Tensorflow-bin 
TPU-MobilenetSSD 

1.Introduction
前回、無謀にも非サポートのモデル MobileNetv2-SSDLite のTPUモデルを生成しようとして失敗しました。
【前回記事】 Edge TPU Accelaratorの動作を少しでも高速化したかったのでダメ元でMobileNetv2-SSDLite(Pascal VOC)の.tfliteを生成してTPUモデルへコンパイルしようとした_その1
今回は手順を大幅に見直したうえで、再度 MobileNetv2-SSDLite のコンバートと、MobileNetv1-SSD / MobileNetv2-SSD のコンバートを実施します。 公式の手順でリトライしたところ、 GPUを使用できないDocker環境 という、なかなか挑戦的な環境での作業を強要されました。 正直、転移学習でも無駄に時間が掛かりますので、公式の手順の大半を無視してリトライしました。
公式のDockerイメージを一切使用せず、なおかつ Google Colaboratory も使用しません。
環境構築を含む全ての手順を明示するため、Dockerファイルをただ貼り付けるのではなく、作成した全てのスクリプトをそのまま記載します。 どうしても Dockerファイル が必要な方は、お手数ですがご自身でImageを細かく分離するなどしてDockerファイルを生成してください。 学習用のデータセットは私の個人用Googleドライブから高速にダウンロードされるようにしてあります。 また、ショボいGPUでも比較的大きなバッチサイズでトレーニングができるように工夫してあります。
- 今回カスタマイズのポイント
- DockerイメージによるGPU学習対応
- MobileNetv1-SSD / MobileNetv2-SSD / MobileNetv2-SSDLite の転移学習への対応
- Pascal VOC データセット (20クラス) への対応
※ 学習時間を大幅に短縮したい方は、素直に Google Colaboratory で作業を実施してください。
※ MS-COCOデータセットに比べ、Pascal VOCデータセットでは 1MB ほど.tfliteファイルのサイズが小さくなりました。
※ MS-COCO = 6.9 MB, Pascal VOC = 5.9 MB
2.Environment
- Ubuntu 16.04 x86_64
- Corei7 Gen8
- Geforce GTX 1070
- Tensorflow-GPU v1.12.0
- CUDA 9.0
- cuDNN 7
- Pascal VOC 2007/2012 Dataset
- Netron 2.8.1 here
- Protobuf 3.7.0 here
- Nvidia-Docker version 18.09.2, build 6247962 here
- NVIDIA Driver Version: 396.54
- [Docker Image] nvidia/cuda:9.0-cudnn7-devel-ubuntu16.04 here
3.Procedure
$ sudo docker run -it --privileged -p 6006:6006 --name="edgetpu-detect" nvidia/cuda:9.0-cudnn7-devel-ubuntu16.04 /bin/bash
$ apt-get update;apt-get upgrade -y
$ apt-get install -y protobuf-compiler python-pil python-lxml python-tk \
autoconf automake libtool curl make g++ unzip wget git nano \
libgflags-dev libgoogle-glog-dev liblmdb-dev libleveldb-dev \
libhdf5-10 libhdf5-serial-dev libhdf5-dev libhdf5-cpp-11 \
python3-dev python3-numpy python3-skimage gfortran libturbojpeg \
python-dev python-numpy python-skimage python3-pip python-pip \
libboost-all-dev libopenblas-dev libsnappy-dev software-properties-common \
protobuf-compiler python-pil python-lxml python-tk libfreetype6-dev pkg-config libpng12-dev
$ wget https://bootstrap.pypa.io/get-pip.py
$ python3 get-pip.py
$ pip3 install pip==18.0.0 --upgrade
$ pip3 install --user Cython contextlib2 jupyter matplotlib opencv-python lxml
$ git clone https://github.com/tensorflow/models.git
$ cd models/research
$ nano constants.sh
# !/bin/bash
declare -A ckpt_link_map
declare -A ckpt_name_map
declare -A config_filename_map
# ckpt_link_map["mobilenet_v1_ssd"]="http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v1_quantized_300x300_coco14_sync_2018_07_18.tar.gz"
ckpt_link_map["mobilenet_v1_ssd"]="http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v1_coco_2018_01_28.tar.gz"
# ckpt_link_map["mobilenet_v2_ssd"]="http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v2_quantized_300x300_coco_2019_01_03.tar.gz"
ckpt_link_map["mobilenet_v2_ssd"]="http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v2_coco_2018_03_29.tar.gz"
ckpt_link_map["mobilenet_v2_ssdlite"]="http://download.tensorflow.org/models/object_detection/ssdlite_mobilenet_v2_coco_2018_05_09.tar.gz"
# ckpt_name_map["mobilenet_v1_ssd"]="ssd_mobilenet_v1_quantized_300x300_coco14_sync_2018_07_18"
ckpt_name_map["mobilenet_v1_ssd"]="ssd_mobilenet_v1_coco_2018_01_28"
# ckpt_name_map["mobilenet_v2_ssd"]="ssd_mobilenet_v2_quantized_300x300_coco_2019_01_03"
ckpt_name_map["mobilenet_v2_ssd"]="ssd_mobilenet_v2_coco_2018_03_29"
ckpt_name_map["mobilenet_v2_ssdlite"]="ssdlite_mobilenet_v2_coco_2018_05_09"
config_filename_map["mobilenet_v1_ssd-true"]="pipeline_mobilenet_v1_ssd_retrain_whole_model.config"
config_filename_map["mobilenet_v1_ssd-false"]="pipeline_mobilenet_v1_ssd_retrain_last_few_layers.config"
config_filename_map["mobilenet_v2_ssd-true"]="pipeline_mobilenet_v2_ssd_retrain_whole_model.config"
config_filename_map["mobilenet_v2_ssd-false"]="pipeline_mobilenet_v2_ssd_retrain_last_few_layers.config"
config_filename_map["mobilenet_v2_ssdlite-true"]="pipeline_mobilenet_v2_ssdlite_retrain_whole_model.config"
config_filename_map["mobilenet_v2_ssdlite-false"]="pipeline_mobilenet_v2_ssdlite_retrain_last_few_layers.config"
INPUT_TENSORS='normalized_input_image_tensor'
OUTPUT_TENSORS='TFLite_Detection_PostProcess,TFLite_Detection_PostProcess:1,TFLite_Detection_PostProcess:2,TFLite_Detection_PostProcess:3'
OBJ_DET_DIR="$PWD"
LEARN_DIR="${OBJ_DET_DIR}/learn"
DATASET_DIR="${LEARN_DIR}/data"
CKPT_DIR="${LEARN_DIR}/ckpt"
TRAIN_DIR="${LEARN_DIR}/train"
OUTPUT_DIR="${LEARN_DIR}/models"
$ nano prepare_checkpoint_and_dataset.sh
# !/bin/bash
# Exit script on error.
set -e
# Echo each command, easier for debugging.
set -x
usage() {
cat << END_OF_USAGE
Downloads checkpoint and dataset needed for the tutorial.
