はじめに
前回の記事では、TensorFlowが提供しているObject Detection APIの使用方法についてまとめました。
このAPIを使用して、画像や動画の中から「この物体が○○だよ」と教えるためには、
アノテーションしてTFRecord形式に変換して、
教師データや検証用データとして使用するという流れになりますが、
このTFRecord形式の具体的な内容について触れた記事等はまだまだ少ないように感じます。
本記事では、手始めにプログラミング不要で作成できる方法から、
Pythonコードを書いて作成する方法まで、様々な角度でまとめていきます。
もちろん、私が試行錯誤して分かった知見をまとめているだけなので、
至らない部分もあるかとは思いますが、ご了承下さい。
紹介する内容
- MicrosoftのVoTTでのTFRecordファイル作成手順
- TFRecordとはどんなファイルなのか?
- アノテーションしたデータから、アノテーション部分を切り出す方法
- Pythonで物体検出用のTFRecordを作成してみる
VoTTでのTFRecordファイル作成手順
VoTTのインストール
以下のサイトからダウンロードしましょう。OSがWindowsなら.exe、Macなら.dmgを選択します。
VoTT
初期設定
まずは「New Project」で新しいプロジェクトを作ります。

プロジェクト設定を行います。
-
Display Name: お好きな名前でどうぞ。 -
Security Token: デフォルトでOK。 -
Source Connection: 画像を読む場所の設定名 -
Target Connection: プロジェクトを保存する場所の設定名。
ここで指定したディレクトリに.vottと.jsonとTFRecordのフォルダが保存される。
VoTTは、各ディレクトリを指定する際に、「Add Connection」でフォルダの場所など設定情報を名付けて保管し、
「〜Connection」の項目ではその設定名を指定するという仕組みになっています。
そのため、初めて使う場合は右側の「Add Connection」でその設定を作るところから始めます。

ディレクトリの設定を行います。
- Display Name : 設定の名称です。フォルダ名など分かりやすければ何でもOK。
- Provider : 今回はローカルのディレクトリを指定するので、「Local File System」 を選択します。
- Folder Path : Providerで上記を指定すると設定できます。フォルダを選択しましょう。
最後に「Save Connection」を選択します。

こうして「Source Connection」と「Target Connection」をそれぞれ設定できたら、いよいよ次はアノテーション作業です。

アノテーション
アノテーションは、左の上から2番目(家マークの下)で行うことが出来ます。
(写真は愛猫のミミィとキティです)

