Introduction
強化学習におけるTensorflowの実装たるや、その多くは可読性が低いです。それに比べて、PyTorchやchainerといったDefine-by-Run型のフレームワークの実装は読みやすく作りやすい。しかし、その時代もEager Modeの出現により終わりました。
本稿では、Eager Modeの実践的な記述方法と、強化学習における有用性を示すことを目指します。
主な内容として
- PyTorchからTensorflow Eagerへの1対1の移植方法
- Eager Modeにおけるsummary
- Eager Modeにおける学習結果のsave&load
- PyTorchよりEagerを高速に動作させる
を含みます。
今回、題材として用いるのは、ICML2018に採択されたFujimotoらの「Addressing Function Approximation Error in Actor-Critic Methods」の作者実装です。その中で実装されたDDPGをTensorflow Eagerに移植し、比較します。
さらに別記事にて、Eager Modeでの実装をベースとして、Graph Modeに移行し、MujocoのAnt-v2ベンチマークにおける(たぶん)state of the artを達成する例を示します。
なお、Eagerモードの基本的なトピックは詳しくは扱わないため、Tensorflowの日本語記事でお世話になるHELLO CYBERNETICSさんの記事とか、公式とか見てください。
強化学習は知らなくてもあまり困らないように記述してあります。また、本記事のソースコードはgithubに配置しています。
強化学習実装の困難性
Tensorflowでの強化学習実装の可読性が低いのは主に2つ原因があります。一つは複雑なparameter sharingにおけるvariable_scopeの管理。もう一つは強化学習のシステムに存在するPython部分との通信です。
強化学習ではシステムの中に、複数のNeural Networkを含みます。例えばTD3であれば6つのNetworkがやり取りをするシステムになっています。Tensorflowの古い記述方法ではtf.trainable_variablesというグローバル空間の中から、各々のNetworkに関連する変数だけを取り出す処理を記述する必要があります。
一方で、tf.keras.layersを使うことで、各Networkに紐づく変数がきちんと管理されるようになるため、variable_scopeによるパラメーターの使い回しなどが不要になりました。
また、DDPG系の強化学習は、Pythonで記述されがちな環境とReplay Bufferを含んでいます。この環境やReplay Bufferとやり取りするために、典型的な強化学習プログラムではTensorflow部分とPython部分の間はplaceholderとfeed_dictを使って通信を行っています。このplaceholderの定義などが著しくTensorflow強化学習の可読性を下げています。
ですが、Eager Modeを用いることで、すべてのTensorflow部分がPython上で動作するようになるため、非常に簡潔な形で処理を記述できます。
PyTorchからTensorflowへの移植
学習プログラムの大まかな流れは
- 環境上でAgentを動作させtransitionを収集する
- transitionをReplay Bufferに格納する
- Replay Bufferからtransitionをサンプリングし、そのデータでNeural Networkを学習させる
です。Tensorflow Eagerを使うことで、1と2はPyTorchのプログラムをそのまま流用できます。
よって、Neural Networkの定義とパラメーター更新さえ移植してしまえば、世にあふれるPyTorchやchainerのソースコードをTensorflowで利用することが可能になるのです!
Neural Networkの移植
PyTorchのNetwork定義から見てみましょう。
class Actor(nn.Module):
def __init__(self, state_dim, action_dim, max_action):
super(Actor, self).__init__()
self.l1 = nn.Linear(state_dim, 400)
self.l2 = nn.Linear(400, 300)
self.l3 = nn.Linear(300, action_dim)
self.max_action = max_action
def forward(self, x):
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = self.max_action * torch.tanh(self.l3(x))
return x
シンプルで素晴らしいですね。一方で、tf.keras.layersを用いたNetwork定義は、
class Actor(tf.keras.Model):
def __init__(self, state_dim, action_dim, max_action, name="Actor"):
super().__init__(name=name)
self.l1 = layers.Dense(400)
self.l2 = layers.Dense(300)
self.l3 = layers.Dense(action_dim)
self.max_action = max_action
def call(self, inputs):
with tf.device("/gpu:0"):
features = tf.nn.relu(self.l1(inputs))
features = tf.nn.relu(self.l2(features))
features = self.l3(features)
action = self.max_action * tf.nn.tanh(features)
return action
となります。ほぼ同一ですね。keras.layersのModelは次のように使います。
actor = Actor(state_dim, action_dim, max_action)
action1 = actor(states1)
action2 = actor(states2) # parameter sharingができている
Modelの__call__は内部でcall関数を呼び出すようになっています。initで定義したDenseレイヤーを再利用しているため、variable_scope(reuse=True)のようなことをしなくてもparameterの再利用が行えます。
その上、Actorに紐づく変数を
actor.weights
でlistとして取り出すことが可能です。これを用いることで、2つのNetworkの変数の値を揃える処理も簡単に記述できます。
for param, target_param in zip(actor.weights, actor_target.weights):
target_param.assign(param)
Tensorflowマスターの皆さんなら、各Layerの入力次元が__init__時点では確定しないことに気づいたかと思います。入力次元は1回目のcall時点で確定するため、parameterのshapeは1回目のcall呼び出しまで不明です。
よってactor.weightsをcall呼び出し前に参照しても空のリストが返ってきます。そのために、慣習として私はinitの末尾でcallを明示的に呼び出すようにしています。
class Actor(tf.keras.Model):
def __init__(self, state_dim, action_dim, max_action, name="Actor"):
...
