はじめに
2年目社員の川波(@dcm_ryou-kawanami)です。
この記事は、NTTドコモ R&D Advent Calendar 2021の14日目の記事になります。
我々 NTTドコモ R&Dでは通信技術はもちろんのこと、自然言語処理,画像処理,ビッグデータ解析,クラウド,IoTといった様々な先端技術を学んでおり、若手社員から中堅社員まで日々自己研鑽を行っています。
習得した技術を業務で活かつつ、積極的に社外に発信していくための有志の取り組みとして始めたのがこちらのNTTドコモ R&D Advent Calendarになります。
今年度は運営としてNTTドコモ R&D Advent Calendar 2021の取りまとめを行っていますが、今年度投稿者は分野が幅広くギークで面白い人ばかりですのでぜひ他の記事も見ていただけると嬉しいです!
さて、今回の記事ではData Science Cafe #5 [1]で発表した内容をアップデートして文字検出のあれこれについて紹介していきたいと思います。
きっと読み終わる頃には「文字検出 完全に理解した!1」状態になっていることでしょう...!
 (文字検出データセット[ICDAR2015](https://rrc.cvc.uab.es/?ch=2&com=mymethods&task=1)より)
(文字検出データセット[ICDAR2015](https://rrc.cvc.uab.es/?ch=2&com=mymethods&task=1)より)
忙しい人向けのまとめ
4行でわかる「文字検出って何ですか?」
時間がない人向けにこの記事でお伝えしたいことを4行でまとめました!
- 文字認識を行う前段として、画像中の文字領域を1行で検出する必要がある
- そこで文字を検出するための方法として、
物体検出よりも文字に特化させた文字検出というタスクを解くためのモデルがある- 文字検出のポイント1:さまざまな形状の文字領域を検出できるため、文字認識の適用範囲を拡張することができる
- 文字検出のポイント2:文字以外の背景ノイズを除けるため、文字認識の精度向上に寄与する
この4行を見て理解できた方は「文字検出 完全に理解した!1」人の仲間入りです。

想定している読者
もっと記事を見てくれるというそこのあなた、ありがとうございます!
この記事で想定している読者は以下のような方です。
- 近年のOCR技術に興味がある人
- Deep LearningとComputer Visionに興味がある人
- タイトルを見て「文字検出ってなんですか?」と思った人
昨今では、文字検出もDeep Learningベースの手法が中心になっているので、Computer Visionの分野に興味がある人には物体検出以外にもこんなタスク・モデルがあったんだという感じで面白いかなと思います!(2年前の自分の感想)

画像中から文字情報を取得する
まず画像中の文字をデジタル情報としてどのように抽出するのかについて説明します。
基本的には、**「文字検出→文字認識の流れで画像中の文字情報を抽出する」**のが基本的な流れになります。
もっと詳しく説明すると、
-
画像には文字以外の領域も多く含まれているので、文字領域の座標を取得するために文字検出を行った後、その文字領域に対して文字認識を行うことで画像中の文字をデジタル情報として抽出します。
-
よって、文字検出と文字認識は別のタスクですが、画像中の文字をデジタル情報にする際には文字検出→文字認識の順に使用することになります。
-
ここで、文字認識側で1行の文字を認識することを想定しているため、文字検出で取得する文字領域も1行で取得するタスクになることに注意が必要です。
-
文字検出とは画像中から文字を検出するタスク・モデル -
文字認識とは画像中の文字を認識するタスク・モデル
-
-
この画像から文字をデジタル情報に変換する一連の流れのことを
OCRと呼びます。 -
また、最近では
文字検出・文字認識を同時にEnd2Endで行うDeep Learningベースのモデルが提唱されており、このタスク・モデルはText Spotting[3](※FOTS [5]の論文中で提唱)と呼ばれています。

文字検出と物体検出ってどう違うの?
Computer Vision(画像認識)の分野に詳しい人は
「物体検出とどう違うの?」
と思われるのではないかなと思います。
結論を言うと、**「文字検出は物体検出から派生したものであり、用途の観点で見るとほぼ同じ」**です。
しかし、近年ではより文字を検出することに特化したタスク・モデルが登場しています。
これについては、後半の『[文字検出手法の紹介] (#文字検出手法の紹介)』の見出しで触れていますのでもう少々お待ちください。
-
文字検出と物体検出の違い:
- 物体検出を文字を検出するために使うこともできるため、用途としてはほぼ同じ
- しかし物体検出よりもさらに文字に特化したタスク・モデルが文字検出である
-
文字に特化した点:
- さまざまな大きさ・形状を持つ文字を柔軟に検出できるようにした(以下のような例)
- 斜めに回転した文字
- アーチ状に曲がったような文字
- さまざまな大きさ・形状を持つ文字を柔軟に検出できるようにした(以下のような例)