--network_type Can be one of [mobilenet_v1_ssd, mobilenet_v2_ssd, mobilenet_v2_ssdlite],
mobilenet_v1_ssd by default.
--train_whole_model Whether or not to train all layers of the model. false
by default, in which only the last few layers are trained.
--help Display this help.
END_OF_USAGE
}
network_type="mobilenet_v1_ssd"
train_whole_model="false"
while [[ $# -gt 0 ]]; do
case "$1" in
--network_type)
network_type=$2
shift 2 ;;
--train_whole_model)
train_whole_model=$2
shift 2;;
--help)
usage
exit 0 ;;
--*)
echo "Unknown flag $1"
usage
exit 1 ;;
esac
done
export PYTHONPATH=`pwd`:`pwd`/slim:$PYTHONPATH
export PATH=/usr/local/cuda-9.0/bin:${PATH}
export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64/:/usr/local/cuda-9.0/targets/x86_64-linux/lib/stubs:${LD_LIBRARY_PATH}
ldconfig
cp pipeline_mobilenet_v1_ssd_retrain_whole_model.config configs
cp pipeline_mobilenet_v1_ssd_retrain_last_few_layers.config configs
cp pipeline_mobilenet_v2_ssd_retrain_whole_model.config configs
cp pipeline_mobilenet_v2_ssd_retrain_last_few_layers.config configs
cp pipeline_mobilenet_v2_ssdlite_retrain_last_few_layers.config configs
source "$PWD/constants.sh"
echo "PREPARING checkpoint..."
mkdir -p "${LEARN_DIR}"
ckpt_link="${ckpt_link_map[${network_type}]}"
ckpt_name="${ckpt_name_map[${network_type}]}"
cd "${LEARN_DIR}"
wget -O "${ckpt_name}.tar.gz" "$ckpt_link"
tar zxvf "${ckpt_name}.tar.gz"
rm "${ckpt_name}.tar.gz"
rm -rf "${CKPT_DIR}/${ckpt_name}"
rm -rf "${CKPT_DIR}/saved_model"
mv -f ${ckpt_name}/* "${CKPT_DIR}"
echo "CHOSING config file..."
config_filename="${config_filename_map[${network_type}-${train_whole_model}]}"
cd "${OBJ_DET_DIR}"
cp "configs/${config_filename}" "${CKPT_DIR}/pipeline.config"
echo "REPLACING variables in config file..."
sed -i "s%CKPT_DIR_TO_CONFIGURE%${CKPT_DIR}%g" "${CKPT_DIR}/pipeline.config"
sed -i "s%DATASET_DIR_TO_CONFIGURE%${DATASET_DIR}%g" "${CKPT_DIR}/pipeline.config"
echo "PREPARING dataset"
rm -rf "${DATASET_DIR}"
mkdir "${DATASET_DIR}"
cd "${DATASET_DIR}"
# VOCtrainval_11-May-2012.tar <--- 1.86GB
curl -sc /tmp/cookie "https://drive.google.com/uc?export=download&id=1rATNHizJdVHnaJtt-hW9MOgjxoaajzdh" > /dev/null
CODE="$(awk '/_warning_/ {print $NF}' /tmp/cookie)"
curl -Lb /tmp/cookie "https://drive.google.com/uc?export=download&confirm=${CODE}&id=1rATNHizJdVHnaJtt-hW9MOgjxoaajzdh" -o VOCtrainval_11-May-2012.tar
# VOCtrainval_06-Nov-2007.tar <--- 460MB
curl -sc /tmp/cookie "https://drive.google.com/uc?export=download&id=1c8laJUn-aaWEhE5NlDwIdNv5ZdogUAcD" > /dev/null
CODE="$(awk '/_warning_/ {print $NF}' /tmp/cookie)"
curl -Lb /tmp/cookie "https://drive.google.com/uc?export=download&confirm=${CODE}&id=1c8laJUn-aaWEhE5NlDwIdNv5ZdogUAcD" -o VOCtrainval_06-Nov-2007.tar
# Extract the data.
tar -xvf VOCtrainval_11-May-2012.tar;rm VOCtrainval_11-May-2012.tar
tar -xvf VOCtrainval_06-Nov-2007.tar;rm VOCtrainval_06-Nov-2007.tar
echo "PREPARING label map..."
cd "${OBJ_DET_DIR}"
cp "object_detection/data/pascal_label_map.pbtxt" "${DATASET_DIR}"
echo "CONVERTING dataset to TF Record..."
protoc object_detection/protos/*.proto --python_out=.
python3 object_detection/dataset_tools/create_pascal_tf_record.py \
--label_map_path="${DATASET_DIR}/pascal_label_map.pbtxt" \
--data_dir=${DATASET_DIR}/VOCdevkit \
--year=merged \
--set=train \
--output_path="${DATASET_DIR}/pascal_train.record"
python3 object_detection/dataset_tools/create_pascal_tf_record.py \
--label_map_path="${DATASET_DIR}/pascal_label_map.pbtxt" \
--data_dir=${DATASET_DIR}/VOCdevkit \
--year=merged \
--set=val \
--output_path="${DATASET_DIR}/pascal_val.record"
Edit pipeline_config.
First, the MobileNet-SSD v2 config sample is shown below.
"Left side" for transfer learning. If you do not transfer learning, "Right side".

