2019/5/11 PR: こちらの内容を含め、2019年5月11日発刊の
図解速習DEEP LEARNINGという本ができました。[2019年5月版] 機械学習・深層学習を学び、トレンドを追うためのリンク150選 - Qiitaでも、一部内容をご覧いただけます
2019/3/9 Colaboratoryに関する情報交換Slackを試験的に立ち上げました。リンクより、登録・ご参加ください。
2019/3/3 TensorBoardに公式対応しました。また、ランタイムのRAM/ディスク空き容量が一目で確認できるようになりました。後ほど記事に追記します。

はじめに
Colaboratoryは、無料で使うことができ、ほとんどの主要ブラウザで動作する、設定不要のJupyterノートブック環境です。Googleが、機械学習の教育、研究用に使われることを目的に、無償提供しています。ざっくりというなら、WordライクなGoogle Docs、ExcelライクなSpreadsheetといった、クラウドアプリケーションのPython/ 機械学習版で、Pythonのソースコードを対話型で実行できるだけでなく、前に挙げたアプリケーション同様、作ったものを共有したり、共同編集したりすることができます。
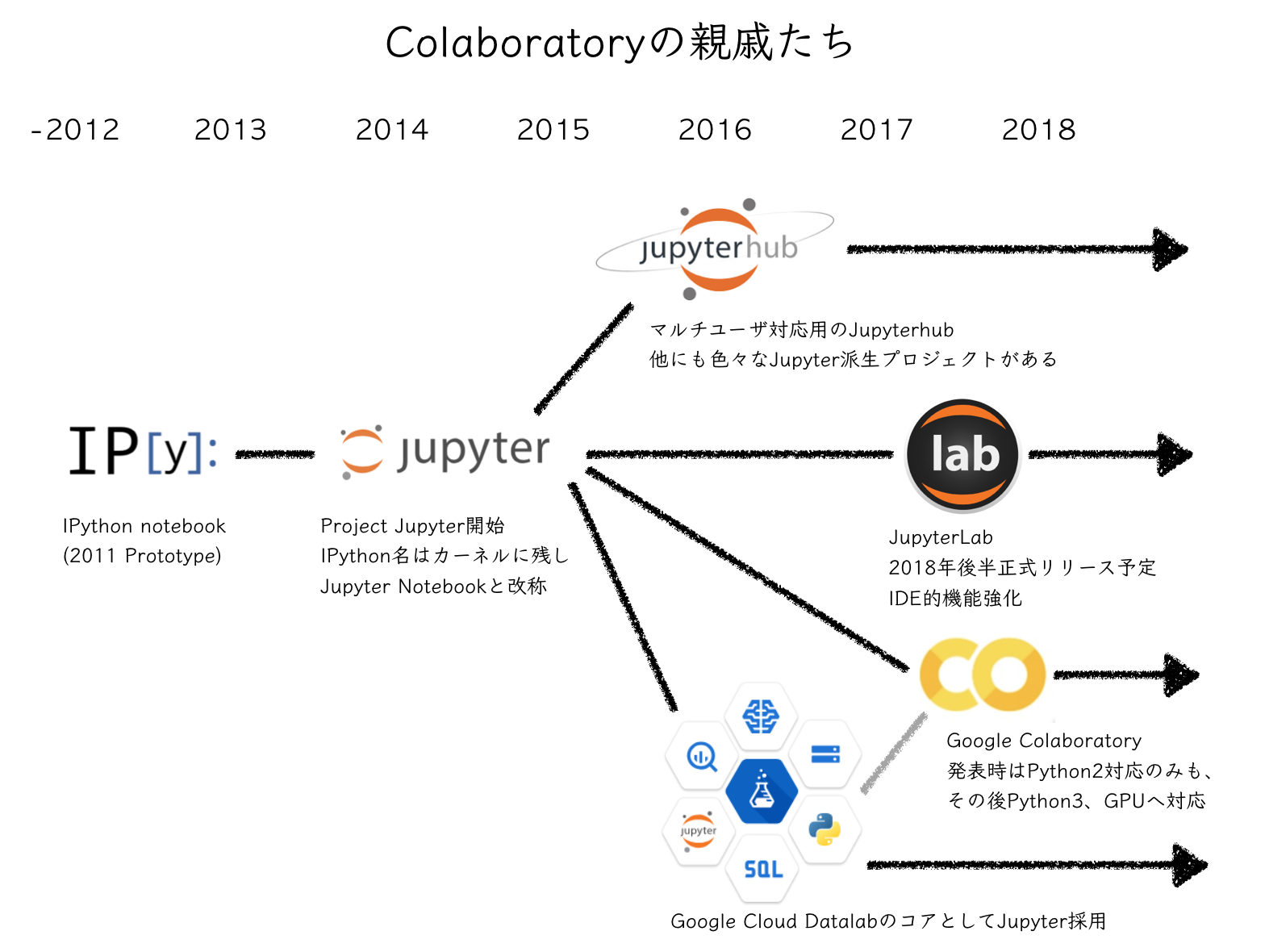
Jupyterというオープンソースプロジェクトは、データサイエンス、機械学習コミュニティに広く受け入れられています。古くはIPythonというプロジェクトから、2010年代に大きく成長しました。Colaboratoryは、下記の系譜でそれらから派生したものです。Webや書籍等で解説されるJupyter用のTipsも使うことができます。
本稿では、Colaboratoryを使うにあたっての「知っておくと便利」「手詰まりを避けられる」Tipsをまとめます。公式のFAQも準備されているため、困った時には併せてご参照ください。
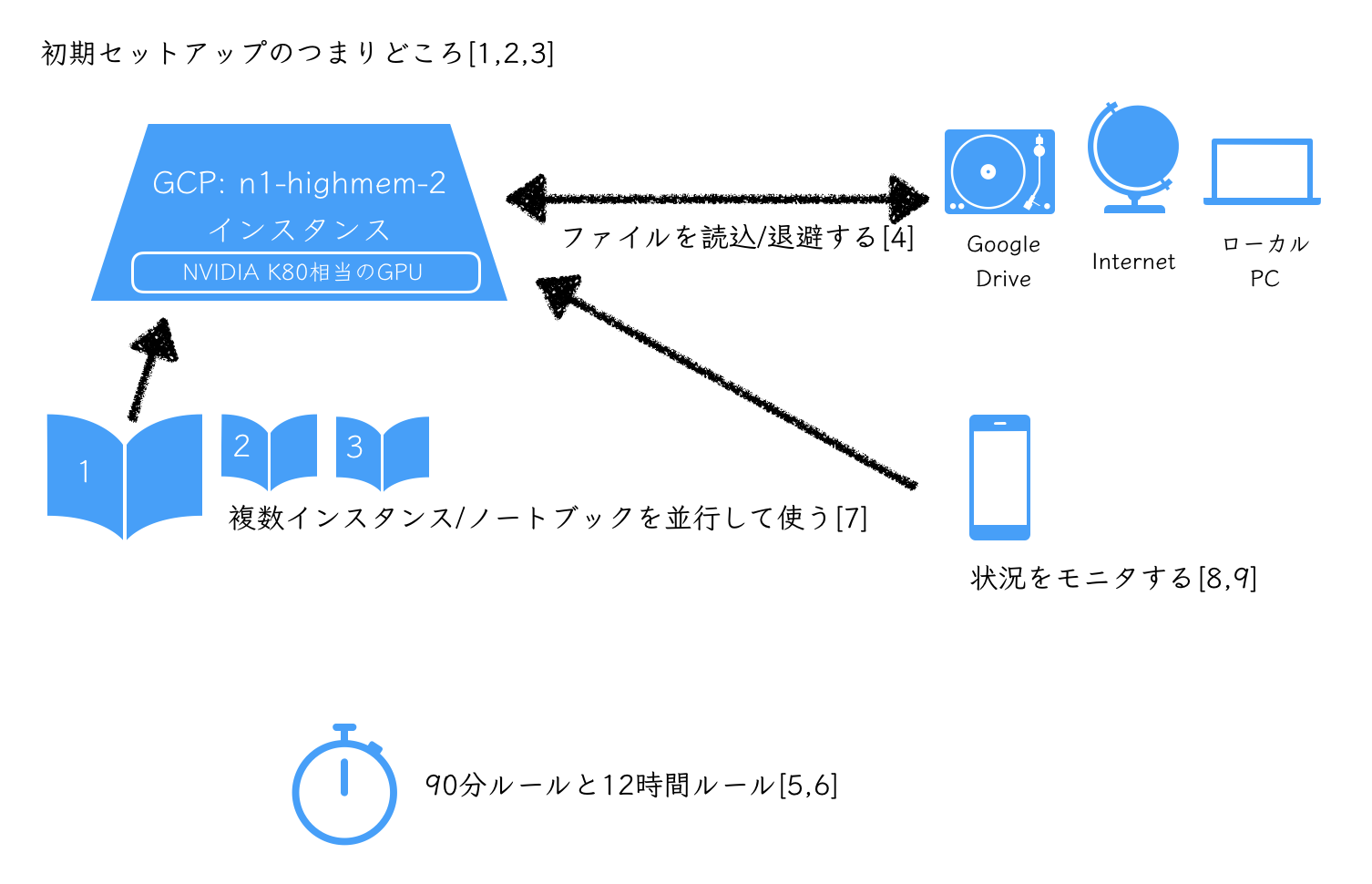
前提. シェルコマンドの実行、パッケージ導入とカレントディレクトリ
- 様々なサンプルノートブックを開く(Google DriveやGitHub、その他)
- シャットダウンまでの残時間確認(90分ルールと12時間ルール)
- 適切なメモリ、ディスクスペースの利用
- インスタンスへのファイル読込みと退避
- 12hを超えるタスクの実行方法
- ブラウザセッションの維持
- 実行負荷を確認したり、並行作業をしたい
- スマホで学習状況をモニタしたい
- Tensorboardでモニタしたい
- Colabの制約を外したい時は
- おかしいな、と思ったら
- あとは実践あるのみ