文字検出の難しさ
物体検出と比べて文字検出が難しい点は以下のような点です。
-
文字の難しさ:
- 検出対象である文字が極端に大きかったり極端に小さかったりスケールが異なる
- 斜めに傾いたり回転している文字は特徴が異なる
- フォントやロゴなど多種多様である
- 横に長いような極端なアスペクト比がある [2]
 (文字検出データセット[ICDAR2015](https://rrc.cvc.uab.es/?ch=2&com=mymethods&task=1)より)
(文字検出データセット[ICDAR2015](https://rrc.cvc.uab.es/?ch=2&com=mymethods&task=1)より)
-
日本語ならではの難しさ:
-
英数字、記号に加え、ひらがな、カタカナ、漢字と文字の種類が多いため、学習データが大量に必要となります。 [2]- アルファベット大文字/小文字(52字)
- 記号(、。!@#$%^&*()など)
- ひらがな(46字)
- カタカナ(46字)
- 漢字(常用漢字のみで1945字)
-

(芸術新聞社より)
文字検出の歴史
**「ふむふむなるほど、次は文字の難しさを解消した最新のモデルが紹介されるんだな...」**と思った方、ちょっと待ってください。
誰かに**「文字検出ってなんですか?」**と聞かれた時、
**「最近ではこう言う文字検出のモデルがあってだね...」というアンサーだけだとちょっと弱い気がしませんか?
これでは「最新の文字検出は分かったけど昔はどうやったん?」**と突っ込まれた時に「うぅぅ...」となりかねません。
「そんなこと言うんだったら、もうちょっと昔の歴史も教えてくれよーーー!」
そんな方へ向けて、近年の文字検出に至るまでの歴史をまとめてみました。

-
基本的には、物体検出の派生系なだけあって、途中までは物体検出の歴史と同じです。
-
スライディングウィンドウ+局所特徴量を用いるSliding Window + MSER から Deep Learningが登場し、YOLOやSSDといったDeep LearningベースのOne-Shotモデルが登場した2015年あたりまでは物体検出のタスクを文字検出として応用させていただけなので、アーキテクチャも物体検出と同じものを使用しています。
(ちょっと詳しめの方向けの記事ですが、物体検出手法YOLOまでの歴史を知りたい方はこちらの記事が参考になるかもしれません。) -
新しいアーキテクチャを持つ文字検出手法が本格的に登場してきたのは、2015年に発表されたTextBoxes [4]あたりからです。このTextBoxesも物体検出手法のSSDを文字検出用に改良したものであり、この辺りから『文字検出の難しさ』の見出しで紹介した、文字特有の難しさに対処するモデルが台頭してきました。
-
近年では、傾いていることの多い文字に対応するべく、2017年に回転した斜めの文字領域を取得できるEAST [5]が登場し、2018年には、文字検出と文字認識を同じモデルでEnd2Endに同時に出力してしまうFOTS [6](Text Spottingモデル)まで現れました。2019年には湾曲した文字領域まで取得できるモデルであるCRAFT [7]が登場するなど、多種多様な発展が見られます。
-
これからの文字検出の注目分野としては、Youtubeの字幕のような**「画像を横断くらい横に長いアスペクト比の文字領域をどのように検出するのか」、アラビア文字のように絵に近く風景に溶け込んでいるような「多種多様な言語をどのように検出するのか」**といったところのようです。[7]
これからも発展し続ける文字検出に要チェックです!
文字検出手法の紹介
それでは簡単ではありますが最近の文字検出手法のうち気になる手法について紹介していきたいと思います。
今回紹介する文字検出手法3つは全てCVPR2で発表された手法です。
余談ですが、文字検出でTextというだけあって手法の名前に**"T"**がつくものが多いですね!
1. EAST [5]
まずはCVPR2017で発表されたEASTです。
屋外で撮影された画像中の文字は斜めに回転して傾いているような文字が多く、これによって文字以外の背景領域の画像が入ることが後段の文字認識の精度を悪化させる一つの要因になっていました。
EASTはそんな斜めに回転して傾いている文字領域を背景が入らないように、文字が斜めに傾いた状態のまま検出してくれるモデルです。

