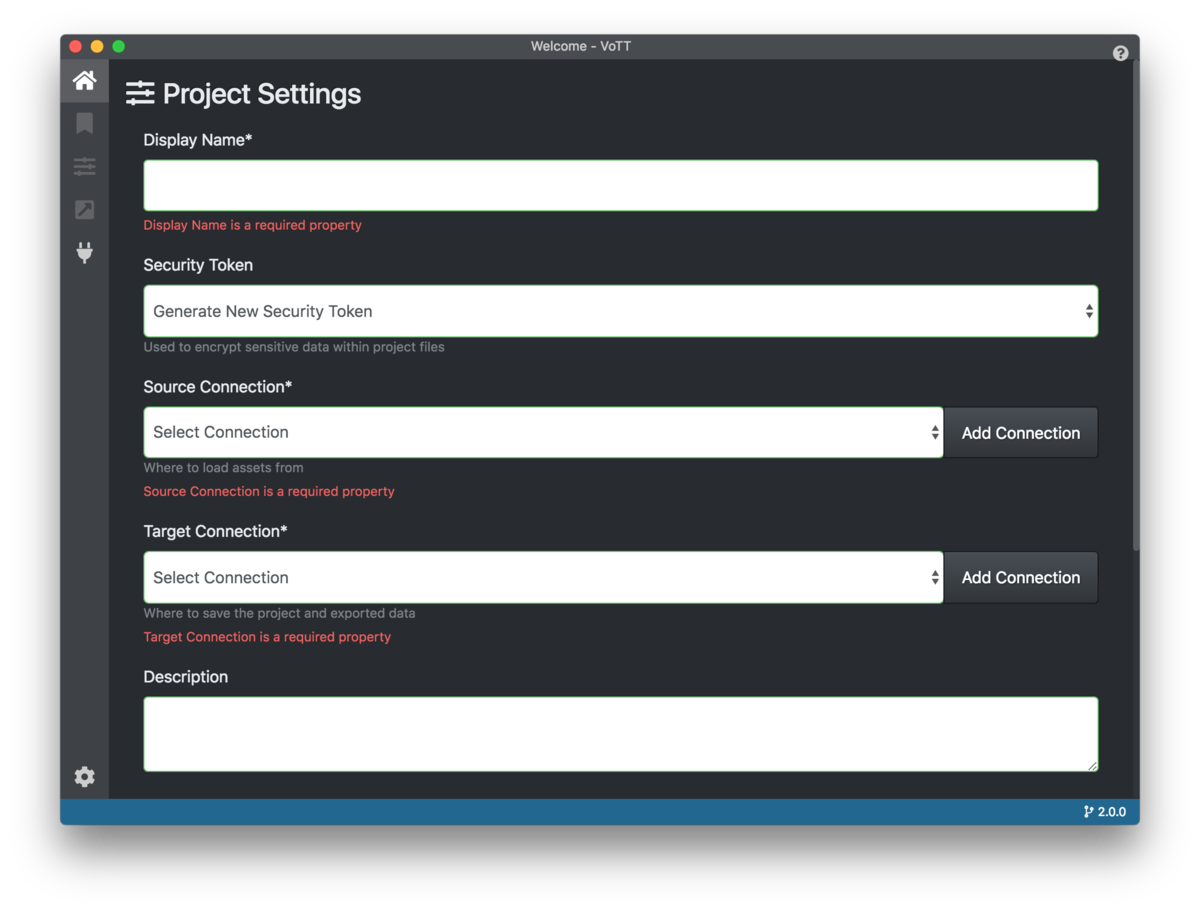
最初に教師データの場所の設定と、アノテーションしたデータの場所の設定を行います。上記画面真ん中のAdd Connectionをクリックすると新たな画面が出るので、以下の様に設定します。

名前(Name)と内容(Description)は好きな内容でOKですが、教師データの場所と、アノテーションしたデータの場所の2種類用意する必要があります。今回は「DeepThereminSource」「DeepThereminTarget」にしてあります。
「Provider」は「Local File System」を選択して「Folder Path」に、教師データの場所となるフォルダとアノテーションしたデータの場所を指定します。
教師データの場所となるフォルダには、教師データ(画像 or 動画)を格納しておきましょう。
ここで、最初の画面に戻り、以下の画面の様にSource ConnectionとTarget Connectionに先ほど設定した名前を選択します。

続いて、下の方のTagsに好きなタグを入力して、「SaveProject」をクリックしましょう。タグは後からでも追加できるので、ここでは空欄でもOKです。

アノテーション作業
ここから、いよいよアノテーション作業です。対象を囲ってひたすらタグ付けしていきます。タグは、右側の対応する数字を入力するとタグ付けできます。
タグ付け終わったら、データをエクスポートします。事前にExport Settingsを以下の様に設定します。Asset Stateは「Only tagged Assets」(タグ付けしたデータのみを使用する)にしておきましょう。