ColaboratoryでのGPUインスタンス使用方法、各フレームワークのセットアップはこちら。
上記のようにセットアップまでは爆速。ただ実践にあたって気をつけるべき点があります。
Colaboratoryを立ち上げると、2018年10月時点では、時間限定で下記の環境が個人に割り当てられます。見た目は、Googleドライブ、スプレッドシート、ドキュメントのように、ブラウザから使えるシングル・ページ・アプリケーションです。裏側にはGCPのVMと、その上のコンテナが割り当てられているようです。 n1-highmem-2 はGoogle Cloud Platformで提供される、仮想マシンタイプの一つです。(20190516更新):
- n1-highmem-2 instance
- Ubuntu 18.04
- 2vCPU @ 2.2GHz
- 13GB RAM
- (GPUなし/ TPU)40GB, (GPUあり)360GB Storage
- GPU NVIDIA Tesla T4 16GB または Tesla K80 12GB
- アイドル状態が90分続くと停止
- 連続使用は最大12時間
- Notebookサイズは最大20MB
使いこなすにあたって、特に太字の容量や上限に注意が必要です。
以降、長くなってきたのでチートシート(beta)をまとめはじめています。
基本操作
初めて使う方は、環境構築不要でPython入門!Google Colaboratoryの使い方を分かりやすく説明|はやぶさの技術ノートの記事などで、一通りまず触ってみましょう。
さらに、こんにちはColaboratory - Colaboratoryというウェルカムノートブックと、そこにあるリンク先ノートブック(英語)を通して見ると、何ができるかが分かります。
- Colaboratory の概要
- データの読み込みと保存: ローカル ファイル、Google ドライブ、Google スプレッドシート、Google Cloud Storage
- ライブラリのインポートと依存関係のインストール
- Google Cloud BigQuery の使用
- フォーム、グラフ、マークダウン、ウィジェット
- GPU を使用した TensorFlow
- Machine Learning Crash Course: Pandas の概要、TensorFlow の最初のステップ
Tips
前提. シェルコマンドの実行、パッケージ導入とカレントディレクトリ
シェルコマンドの実行
!{コマンド}
で実行できる。
パッケージ導入
まずColabを使い始めると、毎回インスタンスがまっさらな状態(とはいえ CUDA/cuDNN numpy scipy tensorflow など基本的なものは導入済み)で立ち上がる.
