Facebookが公開している時系列解析用のライブラリProphetの公式ドキュメントを翻訳していきます。
目次
1.Prophet公式ドキュメント翻訳(概要&特徴編)
2.Prophet公式ドキュメント翻訳(インストール編)
3.Prophet公式ドキュメント翻訳(クイックスタート編)
4.Prophet公式ドキュメント翻訳(飽和状態の予測編)
5.Prophet公式ドキュメント翻訳(トレンドの変化点編)
6.Prophet公式ドキュメント翻訳(周期性・イベント効果・説明変数の追加編)
7.Prophet公式ドキュメント翻訳(増加し続ける周期性編)
8.Prophet公式ドキュメント翻訳(誤差の間隔編)
9.Prophet公式ドキュメント翻訳(外れ値編)
10.Prophet公式ドキュメント翻訳(1日単位ではないデータ編)
11.Prophet公式ドキュメント翻訳(モデルの診断編)
12.Prophet公式ドキュメント翻訳(ヘルプ編)
2018/10/26公開。原文リンクは以下。
・Prophet概要&特徴:https://facebook.github.io/prophet/
・公式ドキュメント:https://facebook.github.io/prophet/docs/quick_start.html
今回の記事は誤差の間隔編です。
誤差の間隔
デフォルト設定では、Prophetはyhatで予測結果の誤差の範囲を出力します。この誤差の間隔を出力する過程では、いくつかの重要な推測が含まれています。
予測の誤差の推定には、3つの要素があります。トレンドの誤差、周期性の推定の誤差、観測ノイズです。
トレンドの誤差
予測の誤差を決める要因の中で最大のものは、トレンドが未来に変化する可能性です。ドキュメントで紹介してきた時系列データは、過去の時系列から未来のトレンドをしっかり予測しています。Prophetはトレンドの変化を感知し、フィッティングを行います。しかし、未来のトレンドはどのように変化するのでしょうか。それを100%の精度で知ることは不可能です。したがって、私たちはできる範囲で最も納得のいく予測をします。そして、未来のトレンドの変化は過去のトレンドの変化と似ているものになるという推測をします。特に、未来のトレンドの変化の頻度と大きさは、過去のものと同じになるだろうと推測します。このようなプロセスを経て誤差の範囲を計算し、未来のトレンドの変化を予測します。
この誤差を計測するプロセスの一つの特徴は、changepoint_prior_scaleを増加させることによって誤差の大きさをより細かく調整し、予測の精度を上げているという点にあります。このことはより細かい変化をモデリングする場合、予測の精度が上がることと、誤差の範囲を過学習の便利な指標とすることを可能にしています。
誤差の範囲の広さ(デフォルト設定では80%信頼区間)は、interval_widthというパラメータで調整することができます。
# R
m <- prophet(df, interval.width = 0.95)
forecast <- predict(m, future)
# Python
forecast = Prophet(interval_width=0.95).fit(df).predict(future)
もう一度述べておくと、これらの誤差の間隔の予測は過去のトレンドの変化の頻度と大きさを基になされています。この予測はおそらく100%正しいわけではないでしょう。
周期性の誤差
デフォルト設定では、Prophetはトレンドの誤差と観測ノイズを考慮します。周期性の誤差を考慮したい場合は、十分なベイジアンサンプリングを行わなければなりません。これは mcmc.samplesというパラメータ(既定値では0)を用います。私たちはこれをクイックスタートの章で使ったPeyton Manningの最初の6カ月分のデータをつかって説明していきます。
# R
m <- prophet(df, mcmc.samples = 300)
forecast <- predict(m, future)
# Python
m = Prophet(mcmc_samples=300)
forecast = m.fit(df).predict(future)
これはMCMCサンプリングによる典型的な最大事後確率推定に代わるものであり、観測値の数によってサンプリングをより大きくとることもできます。例えば、秒単位でとる代わりに、分単位でとるということです。十分なサンプリングを行ったら、プロットして周期性の誤差を見ることができます。
# R
prophet_plot_components(m, forecast)
# Python
fig = m.plot_components(forecast)
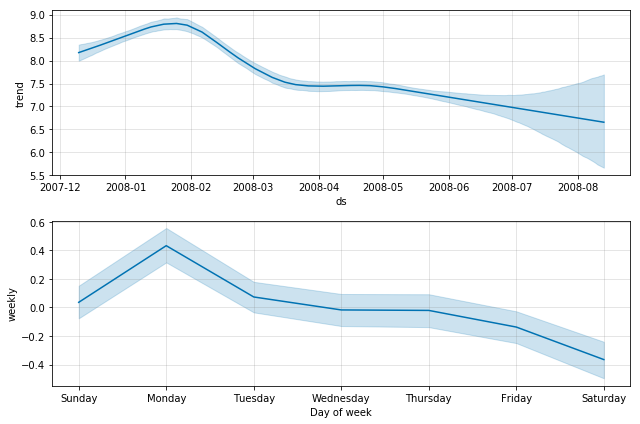
事後に予測した未加工のサンプルを見ることもできます。Pythonではm.predictive_samples(future)メソッド、Rではpredictive_samples(m, future)関数を用います。
話題に上っているようにWindowsでは、PyStanでのMCMCサンプリングは極めて遅いです。そのため、MCMCサンプリングをWindowsで行う場合のベストな選択はRを使うことです。Pythonを使いたい場合は、MacかLinuxの仮想マシンでサンプリングしてください。