はじめに
PyBullet (Python上で動く物理シミュレータ) を使用して,ロボットアームを可視化して,動かしたい.
前記事では,PyBullet (Python上で動く物理シミュレータ) で2軸ロボットアームの強化学習環境を作成した.( 2軸ロボットアームの強化学習 Part1 (環境作成) )
環境作成をメインに実装し,エージェントは常にランダムで動いた.前記事の問題点は,エージェントが学習せずに,ランダムで動いた点である.
本記事では,エージェントの学習方法として,"モンテカルロ法"を採用する.
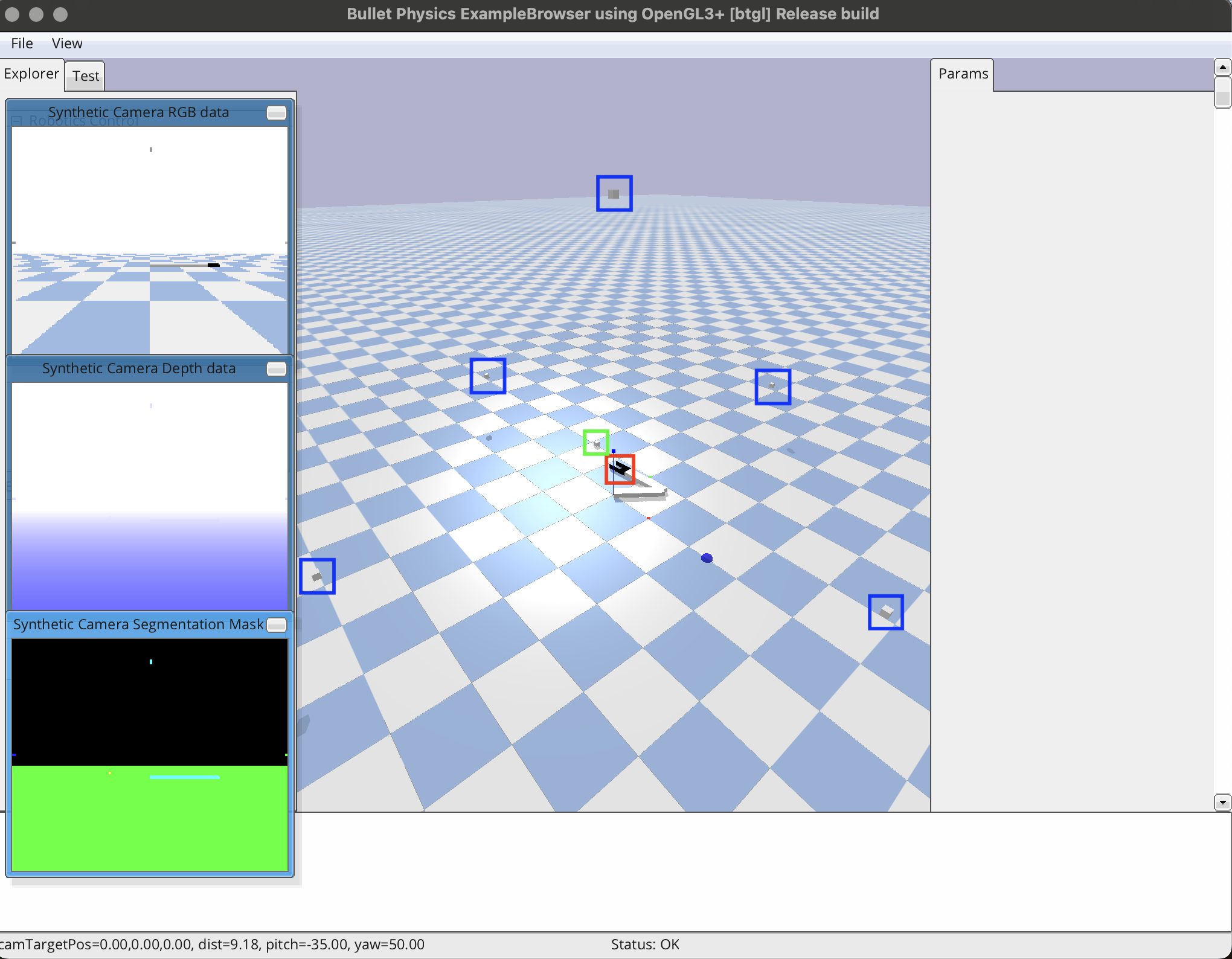
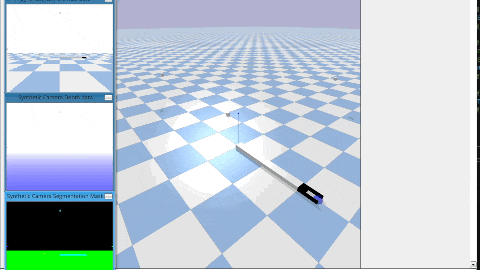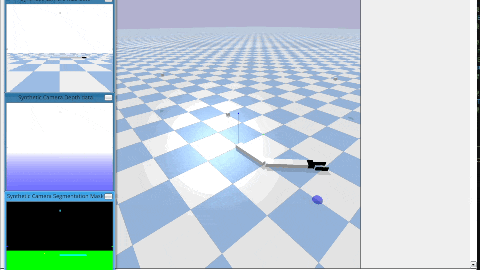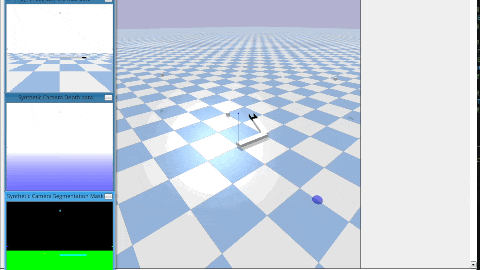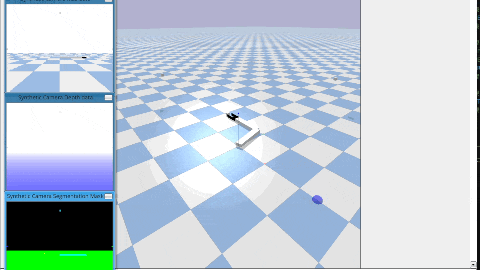
グリッパー付きの2軸ロボットアームを使用して,干渉物が存在しない環境下にて,複数のカメラから把持物体の位置を取得して,物体を把持する(下図はPyBullet上のグリッパー付き2軸ロボットアームである).赤枠がグリッパー,緑枠が把持したい物体,青枠がカメラ,青色の球が初期位置である.
本記事を実施してできる最終的なものは下記動画の通りである.エージェントの学習方法は"モンテカルロ法"である.
下記は,学習中の強化学習による経路生成の動画である.

下記は,学習後の強化学習による経路生成の動画である.
本記事で実装すること
・エージェントの学習方法は"モンテカルロ法"
本記事では実装できないこと (将来実装したい内容)
エージェントの学習手法
・SARSA
・Q学習
・DQN
・Actor-Critic
動作環境
・macOS Sequoia (バージョン15.5)
・Python3 (3.13.3)
・PyBullet (3.25) (物理シミュレータ)
・Numpy (2.3.0) (数値計算用ライブラリ)
PyBullet のインストール方法
PyBullet のインストール方法については記事 PyBulletで2軸ロボットアームを動かす Part1 (関節角度を自由に設定) にて,説明したため,割愛する.
PyBulletの使用方法
Pythonの物理シミュレータであるPyBulletの使用方法については記事 2軸ロボットアームの強化学習 Part1 (環境作成) にて,説明したため,割愛する.
2軸ロボットアームの定義
2軸ロボットアームの定義については記事 2軸ロボットアームの強化学習 Part1 (環境作成) にて,説明したため,割愛する.
カメラによる把持物体の位置を取得
カメラによる把持物体の位置を取得する方法については記事 2軸ロボットアームの強化学習 Part1 (環境作成) にて,説明したため,割愛する.
強化学習に関して
強化学習は機械学習の一つの種類である.強化学習とは,自分で試行錯誤をしてデータを集め,詰めたデータから良い行動を学習することである.
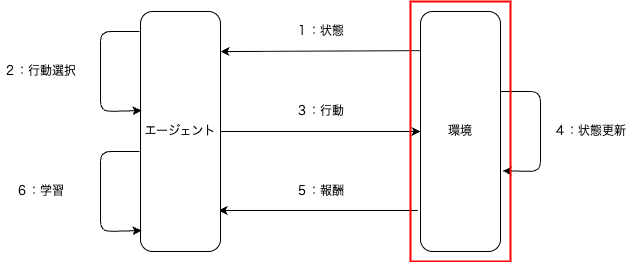
強化学習のイメージは下図の通りである.

