はじめに
こんにちは。機械学習初学者です。
今回はAidemyさんの「AIアプリ開発講座」を受講し、その成果物として簡単なアプリの開発を行いました。
テーマは「猫の種類判別」です。
参考にしたサイト
参照1:ねこと画像処理 part 3 – Deep Learningで猫の品種識別
参照2:ネコと犬の種類判別器を作ってみた
開発環境
・Google Colaboratory
ほぼ全編にわたってGoogle Colaboratoryにて開発を行いました。
パソコンとの画像のやり取りはGoogle Driveとの連携が簡単ですので、まずは連携させておきます。
【Google Colaboratory】Google ドライブにマウントし、ファイルへアクセスする方法
from google.colab import drive
drive.mount('/content/drive')
データセットの活用
オックスフォード大学により公開されている既存のデータセット"The Oxford-IIIT Pet Dataset"を使います。
猫については、12品種の画像がそれぞれ約200枚ずつ収められています。
今回は、このデータセットに追加して"三毛猫"の画像のみは自分で収集したいと思います。
画像のスクレイピング
"三毛猫"をキーワードに画像を収集します。
画像のスクレイピングには、Pythonライブラリのicrawlerを用いました。
Google Colaboratoryでは、pipからインストールするだけで簡単に使用できます。
以下のコマンドは、検索エンジンbingでの検索結果から画像の収集をするプログラムです。
pip install icrawler
from icrawler.builtin import BingImageCrawler
words = ["三毛猫"]
for wotd in words:
crawler = BingImageCrawler(storage={"root_dir": "./drive/MyDrive/Images/"}) #保存先の指定
crawler.crawl(keyword = word, max_num=400)
icrawlerによるスクレイピングはmax_numで最大の画像取得枚数を指定できますが、エラーの発生などがあると実際の取得枚数がその分減少します。
また、取得後の画像の選別もしたいこともあり、max_numは多めに設定しました。
最終的に、ほかの画像と同様の200枚程度になるように選別しています。
データの保存
収集した画像データは、Google Drive内に種別ごとのフォルダを作成して保存しておきます。
既存の"The Oxford-IIIT Pet Dataset"内にある12品種に加えて、「Mike」フォルダを追加しました。
水増し関数の作成
後の機械学習の検証をより多くの画像で行うため、集めた画像の水増しを行います。
画像の水増しにはPythonのライブラリの一つであるOpenCVの機能を用いました。
元画像を加工した画像を作り出し、これを検証画像に加えることで、画像の量を数倍に増やします。
今回は、回転(30度、‐30度)、閾値処理、ぼかし、モザイク、膨張、左右反転の処理を行うことで、画像の枚数を8倍に増やします。

例)元画像(上段左端)に対して、
上段左から、30度回転、-30度回転、閾値処理、
下段左から、ぼかし、モザイク、膨張、左右反転 の処理を行った画像
import numpy as np
import os
import matplotlib.pyplot as plt
import cv2
def make_image(input_img):
img_size = input_img.shape
filter_one = np.ones((3,3))
#回転用
mat1 = cv2.getRotationMatrix2D((img_size[1]/2, img_size[0]/2), 30, 1)
mat2 = cv2.getRotationMatrix2D((img_size[1]/2, img_size[0]/2), -30, 1)
#水増しメソッドに使う関数
fake_method_array = np.array([
lambda image: cv2.warpAffine(image, mat1, [img_size[1], img_size[0]]),
lambda image: cv2.warpAffine(image, mat2, [img_size[1], img_size[0]]),
lambda image: cv2.threshold(image, 100, 255, cv2.THRESH_TOZERO)[1],