pip によるpythonライブラリ追加、 apt-get によるパッケージ追加をする。
例えばKerasなら下記で入る。それ以外のフレームワーク等はこちらを参照。
!pip install keras
カレントディレクトリ
しかしつまづくのは !cd ではディレクトリ変更が反映されないところ。
そこはmagic commandを使い、このようにする。
%cd {対象ディレクトリ}
magic commandとは、Jupyter(iPython)で使える % ではじまる便利コマンド群です。 (参考チートシート Ipython-quick-ref-sheets)
応用として、例えばgit cloneしたソースからコンパイルしてインストールしたい場合は下記のような流れとなる。
基本 README.md などのインストールガイド、シェルコマンドは !{コマンド} とし、 cd は %cd に変えれば、パッケージ依存でハマらなければ動く。
!apt-get {依存するパッケージ}
!pip install {依存するPythonパッケージ}
%cd /content
!git clone {対象リポジトリ}
%cd {対象ディレクトリ}
!./configure
!make
!make install
またはシンプルに、 %%bash を使い、シェルコマンドのみを実行するセルを作ることもできる。
%%bash
apt-get {依存するパッケージ}
pip install {依存するPythonパッケージ}
cd /content
git clone {対象リポジトリ}
cd {対象ディレクトリ}
./configure
make
make install
1. 様々なサンプルノートブックを開く(Google DriveやGitHub、その他)
既存の.ipynb形式のノートブックを開けます。主に3つの場所から開くことができます。
- Googleドライブから開く
- GitHubから開く
- ローカルファイルをアップロードし開く
Googleドライブから開く
Googleドライブ側から開く、Colaboratory側から開く、双方からのやり方があります。
Googleドライブ側から
Googleドライブ上のファイル一覧からノートブック(.ipynb)を選択し、開くアプリケーションとしてColaboratoryを指定すると、直接開けます。
Colaboratory側から
2つのやり方があります。
ファイル> ノートブックを開くから、GOOGLEドライブタブを選ぶ。My Drive> Colab Notebook配下にあるノートブックを選択して開くことができます。
または、ドライブの共有リンクidがわかる場合は、https://colab.research.google.com/drive/{Googleドライブ共有リンクのid}で開くこともできます。
GitHubから開く
同様に、GitHub側から開く、Colaboratory側から開く、双方からのやり方があります。
GitHub側から
https://colab.research.google.com/github/{URLの、github.com/以下の部分}で、直接ノートブック(.ipynb)を開きます。
Colaboratory側から
まずファイル> ノートブックを開くから、GITHUBタブを選びます。GitHub URL、組織またはユーザを入力し、検索します。すると、該当のリポジトリやブランチを選ぶことができます。そこから目的のノートブックを開きます。
アップロードして開く
ファイル> ノートブックをアップロードから、ローカルにある任意の.ipynbファイルを開けます。
手元に試せるものがない!
その場合は、Google Seedbankや、東大松尾研の講座なら、すぐに試すことができる。
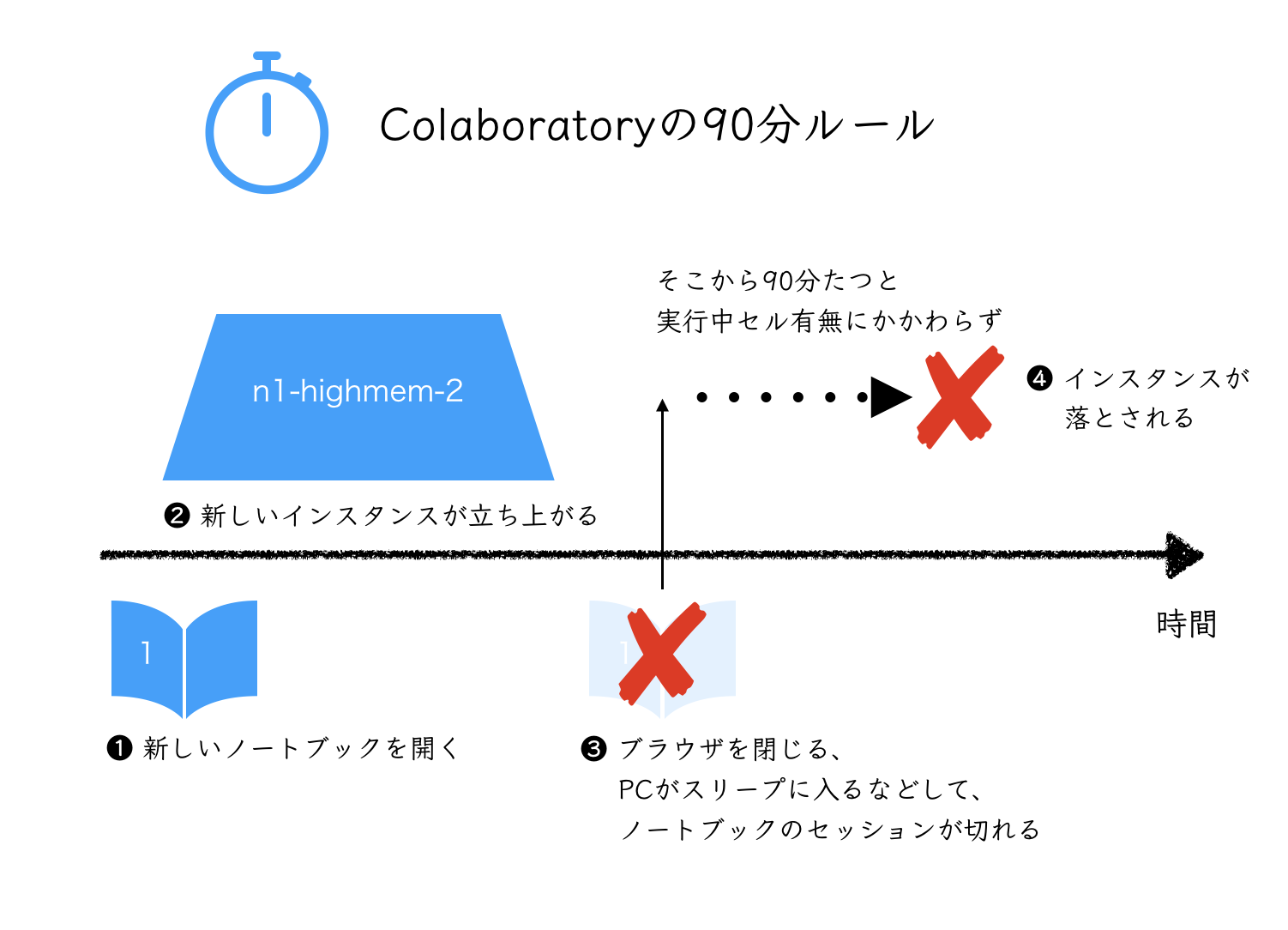
2. シャットダウンまでの残時間は(90分ルールと12時間ルール)
まず、Colaboratoryの90分ルールと12時間ルールを理解する。(食べ物の3秒ルールではない。)
12時間ルールは、下記shコマンドをセルから実行すれば、起動からの時間がわかる。
!cat /proc/uptime | awk '{print $1 /60 /60 /24 "days (" $1 "sec)"}'
結果は、
0.0146818days(1268.51sec)
などと出力される。 0.5days を超えて数分以内に、割り当てインスタンスが再起動される。
3. 残りのディスクスペース、メインメモリ、GPUメモリは
- ストレージはGPUなしやTPU利用の場合40GB、GPUありの場合360GB Storage
- メインメモリは13GB RAM
- GPUメモリは12GB
ディスクは df で上限に目を配る。
!df -h
メインメモリは、7-80%の使用を超えると、Colabのダイアログで警告される。 free で同じく上限に目を配る。
!free -h
最後にGPUメモリの利用状況は、 nvidia-smi で確認する。
!nvidia-smi
- Kerasなら
flow_from_directory()を使うなど、一度にメモリ上の画像のarrayを展開するなどのメモリ使用量にはねる使い方を避ける - ディスク節約は、次のGoogle Driveマウントをうまく活用する
