はじめに
前にアプリの勉強しようと思った際に、本のバーコード使って管理するアプリを見かけました。
最近物体検出使ってみたので、バーコードを使わないで物体検出とOCR(文字認識)使ってできればと思い、わからない部分はchatGPT使いながら形だけやってみました。
やることは以下のような画像を入力して、各本の情報(タイトル、著者とか)をcsvで出力することです。


記事の流れ
-
前置き
1.1 画像中の物体検出
1.2 文字認識
1.3 図書データベースにて検索 -
実装
2.1 文字認識の関数化
2.2 図書データベース検索の関数化
2.3 YoLov7のdetect.py編集、実行
1. 前置き
それぞれについて動作確認のために簡単なコード動かしたので、それの内容とかです。
1.1 画像中の物体検出
最近読んだ本でSSD詳しく解説してあったのでそれにしようと思い一から学習させたり、サイト見ながらファインチューニング試したりしたのですが、最終的な精度がどうしてもイマイチで、結局前に扱ったYoLov7を使ってここの手順は処理しました。
今回は本棚に並んでいる本想定で、学習や検証データはすべて背表紙の画像で行ってます。
YoLov7を使った物体検出は以前投稿した内容とほぼ同じなので細かい手順は割愛します。
(リアルタイムでYOLOv7動かして小銭の合計金額を表示する)
SSD参考
【物体検出】SSD(Single Shot MultiBox Detector)とは
SSDファインチューニング(外部サイト)
PyTorch 新たなクラスの物体検出をSSDでやってみる
1.2 文字認識
文字認識(OCR)のためのライブラリやAPIは複数あり、Tesseract-ocr, Paddle-ocrあたりも試しましたが、結局Google Cloud Vision APIが一番使いやすく、精度もいいのでそれを使いました。
再学習させたり、文字の向きや言語の種類などを気にしなくても勝手にいい感じに検出してくれるので流石だなという感じです。
月あたり1000回までのAPI呼び出しは無料で、以降もかなり安く使えたと思います。
また登録してから3カ月間使える300ドルのクレジットもあるのでお金は気にしなくて大丈夫そうです。
文字認識概要記事
【2021年版】文字検出ってなんですか?
Google Cloud Vision導入参考
Google Cloud Vision APIを使ってみた
Tesseract-ocr参考
PythonとTesseract OCRで文字認識
Paddle-ocr, Easy-ocr参考
【PaddleOCR】Pythonで簡単に日本語OCR_その2(exe化のおまけつき)
導入は上記記事や公式ページを参考にしながら行い、画像に対して文字認識をしてみます。
日本語表示するにあたりopencvだとだめなのでPILで書いてます。
# 検出文字とBBox表示
from google.cloud import vision
from google.oauth2 import service_account
from PIL import Image, ImageDraw, ImageFont
import io
# APIキーのパス
key_path = "key.json"
# 画像上に文字描画するためのフォント
font_path = "C:\\Windows\\Fonts\\meiryo.ttc" # Windowsの場合のMeiryoフォントのパス
# 初期化
credentials = service_account.Credentials.from_service_account_file(key_path)
client = vision.ImageAnnotatorClient(credentials=credentials)
# 画像のパス
image_path = '10.jpg'
# 画像の読み込み
with open(image_path, 'rb') as image_file:
content = image_file.read()
image = vision.Image(content=content)
# テキスト検出の実行, text_annotation情報の取得
response = client.text_detection(image=image)
texts = response.text_annotations
# PILで画像を読み込む
pil_image = Image.open(io.BytesIO(content))
draw = ImageDraw.Draw(pil_image)
font = ImageFont.truetype(font_path, 70) # 日本語フォントのパスを指定, 70:文字サイズ
# 最初のアノテーションは画像全体のテキストを含む。2番目以降のアノテーションで回す。
for text in texts[1:]:
# BBoxの座標を取得
vertices = [(vertex.x, vertex.y) for vertex in text.bounding_poly.vertices]
# BBoxを画像に描画
draw.polygon(vertices, outline='blue')
# テキストを画像に描画 (座標は適当に調整)
text_position = (vertices[0][0] - 50, vertices[0][1] - 70)
draw.text(text_position, text.description, font=font, fill="blue")
# 認識結果を実行結果に表示
print(f"Text: {text.description}")
print(f"Bounding Box: ({vertices[0][0]}, {vertices[0][1]}), ({vertices[1][0]}, {vertices[1][1]}), ({vertices[2][0]}, {vertices[2][1]}), ({vertices[3][0]}, {vertices[3][1]})")
print()
# 画像を表示
pil_image.show()
入力画像

出力
Text: 物体
Bounding Box: (1191, 395), (1696, 388), (1699, 623), (1194, 630)
Text: 検出
Bounding Box: (1704, 389), (2235, 382), (2238, 616), (1707, 623)
Text: GAN
Bounding Box: (2286, 381), (2865, 373), (2868, 608), (2289, 616)
Text: オート
Bounding Box: (1154, 647), (1718, 638), (1722, 888), (1158, 897)
Text: エンコーダー
