最近、友人がTensorflowからPyTorchに流れてしまい危機感を覚えました。ここはTensorflowならstate of the artを簡単に出せることを示し、目を覚まさせる必要があります。
前回の記事では、Eager Modeを使うことで、簡単に強化学習を実装できることを示しました。今回はGraph Modeを使うことで、代表的ベンチマークであるMujocoのAnt-v2でstate of the artをまあまあの難易度で実装できることを示します。
今回実装した軽量Ape-X実装teflonでは、500行程度読めば全体の流れがわかるように記述しつつ、従来手法ではAnt-v2で6900点ぐらいのところを(REMEMBER AND FORGET FOR EXPERIENCE REPLAY, ICLR2019のUnder Review)、8500点をマークすることができます(CPU4コアGPU1枚)。
Ant-v2はこの図のような4足歩行の生物を制御し、移動距離を競うものです。画像の引用元で動いているAntを見られます。状態の次元数111, 行動の次元数8と、MuJoCoベンチマークの中では大きいほうのタスクです。

このタスクに対し、次のような実装手順でstate of the artを出します。
- Soft Actor Criticを実装する (Eager Mode)
- Ape-Xを実装する (Graph Mode)
- 組み合わせて微調整する
なお、Ape-Xの解説は【深層強化学習】Ape-X 実装・解説を読んでください。ただし今回は
- Prioritized Experience Replay
- multi-step bootstrap target
- 分散学習 (マルチスレッド)
の3点しか利用していません。また、上記解説は行動が離散のケースで書かれていますが、今回は行動が連続なので細かいところは少し違います。
Soft Actor Criticは、残念ながら日本語の良い解説がないです。この記事はスコアというよりもApe-X周りの実装テクニックの紹介が主眼なのでとりあえず論文を貼っておきます。(あとで少しだけ解説します)
強化学習実装の問題点と解決
前回の記事でも書きましたが、ほとんどのTensorflowの強化学習実装はめちゃくちゃ読みづらいです。私は画像認識エンジニアなのですが、画像認識と異なり、
- 環境, Replay Bufferの2つがPythonで記述されており、それとTensorflow計算グラフとの通信にfeed_dict, placeholderが大量発生する
- システム内にNetworkが大量に出てきて変数管理が大変 (TD3なら6つ)
という特徴があります。前回の記事ではEager Modeを使い、すべてをPythonに持ってくることでTensorflow計算グラフとの通信を簡略化することができました。(後者はtf.keras.layersで解決)
ですが、今回は逆向きのアプローチを行います。つまり、環境とReplay BufferをTensorflow計算グラフに持っていきます。そうすることで、すべての構成部品がTensorでやり取りを行えるようになり、feed_dictを完全に排除できます。
Soft Actor Critic
まず、基盤となるSoft Actor Criticを実装してしまいましょう。理論に興味がない人は読み飛ばしてください。
Soft Actor Critic(以下SAC)は、以下の目的関数を最大にするようにpolicyを更新するActor-Criticな手法です。
J(\pi) = \sum^T_{t=0} \mathbb{E}_{(s_t, a_t) \sim \rho_\pi } [ r(s_t, a_t) + \alpha \mathcal{H}(\pi(\bullet | s_t)) ]
第1項はいつもの累積割引報酬です。第2項の$\mathcal{H}(\pi(\bullet | s_t))$ は状態$s_t$における行動が従う分布のエントロピーです。これからもわかるようにSACのpolicyはdeterministicな行動ではなく、行動の分布を出力します。そして、累積報酬が高いだけでなく、幅広いActionを取るようなpolicyを選好します。
このことが、さまざまなActionをとることにつながり、結果より良いpolicyを見つけることになる、というのがSACの主張です。ICML 2018で発表されたバージョンではTD3と組み合わせて性能を上げてあります。TD3も意外なことに日本語解説がありませんが、actionの値が連続値なときのDouble Q Learningだと思ってください。(ちなみにTD3のAnt-v2のスコアは4185です)