$ nano pipeline_mobilenet_v1_ssd_retrain_whole_model.config
model {
ssd {
num_classes: 20
image_resizer {
fixed_shape_resizer {
height: 300
width: 300
}
}
feature_extractor {
type: "ssd_mobilenet_v1"
depth_multiplier: 1.0
min_depth: 16
conv_hyperparams {
regularizer {
l2_regularizer {
weight: 3.99999989895e-05
}
}
initializer {
random_normal_initializer {
mean: 0.0
stddev: 0.00999999977648
}
}
activation: RELU_6
batch_norm {
decay: 0.97000002861
center: true
scale: true
epsilon: 0.0010000000475
}
}
override_base_feature_extractor_hyperparams: true
}
box_coder {
faster_rcnn_box_coder {
y_scale: 10.0
x_scale: 10.0
height_scale: 5.0
width_scale: 5.0
}
}
matcher {
argmax_matcher {
matched_threshold: 0.5
unmatched_threshold: 0.5
ignore_thresholds: false
negatives_lower_than_unmatched: true
force_match_for_each_row: true
use_matmul_gather: true
}
}
similarity_calculator {
iou_similarity {
}
}
box_predictor {
convolutional_box_predictor {
conv_hyperparams {
regularizer {
l2_regularizer {
weight: 3.99999989895e-05
}
}
initializer {
random_normal_initializer {
mean: 0.0
stddev: 0.00999999977648
}
}
activation: RELU_6
batch_norm {
decay: 0.97000002861
center: true
scale: true
epsilon: 0.0010000000475
}
}
min_depth: 0
max_depth: 0
num_layers_before_predictor: 0
use_dropout: false
dropout_keep_probability: 0.800000011921
kernel_size: 1
box_code_size: 4
apply_sigmoid_to_scores: false
class_prediction_bias_init: -4.59999990463
}
}
anchor_generator {
ssd_anchor_generator {
num_layers: 6
min_scale: 0.20000000298
max_scale: 0.949999988079
aspect_ratios: 1.0
aspect_ratios: 2.0
aspect_ratios: 0.5
aspect_ratios: 3.0
aspect_ratios: 0.333299994469
}
}
post_processing {
batch_non_max_suppression {
score_threshold: 0.300000011921
iou_threshold: 0.600000023842
max_detections_per_class: 100
max_total_detections: 100
}
score_converter: SIGMOID
}
normalize_loss_by_num_matches: true
loss {
localization_loss {
weighted_smooth_l1 {
}
}
classification_loss {
weighted_sigmoid_focal {
gamma: 2.0
alpha: 0.75
}
}
classification_weight: 1.0
localization_weight: 1.0
}
encode_background_as_zeros: true
normalize_loc_loss_by_codesize: true
inplace_batchnorm_update: true
freeze_batchnorm: false
}
}
train_config {
batch_size: 64
data_augmentation_options {
random_horizontal_flip {
}
}
data_augmentation_options {
ssd_random_crop {
}
}
sync_replicas: true
optimizer {
adam_optimizer: {
learning_rate: {
manual_step_learning_rate {
initial_learning_rate: .0002
schedule {
step: 500
learning_rate: .00003
}
schedule {
step: 1000
learning_rate: .000003
}
schedule {
step: 3000
learning_rate: .0000003
}
schedule {
step: 6000
learning_rate: .00000003
}
}
}
}
use_moving_average: false
}
fine_tune_checkpoint: "CKPT_DIR_TO_CONFIGURE/model.ckpt"
from_detection_checkpoint: true
load_all_detection_checkpoint_vars: true
num_steps: 50000
startup_delay_steps: 0.0
replicas_to_aggregate: 8
max_number_of_boxes: 100
unpad_groundtruth_tensors: false
}
train_input_reader {
label_map_path: "DATASET_DIR_TO_CONFIGURE/pascal_label_map.pbtxt"
tf_record_input_reader {
input_path: "DATASET_DIR_TO_CONFIGURE/pascal_train.record"
}
}
eval_config: {
num_examples: 10
num_visualizations: 10
eval_interval_secs: 0
}
eval_input_reader {
label_map_path: "DATASET_DIR_TO_CONFIGURE/pascal_label_map.pbtxt"
shuffle: false
num_readers: 1
tf_record_input_reader {
input_path: "DATASET_DIR_TO_CONFIGURE/pascal_val.record"
}
}
graph_rewriter {
quantization {
delay: 48000
weight_bits: 8
activation_bits: 8
}
}
$ nano pipeline_mobilenet_v1_ssd_retrain_last_few_layers.config
model {
ssd {
num_classes: 20
image_resizer {
fixed_shape_resizer {
height: 300
width: 300
}
}
feature_extractor {
type: "ssd_mobilenet_v1"
depth_multiplier: 1.0
min_depth: 16
conv_hyperparams {
regularizer {
l2_regularizer {
weight: 3.99999989895e-05
}
}
initializer {
random_normal_initializer {
mean: 0.0
stddev: 0.00999999977648
}
}
activation: RELU_6
batch_norm {
decay: 0.97000002861
center: true
scale: true
epsilon: 0.0010000000475
}
}
override_base_feature_extractor_hyperparams: true
}
box_coder {
faster_rcnn_box_coder {
y_scale: 10.0
x_scale: 10.0
height_scale: 5.0
width_scale: 5.0
}
}
matcher {
argmax_matcher {
matched_threshold: 0.5
unmatched_threshold: 0.5
ignore_thresholds: false
negatives_lower_than_unmatched: true
force_match_for_each_row: true
use_matmul_gather: true
}
}
similarity_calculator {
iou_similarity {
}
}
box_predictor {
convolutional_box_predictor {
conv_hyperparams {
regularizer {
l2_regularizer {
weight: 3.99999989895e-05
}
}
initializer {
random_normal_initializer {
mean: 0.0
stddev: 0.00999999977648
}
}
activation: RELU_6
batch_norm {
decay: 0.97000002861
center: true
scale: true
epsilon: 0.0010000000475
}
}
min_depth: 0
max_depth: 0
num_layers_before_predictor: 0
use_dropout: false
dropout_keep_probability: 0.800000011921
kernel_size: 1
box_code_size: 4
apply_sigmoid_to_scores: false
class_prediction_bias_init: -4.59999990463
}
}
anchor_generator {
ssd_anchor_generator {
num_layers: 6
min_scale: 0.20000000298
max_scale: 0.949999988079
aspect_ratios: 1.0
aspect_ratios: 2.0
aspect_ratios: 0.5
aspect_ratios: 3.0
aspect_ratios: 0.333299994469
}
}
post_processing {
batch_non_max_suppression {
score_threshold: 0.300000011921
iou_threshold: 0.600000023842
max_detections_per_class: 100
max_total_detections: 100
}
score_converter: SIGMOID
}
normalize_loss_by_num_matches: true
loss {
localization_loss {
weighted_smooth_l1 {
}
}
