1.前提知識
・機械学習の基礎
・オライリー『ゼロから作る Deep Learning』
・MLPシリーズ『画像認識』の物体検出の章
2.物体検出とは
多くの物体検出アルゴリズムの内容は、以下の三段階で分けられる。
①物体領域候補の提案
②検出物体のクラス分類
③領域の調整(回帰)
初学者向けの画像認識の実装例では「手書き文字の認識」がよく取り上げられるが、現実の画像においては、「物体が一つのみで全ての物体領域のサイズも同じ」ということは普通はありえない。そこで、1枚の画像の中で様々なサイズで写っている複数の物体を上手く切り出すバウンディングボックスを探し、クラス分類の問題に持ち込む必要がある。
愚直にやるならバウンディングボックスの位置を動かして全パターン探索するSliding Window法が考えられるが、工夫なく行うのでは非常に時間がかかることは容易に想像できる。
R-CNN、Fast R-CNNなどでは、似た特徴を持った小さい領域を統合させていくことで、物体が存在しそうな領域に当たりをつけるSelective Search(選択的検索法)という手法が用いられた。しかし、この手法では計算に冗長性があり、ボトルネックになっていた。
そこでFaster R-CNNでは、物体領域候補もCNNで検出するために**RPN(Region Proposal Network)**という別のネットワークを併用することで、End to Endな学習が可能になり、処理が高速化した。
以上のようなアーキテクチャが提案していたのは、**「バウンディングボックスを色々動かしていい感じの位置を探し出そう」という方針だったが、
その後登場したYOLO(You Only Look Once)とSSD(Single Shot Multibox Detector)では、「画像をグリッドで分割して、それぞれのグリッドに対して固定されたいくつかのバウンディングボックスの当てはまり具合を見てみよう」**という方針を採っている。
今回はこのSSDのアーキテクチャについて紹介していく。
参考
http://tech-blog.abeja.asia/entry/object-detection-summary
3.SSD論文の要約
https://arxiv.org/abs/1512.02325
上記の原著論文を読み、以下のブログ記事等も参考にしながら重要な部分を要約する。以下の数式、図、表は特に断りのない限り上記の論文から引用している。
参考
Stanford Univ.の授業動画
https://www.youtube.com/watch?v=nDPWywWRIRo


(引用:SSD: Single Shot MultiBox Detector:https://arxiv.org/pdf/1512.02325.pdf)
概観
SSDではExtra Feature Layersという畳み込み層を挿入している。図を見れば分かるように、後段に向かうほど特徴マップの分割領域数をスケールダウンさせている。そしてこの分割領域それぞれに対し、いくつかのアスペクト比のデフォルトボックスを対応させ、損失関数とjaccard係数から正解に近いボックスを複数選択する。
猫を検出している図(b)と、犬を検出している図(c)を比べれば分かるが、分割領域数を減らすと、デフォルトボックスはより大きくなる(=より大きい物体に当てはまりやすくなる)ということである。
出力サイズ
出力のサイズは以下のように表せる。
クラススコアの数 c
元のデフォルトボックスの オフセットの値4つ(x座標、y座標、幅、高さ)
そのセルにおけるデフォルトボックスの数 k
特徴マップのサイズ m×n
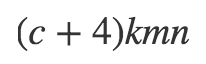
マッチング戦略
