概要
Pythonの勉強をしている時に良い題材がないかを調べている際、文字認識について興味があったので一緒に使って勉強しようと思いました。
オープンソースで使用可能なOCRはTesseract OCRが優秀だということでこちらを使ってみたいと思います。
Tesseract OCRのインストール
今回はTesseract OCR4.0以降を使用します。
ダウンロード
公式ページ
https://github.com/tesseract-ocr/tesseract
windowsの場合
自力でコンパイルしても良いが、Windows用インストーラが用意されているのでそちらを実行してインストールを行う。
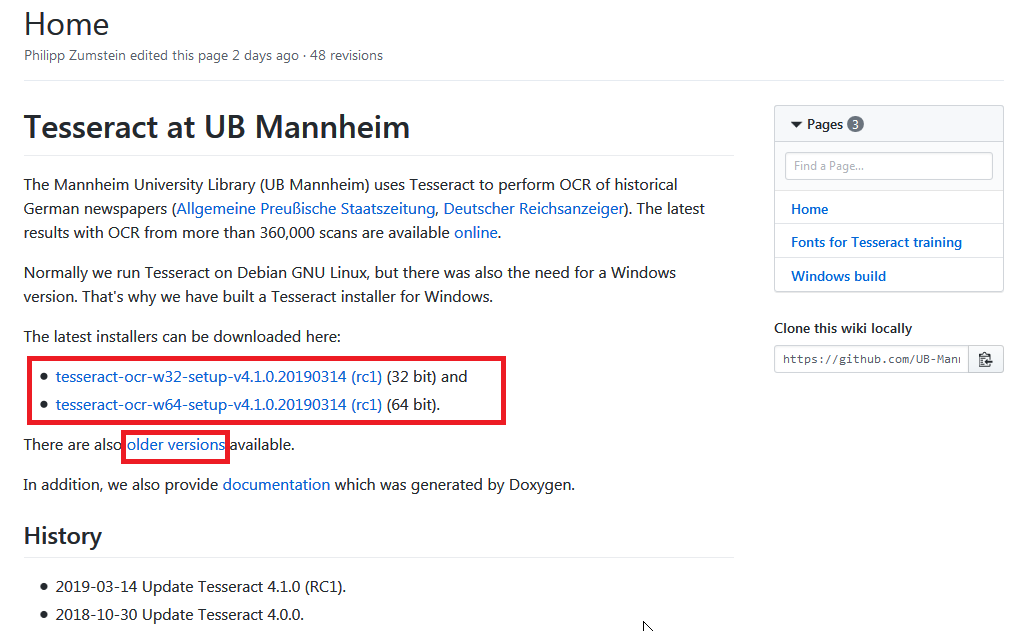
wikiの「Windows」項目内の「Tesseract at UB Mannheim」をクリック
遷移先のページの32bitもしくは64bitのどちらかをダウンロード。
古いバージョンが欲しい場合は「older versions」の方をクリックして任意のバージョンをダウンロード
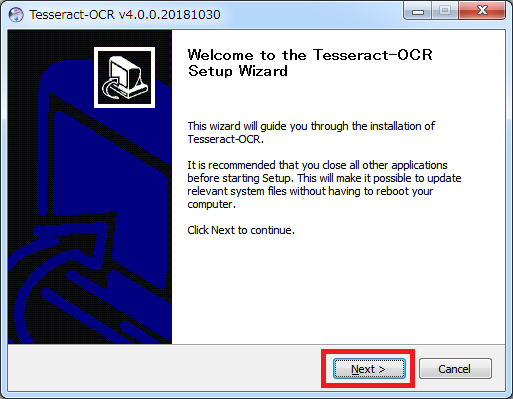
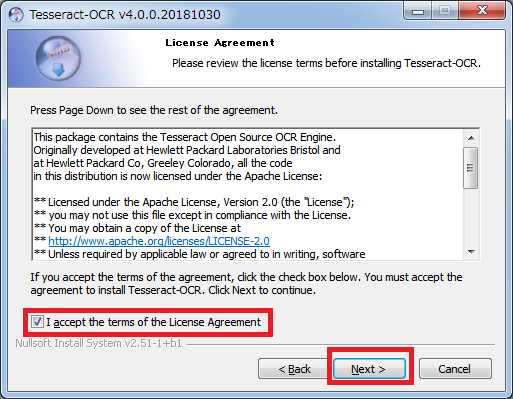
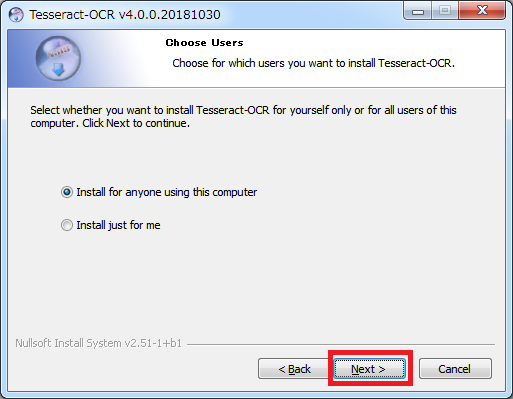
インストール
script dataは書字系と言われ、日本語の場合、日本語+英語のデータで学習させた言語ファイル。
language dataは各言語のみで学習させたファイルとなっている。
言語データ(=tessdata)は後から追加が可能。
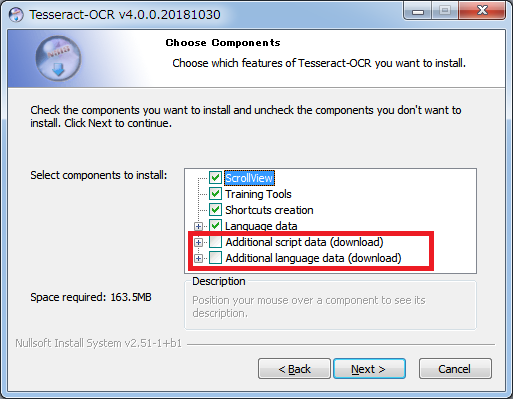
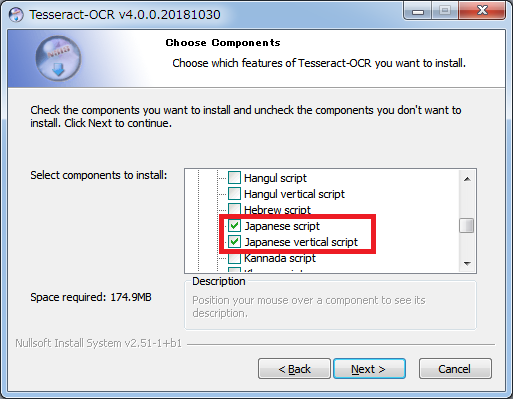
「Additional script data」配下の二つのtessdataにチェックを入れる。
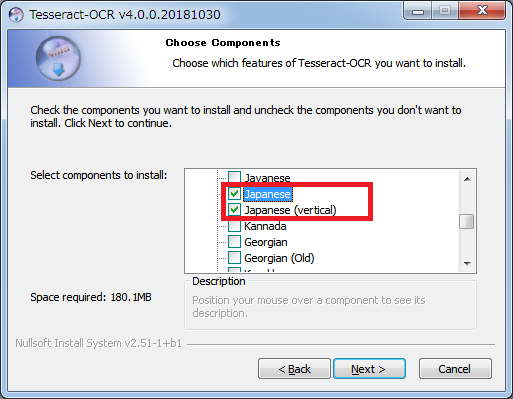
verticalは縦書きを認識させるための言語データとなっている。
「Additional language data」配下の二つのtessdataにチェックを入れる。
インストール先を変更したい場合は任意の場所に変更する。
環境変数の編集
環境変数Pathに「【インストール先】\Tesseract-OCR」を追加。
環境変数TESSDATA_PREFIXを作成して「【インストール先】\Tesseract-OCR\tessdata」を追加。
既に作成されている場合は不要。
**注意:**Tesseract OCRのバージョンを変更する場合などで上書きアップデートする場合、一度アンインストールが実行される。
その場合、インストールディレクトリ全体が削除されるので「TESSDATA_PREFIX」は可能であればインストール配下以外のディレクトリを指定した方が良い(「C:\Tesseract-OCR\tessdata」など)
実行確認
コマンドプロンプトを起動してTesseract OCRが正常にインストールされたかを確認する。
# 環境変数に追加しない場合はインストール先を指定しても動作可能
"C:\Program Files (x86)\Tesseract-OCR\tesseract.exe" D:/test/test.png D:/test/output -l jpn
Tesseract OCRの使い方
Tesseract OCRの使い方についてと、文字認識を行う際の設定方法・種別について確認する。
Tesseract OCRの実行
Tesseract OCRを呼び出すには以下をコマンドラインで実行する。
各オプションの詳細については別項で説明する。
