概要
前回の記事ではTesseract OCRの使い方と実行時のオプションについて記載しました。
今回はTesseract OCR4.x(LSTM)版について言語データをトレーニングする際の手法一覧と、トレーニング前に行うべき品質改善の方法について記載したいと思います。
Tesseract OCR 4.xについて
それまでのTesseract OCR 3.5までと違い、Tesseract OCR 4.0から文字認識のエンジンにニューラルネットワークの一つであるLSTMを追加で採用しました。
その結果、計算時間が増加した代わりに3.5までのTesseractエンジンより遥かに認識精度が向上しました。
※しかし複雑な言語では、Tesseractエンジンより実行結果は早くなる場合がほとんどです。
ニューラルネットワークでのトレーニングは今までのTesseractエンジンより多くの時間がかかり、場合によっては数日から数週間かかる場合があります。
もし言語データを再トレーニングしたとしても特定のデータには不十分な場合が発生することがあります。
そのため、特定の言語や特定の状況に応じて再トレーニングする必要があります。
トレーニングの種類
トレーニングには次の3種類がある。
1. 微調整(Fine tune)
既存のトレーニングされた言語データに対して特定の追加データを与えてトレーニングを行う。
2. ネットワークから最上位または任意のレイヤー(層)を切り離してトレーニング
(原文ではCut off the top layer (or some arbitrary number of layers) from the network and retrain a new top layer using the new data)
ニューラルネットワークでは層という概念がある。そのうち最上位または任意のレイヤーのみを切り離し、切り離した部分に対して特定の追加データを与えてトレーニングを行う方法である。
「1. 微調整」でうまくいかない場合はこちらの方法でうまく改善できる可能性がある。
3. 初めから再トレーニング(Retrain from scratch)
全てのデータを自分で準備をしてトレーニングを行います。こちらの場合、十分なトレーニングのセットがない限り非常に困難になる。
その場合、トレーニングデータのみでうまく機能する言語データになる場合がほとんどになる。
トレーニングを行う前に
Tesseract OCR 4.xのトレーニング・使用自体にニューラルネットワークの知識は必要がない。
言語のトレーニングには多大な時間がかかるためその前に必ずImproveQualityを読み、先に品質の改善を行った方が良い。
品質の改善について
Tesseract OCRは実際の文字認識を実行する前に複数の画像処理操作をLeptonicaライブラリを介して行う。
通常はLeptonicaライブラリが実行する処理のみでも問題がないクオリティで文字認識が行われるが、処理を行う画像によっては事前の画像処理が十分ではないこともあり得るため、精度が大きく低下する場合がある。
精度に問題があると感じた場合はTesseract OCRの実行時に下記のどちらかを設定することでTesseract OCRが画像を処理した方法を確認できる。
-
configfilesにtessedit_write_imagesをtrueとして設定し、該当のconfigfilesを実行時に指定 - Tesseract OCR実行時にコントロールパラメータ(ControlParams)の
出力形式にget.imagesを指定
上記処理によって出力されたtessinput.tifを確認して画像処理に問題があると感じた場合、Tesseract OCRの実行前に下記の画像処理のいくつかを実行することによって認識精度が向上する場合がある。
画像処理
1. 白黒反転の画像を使用しない(4.0以上)
Tesseract OCR 4.0以上のLSTMベースのOCRエンジンを使用する場合は白背景に黒字を使うようにする。