1:「環境」から「エージェント」に対して,「状態」を渡す
2:「エージェント」が「状態」より,「行動」を選択する
3:「エージェント」から「環境」に対して,「行動」を実行する
4:「環境」が「行動」より,「状態」を更新する
5:「環境」から「エージェント」に対して,「報酬」を渡す
6:「エージェント」が「報酬」より,「学習」する
ここで,用語の定義をする.
| 用語 | 用語の定義 |
|---|---|
| エージェント | 行動の主体者 |
| 環境 | エージェントと相互作用を行う対象 |
| 状態 | エージェントの行動によって置かれるエージェントの状況 |
| 行動 | エージェントが起こすアクション |
| 報酬 | エージェントの行動に対する環境からのフィードバック |
本記事での "環境" は "PuBullet上のロボットと環境" である."エージェント" は "ロボットを動かすための頭脳" である.
以下では,本記事で使用する "環境" と "エージェント" を説明していく.
強化学習の環境に関して
強化学習の環境に関して説明する.強化学習の全体像の中で,下図の赤枠で囲んだ「環境」を説明する.
環境側で設計する情報(用語)は下表の通りである.
| 用語 |
|---|
| 環境 |
| 報酬 |
| 状態 |
| 行動 |
上表に記載した用語の設計を1つずつ,これから説明していく.
環境の定義
環境の定義に関しては記事 2軸ロボットアームの強化学習 Part1 (環境作成) にて,説明したため本記事では割愛する.
報酬の定義
報酬の定義に関しては記事 2軸ロボットアームの強化学習 Part1 (環境作成) にて,説明したため本記事では割愛する.
状態の定義
本記事での状態を定義する.2軸ロボットアームの各関節で状態を持つ.
ロボットアームの各軸の関節角度を 「$-180 ~ 180$ [deg] 」 として,考える.
今回は,関節角度を $10$[deg] 刻みの$37$分割で考える.具体的には,$-180, -170, ... , -10, 0, 10, 170, 180$ [deg] の$37$分割である.
関節$1$は$37$状態(分割),関節$2$も$37$状態(分割)と考えると,全状態が$1,369 (37 * 37)$となる.
関節角度の刻み幅を $1$[deg] 刻みの$361$分割と考えると,全状態が$130,321$となるため,$10$[deg] 刻みとした.
状態数が多い場合のメリット・デメリットに関して,下表にまとめた.
| メリット | デメリット |
|---|---|
| 様々な状態を保存できる | 状態数が爆発的に増加する |
| 表現力(精度)が高い | 表現力(精度)が小さい |
| - | 学習回数を大きくする必要がある |
本記事では,ロボットアームの関節角度を$10$[deg]刻みの離散値とした.
2軸ロボットアームの全状態が$1,369$のため,6軸ロボットアームで同様の状態を定義してしまうと全状態数が膨大になってしまうので,将来的には状態を変える必要がある.
将来的には,ロボットアームの関節角度を連続値とし,深層学習を採用することで,状態数の多さに対処する.
行動の定義
行動の定義に関しては記事 2軸ロボットアームの強化学習 Part1 (環境作成) にて,説明したため本記事では割愛する.
強化学習のエージェントに関して
強化学習のエージェントに関して説明する.強化学習の全体像の中で,下図の赤枠で囲んだ「エージェント」を説明する.
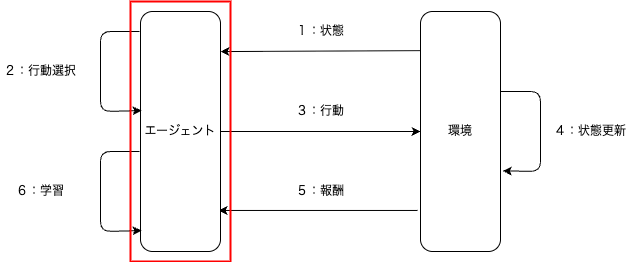
エージェントは,環境から「状態」を受け取り,「行動」を行い,「報酬」を得て,次の「状態」へ遷移する.下記のように1エピソードが完了するまで,「状態(S)」,「行動(A)」,「報酬(R)」,「状態(S)」のループとなる.
$S_{0}, A_{0}, R_{0}, S_{1}, A_{1}, R_{1}, ...$
エージェントは環境から受け取った「報酬」の和を「収益」として,学習する.収益とは,エージェントが得る報酬の和である.
次節では,報酬の和である収益について説明する.
収益に関して
報酬の和である収益に関して説明する.
はじめに,時刻 0 における収益 (初期状態の収益) と時刻 T における収益 (目標状態の収益) を下式で示す.
\displaylines{
時刻 0 における収益 (初期状態の収益) \\
G_{0} = R_{0} + \gamma * R_{1} + \gamma ^ 2 * R_{2} + ... \\
文字の意味は以下の通り.\\
G ... 収益,R ... 報酬,添え字 ... 時刻, \\
\gamma ... 割引率(未来の報酬をどれだけ重要視するか.) \\
\\
時刻 T における収益 (目標状態の収益) \\
G_{T} = R_{T} \\
}
次に,時刻 t と t + 1 における収益を下式で示す.最終的には,現在時刻の収益を次時刻の収益で表現できるようになると,全報酬を覚えていなくても次時刻の収益だけで現在時刻の収益が算出できるようになる.
\displaylines{
時刻 t における収益 \\
G_{t} = R_{t} + \gamma * R_{t + 1} + \gamma ^ 2 * R_{t + 2} + ... \\
時刻 t + 1 における収益 \\
G_{t + 1} = R_{t + 1} + \gamma * R_{t + 2} + \gamma ^ 2 * R_{t + 3} + ... \\
}
最後に,時刻 t における収益を時刻 t + 1 における収益を使って,表現すると下式の通りとなる.
\displaylines{
時刻 t における収益 \\
G_{t} = R_{t} + \gamma * R_{t + 1} + \gamma ^ 2 * R_{t + 2} + ... \\
G_{t} = R_{t} + \gamma * (R_{t + 1} + \gamma * R_{t + 2} + \gamma ^ 2 * R_{t + 3} + ... ) \\
G_{t} = R_{t} + \gamma * G_{t + 1} \\
}
現在時刻の収益を次時刻の収益を使って表現できるようになることで,簡単に収益を算出できるようになる.
次に,収益の期待値である状態価値関数に関しての説明をする.
状態価値関数に関して
収益の期待値である状態価値関数に関して説明する.期待値とは,"期待される平均値"である.
状態価値関数は,"収益が期待される平均値"となる.数式で記載すると下式の通りとなる.
\displaylines{
v_{pi}(s) = E_{pi}[G_{t}|S_{t} = s] ... ① \\
文字の意味は以下の通り.\\
v ... 状態価値関数,pi ... 方策(状態から行動を選択するルール) \\
s ... 状態,G ... 収益,添え字 ... 時刻,E[] ... 期待値
}
上式は,ある方策(状態から行動を選択するルール)で,状態$s$における状態価値関数を$v_{pi}(s)$と記載している.
ここで一度,確率と報酬に関しての文字式を定義する.状態価値関数を定義する時に必要となるため,ここで定義しておく.
\displaylines{
状態sにおける行動aを選択する確率 \\
pi(a|s) \\
状態sで行動aを選択した時に,状態がs'に遷移する確率 \\
p(s'|s, a) \\
状態sから,行動a1をして,状態がs1になる確率 \\
pi(a=a1|s) * p(s'=s1|s, a=a1) \\
状態sから,行動a1をして,状態がs1になった時の報酬 \\
r(s, a=a1, s'=s1) \\
}
式①の右辺にある収益$G_{t}$を展開すると,下式の通りとなる.
\displaylines{
v_{pi}(s) = E_{pi}[G_{t}|S_{t} = s] \\
v_{pi}(s) = E_{pi}[R_{t} + gamma * G_{t + 1}|S_{t} = s] \\
v_{pi}(s) = E_{pi}[R_{t}|S_{t} = s] + gamma * E_{pi}[G_{t + 1}|S_{t} = s] \\
}
次に,上式の右辺にある $E_{pi}[R_{t}|S_{t} = s]$ について,解いていく.$E_{pi}[R_{t}|S_{t} = s]$ は,方策(状態から行動を選択するルール) $pi$ における 状態$s$の収益の期待値である.下式のように解くことができる.
\displaylines{
期待値の定義より,\\
期待値(E_{pi}[R_{t}|S_{t} = s]) = 報酬(R_{t}) * 報酬となる確率(P(R_{t}|)) \\
そのため,下式の通りとなる. \\
E_{pi}[R_{t}|S_{t} = s] = \sum_{a}(\sum_{s'}( pi(a|s) * p(s'|s, a) * r(s, a, s') ) ) ) \\
}
上式の意味としては,「状態$s$という条件で,取り得る全部の行動と取り得る全部の次状態における報酬の平均値」である.
エージェントは試行錯誤をして,状態価値関数を学習していき,状態価値関数が最大となるような行動を選択させる.
