はじめに
Chainerは深層学習のフレームワークです。Preffered Networks, PFNが開発、公開しています。この記事では、Chainerを使う「雰囲気」のようなものを簡単に説明してみようと思います。
Re:ゼロから始めるChainer生活と内容がかなり重なってしまいますが、ご容赦ください。また、Chainer Advent Calender 2017の三日目の記事としてPFNの中の人が書いたChainer v3 ビギナー向けチュートリアルが大変オススメです。この記事は、Chainerの中の人では無い人がChainerをどう思っているかを書いた記事だと思って参考程度に読んでいただければ幸いです。
https://github.com/kaityo256/chainer_zero
にアップロードしたソースを例に説明します。
分類問題
機械学習には様々な種類がありますが、ここでは簡単のため、分類問題を考えましょう。分類問題とは、何か入力が与えられた時、あらかじめ決められたカテゴリのどれに分類するかを決める問題です。有名なのはMNISTという0から9までの手書き文字を分類するもので、これは28x28=784個の入力が与えられた時、0から9の10種類のラベルを出力する問題となります。他にも画像が与えられた時にそれが「犬であるか」「猫であるか」といった判定をするのも分類問題です。このように、与えられた入力に対して何かラベルを返す仕組みを分類器といいます。
様々なデータの与えかたが考えられますが、簡単のために、一次元のデータ列として入力が与えられるとしましょう。いま、入力を$n_{\mathrm{out}}$個のカテゴリに分類することにします。分類器をもっとも簡単に実現するには、データが与えられた時に0から$n_{\mathrm{out}}-1$の数字一つを返す、という仕組みが考えられますが、これでは出力に「重み」がありません。つまり、どんな入力に対しても自信満々に「これだ!」と答えていることになります。勉強でも、自信があって答えて正解だった場合と、自信がなくてたまたま正解だった場合は区別して、たまたま正解だった場合はちゃんと勉強しなおした方がいいですよね。機械学習でも、「その判断にどれくらい自信があるか」の重みを数値化しておいたほうが学習がうまくいくため、出力は$n_{\mathrm{out}}$次元のベクトルで出させたほうが便利です。この時、一番数値が大きい場所が「分類器がそれだと思うカテゴリ」ということになります。
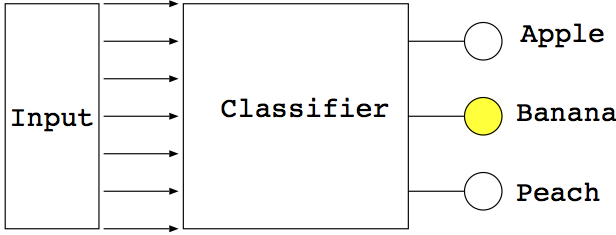
そんなわけで、分類器とは「一次元ベクトルを受け取って一次元ベクトルを返す大きな行列のようなもの」と思うことができます。
さて、ここで行列と書きましたが、実は行列ではうまくいきません。行列で表現できるのは入力に対して出力が線形のものだけです。一般の学習にはなんらかの非線形性が必要になります。
非線形性の説明は難しいですが、分類器の内部では「情報をいい感じに複雑に処理する」必要があります。単なる行列では単純すぎてうまく分類ができません。この「いい感じに複雑に処理する」ために参考にしたのが生物の神経ネットワークです。神経ネットワークはニューロンがいくつもつながって、お互いがお互いに影響を与えながら、全体として何かの機能を発現します。この神経ネットワークを模して作られたのがニューラルネットワークです1。
具体的に、10個の数字列を入力とし、それがあるカテゴリに属すかどうかの二値分類をする分類器を考えることにします。分類器は、長さ10のベクトルを受け取り、長さ2のベクトルを出力します。出力のうち、0番目の方が値が大きければ、この分類器は「OFF」、つまりそのカテゴリに属さないと判断したことになります2。逆に、1番目の値が大きければ、この分類器は「ON」、つまり入力データはそのカテゴリに属す、と判断したことになります。