まず、タグの設定します。
右側にTAGSと書いてあり、その横に+のアイコンがありますね。
これを選択すると、新しくタグを設定することができます。
今回は愛猫の名前で「Mimmy」「Kitty」と設定しました。
次に、上部の左から2番目の四角いアイコンを選択します。
そして、アノテーションしたい場所をドラッグして囲みます。
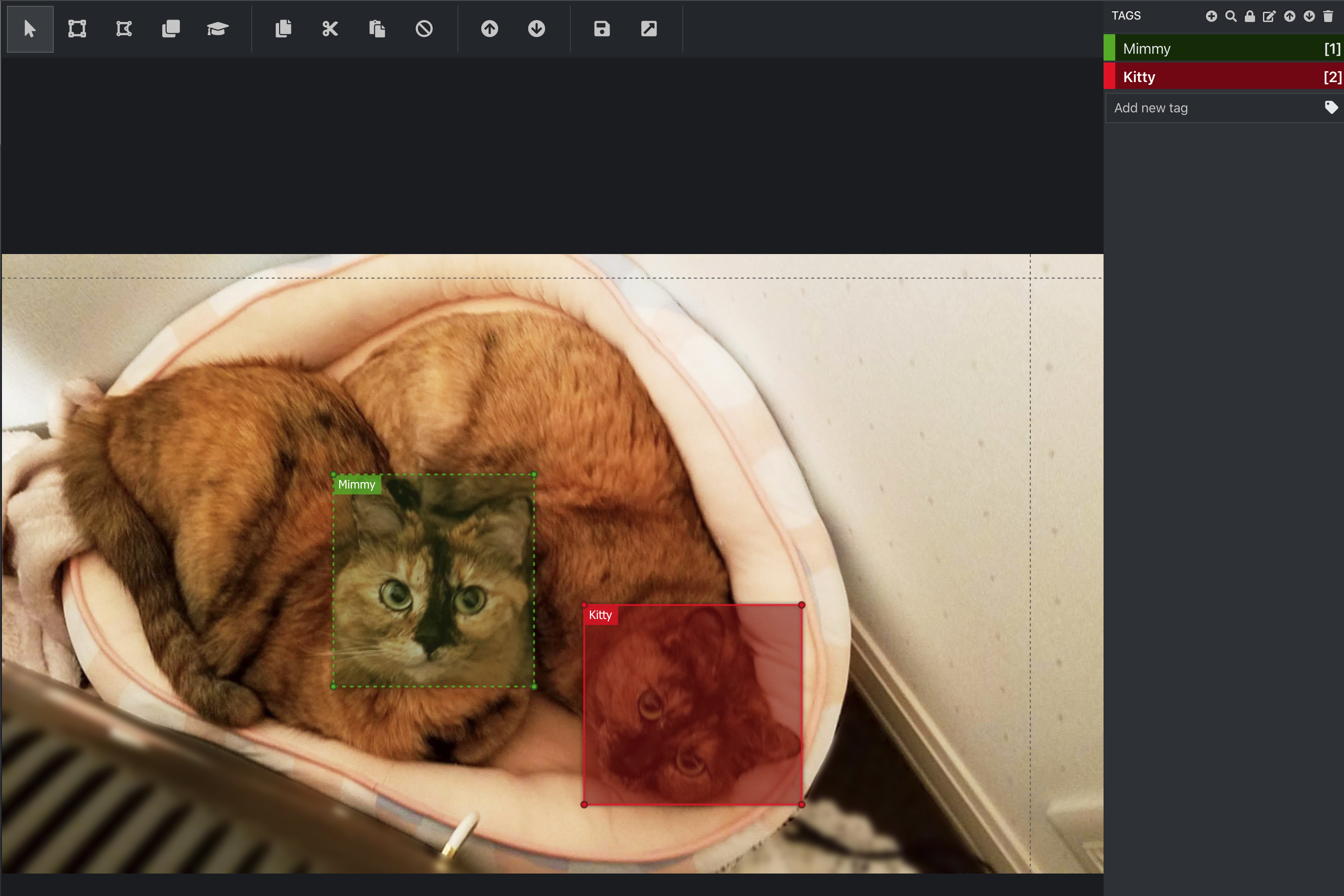
囲った時点ではグレーの四角になっているかもしれません。
もし囲った瞬間に任意のタグ名をつけたい場合は、右側のタグ名を選択したあと、
鍵マークのようなアイコンを選択して「このタグ固定でつけるぞ」と設定しておけば、
アノテーションしたときに自動でそのタグ名をつけてくれます。
(もしくは、MacだとCommandキーを押しながらタグ名クリックで同様の操作ができます。
WindowsはCtrlキー…?未確認です)
また、アノテーションの際にShiftキーを押すと正方形に固定してアノテーションすることも出来ます。
この辺は色々触って慣れると良いでしょう。
TFRecordとjsonの書き出し
TFRecordを生成するには、エクスポートの設定であらかじめ設定しておく必要があります。
左側のメニューアイコンで上から4番目の矢印のアイコンを選択します。
- Provider : 「Tensorflow Records」を選択します。
- Asset State : 「Only tagged Assets」を選択します。
もし誤って「Only Visited Assets」にしていると、
画像を確認したがアノテーションしていない画像の分まで書き出されてしまいます。
そうなると、学習結果に影響が出てしまいますので、ご注意下さい。
設定を終えたら「Save Export Settings」を選択して設定を保存します。

あとはアノテーションの画面に戻り、上部の右側にあるフロッピーのアイコンでプロジェクトの保存、右上矢印のアイコンで設定した形式(今回はTFRecord)の書き出しを行います。
ちなみに、jsonファイルは何も設定していなくても保存すると勝手に作成されています。