Bounding Box: (1709, 638), (2921, 618), (2925, 868), (1713, 888)
Text: 、
Bounding Box: (2891, 619), (2927, 618), (2931, 867), (2895, 868)
Text: 画像
Bounding Box: (1128, 932), (1726, 921), (1731, 1185), (1133, 1196)
Text: 処理
Bounding Box: (1707, 922), (2337, 911), (2342, 1174), (1712, 1185)
Text: 入門
Bounding Box: (2321, 911), (2842, 902), (2847, 1166), (2326, 1175)
Text: PyTorch
Bounding Box: (1099, 1274), (1408, 1266), (1410, 1339), (1101, 1347)
Text: /
Bounding Box: (1394, 1267), (1446, 1266), (1448, 1338), (1396, 1339)
Text: TensorFlow2
Bounding Box: (1437, 1265), (1899, 1253), (1901, 1326), (1439, 1338)
Text: に
Bounding Box: (1914, 1253), (1978, 1251), (1980, 1323), (1916, 1325)
Text: よる
Bounding Box: (1980, 1252), (2110, 1249), (2112, 1321), (1982, 1324)
Text: 発展
Bounding Box: (1085, 1372), (1239, 1369), (1241, 1442), (1087, 1445)
Text: 的
Bounding Box: (1238, 1368), (1317, 1366), (1319, 1439), (1240, 1441)
Text: ・
Bounding Box: (1325, 1366), (1351, 1365), (1353, 1438), (1327, 1439)
Text: 実装
Bounding Box: (1370, 1365), (1533, 1361), (1535, 1435), (1372, 1439)
Text: ディープ
Bounding Box: (1525, 1362), (1788, 1356), (1790, 1429), (1527, 1435)
Text: ラーニング
Bounding Box: (1780, 1356), (2121, 1349), (2123, 1423), (1782, 1430)
Text: ■
Bounding Box: (2671, 1244), (2709, 1245), (2708, 1285), (2670, 1284)
Text: チーム
Bounding Box: (2726, 1244), (2867, 1247), (2866, 1288), (2725, 1285)
Text: ・
Bounding Box: (2881, 1247), (2921, 1248), (2920, 1288), (2880, 1287)
Text: カルポ
Bounding Box: (2915, 1248), (3056, 1251), (3055, 1291), (2914, 1288)
Text: ダウンロード
Bounding Box: (2674, 1373), (2880, 1376), (2880, 1410), (2674, 1407)
Text: サービス
Bounding Box: (2878, 1376), (3026, 1378), (3026, 1412), (2878, 1410)
Text: 付
Bounding Box: (3023, 1378), (3051, 1378), (3051, 1411), (3023, 1411)
Text: ・
Bounding Box: (2681, 2512), (2856, 2511), (2857, 2631), (2682, 2632)
Text: 秀和
Bounding Box: (2852, 2810), (3016, 2810), (3016, 2883), (2852, 2883)
Text: システム
Bounding Box: (3012, 2810), (3294, 2810), (3294, 2883), (3012, 2883)

細かく分割されてますが、なかなかの精度で問題なく検出できています。
1.3 図書データベースにて検索
本の情報の取得にはGoogle books APIを使います。
検索のための機能がたくさんあるようです。
paramsで検索条件指定したり、出版の新しい順で検索したりできます。
本のタイトルや、著者、金額、表紙の画像などなど取得できます。
Google Books API参考
Google Books APIの使い方~その1~
特に何かを登録したりインストールすることなく使うことができます。
# "ディープラーニング"でタイトル検索して結果を受け取る
import requests
import json
base_url = "https://www.googleapis.com/books/v1/volumes"
title = "ディープラーニング"
params = {
"q": f"intitle:{title}", # intitleで本のタイトルから検索
"printType": "books",
"maxResults": 10
}
response = requests.get(base_url, params=params)
if response.status_code == 200:
results = json.loads(response.text)
else:
results = None
# 最初の5冊の情報を表示
for i, item in enumerate(results["items"][:5]):
print(f"Title: {item['volumeInfo']['title']}")
print(f"Authors: {item['volumeInfo'].get('authors', ['N/A'])}")
print()
出力
Title: PythonとKerasによるディープラーニング
Authors: ['FrancoisChollet']
Title: ゼロから作るDeep Learning
Authors: ['斎藤康毅']
Title: 深層学習教科書 ディープラーニング G検定(ジェネラリスト)公式テキスト 第2版