lambda image: cv2.GaussianBlur(image, (5, 5), 0),
lambda image: cv2.resize(cv2.resize(image, (img_size[1] // 5, img_size[0] // 5)),(img_size[1], img_size[0])),
lambda image: cv2.erode(image, filter_one),
lambda image: cv2.flip(image,1),
])
images = []
for method in fake_method_array:
faked_img = method(input_img)
images.append(faked_img)
return images
データの準備
Google Drive上の画像データに水増し関数を適用して、メモリ上に画像データ群を作成します。
データセット"The Oxford-IIIT Pet Dataset"の画像やicrawlerで収集した画像は大きさがまちまちですので、画像サイズを256×256にリサイズしています。
データの準備は、以下の手順で実施します。
データ読み出し
↓
リサイズ
↓
水増し関数の適用
↓
ラベリング
※入力画像の大きさを合わせるためcv2.resize()を行いますが、最初処理を実行した際にエラーが発生しました。
確認したところデータセットの一部の画像が<class 'NoneType'>となっていたのが原因だったようです。
以下の画像は<class 'NoneType'>でしたので、あらかじめ手動で画像を削除しておきました。
Abyssinian_34.jpg
Egyptian_Mau_139.jpg
Egyptian_Mau_145.jpg
Egyptian_Mau_167.jpg
Egyptian_Mau_177.jpg
Egyptian_Mau_191.jpg
import glob
import os
img_dir = "/content/drive/MyDrive/Images_Cats/"
# 画像フォルダ(猫の種別)を取得
folders = os.listdir(img_dir)
cat_kind_list = ("Abyssinian","Bengal","Birman,","Bombay","British_Shorthair","Egyptian_Mau","Maine_Coon","Mike","Persian","Ragdoll","Russian_Blue","Siamese","Sphynx")
x = []
y = []
label_num = 0
# 画像フォルダ分の繰り返し
for cat_kind in cat_kind_list:
cat_file_list = glob.glob(img_dir + cat_kind + "/*.jpg")
# 画像数分の繰り返し
for cat_file in cat_file_list:
cat_img = cv2.imread(cat_file)
# 画像サイズを256x256にする
resize_img = cv2.resize(cat_img, (256, 256))
resize_img = cv2.cvtColor(resize_img,cv2.COLOR_BGR2RGB)
# 画像の水増し
doubling_img = make_image(resize_img)
x = x + doubling_img
# ラベル付与
for i in range(len(doubling_img)):
y_tmp = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 ,0]
y_tmp[label_num] = 1
y.append(y_tmp)
label_num =label_num + 1
続いて、準備した画像データを「訓練用」と「検証用」に分けます。
import numpy as np
x = np.array(x)
y = np.array(y)
# データの並び替え(乱数を使用)
np.random.seed(42)
rand_index = np.random.permutation(np.arange(len(x)))
x = x[rand_index]
y = y[rand_index]
# データの分割(8割を「訓練用」の画像、2割を「検証用」の画像とする)
x_train = x[:int(len(x)*0.8)]
y_train = y[:int(len(y)*0.8)]