# 後段の処理のために早めにshapeを確定させる
dummy_state = tf.constant(np.zeros(shape=[1, state_dim], dtype=np.float32))
self(dummy_state)
なお、build(input_shape)という関数を定義することで、実処理を行うことなくparameterを作成することも可能なのですが、callと似た処理をもう1回書くのがだるいため、callで代用しています。
weightsにparameterを追加するために、tf.keras.Modelでは__setattr__をoverwriteしており、属性代入時にその代入されたオブジェクトがCheckpointableBase等のサブクラスだった場合に、自動でそのオブジェクトのparameterが追加されるようになっています。
もう少し複雑なNetworkとして、regularizerをつけたり、入力を複数取る場合は以下のようになります。
class Critic(tf.keras.Model):
def __init__(self, state_dim, action_dim, wd=1e-2, name="Critic"):
super().__init__(name=name)
self.l1 = layers.Dense(400, kernel_regularizer=regularizers.l2(wd), name="L1")
self.l2 = layers.Dense(300, kernel_regularizer=regularizers.l2(wd), name="L2")
self.l3 = layers.Dense(1, kernel_regularizer=regularizers.l2(wd), name="L3")
dummy_state = tf.constant(np.zeros(shape=[1, state_dim], dtype=np.float32))
dummy_action = tf.constant(np.zeros(shape=[1, action_dim], dtype=np.float32))
self([dummy_state, dummy_action])
def call(self, inputs):
with tf.device("/gpu:0"):
x, u = inputs
x = tf.nn.relu(self.l1(x))
inner_feat = tf.concat([x, u], axis=1)
x = tf.nn.relu(self.l2(inner_feat))
x = self.l3(x)
return x
入力を複数とる場合はlistを引数に渡していることがわかります。PyTorchの場合はOptimizerの引数としてL2 lossの係数が設定されるため、Tensorflowの方がLayerごとに異なるL2 lossを設定しやすいです。(PyTorchでも他の書き方があるかもしれませんが)
パラメーター更新ロジックの移植
次はparameterの更新ロジックを移植します。まず、PyTorchの例から見ていきましょう。なお、簡単のためcriticに関する更新式だけ抜粋しています。
処理の流れは
- 目的変数となるtarget_Qを計算
- current_Qを計算
- target_Qにcurrent_Qを近づけるようにparameterを更新
- critic_targetにcriticの値を足す
def train(self, replay_buffer, iterations, batch_size=64, discount=0.99, tau=0.001):
for it in range(iterations):
x, y, u, r, d = replay_buffer.sample(batch_size)
state = torch.FloatTensor(x).to(device)
action = torch.FloatTensor(u).to(device)
next_state = torch.FloatTensor(y).to(device)
done = torch.FloatTensor(1 - d).to(device)
reward = torch.FloatTensor(r).to(device)
target_Q = self.critic_target(next_state, self.actor_target(next_state))
target_Q = reward + (done * discount * target_Q).detach()
current_Q = self.critic(state, action)
critic_loss = F.mse_loss(current_Q, target_Q)
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
for param, target_param in zip(self.critic.parameters(), self.critic_target.parameters()):
target_param.data.copy_(tau * param.data + (1 - tau) * target_param.data)
これをEager Modeのスタイルで書くと
def train(self, replay_buffer, iterations, batch_size=64, discount=0.99, tau=0.001):
for it in range(iterations):
state, next_state, action, reward, done = replay_buffer.sample(batch_size)
state = np.array(state, dtype=np.float32)
next_state = np.array(next_state, dtype=np.float32)
action = np.array(action, dtype=np.float32)
reward = np.array(reward, dtype=np.float32)