Authors: ['岡田 陽介', '山下 隆義', '巣籠 悠輔', '藤本 敬介', '松井 孝之', '徳田 有美子', '猪狩 宇司', '工藤 郁子', '今井 翔太', '松嶋 達也', '瀬谷 啓介', '中澤 敏明', '松尾 豊', '江間 有沙']
Title: TensorFlowで学ぶディープラーニング入門
Authors: ['中井悦司']
Title: 今すぐ試したい!機械学習・深層学習(ディープラーニング)画像認識プログラミングレシピ
Authors: ['川島賢']
簡単に本の検索が行えました。
2. 実装
前置きのコードに諸々条件付けたり、使いやすくするために関数化して最終的にYoLov7のdetect.py関数の中に入れ込みます。
2.1 文字認識の関数化
図書データベースでの検索にあたり、文字認識結果に誤った情報があると検索しても出てこなくなるため、文字認識時の信頼度を取得できるようにし信頼度の高いものだけ使います。
また検索のためには本のタイトルだけあればいいので、変な文字(出版社名とか説明書きとか)拾わないようにします。
基本的には本のタイトルが一番大きい文字サイズで書かれていると思うので、検出されたBBoxの中でも一番大きいものを基準にしてそれに近いサイズの文字だけを使うようにしてます(BBox短辺での比較)。
また文字検出前に軽く画像のノイズ除去や輝度調整の画像処理してます。
その辺の処理の値は決め打ちで入れてるので実際の画像に応じて自動で調整できるようになればいいなと思いました。
(下記コードでコメントアウトした部分は、本のタイトルに加え、著者名の一部も頑張って取得するようにしてます。
ただ、この後のGoogle Books APIで検出ワード入れる際に"タイトル 著者名"の順番で文字が検出されていると結果が出るのに, "著者名 タイトル"だと結果出なかったりして、Google Books APIの検索の勝手がわからず、タイトルだけにしました。
この後のGoogle Books APIの段階ではこの著者情報はないものとしてのコードです。)
# 文字検出関数
from google.cloud import vision
from google.oauth2 import service_account
from PIL import Image, ImageDraw, ImageFont
import cv2
import numpy as np
import io
def extract_text_from_image(image_data, key_path="key.json"):
"""
画像からテキスト抽出
input1 image_data: 入力画像データ
input2 key_path: Google API キーのパス
return 検索テキスト
"""
#cho_center = (5000, 5000) # "著"BBox中心座標初期化
# 検索ワード初期化
search_text = ""
# 初期化
credentials = service_account.Credentials.from_service_account_file(key_path)
client = vision.ImageAnnotatorClient(credentials=credentials)
# ノイズ除去
image_data = cv2.GaussianBlur(image_data, (9, 9), 0)
# コントラスト調整
image_data = cv2.convertScaleAbs(image_data, alpha=1.5, beta=50)
# OpenCVの画像をPIL形式に変換
pil_image = Image.fromarray(cv2.cvtColor(image_data, cv2.COLOR_BGR2RGB))
# 画像をバイト形式に変換
byte_io = io.BytesIO()
pil_image.save(byte_io, format="JPEG")
content = byte_io.getvalue()
image = vision.Image(content=content)
# テキスト検出
response = client.document_text_detection(image=image)
# BBox短辺長とテキスト検出の信頼度を保持するための配列
short_sides_and_confidences = []
# responseの中から信頼度, BBox, text取得
for page in response.full_text_annotation.pages:
for block in page.blocks:
for paragraph in block.paragraphs:
for word in paragraph.words:
confidence = word.confidence # 信頼度スコア
bounding_box = [(vertex.x, vertex.y) for vertex in word.bounding_box.vertices] # BBox座標
word_text = ''.join([symbol.text for symbol in word.symbols]) # テキスト
if confidence >= 0.8: # 信頼度が0.8以上のものに対して処理
# BBoxの短辺長の計算
side1 = ((bounding_box[0][0] - bounding_box[1][0])**2 + (bounding_box[0][1] - bounding_box[1][1])**2) ** 0.5
side2 = ((bounding_box[1][0] - bounding_box[2][0])**2 + (bounding_box[1][1] - bounding_box[2][1])**2) ** 0.5
short_side = min(side1, side2)
short_sides_and_confidences.append((short_side, confidence, word_text, bounding_box))
#if word_text == '著':
# cho_bounding_box = bounding_box
# cho_center = ((cho_bounding_box[0][0] + cho_bounding_box[2][0]) / 2, (cho_bounding_box[0][1] + cho_bounding_box[2][1]) / 2)
# cho_short_side = short_side
if short_sides_and_confidences:
# 信頼度が0.8以上の短辺の中で最も長いものを特定
max_short_side = max(short_sides_and_confidences, key=lambda x: x[0])[0]
else:
max_short_side = None