目的関数から導かれる価値関数やpolicyの更新式はここでは割愛します。
まず、これをEager Modeで実装し、論文通り6000点ぐらい出ることを確認しました。
実装の詳細はteflonレポジトリに含まれるSAC_eager.pyを読んでください。
Ape-Xの実装
Ape-Xの処理の流れは下図のようになります。Ape-Xの元論文ではExplorerではなくActorと呼ばれていますが、Actor-Criticと紛らわしいのでここではExplorerと呼びます。
- ExplorerがノイズありActionを実行し環境からtransition $(s_t, a_t, r_{t+1}, s_{t+1})$ を集める
- ExplorerがtransitionをReplay Bufferに積む
- LearnerがReplay BufferからtransitionをPriorityに従って取り出す
- Learnerがtransitionを使ってpolicyを更新する
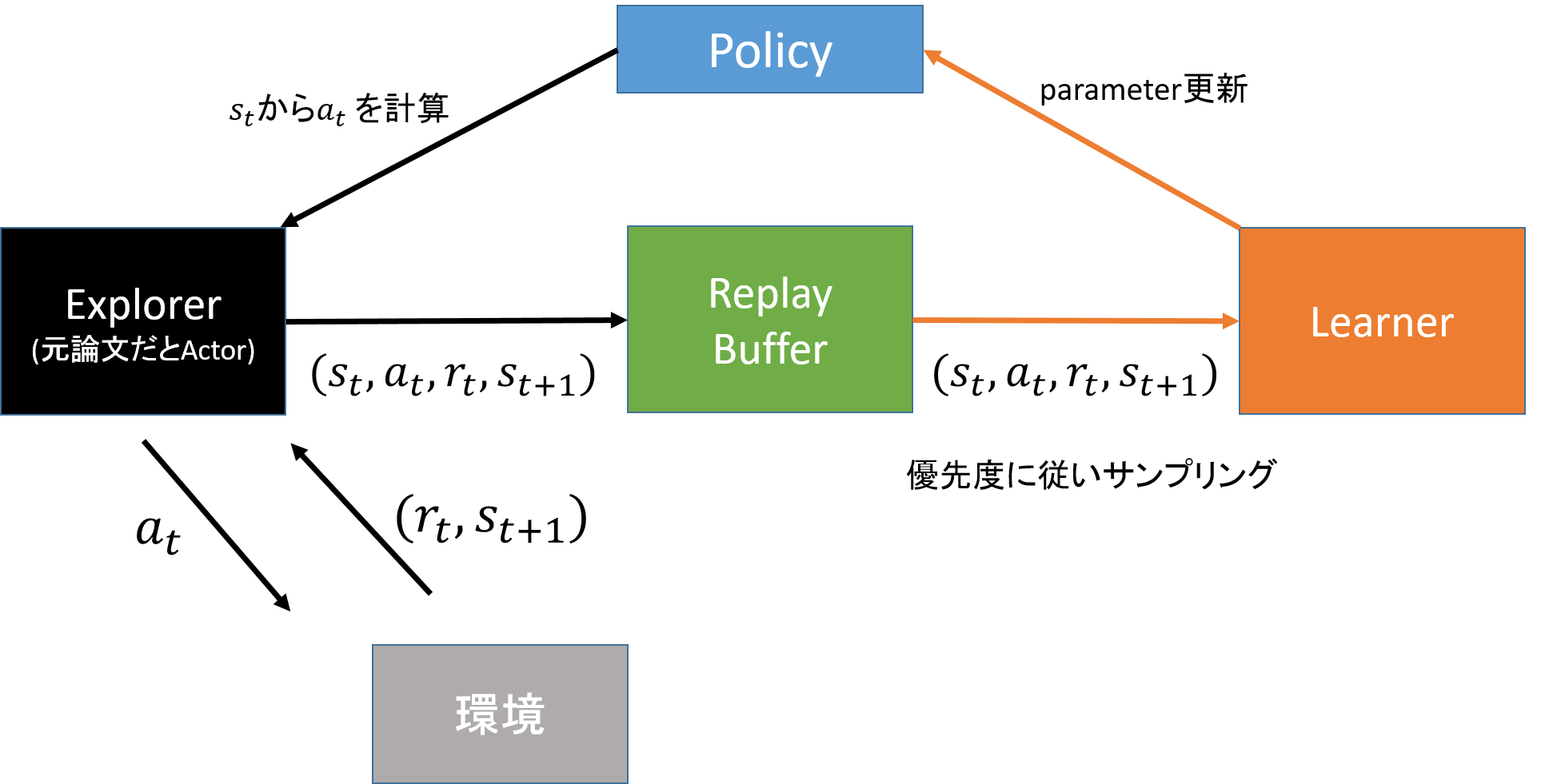
ReplayBufferをはさんで左側の黒い矢印部分と、右側のオレンジ色の矢印部分は非同期で動作します。
1のノイズありActionと4のpolicy更新のアルゴリズムを切り替えることで、Ape-X+DDPGとかApe-X+SACとかのバリエーションを試すことができます。
ここの環境とReplay BufferをTensorflow計算グラフワールドに持ってこれれば、他の実装は大したことありません。(ただしmulti-step bootstrapを除く)
環境をTensorflow計算グラフに持ってくる
環境の要件
環境はactionを受け取り、rewardと新しいstateと終了したかどうかのdoneを返すstep関数を持ちます。
policyを使ってtransitionを収集し、replay_bufferに追加するコードの擬似コードは以下のようになります。
while True:
action = policy.noise_action(state)
reward, next_state, done = env.step(action)
replay_buffer.append((state, action, reward, next_state, done))
state = next_state
if done:
state = env.reset()
envがPythonで、policyがTensorflowであれば、上のようにシンプルにはかけず、
action = sess.run(policy.noise_action, feed_dict={state_place:state})
のような記述が必要になります。これはsess.runのオーバーヘッドがかかる上に、placeholderの宣言部とplaceholderの処理部は分離して書かれがちなため保守性が低下します。
そこで、env.stepをTensorflowのOperatorにしてしまい、引数にTensorを取り、返り値もTensorを返すようにします。
愚直に実装するとTensorflow上でenv.step Operatorの呼び出し回数がかなりのものになってしまい、これはこれでオーバーヘッドになってしまいます。そこで、envを単一の環境ではなく64個程度の環境の塊とみなし、長さ64のベクトルのactionを渡すことで、64環境が同時に1step進むようなOperatorを作ります。その際に返ってくるのはそれぞれベクトル化されたreward, next_state, doneです。
今回の環境
今回は環境としてMuJoCoとそのwrapperのmujoco-pyとOpenAI gymを使います。関係としてはMuJoCoがバイナリ、mujoco-pyがそのPythonインターフェイス、OpenAI gymがPythonインターフェイス上でタスク(今回はAnt-v2)を定義しています。
環境のマルチスレッド実行
64個の環境を1コアから実行するのも馬鹿らしい話です。マルチコアを使ってより多くのtransitionを集めたいところです。
マルチコアでの環境実行は先行実装として
- OpenAI baselineのマルチプロセスからの環境実行
- Uber Ape-XのC++でのマルチスレッドからのALE実行