エクスポートは、タグ付け作業をする画面の、右上の斜め矢印のアイコンをクリックして下さい(Control + EでもOK)。最初に設定したフォルダにデータがエクスポートされます。
アノテーションしたデータの確認
tfrecordは、データがシリアライズされているので、中身の確認がそのままでは難しいのですが、tfrecord-viewerを使うと、ブラウザでアノテーションした内容が手軽に確認できます。
使用方法は、サイトのREADMEを確認下さい。
学習
学習環境構築
Pyenv + Anacondaを使ってセットアップしていきます。以下記事を参考にPyenvのインストールをしておいて下さい。
pyenv/pyenv-virtualenv/Anacondaを使ってクリーンなPython環境をセットアップ
Pyenvインストール後は、以下コマンドを実行して物体検出(Object Detection)に必要な環境を用意します。
最初にAnacondaをセットアッップして
$ pyenv install anaconda3-5.1.0
$ pyenv global anaconda3-5.1.0
$ conda create -n od anaconda
$ pyenv global anaconda3-5.1.0/envs/od
TensorFlowとOpenCVをセットアップします。
$ pip install tensorflow==1.14.0
$ pip install opencv-python
Object Detection APIの設定とテスト
Object Detection APIのリポジトリをクローンします。
$ cd && git clone https://github.com/tensorflow/models
$ cd ~/models/research
以降の動作は、基本models/research 以下のディレクトリで行うことを前提として下さい。
Protocol Buffersをインストールします。以下はMacの例です。
$ curl -OL https://github.com/protocolbuffers/protobuf/releases/download/v3.8.0-rc1/protoc-3.8.0-rc-1-osx-x86_64.zip
$ sudo unzip -o protoc-3.8.0-rc-1-osx-x86_64.zip -d /usr/local bin/protoc
$ rm -f protoc-3.8.0-rc-1-osx-x86_64.zip
Linux(Ubuntu)の場合は、以下サイトを参考にすればセットアップできると思います。
$ curl -OL https://github.com/google/protobuf/releases/download/v3.2.0/protoc-
$ unzip protoc-3.2.0-linux-x86_64.zip -d protoc3
$ sudo mv protoc3/bin/* /usr/local/bin/
$ sudo mv protoc3/include/* /usr/local/include/
$ rm -rf protoc3 protoc-3.2.0-linux-x86_64.zip
参考にしていた以下サイトはリンク切れ
https://gist.github.com/sofyanhadia/37787e5ed098c97919b8c593f0ec44d8
Protocol Buffersセットアップしたら、以下を実行しておいて下さい。
$ cd ~/models/research
$ /usr/local/bin/protoc object_detection/protos/*.proto --python_out=.
ここで、Object Detection APIが正しくセットアップできているかテストを行います。以下コマンドを実行して下さい。
$ cd ~/models/research
$ export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim
$ python object_detection/builders/model_builder_test.py
最後にOKと出ればOKです。
ついでに、学習に必要なcocoapiライブラリをインストールしておきます。
$ pip install git+https://github.com/waleedka/coco.git#subdirectory=PythonAPI
「Object Detection Tools」を使った学習
続いて、以下コマンドで「Object Detection Tools」をダウンロードします。
$ cd ~/models/research
$ git clone https://github.com/karaage0703/object_detection_tools
次に、教師データをコピーします。以下のような構成になるように、dataディレクトリ直下にラベルファイル(tf_label_map.pbtxt)、train、valディレクトリ以下にtfrecordファイルを格納して下さい。valは検証用のファイルです。trainとvalの割合はとりあえず 7:3くらいにしておいて下さい。
object_detection_tools/
└── data
├── change_tfrecord_filename.sh
├── tf_label_map.pbtxt
├── train
│ ├── xxx.tfrecord
│ ├── xxx.tfrecord
│ ├── ...
└── val
├── xxx.tfrecord
├── xxx.tfrecord
├── ...
tfrecordファイル名を、スクリプトで変換します。
$ cd ~/models/research/object_detection_tools/data
$ ./change_tfrecord_filename.sh
学習済みのモデルをダウンロードします。学習済みモデルを使用するのは、今回、学習時間を短縮するため、転移学習(Fine Tuning)を行うためです。ゼロから学習する場合は、学習済みモデルのダウンロードは不要です。
$ cd ~/models/research/object_detection_tools/models
$ ./get_ssd_inception_v2_coco_model.sh
次に、使用するconfigファイルssd_inception_v2_coco.configを必要に応じて修正して下さい。特にnum_classesはクラス数になるので、アノテーションしたラベルの数に合わせて修正して下さい。
その他、data_augmentation_optionsでデータの水増しをする機能を使えます。詳細は、以下記事参照下さい。
フリー素材で遊びながら理解するディープラーニング精度向上のための画像データ水増し(Data Augmentation)手法
また、転移学習が不要な場合は fine_tune_checkpointの行を削除しておいて下さい。
設定が完了したので以下コマンドで学習させます。学習前に、学習したモデルを保存するディレクトリ(下記コマンドだとsaved_model_01)は、空にしておくか削除しておいて下さい。
$ cd ~/models/research
$ export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim
$ python object_detection/model_main.py --pipeline_config_path="./object_detection_tools/config/ssd_inception_v2_coco.config" --model_dir="./saved_model_01" --num_train_steps=10000 --alsologtostderr
しばらく学習が進んだら、TensorBoardで学習した結果を可視化します。--logdirで先ほど指定したモデルを保存するディレクトリを選択します。
$ tensorboard --logdir='saved_model_01/'
ブラウザでhttp://localhost:6006/にアクセスします。以下の様に、精度が向上していれば、学習が進んでいることになります。