4. インスタンスへのファイル読込みと退避
開始時のColab上へのファイル読み込み、および最大12h経過後shutdown対策。
ローカル環境とColab間でのやりとり
ある程度の数、サイズのファイルなら、ブラウザを経由してColabとローカルでやりとりすれば良い。
左ペインを使う
左ペインを開くと、ファイルというメニューがあります。ここには /content 配下のファイルが表示されています。
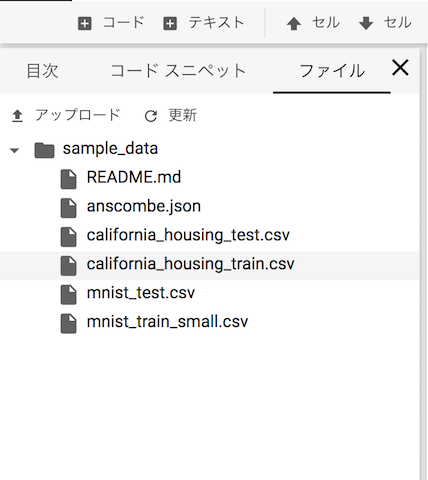
左上のボタンからファイルの アップロード、右クリックメニューからファイルの ダウンロード いずれも可能です。
コマンドを使う
まず、 files をimportする。
from google.colab import files
アップロードは下記を実行し、
uploaded = files.upload()
表示される ファイル選択 ボタンを押し、アップロードしたいファイルを選ぶ。複数選択し、一括アップロードすることもできる。

ファイルを名を指定し実行すると、ブラウザでダウンロードが開始する。
files.download('{ファイル名}')
Google Driveをマウント
一定以上のファイル容量、ローカルではないところに保存しておきたいなどの場合、Google Driveが便利。下記でマウントできる。
from google.colab import drive
drive.mount('/content/drive')
以前は astrada/google-drive-ocamlfuse が使われていたが、公式にgoogle.colabのライブラリがGoogle Driveに対応した。
参考: ColaboratoryでのGoogle Driveへのマウントが簡単になっていたお話 - Qiita
正常にマウントできれば対象Google Drive内容が表示される。
!ls /content/drive/My Drive
ここからは、 My Drive/ 配下のファイルに対して cp なり mv なり、通常のLinuxコマンドでファイルをコピー、移動できる。
Google Driveをローカルディスクのように扱う
新たにファイルを取得する
データセット等をColabのインスタンス上に持ってくる必要がある。下記の複数の方法がある:
- ローカルからアップロード(先述)
- wgetでWebから取得
- git cloneでWebから取得
- Google Driveに入れて、インスタンスへ都度コピー
- kaggle-apiで取得
初回は wget や git clone で持ってくる。Kaggle参加の場合は、 kaggle-api でデータセットをダウンロードし、Google Driveへコピーしておくとよい。それぞれ継続して使う場合は、Google Driveへコピーしておく。
そして、各作業用Notebook冒頭に
- Google Driveマウント
- 初期コピー
を書いておき、毎回作業開始時のルーチンとして実行すると便利。
tar, zipは標準で解凍可能。7zipは入っていないため apt-get -y install p7zip-full する。
# wget
!wget https://xxx/xxx.zip
# git clone
!git clone https://xxx/xxx.git
# kaggle-api
!pip install kaggle-api
# .7z形式を扱う場合
!apt-get -y install p7zip-full
# ファイルの解凍等
!unzip xxx.zip
!7z x xxx.7z
!tar -zxvf xxx.tar.gz
kaggle-apiコマンドの使い方は、kaggle-api kaggleコマンドの使い方 - Qiitaなどをご参照ください。
Kaggle webサイトからダウンロードした kaggle.json は、左ペインのファイルブラウザからアップロード可能です。
余談ではあるが、あるディレクトリ下のzipファイルを一括で解凍したいときは、 !unzip *.zip ではなく、 !unzip '*.zip' と、シングルクォーテーションで正規表現を囲んでやる必要がある。
ファイルを編集する
git clone してきた xxx.py ファイルを一部編集したいときがあるとする。
!cat xxx.py
し、出力セルからコピーする。新規セルに貼り付け、編集し、下記のように実行する。
%%writefile xxx.py
{編集済みのxxx.pyの内容}
必要に応じて、
%run xxx.py
で xxx.py 自体を単体で実行することができる。
ファイルを退避する
さきほどwgetなどしたファイルも、利用上限の範囲内(無料で15GBまで。250円/月で100GBまで。)でGoogle Driveへコピーしておくと、再利用できて便利。
# 必要に応じてdirectory作成
!mkdir drive/<指定のフォルダ>
# 指定ファイルをdriveへコピー
!cp xxx drive/<指定のフォルダ>
ファイルを再度利用する場合は、Google Driveからインスタンスへ戻してくる。
!cp drive/My Drive/<指定フォルダ>/<指定ファイル等> .