があります。前者はPythonのGlobal Interpreter Lock(GIL)を回避するために、環境ごとにプロセスを立ち上げ、各環境が集めたtransitionをプロセス間通信で収集します。後者はenv.stepを呼び出すと内部のC++実装が複数スレッドを立ち上げ、複数環境を操作することでGILを回避しつつマルチコアを利用します。
前者はプロセス間通信のオーバーヘッドが大きく、また実装も複雑という問題があります。後者は素晴らしい実装なのですが、MuJoCoの「物理モデルはC++で記述され、タスクのルールはPythonで記述される」という性質上、Ant-v2やHalfCheetah-v2といったタスクごとに移植実装が必要になってしまうため、実装コストが高いです。
今回は、MuJoCoがThread-Safeである性質を利用してPythonのマルチスレッドから複数のMuJoCo環境を操作します。なお、MuJoCoがThread-Safeである旨はこのページのMulti-threadingにあります。
mujoco-pyはCythonで記述されており、
def step(self):
for _ in range(self.nsubsteps):
mj_step(self.model.ptr, self.data.ptr)
こんな感じでC++のmj_stepをPythonから呼び出すインターフェイスを提供しています。このままではmj_step中もGILを解放しないため、
def step(self):
with nogil:
for _ in range(self.nsubsteps):
mj_step(self.model.ptr, self.data.ptr)
でmj_step中はGILを解放するようにしてやります。これでPythonのマルチスレッドから複数のMuJoCo環境を操作する際に、あるスレッドがmj_stepの処理中であれば他のスレッドが実行可能になります。
なぜデフォルトでこうなっていないかというと、「ある環境がstepを実行している最中に、他のスレッドからresetを実行するとクラッシュする」といった事例が発生するようになってしまうためです。同じ環境を同時に操作しないように、mujoco-pyの利用者側が気をつけて制御する必要が出てきます。
このGILを解放したenvを使えば以下のように、簡単に複数環境をマルチスレッドから操作する関数を記述できます。
self.envsは64個の環境のlistです。
def py_step(self, action):
def _process(offset):
for idx_env in range(offset, offset+self.batch_thread):
new_obs, reward, done, _ = self.envs[idx_env].step(action[idx_env, :].astype(np.float64))
new_obs = new_obs.astype(np.float32)
reward = reward.astype(np.float32)
self.list_obs[idx_env] = new_obs
self.list_rewards[idx_env] = reward
self.list_done[idx_env] = done
self.list_steps[idx_env] += 1
threads = []
for i in range(self.thread_pool):
thread = threading.Thread(target=_process, args=[i*self.batch_thread])
thread.start()
threads.append(thread)
for t in threads:
t.join()
obs = np.stack(self.list_obs, axis=0)
reward = np.stack(self.list_rewards, axis=0)
done = np.stack(self.list_done, axis=0)
return obs, reward, done
Tensorflowインターフェイス部をあわせても100行ちょっとで実装できるにもかかわらず、コアが少ない環境であればOpenAIの実装よりも高速に動作します。
Tensorflow Operatorにする
上記実装をTensorflow Operatorにするのは簡単で、py_funcを使います。
def step(self, action, name=None):