for short_side, confidence, word_text, bounding_box in short_sides_and_confidences:
# BBox中心座標と"著"のBBox中心の距離
#box_center = ((bounding_box[0][0] + bounding_box[2][0]) / 2, (bounding_box[0][1] + bounding_box[2][1]) / 2)
#distance = ((cho_center[0] - box_center[0]) ** 2 + (cho_center[1] - box_center[1]) ** 2) ** 0.5
# 検出文字のBBox短辺が最大BBox短辺より15pxcel差以内ならその情報を検索ワードに追加
#if (distance < 100 and abs(short_side - cho_short_side) <= 30 and word_text != "著") or abs(max_short_side - short_side) <= 15:
if max_short_side - short_side <= 15:
search_text += word_text + " "
#著の両隣によくある[]を取り除く用
#search_text = search_text.replace("[", "").replace("]", "")
return search_text
2.2 図書データベース検索の関数化
テキスト検出結果を入力して、本の情報をデータフレームとして受け取れるような関数にします。
とりあえず本のタイトル、著者、値段、国、表紙画像を取得するようにしてます。
同じ書籍情報が重複してGoogle Books APIの中にあったりするので、重複してても検索ワードを含むタイトルが一件見つかったら検索終了するようになってます。
第二版とかの区別はできてません。
(もし同じようなタイトルで異なる書籍だった場合も片方だけ取得するような処理なので、区別するために著者情報も入れたかったです。)
# 書籍検索関数化済
import requests
import pandas as pd
def search_books(partial_title):
"""
検出したテキストを入力して、一致するタイトルの本の情報をデータフレームで返す
"""
base_url = "https://www.googleapis.com/books/v1/volumes"
query = f"intitle:{partial_title}"
params = {"q": query}
response = requests.get(base_url, params=params)
if response.status_code == 200: # 200は検索が成功しましたよ、の番号
results = response.json()
items = results.get('items', [])
books = []
found = False # 本が見つかったかどうかのフラグ
for item in items:
if found: # 本が見つかった場合、ループを抜ける
break
info = item.get('volumeInfo', {})
sale_info = item.get('saleInfo', {})
list_price = sale_info.get('listPrice', {})
image_links = info.get('imageLinks', {})
book = {
'title': info.get('title', '').lower(),
'authors': ", ".join(info.get('authors', [])).lower(),
'price': list_price.get('amount', 'N/A'),
'currency': list_price.get('currencyCode', 'N/A'),
'thumbnail': image_links.get('thumbnail', 'N/A')
}
books.append(book)
found = True # 本を見つけたのでフラグを更新
return pd.DataFrame(books)
else:
return None
2.3 YoLov7のdetect.py編集、実行
YoLov7のdetect.py関数と同じ階層に先ほど作った2つの関数を配置して、detect.pyにimportして使います。
物体検出BBoxの数だけfor文回してるところでBBox領域を切り取って、その領域に対して文字認識と本検索の関数いれてあげて、都度検索結果を最終DataFrameに追加していきます。
最後にそのデータフレームをcsv出力します。
他は元のままです。
import argparse
import time
from pathlib import Path
import cv2
import torch
import torch.backends.cudnn as cudnn
from numpy import random
import pandas as pd
from models.experimental import attempt_load
from utils.datasets import LoadStreams, LoadImages
from utils.general import check_img_size, check_requirements, check_imshow, non_max_suppression, apply_classifier, \
scale_coords, xyxy2xywh, strip_optimizer, set_logging, increment_path
from utils.plots import plot_one_box
from utils.torch_utils import select_device, load_classifier, time_synchronized, TracedModel
# 作った関数追加
from extract_text import extract_text_from_image
from books_googleapi import search_books
def detect(save_img=False):
source, weights, view_img, save_txt, imgsz, trace = opt.source, opt.weights, opt.view_img, opt.save_txt, opt.img_size, not opt.no_trace
save_img = not opt.nosave and not source.endswith('.txt') # save inference images