大きなデータセットなどはzipのままGoogle Driveに保存しておき、Colabを起動都度、Colabローカルに解凍して持ってくると良い。
!unzip -q drive/My Drive/<指定フォルダ>/<指定ファイル>.zip
-q は解凍時のメッセージを出さないオプション。2GB程度、数千ファイルを含むアーカイブでも、1分程度でGoogle Driveからの取得と解凍が終わる。
モデル保存先をGoogle Driveにする
- 逐次のモデル保存ができる。12hr以上の学習、突然のshutdownに備えてスナップショットをとっておく
- Kerasの場合、モデルのスナップショットである
.hdf5逐次保存はうまくいく - 逐次のlog保存は、学習途中は反映されない。完了時に保存されるため注意
- 同一ファイル名で上書き保存を続ける(例: best modelの保存等)と、都度の履歴が保持されGoogle Driveの容量制限をすぐ超えてしまうらしい(未確認)
- Kerasの場合、モデルのスナップショットである
google_drive_dir = 'drive/'
base_file_name = 'test1'
# Google Driveに逐次モデルのスナップショットを保存
checkpointer = ModelCheckpoint(filepath = google_drive_dir + base_file_name + '.{epoch:02d}-{val_loss:.2f}.hdf5', verbose=1, save_best_only=True, monitor='val_acc', mode='max')
# Google Driveでは学習終了まで反映されない。localに保存
csv_logger = CSVLogger('./xxx.log')
...
history = model.fit_generator(train_gen,
validation_data=val_gen,
nb_val_samples=nb_validation_samples,
samples_per_epoch=nb_train_samples,
nb_epoch=nb_epoch, callbacks=[csv_logger, checkpointer])
Google Driveの容量オーバーに注意
容量を超過すると、途中経過のモデルが正しく保存されず、半日の学習結果が失われるなど、悲しい事態となる。
Google Driveをマウントしていれば、 df コマンドで空き容量を確かめられる。
!df -h drive
出力例
Filesystem Size Used Avail Use% Mounted on
google-drive-ocamlfuse 15G 6.3G 8.8G 42% /content/drive
Google Drive無料枠は15GB。モデルサイズやデータセットサイズによってはすぐに超過する。有償での容量追加、またはこまめな不要ファイル削除を心がける。なおも足りない時は、250円/月で100GB等、容量追加ができる。
5. 12h超えタスクを実行するには
最大12h経過後shutdown対策。
- 上で保存しておいた学習済みモデルの重みを読込み、学習を再開する
- Kerasの場合、
.hdf5ファイルは、ネットワーク構造、重みのスナップショットなので、読み込めば学習を再開できる
- Kerasの場合、
# モデルの読込(再 model.compile() は不要)
model = loadl_model("drive/xxx.hdf5")
# 学習再開など
model.fit(...)
6. 12hたたずシャットダウンされるけど..
Colaboratoryは、なにも実行されていない状態、または実行中でもブラウザでタブが開かれていない状態で90分たつと、インスタンスが落とされる。
