Facebookが公開している時系列解析用のライブラリProphetの公式ドキュメントを翻訳していきます。
目次
1.Prophet公式ドキュメント翻訳(概要&特徴編)
2.Prophet公式ドキュメント翻訳(インストール編)
3.Prophet公式ドキュメント翻訳(クイックスタート編)
4.Prophet公式ドキュメント翻訳(飽和状態の予測編)
5.Prophet公式ドキュメント翻訳(トレンドの変化点編)
6.Prophet公式ドキュメント翻訳(周期性・イベント効果・説明変数の追加編)
7.Prophet公式ドキュメント翻訳(増加し続ける周期性編)
8.Prophet公式ドキュメント翻訳(誤差の間隔編)
9.Prophet公式ドキュメント翻訳(外れ値編)
10.Prophet公式ドキュメント翻訳(1日単位ではないデータ編)
11.Prophet公式ドキュメント翻訳(モデルの診断編)
12.Prophet公式ドキュメント翻訳(ヘルプ編)
2018/10/29公開。原文リンクは以下。
・Prophet概要&特徴:https://facebook.github.io/prophet/
・公式ドキュメント:https://facebook.github.io/prophet/docs/quick_start.html
今回の記事はモデルの診断編です。
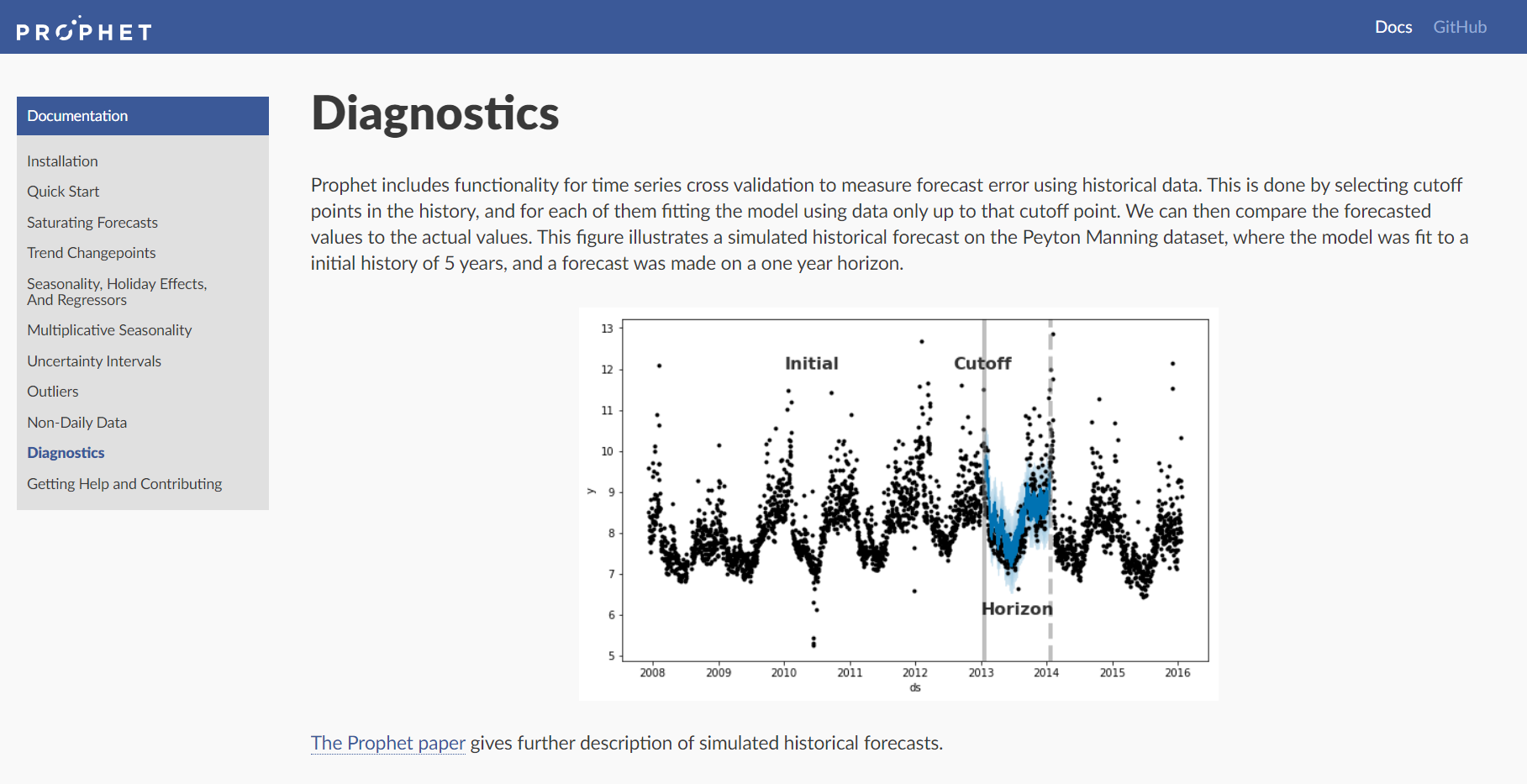
モデルの診断
Prophetは時系列データを用いた予測を計測するために、データに対してCV(交差検証)を実行する関数があります。それは、時系列データにいくつかのcutoff(切断)ポイントを置き、ポイント間のデータに対してモデルのフィッティングを行います。すると、予測値と実測値の比較ができるようになります。(未来の予測と違い正解データである実測値が存在するため)以下の図はPeyton Manningの時系列データセットで、この関数をシミュレートしたものです。モデル図のInitialの部分から5年分をフィッティングしたものであり、予測の範囲はcutoffから1年です。
Prophetの論文では、今回のトピックに関するさらなる説明がなされています。
CV(交差検証)のプロセスはcross_validation関数を用いて、時系列データにあるcutoffの範囲を自動的に計算することで進められます。horizonという引数で予測の範囲を指定し、initial引数でモデリングするデータの始点を指定できます。また、period引数でcutoffポイントを置く間隔を指定します。デフォルト設定では、モデリングするデータの大きさは予測の範囲の3倍で、cutoffは予測の範囲の半分の間隔で置かれます。
cross_validationの結果は、cutoffの日付カラム・予測した日付のカラム・実測値のyカラム・テストデータで予測したyhatカラムの4つを格納したデータフレームで返されます。特筆すべきは、cutoffからcutoff + horizonの範囲で予測値が計算されるということです。そしてこのデータフレームは、yhatとyの間の残差を計算するために使われます。