状態価値関数は,方策(状態$s$における行動$a$を選択する確率)$pi(a|s)$が既知でないといけない.次節では,方策が未知であっても学習可能である "行動価値関数" に関して説明する.
行動価値関数に関して
方策が未知であっても学習可能である "行動価値関数" に関して説明する.
行動価値関数は,時刻$t$の時に状態$s$で行動$a$を取り,時刻$t + 1$以降では方策$pi$に従った行動をとった時の収益の期待である.数式で表すと下式の通りとなる.
\displaylines{
q_{pi}(s, a) = E_{pi}[G_{t}|S_{t} = s, A_{t} = a] \\
文字の意味は以下の通り.\\
q ... 行動価値関数,pi ... 方策(状態から行動を選択するルール) \\
s ... 状態,a ... 行動,G ... 収益,添え字 ... 時刻,E[] ... 期待値
}
行動価値関数の行動$a$自由に決めることができ,$a$という行動後は方策$pi$に従って行動していく.
次は,"状態価値関数"と"行動価値関数"の関係性に関して説明する.
簡単にいうと,ある状態の "状態価値関数" を各行動ごとに分割したものを "行動価値関数" と呼ぶ.また,ある状態の "行動価値関数" を全行動の重み付き和より "状態価値関数" を表現することができる.
"行動価値関数" と "状態価値関数" の関係性を数式で表すと下式の通りとなる.
\displaylines{
行動数を仮に3(a1,a2,a3)と考えて,状態価値関数と行動価値関数の関係性を表現すると \\
v_{pi}(s) = pi(a1|s) * q_{pi}(s, a1) + pi(a2|s) * q_{pi}(s, a2) + pi(a3|s) * q_{pi}(s, a3) \\
v_{pi}(s) = \sum_{a}( pi(a|s) * q_{pi}(s, a) ) \\
文字の意味は以下の通り.\\
v ... 状態価値関数,q ... 行動価値関数,pi ... 方策(状態から行動を選択するルール) \\
p(a1|s) ... 状態sで行動a1を選択する確率
}
エージェントは試行錯誤をして,行動価値関数を学習していき,ある状態における行動価値関数が最大となるような行動を選択させる.
次節では,エージェントの学習方法の一種である "モンテカルロ法" に関して説明する.
モンテカルロ法に関して
エージェントの学習方法の一種である "モンテカルロ法" に関して説明する.
モンテカルロ法は,"データのサンプリングを繰り返し行って,結果から推定する手法の総称" である.経験(サンプリング)から価値関数を推定する.簡単に言うと, "試行錯誤をたくさんして平均値を取ると,期待値(理論値)に近づく" と言う手法である.
具体例としては,サイコロをたくさん投げて,平均値を取ると期待値の$3.5$に近づくという考え方である.
モンテカルロ法の特徴を下表にまとめた.
| 特徴 |
|---|
| 1エピソード完了後に,価値関数の推定 |
| エージェントは環境の内部情報が未知でも学習可能 |
| 試行回数をたくさんすることで,期待値に近づく |
モンテカルロ法は,"1エピソード完了後に,価値関数の推定" するため,学習が遅いというデメリットが存在する.
本記事では,モンテカルロ法を採用して,行動価値関数を学習させる.
行動の選択方法は,「ε-greedy法」を採用する.次節で,「ε-greedy法」の説明をする.
行動の選択方法 (ε-greedy法)
行動の選択方法に関して説明する.行動の選択方法として,「ε-greedy法」を採用する.
「ε-greedy法」は「探索」と「活用」のバランスを取るための手法である.
「探索」 ... ランダムに行動すること.
「活用」 ... 価値関数が最大となる行動をとること.
「ε-greedy法」を簡単に説明すると,"たまにランダムな行動をして,より良い行動を探す"
活用(価値関数が最大となる行動)だけをすると,未知の行動を試さなくなる.
探索(ランダムに行動)だけをすると,無駄と学習した行動をたくさんして,学習効率が悪い.
「ε-greedy法」による,活用と探索を選択するフローチャートは下図の通りである.
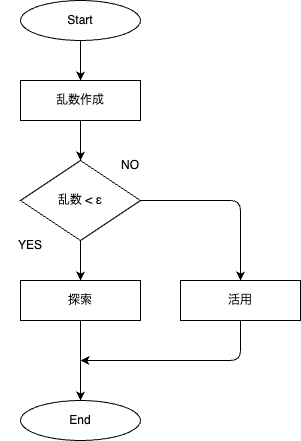
乱数を作成して,乱数が$\epsilon$未満なら「探索」し,乱数が$\epsilon$以上なら「活用」する.パラメータ$\epsilon$を上手に設計しないと,学習の効率が悪くなっていく.
次節では,パラメータ$\epsilon$の設定方法を説明する.
パラメータεの設定方法
パラメータ$\epsilon$は行動を選択するときに,「探索」する確率を定義したパラメータである.$\epsilon = 1$なら常に「探索」し,$\epsilon = 0$なら常に「活用」する.
$\epsilon$の設定方法の方針としては,下記の通りとする.
1:学習の初期では,価値関数を学習できていないから,探索をメイン
2:学習の中盤では,探索と活用の両方
3:学習の終盤では,価値関数が学習できているから,活用をメイン
$\epsilon$を変更するフローチャートは下図の通りである.
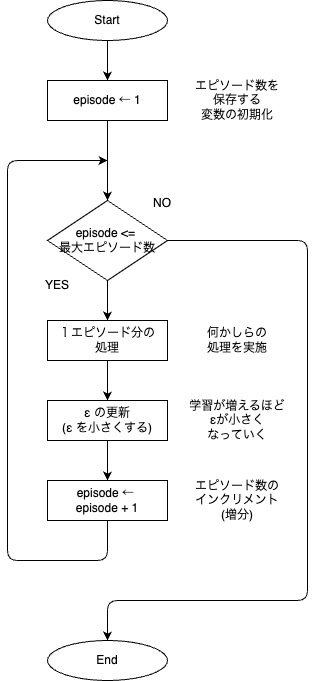
1エピソード完了ごとに,$\epsilon$を小さくすることで,学習の初期で「探索」をメインにし,学習の終盤で「活用」をメインにする.
URDFソースコード
今回使用する,URDFのソースコードについて説明する.
ソースコードとして,下表の9ファイルを作成する.
| ファイル名 | 概要 | リンク先 |
|---|---|---|
| camera_back_to_front.urdf | 手前方向(-Y方向)を向いているカメラの定義 | [PyBullet] [カメラ] 2軸ロボットアームを動かす Part7 (複数カメラによる把持物体の位置把握) |
| camera_front_to_back.urdf | 奥行き方向(+Y方向)を向いているカメラの定義 | [PyBullet] [カメラ] 2軸ロボットアームを動かす Part7 (複数カメラによる把持物体の位置把握) |
| camera_left_to_right.urdf | 右方向(+X方向)を向いているカメラの定義 | [PyBullet] [カメラ] 2軸ロボットアームを動かす Part7 (複数カメラによる把持物体の位置把握) |
| camera_right_to_left.urdf | 左方向(-X方向)を向いているカメラの定義 | [PyBullet] [カメラ] 2軸ロボットアームを動かす Part7 (複数カメラによる把持物体の位置把握) |
| camera_up_to_down.urdf | 下方向(-Z方向)を向いているカメラの定義 | [PyBullet] [カメラ] 2軸ロボットアームを動かす Part7 (複数カメラによる把持物体の位置把握) |
| environment_2dof.urdf | 2軸ロボットアームの環境を定義 | 2軸ロボットアームの強化学習 Part1 (環境作成) |
| grasp_object.urdf | 把持物体の定義 | [PyBullet] 2軸ロボットアームを動かす Part5 (干渉物が存在する環境下にて物体把持) |
| robot_2dof_hand.urdf | グリッパー付き2軸ロボットアームの定義 | 2軸ロボットアームの強化学習 Part1 (環境作成) |
| robot_2dof.urdf | グリッパーなし2軸ロボットアームの定義の定義 | [PyBullet] 2軸ロボットアームを動かす Part5 (干渉物が存在する環境下にて物体把持) |
上表内のファイルに関しては,以前の記事にて説明済のため,本記事では割愛する.表の列「リンク先」に記事のリンクを記載したため,参照してください.
全体のソースコード
はじめに,本記事で使用する全体のソースコードについて説明する.
その後,重要な箇所を抜粋して別途解説をしていく.