with tf.variable_scope(name, default_name="MultiStep"):
obs, reward, done, reach_limit = tf.py_func(self.py_step, [action], [tf.float32, tf.float32, tf.bool, tf.bool])
obs.set_shape((self.batch_size,) + self.observation_shape)
reward.set_shape((self.batch_size,))
done.set_shape((self.batch_size,))
reach_limit.set_shape((self.batch_size,))
return obs, reward, done, reach_limit
これで、マルチコアを活かせて計算グラフに組み込める環境が手に入りました!
環境パフォーマンス比較
せっかく、作ったので各種実装のパフォーマンスを比較しましょう。それぞれの環境実装において、Ant-v2の環境を秒間何step実行できるかを比較します。
実行マシンは、Intel(R) Core(TM) i5-4440 CPUで4コア4スレッドです。
| 環境名 | steps/sec |
|---|---|
| シングルスレッド | 1882.9 |
| OpenAI実装 | 3247.0 |
| 今回の実装 | 1423.3 |
| 今回の実装(nogil mujoco-py) | 5368.8 |
| Tensorflowから今回の実装を呼び出した | 4872.8 |
上4つは、Tensorflowは関係ないPython上での速度比較です。最後は、Tensorflowから今回の実装を呼び出した場合のパフォーマンスになります。OpenAI baselinesの実装よりも今回実装の方が高速に動作することや、nogilをつけないとまったくパフォーマンスが出ないことがわかります。
Replay BufferをTensorflow計算グラフにもってくる
こちらは相当ハイレベルなTensorflowエンジニアがいるUberのApe-X実装に含まれるReplayBufferを、デバッグと少し改変したものを用いています。
完全にC++で記述されているため、読むのは難しいですが使うのは簡単です。以下でやりとりされているデータはすべてTensorで、計算グラフが構築されています。
replay_buffer = ReplayBuffer(replay_buffer_size,
shapes=buffer_shapes,
dtypes=buffer_dtypes)
transition = state, action, reward, next_state, discount_rate
# データを追加するOperatorを作成
enqueue_op = replay_buffer.enqueue_many(transition, priority)
# データを取り出す処理
idx, weights, components = replay_buffer.sample_proportional_from_buffer(batch_size)
state, action, reward, next_state, discount_rate = components
あとは、Explorer側のtransitionをreplay_bufferにenqueueする処理とLearner側のtransitionをsampleする処理を非同期で動作させれば、大体Ape-Xになります。
非同期で動作させるには、Learner側の処理をメインスレッドのsess.runでやる傍ら、Explorer用のスレッドを立ててそちらからenqueue_opを呼び出す必要があります。スレッドは自分で立ててもいいのですが、以下のようにQueueRunnerに管理してもらうと、簡潔に記述できます。QueueRunnerは第一引数のQueueと第二引数のOperatorをまとめて管理し、第二引数で渡されたOperator用のThreadを立てたり落としたりしてくれます。ReplayBufferはUberの実装そのままではQueueの要件を満たさないので、closeやnameといった関数を足してやることでTensorflowからQueueに見えるようにします。
enqueue_op = replay_buffer.enqueue_many(transition, priority)