done = np.array(done, dtype=np.float32)
not_done = 1 - done
with tf.device("/gpu:0"):
with tf.GradientTape() as tape:
target_Q = self.critic_target([next_state, self.actor_target(next_state)])
target_Q = reward + (not_done * discount * target_Q)
# detach => stop_gradient
target_Q = tf.stop_gradient(target_Q)
current_Q = self.critic([state, action])
# Compute critic loss + L2 loss
critic_loss = tf.reduce_mean(losses.MSE(current_Q, target_Q)) + 0.5*tf.add_n(self.critic.losses)
critic_grad = tape.gradient(critic_loss, self.critic.trainable_variables)
self.critic_optimizer.apply_gradients(zip(critic_grad, self.critic.trainable_variables))
for param, target_param in zip(self.critic.weights, self.critic_target.weights):
target_param.assign(tau * param + (1 - tau) * target_param)
ほぼ同一の形で記述できることがわかります。特筆すべき点は、
- L2 lossの扱い
- assignの扱い
の2点です。tf.keras.Modelは自信に紐づくparameterに加えて、紐づくregularization lossも管理しています。それをcritic.lossesで取り出し、損失関数に加えています。
assignはGraph Modeの際はその実行タイミングが直感に反することから、Tensorflow初心者殺しのオペレーターでしたが、Eager Modeでは即時実行されるようになったため、大変使いやすいです。
GradientTapeによる微分もtf.gradientsを使っていれば今までとほとんど変わりません。
Eager Modeにおけるsummary
ここまででPyTorchの移植は完了です。ですが、これだけでは不便なのでsummaryを仕込みます。
total_timesteps = tf.train.create_global_step()
writer = tf.contrib.summary.create_file_writer(args.logdir)
writer.set_as_default()
# tf.contrib.summary.record_summaries_every_n_global_steps
with tf.contrib.summary.always_record_summaries():
tf.contrib.summary.scalar("return", episode_reward, family="reward")
total_timesteps.assign_add(13)
上は説明用のコードです。summaryを使うには、まずsummaryにおけるstep数の基準となるglobal_stepを作成します。
そして、with tf.contrib.summary.always_record_summaries() の中でsummary.scalarを呼び出せば、summaryが作成され、create_file_writerで指定したフォルダに出力されます。
always_record_summariesを使うと、毎回summaryが記録されますが、tf.contrib.summary.record_summaries_every_n_global_steps(n=10)を使うと、summary.scalarを呼び出した際に、global_stepsがnで割り切れるときだけ記録されるようになります。
なお、summary.scalarの引数はnumpyでもfloatでも良いため、PyTorchからも簡単にTensorboardが利用できます。
学習結果の保存
Eagerモードでは、tf.train.Checkpointを使って、学習結果を保存します。
Checkpointはコンストラクタにおいて、保存対象を名前付き引数で受けとり、save時に保存します。こんな感じです。
checkpoint = tf.train.Checkpoint(optimizer=optimizer, model=model)
checkpoint.save(file_prefix=checkpoint_prefix)
名前付き引数にはtf.contrib.checkpoint.Checkpointableを継承しているオブジェクトなら何でも渡せます。
よって自作クラスを保存したい場合は、
class DDPG(tf.contrib.checkpoint.Checkpointable):
def __init__(self, state_dim, action_dim, max_action):
self.actor = Actor(state_dim, action_dim, max_action)
self.actor_target = Actor(state_dim, action_dim, max_action)
self.actor_optimizer = tf.train.AdamOptimizer(learning_rate=1e-4)
self.critic = Critic(state_dim, action_dim)
self.critic_target = Critic(state_dim, action_dim)
self.critic_optimizer = tf.train.AdamOptimizer(learning_rate=1e-3)
...