この分類を、三層のニューラルネットワークで行うことを考えましょう。ニューラルネットワークは、入力側から出力まで、ニューロンが層のように並んでいるように見えます。このニューロンの「層」は、行列$W$、ベクトル$b$、そして非線形な関数(活性化関数)で表現されます。非線形な関数はなんでもいいのですが、最近はReLUがよく使われているようです。
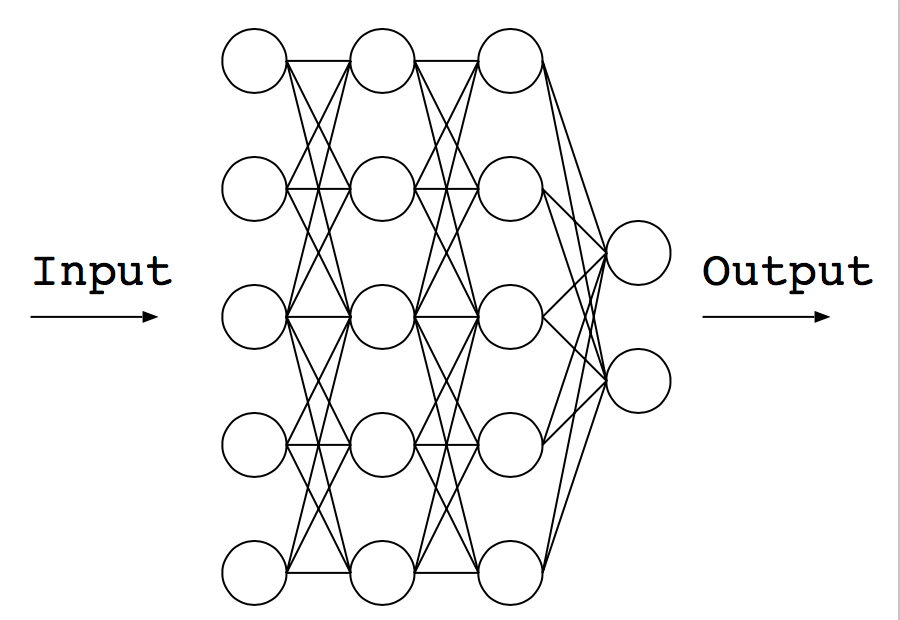
上図ではニューラルネットワークが左からデータを刺激として受け取って、最終的に右側のどのニューロンが活性化したかで分類された、みたいな解釈がなされますが、実際に行われているのは、一層ごとに、入力ベクトルを$x$、出力ベクトルを$y$として、
y = \mathrm{ReLU}(W x + b)
みたいなことを繰り返しているだけです。ここで、系の持つ自由度(自由パラメータ)は、三個の行列$W$と、三個のベクトル$b$の中身です。学習とは、あらかじめ入力と出力(ラベル)がわかっているデータセットを利用して、これら行列とベクトルの中身をいい感じに調整することに他なりません。要するにここでいう学習とは最適化の一種となります3。
我々は、手持ちのデータセットから、目的に沿う結果が得られる分類器とするために何か最適化をする、それがここでの文脈での機械学習ということになります。
Chainerがやってくれること
さて、分類器をつくるためには、
- ネットワーク形状を決める
- $W$や$b$に適当な数字をいれる
- あるデータセットを入れてみて、出力を確認する
- 正解データからのずれから、適切にパラメータを調整する
- 以下、「学習がそれなりにうまくいった」と思えるまで繰り返し
といったことをしなければなりません。特に面倒なのが「正解データからのずれから、適切にパラメータを調整する」で、それはそれはたくさんのパラメータ調整法が提案されています。AdamとかAdaGradとかRMSPropとかSGDとかよく目にすると思いますが、これらはすべて「入力を入れてみて、正解からずれていた時に、そのずれから適切にパラメータを調整する手法」です。これを実際に実装したり、いちいち切り替えたりするのはとても面倒です。なのでそこを代わりにやってくれるフレームワークが作られることになりました。Chainerもその一つです。
具体的には、Chainerは「1. ネットワーク形状を決める」以外のすべてを肩代わりしてくれます。プログラマが行うのは
- ネットワーク形状を決める
- 正解データを用意する
- 最適化手法を選ぶ
- 最適化のためのパラメータ(エポック数やミニバッチサイズ等)を決める
ことだけです。後は全部Chainerがよしなにやってくれます。前置きが長くなりましたが、具体的にChainerが何をやってくれるかを見てみようと思います。
モデルの定義
Chainerは、「ニューロンのつながり」に注目し、それを「リンク」と呼びます。ニューラルネット(以後、モデルと呼びます)は、リンクの集まり(Chain)として表現されます。
このChainerのChainをラップするクラスを作っておくと便利なので、こんなスクリプトを書きます。入力は自由ですが、出力は2個、つまり二値分類決め打ちのクラスになっていることに注意してください。
import chainer
import chainer.functions as F
import chainer.links as L
from chainer import training
from chainer.training import extensions
class MLP(chainer.Chain):