classification_loss {
weighted_sigmoid_focal {
gamma: 2.0
alpha: 0.75
}
}
classification_weight: 1.0
localization_weight: 1.0
}
encode_background_as_zeros: true
normalize_loc_loss_by_codesize: true
inplace_batchnorm_update: true
freeze_batchnorm: false
}
}
train_config {
batch_size: 64
data_augmentation_options {
random_horizontal_flip {
}
}
data_augmentation_options {
ssd_random_crop {
}
}
sync_replicas: true
optimizer {
adam_optimizer: {
learning_rate: {
manual_step_learning_rate {
initial_learning_rate: .0002
schedule {
step: 500
learning_rate: .00003
}
schedule {
step: 1000
learning_rate: .000003
}
schedule {
step: 3000
learning_rate: .0000003
}
schedule {
step: 6000
learning_rate: .00000003
}
}
}
}
use_moving_average: false
}
fine_tune_checkpoint: "CKPT_DIR_TO_CONFIGURE/model.ckpt"
from_detection_checkpoint: true
load_all_detection_checkpoint_vars: true
num_steps: 50000
startup_delay_steps: 0.0
replicas_to_aggregate: 8
max_number_of_boxes: 100
unpad_groundtruth_tensors: false
freeze_variables:
['Conv2d_0',
'Conv2d_1_pointwise',
'Conv2d_1_depthwise',
'Conv2d_2_pointwise',
'Conv2d_2_depthwise',
'Conv2d_3_pointwise',
'Conv2d_3_depthwise',
'Conv2d_4_pointwise',
'Conv2d_4_depthwise',
'Conv2d_5_pointwise',
'Conv2d_5_depthwise',
'Conv2d_6_pointwise',
'Conv2d_6_depthwise',
'Conv2d_7_pointwise',
'Conv2d_7_depthwise',
'Conv2d_8_pointwise',
'Conv2d_8_depthwise',
'Conv2d_9_pointwise',
'Conv2d_9_depthwise']
}
train_input_reader {
label_map_path: "DATASET_DIR_TO_CONFIGURE/pascal_label_map.pbtxt"
tf_record_input_reader {
input_path: "DATASET_DIR_TO_CONFIGURE/pascal_train.record"
}
}
eval_config: {
num_examples: 10
num_visualizations: 10
eval_interval_secs: 0
}
eval_input_reader {
label_map_path: "DATASET_DIR_TO_CONFIGURE/pascal_label_map.pbtxt"
shuffle: false
num_readers: 1
tf_record_input_reader {
input_path: "DATASET_DIR_TO_CONFIGURE/pascal_val.record"
}
}
graph_rewriter {
quantization {
delay: 48000
weight_bits: 8
activation_bits: 8
}
}
$ nano pipeline_mobilenet_v2_ssd_retrain_whole_model.config
# Quantized trained SSD with Mobilenet v2 on Pascal VOC Dataset.
model {
ssd {
num_classes: 20
image_resizer {
fixed_shape_resizer {
height: 300
width: 300
}
}
feature_extractor {
type: "ssd_mobilenet_v2"
depth_multiplier: 1.0
min_depth: 16
conv_hyperparams {
regularizer {
l2_regularizer {
weight: 3.99999989895e-05
}
}
initializer {
random_normal_initializer {
mean: 0.0
stddev: 0.00999999977648
}
}
activation: RELU_6
batch_norm {
decay: 0.97000002861
center: true
scale: true
epsilon: 0.0010000000475
}
}
override_base_feature_extractor_hyperparams: true
}
box_coder {
faster_rcnn_box_coder {
y_scale: 10.0
x_scale: 10.0
height_scale: 5.0
width_scale: 5.0
}
}
matcher {
argmax_matcher {
matched_threshold: 0.5
unmatched_threshold: 0.5
ignore_thresholds: false
negatives_lower_than_unmatched: true
force_match_for_each_row: true
use_matmul_gather: true
}
}
similarity_calculator {
iou_similarity {
}
}
box_predictor {
convolutional_box_predictor {
conv_hyperparams {
regularizer {
l2_regularizer {
weight: 3.99999989895e-05
}
}
initializer {
random_normal_initializer {
mean: 0.0
stddev: 0.00999999977648
}
}
activation: RELU_6
batch_norm {
decay: 0.97000002861
center: true
scale: true
epsilon: 0.0010000000475
}
}
min_depth: 0
max_depth: 0
num_layers_before_predictor: 0
use_dropout: false
dropout_keep_probability: 0.800000011921
kernel_size: 1
box_code_size: 4
apply_sigmoid_to_scores: false
class_prediction_bias_init: -4.59999990463
}
}
anchor_generator {
ssd_anchor_generator {
num_layers: 6
min_scale: 0.20000000298
max_scale: 0.949999988079
aspect_ratios: 1.0
aspect_ratios: 2.0
aspect_ratios: 0.5
aspect_ratios: 3.0
aspect_ratios: 0.333299994469
}
}
post_processing {
batch_non_max_suppression {
score_threshold: 0.300000011921
iou_threshold: 0.600000023842
max_detections_per_class: 100
max_total_detections: 100
}
score_converter: SIGMOID
}
normalize_loss_by_num_matches: true
loss {
localization_loss {
weighted_smooth_l1 {
}
}
classification_loss {
weighted_sigmoid_focal {
gamma: 2.0
alpha: 0.75
}
}
classification_weight: 1.0
localization_weight: 1.0
}
encode_background_as_zeros: true
normalize_loc_loss_by_codesize: true
inplace_batchnorm_update: true
freeze_batchnorm: false
}
}
train_config {
batch_size: 64
data_augmentation_options {
random_horizontal_flip {
}
}
data_augmentation_options {
ssd_random_crop {
}
}
sync_replicas: true
optimizer {
adam_optimizer: {
learning_rate: {
manual_step_learning_rate {
initial_learning_rate: .0002
schedule {
step: 500
learning_rate: .00003
}
schedule {
step: 1000
learning_rate: .000003
}
schedule {
step: 3000
learning_rate: .0000003
}
schedule {
step: 6000
learning_rate: .00000003
}
}
}
}
use_moving_average: false
}
fine_tune_checkpoint: "CKPT_DIR_TO_CONFIGURE/model.ckpt"
from_detection_checkpoint: true
load_all_detection_checkpoint_vars: true
num_steps: 50000
startup_delay_steps: 0.0
replicas_to_aggregate: 8
max_number_of_boxes: 100
unpad_groundtruth_tensors: false
}
train_input_reader {
label_map_path: "DATASET_DIR_TO_CONFIGURE/pascal_label_map.pbtxt"
tf_record_input_reader {
input_path: "DATASET_DIR_TO_CONFIGURE/pascal_train.record"
}
}
eval_config: {
num_examples: 10
num_visualizations: 10
eval_interval_secs: 0
}
eval_input_reader {
label_map_path: "DATASET_DIR_TO_CONFIGURE/pascal_label_map.pbtxt"
shuffle: false
num_readers: 1
tf_record_input_reader {
input_path: "DATASET_DIR_TO_CONFIGURE/pascal_train.record"