sleepを切ったマシンで常時タブに繋いでおく、などで回避できる。スマートフォンからnotebookを開きインスタンスに接続する、などでも残り時間が延長される。
notebookとインスタンスの対応関係は次の項目を参照のこと。
7. 同時に複数notebookを使い分ける
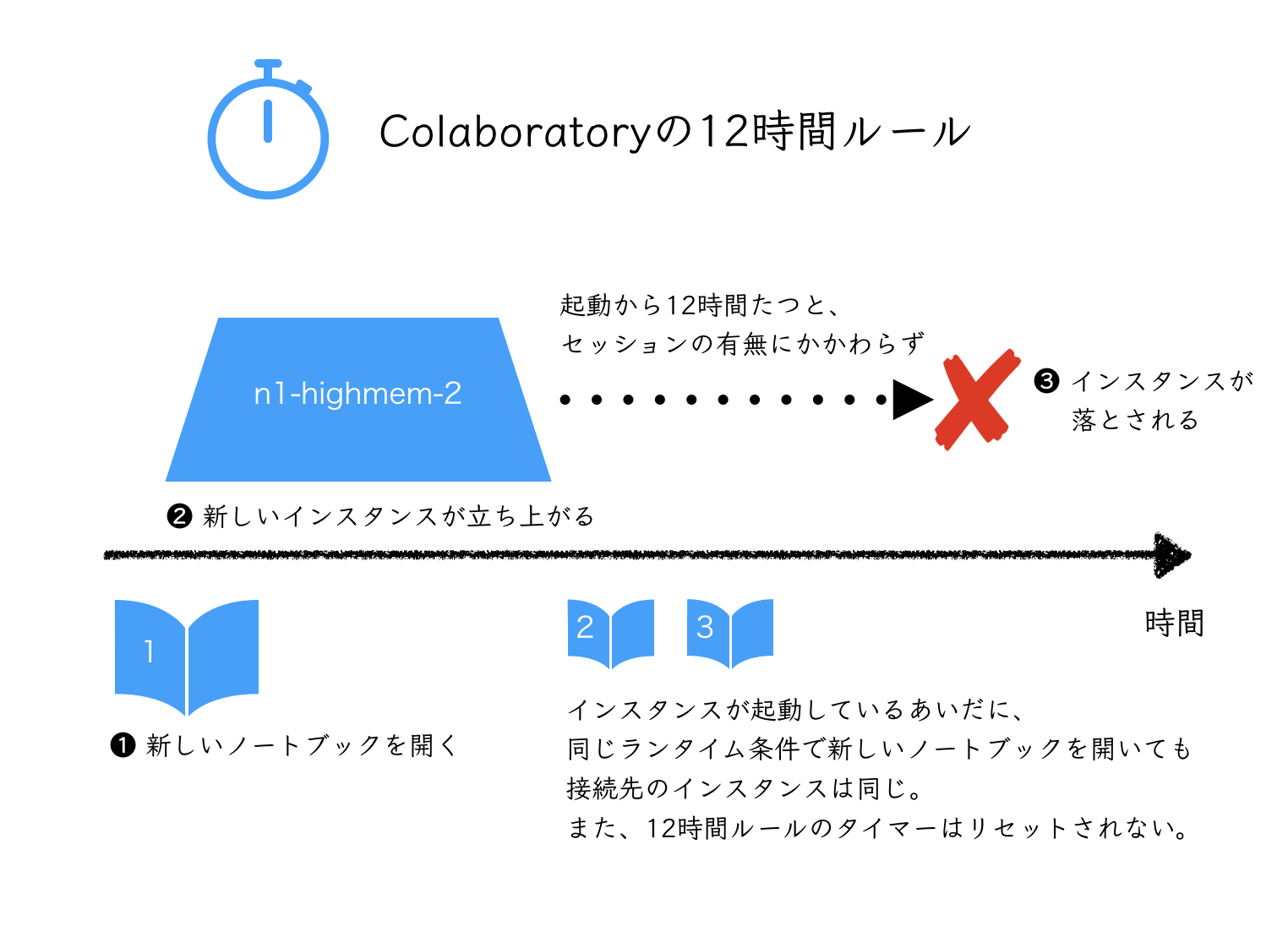
- Colaboratoryは、同じランタイム条件で複数タブを開いても、同時に立ち上がっているインスタンスは1つ
- 正確には、Googleアカウント1つにつき、下記2つまで同時に起動する
- GPUありインスタンスを1つ
- GPUなしインスタンスを1つ
- sshを複数セッション立ち上げるのと同様、1 Notebookが学習のため占有されていても、他のNotebookを立ち上げることで操作できる
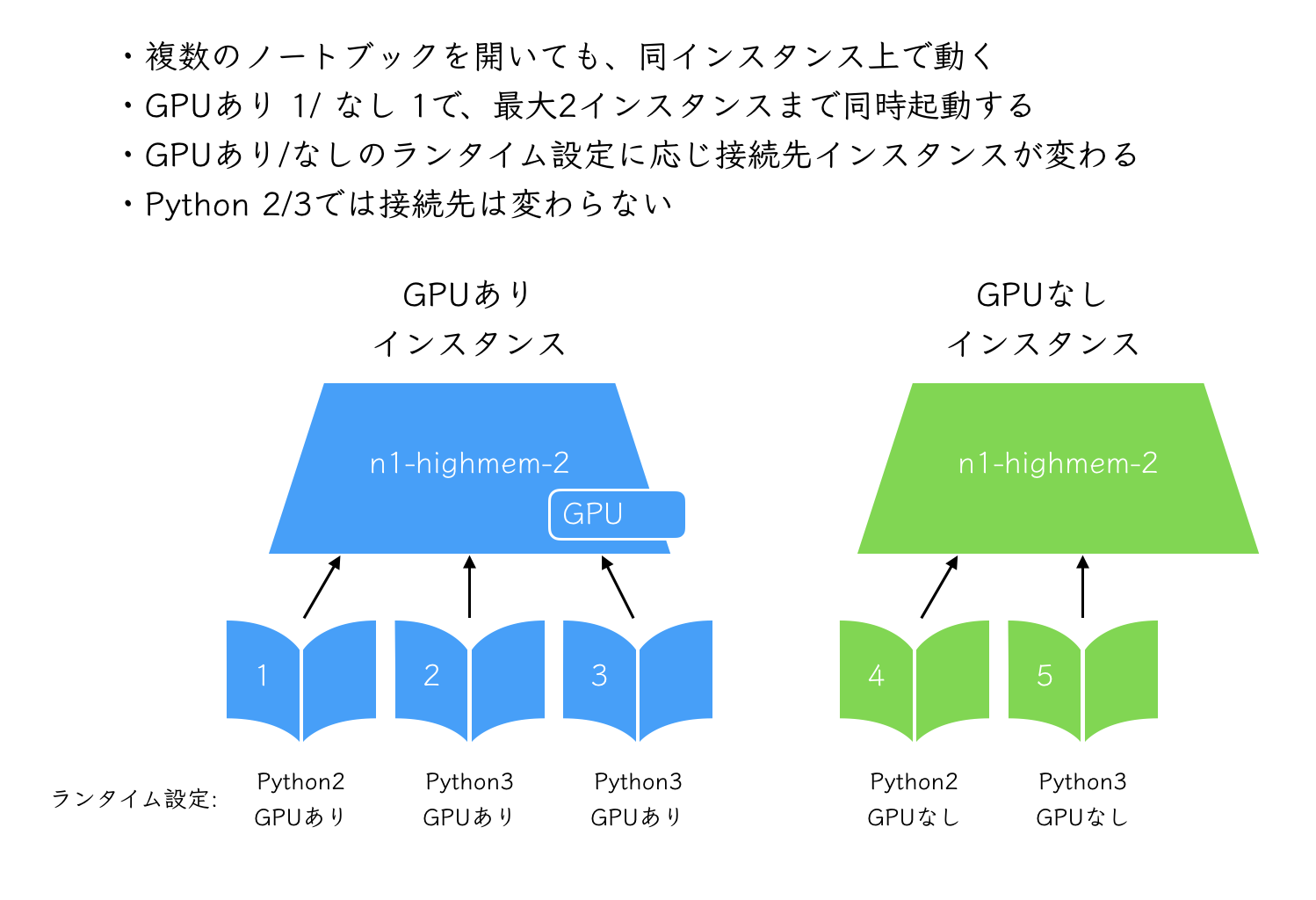
注記: ディスクやインストール済みパッケージが共有された仮想環境という意味でインスタンスと記載しました。実際には各ランタイムはコンテナとして提供されているように見えます。また、TPU v2ランタイムの対応後は、実際はCPU、GPU、TPUv2の3環境が同時に立ち上げ可能です。
これを応用すると、以下のような使い方ができる。
メインノートブックの実行負荷を確認する
メモリ利用量が多い、実行時間がかかる、などのタスクについて状況を確認したいことがある。
同じインスタンス条件(GPUあり/ なし)で新規ノートブックを作成し、下記コマンドを実行することで、インスタンスの状況を確認できる。
!apt-get install sysstat #sarの準備
!df -h #ディスク空き
!free -tm #メモリ空き
!ps aux #プロセス実行状況
!top # 各プロセスのリソース使用状況
!sar -u -r 1 5 #メモリ、CPU利用率の履歴
学習や推論中に並行作業をする
ちょっとファイルを退避させたい、連続起動時間を確認するなどに使える。学習で占有されているインスタンスで別作業ができる。
-
A.ipynbで数時間かかる学習中(同Notebookでは完了まで他のコマンドを実行できない) - そんな時も、
B.ipynbをGPUあり/なしの条件を合わせて立ち上げると、同インスタンスで並行作業できる-
cp xxx.log drive/tmpで作業中ファイルを回収するなど
-
講義・勉強会で内容をリアルタイム共有する
同じNotebookで、出力を共有することができる。
- 高橋さんが
A.ipynbで作業中に、中山さんが、共有されたA.ipynbを開く - 中山さんは、高橋さんの作業結果(セル出力)を、自分の手元の
A.ipynbでリアルタイムに見ることができる- 閲覧だけなら、中山さんの
A.ipynbのステータスは、インスタンスへ未接続でも問題ない - Google Spreadsheet, docsの共同編集のイメージ
- 閲覧だけなら、中山さんの
8. 学習状況をスマホでモニタしたい
-
スマホブラウザ(iOS Chrome, Android)からも、同Notebookを開けば、簡単な状況確認ができるが、スクロールが怪しい、正しくインスタンスに接続できない、など公式にはサポートはされていない初期は動作が不安定でしたが、スマホブラウザでも、一定の操作ができるようになった - 閉じていても、進行中の学習状況を遠隔で知りたい場合などは、 Hyperdash | Machine Learning Monitoring を使うと良い
Hyperdash
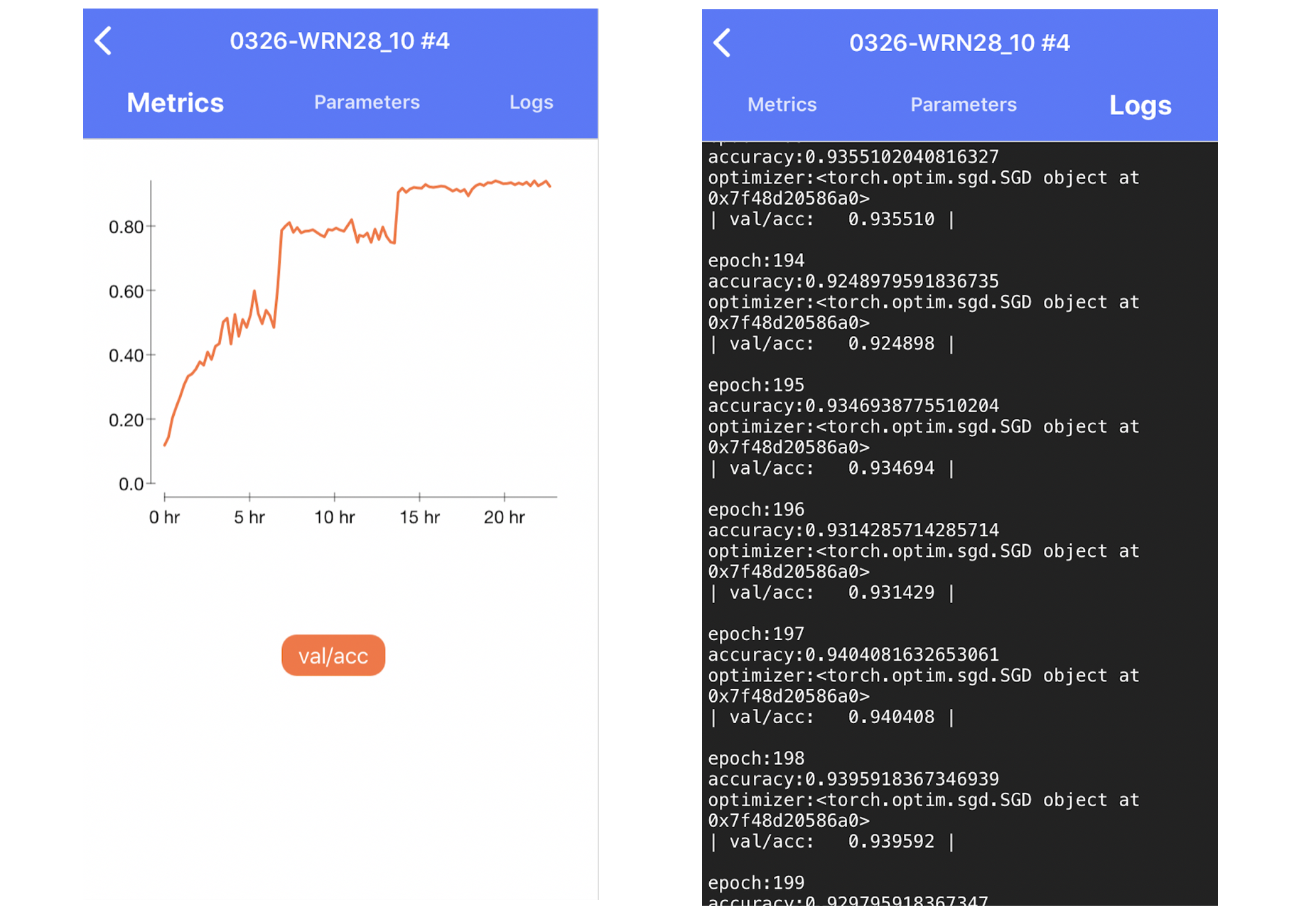
スマホアプリから、いつでもどこでも進捗を確認できる。もはやちょっとした育てゲー。