x_test = x[int(len(x)*0.8):]
y_test = y[int(len(y)*0.8):]
これにより、
水増し後の計16730枚の画像データから、
「訓練用」データ・・・13384枚
「検証用」データ・・・3346枚
を準備することができました。
モデルの学習(VGG16の転移学習)
モデルの学習には、VGG16の転移学習を用います。
転移学習とは、モデルを1から学習させると非常に多くの時間がかかるため、すでに学習済みのモデル(VGG16)を使用して、一部のみを学習しさせなおす手法のことをいいます。
転移学習については、以下の画像の引用元や参考のサイトの説明がわかりやすかったです。
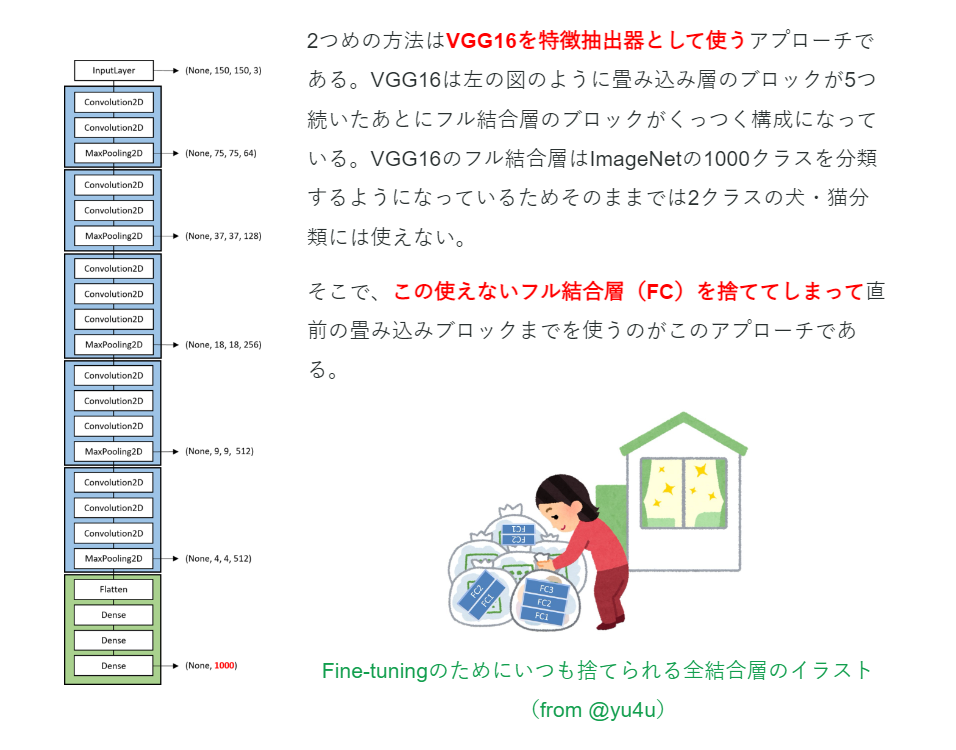
画像の引用元:VGG16のFine-tuningによる犬猫認識 (2)
参考:少ない画像から画像分類を学習させる方法(kerasで転移学習:fine tuning)
以下が学習用のコードです。
バッチサイズ:100
エポック数:100
としています。次のサイトを参照しました。
参考:GPUを使ってVGG16をFine Tuningして、顔認識AIを作って見た
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
# VGG16のロード。include_top=FalseとしてFC層は捨てる。
input_tensor = Input(shape=(256, 256, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# 追加する全結合層(FC層)の記述。出力を13次元(猫の種別の数)に指定。
#---------------------------
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(rate=0.5))
top_model.add(Dense(128, activation='relu'))
top_model.add(Dense(13, activation='softmax'))
#---------------------------
# モデルの連結。VGG16に上で記述した全結合層をドッキングさせて新しいモデルとする。
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
print(model.summary())
# 重みの固定。モデルのどの層までの重みを変化させないか(=どの層から学習させるか)を指定。(今回は19層まで固定)
for layer in model.layers[:19]:
layer.trainable = False
# 他クラス分類を指定して、モデルをコンパイルする。
model.compile(loss='categorical_crossentropy',
optimizer='adadelta',
metrics=['accuracy'])
# 用意した画像でモデルの学習を実施。batch_sizeでサブセットのデータ数を、epochsで学習の繰り返し回数を指定。
history = model.fit(x_train, y_train, batch_size=100, epochs=100, validation_data=(x_test, y_test))
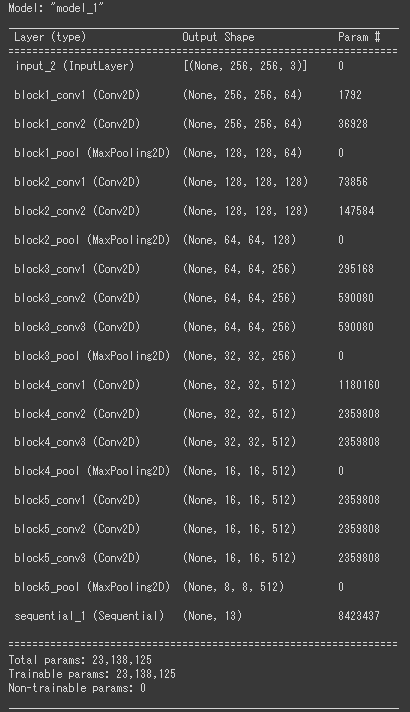
上記で作成したモデルのレイヤー構成:
import matplotlib.pyplot as plt
plt.plot(history.history['accuracy'], label='acc', ls='-', marker='o')
plt.plot(history.history['val_accuracy'], label='val_acc', ls='-', marker='x')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.suptitle('model', fontsize=12)
plt.legend()
plt.show()
学習結果は以下の通りです。
所要時間:114~120s / 1epoch
最終スコア:loss: 1.6492 - accuracy: 0.4511 - val_loss: 1.7999 - val_accuracy: 0.4295
学習経過グラフ:
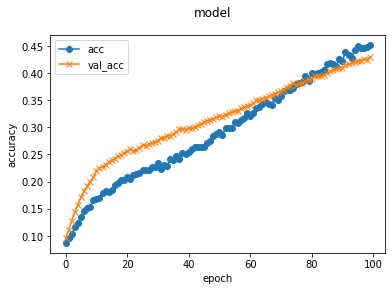
正答率42.95%です。