デフォルトボックスはjaccard係数の閾値が0.5を超えたものは全て正解ボックスと対応づける。正解ボックスとの重複が一番大きいものを一つ選択する方法よりこちらの方が精度が高い。
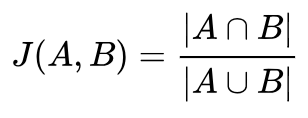
(引用:Wikipedia 「jaccard index」)
損失関数
損失関数は、確信度誤差と位置特定誤差の重み付き和で以下のように定義される。
確信度誤差 L(conf)
位置特定誤差 L(loc)
マッチしたデフォルトボックスの数 N (N=0の場合は誤差0とする)
予測位置 l
正解位置 g
デフォルトボックスの位置 d
クラスの確信度 c
ハイパーパラメータ α (実験では1と設定)

位置特定誤差は以下のように定義される。

smooth関数はFast R-CNNなどでも用いられている損失関数である。予測位置と正解位置の誤差が1より小さい場合は大きく出力し、それ以外の時は絶対値から0.5を引くことで極端に外れた値を取らないように抑えている。
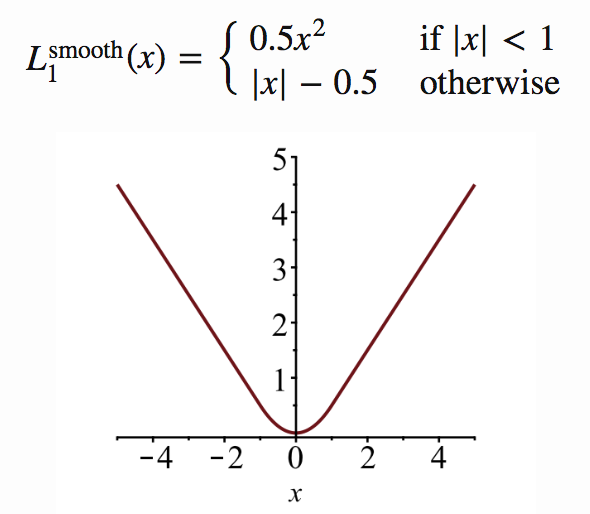
(引用:Object Recognition for Dummies Part 3: R-CNN and Fast/Faster/Mask R-CNN and YOLO https://lilianweng.github.io/lil-log/2017/12/31/object-recognition-for-dummies-part-3.html)
確信度誤差は以下のように定義される。
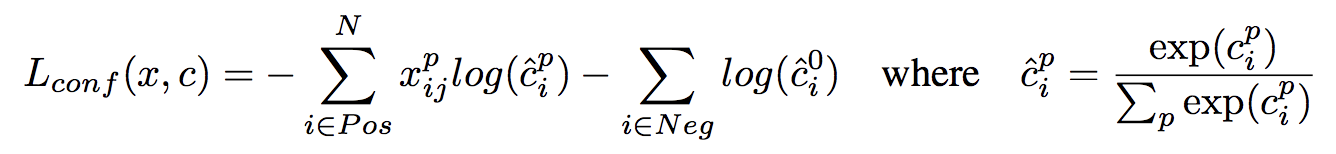
クラスの確信度cはSoftmax関数で求めている。L(conf)の第1項は正解ボックスと対応づけられた正例の予測誤差和、第2項は正解ボックスと対応づけられなかった負例の予測誤差和である。
デフォルトボックスの大きさとアスペクト比の選び方
各特徴マップにおけるデフォルトボックスのスケールは以下のように定義される。
k番目の特徴マップのスケール sk
特徴マップの数 m
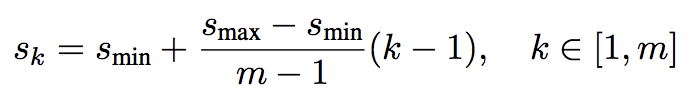
アスペクト比arは、
$ a_{r}={ 1,2,3,\dfrac {1}{2},\dfrac{1}{3}} $
として、幅と高さを以下のように求める。
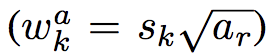
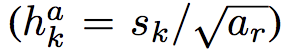
また、アスペクト比が1の時は以下のスケールを追加する。
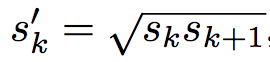
以上により、各特徴マップの分割領域ごとに6つのデフォルトボックスが対応する。
各デフォルトボックスの中心座標は、以下のようにおく。fkはk番目の特徴マップのサイズである。
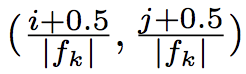
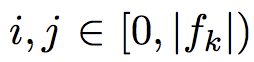
ただし、論文中ではデフォルトボックスの敷き詰め方はオープンクエスチョンである、と述べられている。
ハードネガティブマイニング
実際の画像は物体より背景部分の方が多いため、正解ラベルとの対応付けにより、ほとんどのデフォルトボックスがnegativeになる。これを全て学習させてしまうと、背景のような負例しか出力しないネットワークでも損失関数を下げることができてしまうため、モデルの精度が下がってしまう。
そこで、確信度誤差が高い順にソートし、負例と正例が最大でも3:1になるように調整する。
データ拡張
様々な入力物体のサイズや形状にロバストにするためにデータを拡張する。以下の3点をランダムにサンプリングして学習を行う。