1.1. アーキテクチャ
- 特徴抽出を行うバックボーンはピクセル単位でのクラスを分類するセマンティックセグメンテーションのタスクで使われるFCNを採用しています。
- FCNを採用した理由は、論文中に明示的にはなかったのですが、画像中の文字は小さくて複雑なものが多いため、より小さくて複雑な文字でも検出できるようにピクセル単位のセグメンテーションベースのモデルを採用しているのだと思います。
- アーキテクチャからの出力は以下です。
- text score map: 文字領域である確率をピクセル単位のスコア付したマップ情報(Figure4. (a)(b))
-
text boxes: RBOX geometryを元に作成
- RBOX geometry: それぞれのピクセルからピンクの長方形の境界までの距離情報を書くチャネルとして用意(Figure4. (c)(d))
- text rotation angle: 水平線に対して文字領域を示すピンクの矩形が傾いている回転角を用意(Figure4. (e))
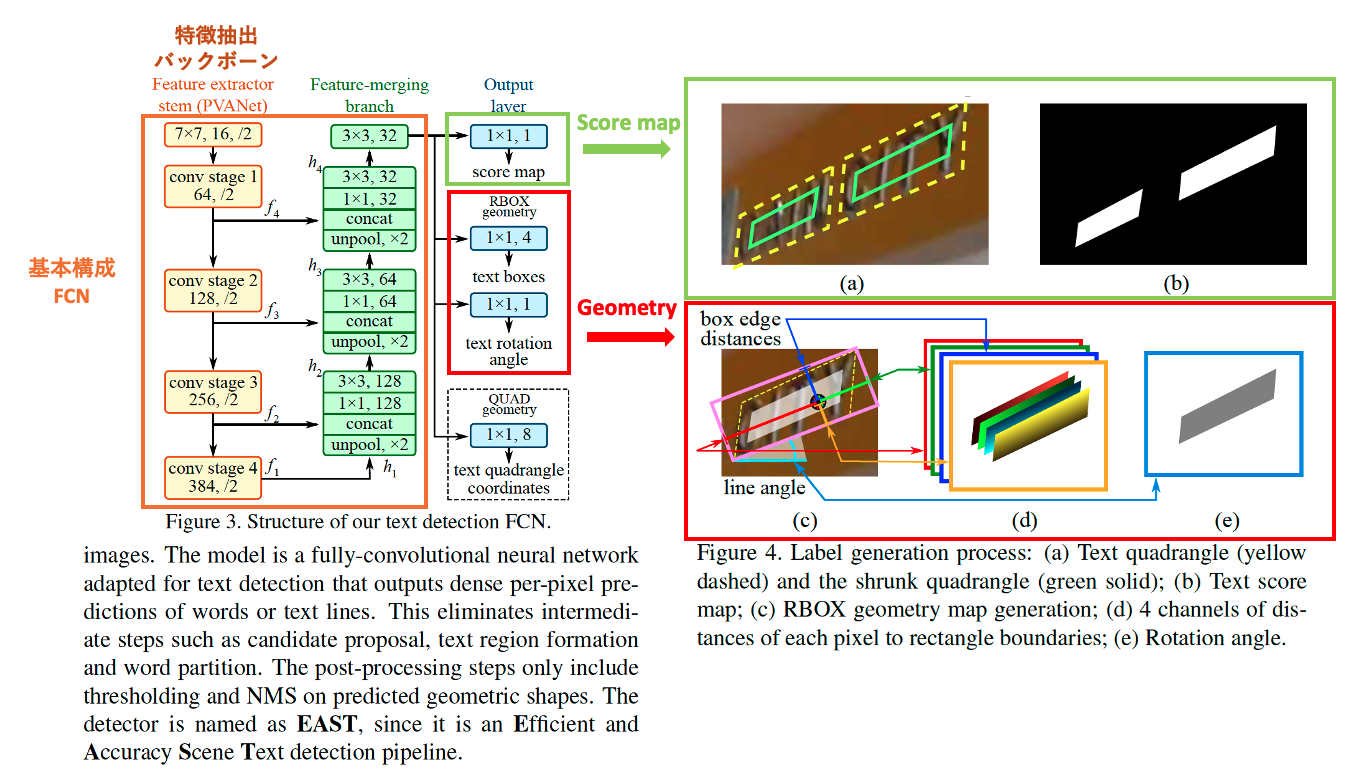
1.2. Loss
- LossではText Score Mapの項に加えて、Text Boxesが正解とどれだけ一致しているのかを示すIoUの項と、斜めに回転した文字に対応するために追加された回転角の項を入れていることが特徴的です。