10エポック目ぐらいからあまり伸びないな、と感じていましたが、どうやらその通りのようでした。
10~100エポックではほぼ直線的に上昇しているので、エポックを増やせばまだ伸びそうな気はしますが…改善の余地はかなり多そうです。
なにはともあれ、Google Colaboratoryとの接続が切れないうちに学習済みモデルを保存します。
以下のように、cat_vgg16_model1.h5と名称を付けて保存しました。
#resultsディレクトリを作成
result_dir = '/content/drive/MyDrive/results'
if not os.path.exists(result_dir):
os.mkdir(result_dir)
# 重みを保存
model.save(os.path.join(result_dir, 'cat_vgg16_model1.h5'))
モデルの改良
正答率4割とかなり低かったので、改良できないかと試行錯誤しました。
その結果、「重みの固定」で指定するlayer数を変更すると、正答率が格段に上昇することがわかりました。
重みの固定の設定のみを変更(バッチサイズ=100,エポック数=100で固定)して、学習させた結果は以下の通りです。
モデルの改良1:重みの固定layerを16層までに変更
for layer in model.layers[:16]:
layer.trainable = False
所要時間:120~125s / 1epoch
最終スコア:loss: 0.8517 - accuracy: 0.7170 - val_loss: 1.0832 - val_accuracy: 0.6491
モデルの改良2:重みの固定layerを11層までに変更
for layer in model.layers[:11]:
layer.trainable = False
所要時間:144s~145s / 1epoch
最終スコア:loss: 0.4603 - accuracy: 0.8450 - val_loss: 0.6616 - val_accuracy: 0.7887
学習経過グラフ:
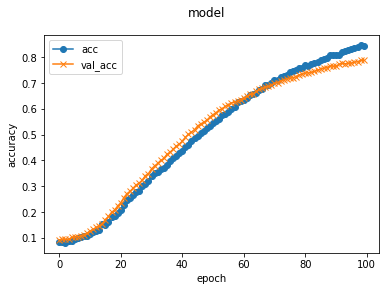
改良により、正答率8割近くまで伸ばすことができました。
最初はVGGの特徴量をほぼそのまま使用する(19層まで固定)と設定していましたが、中層以降の特徴量から計算しなおさせて、用意した画像に特化させるようにしたことが功を奏したようです。
ただし、学習し直すlayerが増えたためにかかる時間もかなり長くなってきています。
一長一短ですね。
改良後モデルの動作確認
気になったので、出来たモデルで遊んでみました。
検証用に作成した全画像をモデルに投入して、どのような判定ができたかのマトリックスを作成してみます。
import numpy as np
from tensorflow.keras.models import Sequential, load_model
# 学習済みのモデルを用意する。
model = load_model('/content/drive/MyDrive/results/cat_vgg16_model_v2.h5')
classes = ["Abyssinian","Bengal","Birman,","Bombay","British_Shorthair","Egyptian_Mau","Maine_Coon","Mike","Persian","Ragdoll","Russian_Blue","Siamese","Sphynx"]
# 画像を一枚渡して、識別する関数
def pred_cats(img):
pred = model.predict(np.array([img]))
return pred
#結果用マトリックスの構築
score_matrix = [[0] * 13 for i in range(13)]
# 検証用に使用した写真をモデルに渡して予測させる
for i in range(3345):
img = x_test[i]
x_class = np.argmax(pred_cats(img))
y_class = np.argmax(y_test[i])
#予測結果をマトリックスに加算
score_matrix[y_class][x_class] += 1
print(score_matrix)
#正答率を表示させる
#20回以上間違えた猫種を「間違いやすい猫種」として表示させる
for i in range(13):
cat_kind = classes[i]
sum_img = sum(score_matrix[i])
wrong_cat_list = []