ddpg = DDPG(3,8,1.0)
checkpoint = tf.train.Checkpoint(policy=ddpg)
checkpoint.save(file_prefix=checkpoint_prefix)
で保存することができます。このとき、policyが所有するactorやactor_targetも再帰的に保存されます。この機能は、__setattr__のoverwriteによって実現されています。ちなみに保存されたcheckpointをinspectすると以下のような名前で保存されているのがわかります。
_CHECKPOINTABLE_OBJECT_GRAPH (DT_STRING) []
policy/actor/l1/.ATTRIBUTES/OBJECT_CONFIG_JSON (DT_STRING) []
policy/actor/l1/bias/.ATTRIBUTES/VARIABLE_VALUE (DT_FLOAT) [400]
policy/actor/l1/bias/.OPTIMIZER_SLOT/policy/actor_optimizer/m/.ATTRIBUTES/VARIABLE_VALUE (DT_FLOAT) [400]
policy/actor/l1/bias/.OPTIMIZER_SLOT/policy/actor_optimizer/v/.ATTRIBUTES/VARIABLE_VALUE (DT_FLOAT) [400]
policy/actor/l1/kernel/.ATTRIBUTES/VARIABLE_VALUE (DT_FLOAT) [17,400]
...
詳細は省きますが、重要なのはnameで指定した名前ではなく属性名で保存されるということです。トップレベルのオブジェクトは属性名を持たないため、それはCheckpoint構築時の引数名で与えられます。
なお、上記の方法でmodelを保存した場合、大量のCheckpointが保存されてしまうため、CheckpointManagerを用いるのがおすすめです。この書き方だと今までのModel保存方法と使用感が近いです。
checkpoint = tf.train.Checkpoint(policy=policy)
checkpoint_manager = tf.contrib.checkpoint.CheckpointManager(checkpoint,
directory="./eager_models/",
max_to_keep=5)
....
checkpoint_manager.save(checkpoint_number=total_timesteps)
なお、restoreも簡単です。
policy = tf_DDPG.DDPG(state_dim, action_dim, max_action)
checkpoint = tf.train.Checkpoint(policy=policy)
checkpoint.restore(args.parameter)
Eagerを高速に動作させる
さて、これで移植は完了です! PyTorchとパフォーマンスを比較してみましょう。
計測環境は
- PyTorch 0.4.1
- tensorflow-gpu 1.13.0-dev20181027
- GPU GTX 1070
- CPU i5-4440
です。200kステップまで実行した際にかかった時間で比較します。
| 手法 | 時間 |
|---|---|
| PyTorch | 21分7秒 |
| Eager | 1時間6分 |
となりました。Eagerモードめちゃくちゃ遅いですね。残念ながらEagerモードは無邪気に使うとPyTorchより遅いです。無駄なGPU, CPU間のデータ転送でもしているのでしょうか? そこで、tf.contrib.eager.defunを使って、処理の一部を計算グラフに変換してしまいます。
使い方は極めて簡単です。上述したtrain関数を「Python部分」と「Tensorflow部分」に分割し、Tensorflow部分の関数の先頭に@tf.contrib.eager.defunをつけるだけです。
def train(self, replay_buffer, iterations, batch_size=64, discount=0.99, tau=0.001):
for it in range(iterations):
state, next_state, action, reward, done = replay_buffer.sample(batch_size)
state = np.array(state, dtype=np.float32)
next_state = np.array(next_state, dtype=np.float32)
action = np.array(action, dtype=np.float32)
reward = np.array(reward, dtype=np.float32)
done = np.array(done, dtype=np.float32)
not_done = 1 - done
self._train_body(state, next_state, action, reward, not_done, discount, tau)
@tf.contrib.eager.defun
def _train_body(self, state, next_state, action, reward, not_done, discount, tau):
with tf.device("/gpu:0"):
with tf.GradientTape() as tape:
target_Q = self.critic_target([next_state, self.actor_target(next_state)])
target_Q = reward + (not_done * discount * target_Q)
# detach => stop_gradient
target_Q = tf.stop_gradient(target_Q)
current_Q = self.critic([state, action])
# Compute critic loss + L2 loss
critic_loss = tf.reduce_mean(losses.MSE(current_Q, target_Q)) + 0.5 * tf.add_n(self.critic.losses)
critic_grad = tape.gradient(critic_loss, self.critic.trainable_variables)
self.critic_optimizer.apply_gradients(zip(critic_grad, self.critic.trainable_variables))
# Update target networks
for param, target_param in zip(self.critic.weights, self.critic_target.weights):
target_param.assign(tau * param + (1 - tau) * target_param)
本当に2つに分けただけなので、5分ぐらいで出来ると思います。Python部分をdefun以下に含めない理由は、Python部分は一度しか評価されないため、そこを含めてしまうと、毎回同じデータに対して学習することになってしまうからです。defunの挙動は一度ぜひ公式ドキュメントを確認してください。
Eager vs PyTorch
では、あらためてパフォーマンスを比較しましょう。まず、スコアが一致しているかどうか確認します。
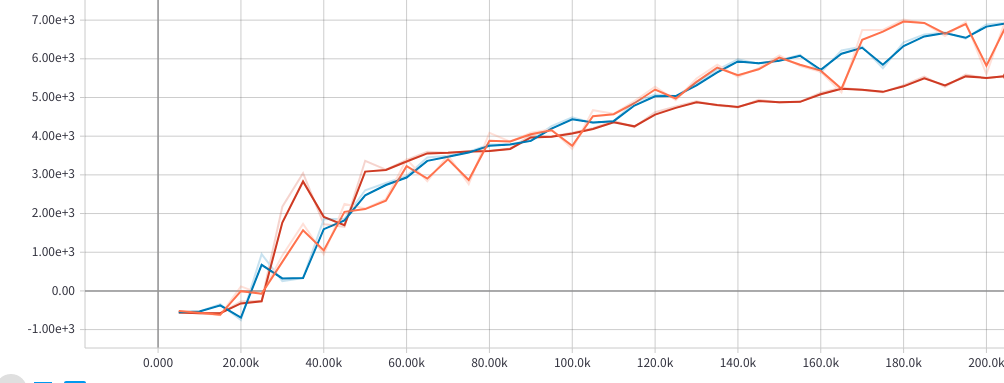
オレンジがPyTorch, 赤がEager, 青がEager+defunとなっています。ちょっとのずれはありますが、乱数によって結構結果が変わるジャンルなので、ここまで近ければ結果は再現できていそうです。(なお、biasの初期化方法がPyTorchとTensorflowで異なります)
次に200kステップまでの実行時間を比較します。
| 手法 | 時間 |
|---|---|
| PyTorch | 21分7秒 |
| Eager | 1時間6分 |
| Eager+defun | 17分12秒 |
Tensorflowが約20%速い!ありがとうTensorflow!
というわけでTensorflow Eagerも、ちょっといじればPyTorch並の速度が出せることを示せました。もちろん、私はPyTorchはチュートリアルレベルなので少しアンフェアではあります。
結び
本記事では、Eager Modeを使う際のAPI群とパフォーマンスを示しました。feed_dictを完全に排除した今回の実装は、Graph Modeで書かれた多くの強化学習実装よりも可読性に優れており、実装コストも低いです。
Eager Modeは状況がはまれば強力な武器ですが、ドキュメントがまだ薄いためか、あまり使われていない印象があります。
私が使っているシチュエーションは
- Graphモードで学習したモデルをEagerモードで評価する (評価コードがすっきりする)
- scikit.learnと組み合わせる際にEagerモードを使う (Pythonの関数群と組み合わせやすい)
- アルゴリズムの初期検証にEagerモードを使う
- モデルを利用するツールをEagerモードで作る
などです。一方で使っていないのは
- 既存Tensorflowコードと組み合わせるとき (keras.layersなしのモデルとの連携は難しい)
- 画像認識のとき (単純なモデルだと別にいらない)
などです。
以上で本論は終了です。Eager ModeをはじめとするTensorflow 2.0 API群を皆さんもぜひ使ってみてください。
以下はおまけ。
部分グラフを可視化する
tf.contrib.eager.defunで作成したグラフはGraphなのでTensorboardに出力することが可能です。こんな感じ。
@tf.contrib.eager.defun
def graph():
v1.assign_add(1, name="v1_asssign")
v2.assign(v1, name="v2_assign")
diff = tf.equal(v1, v2)
return diff
summary_writer = tf.contrib.summary.create_file_writer("./test_log", flush_millis=1000)
with summary_writer.as_default():
returns = graph._maybe_define_function(args=[],kwargs={})
function_graph = returns[0]
print (type(function_graph))
tf.contrib.summary.graph(
function_graph.graph
)
これで、defunで生成した計算グラフをデバッグすることが可能です。上の例では2つのassign間に順序関係がきちんと定義されていることを確認できます。
なお、private関数を呼んでいるのでバージョンによっては動かないことがあります。