ここでは、予測のパフォーマンスを評価するためにCV(交差検証)を365日の範囲で行います。トレーニングデータの始点は730日目でそこから180日ごとの間隔でcutoffを置き、予測します。今回の8年分の時系列データでは、11回予測を行うことになります。
# R
df.cv <- cross_validation(m, initial = 730, period = 180, horizon = 365, units = 'days')
head(df.cv)
# Python
from fbprophet.diagnostics import cross_validation
df_cv = cross_validation(m, initial='730 days', period='180 days', horizon = '365 days')
df_cv.head()
| DS | YHAT | YHAT_LOWER | YHAT_UPPER | Y | CUTOFF | |
|---|---|---|---|---|---|---|
| 0 | 2010-02-16 | 8.957184 | 8.438130 | 9.431683 | 8.242493 | 2010-02-15 |
| 1 | 2010-02-17 | 8.723619 | 8.228941 | 9.225985 | 8.008033 | 2010-02-15 |
| 2 | 2010-02-18 | 8.607378 | 8.086717 | 9.125563 | 8.045268 | 2010-02-15 |
| 3 | 2010-02-19 | 8.529250 | 8.053584 | 9.056437 | 7.928766 | 2010-02-15 |
| 4 | 2010-02-20 | 8.271228 | 7.748368 | 8.756539 | 7.745003 | 2010-02-15 |
performance_metricsの効用としては、予測のパフォーマンスを示す値(yhat・yhat_lower・yhat_upperとyを比較した値)を計算するために使われるということです。計算する統計量は、MSE(平均二乗誤差)・RMSE(MSEの平方根をとったもの)・MAE(平均絶対誤差)・MAPE(平均絶対パーセント誤差)そして、yhat_lowerからyhat_upperの範囲です。これらの統計量はdf_cvというデータセットをperformance_metrics関数(メソッド)に渡すことで計算されます。計算結果を格納したデータセットは、horizen(データの日付からcutoffの日付を引いた日数)でソートされます。デフォルト設定では、cutoffからcutoff+horizenの範囲内にあるデータの10%が予測に使われます。そして、その予測をもとにデータフレームの各行で統計量の計算が行われます。この10%という数字はrolling_windowというパラメータで調整できます。 |