tesseract imagename outputbase [-l lang] [--oem ocrenginemode] [--psm pagesegmode] [configfiles...]
データファイルについて
script dataは書字系と言われ、日本語の場合、日本語+英語のデータで学習させた言語ファイル。
language dataは各言語のみで学習させたファイルとなっている。
言語データ(=tessdata)は後から追加が可能。
TesseractOCR4.0から二種類のtessdataが追加されており、基本的にtessdata_fast版は速度を重視している。
システムに組み込む場合やRaspberry PiなどのIoTで使用する場合はこちらを使用した方がCPU消費が少ない。
精度を重視したい場合や再学習を行う場合はtessdata_bestの方が適している。
これらのデータを使用した場合、LSTMベースのOCRエンジンしかしかサポートしていない。
そのため、オプション詳細で説明しているOEMモードに--oem 0もしくは--oem 2を指定すると__動作をしない__。
https://github.com/tesseract-ocr/tessdata_best
https://github.com/tesseract-ocr/tessdata_fast
下記URLのData Files for Version 4.00内のtessdataはレガシーのエンジン--oem 0とLSTMベースのエンジン--oem 1の両方をサポートする。
インストーラーはこちらのtessdataをダウンロードしていると思われる。
(バイナリを比較したらtessdata = tessdata_fastだったので実際はtessdata_fastと同一?)
こちらは3.5までのtessdataになる。
https://github.com/tesseract-ocr/tessdata
1. 特殊なデータファイル
osd.traineddataとequ.traineddataは特殊なデータファイルとなっている。
| 言語コード | 説明 |
|---|---|
| osd | 言語の判定、文字角度の識別を行う |
| equ | 数学文字列と方程式の検出を行う |
各オプションの詳細
起動コマンドはwikiのCommand Line Usageに記載されている(tesseract imagename outputbase [-l lang] [--oem ocrenginemode] [--psm pagesegmode] [configfiles...])が、各オプションがどのような動作を行うのかをGoogle翻訳にかけながら下記にまとめた。
追記
wikiを確認しながらこのページを作った後に**コマンドの使い方についてまとめていたサイトを発見しました。
こちらを見た方が確実にわかりやすい**です。
1. 最も簡単なOCRの呼び出し
下のコマンドが最も基本的な使い方となる。
入出力引数について
imagenameには画像ファイルもしくはテキストファイルへのパスを記載する。読み込み可能な画像形式はLeptonicaが対応している画像形式になる。
outputbaseには出力先ファイルへのパスを記載する。ファイル名のみ記載して出力形式を指定しない場合、デフォルトではtxt形式のファイルが結果として出力される。
デフォルトの仕様
入出力引数以降のオプションを指定しない場合、解析言語はデフォルトで英語を、ページセグメンテーションモード(以後、psm)はデフォルトで3を指定し、かつ結果をtxt形式で出力する。