def __init__(self, n_units, n_out):
super(MLP, self).__init__(
l1 = L.Linear(None, n_units),
l2 = L.Linear(None, n_units),
l3 = L.Linear(None, n_out)
)
def __call__(self, x):
h1 = F.relu(self.l1(x))
h2 = F.relu(self.l2(h1))
return self.l3(h2)
class Model:
def __init__(self,n_in):
self.model = L.Classifier(MLP(n_in, 2))
def load(self,filename):
chainer.serializers.load_npz(filename, self.model)
def save(self,filename):
chainer.serializers.save_npz(filename, self.model)
def predictor(self, x):
return self.model.predictor(x)
def get_model(self):
return self.model
これはChainerの分類器(chainer.links.Classifier)をラップしたクラスです。このように、Chainerはモデルをクラスの形で表現します。MLPの中のl1やl2は、ニューロン間の「層」を表現しています。
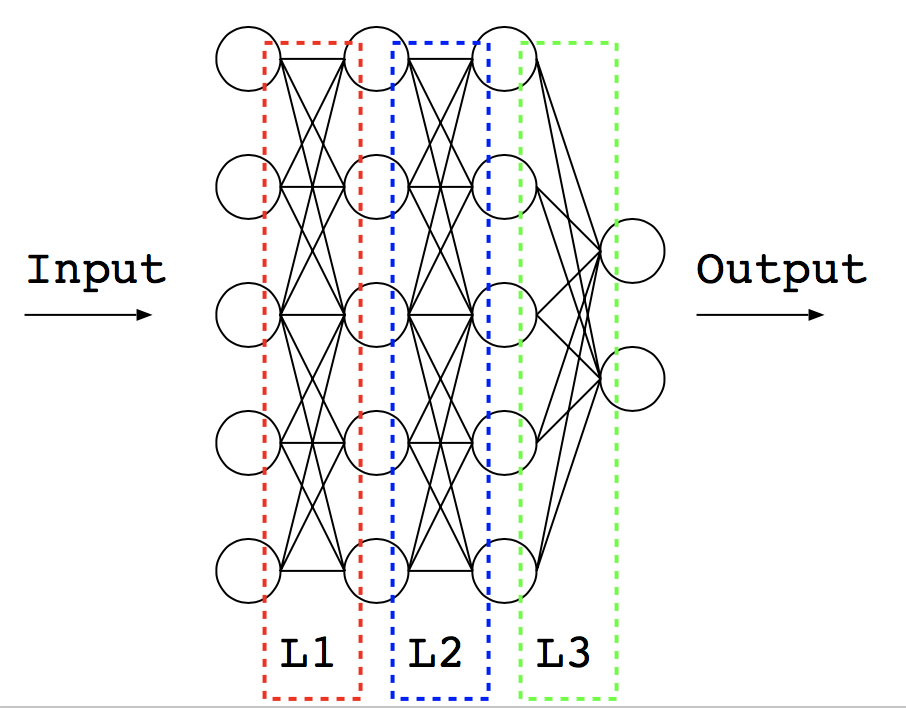
このように、Chainerが扱う実体はニューロン間の「層」であり、ニューロンではありません。
このクラスはこんな感じに使います。
m = Model(units)
model = m.get_model()
mがラップしたクラス、modelがChainerの最適化器に渡すモデルです。こうしてラップしておくと、学習が済んだ後に
m.save(`test.model`)
としてデータを保存し、その後
m.load(`test.model`)
として読み込んで使えます。ソース見て分かる通り、これらはChainerのシリアライザのラッパーです。
学習
学習方法については、他の様々な文献があるので詳細は省きます。
やるべきことは
- テスト用とトレーニング用のデータセットを用意する
- 最適化手法を選ぶ
- 学習を指示する
これだけです。
Chainerの学習用データはchainer.datasets.TupleDatasetという形式です。これにnumpyの配列を与えるとデータセットを作れます。例えば入力データのリストをx、その正解ラベルのリストをyとします。例えば入力x[i]に対応するラベルはy[i]といった具合です。そうすると、
dataset = chainer.datasets.TupleDataset(x,y)
としてChainerに食わせるデータが作れます。なお、xはnumpy.float32型、yはnumpy.int32型で用意してください。
こうして、トレーニング用データtrainと、テスト用データtestが用意できたら、次にイテレータを用意します、
train_iter = chainer.iterators.SerialIterator(train, batchsize)
test_iter = chainer.iterators.SerialIterator(test, batchsize, repeat=False, shuffle=False)
ここで、バッチサイズは適当な値を入れてあげてください。
次に最適化手法を選びます。とりあえずAdamで良いでしょう。
optimizer = chainer.optimizers.Adam()