以上がVoTTを使用したTFRecordファイルの作成手順です。
次からがいよいよ本記事の本題です。
TFRecordとはどんなファイルなのか?
TFRecordとは
そもそもTFRecordとは何なのでしょうか?
TensorFlowの公式チュートリアルから抜粋すると、このように記載されています。
TFRecord 形式は、バイナリレコードのシリーズを保存するための単純な形式です。
プロトコルバッファ は、構造化データを効率的にシリアライズする、
プラットフォームや言語に依存しないライブラリです。
参考)TFRecords と tf.Example の使用法
これを読んだだけではピンと来ませんよね。
では早速先程VoTTを使用して書き出したTFRecordの中身を見てみましょう。
TFRecordファイルを読み込んで可視化してみる
TFRecordの中身は、以下のソースで可視化が可能です。
from __future__ import absolute_import, division, print_function, unicode_literals
import tensorflow as tf
import numpy as np
import IPython.display as display
# TFRecordのパスを指定する
filenames = 'VoTT/Cat/Cat-TFRecords-export/Mimmy_and_Kitty.tfrecord'
raw_dataset = tf.data.TFRecordDataset(filenames)
# 読み込んだ内容を別の形式に書き出す
# (.txtでも良い。jsonだとエディタ次第だが色ついて見やすくなるのでtxtよりオススメ)
tfr_data = 'tfr.json'
for raw_record in raw_dataset.take(1):
example = tf.train.Example()
example.ParseFromString(raw_record.numpy())
print(example)
# ファイルに書き出す。書き出さなくてもコンソールで見れるので必須ではない。
with open(tfr_data, 'w') as f:
print(example, file=f)
上記ソースで書き出したファイルを早速見てみましょう。
features {
feature {
key: "image/encoded"
value {
bytes_list {
value: "\377\330\377...
.....(大量なので割愛)..."
}
}
}
feature {
key: "image/filename"
value {
bytes_list {
value: "Mimmy_and_Kitty.jpg"
}
}
}
feature {
key: "image/format"
value {
bytes_list {
value: "jpg"
}
}
}
feature {
key: "image/height"
value {
int64_list {
value: 1440
}
}
}
feature {
key: "image/key/sha256"
value {
bytes_list {
value: "TqXFCKZWbnYkBUP4/rBv1Fd3e+OVScQBZDav2mXSMw4="
}
}
}
feature {
key: "image/object/bbox/xmax"
value {
float_list {
value: 0.48301976919174194
value: 0.7260425686836243
}
}
}
feature {
key: "image/object/bbox/xmin"
value {
float_list {
value: 0.3009025752544403
value: 0.5285395383834839
}
}
}
feature {
key: "image/object/bbox/ymax"
value {
float_list {
value: 0.6981713175773621
value: 0.8886410593986511
}
}
}
feature {
key: "image/object/bbox/ymin"
value {
float_list {
value: 0.3555919826030731
value: 0.5664308667182922
}
}
}
feature {
key: "image/object/class/label"
value {
int64_list {
value: 0
value: 1
}
}
}
feature {
key: "image/object/class/text"
value {
bytes_list {
value: "Mimmy"
value: "Kitty"
}
}
}
feature {
key: "image/width"
value {
int64_list {
value: 2560
}
}
}
}
他にもdifficult、truncated、view、source_idといったkeyが含まれていますが、
ここでは必要だと思われる内容のみ抜粋しました。
中身を確認すれば、以下のような構成であることが分かります。
-
image/encoded: 画像のバイナリデータ -
image/width,image/height: 画像のサイズ -
xmin,xmax,ymin,ymax: アノテーションした座標情報。アノテーションした数だけ値が含まれる。 -
class/text,class/label: タグ情報。textはタグの名前で、labelの数字はタグ名に付与された番号と考えて良い。今回の場合は、「Mimmy」が0で、「Kitty」 が1となっている。
ここまで来ると、だいぶTFRecordがどんな構成で出来ているデータなのか、きっと分かってきたことでしょう。
アノテーションしたデータから、アノテーション部分を切り出す方法
次は、VoTTでアノテーションした部分をプログラムで切り出す方法です。
もしこの作業が出来たら、自分でプログラムを書いてTFRecordファイルを作る際に、
次で紹介するような検出したい物体と背景を合成する、なんてアイデアに必要になるかもしれません。
または画像分類の機械学習にもきっと役立つでしょう。
また、これは試して気がついたことですが、
VoTTで見える画像の向きと実際に切り出すときの画像の向きが違うことがある
ということが分かりました。
つまり、VoTT内でアノテーションしたときに画面で見ている画像と、