Tesseract OCRを実行する場合は縦・横を認識するosd.traineddataと英語の言語データであるeng.traineddata、及び全ての言語データはtessdataディレクトリに格納されている必要がある。
また、TESSDATA_PREFIX環境変数はtessdataの親ディレクトリを指している必要がある。
tesseract imagename outputbase
# 具体的な呼び出し例
tesseract D:/test/test.png D:/test/output
次のコマンドはosd.traineddataとeng.traineddataがC:\Program Files (x86)\Tesseract-OCR\tessdataに存在することを明確に示す。
実行結果はシンプルな呼び出し(1)と同一である。
tesseract.exe --tessdata-dir "C:\Program Files (x86)\Tesseract-OCR" D:/test/test.png D:/test/output -l eng --psm 3
標準入力と標準出力の使用
imagenameにstdinもしくは-を指定した場合、
また、outputbaseにstdoutもしくは-を指定した場合、出力結果が標準出力(=コマンドライン)に出力される。
# 入力対象に標準入力を指定する
# (主な使用方法としてはパイプを使用して複数コマンドを組み合わせる場合にstdinが使用される)
tesseract.exe stdin outputbase
# OCRの結果がコマンドラインに表示される
tesseract.exe imagename stdout
2. 言語を指定して文字認識を行う
通常オプションに何も指定しない場合、-l engが指定されたものとして文字認識を行うが、指定することにより英語以外の言語として文字認識を行わせることが可能になる。
単一言語を使用して文字認識を行う
-l LANGのオプションを追加し、認識を行わせる言語を変更することが可能。
LANGに指定できる文字列はtesseract --list-langsを実行した場合に表示される言語コードの一覧のみ使用可能。
# 日本語を使用して文字認識を行う
"C:\Program Files (x86)\Tesseract-OCR\tesseract.exe" D:/test/test.png D:/test/output -l jpn
複数の言語を使用して文字認識を行う
複数言語を指定する場合、認識をさせたい言語を全て+で連結させる。
第一言語を入れ替えた場合で出力結果が異なる可能性がある。
# 第一言語を日本語とし、次に英語を使用して文字認識を行う
tesseract D:/test/test.png D:/test/output -l jpn+eng
3. ページセグメンテーションモード(=psm)について
特定の画像に特化したレイアウト解析をするためのオプションを指定する。このオプションを指定した場合、画像の種類によっては文字認識の結果が改善される可能性がある。
デフォルトでは--psm 3が指定されている。
--psm 1と--psm 2の内部動作の違いがいまいちわからないのでわかったら追記します。
| オプション | 説明 |
|---|---|
| 0 | 文字角度の識別と書字系のみの認識(OSD)のみ実施(outputbase.osdが出力され、OCRは行われない) |
| 1 | OSDと自動ページセグメンテーション |
| 2 | OSDなしの自動セグメンテーション(OCRは行われない) |
| 3 | OSDなしの完全自動セグメンテーション(デフォルト) |
| 4 | 可変サイズの1列テキストを想定する |
| 5 | 縦書きの単一のテキストブロックとみなす |
| 6 | 単一のテキストブロックとみなす(5と異なる点は横書きのみ) |