TODO 再確認 ↓
ソースコードとして,下表の15ファイルを作成する.
| ファイル名 | 概要 | 保存されているフォルダ名 | リンク先 |
|---|---|---|---|
| constant.py | 定数の定義 | - | - |
| main.py | 全体的なメイン処理 | - | - |
| pybullet_environment.py | PyBulletの環境 | - | [PyBullet] [カメラ] 2軸ロボットアームを動かす Part7 (複数カメラによる把持物体の位置把握) |
| pybullet_grasp.py | PyBulletの把持物体 | - | 2軸ロボットアームの強化学習 Part1 (環境作成) |
| pybullet_gripper.py | PyBulletのグリッパー | - | [PyBullet] [カメラ] 2軸ロボットアームを動かす Part7 (複数カメラによる把持物体の位置把握) |
| pybullet_robot.py | PyBulletのロボット | - | [PyBullet] [カメラ] 2軸ロボットアームを動かす Part7 (複数カメラによる把持物体の位置把握) |
| pybullet_camera.py | PyBulletのカメラ | - | [PyBullet] [カメラ] 2軸ロボットアームを動かす Part7 (複数カメラによる把持物体の位置把握) |
| pybullet_agent_controller.py | PyBulletのエージェント制御 | - | - |
| BaseAgent.py | PyBulletのエージェントの抽象クラス | Agent | - |
| RandomAgent.py | PyBulletのランダムに動くエージェント | Agent | - |
| MonteCarlo.py | PyBulletのモンテカルロ法で学習するエージェント | Agent | - |
| pybullet_environment_controller.py | PyBulletの強化学習用の環境制御 | - | 2軸ロボットアームの強化学習 Part1 (環境作成) |
| BaseEnvironment.py | PyBulletの強化学習用の環境の抽象クラス | Environment | 2軸ロボットアームの強化学習 Part1 (環境作成) |
| DiscretizeEnvironment.py | PyBulletの強化学習用の離散値環境 | Environment | - |
| pybullet_main.py | PyBulletのメイン処理 | - | - |
表の列「リンク先」に記事のリンクを記載したものは,本記事では説明しないため,リンク先を参照ください.表の列「保存されているフォルダ先」にフォルダ名が記載されているものは,フォルダを作成して,フォルダ内にファイルを保存してください.
本記事で説明するファイルは下表の通りである.
| ファイル名 | 概要 |
|---|---|
| constant.py | 定数の定義 |
| main.py | 全体的なメイン処理 |
| pybullet_agent_controller.py | PyBulletのエージェント制御 |
| BaseAgent.py | PyBulletのエージェントの抽象クラス |
| RandomAgent.py | PyBulletのランダムに動くエージェント |
| MonteCarlo.py | PyBulletのモンテカルロ法で学習するエージェント |
| DiscretizeEnvironment.py | PyBulletの強化学習用の離散値環境 |
| pybullet_main.py | PyBulletのメイン処理 |
定数の定義 (constant.py)
定数を定義する constant.py について説明する.
# 複数ファイルで使用する定数の定義
from enum import Enum
from enum import auto
# 次元数を定義
DIMENTION_NONE = -1 # 未定義
DIMENTION_2D = 2 # 2次元
DIMENTION_3D = 3 # 3次元
DIMENTION_6D = 6 # 6次元
# 重力
GRABITY_VALUE = 9.81
# 0割を防ぐための定数
EPSILON = 1e-6
# フォルダ名
URDF_FOLDER_NAME = "URDF" # 全URDFを一つにまとめたフォルダ名
RESULT_FOLDER_NAME = "Result" # 学習フェーズ内の結果を保存するフォルダ
# 補間方法の定義
class INTERPOLATION(Enum):
"""
補間方法
"""
NONE = "none" # 未定義
JOINT = "joint" # 関節補間
POSITION = "pos" # 位置補間
# ロボットアームが保存されている URDF ファイル名
class ROBOTURDF(Enum):
"""
ロボットのURDFファイル名
"""
# 2軸ロボットアーム
DOF2 = f"{URDF_FOLDER_NAME}/robot_2dof.urdf" # ハンド(グリッパ)なし
DOF2_HAND = f"{URDF_FOLDER_NAME}/robot_2dof_hand.urdf" # ハンド(グリッパ)付き
# カメラが保存されている URDF ファイル名
class CAMERAURDF(Enum):
"""
カメラのURDFファイル名
"""
# X軸方向に向いているカメラ
RIGHT2LEFT = f"{URDF_FOLDER_NAME}/camera_right_to_left.urdf" # 左向き(-X方向)のカメラ
LEFT2RIGHT = f"{URDF_FOLDER_NAME}/camera_left_to_right.urdf" # 右向き(+X方向)のカメラ
# Y軸方向に向いているカメラ
FRONT2BACK = f"{URDF_FOLDER_NAME}/camera_front_to_back.urdf" # 奥向き(+Y方向)のカメラ
BACK2FRONT = f"{URDF_FOLDER_NAME}/camera_back_to_front.urdf" # 手前向き(-Y方向)のカメラ
# Z軸方向に向いているカメラ
UP2DOWN = f"{URDF_FOLDER_NAME}/camera_up_to_down.urdf" # 下向き(-Z方向)のカメラ
# カメラ数を定義する定数
class CAMERANUM(Enum):
"""
カメラ数
"""
SINGLE = 1 # 1つのカメラ
MULTI = 5 # 複数のカメラ
# 環境URDFに関する定数
class ENVURDF(Enum):
"""
環境のURDFに関する定数
"""
TWODOF = f"{URDF_FOLDER_NAME}/environment_2dof.urdf" # 2軸ロボットアーム
# 強化学習の環境に関する定数
class ENV(Enum):
"""
強化学習の環境に関する定数
"""
TWODOF = 0 # 2軸ロボットアーム
# 強化学習のエージェントを定義する定数
class AGENT(Enum):
"""
強化学習のエージェント
"""
RANDOM = 0 # ランダムに行動するエージェント
MONTECARLO = auto() # モンテカルロ法に沿って行動するエージェント
# 強化学習のフェーズを定義する定数
class REIN_PHASE(Enum):
"""
強化学習のフェーズ
"""
LEARN = 0 # 学習フェーズ
IMITATION = auto() # 学習の再現フェーズ
INFERENCE = auto() # 学習後の推論フェーズ
全体的なメイン処理 (main.py)
全体的なメイン処理を定義する main.py について説明する.
# Pybullet (Pythonでの3次元物理シミュレータ) による2軸ロボットアームの可視化
# 標準ライブラリの読み込み
import numpy as np
import glob
from tkinter import messagebox
import csv
from natsort import natsorted
# 自作モジュールの読み込み
from pybullet_main import MainPyBulletRobot
from constant import *
CONST_SEED = 1 # シード値 (常に同じ結果としたいから)
HAND_FLG = True # ハンドの装着有無
# ロボットの関節数 ↓
N_JOINTS = DIMENTION_2D # 2軸ロボットアーム
# ロボットの関節数 ↑
# カメラ数 ↓
# N_CAMERAS = CAMERANUM.SINGLE.value # 1台のカメラ
N_CAMERAS = CAMERANUM.MULTI.value # 複数台のカメラ
# カメラ数 ↑
# PyBulletの環境 ↓
ENV_URDF = ENVURDF.TWODOF.value # 2軸ロボットアーム
# PyBulletの環境 ↑
# 強化学習のエージェント ↓
# AGENT_TYPE = AGENT.RANDOM.value # ランダム法
AGENT_TYPE = AGENT.MONTECARLO.value # モンテカルロ法
# 強化学習のエージェント ↑
# 強化学習の環境 ↓
ENV_TYPE = ENV.TWODOF.value # 2軸ロボットアーム
# 強化学習の環境 ↑
# 強化学習の学習フェーズ ↓
REINFORCE_LEARN = REIN_PHASE.LEARN # 学習フェーズ
# REINFORCE_LEARN = REIN_PHASE.IMITATION # 学習の再現フェーズ
# REINFORCE_LEARN = REIN_PHASE.INFERENCE # 学習後の推論フェーズ
# 強化学習の学習フェーズ ↑
# 強化学習の再現フェーズの定数 ↓
REINFORCE_IMITATION_IDX = 0 # 強化学習の再現フェーズ時のファイル番号
# 強化学習の再現フェーズの定数 ↑
def __get_all_action_files():
"""
フォルダ内に保存されている行動ファイルを全部取得
戻り値
list[str]: 全部の行動ファイル
"""
# フォルダ内のCSVで保存されている行動ファイル名を取得
all_action_files = glob.glob(f"{RESULT_FOLDER_NAME}/*.csv")
# ファイル名を昇順に並び替える
all_action_files = natsorted(all_action_files)
return all_action_files
def __print_episode_from_action_file_name(action_file):
"""
行動ファイル名のエピソード番号を画面に表示
パラメータ
action_file (str): 行動ファイル
"""
# ファイル名から,エピソード番号の取得
# ファイル名は episode_{エピソード番号}.csv として,設計している
# "_" 以降の文字列を取得
under_score_split = action_file.split('_')[1]
# "." で文字列を分割
extension_split = under_score_split.split('.')