json情報で切り出すときの元データの画像の向きが180度違うことがあったということです。
おかげで1枚だけ全然意図しない場所の画像が切り出されてしまっていました。
これがTFRecordでは正しい向きでアノテーションされているのかは定かではないので、
一度目視しておくと安心かもしれません。
さて、前置きが長くなりましたが、早速画像切り出しのためのjsonを確認してみましょう。
VoTTでアノテーション作業を終えて書き出す際、jsonも自動で書き出されることについては先述しましたね。
例で挙げた猫のデータは、以下のように書き出されました。
{
"asset": {
"format": "jpg",
"id": "1da8e6914e4ec2e2c2e82694f19d03d5",
"name": "Mimmy_and_Kitty.jpg",
"path": "【フォルダ名】/VoTT/Cat/IMAGES/Mimmy_and_Kitty.jpg",
"size": {
"width": 2560,
"height": 1440
},
"state": 2,
"type": 1
},
"regions": [
{
"id": "kFskTbQ6Z",
"type": "RECTANGLE",
"tags": [
"Mimmy"
],
"boundingBox": {
"height": 493.3142744479496,
"width": 466.2200532386868,
"left": 770.3105590062112,
"top": 512.0524447949527
},
"points": [
{
"x": 770.3105590062112,
"y": 512.0524447949527
},
{
"x": 1236.5306122448978,
"y": 512.0524447949527
},
{
"x": 1236.5306122448978,
"y": 1005.3667192429023
},
{
"x": 770.3105590062112,
"y": 1005.3667192429023
}
]
},
],
"version": "2.1.0"
}
(載せると長くなるため、もう1匹のKittyタグの情報は割愛しました。)
ご覧の通り、ファイル名と画像サイズ、さらにはアノテーションした座標情報が入っています。
これらの情報だけで画像を切り出すことは十分可能ですね。
アノテーションされた座標情報はboundingBoxとpointsの2種類がご丁寧に含まれています。
色々やり方はありそうですが、今回はboundingBoxを見に行って、切り出す方法を取ってみました。
以下、そのソースコードです。
import json
import os
import fnmatch
import cv2 as cv
JSON_DIR = 'VoTT/Cat/'
IMG_DIR = 'VoTT/Cat/'
CUT_IMAGE = 'cut_images/'
CUT_IMAGE_NAME = 'cat'
IMAGE_FORMAT = '.jpg'
class Check():
def filepath_checker(self, dir):
if not (os.path.exists(dir)):
print('No such directory > ' + dir)
exit()
def directory_init(self, dir):
if not(os.path.exists(dir)) :
os.makedirs(dir, exist_ok=True)
def main():
check = Check()
#jsonファイルを格納したディレクトリが存在するかチェック
check.filepath_checker(JSON_DIR)
#'CUTした画像の格納場所を準備'
check.directory_init(CUT_IMAGE)
#jsonを解析し、画像とアノテーション座標から切り出しをしていく
count = 0
for jsonName in fnmatch.filter(os.listdir(JSON_DIR), '*.json'):
#jsonを開く
with open(JSON_DIR + jsonName) as f :
result = json.load(f)
#画像のファイル名の取得
imgName = result['asset']['name']
print('jsonName = {}, imgName = {} '.format(jsonName, imgName))
img = cv.imread(IMG_DIR + imgName)
if img is None:
print('cv.imread Error')
exit()
#アノテーションした数だけループ
for region in result['regions'] :
height = int(region['boundingBox']['height'])
width = int(region['boundingBox']['width'])
left = int(region['boundingBox']['left'])
top = int(region['boundingBox']['top'])
cutImage = img[top: top + height, left: left + width]
#アノテーション中に誤って1点クリックしてしまった情報は避ける
if height == 0 or width == 0:
print('<height or width is 0> imgName = ', imgName)
continue
#書き出す前にリサイズする場合はコメントアウトを外しましょう
#cutImage = cv.resize(cutImage, (300,300))
#「cut_images/cat0000.jpg」と連番でファイルを書き出す
cv.imwrite(CUT_IMAGE + CUT_IMAGE_NAME + "{0:04d}".format(count + 1) + IMAGE_FORMAT, cutImage)
print("{0:04d}".format(count+1))
count += 1
if __name__ == "__main__":
main()
ソースコード内に、if height == 0 or width == 0という条件分岐があるのは、
VoTTでアノテーション中に誤操作でクリックした部分がデータとして残ってしまい、
切り出す面積が無いためにエラーが起きたことがあったため、
そのヒューマンエラーを回避するために盛り込んでみました。