optimizer.setup(model)
先程作ったmodelを与えてセットアップしてください。
後はtrainer.extendでいろいろ出力する情報を設定した後、updaterにイテレータを登録し、trainerにupdaterを登録して、trainer.run()を実行すると学習を開始します。
updater = training.StandardUpdater(train_iter, optimizer, device=gpu)
trainer = training.Trainer(updater, (epoch, 'epoch'), out='result')
trainer.run()
epochはエポックです。これも適当な値を入れてあげてください。
もしAdamでうまくいかなかったら、別の最適化手法を試しましょう。例えばSGDなら
optimizer = chainer.optimizers.SGD()
とするだけです(簡単!)。
Chainerには他にもいろいろな最適化手法が実装されているので、いろいろ試してみるといいでしょう。
学習結果を使う
いま。10入力、2出力の分類器が学習できたとしましょう。そしてそれがtest.modelとして保存されているとします。それはこうやって使うことができます。まず、ロードします。
model = Model(10)
model.load(`test.model`)
さて、このロードされたニューラルネットに「全部ゼロ」の入力を与えた場合の出力を調べましょう。こんな感じになります。
a = [0.0]*10
x = np.array([a],dtype=np.float32)
y = model.predictor(x).data[0]
print(y)
ここで、Chainerは「入力を複数ひとまとめにして渡し、出力もひとまとめにして返す」仕様になっています。なので、実際にはxは入力のリストで、yは出力のリストになります。例えば100個のデータを一度に渡して100個の分類結果を一度にもらえるイメージです。バッチ処理といえばわかりやすい人がいるかもしれません。
だから、ここではリストaというデータ一つだけに対する出力を知りたいわけですが、モデルに渡すのはそれをさらにリストに入れた[a]です。
出力はたとえばこんな感じになります。
[ 0.196338 0.16816881]
これはオールゼロという入力に対して、ラベル0の重みが0.196338、ラベル1の重みが0.16816881という値だということです。このニューラルネットの気持ちとしては、「おそらくラベルは0だと思うけれど、あまり自信がない」といったところでしょうか(自信がある場合には重みにもっと差がつきます)。ちなみに、ラベルそのものを知りたい場合はnumpy.argmaxを使います。
import numpy as np
print(np.argmax(y))
結果は
$ python test.py
0
となり、このニューラルネットは、「0」に分類した、ということです。
まとめ
Chainerをどんな感じに使うのかを簡単にまとめてみました。他のフレームワークを使ったことがないのであまり比較とかできませんが、どちらかというとChainerは、Pythonっぽいスクリプトになります。また、Numpyがあらわに「見える」ことが多いです。これはこのフレームワークが後ろを隠蔽しきれていないという見方もできますが、そのあたりを完全に抽象化されてしまうと逆にわかりづらくなりますし、これくらい後ろの実装が見える方がいろいろやりやすいのかな、という気がします。
ここで述べたのはChainerの機能のほんの一部です。ドキュメントもわりと豊富なので、PythonとNumpyに慣れている人ならChainerはすぐ使えるようになると思いますよ。