}
}
graph_rewriter {
quantization {
delay: 48000
weight_bits: 8
activation_bits: 8
}
}
$ nano pipeline_mobilenet_v2_ssd_retrain_last_few_layers.config
# Quantized trained SSD with Mobilenet v2 on Pascal VOC Dataset.
model {
ssd {
num_classes: 20
image_resizer {
fixed_shape_resizer {
height: 300
width: 300
}
}
feature_extractor {
type: "ssd_mobilenet_v2"
depth_multiplier: 1.0
min_depth: 16
conv_hyperparams {
regularizer {
l2_regularizer {
weight: 3.99999989895e-05
}
}
initializer {
random_normal_initializer {
mean: 0.0
stddev: 0.00999999977648
}
}
activation: RELU_6
batch_norm {
decay: 0.97000002861
center: true
scale: true
epsilon: 0.0010000000475
}
}
override_base_feature_extractor_hyperparams: true
}
box_coder {
faster_rcnn_box_coder {
y_scale: 10.0
x_scale: 10.0
height_scale: 5.0
width_scale: 5.0
}
}
matcher {
argmax_matcher {
matched_threshold: 0.5
unmatched_threshold: 0.5
ignore_thresholds: false
negatives_lower_than_unmatched: true
force_match_for_each_row: true
use_matmul_gather: true
}
}
similarity_calculator {
iou_similarity {
}
}
box_predictor {
convolutional_box_predictor {
conv_hyperparams {
regularizer {
l2_regularizer {
weight: 3.99999989895e-05
}
}
initializer {
random_normal_initializer {
mean: 0.0
stddev: 0.00999999977648
}
}
activation: RELU_6
batch_norm {
decay: 0.97000002861
center: true
scale: true
epsilon: 0.0010000000475
}
}
min_depth: 0
max_depth: 0
num_layers_before_predictor: 0
use_dropout: false
dropout_keep_probability: 0.800000011921
kernel_size: 1
box_code_size: 4
apply_sigmoid_to_scores: false
class_prediction_bias_init: -4.59999990463
}
}
anchor_generator {
ssd_anchor_generator {
num_layers: 6
min_scale: 0.20000000298
max_scale: 0.949999988079
aspect_ratios: 1.0
aspect_ratios: 2.0
aspect_ratios: 0.5
aspect_ratios: 3.0
aspect_ratios: 0.333299994469
}
}
post_processing {
batch_non_max_suppression {
score_threshold: 0.300000011921
iou_threshold: 0.600000023842
max_detections_per_class: 100
max_total_detections: 100
}
score_converter: SIGMOID
}
normalize_loss_by_num_matches: true
loss {
localization_loss {
weighted_smooth_l1 {
}
}
classification_loss {
weighted_sigmoid_focal {
gamma: 2.0
alpha: 0.75
}
}
classification_weight: 1.0
localization_weight: 1.0
}
encode_background_as_zeros: true
normalize_loc_loss_by_codesize: true
inplace_batchnorm_update: true
freeze_batchnorm: false
}
}
train_config {
batch_size: 64
data_augmentation_options {
random_horizontal_flip {
}
}
data_augmentation_options {
ssd_random_crop {
}
}
sync_replicas: true
optimizer {
adam_optimizer: {
learning_rate: {
manual_step_learning_rate {
initial_learning_rate: .0002
schedule {
step: 500
learning_rate: .00003
}
schedule {
step: 1000
learning_rate: .000003
}
schedule {
step: 3000
learning_rate: .0000003
}
schedule {
step: 6000
learning_rate: .00000003
}
}
}
}
use_moving_average: false
}
fine_tune_checkpoint: "CKPT_DIR_TO_CONFIGURE/model.ckpt"
from_detection_checkpoint: true
load_all_detection_checkpoint_vars: true
num_steps: 50000
startup_delay_steps: 0.0
replicas_to_aggregate: 8
max_number_of_boxes: 100
unpad_groundtruth_tensors: false
freeze_variables:
[ 'FeatureExtractor/MobilenetV2/Conv/',
'FeatureExtractor/MobilenetV2/expanded_conv/',
'FeatureExtractor/MobilenetV2/expanded_conv_1/',
'FeatureExtractor/MobilenetV2/expanded_conv_2/',
'FeatureExtractor/MobilenetV2/expanded_conv_3/',
'FeatureExtractor/MobilenetV2/expanded_conv_4/',
'FeatureExtractor/MobilenetV2/expanded_conv_5/',
'FeatureExtractor/MobilenetV2/expanded_conv_6/',
'FeatureExtractor/MobilenetV2/expanded_conv_7/']
}
train_input_reader {
label_map_path: "DATASET_DIR_TO_CONFIGURE/pascal_label_map.pbtxt"
tf_record_input_reader {
input_path: "DATASET_DIR_TO_CONFIGURE/pascal_train.record"
}
}
eval_config: {
num_examples: 10
num_visualizations: 10
eval_interval_secs: 0
}
eval_input_reader {
label_map_path: "DATASET_DIR_TO_CONFIGURE/pascal_label_map.pbtxt"
shuffle: false
num_readers: 1
tf_record_input_reader {
input_path: "DATASET_DIR_TO_CONFIGURE/pascal_val.record"