# Enqueing threads are bound to replay_buffer.
qr = tf.train.QueueRunner(replay_buffer, [enqueue_op])
tf.train.add_queue_runner(qr)
今回は1回のenqueue_opから呼ばれるenv.step内で複数のスレッドが動作するようになっているため、ここで作成するスレッドは一つだけです。
これで非同期に動作するExplorerとLearnerが手に入りました!
全部合体させる
これで
- Soft Actor CriticによるPolicy定義
- 計算グラフに組み込める環境
- 計算グラフに組み込めるReplayBuffer
というすべての材料が揃ったので合体させます。グラフ構築とその実行部を抜粋したのが以下のコードです。
env_maker = lambda: gym.make(args.env)
# Ant-v2環境をマルチスレッドインターフェイスに渡す
env = MultiThreadEnv(env_maker, batch_size=explorer_size, thread_pool=num_envs)
# policyを作成
policy = SAC(env.state_dim, env.action_dim, env.max_action, lr=lr)
# transitionを収集するexplorer用の計算グラフを構築(別関数)
transition = explorer(env, policy, initial_random=(not is_finetune))
replay_buffer = ReplayBuffer(replay_buffer_size)
# Priorityの計算
state, action, reward, next_state, done, reach_limit = transition
td_error = policy.explorer_td_error(state, action, reward, next_state, discount_rate)
priority = tf.abs(td_error)
enqueue_op = replay_buffer.enqueue_many(transition, priority)
# Enqueing threads are bound to replay_buffer.
qr = tf.train.QueueRunner(replay_buffer, [enqueue_op])
tf.train.add_queue_runner(qr)
# Learnerを定義する(別関数)。内部でreplay_bufferからtransitionをsampleしている
train_op, policy_loss, vf_loss, qf_loss = learner(learner_steps, policy, replay_buffer, learner_size)
hooks = [tf.train.StopAtStepHook(last_step=args.max_timesteps)]
checkpoint = tf.train.Checkpoint(policy=policy)
checkpoint_manager = tf.contrib.checkpoint.CheckpointManager(checkpoint)
policy_init_op = policy.init_op()
# MonitoredTrainingSessionを使っているのでQueueRunner管理下のスレッドを勝手に立ててくれる
with tf.train.MonitoredTrainingSession(hooks=hooks) as sess:
logger.info('Training started')
while not sess.should_stop():
# メインスレッド側でLearnerの処理をまわす (Explorerの処理は別スレッドで走っている)
cur_step, _, cur_policy_loss, cur_vf_loss, cur_qf_loss = sess.run(
[learner_steps, train_op, policy_loss, vf_loss, qf_loss])
if cur_step % save_interval == 0:
with sess._tf_sess().as_default():
checkpoint_manager.save(checkpoint_number=cur_step)
シンプルなコードなので特に解説なく読めると思います。これでfeed_dictなく単一グラフに格納されたApe-X実装が手に入りました!