# エピソード番号を取得
episode = int(extension_split[0])
# エピソード番号の表示
# print(f"episode num = {episode}")
return episode
def __get_action_file_from_list(idx):
"""
リストから行動ファイルを取得
パラメータ
idx (int): リストの要素番号
戻り値
str: 行動ファイル
"""
# フォルダ内に保存されている行動ファイルを全部取得
all_action_files = __get_all_action_files()
# パラメータ idx の範囲確認
if (idx < 0 or idx >= len(all_action_files)):
# 範囲外
raise ValueError(f"idx is abnormal. idx is {idx}")
# 要素番号に応じた行動ファイル
selected_action_file = all_action_files[idx]
# 行動ファイル内のエピソード番号を表示
__print_episode_from_action_file_name(selected_action_file)
return selected_action_file
def __print_all_actions_count():
"""
全行動数を表示
"""
# 全行動ファイルを取得
all_action_files = __get_all_action_files()
for action_file in all_action_files:
# エピソード番号の表示
episode = __print_episode_from_action_file_name(action_file)
# ファイルオープン
with open(action_file, "r") as f:
# 行動をファイルから2次元配列の形式で取得
actions = csv.reader(f)
# 全行動の実行
for list_action in actions:
print(f"{episode} 回目の結果= {len(list_action)}")
def main():
"""
メイン処理
"""
# 把持対象物が保存されている URDF ファイル名
grasp_urdf = f"{URDF_FOLDER_NAME}/grasp_object.urdf"
# 探索空間を指定
interpolation = INTERPOLATION.JOINT.value # 関節空間
# Pybulletを使用するインスタンス作成
my_robot = MainPyBulletRobot(interpolation, N_JOINTS, ENV_URDF, grasp_urdf, N_CAMERAS, hand=HAND_FLG, learn=REINFORCE_LEARN)
# シード値の設定
np.random.seed(CONST_SEED)
# 強化学習の再現フェーズ時のファイルを取得
file_name = ""
if REINFORCE_LEARN == REIN_PHASE.IMITATION:
file_name = __get_action_file_from_list(REINFORCE_IMITATION_IDX)
# 強化学習の実行
my_robot.run(AGENT_TYPE, ENV_TYPE, imitation_file_name=file_name)
if REINFORCE_LEARN == REIN_PHASE.LEARN:
# 学習時はDIRECTモードであり,学習が完了したことを知らせたいから,メッセージボックスを採用
messagebox.showinfo(
"Fin ReinForcement",
"強化学習の実行が終了しました"
)
if __name__ == "__main__":
# 本ファイルがメインで呼ばれた時の処理
main()
PyBulletのエージェント制御 (pybullet_agent_controller.py)
PyBulletのエージェント制御を定義する pybullet_agent_controller.py について説明する.
# エージェント制御クラスの作成
from constant import AGENT # エージェント定数
from Agent.BaseAgent import BaseAgent # ベースエージェントクラス (抽象クラス)
from Agent.RandomAgent import RandomAgent # ランダムエージェントクラス
from Agent.MontecarloAgent import MonteCarloAgent # モンテカルロエージェントクラス
class PyBulletAgentController:
"""
エージェント制御クラス
プロパティ
メソッド
public
protected
private
"""
# 定数の定義
def __init__(self, agent_type: AGENT, n_action, state_dim):
"""
コンストラクタ
パラメータ
agent_type(AGENT): エージェント
n_action(int): 行動数
state_dim(int): 状態の次元数
"""
# エージェントクラスの取得
agent_cls = self.__get_agent_class(agent_type)
# エージェントクラスのインスタンス作成
self.__agent: BaseAgent = agent_cls(n_action)
# エージェントタイプをプロパティに保存
self.__agent_type = agent_type
def __get_agent_class(self, agent_type: AGENT):
"""
エージェントクラスの取得
パラメータ
agent_type(AGENT): エージェントタイプ
戻り値
エージェントに応じたクラス
"""
# エージェント番号とエージェントクラスを保存する辞書型データの定義
agents = {
AGENT.RANDOM.value: RandomAgent,
AGENT.MONTECARLO.value: MonteCarloAgent
}
# エージェントクラスの定義
agent_cls = None
for key, value in agents.items():
if agent_type == key:
# エージェント番号が一致
agent_cls = value
break
if agent_cls is None:
# エージェント番号が一致しなかった
raise ValueError(f"agent is abnormal. agent is {agent_type}")
return agent_cls
def set_epsilon(self, value):
"""
探索確率である ε の設定
パラメータ
value(float): 設定値
"""
self.__agent.set_epsilon(value)
def get_action(self, state):
"""
行動の取得
パラメータ
state(tuple): 状態
戻り値
int: 行動
"""
return self.__agent.get_action(state)
def reset(self):
"""
初期化
"""
self.__agent.reset()
def update(self):
"""
1エピソード分のデータで更新
"""
self.__agent.update()
def add(self, state, action, reward):
"""
データの追加
パラメータ
state(numpy.ndarray): 状態
action(int): 行動
reward(float): 報酬
"""
self.__agent.add(state, action, reward)
def save(self):
"""
学習データの保存
"""
self.__agent.save()
def load(self):
"""
学習データの読み込み
"""
self.__agent.load()
PyBulletのエージェントの抽象クラス (BaseAgent.py)
PyBulletのエージェントの抽象クラスを定義する BaseAgent.py について説明する.
# 強化学習の全エージェントのベースを定義
class BaseAgent:
"""
全エージェントのベースクラス (抽象クラス)
プロパティ
メソッド
public
get_action(): 行動の取得
reset(): 初期化
update(): 更新
add(): データの追加
set_epsilon(): 探索確率の設定
"""
# 定数の定義
# プロパティのゲッター ↓
@property
def Q(self):
"""
行動価値関数の取得
"""
raise NotImplementedError("Q() is necessary override.")
@property
def V(self):
"""
状態価値関数の取得
"""
raise NotImplementedError("V() is necessary override.")
# プロパティのゲッター ↑
def set_epsilon(self, value):
"""
探索確率である ε の設定
パラメータ
value(float): 設定値
"""
raise NotImplementedError("set_epsilon() is necessary override.")
def get_action(self, state):
"""
行動の取得
パラメータ
state(numpy.ndarray): 状態
戻り値
int: 行動
"""
raise NotImplementedError("get_action() is necessary override.")
def reset(self):
"""
初期化
"""
raise NotImplementedError("reset() is necessary override.")
def update(self):
"""
データの更新
"""
raise NotImplementedError("update() is necessary override.")
def add(self, state, action, reward):
"""
データの追加
パラメータ
state(numpy.ndarray): 状態
action(int): 行動
reward(float): 報酬
"""
raise NotImplementedError("add() is necessary override.")
def save(self):
"""
学習データの保存
"""
raise NotImplementedError("save() is necessary override.")
def load(self):
"""
学習データの読み込み
"""
raise NotImplementedError("load() is necessary override.")
PyBulletのランダムに動くエージェント (RandomAgent.py)
PyBulletのランダムに動くエージェントを定義する RandomAgent.py について説明する.
# ランダムエージェントの作成
# 外部ライブラリの読み込み
import numpy as np
# 自作モジュールの読み込み
from .BaseAgent import BaseAgent
class RandomAgent(BaseAgent):
"""
ランダムエージェントのクラス
プロパティ
メソッド
public
get_action(): 行動の取得
reset(): 初期化
update(): データの更新
add(): データの追加
"""
# 定数の定義
def __init__(self, n_action):
"""
コンストラクタ
パラメータ
n_action(int): 行動数
"""
self.__n_action = n_action
def set_epsilon(self, value):
"""
探索確率である ε の設定
パラメータ
value(float): 設定値
"""
# 何もしない
pass
def get_action(self, state):
"""
行動の取得
パラメータ
state(tuple): 状態
戻り値
int: 行動
"""
# 行動をランダムに選択
action = np.random.choice(range(self.__n_action))
return int(action)
def reset(self):
"""
初期化
"""
# 何もしない
pass
def update(self):
"""
データの更新
"""
# 何もしない
pass
def add(self, state, action, reward):
"""
データの追加
パラメータ
state(numpy.ndarray): 状態
action(int): 行動
reward(float): 報酬
"""
# 何もしない
pass
def save(self):
"""
学習データの保存
"""
# 何もしない
pass
def load(self):
"""
学習データの読み込み
"""
# 何もしない
pass
PyBulletのモンテカルロ法で学習するエージェント (MontecarloAgent.py)
PyBulletのモンテカルロ法で学習するエージェントを定義する MontecarloAgent.py について説明する.