私の場合、1枚にたくさんアノテーションする必要性が業務上あったため、
ますますそれに気づきにくい状況でした。しかも大量に画像データがあるとなおさらです。
さて、長くなってしまいましたが、次からはいよいよTFRecordを作成するプログラムを書いてみましょう。
Pythonで物体検出用のTFRecordを作成してみる
TFRecordの中身の構成を大まかに理解できたところで、
最後はいよいよソースコードを書いてTFRecordを生成してみましょう。
ソースコードの説明
今回載せているソースでやっていることは、次の通りです。
- 事前に背景画像と合成する物体(猫)の画像を用意する
- 背景画像と物体画像を合成する(今回は任意の位置に固定)
- 合成した座標位置情報などTFRecordに必要な情報を整理する
- TFRecordファイルを生成する
まず、背景画像は素材サイトから拝借しました。
こちらです。

そして、合成する物体画像はこちらです。

ソースコードのサンプル
以下、そのソースコードです。
import tensorflow as tf
import cv2 as cv
import utils.dataset_util as dataset_util
def img_composition(bg, obj, left, top):
"""
背景と物体を合成する関数
----------
bg : numpy.ndarray 〜 背景画像
obj : numpy.ndarray 〜 物体画像
left : int 〜 合成する座標(左)
top : int 〜 合成する座標(上)
"""
bg_img = bg.copy()
obj_img = obj.copy()
bg_h, bg_w = bg_img.shape[:2]
obj_h, obj_w = obj_img.shape[:2]
roi = bg_img[top:top + obj_h, left:left + obj_w]
mask = obj_img[:, :, 3]
ret, mask_inv = cv.threshold(cv.bitwise_not(mask), 200, 255, cv.THRESH_BINARY)
img1_bg = cv.bitwise_and(roi, roi, mask=mask_inv)
img2_obj = cv.bitwise_and(obj_img, obj_img, mask=mask)
dst = cv.add(img1_bg, img2_obj)
bg_img[top: obj_h + top, left: obj_w + left] = dst
return bg_img
def set_feature(image_string, label, label_txt, xmins, xmaxs, ymins, ymaxs):
"""
TFRecordに書き込む情報をセットする関数
この関数を使用するには、TensorFlow Object Detection APIの「object detection」ディレクトリにある
「util」のライブラリを持ってくる必要がある
----------
image_string : bytes 〜 合成済みの画像の情報
label : list 〜 アノテーションしたタグの番号
label_txt : list 〜 アノテーションしたタグ名
xmins, xmaxs, ymins, ymaxs : list 〜 アノテーションした座標を0.0~1.0で表現された値
"""
image_shape = tf.io.decode_jpeg(image_string).shape
feature = {
'image/encoded': dataset_util.bytes_feature(image_string),
'image/format': dataset_util.bytes_feature('jpg'.encode('utf8')),
'image/height': dataset_util.int64_feature(image_shape[0]),
'image/width': dataset_util.int64_feature(image_shape[1]),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
# 1つのみ情報を付与するならこのコメントアウトしている関数でも可能(型は合わせて)
# 'image/object/class/label': dataset_util.int64_feature(label),
# 'image/object/class/text': dataset_util.bytes_feature(LABEL.encode('utf8')),
# 1枚に2つ以上タグ付けするような場合なら下の「_list_」が入った関数を使う
# もちろん1つだけの場合も使えるので、結局こちらを使用するのがオススメです
'image/object/class/label': dataset_util.int64_list_feature(label),
'image/object/class/text': dataset_util.bytes_list_feature(label_txt),
}
return tf.train.Example(features=tf.train.Features(feature=feature))
def main():
# 各ファイルパス名
bg_image_path = './comp/bg.jpg'
obj_img_path = './comp/Mimmy_image.png'
comp_img_path = './comp/img_comp.jpg'
tfr_filename = './mimmy.tfrecord'
# TFRecord用
tag = {'Mimmy': 0, 'Kitty': 1, 'Mimelo': 2}
xmins = []
xmaxs = []
ymins = []
ymaxs = []
class_label_list = []
class_text_list = []
datas = {}
# ラベル名の設定
class_label = tag['Mimmy']
# 背景の読み込み
bg_img = cv.imread(bg_image_path, -1)
bg_img = cv.cvtColor(bg_img, cv.COLOR_RGB2RGBA)
bg_h, bg_w = bg_img.shape[:2]
# 物体の読み込み
obj_img = cv.imread(obj_img_path, -1)
obj_img = cv.cvtColor(obj_img, cv.COLOR_RGB2RGBA)
scale = 250 / obj_img.shape[1]
obj_img = cv.resize(obj_img, dsize=None, fx=scale, fy=scale)
obj_h, obj_w = obj_img.shape[:2]
# 背景と物体を合成
x = int(bg_w * 0.45) - int(obj_w / 2)
y = int(bg_h * 0.89) - int(obj_h / 2)
comp_img = img_composition(bg_img, obj_img, x, y)
# 合成した画像の書き出し
cv.imwrite(comp_img_path, comp_img)
# TFRecordの座標情報リストに追加
xmins.append(x / bg_w)
xmaxs.append((x + obj_w) / bg_w)
ymins.append(y / bg_h)
ymaxs.append((y + obj_h) / bg_h)
# TFRecordのlabel情報を追加
class_label_list.append(class_label)
class_text_list.append('Mimmy'.encode('utf8'))
datas[comp_img_path] = class_label
# TFRecordを作成する処理
with tf.io.TFRecordWriter(tfr_filename) as writer:
for data in datas.keys():
image_string = open(data, 'rb').read()
tf_example = set_feature(image_string, class_label_list, class_text_list, xmins, xmaxs, ymins, ymaxs)
writer.write(tf_example.SerializeToString())
if __name__ == "__main__":
main()
プログラム実行後に出来た画像はこちらです。