webcam = source.isnumeric() or source.endswith('.txt') or source.lower().startswith(
('rtsp://', 'rtmp://', 'http://', 'https://'))
# Directories
save_dir = Path(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok)) # increment run
(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Initialize
set_logging()
device = select_device(opt.device)
half = device.type != 'cpu' # half precision only supported on CUDA
# Load model
model = attempt_load(weights, map_location=device) # load FP32 model
stride = int(model.stride.max()) # model stride
imgsz = check_img_size(imgsz, s=stride) # check img_size
if trace:
model = TracedModel(model, device, opt.img_size)
if half:
model.half() # to FP16
# Second-stage classifier
classify = False
if classify:
modelc = load_classifier(name='resnet101', n=2) # initialize
modelc.load_state_dict(torch.load('weights/resnet101.pt', map_location=device)['model']).to(device).eval()
# Set Dataloader
vid_path, vid_writer = None, None
if webcam:
view_img = check_imshow()
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(source, img_size=imgsz, stride=stride)
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride)
# Get names and colors
names = model.module.names if hasattr(model, 'module') else model.names
colors = [[random.randint(0, 255) for _ in range(3)] for _ in names]
# Run inference
if device.type != 'cpu':
model(torch.zeros(1, 3, imgsz, imgsz).to(device).type_as(next(model.parameters()))) # run once
old_img_w = old_img_h = imgsz
old_img_b = 1
t0 = time.time()
# 全部の本のデータフレーム初期化
df_all = pd.DataFrame()
for path, img, im0s, vid_cap in dataset:
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
# Warmup
if device.type != 'cpu' and (old_img_b != img.shape[0] or old_img_h != img.shape[2] or old_img_w != img.shape[3]):
old_img_b = img.shape[0]
old_img_h = img.shape[2]
old_img_w = img.shape[3]
for i in range(3):
model(img, augment=opt.augment)[0]
# Inference
t1 = time_synchronized()
with torch.no_grad(): # Calculating gradients would cause a GPU memory leak
pred = model(img, augment=opt.augment)[0]
t2 = time_synchronized()
# Apply NMS
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms)
t3 = time_synchronized()
# Apply Classifier
if classify:
pred = apply_classifier(pred, modelc, img, im0s)
# Process detections
for i, det in enumerate(pred): # detections per image
if webcam: # batch_size >= 1
p, s, im0, frame = path[i], '%g: ' % i, im0s[i].copy(), dataset.count
else:
p, s, im0, frame = path, '', im0s, getattr(dataset, 'frame', 0)
p = Path(p) # to Path
save_path = str(save_dir / p.name) # img.jpg
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # img.txt
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if opt.save_conf else (cls, *xywh) # label format
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
if save_img or view_img: # Add bbox to image
label = f'{names[int(cls)]} {conf:.2f}'
plot_one_box(xyxy, im0, label=label, color=colors[int(cls)], line_thickness=1)
# 追加箇所(BBoxで画像領域を切り取って各関数を適用)
x1, y1, x2, y2 = map(int, xyxy)