以下の様に全く精度が上がらないようなら、一度学習データなどを見直してみましょう。

ちなみに、上記の場合は、アノテーションの際の
Export SettingsのAsset Stateが「Only visited Assets」(一度確認したデータのみを使用する)になっており、タグ付けされていないデータが大量に含まれていたのが原因でした。
学習したモデルファイルとラベルデータを変換
以下コマンドで、ckptファイルをグラフファイル(pbファイル)へ変換します。configファイルは学習の際に使用したものを使って下さい。モデルファイルは、基本的には一番学習の進んだファイルを使用して下さい。以下は756世代進んだものを使用しているのでmodel.ckpt-756を指定しています。
$ cd ~/models/research
$ export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim
$ python object_detection/export_inference_graph.py --input_type image_tensor --pipeline_config_path object_detection_tools/config/ssd_inception_v2_coco.config --trained_checkpoint_prefix saved_model_01/model.ckpt-756 --output_directory exported_graphs
以下コマンドでラベルデータをpbtxtファイルから、シンプルなラベルファイルに変換します。
$ cp object_detection_tools/scripts/convert_pbtxt_label.py ./
$ export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim
$ python convert_pbtxt_label.py -l='object_detection_tools/data/tf_label_map.pbtxt' > ./exported_graphs/labels.txt
これで exported_graphs ディレクトリにラベルファイルlabels.txt とモデルファイル frozen_inference_graph.pb が生成されました。
テスト(学習したモデルを使って物体検出)
以下実行すると学習したモデルを使って物体検出ができます。
$ cd ~/models/research
$ python object_detection_tools/scripts/object_detection.py
以下は、公開されている学習済みモデルで実行した様子です

なお、Python、TensorFlowとOpenCVがセットアップされている環境だったら、先ほど生成したラベルファイルlabels.txt とモデルファイル frozen_inference_graph.pbさえあれば、物体検出が実現できます。
具体的には、以下で物体検出のプログラムをダウンロードして、同じ場所にラベルファイルとモデルファイルを格納します。
$ wget https://raw.githubusercontent.com/karaage0703/object_detection_tools/master/scripts/object_detection.py
あとは、以下コマンドでラベルオプションと、学習済みモデルを指定して、プログラムを実行するだけでOKです。
$ python object_detection.py -l='labels.txt' -m='frozen_inference_graph.pb'
学習モデルはpbファイルなので、ARMコアのJetsonでも動作します。Jetson Nanoでの環境構築から物体検出まで行う方法は、以下記事参照下さい。
Jetson Nanoでリアルタイムに物体検出をする方法(TensorFlow Object Detection API/NVIDIA TensorRT)
またモデルを変えると、様々なものが認識できるようになります。以下は、手を検出するモデルの例です。
ディープラーニングで高性能な手の検出器を簡単に作る方法
まとめ
「Object Detection API」と自作ツールの「Object Detection Tools」で物体検出の自前データを学習する方法について書きました。「Object Detection API」で学習する記事は多くありますが、TFRecordの変換やパスの指定でハマることが多かったので、極力ハマらない方法に仕上げました。Object Detection APIでハマっている人の一助になれば幸いです。
ディープラーニングに関しては、ブログで以下の様に優良なチュートリアルをまとめたりしていますので、興味ある方はこちらもご覧下さい。
手を動かしながら学べるディープラーニングの優良なチュートリアル
参考リンク
- https://ghlinkcard.com
- https://tensorflow-object-detection-api-tutorial.readthedocs.io/en/latest/index.html
- https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/installation.md
- https://qiita.com/sanoyo/items/1a5c4e8671203d190fca
- https://devtalk.nvidia.com/default/topic/1049646/jetson-nano/jupyter-notebook-in-jetson-nano/
- https://qiita.com/PINTO/items/c35535432a5a021ca1bb
- https://qiita.com/PINTO/items/8a91d79abe6e939ef01c
- https://qiita.com/PINTO/items/6eb6de95e3cda0e09c84
- https://qiita.com/tsutof/items/0328ede42d509eb247ad
- https://medium.com/nanonets/how-to-automate-surveillance-easily-with-deep-learning-4eb4fa0cd68d
- https://medium.com/nanonets/how-to-easily-detect-objects-with-deep-learning-on-raspberrypi-225f29635c74
- https://medium.com/coinmonks/build-a-diy-security-camera-with-neural-compute-stick-part-1-805a1b1596b0
- https://qiita.com/IchiLab/items/fd99bcd92670607f8f9b
- https://qiita.com/IchiLab/items/8ad0cdb9c2006f416c3b
- https://gist.github.com/NobuoTsukamoto/ba7028bd4e77c1431f4ff560ad61e8d7
変更履歴
- 2020/07/30 誤記訂正・追記
- 2020/07/20 TensorFlow 2.x対応に関して追記