計測と微調整
ではさっそくAnt-v2を実行し調整していきましょう。
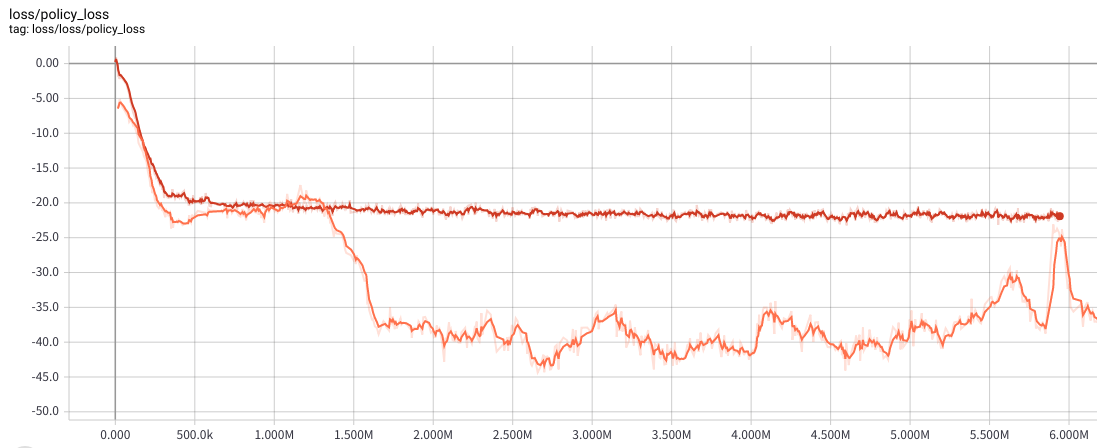
以下はActorのlossのsummaryです。オレンジはmulti-stepなし、赤は4step先まで使ったmulti-step bootstrappingの場合です。
multi-stepによってActor lossが安定しました。(Criticの値が安定したおかげかな?)
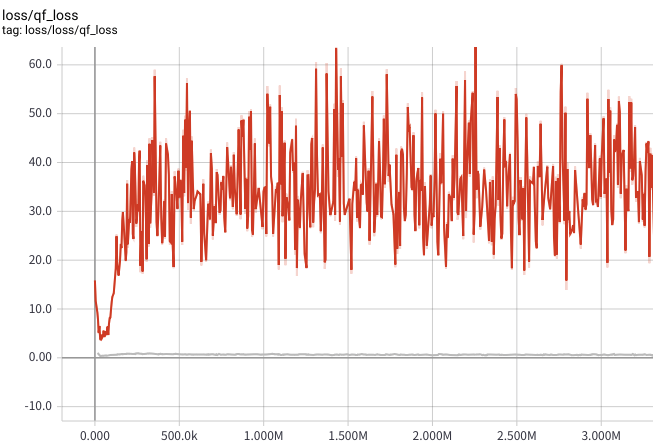
Critic LossもTensorboardで確認したところあからさまに外れ値っぽいものがあったので、Huber Lossを導入しました。赤がHuber Loss導入前、灰色がHuber Loss導入後です。Critic Lossが安定しました。
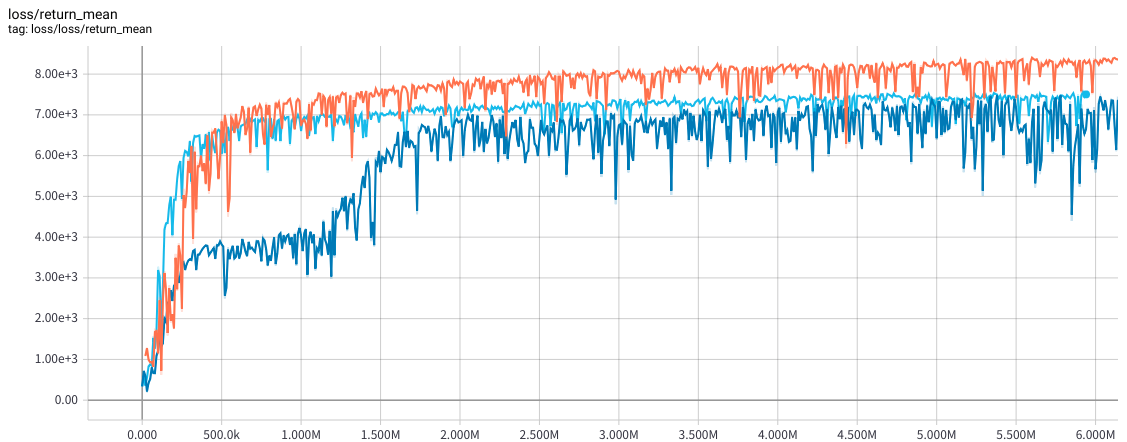
では、multi-stepとHuber Lossを導入した上で10回平均のスコアを見てみましょう。紺色が両方適用していないもの、水色がmulti-stepのみ適用、オレンジがmutli-step + Huber Loss導入のものです。これをもうちょっとほっとけば8500ぐらいまで行きます。state-of-the-art!