# モンテカルロエージェントの作成
# 外部ライブラリの読み込み
import numpy as np
from collections import defaultdict
import json
# 自作モジュールの読み込み
from .BaseAgent import BaseAgent
class MonteCarloAgent(BaseAgent):
"""
モンテカルロエージェントのクラス
プロパティ
メソッド
public
get_action(): 行動の取得
reset(): 初期化
update(): データの更新
add(): データの追加
"""
# 定数の定義
_GAMMA = 0.9 # 割引率
_ALPHA = 0.1 # 更新量
# 探索確率に関する定数
_EPSILON_MIN = 0.1 # 探索の最小確率
_EPSILON_MAX = 0.9 # 探索の最大確率
_EPSILON_DECAY = 0.9999 # 探索確率の倍率
__INITIAL_Q_VALUE = 0 # 行動価値関数の初期値
__PARAMATER_FILE = "montecarlo_param.json" # パラメータを保存する JSON ファイル
def __init__(self, n_action):
"""
コンストラクタ
パラメータ
n_action(int): 行動数
"""
# 行動数
self.__n_action = n_action
# 探索確率
self.__epsilon = self._EPSILON_MAX
# メモリー
self.__memory = []
# 全状態・行動の行動価値関数を辞書型で定義
self.__Q = defaultdict(lambda: self.__INITIAL_Q_VALUE)
def __update_epsilon(self):
"""
探索確率の更新
"""
if self.__epsilon > self._EPSILON_MIN:
# 探索確率の修正
self.__epsilon *= self._EPSILON_DECAY
print(f"self.__epsilon = {self.__epsilon}")
def set_epsilon(self, value):
"""
探索確率である ε の設定
パラメータ
value(float): 設定値
"""
if value >= 0.0 and value <= 1.0:
self.__epsilon = value
def get_action(self, state):
"""
行動の取得
パラメータ
state(tuple): 状態
戻り値
int: 行動
"""
if np.random.rand() < self.__epsilon:
# ランダム探索
action = np.random.choice(self.__n_action)
else:
# 行動価値関数が最大となる行動を活用
Qs = [self.__Q[state, a] for a in range(self.__n_action)]
action = np.argmax(Qs)
return int(action)
def reset(self):
"""
初期化
"""
# メモリーの初期化
self.__memory.clear()
def update(self):
"""
データの更新
"""
# 収益の保存
G = 0.0
# データは初期状態から終了状態の順番に入っていて,収益を計算するために,終了状態からデータを取得する
for data in reversed(self.__memory):
# データを一つ一つに分ける
state, action, reward = data
# 収益の計算 (収益 = 報酬 + 割引率 * 収益)
G = reward + self._GAMMA * G
# 行動価値関数のキー
key = (state, action)
# 行動価値関数の更新
self.__Q[key] = self.__Q[key] + self._ALPHA * (G - self.__Q[key])
# 探索確率の更新
self.__update_epsilon()
def add(self, state, action, reward):
"""
データの追加
パラメータ
state(numpy.ndarray): 状態
action(int): 行動
reward(float): 報酬
"""
# データを1つにまとめる
data = (state, action, reward)
# メモリーにデータを追加
self.__memory.append(data)
def save(self):
"""
学習データの保存
"""
# JSONファイルに保存するデータを1つにまとめる
save_datas = {
# 行動価値関数の保存
"Q": {str(k): v for k, v in self.__Q.items()}
}
# ファイルオープン
with open(self.__PARAMATER_FILE, "w") as f:
# データをJSONファイルに保存する
json.dump(save_datas, f)
def load(self):
"""
学習データの読み込み
"""
# ファイルオープン
with open(self.__PARAMATER_FILE, "r") as f:
# データを読み込む
datas = json.load(f)
# 行動価値関数をメンバ変数に保存
Q = datas["Q"]
self.__Q = {eval(k): v for k, v in Q.items()}
PyBulletの強化学習用の離散値環境 (DiscretizeEnvironment.py)
PyBulletの強化学習用の離散値環境を定義する DiscretizeEnvironment.py について説明する.
# 強化学習の全環境のベースを定義
# 外部ライブラリの読み込み
import numpy as np
from enum import Enum
from enum import auto
from abc import ABC, abstractmethod
import pybullet as p # PyBullet
import time
# 自作モジュールの読み込み
from constant import *
from pybullet_robot import PyBulletRobotController
class _DiscritizeBaseEnvironment(ABC):
"""
状態が離散値のベースクラス (抽象クラス)
プロパティ
メソッド
public
reset(): 初期化
step(): 1ステップ実行
"""
# 定数の定義
# ロボットに関する定数 ↓
_ROBOT_MOVE_VAL = round(np.deg2rad(5), 2) # 関節角度の移動量 [rad]
_ROBOT_JOINT_MAX = np.pi # 関節の最大値 [rad]
_ROBOT_JOINT_MIN = -np.pi # 関節の最小値 [rad]
# ロボットに関する定数 ↑
# オーバーライド必須の定数 ↓
_DIMENTION = DIMENTION_NONE # 次元数
# 行動に関する定数 ↓
_N_ACTION = 0 # 行動数
class _ACTION(Enum):
"""
行動に関する定数
"""
pass
# 行動に関する定数 ↑
# オーバーライド必須の定数 ↑
# 状態に関する定数 ↓
# _STATE_NUM = 73 # 状態数 (73は5度刻みになる)
_STATE_NUM = 37 # 状態数 (37は10度刻みになる)
_STATE_GRID = np.linspace(_ROBOT_JOINT_MIN, _ROBOT_JOINT_MAX, _STATE_NUM)
# 状態に関する定数 ↑
_THRESHOLD_GOAL = 0.1 # 手先位置と目標位置との閾値 [m]
_THRESHOLD_INIT = 0.001 # 現在間接角度と初期間接角度との閾値 [rad]
# 状態に関する定数 ↓
_STATE_START = (int(_STATE_NUM/2), int(_STATE_NUM/2)) # 初期関節状態
# 状態に関する定数 ↑
def __init__(self, robot: PyBulletRobotController, state_goal, sim_sleep_time_step):
"""
コンストラクタ
パラメータ
robot(PyBulletRobotController): ロボット制御クラス
state_goal(numpy.ndarray): 目標状態(関節角度 [rad])
sim_sleep_time_step(float): 1ステップ終了後のシミュレーションの待機時間 [sec]
"""
# 定数のオーバーライド確認
self.__chk_override_constant()
# 引数の次元数確認
if len(state_goal) != self._DIMENTION:
# 引数が異常
raise ValueError(f"len(state_goal) is abnormal. len(state_goal) is {len(state_goal)}")
# 目標状態の更新
self._state_goal = state_goal
# 初期状態の更新
self._state_start = self._STATE_START
# ロボットの更新
self._robot = robot
# シミュレーションの待機時間を更新
self._sim_sleep_time_step = sim_sleep_time_step
# 状態の初期化
self.reset()
def __chk_override_constant(self):
"""
定数のオーバーライド確認
"""
# 比較元と比較先が一致していたら,異常とする辞書型データの作成
compare_match_datas = {
"self._DIMENTION": [self._DIMENTION, DIMENTION_NONE],
"self._N_ACTION": [self._N_ACTION, 0]
}
# 比較元と比較先が不一致なら,異常とする辞書型データの作成
compare_not_match_datas = {
"len(self._ACTION)": [len(self._ACTION), self._N_ACTION]
}
# オーバーライドが正しいかの確認
for tag, datas in compare_match_datas.items():
# データから,比較元と比較先を取得
sorce, target = datas
if sorce == target:
# オーバーライドしていないから,エラー発報
raise NotImplementedError(f"{tag} is abnormal. {tag} is {sorce}.")
# オーバーライドが正しいかの確認
for tag, datas in compare_not_match_datas.items():
# データから,比較元と比較先を取得
sorce, target = datas
if sorce != target:
# オーバーライドしていないから,エラー発報
raise NotImplementedError(f"{tag} is abnormal. {tag} is {sorce}.")