Colabのセルから実行した場合、hd loginなどのプロンプトに対応できないため、ローカル環境などであらかじめhyperdashのAPI Keyを取得し、Colab実行時に環境変数に投げ込む。
!pip install hyperdash
%env HYPERDASH_API_KEY = <あらかじめ取得したAPI Key>
- マジックコマンド一発でモニタできるらしい(まだうまくいっていない)
from hyperdash import monitor_cell
%%monitor_cell "Experiment 1"
-
学習過程をグラフ化する、ハイパーパラメータを保持するためにはExperiment APIを使う
-
ざっくり言うと下記の流れ:
- まずExperiment APIのimport
from hyperdash import Experiment - Experimentの宣言
exp=Experiment("Model 1", capture_io=False)-
api_key_getter=API_KEYとも書けるようだ
-
-
capture_io=Trueとすると、Colab側のCell出力が出なくなることがある
- パラメータ設定は
exp.param() - ログを送るには
exp.log() - グラフ描画、ハイパーパラメータ保持用にmetricとして送る
exp.metric() - 終わったら
exp.end()
- Kerasなら下記が詳しい
- 他ライブラリも記事がある
- PyTorch: PyTorch で Hyperdash を使ってみる - Qiita
- Chainer/ XGBoost: スマホアプリで学習状況を監視するHyperdash入門 - kumilog.net
9. 学習状況をTensorboardでモニタしたい
上述のGoogle Driveへのファイル出力での詰まりポイントとあわせ、Tensorboard対応のworkaroundが紹介されている。また、taomanwai/tensorboardcolab: A library make TensorBoard working in Colab GoogleというColaboratoryにTensorboardを対応させるオープンソースプロジェクトも開始しています。
10. Colabの制約を外したい時は
下記の制限から自由になりたいことがある。
- 12時間制限をなくす
- アイドル時シャットダウン待ち時間を長くする
- CPUコア、RAM、GPU枚数を増やす
それには、下記のような方法がある。
- 自身の好きなVMでColabバックエンドを立上げる
- Cloud Datalabを使う
自前のColabバックエンド(ローカルランタイム接続)
@ikeyasu さんの記事に詳しい。
TPUを使うことだってできる。
Cloud Datalab
Cloud Datalabは、Colaboratory以前からGCPで提供されている、Jupyter Notebook付きで立ち上がるVM。ただし、下記の注意点がある。
- 課金が必要
- 使えるNotebookはColaboratoryと同じくJupyter亜種だが、GUIが異なる
- Colabと比較し、インスタンスの初回起動に時間がかかる(5-10分程度)
Google Cloud Console上からシェルを使えば、インスタンスの立ち上げ、ログイン、破棄までブラウザで完結することができ、Colabと遜色ない手軽さで使え、個人ユースでは、Colabでおさまらないプロジェクトで、たまに割り切って課金して回すという使い方ができている。
11. おかしいな、と思ったら
- ランタイムは目的のものを選んでいるか
- ホストか、ローカルか
- Python2か、3か
- GPUは割り当てられているか
この辺りを確認する。
