(2020/12/3訂正:論文中の単語ConfidenceとConfidence score(信頼度スコア)について本項での表現が紛らわしかったのでその修正と合わせて大幅に追記させていただきました。)
本稿は,YOLO【You Only Look Once: Unified, Real-Time Object Detection】,を簡潔に紹介したものです.
本項では,YOLOの理解をする上で物体検出の歴史を辿りながら,わかりやすく記述することを心がけました.
また,YOLOの論文の内容を忠実にお読みになりたい方は「YOLOv3 論文訳」の方をご参照ください.
※専門性があると判断した用語については日本語訳せずそのまま記述するか,()の中に元の単語を記述しています.
YOLOの名前の由来
まず,YOLOという名前の由来から見ていきましょう.
YOLOは,
“Humans glance at an image and instantly know what objects are in the image, where they are, and how they interact. "
「人類は画像を一目見て,瞬時にそれが画像の中にある物体が何であるのか,どこにあるのか,どのように相互作用しているのかを理解する.」(YOLO原論文より引用)
というコンセプトの元提案された論文です.このコンセプトが実は名前の由来になっています.
YOLOというのはもともと"You only live once”「人生一度きり」の頭文字をとったスラングで,これをYOLOの著者であるJoseph Redmon氏は"You Only Look Once"「見るのは一度きり」という風に文字ってモデルを名付けました.つまり,このYOLOというモデルは人間のように一目見ただけで物体検出ができることが強みであるということです.
あーYOLOのJoseph Redmonこの人かhttps://t.co/MtGLXS8lYp
— CarNavy (@ryosanworld) February 5, 2019
物体検出手法の歴史
YOLOの凄さを語るには物体検出手法の歴史を知る必要があります.私は物体検出の歴史には以下の3つの時代があると考えています.
・【sliding window approach時代】:Deformable Parts Models(DPM)
・【region proposal method + deep learning時代】:R-CNN,Fast R-CNN
・【end-to-end時代】:Faster R-CNN, YOLO, SSD
以下でそれぞれを解説していきます.
※前提として補足しておくと,物体検出では物体らしい領域を見つける「検出」の部分と,見つけた領域に対して何の物体かの判断を行う「識別」の部分があり,これら2つから物体検出が成り立っています.この前提を踏まえて以下の説明を読んでいただくとよりわかりやすいと思います.
【sliding window approach時代】
Sliding window approachとは以下の図のように画像の左上から右下にかけてウィンドウをスライドしていき,画像のすべての領域をウィンドウで探索し検出していきます.そして逐一,ウィンドウ内の物体に対して識別処理を行い,対象物体であるかの判定を行う手法です.

【region proposal method+deep learning時代】
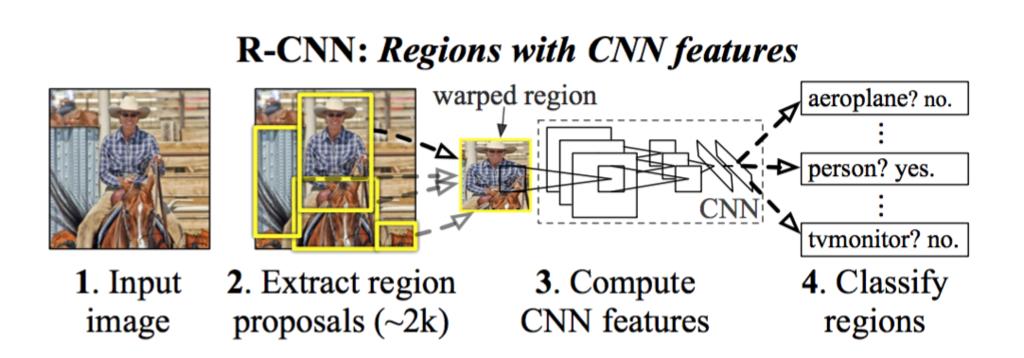
Region proposal methodとはR-CNNなどで使われている手法で,物体らしさ(Objectness)の高い領域を見つける手法であるSelective Searchなどがそれに当たります.画像中からRegion proposal methodで物体と思われる領域を検出して,それをdeep neural networkの入力として識別処理を行うという,2段構えで物体検出を行っていました.しかしRegion proposal methodで抽出した領域全てをdeep neural networkの入力とするため,かなりの時間がかかる手法でした.