# プロパティのゲッター ↓
@property
def n_action(self):
"""
行動数を取得
"""
return self._N_ACTION
@property
def state_goal(self):
"""
目標状態(関節角度[rad])を取得
"""
return self._state_goal
@property
def state_start(self):
"""
初期状態(関節角度[rad])を取得
"""
return self._state_start
@property
def state_dimention(self):
"""
状態の次元数を取得
"""
return self._DIMENTION
# プロパティのゲッター ↑
# public ↓
@abstractmethod
def reset(self):
"""
初期化
戻り値
numpy.ndarray: 初期状態
"""
pass
@abstractmethod
def step(self, action):
"""
1ステップ実行
パラメータ
action(numpy.ndarray): 行動
戻り値
numpy.ndarray: 次の状態
float: 報酬
bool: 完了フラグ
"""
pass
class TwoDOFEnv(_DiscritizeBaseEnvironment):
"""
2軸ロボットアームの環境クラス
プロパティ
メソッド
public
protected
private
"""
# 定数の定義
# オーバーライド必須の定数 ↓
_DIMENTION = DIMENTION_2D # 次元数
# 行動に関する定数 ↓
_N_ACTION = 9 # 行動数
class _ACTION(Enum):
"""
行動に関する定数
"""
# 定数名は "関節1の移動角度_関節2の移動角度" で定義
# 関節1の角度をプラス ↓
PLUS_PLUS = 0
PLUS_NONE = auto()
PLUS_MINUS = auto()
# 関節1の角度をプラス ↑
# 関節1の角度は変わらない ↓
NONE_PLUS = auto()
NONE_NONE = auto()
NONE_MINUS = auto()
# 関節1の角度は変わらない ↑
# 関節1の角度をマイナス ↓
MINUS_PLUS = auto()
MINUS_NONE = auto()
MINUS_MINUS = auto()
# 関節1の角度をマイナス ↑
# 行動に関する定数 ↑
# オーバーライド必須の定数 ↑
_REWARD_SUCCESS = 100 # 成功時の報酬
def __init__(self, robot: PyBulletRobotController, state_goal, sim_sleep_time_step):
"""
コンストラクタ
パラメータ
robot(PyBulletRobotController): ロボット制御クラス
state_goal(numpy.ndarray): 目標状態(関節角度 [rad])
sim_sleep_time_step(float): 1ステップ終了後のシミュレーションの待機時間 [sec]
"""
# 親クラスのコンストラクタ
super().__init__(robot, state_goal, sim_sleep_time_step)
# 初期関節角度から,初期状態を取得
self._state_start = self.__cnvrt_state_to_joints(self._STATE_START)
def reset(self):
"""
初期化
戻り値
tuple: 初期状態
"""
# 近傍フラグの初期化
near_flg = False
# 初期状態の位置を計算
init_thetas = self.__cnvrt_state_to_joints(self._STATE_START)
while not near_flg:
# 初期値へ移動
self.__set_thetas_from_state(self._STATE_START)
# 現在位置と現在姿勢の取得
current_pos, current_ori = self._robot.get_ee_pos()
# 位置から角度へ変換
current_thetas = self._robot.convert_pos_to_theta(current_pos, True)
# print(f"init_thetas = {init_thetas}")
# print(f"current_thetas = {current_thetas}")
# 現在角度と初期角度が近傍になれば,ループから抜ける
if (np.linalg.norm(init_thetas - current_thetas) <= self._THRESHOLD_INIT):
near_flg = True
# エージェント位置の初期化
# 初期関節角度を初期状態へ変換
self._agent_state = self._STATE_START
print(f"self._agent_state = {self._agent_state}")
return self._agent_state
def __cnvrt_state_to_joints(self, state):
"""
状態から関節角度に変換
パラメータ
state(tuple): 状態
戻り値
numpy.ndarray: 関節角度
"""
# 戻り値を定義
joints = np.zeros(self._DIMENTION)
for i in range(len(state)):
# 状態から関節角度へ変換
joints[i] = self._STATE_GRID[state[i]]
return joints
def __set_thetas_from_state(self, state):
"""
状態から関節角度を計算してロボットに設定
パラメータ
state(tuple): 状態
"""
# 状態から関節角度に変換
joints = self.__cnvrt_state_to_joints(state)
# print(f"state = {state}")
# print(f"joints = {joints}")
# ロボットに次状態を渡し,動かす
self._robot.set_joint(joints)
# グリッパーの実行
self._robot.run_gripper(open=True)
# 実行
p.stepSimulation()
# シミュレーション実行の待機時間
time.sleep(self._sim_sleep_time_step)
def step(self, action):
"""
1ステップ実行
パラメータ
action(int): 行動
戻り値
tuple: 次の状態
float: 報酬
bool: 完了フラグ
"""
# 行動後の次状態を取得
next_state = self.__next_state(action)
# 状態から関節角度を取得して,ロボットを動かす
self.__set_thetas_from_state(next_state)
# 手先位置と目標位置との距離を計算
dist = self.__calc_dist()
# 報酬の計算
reward = self.__calc_reward(dist)
# 距離が近傍であるかの確認
done = self.__is_closed(dist)
if done:
# 近傍なら,報酬を更新
reward += self._REWARD_SUCCESS
# エージェント位置の更新
self._agent_state = next_state
# print(f"ee_pos = {self._robot.get_ee_pos()}")
# print(f"self._agent_state = {self._agent_state}")
# print(f"reward = {reward}")
return next_state, reward, done
def __next_state(self, action):
"""
次状態の取得
パラメータ
action(int): 行動
戻り値
tuple: 次状態
"""
# 関節角度の差分を計算
delta_thetas = self.__get_delta_thetas(action)
# 現在の状態から関節角度を取得
thetas = self.__cnvrt_state_to_joints(self._agent_state)
# 次状態の関節角度を計算
next_thetas = thetas + delta_thetas
# 次状態を離散化
next_state = self.__discretize_state(next_thetas)
return next_state
def __get_delta_thetas(self, action):
"""
関節角度の差分を計算
パラメータ
action(int): 行動
戻り値
numpy.ndaray: 関節角度の差分
"""
# 行動をキー,行動内容をバリューとして,辞書型データにまとめる
actions = {
self._ACTION.PLUS_PLUS.value: np.array([ self._ROBOT_MOVE_VAL, self._ROBOT_MOVE_VAL]),
self._ACTION.PLUS_NONE.value: np.array([ self._ROBOT_MOVE_VAL, 0.0 ]),
self._ACTION.PLUS_MINUS.value: np.array([ self._ROBOT_MOVE_VAL, -self._ROBOT_MOVE_VAL]),
self._ACTION.NONE_PLUS.value: np.array([ 0.0 , self._ROBOT_MOVE_VAL]),
self._ACTION.NONE_NONE.value: np.array([ 0.0 , 0.0 ]),
self._ACTION.NONE_MINUS.value: np.array([ 0.0 , -self._ROBOT_MOVE_VAL]),
self._ACTION.MINUS_PLUS.value: np.array([-self._ROBOT_MOVE_VAL, self._ROBOT_MOVE_VAL]),
self._ACTION.MINUS_NONE.value: np.array([-self._ROBOT_MOVE_VAL, 0.0 ]),
self._ACTION.MINUS_MINUS.value: np.array([-self._ROBOT_MOVE_VAL, -self._ROBOT_MOVE_VAL])
}
# 行動内容を保存
delta_thetas = None
# 辞書型データから,行動に応じた行動内容を取得
for key, value in actions.items():
if action == key:
# 行動が辞書型データに保存されている
delta_thetas = value
break
if delta_thetas is None:
# 行動が辞書型データに保存されていないため,異常
raise ValueError(f"action is abnorma. action is {action}")
return delta_thetas
def __discretize_state(self, state):
"""
状態の離散化
パラメータ
state(numpy.ndarray): 状態
戻り値
tuple: 離散化した状態
"""
# 関節分のデータを保存する領域を確保
joints_idx = [0 for _ in range(self._DIMENTION)]
# 各関節に離散化した状態を保存
for i in range(self._DIMENTION):
joints_idx[i] = int(np.argmin(np.abs(self._STATE_GRID - state[i])))
# print(f"joints_idx = {joints_idx}")
return tuple(joints_idx)
def __calc_dist(self):
"""
手先位置と目標位置との距離[m]を計算
戻り値
float: 手先位置と目標位置との距離 [m]
"""
# 手先位置を取得
ee_pos, ee_ori = self._robot.get_ee_pos()
# 手先位置と目標位置との差分を計算
difference = self._state_goal - ee_pos
# 手先位置と目標位置との距離を計算
dist = np.linalg.norm(difference)
return dist
def __calc_reward(self, dist):
"""
報酬の取得
パラメータ
dist(float): 手先位置と目標位置との距離
戻り値
float: 報酬(手先位置と目標位置との距離のマイナス値)
"""
# 報酬は手先位置と目標位置との距離のマイナス値とする
reward = -dist
return reward
def __is_closed(self, dist):
"""
手先位置と目標位置との距離が近傍であるかの判定
パラメータ
dist(float): 手先位置と目標位置との距離
戻り値
bool: True / False = 近傍である / 近傍ではない
"""
return dist <= self._THRESHOLD_GOAL
PyBulletのメイン処理 (pybullet_main.py)
PyBulletのメイン処理を定義する pybullet_main.py について説明する.