| 7 | 画像を1行のテキストとみなす |
| 8 | 画像を単語とみなす |
| 9 | 円の中に記載された1単語とみなす(例:①、⑥など) |
| 10 | 画像を1文字とみなす |
| 11 | まだらなテキスト。特定の順序でなるべく多くの単語を検出する(角度無し) |
| 12 | 文字角度検出を実施(OSD)しかつ、まだらなテキストとしてなるべく多くの単語を検出する |
| 13 | Tesseract固有の処理を回避して1行のテキストとみなす |
1行のみを読み込ませる場合は--psm 7と指定するべき。デフォルトの3だと誤認識してしまう。
縦書きを読み込ませる場合は縦書きのtessdataを使用した上で--psm 5と指定した方が認識率が高くなる。
--psm 11は画像の前処理を行っていない状態(罫線やノイズが残っている場合)だと誤認識が高くなるため、前処理をきちんと行いたい場合や、とりあえず単語を抜き出したい場合など、特定の条件下でのみ使用するようにする。
角度がついたテキストを認識させたい場合、--psm 1もしくは--psm 12を使用するべきと記載されているが、何回かテストを実施したところ正答率があまり良くなかった。
可能であれば前処理として画像の角度を補正してから他のオプションを指定した方が正答率が高くなると思われる。
横書きの日本語を複数行で--psm 6で認識させた場合と、1行に切り取ってからの各行を--psm 7で読み込ませたところ、1行に区切った方が正答率が高かった。
また、更に単語毎に区切って読み込ませたところ、逆に文字として認識されなくなってしまった。
数字を単語毎に区切った場合はテストした際は全て正しい文字が読み込まれていた。
英数字は単語毎に区切って--psm 10で読み込ませるか1行毎で--psm 7を指定するかのどちらかの方法がおそらく一番正答率が高くなると思われる。
日本語の場合は、可能であれば1行ごとに区切って水平の横書きに補正し、--psm 7を指定した方が一番正答率が高くなると思われる。
# 1行テキストのみ画像に存在するものとして文字認識を行う
tesseract D:/test/test.png D:/test/output -l jpn --psm 7
4. OCRエンジンの切り替え
文字認識を行うためのエンジンを指定する。
明示的にLSTMのみを使用したい場合は--oem 1を、3.5までのTesseractエンジンを使用したい場合は--oem 0を使用する。
0または1を指定した際に指定されたエンジンに適したtessdataが存在しない場合、エラーが返却される。
| オプション | 説明 |
|---|---|
| 0 | 以前(3.5まで)のTesseractエンジンのみを使用する |
| 1 | ニューラルネットLSTMのみを使用する |
| 2 | TesseractエンジンとLSTM両方使用する |
| 3 | デフォルト。LSTMとTesseractエンジンを状況に応じて使用する ※LSTM用のtessdataが存在する場合はLSTMを使用し、存在しない場合はTesseract用のtessdataを使用する |
# LSTMのみを使用して文字認識を行う。
tesseract D:/test/test.png D:/test/output -l jpn --oem 1
5. 解像度を指定する
入力画像の解像度を指定する場合は--dpi Nで行う。Nの値は70~2400の値で指定することができるが、一般的な推奨値はN=300となっている。
DPIが300以下の場合、可能であれば前処理などで解像度を300に近づけた方がより精度の高い結果が得られる。