なお、3.05までのエンジンの場合は白黒反転の画像にも対応しているため黒背景に白字の場合でも問題なく処理が可能である。

2. 適切なスケーリング
画像サイズが以下に当てはまるように再設定する。
- 300dpi以上
- 10pt以上
-
x-heightが少なくとも10ピクセル以上(10ptかつ300dpiの場合、20ピクセルが望ましい)
10ptかつ300dpi未満の場合に精度が低下していき、更に8ptかつ300dpi未満の場合、著しく精度が低下する。
画像に含まれる文字のptがわからない場合の簡単な確認方法はx-heightを確認して画像の再スケーリングを行うことである。
10ptかつ300dpiの場合はx-heightが一般的なフォントの場合約20ピクセルとなる。
(フォントによっては大幅に異なる可能性がある)
x-heightが10ピクセル未満の場合、正しい認識結果が得られる可能性がほとんどなく、8ピクセル未満の場合は文字のほとんどがノイズ除去の対象として認識されてしまう。
3. 二値化
Tesseract OCRでは文字認識の実行時、内部で大津の二値化を実行しているが、認識させたい画像の背景の色が不均一な場合に適切な二値化が行われない可能性がある。
その場合はTesseract OCRの実行前にその画像にとって最適なアルゴリズムの二値化を実行して文字と背景を適切に分離する必要がある。

原文のアルゴリズムの例としては以下のものが挙げられている
- ImageJのAuto Threshold
- OpenCVの画像の閾値処理
- scikit-imageのThresholding
もしTesseract OCRで最適な二値化が難しい画像を扱う場合は、自分の実行するライブラリや言語に合わせて適切な二値化を行う。
4. ノイズ除去
認識させる画像に対してごま塩ノイズ(インパルスノイズ)などが発生している場合、Tesseract OCRによる二値化でノイズが除去しきれない場合がある。
いくつかのノイズはTesseract OCRでは除去しきれないためノイズが含まれたままになってしまい、精度が低下する可能性がある。
一般的に簡単に実施できるノイズ除去処理は収縮・膨張処理をn回繰り返すことであるが、画像のノイズの入り方によってはこの手法では除去できない場合もあるため、画像ごとに適切なノイズ除去の方法を選択する必要がある。

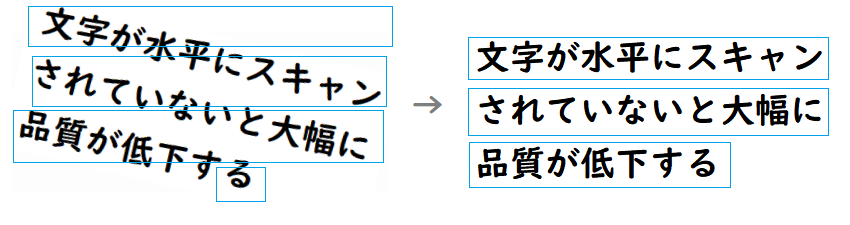
5. 回転/回転補正
画像をスキャナなどで読み込む際、場合によっては文字列が水平にスキャンできない場合がある。この時に文字列が水平になっていない画像を読み込む場合、行ごとの分割が正しく行われない可能性が非常に高くなり、文字認識の精度が大幅に低下する。
水平にスキャンされていない画像に対してOCRを実行する場合は必ず文字列が水平になるように画像の角度を回転させて調整を行うこと。
6. 境界線
6.1. 不要な境界線の除去
スキャナなどで本をスキャンした場合にページの周囲に境界線が表示されることがある。
境界線にグラデーションがかかっていたり、複数の形状の境界線がページに含まれている場合、OCRを実行した場合に誤認識を行う可能性がある。
上記のような境界線が画像に含まれている場合は余分な境界線を予め削除しておくこと。

6.2. 文字と画像との境界線を追加
画像に対して境界がほとんどない文字を認識させようとする場合、問題が発生する場合がある。
その場合は文字に対して10ptほどでよいので白い境界線を追加すれば認識精度が向上する場合がある。
(原文ではImageMagickを使用すれば簡単に境界線を追加できると書かれているが、多くの脆弱性が発見されているため他のツールを使用した方が良いと思われる)
※参考URL
Why do I get such poor results from Tesseract for simple single character recognizing?