【end-to-end時代 】
End-to-end時代では,前述したregion proposalがdeep neural networkの一つのレイヤーとして組み込まれた物体検出手法が登場しました.つまり,色々な物体を含んだ1枚の画像をdeep neural networkに入力するだけで検出と識別を一貫して行う夢のような物体検出手法として注目を集めました.最初から最後までdeep neural networkが処理を行ってくれるという意味でend-to-endな物体検出手法と呼ばれています.有名な文献の中ではFaster R-CNNが初めてこのend-to-endの物体検出手法を実装しました.end-to-endにすることにより物体らしさ(Objectness)の高い領域を抽出する際にもdeep neural networkによる最適化の恩恵が受けられ、多段構成のボトルネックも解消されるため,より高速で高精度な検出手法が可能となりました.そして,本稿のメイントピックであるYOLOもこのend-to-end時代の手法です.
YOLOとはどんな手法か
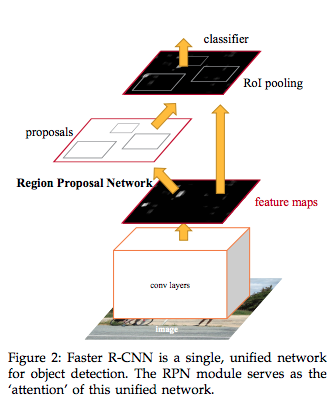
上記の前提を読んでいただいてようやくYOLOとは何かの説明ができます.End-to-end時代の先駆けとなったFaster R-CNNでは,図のようにRegion Proposal Networkという「検出」のためのネットワークを通った後にClassifierにて識別を行っています.つまり,「検出」の処理の後に「識別」の処理を行うような直列の処理構成になっており,このRegion Proposal Networkがボトルネックとなり処理速度の遅延を招いているのです.
そこでYOLOでは「検出」と「識別」を同時に行うことで,この処理時間の遅延を解消しようとしました.
YOLOの処理手順
ここではYOLOがどのように同時に「検出」と「識別」を行っているのかをアルゴリズムに基づいて解説します.
信頼度スコア
まず、YOLOの大まかな流れを知ってもらうため、Confidence score(信頼度スコア)からご紹介します。
このConficence scoreがYOLOが検出と識別を同時に行えることに大きく寄与しています。
以下、信頼度スコアを算出するための3ステップです。
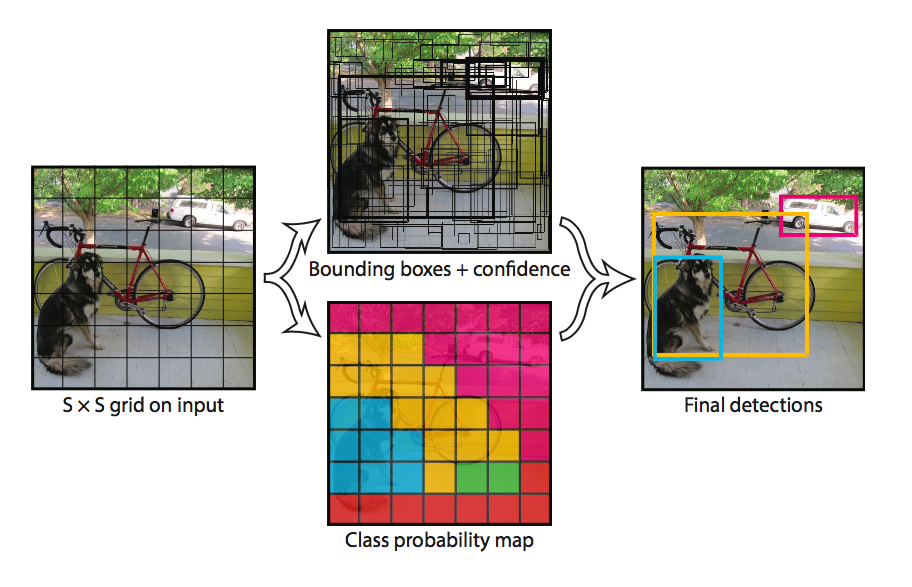
1.(図:左)
入力画像を$S×S$のグリッドセルと呼ばれる領域に分割します.