まとめ
以上のようにTensorflowを使うことで容易にstate-of-the-artが出せることが示せました。これを読んだ友人がPyTorchを捨てTensorflowに戻ってきてくれることを願うばかりです。
今回の実装はUberのブログとUberのApe-X実装を大いに参考にしています。Tensorflow上での高速実装に興味がある方はぜひご確認ください。特にUberのApe-X実装は、あまり使われないStagingArea等の技法が使われており面白いです。
今回はマルチスレッドによる環境実行を行いましたが、報酬計算や終了条件判定はPythonで記述されているため、その間はGILが解放できていません。よってコア数が多いマシンではこの方式では性能の向上が頭打ちになります。UberのApe-X実装の中にAtariでのC++マルチスレッド実装があるので、これをちょっといじればMujocoのC++マルチスレッド実装が作れます。真に性能を求める場合はそちらの利用をお勧めします。(issueに上げようと思っているのですが、メモリ解放部にバグがあるので気を付けてください)
ここからはTensorflowが好きな人向けの実装の詳細になります。
非同期処理におけるパラメーターの共有
今回のExplorerの実装では、Learnerとpolicyのparameterを共有しているため、Learnerで起こったparameter更新が即座に反映されます。
しかし、ExplorerとLearnerは非同期で動作しているため、運が悪いとLearnerがparameterを更新している途中でExplorerがparameterにアクセスしてしまい、一貫性のないparameterをもとにExplorerがActionを決定してしまいます。
「どうせノイズののったActionを使ってtransitionを集めているから、それぐらいいいじゃないか」という立場もありなのですが、性能が悪いときにそこを疑うのも面倒なので、対策を行いました。
これにはtf.contrib.framework.CriticalSectionを使います。これを使うことで指定した複数の計算グラフが並列に実行されないようにできます。これでparameterの更新とExplorerのAction決定が同時に起きないように制御しました。CriticalSectionの詳細な議論はこちらのページに書いてあります。
MonitoredTrainingSessionからのCheckpointの利用
現在、Eagerモードとの相互運用を行っているため、tf.train.Checkpointを用いてモデルのsave&loadを行っています。
tf.contrib.checkpoint.CheckpointManagerは、Checkpointを便利に利用できる優れたインターフェイスですが、MonitoredTrainingSessionと食い合わせが悪いです。
MonitoredTrainingSessionは処理の開始時に計算グラフをfinalizeし、それ以降のグラフの変更を認めません。これがさまざまなインターフェイスと食い合わせが悪くイライラすることが多いです。特にEagerとの共有インターフェイスであるCheckpointManagerは「グラフの定義」と「処理の実行」が分離されておらず、グラフを定義するためには一度実行する必要があります。
そこで今回はださいのですがダミーSessionを一度立てて無理やり計算グラフを構築し、そのあとMonitoredTrainingSessionを初期化しています。
checkpoint_manager = tf.contrib.checkpoint.CheckpointManager(checkpoint)
# 計算グラフ構築のためだけのダミーSession
with tf.Session(config=config) as sess:
sess.run(tf.global_variables_initializer())
# checkpoint_managerはデフォルトセッションを参照する
checkpoint_manager.save()
もっとスマートなやり方を知っている方はぜひ教えてください。