# 入力画像の解像度を指定して文字認識を行う
tesseract D:/test/test.png D:/test/output -l jpn --dpi 72
6. 出力形式を変更する
出力形式はtxt、pdf、hocr、tsv、テキストのみのpdfの5種類で行うことができる。
複数形式指定することが可能。
pdfに設定した場合、読み込んだ画像にテキストが追加された状態のpdfが出力され、-c textonly_pdf=1を追加するとテキストのみのPDFを作成する事が可能。
また、出力形式にlogfileを追加した場合、通常コマンドラインに出力されているデバッグメッセージをtesseract.logとして出力することができる。
-l LANG及び、--psm Nは出力形式およびコンフィグファイルの前に記載する必要がある。
# 日本語ファイルを使用して文字認識を行い、pdfで出力する
tesseract D:/test/test.png D:/test/output -l jpn pdf
# 日本語ファイルを使用して文字認識を行い、txtとpdfで出力する
tesseract D:/test/test.png D:/test/output -l jpn txt pdf
# 日本語ファイルを使用して文字認識を行い、テキストのみのpdfで出力する
tesseract D:/test/test.png D:/test/output -l jpn pdf -c textonly_pdf=1
7. 複数画像ファイルの読み込み
入力ファイルとして、読み込ませたい画像ファイルのパスを全て記載したテキストファイルを準備する。
D:/test/test1.png
C:/temp/test2.jpg
E:/test3.tiff
テキストファイルの準備後、コマンド実行時に入力ファイルに先程作成したテキストファイルを指定する。
# 複数の画像に対して文字認識を行う
tesseract D:/test/input.txt D:/test/output -l jpn
8. 特定のパターンや単語から検出する(3.5まで)
特定のパターンが存在する文字列(2018-01-01、2018-02-01…)を検出する場合、正規表現を用いて出現するパターンを与えることができる。
テキストファイルに任意のパターンの正規表現を記載した後、オプションに--user-patterns FILEを指定する。
また、特定の単語しか出現しない場合も--user-words FILEのオプションを使用することで出現する単語の一覧を指定することができる。
注意:これらのオプションはLSTMで動作しないとのこと
このオプションを使用したい場合は3.5までのエンジンを使用すれば動作すると思われるが、未確認。
Stack overflow:Tesseract user-patterns
Stack overflow:user pattern/dict does not work at all
コントロールパラメータ(ControlParams)
Tesseract OCRは上記のオプションの他に、コントロールパラメータ(=ControlParams)及び設定ファイルによる制御を行う事ができる。
コントロールパラメータの一覧はtesseract --print-parametersで確認することができる。
コントロールパラメータを変更したい場合、TESSDATA_PREFIX/configs配下に任意の名前のファイルを作成し、変更を行うパラメータをCONFIGVAR VALUEの形式で一行ごとに設定した後、BOMを付加しないかつ、LFで改行させた状態で保存を行う。
-l LANG及び、--psm Nは出力形式およびコンフィグファイルの前に記載する必要がある。