Error in boxClipToRectangle: box outside rectangle #427
7. 透明度及びアルファチャネルの除去
PNGなどの画像形式は透過度の情報を扱うためのアルファチャンネルが含まれている。
しかしTesseract OCRではアルファチャンネルを持つ画像にOCRをかける場合、状況に応じてOCR実行前にアルファチャンネルの削除を行う必要がある。
Tesseract OCR 4.0以上の場合
4.0以上のエンジンの場合はleptonica関数のpixRemoveAlpha()を使用してアルファチャンネルの削除が行われる。
上記の手法では背景を白としてブレンドを行いアルファチャンネルの削除が行われるため、特定の条件(例えば、映画の字幕に対してそのままOCRを実行する場合)では問題が発生する可能性がある。
そのような場合にはOCR実行前に前処理としてアルファチャンネルを削除するか、画像を反転させておく必要がある。
Tesseract OCR 3.05までの場合
3.05までのエンジンを使用する場合はTesseract OCRではアルファチャンネル削除を行わないため、OCR実行前にユーザが透過度及びアルファチャンネルを削除しておく必要がある
8. ツール・ライブラリの紹介
- Leptonica
- OpenCV
- ScanTailor Advanced
- ImageMagick
- unpaper
- ImageJ
- Gimp
- PRLib ※OCR品質を改善するための事前認識ライブラリ
9. 画像改善のプログラム例
- OpenCV のRotationによるスキュー角の除去 C++でスキャン時の角度の歪みの除去の例
- Fred's ImageMagick ScriptsのTEXTCLEANER テキスト画像の背景を処理するための各種前処理を行うbashスクリプト(ノイズ除去、歪み除去などが可能)
- rotation_spacing.py ラドン変換を利用してテキスト画像の回転と行間隔を自動検出するためのPythonスクリプト
- crop_morphology.py OpenCV、numpyを使用して画像内のテキストブロックを検索するためのPythonスクリプト
- OpenCVおよびPythonを使用したクレジットカードOCR OpenCVを利用してクレジットカードの文字を読み取るためのPythonスクリプト
- noteshrink 手書き文字の画像をPDFにクリーンアップするPythonのスクリプト(詳細は手書きメモの圧縮と強化に記載)
- uproject text テキスト画像に施された遠近感を解除するためのPythonスクリプトの例(詳細はテキストに楕円を当てはめて投影変換を解除に記載)
- page_dewarp 「キュービックシート」モデルを使用してスキャン時に付与されたページカールを修正するPythonスクリプトの例(詳細はページの歪みに記載)
- OpenCVを使用してスキャンした画像から影を削除する方法 OpenCVを使用して画像から影を削除するPythonスクリプトの例
10. アウトライン化の除去(原文では存在しないが、Issue #2048: Accuracy problemから追記)
文字列がアウトライン化されている場合、Tesseract OCRの認識精度は大幅に低下する。
上記のような文字列が含まれている場合、アウトライン部分を除去する必要がある。
ページセグメンテーション
通常何もオプションを指定しない場合、Tesseract OCRでは複数行が含まれる1枚の原稿のような画像を期待する。小さい領域を文字認識したい場合はページセグメンテーションモード(=psm)を使用して別のページセグメンテーションモードを試すことをすすめる。
トリミングされすぎていて画像に対して境界線がほとんどない場合、テキスト画像の周囲に白い境界線を追加することでも文字認識の改善が行われる場合もある。
(Issue #398: without output resultを参照)
サポートされているページセグメンテーションモードを確認するにはtesseract -hを実行すること。
(ページセグメンテーションの各モードについては以下のページで翻訳している)
辞書、単語リスト、および文字パターン
通常何もオプションを指定しない場合、Tesseract OCRでは各単語を認識するように最適化されている。領収書、価格表、コードなど一般的な単語とはことなる文を認識しようとしている場合は適切なページセグメンテーションモードが選択されていること以外にもいくつかの方法で精度を向上させることができる。
Tesseractに対して辞書を無効にするオプションを指定した場合、テキスト画像のほとんどが辞書に含まれるような単語でない場合に文字認識の精度が向上する。
辞書を無効にするためにはコントロールパラメータ(ControlParams)のload_system_dawgとload_freq_dawgの二つに対してfalseを設定する。
Tesseractによる文字認識を支援するために単語リストに単語を追加したり、一般的な文字パターンを追加することも可能である。
これについては、Tesseractマニュアルで詳細が記載されている。
数字を認識したい場合といった、一部の文字のみのパターンしかあり得ないことがわかっている場合はtessedit_char_whitelistで認識する文字列を制限することができる。例についてはFAQを参照すること。
(tessedit_char_whitelistについては以下のページで翻訳・解説している)
上記を試しても問題がある場合
画像処理を試してもまだ読み取り精度が低い場合はフォーラムでヘルプを求めることが推奨される。
可能な限りサンプル画像を投稿すること。
総括
今回はOCR前に行った方が良い品質改善方法について書きました。
一般的な横書きに近いテキストの場合、おそらくこちらに記載した内容を実施するだけで認識精度が向上します。トレーニング不要になる場合も多いと思われます。
しかし、特殊なフォントもしくは文字の場合、こちらだけでは精度不足になる場合があると思います。その場合は言語データに対してトレーニングが必要になります。
次回の記事では言語データのトレーニングについて書きたいと思います。
PythonでTesseract OCRの使用方法について書くと言っていましたがまだ書いていないので早めに書きたい