cropped_img = im0[y1:y2, x1:x2]
extracted_text = extract_text_from_image(cropped_img)
print(extracted_text)
df = search_books(extracted_text)
df_all=pd.concat([df_all, df])
# Print time (inference + NMS)
print(f'{s}Done. ({(1E3 * (t2 - t1)):.1f}ms) Inference, ({(1E3 * (t3 - t2)):.1f}ms) NMS')
# Stream results
if view_img:
cv2.imshow(str(p), im0)
cv2.waitKey(1) # 1 millisecond
# Save results (image with detections)
if save_img:
if dataset.mode == 'image':
cv2.imwrite(save_path, im0)
print(f" The image with the result is saved in: {save_path}")
else: # 'video' or 'stream'
if vid_path != save_path: # new video
vid_path = save_path
if isinstance(vid_writer, cv2.VideoWriter):
vid_writer.release() # release previous video writer
if vid_cap: # video
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
else: # stream
fps, w, h = 30, im0.shape[1], im0.shape[0]
save_path += '.mp4'
vid_writer = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
vid_writer.write(im0)
df_all.to_csv("df.csv", index=False) # 追加
if save_txt or save_img:
s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
#print(f"Results saved to {save_dir}{s}")
print(f'Done. ({time.time() - t0:.3f}s)')
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='yolov7.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='inference/images', help='source') # file/folder, 0 for webcam
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--no-trace', action='store_true', help='don`t trace model')
opt = parser.parse_args()
print(opt)
#check_requirements(exclude=('pycocotools', 'thop'))
with torch.no_grad():
if opt.update: # update all models (to fix SourceChangeWarning)
for opt.weights in ['yolov7.pt']:
detect()
strip_optimizer(opt.weights)
else:
detect()
関数の編集が終わったらdetect関数を実行します。"--conf-thres"でdetectionの信頼度の閾値(デフォルトは0.25)つけないと本以外も本として検出されてしまいます。
本自体は結構な信頼度で検出されてたので0.8と高めに設定してます。
testフォルダーに読み込ませる画像一枚だけいれて実行します。
!python detect.py --weights runs/train/book_result2/weights/best.pt --source book_data/images/test --name test_result --conf-thres 0.8
最初に貼った画像に対しての結果
- 物体検出結果

- 各BBoxの検出テキスト
詳解 ディープ ラーニング
Tableau 徹底 入門
Python 機械 学習 深層 学習 アプリ つくり
Python による データ 分析 入門
Kaggle データ 分析 技術
物体 検出 GAN オート エンコーダー 画像 処理 入門
アルゴリズム 実技 検定
前 処理 大全
-
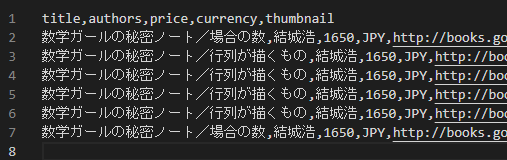
最終的な出力(csv)
タイトル、著者、金額、国、表紙画像のリンク
-
参考:物体検出信頼度閾値設定しない場合

他の画像の実行結果貼って終わりにします。
画像によって前処理部分変えたりしてます。
物体検出の学習時、角度のデータ拡張してるので横向きでも検出でき、APIの文字認識も機能してくれてます。
今回タイトルとることだけしか考えていないのでシリーズ物とかは区別つかなかったり、タイトルを綺麗に全部高精度で認識するのは難しいため、一部だけ検出されて違う書籍情報取得してしまったりとかもあります。
文字検出条件ちゃんとすればもう少し精度よく本の検索できそうです。
- 物体検出結果

- 各BBoxの検出テキスト
詳解 3 次 元 点
物体 画像 認識 系列 データ 処理 入門
Deep Learning
Web サービス スマホアプリ プロトタイプ
PyTorch に よる 発展 ディープ ラーニング
ゼロ から 作る Deep Learning
Python つくる ゲーム 開発 入門 講座
- 最終的な出力(csv)

- 物体検出結果

- 各BBoxの検出テキスト
数学 ガール 結城
数学 ガール
数学 ガール
数学 ガール
数学 ガール
数学 ガール 結城
- 最終的な出力(csv)
おわりに
今回のコードは物体検出に加え条件つけてテキスト抽出したり、本の情報をAPI使ってもってきたりするのでそこそこの処理時間がかかり、リアルタイムで行うとかは厳しいです。
もう少し効率的な処理ができたり、無駄な部分もあるかもしれませんがとりあえずやってみたかった処理にはなったのでよかったです。
SSDで上手くいかなかった点はまた改めて触ったときに確認できればと思います。