・元の画像全体
・jaccard係数が0.1,0.3,0.5,0.7,0.9となるようにサンプリング
・ランダムにサンプリング
サンプリングする画像の大きさは、元画像に対し[0.1,1]で、アスペクト比は[0.5,2]である。サンプルパッチの中に正解ボックスの中心座標がある場合は、そのデータは保持しておく。サンプリングの後、リサイズしたり反転させたりする。
実験結果
ベースネットワーク
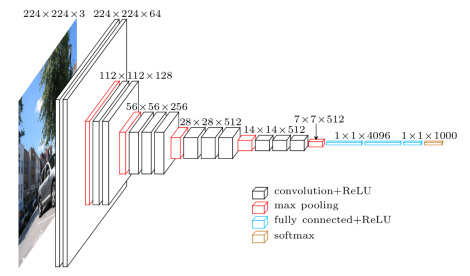
(引用:VGG in TensorFlow http://www.cs.toronto.edu/~frossard/post/vgg16/)
・ILSVRC CLS-LOCデータセットで事前に訓練されたVGG16をベースにしている。
・全結合層6,7を畳み込み層に変更
・プーリング層5の2×2を3×3に、ストライドを2から1に変更
・a trous algorigthmによって畳み込みの範囲を疎に広くしている
・Dropout層と全結合層8は削除
PASCAL VOC 2007
 使用したデータセット
07: VOC2007 trainval (train+validation)
07+12: union of VOC2007 and VOC2012 trainval
07+12+COCO: first train on COCO trainval35k then fine-tune on 07+12
使用したデータセット
07: VOC2007 trainval (train+validation)
07+12: union of VOC2007 and VOC2012 trainval
07+12+COCO: first train on COCO trainval35k then fine-tune on 07+12
 Cor:正解
Loc:位置の間違い
Sim:似たカテゴリとの混同
Oth:別の物体との間違い
BG:背景の間違い
上段:偽陽性のタイプの累積
下段:偽陽性の上位のタイプ
Cor:正解
Loc:位置の間違い
Sim:似たカテゴリとの混同
Oth:別の物体との間違い
BG:背景の間違い
上段:偽陽性のタイプの累積
下段:偽陽性の上位のタイプ
 バウンディングボックス領域
XS=非常に小さい
S=小さい
M=中くらい
L=大きい
XL=非常に大きい
バウンディングボックス領域
XS=非常に小さい
S=小さい
M=中くらい
L=大きい
XL=非常に大きい
アスペクト比
XT=非常に縦長狭い
T=縦長
M=中くらい
W=横長
XW=非常に横長
細かい設定については原著論文を参照されたい。結果を見ると、SSDがR-CNN系より高い精度で予測できていることが分かる。これは、SSDが位置特定誤差について、R-CNNと異なりEnd to Endで直接学習できるためである。
ただし、物体カテゴリ(特に動物)ではよく取り違えをしてしまう。これは、複数カテゴリが一つの領域で共存してしまう場合があるためだと考えられる。
また、SSDは小さい物体に対するパフォーマンスが低いことも分かる。小さい物体は上位のレイヤーではまだ何の情報も持っていない可能性があるからである。
モデル解析

SSDの性能は各構成要素のうち何がどの程度影響を与えているのか検証するため、上記のような対照実験を行った。
その結果、データ拡張を行うとmAP (mean Average Precision)が大きく改善されることが分かる。
また、デフォルトボックスの形状は多いほど良いこと、atrousを使うとより高速になることも分かる。
 この表は複数の出力層を使用した効果を示している。