複数セッションを立ち上げ、メモリが逼迫するなどしたときは、 ランタイム> セッションの管理 から不要なセッションを終了する。
制限時間が切れていないが、一度環境をリセットしたいときには ランタイム> ランタイムを再起動 または、下記コマンドを実行する。
!kill -9 -1
12. あとは実践あるのみ
Colaboratoryを使ったプロジェクトを紹介します。
- はやぶさの技術ノート
- 懇切丁寧な解説で注目を集めた【深層学習入門】画像処理の基礎(画素操作)からCNN設計までの著者 はやぶささんのColaboratory解説記事。本記事では触れられていないところも含めスクリーンショットをふんだんに使った分かりやすいガイドで始められます。
- 環境構築不要でPython入門!Google Colaboratoryの使い方を分かりやすく説明
- ColaboratoryでChainer使ってYoloを動かす
- 【深層学習入門】超実践!Chainerと深層学習でシステム解析する方法
-
ディープラーニングに入門するためのリソース集と学習法(2018年版) - Qiita
- はじめやすいのはわかったけど、何から始めたらよいか、という方にはこちらがおすすめです。プロジェクトを通した学習、fast.ai推しなど、私も同様にはじめたので共感するところが多くありました。
-
【無料】4大深層学習フレームワークをGPU版Colaboratoryとlocaltunnelで使い倒そう【簡単】 - Qiita
- 同一条件下での各フレームワーク比較、Tensorboardの使用方法などコンパクトにまとまった良記事です。MXNet, Sonnetの導入方法もあり
-
Google Colaboratoryが便利・高速で凄過ぎる - Itsukaraの日記
- Wide Residual Networks。Google Driveへのファイル退避を使った12+4=16時間の学習事例
-
ChainerRL を Colaboratory で動かす - Qiita
- Chainerを使った強化学習、Colaboratory上でのアニメーション確認まで行えます
-
Colaboratoryで10秒で起動できる、ChainerのGitHubレポジトリ作ってみた - Qiita
- GitHub上でnotebookをどうバージョン管理するか。また、Travis CIでGoogle Driveへ連携する方法、ハマりどころの解説。chainer-colab-notebookへ今後tutorialが集積されていくとのこと。
募集!
ほかにいいのがあればぜひ、教えてください。みなさんでうまくColabを使えたらと思います。
Appendix. 主な更新
ColabもGPU対応から半年が経過、当初から様々な機能が追加され使いやすくなったため、何がいつ頃変化したか、時系列で振り返ります(20181016/更新中。上が新しい)
- (Ubuntu, TensorFlowは順次最新バージョンへ更新)
- (昔と比べ、一時切断後の再接続が安定した)
- TPU v2ラインタイム対応
- シェルコマンド実行時の対話型入力に対応(Y/Nへの応答など)
- GUIでセッション管理、ランタイムの再起動、全ランタイムリセット
- 左ペインにファイルブラウザが追加
- Google Driveマウントに公式対応、手順が簡便に
- nvidia-smi対応(以前は実行できなかった気がする)
- スマートフォンに公式対応(レスポンシブデザインになった)
- GitHubからの.ipynbオープンに対応(repo指定ですぐ開ける)
- ローカルランタイム接続の追加(自分で建てれば時間制限を外せる)
- フォームの追加(インタラクティブな簡易アプリが作れる)
- GPUありインスタンスのストレージ増(40GB-> 360GB)
- Python3/ GPUランタイム対応