2.
①(図:中央上)
それぞれのグリッドセルについて$B$個(論文中では$B$=2個)のBoundhing box(以下BBox)と**Confidence(※まだ信頼度スコアではありません)**を推測します.
BBoxごとのConfidenceは以下の式で表されます.
$Confidence = {Pr(Object)*IOU^\truth_\pred}$
前項はBBoxの中にObject(物体)が含まれていたらそのBBoxは正確だと判断するためです。もしBBoxの中にObjectが存在しなければConfidence全体も0になります.また、後項は予測と正解のIOUの値が大きければ正確だと判断するためのものです.(※IOUの解説)
②(図:中央下)
それと同時にそれぞれのグリッドセルは$C$個の物体クラスそれぞれの条件付きクラス確率(conditional class probabilities)である$Pr(Class_i|Object)$を表します.
グリッドセルごとに$C$個のクラスだけ算出されるこちらのクラスの予測確率の値は以下の式で表されます.
$Pr(Class_i|Object)$
各クラスの予測確率を表しているため、全てのクラスの値を足し合わせると1になります.
3.(図:右)
その後,**①「各BBoxのConfidence」と②「各クラスの予測確率」をそれぞれ掛け合わせて,各BBox・各クラス毎のConfidence score(信頼度スコア)**を得ることができます.
よってConfidence score(信頼度スコア)の式は以下になります。
$Pr(Class_i|Object) * Pr(Object) * IOU^\truth_\pred = Pr(Class_i) * IOU^\truth_\pred$
この信頼度スコアは**「各BBoxのConfidence(BBoxに物体が入っていて正確に領域を囲えているかの正確さ)」と「各クラスの予測確率」**を意味しています.
つまりこの信頼度スコアに基づいてどのBBoxが対象とするクラスの物体を正確に検出しているかを判断するわけです.
アーキテクチャ
信頼度スコアの説明の中でもありましたが、信頼度スコアの算出には,
*「クラス予測確率」と「BBoxの位置情報4つ(xmin, ymin, width, height)」と「BBoxのConfidence1つ($Confidence = {Pr(Object)IOU^\truth_\pred}$)」
の要素が必要です。(※IOUの計算にBBoxの位置情報4つを使用します)
そこで、これらの要素を出力するためのYOLOのアーキテクチャを見てみましょう。
ここではYOLOのモデル(アーキテクチャ)に画像を入力した時どのような出力がされるのかが分かります。

いきなりだと、なんのことだかわからない。。。となると思うので順を追って説明していきます。
前述しましたがYOLOでは上記のアーキテクチャを用いて、入力画像から**「クラス予測確率」と「BBoxの位置情報4つ(xmin, ymin, width, height)」と「BBoxのConfidence1つ($Confidence = {Pr(Object)*IOU^\truth_\pred}$)」**を出力する必要があります。
①まず**「クラス予測確率」**ですが、
これは、グリッドセル内にいくつか存在するBBox(固定値)ごとにクラス数分出力する必要があります。
よって、
- クラスを予測するグリッドセル:S=7
- 1グリッドセルあたりのBBoxの数:B=2
- PASCAL VOCデータセットを使う場合のクラス数:C=20
という条件であれば全体として
$S * S * C = 7 * 7 * 20$
だけ出力されることになります。
②次に、**「BBoxの位置情報4つ(xmin, ymin, width, height)」と「BBoxのConfidence1つ($Confidence = {Pr(Object)*IOU^\truth_\pred}$)」**ですが、
これは、グリッドセル内にいくつか存在するBBox(固定値)ごとに4+1=5個出力する必要があります。
よって、
- クラスを予測するグリッドセル:S=7
- 1グリッドセルあたりのBBoxの数:B=2
- BBoxの位置情報4つ+Confidence1つ:5
という条件であれば全体として
$S * S * B5 = 7 * 7 * 25$
だけ出力されることになります。
③これらをまとめると、
$S * S * (B5+C) = 7 * 7 * (25+20) = 7 * 7 * 30$
の出力数になります。
実はこの7x7x30の行列(テンソル)がアーキテクチャからの出力に対応しています。
(※上図の最終出力層の数値とも一致すると思います)
ここまでで、信頼度スコアの計算方法とその計算に必要な要素の出力方法がわかっていればOKです。
学習・推論
最後に、学習時・推論時の流れです。先ほどアーキテクチャで説明した信頼度スコアに必要な要素をどう学習するのかというと、
学習時には、信頼度スコアを算出する上で必要な**「クラス予測確率」と「BBoxの位置情報4つ(xmin, ymin, width, height)」と「BBoxのConfidence1つ($Confidence = {Pr(Object)*IOU^\truth_\pred}$)」**の3要素を以下のようにそれぞれの要素を全てLossの項として学習しています。

その後、推論時には、このLossで学習されたモデルに基づいて3要素を出力し、その後、信頼度スコアが算出されるというわけです。
上記で説明したアーキテクチャと信頼度スコアを用いることで、学習・推論時において「検出」と「識別」を同時に行えているわけですね!