}
}
graph_rewriter {
quantization {
delay: 48000
weight_bits: 8
activation_bits: 8
}
}
$ nano pipeline_mobilenet_v2_ssdlite_retrain_last_few_layers.config
# SSDLite with Mobilenet v2 configuration for VOC Dataset.
model {
ssd {
num_classes: 20
image_resizer {
fixed_shape_resizer {
height: 300
width: 300
}
}
feature_extractor {
type: 'ssd_mobilenet_v2'
depth_multiplier: 1.0
min_depth: 16
use_depthwise: true
conv_hyperparams {
regularizer {
l2_regularizer {
weight: 0.00004
}
}
initializer {
truncated_normal_initializer {
mean: 0.0
stddev: 0.03
}
}
activation: RELU_6
batch_norm {
decay: 0.9997
center: true
scale: true
epsilon: 0.001
}
}
}
box_coder {
faster_rcnn_box_coder {
y_scale: 10.0
x_scale: 10.0
height_scale: 5.0
width_scale: 5.0
}
}
matcher {
argmax_matcher {
matched_threshold: 0.5
unmatched_threshold: 0.5
ignore_thresholds: false
negatives_lower_than_unmatched: true
force_match_for_each_row: true
}
}
similarity_calculator {
iou_similarity {
}
}
box_predictor {
convolutional_box_predictor {
conv_hyperparams {
regularizer {
l2_regularizer {
weight: 0.00004
}
}
initializer {
truncated_normal_initializer {
mean: 0.0
stddev: 0.03
}
}
activation: RELU_6
batch_norm {
decay: 0.9997
center: true
scale: true
epsilon: 0.001
}
}
min_depth: 0
max_depth: 0
num_layers_before_predictor: 0
use_dropout: false
dropout_keep_probability: 0.8
kernel_size: 3
box_code_size: 4
apply_sigmoid_to_scores: false
use_depthwise: true
}
}
anchor_generator {
ssd_anchor_generator {
num_layers: 6
min_scale: 0.2
max_scale: 0.95
aspect_ratios: 1.0
aspect_ratios: 2.0
aspect_ratios: 0.5
aspect_ratios: 3.0
aspect_ratios: 0.3333
}
}
post_processing {
batch_non_max_suppression {
score_threshold: 1e-8
iou_threshold: 0.6
max_detections_per_class: 100
max_total_detections: 100
}
score_converter: SIGMOID
}
normalize_loss_by_num_matches: true
loss {
localization_loss {
weighted_smooth_l1 {
}
}
classification_loss {
weighted_sigmoid {
}
}
classification_weight: 1.0
localization_weight: 1.0
hard_example_miner {
num_hard_examples: 3000
iou_threshold: 0.99
loss_type: CLASSIFICATION
max_negatives_per_positive: 3
min_negatives_per_image: 3
}
}
}
}
train_config: {
batch_size: 64
data_augmentation_options {
random_horizontal_flip {
}
}
data_augmentation_options {
ssd_random_crop {
}
}
sync_replicas: true
optimizer {
adam_optimizer: {
learning_rate: {
manual_step_learning_rate {
initial_learning_rate: .0002
schedule {
step: 500
learning_rate: .00003
}
schedule {
step: 1000
learning_rate: .000003
}
schedule {
step: 3000
learning_rate: .0000003
}
schedule {
step: 6000
learning_rate: .00000003
}
}
}
}
use_moving_average: false
}
fine_tune_checkpoint: "CKPT_DIR_TO_CONFIGURE/model.ckpt"
from_detection_checkpoint: true
load_all_detection_checkpoint_vars: true
num_steps: 50000
startup_delay_steps: 0.0
replicas_to_aggregate: 8
max_number_of_boxes: 100
unpad_groundtruth_tensors: false
freeze_variables:
[ 'FeatureExtractor/MobilenetV2/Conv/',
'FeatureExtractor/MobilenetV2/expanded_conv/',
'FeatureExtractor/MobilenetV2/expanded_conv_1/',
'FeatureExtractor/MobilenetV2/expanded_conv_2/',
'FeatureExtractor/MobilenetV2/expanded_conv_3/',
'FeatureExtractor/MobilenetV2/expanded_conv_4/',
'FeatureExtractor/MobilenetV2/expanded_conv_5/',
'FeatureExtractor/MobilenetV2/expanded_conv_6/',
'FeatureExtractor/MobilenetV2/expanded_conv_7/']
}
train_input_reader: {
label_map_path: "DATASET_DIR_TO_CONFIGURE/pascal_label_map.pbtxt"
tf_record_input_reader {
input_path: "DATASET_DIR_TO_CONFIGURE/pascal_train.record"
}
}
eval_config: {
num_examples: 10
num_visualizations: 10
eval_interval_secs: 0
}
eval_input_reader: {
label_map_path: "DATASET_DIR_TO_CONFIGURE/pascal_label_map.pbtxt"
shuffle: false
num_readers: 1
tf_record_input_reader {
input_path: "DATASET_DIR_TO_CONFIGURE/pascal_val.record"
}
}
graph_rewriter {
quantization {
delay: 48000
weight_bits: 8
activation_bits: 8
}
}
$ nano retrain_detection_model.sh
# !/bin/bash
# Exit script on error.
set -e
# Echo each command, easier for debugging.
set -x
usage() {
cat << END_OF_USAGE
Starts retraining detection model.
--num_training_steps Number of training steps to run, 500 by default.
--num_eval_steps Number of evaluation steps to run, 100 by default.
--help Display this help.
END_OF_USAGE
}
num_training_steps=500
while [[ $# -gt 0 ]]; do
case "$1" in
--num_training_steps)
num_training_steps=$2
shift 2 ;;
--num_eval_steps)
num_eval_steps=$2
shift 2 ;;
--help)
usage
exit 0 ;;
--*)
echo "Unknown flag $1"
usage
exit 1 ;;
esac
done
export PYTHONPATH=`pwd`:`pwd`/slim:$PYTHONPATH
export PATH=/usr/local/cuda-9.0/bin:${PATH}
export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64/:/usr/local/cuda-9.0/targets/x86_64-linux/lib/stubs:${LD_LIBRARY_PATH}
ldconfig
source "$PWD/constants.sh"
mkdir "${TRAIN_DIR}"
python3 object_detection/model_main.py \
--pipeline_config_path="${CKPT_DIR}/pipeline.config" \
--model_dir="${TRAIN_DIR}" \
--num_train_steps="${num_training_steps}" \
--num_eval_steps="${num_eval_steps}"
$ chmod +x constants.sh
$ chmod +x prepare_checkpoint_and_dataset.sh
$ chmod +x retrain_detection_model.sh
$ chmod +x protoc_update.sh
$ mkdir configs
$ git clone https://github.com/pdollar/coco.git
$ cd coco/PythonAPI
$ python3 setup.py install
$ cd ../..
$ pip3 install tensorflow-gpu==1.12.0 --upgrade
$ wget https://github.com/protocolbuffers/protobuf/archive/v3.7.0.zip
$ unzip v3.7.0.zip;rm v3.7.0.zip;cd protobuf-3.7.0
$ ./autogen.sh
$ ./configure
$ make -j$(($(nproc) + 1))
$ make install
$ cd python
$ export LD_LIBRARY_PATH=../src/.libs
$ python3 setup.py build --cpp_implementation
$ python3 setup.py test --cpp_implementation
$ python3 setup.py install --cpp_implementation
$ ldconfig
$ cd ../..
$ nano object_detection/utils/object_detection_evaluation.py
# Two lines of correction are required.
# category_name = unicode(category_name, 'utf-8')
category_name = str(category_name, 'utf-8')
Restart Docker container.
$ cd models/research
# No sharing of weight values from learned models
$ ./prepare_checkpoint_and_dataset.sh --network_type mobilenet_v1_ssd --train_whole_model true
or
# Sharing of weight value from learned model
$ ./prepare_checkpoint_and_dataset.sh --network_type mobilenet_v1_ssd --train_whole_model false
or
# No sharing of weight values from learned models
$ ./prepare_checkpoint_and_dataset.sh --network_type mobilenet_v2_ssd --train_whole_model true
or
# Sharing of weight value from learned model
$ ./prepare_checkpoint_and_dataset.sh --network_type mobilenet_v2_ssd --train_whole_model false
or
# Sharing of weight value from learned model
$ ./prepare_checkpoint_and_dataset.sh --network_type mobilenet_v2_ssdlite --train_whole_model false
$ source "$PWD/constants.sh";NUM_TRAINING_STEPS=10000 && NUM_EVAL_STEPS=500;rm -rf learn/train;\
./retrain_detection_model.sh \
--num_training_steps ${NUM_TRAINING_STEPS} \
--num_eval_steps ${NUM_EVAL_STEPS}
or
$ source "$PWD/constants.sh";NUM_TRAINING_STEPS=500 && NUM_EVAL_STEPS=100;rm -rf learn/train;\
./retrain_detection_model.sh \
--num_training_steps ${NUM_TRAINING_STEPS} \
--num_eval_steps ${NUM_EVAL_STEPS}
$ sudo docker exec -it edgetpu-detect /bin/bash
$ cd models/research/learn/train
$ tensorboard --logdir=.