# 特定のconfigファイルを使用する([configfiles...]には任意のファイル名)
tesseract D:/test/input.txt D:/test/output -l jpn [configfiles...]
上記の説明では出力形式とコントロールパラメータを別の項目として記載していたが、出力形式で指定していたtxt、pdfといったオプションも実際はコントロールパラメータの設定ファイルを指定していると同義になっている。
どのコントロールパラメータを指定しているのかを確認したい場合は、TESSDATA_PREFIX/configs配下の設定ファイル(例:txt)を開けば確認することが可能。
# txt形式のファイルを出力する
tessedit_create_txt 1
上記以外に、コマンドライン上で直接各コントロールパラメータを設定する場合は-c CONFIGVAR=VALUEのオプションを与える。(複数のコントロールパラメータの指定が可能)
下記では便利なコントロールパラメータを一部紹介する。
1. 改ページの区切り文字を変更または無効にする
複数の画像を読み込ませた場合はページ毎に区切り文字で改行を行うが、区切り文字を変更するには-c page_separator="[PAGE SEPARATOR]"にて設定する。
なお、オプションを指定しない場合は各画像ごとの出力はFF(=改ページ)で区切られる。LFを指定した場合、以前の動作であるページごとに改行するという処理になる。
# 区切り文字を変更
tesseract D:/test/test.png D:/test/output -l jpn -c page_separator="---------"
# 改ページを無効
tesseract D:/test/test.png D:/test/output -l jpn -c page_separator=''
2. 認識する文字列を制限する(3.5まで・もしくは4.1以上)
特定の文字のみ検出したい場合もしくは、特定の文字は検出しないようにしたい場合にどの文字列が有効か無効かを指定することができる。
ホワイトリストとして指定する場合はtessedit_char_whitelistを、ブラックリストとして指定する場合はtessedit_char_blacklistを指定する。
# 0~7のみ出現対象として設定する
tesseract D:/test/test.png D:/test/output -l jpn -c tessedit_char_whitelist="01234567"
# a~c及び、1~3を出現対象として除外する
tesseract D:/test/test.png D:/test/output -l jpn -c tessedit_char_blacklist="abc123"
2019年10月25日追記
Tesseract OCR 4.1.0でホワイトボックス・ブラックボックスのサポートが実装されました。
@aki_abekawa さん教えていただきありがとうございます。
2.1 Tesseract OCR 4.1以上の場合
4.1.0でLSTM版のホワイトボックス・ブラックボックスがサポートされた。
実行方法はレガシー版と同様。Windowsのインストーラ版を使用する場合はバージョン5.0.0を使用するか、自分でコンパイルを行うこと。
古いバージョン一覧にあがっている4.1のexeでは実行しても動作しなかったので機能が未実装だと思われる。
2.2 Tesseract OCR 4.0の場合
このオプションはverが4.0の場合動作しない
このオプションを使用したい場合は--oem 0を指定してOCRエンジンを古い形式で実行するか、バージョンを4.1以降に変更すること。
Blacklist and whitelist unsupported with LSTM (4.0)
