Facebookが公開している時系列解析用のライブラリProphetの公式ドキュメントを翻訳していきます。
目次
1.Prophet公式ドキュメント翻訳(概要&特徴編)
2.Prophet公式ドキュメント翻訳(インストール編)
3.Prophet公式ドキュメント翻訳(クイックスタート編)
4.Prophet公式ドキュメント翻訳(飽和状態の予測編)
5.Prophet公式ドキュメント翻訳(トレンドの変化点編)
6.Prophet公式ドキュメント翻訳(周期性・イベント効果・説明変数の追加編)
7.Prophet公式ドキュメント翻訳(増加し続ける周期性編)
8.Prophet公式ドキュメント翻訳(誤差の間隔編)
9.Prophet公式ドキュメント翻訳(外れ値編)
10.Prophet公式ドキュメント翻訳(1日単位ではないデータ編)
11.Prophet公式ドキュメント翻訳(モデルの診断編)
12.Prophet公式ドキュメント翻訳(ヘルプ編)
2018/10/21公開。原文リンクは以下。
・Prophet概要&特徴:https://facebook.github.io/prophet/
・公式ドキュメント:https://facebook.github.io/prophet/docs/quick_start.html
今回の記事はトレンドの変化点です。
トレンドの変化点
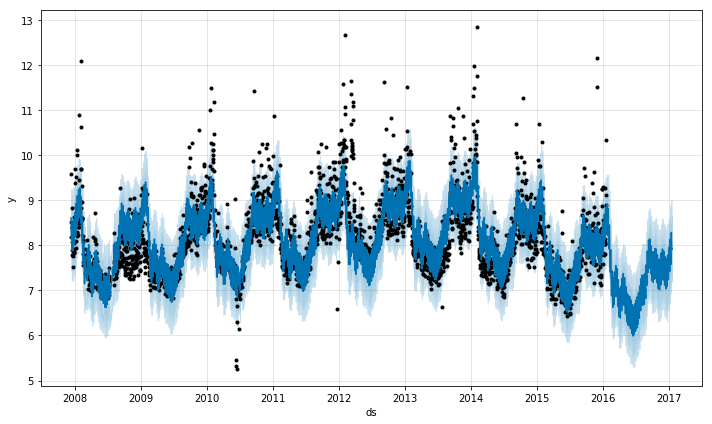
以前のドキュメントで挙げたデータにあるように、時系列データは軌道がしばしば急激に変化します。デフォルト設定では、Prophetは自動的にこれらの変化点を検知し、トレンドがデータに対して適切に対応するように調整することができます。ですが、ユーザが希望すればこのプロセスを精密にコントロールすることができます。例えば、Prophetが変化を取り損なっていたり、時系列データに対して過学習してしまっているときに、ユーザは調整が可能です。使用できるいろいろな引数があります。
Prophetにおける変化点の自動検知について
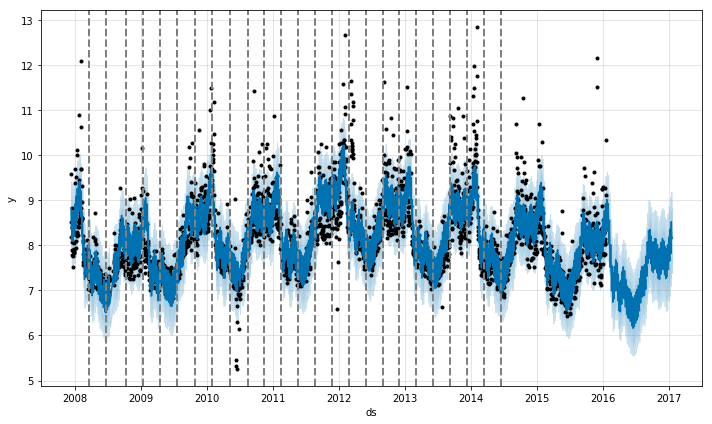
