Facebookが公開している時系列解析用のライブラリProphetの公式ドキュメントを翻訳していきます。
目次
1.Prophet公式ドキュメント翻訳(概要&特徴編)
2.Prophet公式ドキュメント翻訳(インストール編)
3.Prophet公式ドキュメント翻訳(クイックスタート編)
4.Prophet公式ドキュメント翻訳(飽和状態の予測編)
5.Prophet公式ドキュメント翻訳(トレンドの変化点編)
6.Prophet公式ドキュメント翻訳(周期性・イベント効果・説明変数の追加編)
7.Prophet公式ドキュメント翻訳(増加し続ける周期性編)
8.Prophet公式ドキュメント翻訳(誤差の間隔編)
9.Prophet公式ドキュメント翻訳(外れ値編)
10.Prophet公式ドキュメント翻訳(1日単位ではないデータ編)
11.Prophet公式ドキュメント翻訳(モデルの診断編)
12.Prophet公式ドキュメント翻訳(ヘルプ編)
2018/10/27公開。原文リンクは以下。
・Prophet概要&特徴:https://facebook.github.io/prophet/
・公式ドキュメント:https://facebook.github.io/prophet/docs/quick_start.html
今回の記事は外れ値編です。
外れ値
Prophetのモデルで外れ値を扱う場合、大きく分けて2通りのアプローチがあります。ここではRのページ(Wikipedia)の訪問者数についてのログデータを用いて、予測を行います。ただ、このデータにはいくつかの外れ値が含まれています。
# R
df <- read.csv('../examples/example_wp_log_R_outliers1.csv')
m <- prophet(df)
future <- make_future_dataframe(m, periods = 1096)
forecast <- predict(m, future)
plot(m, forecast)
# Python
df = pd.read_csv('../examples/example_wp_log_R_outliers1.csv')
m = Prophet()
m.fit(df)
future = m.make_future_dataframe(periods=1096)
forecast = m.predict(future)
fig = m.plot(forecast)
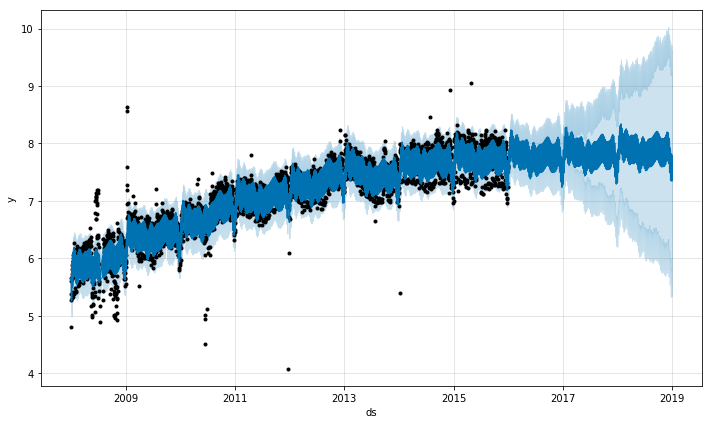
この予測のトレンドは一見、納得がいくように思えます。しかし、誤差の間隔が大きすぎるという問題があります。Prophetは時系列データの外れ値を一応は扱うことができます。ただ、それらをフィッティングしてトレンドの変化を予測するということしかできません。このようにして作成された信ぴょう性に欠けるモデルは、外れ値の影響を受けたまま、未来のトレンドを予測します。
外れ値を扱う最も良い方法は、それらを取り除いてしまうことです。Prophetは時系列データの一部に抜けがあってもモデルを作成します。外れ値をNAに置き換えてしまえば、Prophetは外れ値の影響を受けないモデルを作成し、予測します。