オプション指定以外に実行精度を上げる方法としては、tessdataに対してトレーニングを行わせることでも認識精度をあげることができる。
どちらの方法を使用するのか、もしくはどちらも使用するのかは認識を行いたいデータごとに判断する必要がある。
How to use tesseract4.0 to only recognize the digits
Fine Tuning for ± a few characters
LSTMでのトレーニング
LSTMでのトレーニングについては今までのエンジンよりはるかに多くのトレーニングデータを必要とするため、トレーニングにかかる時間が数日から数週間かかる可能性がある。
しかし、特定の問題に対処するために再トレーニングを必要とする場面が出てくる。
ハードウェア条件としては、Linux以外では基本動作を確認していない。MacOSではほとんど動作すると思われるが、シェルスクリプトへのマイナーハックが必要になる場面がある可能性がある。
Windowsでは未確認だが、msysもしくはCygwinが必要になる。
3.xまでであればjTessBoxEditorが比較的容易にトレーニングが可能だと思われる。
LSTMの場合のトレーニングについてはまだ調べきれていないので次回以降に詳細をまとめる予定。
参考:甲骨文字で書かれた文章をOCRで読み取れるようしてみる
PythonでTesseract OCRを扱うためのライブラリ
PythonからTesseract OCRを使用するためのライブラリは有名なもので以下の3種類が存在する模様。
- [tesserocr](https://github.com/sirfz/tesserocr)
- Cythonを利用してTesseract OCRのC++ APIと直接結合する。Tesseractで画像を処理している間にGILを解放することにより、Pythonの並列化を行った際に同時実行を可能にする。
- [PyOCR](https://gitlab.gnome.org/World/OpenPaperwork/pyocr)
- Tesseract以外にLibtesseract、CuneiformのOCRライブラリでもある。GNU/Linux上でのみテストされているが、BSDやMac、Windowsでも動作する。
- [pytesseract](https://github.com/madmaze/pytesseract)
- PILでサポートされた画像を全て読み込む事が可能。また、スクリプトとして起動した場合にテキストファイルに書き込まずに印刷する事ができる。
総括
インストールした時は何となくで使用していたのですが、これではあまりよくないと思いwikiと各ページをきちんと読み返しました。
思っていた以上に使い方が良くなかった部分も見えてきたのでこれ以降は状況に応じて使い分けができそうです。
PythonでOCRを使用するところまで記載したかったのですが、思ったよりTesseract OCR自体に対する文章が増えてしまったので次回にしたいと思います。
2019年12月12日追記
言語トレーニング前の品質改善についての記事を公開しました。(こちらにリンク貼り忘れていました)
ほとんどは公式wikiの日本語訳になります。
言語トレーニングはメリット・デメリットあるため、なるべく読み込む画像に対して適切な前処理を行う方法で品質を改善した方が良いです。
参考
tesseractコマンドの使い方(Tesseract OCR 4.x)
Tesseract OCR 近況(2018/06)
Tesseractの各言語のラッパーいろいろ(随時更新)
Tesseract-OCR 3.04 を試してみる
tesseract PSMをいじってみた