ソースコードの補足
ソースコード内のコメントにも記載しましたが、TensorFlow Object Detection APIに含まれるライブラリが必要になりますので、ご注意下さい。
- 必要なライブラリ
- TFRecordを生成するのにとても参考になるソース達(
xmin,yminなど座標情報の計算はここで勉強になりました)
今回は説明用のために、合成用の画像1枚ずつと、1つのTFRecordファイルを生成するソースコードをご紹介しました。
ですが、実際はもっともっと多くの画像から大量のTFRecordファイルを生成する必要があるかと思います。
私の場合は、指定したフォルダからランダムに画像を選んで組み合わせるやり方や、
合成する座標も少しランダムにするなどして量産する方法を試してみました。
皆さんも、もし教師データの量産のコツが本記事をきっかけに色々分かりましたら、ぜひ教えていただけたらと思います。
作成したTFRecordの中身を確認してみる
それでは最後に念の為、今作成したTFRecordファイルの中身を、
前半で紹介した方法で確認してみましょう。
features {
feature {
key: "image/encoded"
value {
bytes_list {
value: "\377\330\377...
.....(大量なので割愛)..."
}
}
}
feature {
key: "image/format"
value {
bytes_list {
value: "jpg"
}
}
}
feature {
key: "image/height"
value {
int64_list {
value: 1397
}
}
}
feature {
key: "image/object/bbox/xmax"
value {
float_list {
value: 0.5151041746139526
}
}
}
feature {
key: "image/object/bbox/xmin"
value {
float_list {
value: 0.38489583134651184
}
}
}
feature {
key: "image/object/bbox/ymax"
value {
float_list {
value: 0.9878310561180115
}
}
}
feature {
key: "image/object/bbox/ymin"
value {
float_list {
value: 0.7916964888572693
}
}
}
feature {
key: "image/object/class/label"
value {
int64_list {
value: 0
}
}
}
feature {
key: "image/object/class/text"
value {
bytes_list {
value: "Mimmy"
}
}
}
feature {
key: "image/width"
value {
int64_list {
value: 1920
}
}
}
}
上記のように一度で良いので中身をきちんと確認し、
意図した値になっていれば問題ないでしょう!
さいごに
TensorFlowで物体検出を行うために役立つTFRecord形式のデータについて、
また長い記事になってしまいましたが分かる範囲でまとめてみました。
本記事をきっかけに教師データ作成の幅が広がれば幸いです。
最後まで目を通していただきありがとうございます。