# R
df.p <- performance_metrics(df.cv)
head(df.p)
# Python
from fbprophet.diagnostics import performance_metrics
df_p = performance_metrics(df_cv)
df_p.head()
| HORIZON | MSE | RMSE | MAE | MAPE | COVERAGE | |
|---|---|---|---|---|---|---|
| 3297 | 37 days | 0.481970 | 0.694241 | 0.502930 | 0.058371 | 0.673367 |
| 35 | 37 days | 0.480991 | 0.693535 | 0.502007 | 0.058262 | 0.675879 |
| 2207 | 37 days | 0.480936 | 0.693496 | 0.501928 | 0.058257 | 0.675879 |
| 2934 | 37 days | 0.481455 | 0.693870 | 0.502999 | 0.058393 | 0.675879 |
| 393 | 37 days | 0.483990 | 0.695694 | 0.503418 | 0.058494 | 0.675879 |
CV(交差検証)のパフォーマンスの表はplot_cross_validation_metricで可視化できます。以下ではMAPE(平均絶対パーセント誤差)を表示しています。図の各点はdf_cvで計算した残差の絶対値(%)を表しています。青線がMAPEです。それは図の各点を横軸の日毎に平均をとることで算出しています。この図から、1ヵ月先の予測はMAPEが約5%になり、1年先の予測では約11%まで上昇することが読み取れます。 |
# R
plot_cross_validation_metric(df.cv, metric = 'mape')
# Python
from fbprophet.plot import plot_cross_validation_metric
fig = plot_cross_validation_metric(df_cv, metric='mape')
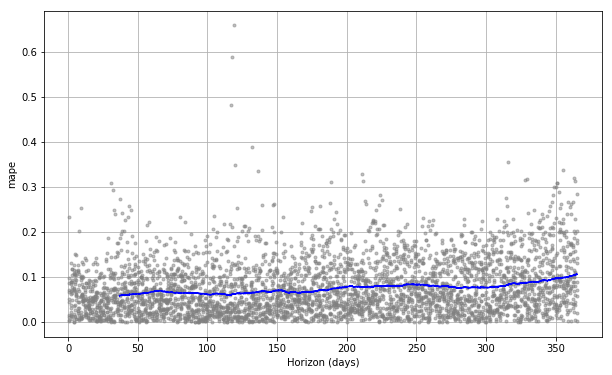
先ほど述べたrolling_windowというパラメータを増加させることは、上の図のMAPEの青線をより滑らかにすることにつながります。
また、今回は720としたinitialというパラメータを指定する際は、CV(交差検証)に使えるデータをできるだけ多くできるように指定してください。というのも、CVに使うモデルに全ての特徴を含んだデータを渡す必要があるからです。特に、周期性や追加した説明変数の情報が入っているようにしてください。少なくとも、年単位または週単位の周期性などはモデルに使うデータに入れてください。