Prophetはまず、大量の潜在的変化点を可能な範囲で検知します。そして、変化率の大きなものを優先してスパースを置きます(L1正則化と同意です)。このことは、基本的にProphetは変化率を上下させることのできる多くのスペースをもっているということです。ですが、実際にProphetが変化点を反映させることができるのはわずかです。クイックスタートの章で説明したPeyton Manningの予測の例を使って考えてみましょう。デフォルト設定では、Prophetは25個の潜在的な変化点を検知します。それらの変化点は、時系列データの前から80%の部分に均等な感覚で置かれたものです。下の図の垂直な線は潜在的変化点が置かれた場所を示しています。
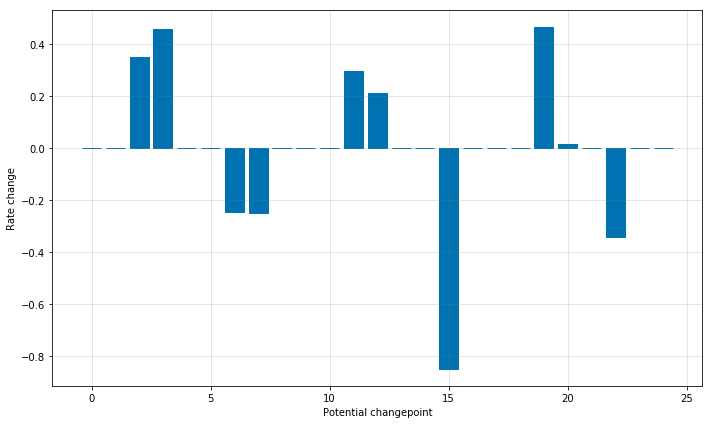
私たちは変化率を調整できる多くの場所があるにもかかわらず、それらの多くがスパースであるために大半が使われません。このことは、それぞれの変化点における変化率をプロットした以下の図で確認できます。
潜在的変化点の数はn_changepointsという引数を使うことで指定できます。ですが、これは正則化によってチューニングしたほうがよいです。重要な変化点の場所のプロットについては、以下で可視化できます。
# R
plot(m, forecast) + add_changepoints_to_plot(m)
# Python
from fbprophet.plot import add_changepoints_to_plot
fig = m.plot(forecast)
a = add_changepoints_to_plot(fig.gca(), m, forecast)
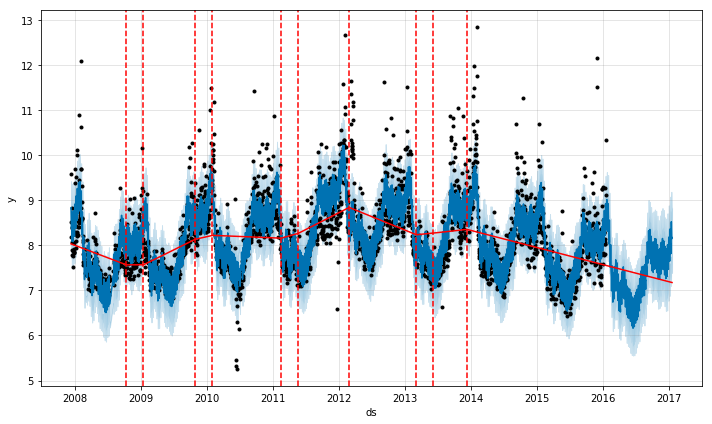
変化点を推測する際、デフォルト設定では時系列データの前から80%を参照しています。これは時系列データ全体を使うことによって過学習が発生することを防ぐためです。この80%というデフォルトの値は多くのケースでうまくいきますが、すべてのケースには当てはまりません。changepoint_rangeという引数を使うことでこの値を変更することができます。例えば、Pythonではm = Prophet(changepoint_range=0.9)、Rではm <- prophet(changepoint.range = 0.9)というコードで、時系列データの前から90%のデータを用いて、潜在的な変化点を推測することができます。
トレンドの柔軟性を調整する
トレンドの変化が過学習になっている(トレンドの柔軟性がありすぎる)場合や、学習しきれていない(柔軟性が足りていない)場合は、changepoint_prior_scaleという引数を使うことで、スパースの優先度の大きさを調整できます。デフォルトでは、このパラメータは0.05に設定されています。この値を増加させると、トレンドはさらに柔軟になります。