# R
outliers <- (as.Date(df$ds) > as.Date('2010-01-01')
& as.Date(df$ds) < as.Date('2011-01-01'))
df$y[outliers] = NA
m <- prophet(df)
forecast <- predict(m, future)
plot(m, forecast)
# Python
df.loc[(df['ds'] > '2010-01-01') & (df['ds'] < '2011-01-01'), 'y'] = None
model = Prophet().fit(df)
fig = model.plot(model.predict(future))
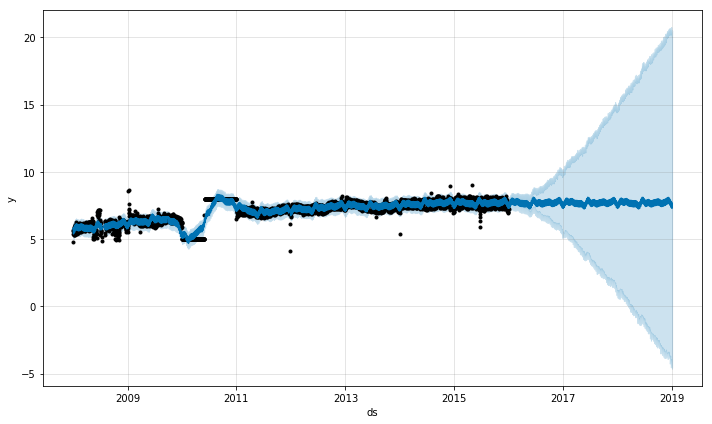
上記の例では、外れ値がかなり散らばっていてモデルに悪影響を与えそうですが、それらを除去したおかげで予測結果に影響はあまりないことが見て取れます。このように、いつも外れ値の影響を回避できるというわけではありません。次の外れ値をさらに増やした例を見てみましょう。
# R
df <- read.csv('../examples/example_wp_log_R_outliers2.csv')
m <- prophet(df)
future <- make_future_dataframe(m, periods = 1096)
forecast <- predict(m, future)
plot(m, forecast)
# Python
df = pd.read_csv('../examples/example_wp_log_R_outliers2.csv')
m = Prophet()
m.fit(df)
future = m.make_future_dataframe(periods=1096)
forecast = m.predict(future)
fig = m.plot(forecast)
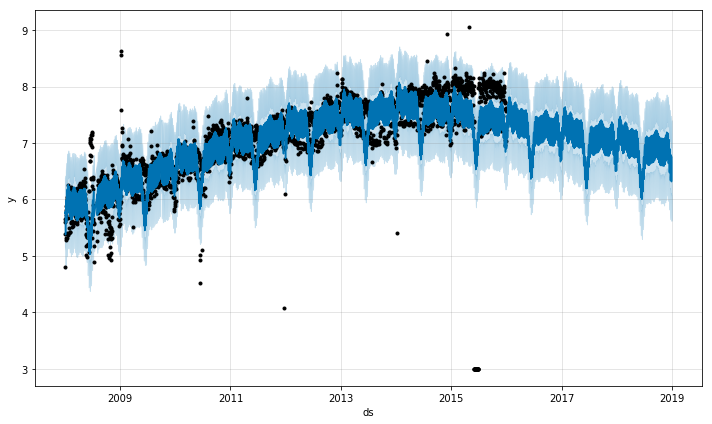
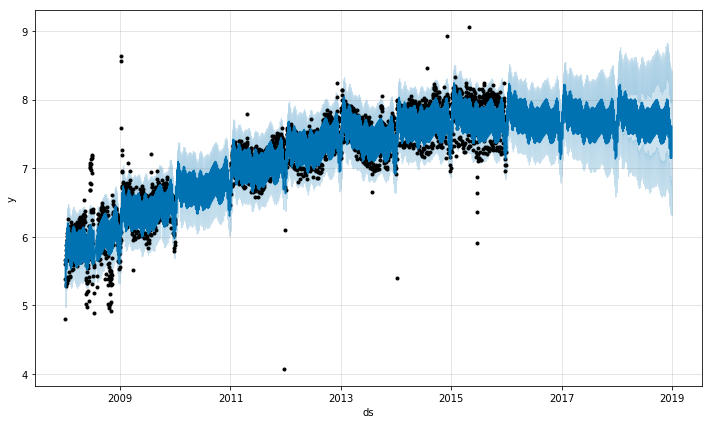
上記の例では、2015年の6月に極めて多くの外れ値が散らばっており、予測に悪影響を及ぼしています。これらを取り除く正しいアプローチをもう一度示しておきます。
# R
outliers <- (as.Date(df$ds) > as.Date('2015-06-01')
& as.Date(df$ds) < as.Date('2015-06-30'))
df$y[outliers] = NA
m <- prophet(df)
forecast <- predict(m, future)
plot(m, forecast)
# Python
df.loc[(df['ds'] > '2015-06-01') & (df['ds'] < '2015-06-30'), 'y'] = None
m = Prophet().fit(df)
fig = m.plot(m.predict(future))