YOLOのアドバンテージとディスアドバンテージ
ここでYOLOのアドバンテージとディスアドバンテージを述べておきたいと思います.
アドバンテージ
1.シンプルなネットワーク構成で高速:Titan X GPUを用いて45fps,高速なバージョンであるFast YOLOだと150fps以上.他のリアルタイムシステムの2倍のmAP(mean average precision)を示す.
2.背景と物体の区別がしやすい:Fast R-CNNではRegion proposalで抽出した領域のみのコンテキストしか見れないため背景と判断すべき領域を間違うことがあったが,YOLOは画像全体を見るので、クラス(物体の種類)とその外観に関するコンテキスト情報を暗黙的にエンコード(暗号化)するので背景の間違いが少ない.当時トップの検出手法であったFast R-CNNと比較して,YOLOは半分以下の背景エラーであった.
3.一般化が可能:花などの自然の画像を学習させて,アート作品のような絵の画像でテストした場合,YOLOはDPMやR-CNNよりもはるかに優れている.
ディスアドバンテージ
1.最先端の手法と比較して精度が低い.
2.小さな物体の検出が困難.
【Abstract日本語訳】
最後にAbstractの日本語訳を示して終わりにしたいと思います.
我々は物体検出のための新しいアプローチであるYOLOを提案する.物体検出における先行研究は検出を行うためにclassifierを再利用(repurpose)する.代わりに,我々は空間的に分離されたbounding boxesと関連するclass probabilitiesへの回帰問題(regression problem)として物体検出を構成する.Single neural networkはある評価においてfull imageからbounding boxesとclass probabilitiesを直接予測します.全体のdetection pipelineがsingle networkなので,検出においてend-to-endで直接最適化することができる.
我々の統合されたアーキテクチャはかなり速い.我々のbase YOLO modelは45fpsのリアルタイムで画像を処理する.類似のnetworkバージョンであるFast YOLOは他のリアルタイム検出器(detector)の2倍のmAPを誇る一方で,155fpsという驚異的な速さで処理する.最先端の(state-of-the-art)検出システムと比較すると,YOLOはlocalization errorsをより多く発生させるが,背景においてfalse positivesを予測しうる.最終的にYOLOはとても一般的な物体の表現(representations)を学習する.自然画像(natural images)からアート作品などの他の領域(domain)まで一般化した時,YOLOはDPMやR-CNNを含む他の検出手法より優れている.
以上,YOLOを物体検出の時代背景と絡めて紹介しました.本稿ではNetworkなどの解説は行っていないので,そちらの方は別のサイトを参照お願いします.
本稿に度々出てくるIoU,mAPの説明は「【物体検出】mAP ( mean Average Precision ) の算出方法」へどうぞ.
P.S.
機械学習,画像認識,自動運転の情報を発信していくのでQiitaと twitterのフォローお待ちしております!お仕事はQiita Jobsまたは、TwitterのDMからお願いします.