1.3. モデル出力後の後処理
- モデルの出力である斜め文字領域の頂点を示す(x.y)座標4点の出力は、アーキテクチャの出力であるtext boxesとtext rotation angleを元に後処理で出力
2. FOTS [6]
次にCVPR2018で発表されたFOTSです。
これまでは文字検出モデルと文字認識モデルをそれぞれ組み合わせてOCRを行う方法が主流でした。
しかしこのFOTSは1つのモデルで文字検出+文字認識を同時に行うことのできるモデルになっています。
前半でもお話ししたText Spottingモデルです。
文字検出と文字認識をEnd2Endに学習するため、文字検出と文字認識に使う学習データがセットとして必要になってきますが、それぞれ独立していたものを1つのモデルで行えるようにしたというところが本手法のすごいところです。
1つのモデルにしたことで処理計算のロスを減らすこともできており、文字認識とのマルチタスクにすると文字検出の方も精度が向上したりと、処理時間の削減・精度向上を実現しています。
文字を検出するだけでなく、その場所の文字も1つのモデルで同時に予測している結果が右側の図から見てとれますね。

2.1. アーキテクチャ
- Faster RCNN構造のRoI部分が回転に対応(RoIRotate)し、文字認識のBranchを追加した構造になっています。
- RoIRotateにより、検出において回転したbboxから得られる畳み込みの特徴を認識のBranchで共有することができる。
- 回転矩形を水平に戻すときに、NW内でAffine変換してBilinear補間する方法を実現した。
- max-poolを使う方法だと出力特徴の長さが丸められてしまう欠点を、Bilinear補間により長さを可変することで解消し、これにより細長い文字にも対応できて認識でも使える特徴になった。

3. CRAFT [7]
最後にCVPR2019で発表されたCRAFTです。
文字の中には様々な形状の文字があり、斜めに回転しているものもそうですし、中には図に示すようなアーチ状の文字などもあります。
CRAFTは1文字単位のレベルで文字を検出し、後処理でくっつけることにより、いろんな向き・形状の文字を検出することのできるモデルです。

3.1. アーキテクチャ
アーキテクチャの基本構成はVGGベースのFCN

3.2. 文字の隙間を学習させる
- 1文字ごとに分けて認識する上で、文字間隔の狭い日本語に対応するために文字の隙間に注目するaffinity scoreを持ちます。
- また、1文字単位で細かい特徴を扱いたいのでheatmapを採用しています。

3.3. 弱教師あり学習の工夫
以下の2つのステップで弱教師学習を行うことにより文字単位のアノテーションでコストがかかるという課題を改善しています。
- 1stステップ:文字を合成した画像を生成してそのheatmapを事前学習
- 2ndステップ:実画像の単語単位のアノテーションを文字単位に分割してheatmapの正解データを作り追加学習

3.4. モデル出力後の後処理
- 推論時は1文字単位のBBoxを繋げて斜めに傾いた文字やアーチ状など文字など様々な形状の文字領域を出力します。
さいごに
本稿では「文字検出ってなんですか?」の質問にアンサーすべく、文字検出とは何かから最新手法までをご紹介してきました。
個人的にも分野的にも「OCRなんてオワコンじゃん、文字認識なんてMNISTでやってるし簡単でしょ」ということは全然なく、文字検出・文字認識を含めOCRはまだまだ発展している分野なのだということをお伝えできていれば嬉しい限りです!
また、NTTドコモ R&D Advent Calendar 2021はまだまだ続きますので、面白いと思っていただけたらこちらの**「タイトル右下の☆ボタン」**を押して購読していただき続きの記事をチェックしてみてください。
それではー!
参考
- [2] 日本語OCRはなぜ難しい?NAVERのエンジニアが語る、テキスト検出における課題と解決策
- [3] Paper with Code : Text Spotting
- [4] TextBoxes: A Fast Text Detector with a Single Deep Neural Network (AAAI2017)
- [5] EAST: An Efficient and Accurate Scene Text Detector (CVPR2017)
- [6] FOTS: Fast Oriented Text Spotting with a Unified Network (CVPR2018)
- [7] CRAFT: Character Region Awareness for Text Detection (CVPR2019)