To check the progress of learning with Tensorboard, access "http://localhost:6006" from the browser of the host PC.
$ nano convert_checkpoint_to_edgetpu_tflite.sh
# !/bin/bash
# Exit script on error.
set -e
# Echo each command, easier for debugging.
set -x
usage() {
cat << END_OF_USAGE
Converts TensorFlow checkpoint to EdgeTPU-compatible TFLite file.
--network_type Can be one of [mobilenet_v1_ssd, mobilenet_v2_ssd, mobilenet_v2_ssdlite],
mobilenet_v1_ssd by default.
--checkpoint_num Checkpoint number, by default 0.
--help Display this help.
END_OF_USAGE
}
network_type="mobilenet_v1_ssd"
ckpt_number=0
while [[ $# -gt 0 ]]; do
case "$1" in
--network_type)
network_type=$2
shift 2 ;;
--checkpoint_num)
ckpt_number=$2
shift 2 ;;
--help)
usage
exit 0 ;;
--*)
echo "Unknown flag $1"
usage
exit 1 ;;
esac
done
export PYTHONPATH=`pwd`:`pwd`/slim:$PYTHONPATH
export PATH=/usr/local/cuda-9.0/bin:${PATH}
export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64/:/usr/local/cuda-9.0/targets/x86_64-linux/lib/stubs:${LD_LIBRARY_PATH}
ldconfig
source "$PWD/constants.sh"
rm -rf "${OUTPUT_DIR}"
mkdir "${OUTPUT_DIR}"
echo "0 aeroplane" > "${OUTPUT_DIR}/labels.txt"
echo "1 bicycle" >> "${OUTPUT_DIR}/labels.txt"
echo "2 bird" >> "${OUTPUT_DIR}/labels.txt"
echo "3 boat" >> "${OUTPUT_DIR}/labels.txt"
echo "4 bottle" >> "${OUTPUT_DIR}/labels.txt"
echo "5 bus" >> "${OUTPUT_DIR}/labels.txt"
echo "6 car" >> "${OUTPUT_DIR}/labels.txt"
echo "7 cat" >> "${OUTPUT_DIR}/labels.txt"
echo "8 chair" >> "${OUTPUT_DIR}/labels.txt"
echo "9 cow" >> "${OUTPUT_DIR}/labels.txt"
echo "10 diningtable" >> "${OUTPUT_DIR}/labels.txt"
echo "11 dog" >> "${OUTPUT_DIR}/labels.txt"
echo "12 horse" >> "${OUTPUT_DIR}/labels.txt"
echo "13 motorbike" >> "${OUTPUT_DIR}/labels.txt"
echo "14 person" >> "${OUTPUT_DIR}/labels.txt"
echo "15 pottedplant" >> "${OUTPUT_DIR}/labels.txt"
echo "16 sheep" >> "${OUTPUT_DIR}/labels.txt"
echo "17 sofa" >> "${OUTPUT_DIR}/labels.txt"
echo "18 train" >> "${OUTPUT_DIR}/labels.txt"
echo "19 tvmonitor" >> "${OUTPUT_DIR}/labels.txt"
echo "EXPORTING frozen graph from checkpoint..."
python3 object_detection/export_tflite_ssd_graph.py \
--pipeline_config_path="${CKPT_DIR}/pipeline.config" \
--trained_checkpoint_prefix="${TRAIN_DIR}/model.ckpt-${ckpt_number}" \