まず、出力層の種類を減らしていくとmAPは74.3から62.4に減少を続ける。これより、**異なる層で異なるスケールのボックスを使うことが重要**であることが分かる。
また、一つの層に複数のスケールのボックスを用いると、多くは画像の境界上に位置することになる。Faster R-CNNではこういった境界上にあるボックスは無視するという戦略を採っており、その戦略を今回SSDで検証した結果も表に示されている。結果としては、非常に粗い特徴マップ(下位層)についてはmAPが下がるということが分かった。これは、境界上のボックスを取り除くことで大きい物体をカバーできるボックスが無くなってしまった、と考えることができる。実際、解像度の高い画像を用いて同じ実験をすると性能は向上するが、これは取り除いても十分にボックスが残っているためだと考えられる。
この表は複数の出力層を使用した効果を示している。
まず、出力層の種類を減らしていくとmAPは74.3から62.4に減少を続ける。これより、**異なる層で異なるスケールのボックスを使うことが重要**であることが分かる。
また、一つの層に複数のスケールのボックスを用いると、多くは画像の境界上に位置することになる。Faster R-CNNではこういった境界上にあるボックスは無視するという戦略を採っており、その戦略を今回SSDで検証した結果も表に示されている。結果としては、非常に粗い特徴マップ(下位層)についてはmAPが下がるということが分かった。これは、境界上のボックスを取り除くことで大きい物体をカバーできるボックスが無くなってしまった、と考えることができる。実際、解像度の高い画像を用いて同じ実験をすると性能は向上するが、これは取り除いても十分にボックスが残っているためだと考えられる。
PASCAL VOC2012
 07++12: VOC2007 trainval、test、VOC2012 trainval
07++12+COCO: COCO trainval35k で訓練してから07++12でファインチューニング
07++12: VOC2007 trainval、test、VOC2012 trainval
07++12+COCO: COCO trainval35k で訓練してから07++12でファインチューニング
PASCAL VOC2012のテストデータで性能評価をしても同様の結果が得られた。
COCO

COCOの物体はPASCAL VOCより小さい傾向にあるため、こちらのデータセットでも検証されている。
SSD512とFaster[25]のAvg.PrecisionとAvg.Recallを比べると、大きいサイズでは5%程度改善されるのに対して、小さいサイズでは1~2%程度しか改善していない。
SSDはFaster R-CNNよりは精度も速度も優位だが、まだ小さい物体の検出には改善の余地がありそうだ。
小さい物体の予測精度を上げるためのデータ拡張


小さい物体の訓練例を増やすために、「ズームアウト」によるデータ拡張を行った。添え字がついているものがデータ拡張をして訓練されたものである。これらを見ると精度が向上していることが分かる。
さらにSSDを改善するためには、デフォルトボックスの敷き詰め方を上手く設計することが挙げられる。
推定時間
 この表を見ると、SSD300とSSD512は、速度と精度の両面でFaster R-CNNを上回っている。
SSDの計算時間の80%はベースネットワーク(今回はVGG16)に費やされているので、**ベースネットワークの速度が改善されればより速いモデルになる。**
この表を見ると、SSD300とSSD512は、速度と精度の両面でFaster R-CNNを上回っている。
SSDの計算時間の80%はベースネットワーク(今回はVGG16)に費やされているので、**ベースネットワークの速度が改善されればより速いモデルになる。**