if sum_img == 0:
test_acc = 0
else:
test_acc = score_matrix[i][i] / sum_img
for n in range(13):
if 20 < score_matrix[i][n] < score_matrix[i][i]:
wrong_cat_list.append(classes[n])
print(cat_kind + ":" + str(score_matrix[i]))
print("正答率:" + str(format(test_acc * 100, ".2f")) + "%")
print("間違いやすい猫種:" + str(wrong_cat_list))
print("")
結果はこんな感じ。すぐ終わると思いましたが、結構時間がかかりました。(30分以上)
Abyssinian:[184, 28, 0, 2, 2, 1, 12, 14, 0, 4, 5, 2, 28]
正答率:65.25%
間違いやすい猫種:['Bengal', 'Sphynx']
Bengal:[22, 198, 0, 1, 6, 22, 8, 2, 0, 0, 2, 0, 5]
正答率:74.44%
間違いやすい猫種:['Abyssinian', 'Egyptian_Mau']
Birman,:[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
正答率:0.00%
間違いやすい猫種:[]
Bombay:[6, 1, 0, 238, 0, 0, 2, 0, 1, 1, 4, 4, 0]
正答率:92.61%
間違いやすい猫種:[]
British_Shorthair:[7, 4, 0, 3, 219, 2, 1, 2, 3, 2, 26, 1, 2]
正答率:80.51%
間違いやすい猫種:['Russian_Blue']
Egyptian_Mau:[10, 24, 0, 1, 2, 219, 3, 1, 0, 0, 1, 0, 5]
正答率:82.33%
間違いやすい猫種:['Bengal']
Maine_Coon:[17, 14, 0, 1, 0, 4, 232, 7, 3, 13, 1, 0, 2]
正答率:78.91%
間違いやすい猫種:[]
Mike:[10, 5, 0, 0, 1, 0, 4, 205, 0, 28, 2, 13, 2]
正答率:75.93%
間違いやすい猫種:['Ragdoll']
Persian:[2, 1, 0, 3, 1, 1, 17, 1, 264, 7, 1, 0, 1]
正答率:88.29%
間違いやすい猫種:[]
Ragdoll:[1, 0, 0, 0, 1, 0, 7, 12, 5, 273, 0, 13, 0]
正答率:87.50%
間違いやすい猫種:[]
Russian_Blue:[9, 4, 0, 14, 59, 1, 0, 4, 0, 4, 179, 0, 5]
正答率:64.16%
間違いやすい猫種:['British_Shorthair']
Siamese:[3, 2, 0, 1, 1, 0, 3, 4, 0, 9, 5, 214, 17]
正答率:82.63%
間違いやすい猫種:[]
Sphynx:[19, 2, 0, 3, 2, 3, 3, 12, 1, 3, 4, 24, 213]
正答率:73.70%
間違いやすい猫種:['Siamese']
正答率が一番低かったのは、意外にもロシアンブルーで、ブリッティッシュショートヘアと間違える率がかなり多いようでした。両者は顔の形は違いますが、色合いは良く似ていますね。
あと、検証用の画像には何故かバーマンの画像が一つもなかったようです。(乱数のせい…?)
いくつか画像を投入して動作を見てみましたが、全く検証されなかったおかげで判定はひどいもので、30枚見ましたが正答は1枚もありませんでした。
しっかり全身が映っていても全然ダメ↓

モデルを実装したアプリの作成
Birmanが判定できない問題はあるものの、ウェブアプリとして実装します。
flaskを用いて作成し、herokuにデプロイしました。ここら辺は説明割愛します。
実装後のアプリは以下の通り。
感想
かなり時間がかかってしましたがなんとかアプリの作成まで漕ぎつけることができてよかったです。
プログラミングなど全くやったことのない状態からのスタートでしたので、わからない点・躓く点もかなり多かったです。(正直今も多いけど…)
Aidemyさんの教材やいくつかの参考書のおかげでなんとかかんとか最初の一歩を踏み出せた感じです。
何はともあれ最初の一歩は踏み出せたので、これからさらに勉強を続けていきたいと思います。