--output_directory="${OUTPUT_DIR}" \
--add_postprocessing_op=true
echo "CONVERTING frozen graph to TF Lite file..."
tflite_convert \
--output_file="${OUTPUT_DIR}/output_tflite_graph.tflite" \
--graph_def_file="${OUTPUT_DIR}/tflite_graph.pb" \
--inference_type=QUANTIZED_UINT8 \
--input_arrays="${INPUT_TENSORS}" \
--output_arrays="${OUTPUT_TENSORS}" \
--mean_values=128 \
--std_dev_values=128 \
--input_shapes=1,300,300,3 \
--change_concat_input_ranges=false \
--allow_nudging_weights_to_use_fast_gemm_kernel=true \
--allow_custom_ops
echo "TFLite graph generated at ${OUTPUT_DIR}/output_tflite_graph.tflite"
$ chmod +x convert_checkpoint_to_edgetpu_tflite.sh
$ ./convert_checkpoint_to_edgetpu_tflite.sh --network_type mobilenet_v1_ssd --checkpoint_num 50000
or
$ ./convert_checkpoint_to_edgetpu_tflite.sh --network_type mobilenet_v2_ssd --checkpoint_num 50000
or
$ ./convert_checkpoint_to_edgetpu_tflite.sh --network_type mobilenet_v2_ssdlite --checkpoint_num 50000
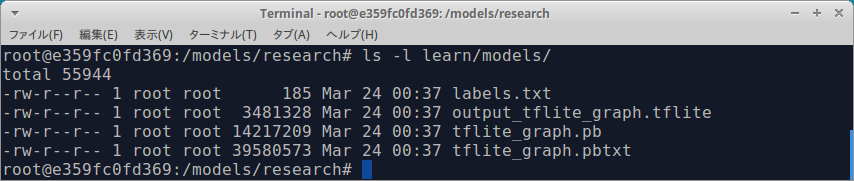
https://coral.withgoogle.com/web-compiler/
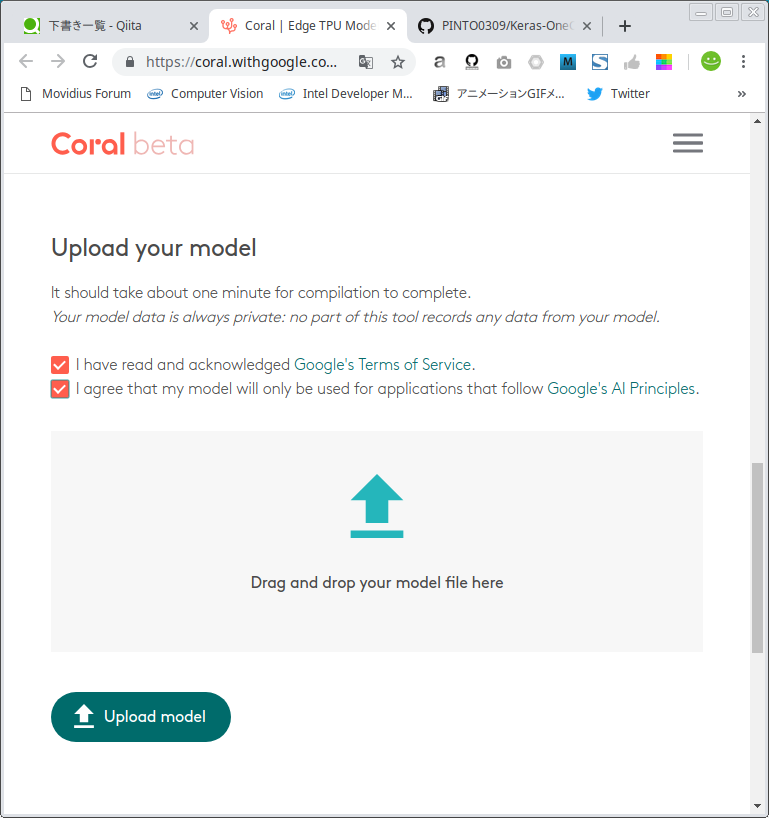
[Successful] MobileNetv1-SSD / MobileNetv2-SSD
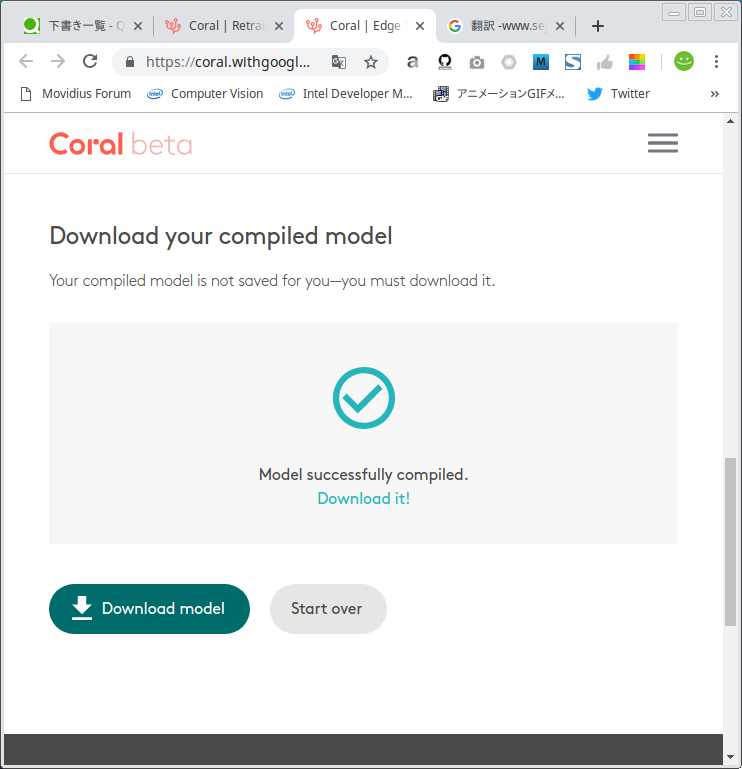
[Failed] MobileNetv2-SSDLite
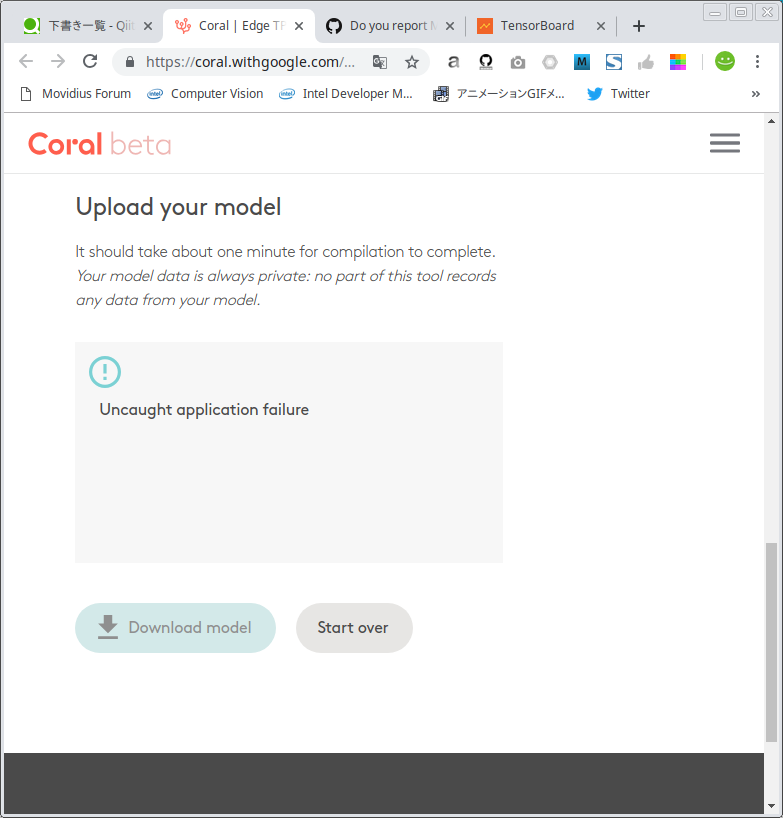
4.Reference articles
Retrain an object detection model
https://coral.withgoogle.com/tutorials/edgetpu-retrain-detection/
Edge TPU Model Compiler
https://coral.withgoogle.com/web-compiler/
Tensorflow detection model zoo
https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md
tensorflow/tensorflow/python/tools/freeze_graph.py
https://github.com/tensorflow/tensorflow/blob/5a74dd467f49cf44d80bd02a1979ecff45ae29e8/tensorflow/python/tools/freeze_graph.py
【Tensorflow】Tensorflow Object Detection API 学習させてみた
http://app.road.jp.net/?p=1985
Adam Optimizer
https://stackoverflow.com/questions/51915803/tensorflow-object-detection-use-adam-instead-of-rmsprop/51920195#51920195
Post-training quantization
https://www.tensorflow.org/lite/performance/post_training_quantization
Tensorflow r1.13.1 Quantization-aware training
https://github.com/tensorflow/tensorflow/tree/r1.13/tensorflow/contrib/quantize
nvidia-docker2のインストール(On Ubuntu 16.04 LTS)
https://qiita.com/spiderx_jp/items/32c421fd00c6ade19720