# R
m <- prophet(df, changepoint.prior.scale = 0.5)
forecast <- predict(m, future)
plot(m, forecast)
# Python
m = Prophet(changepoint_prior_scale=0.5)
forecast = m.fit(df).predict(future)
fig = m.plot(forecast)
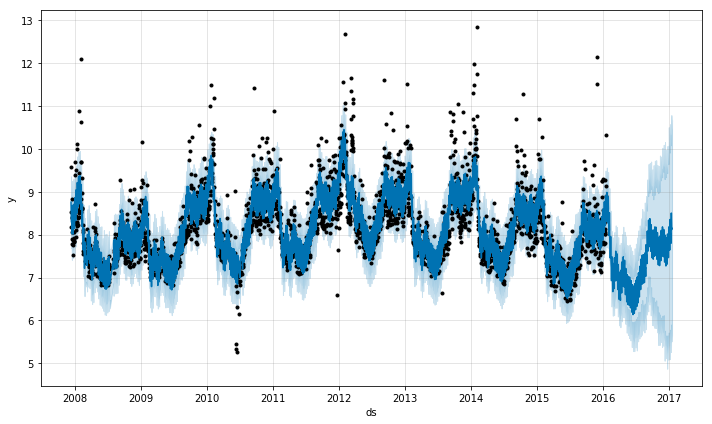
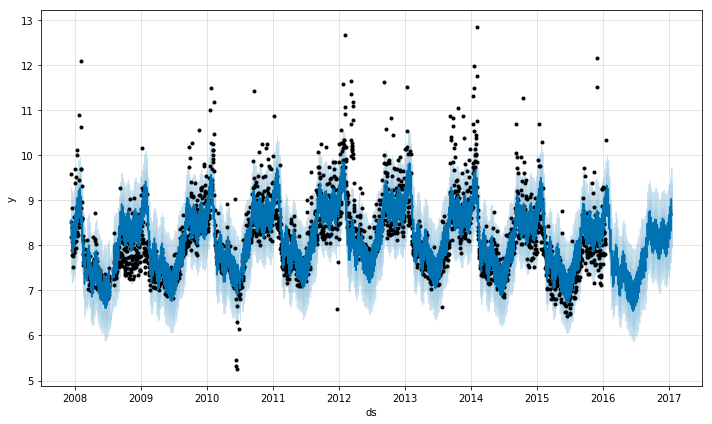
この値を減少させると、トレンドは柔軟性を弱めます。
# R
m <- prophet(df, changepoint.prior.scale = 0.001)
forecast <- predict(m, future)
plot(m, forecast)
# Python
m = Prophet(changepoint_prior_scale=0.001)
forecast = m.fit(df).predict(future)
fig = m.plot(forecast)
変化点の場所を特定する
ユーザが希望する場合は、変化点を自動検知するのではなく、changepointsという引数を用いて変化点の場所を手動で特定することができます。傾斜する変化は自動検知された変化点のみでしかとらえることができず、先ほど述べたスパース正則化がなされます。自動的に変化点のグリッドを作成した後、例えばユーザは変化点になると推測される特定の日を指定したグリッドを引数changepointsによって作成することができます。もう一つの例としては、変化点を小さいワンセットの日付に制限することができます。以下に示します。
# R
m <- prophet(df, changepoints = c('2014-01-01'))
forecast <- predict(m, future)
plot(m, forecast)
# Python
m = Prophet(changepoints=['2014-01-01'])
forecast = m.fit(df).predict(future)
fig = m.plot(forecast)