# PyBulletのメイン処理を記載
# ライブラリの読み込み
import pybullet as p # PyBullet
import pybullet_data # PyBulletで使用するデータ
import numpy as np # 数値計算ライブラリ
import os # OSライブラリ (ディレクトリ作成に使用する)
import shutil # ディレクトリの削除に使用
import csv # CSVファイルの読み書き
# サードパーティの読み込み
# 自作モジュールの読み込み
from constant import *
from pybullet_environment import PyBulletEnvironment # 環境に関して
from pybullet_grasp import PyBulletGraspObject # 把持物体に関して
from pybullet_robot import PyBulletRobotController # ロボットに関して
from pybullet_interference import PyBulletInteference # 干渉判定に関して
from pybullet_camera import PyBulletCameraContoller # カメラに関して
from pybullet_agent_controller import PyBulletAgentController # 強化学習のエージェントに関して
from pybullet_environment_controller import PyBulletEnvironmentController # 強化学習の環境に関して
class MainPyBulletRobot:
"""
PyBulletのメインクラス
プロパティ
__robot(PyBulletRobotController): ロボットアームの制御クラス
__interpolation(str): 探索空間 (直交空間/関節空間)
__environment(PyBulletEnvironment): 環境クラス
__camera(PyBulletCamera): カメラクラス
__env(PyBulletEnvironmentController): 強化学習の環境制御クラス
__agent(PyBulletAgentController): 強化学習のエージェント制御クラス
__learn(REIN_PHASE): 強化学習のフェーズ
メソッド
public
メイン処理関連
run(): 実行 (始点から終点まで,干渉しない経路を生成)
運動学関連
convert_pos_to_theta(): 位置から関節角度に変換 (クラス外で使う用)
private
メイン処理関連
__path_planning(): 始点から終点までの経路生成
__post_path_planning(): 経路生成の後処理 (経路生成成功時だけ実装)
"""
# 定数の定義
__MAX_EPISODES = 12000 # 強化学習のエピソード数
__N_SAVE_EPISODES = 100 # 保存するエピソード数
def __init__(self, interpolation, n_robot_joint, environment_urdf, grasp_urdf, n_cameras, hand=False, learn:REIN_PHASE=REIN_PHASE.LEARN):
"""
コンストラクタ
パラメータ
interpolation(str): 補間方法 (関節空間/位置空間)
n_robot_joint(int): ロボットアームの関節数(2, 3, 6だけ)
environment_urdf(str): 環境のファイル名 (urdf)
grasp_urdf(str): 把持物体のファイル名 (urdf)
n_cameras(CAMERANUM): カメラの数
hand(bool): ハンドの装着有無 True/False = 装着/未装着
learn(REIN_PHASE): 強化学習のフェーズ
"""
# PyBulletの初期化
if learn == REIN_PHASE.LEARN:
# 学習時は,後ろで動かし続ける
p.connect(p.DIRECT)
# ファイル保存用のフォルダ削除
self.__remove_folder()
elif (learn == REIN_PHASE.IMITATION) or (learn == REIN_PHASE.INFERENCE):
# 推論または再現では,GUI上のロボットを動かす
p.connect(p.GUI)
else:
# 異常な値
raise ValueError(f"learn is abnormal. learn is {learn}")
# ファイル保存用のフォルダ作成
self.__make_folder()
# プロパティの初期化
self.__learn = learn
# パスの追加
p.setAdditionalSearchPath(pybullet_data.getDataPath())
# シミュレーションの初期化
p.resetSimulation()
# 重力の設定 (下(-z軸)方向の加速度)
p.setGravity(0, 0, -GRABITY_VALUE)
# ロボットの初期化
self.__robot = PyBulletRobotController(n_robot_joint, interpolation, hand)
# 環境の初期化
self.__environment = PyBulletEnvironment(environment_urdf, self.__robot.n_robot_joint)
# 把持物体の初期化
self.__grasp_obj = PyBulletGraspObject(grasp_urdf, self.__robot.n_robot_joint)
# 干渉判定の初期化
self.__interference = PyBulletInteference(self.__robot, self.__environment)
# カメラの初期化
self.__camera = PyBulletCameraContoller(n_cameras)
def __make_folder(self):
"""
ファイル保存用のフォルダ作成
"""
# フォルダが存在していても,エラー発報させない(exist_ok=True)
os.makedirs(RESULT_FOLDER_NAME, exist_ok=True)
def __remove_folder(self):
"""
ファイル保存用のフォルダを削除
"""
# フォルダの存在確認
if os.path.isdir(RESULT_FOLDER_NAME):
# 存在するため,フォルダを削除
shutil.rmtree(RESULT_FOLDER_NAME)
# メイン処理 ↓
def run(self, agent_type: AGENT, env_type: ENV, imitation_file_name: str=''):
"""
実行
始点から終点まで,干渉しない経路を生成
パラメータ
agent_type(AGENT): エージェントタイプ
env_type(ENV): 環境タイプ
imitation_file_name(str): 再現フェーズ用ファイル名
"""
# 把持物体の位置をカメラから取得
end_pos = self.__get_grasp_pos_from_camera()
# 強化学習の環境の設定
self.__env = PyBulletEnvironmentController(env_type, self.__robot, end_pos, self.__learn)
# 強化学習のエージェントの設定
self.__agent = PyBulletAgentController(agent_type, self.__env.n_action, self.__env.state_dimention)
if self.__learn == REIN_PHASE.LEARN:
# 強化学習の学習フェーズ
self.__learning()
elif self.__learn == REIN_PHASE.IMITATION:
# 強化学習の再現フェーズ
self.__imitation(imitation_file_name)
elif self.__learn == REIN_PHASE.INFERENCE:
# 強化学習の推論フェーズ
self.__inference()
else:
# 異常な引数
raise ValueError(f"self.__learn is abnormal. self.__learn is {self.__learn}")
def __learning(self):
"""
強化学習の学習フェーズ
"""
# 全エピソードの報酬
rewards_history = []
# ファイル保存するエピソードのインターバル
save_episode_interval = int(self.__MAX_EPISODES / self.__N_SAVE_EPISODES)
# インターバルが「0」以下での対処方法
save_episode_interval = max(save_episode_interval, 1)
# エピソード分ループ
for episode in range(self.__MAX_EPISODES):
# 強化学習用の環境とエージェントを初期化
state = self.__env.reset()
self.__agent.reset()
# 完了フラグ
done = False
# 1エピソード分の報酬の合計
total_reward = 0
# ループ数の保存
count = 0
# 1エピソード分の行動を保存
action_per_episode = []
print(f"episode = {episode} is start.")
# 完了するまでループ
while not done:
# 状態から行動を取得
action = self.__agent.get_action(state)
# 1ステップ実行
next_state, reward, done = self.__env.step(action)
# データの追加
self.__agent.add(state, action, reward)
# 報酬の更新
total_reward += reward
# 状態の更新
state = next_state
# カウンタの更新
count += 1
# 行動の保存
action_per_episode.append(action)
# 1エピソード分の情報を使って,データの更新
self.__agent.update()
# 報酬を履歴に追加
rewards_history.append(total_reward)
# 行動をファイルに保存
if episode % save_episode_interval == 0:
self.__save_action(episode, action_per_episode)
print(f"count = {count}")
print(f"total_reward = {total_reward}")
print(f"episode = {episode} is fin.")
print()
# パラメータをファイルに書き込む
self.__agent.save()
def __save_action(self, episode, actions):
"""
1エピソード分の行動をファイルに保存
パラメータ
episode (int): エピソード番号
actions (list[int]): 1エピソード分の行動
"""
# ファイル名の作成
file_name = f"{RESULT_FOLDER_NAME}/episode_{episode}.csv"
# CSVファイルに行動を保存
with open(file_name, 'w') as f:
writer = csv.writer(f)
writer.writerow(actions)
def __imitation(self, file_name: str):
"""
強化学習の再現フェーズ
パラメータ
file_name(str): 行動が保存されているファイル
"""
# 環境の初期化
self.__env.reset()
# 1エピソード分の報酬の合計
total_reward = 0
with open(file_name, "r") as f:
# 行動をファイルから2次元配列の形で取得
actions = csv.reader(f)
# 全行動の実行
for list_action in actions:
for str_action in list_action:
# 文字列から,数値型に型変換
int_action = int(str_action)
# 1ステップ実行
next_state, reward, done = self.__env.step(int_action)
print(f"next_state = {next_state}")
print(f"action = {int_action}")
print()
# 報酬の更新
total_reward += reward
print(f"len(list_action) = {len(list_action)}")
print(f"total_reward = {total_reward}")
print()
def __inference(self):
"""
強化学習の推論フェーズ
"""
# パラメータをファイルから読み込む
self.__agent.load()
# 探索確率を 0 として,活用だけとする
self.__agent.set_epsilon(0.0)
# 強化学習用の環境とエージェントを初期化
state = self.__env.reset()
self.__agent.reset()
# 完了フラグ
done = False
# 1エピソード分の報酬の合計
total_reward = 0
# ループ数の保存
count = 0
print("inference is start.")
# 完了するまでループ
while not done:
# 状態から行動を取得
action = self.__agent.get_action(state)
# 1ステップ実行
next_state, reward, done = self.__env.step(action)
# 報酬の更新
total_reward += reward
# 状態の更新
state = next_state
# カウンタの更新
count += 1
print(f"count = {count}")
print(f"total_reward = {total_reward}")
print("inference is fin.")
print()
def __get_grasp_pos_from_direct(self, offset=False):
"""
把持物体の位置を取得 (直接)
パラメータ
offset(bool): オフセットの有無
戻り値
numpy.ndarray: 把持物体の位置
"""
# 把持物体の位置を取得
pos, _ = self.__grasp_obj.get_grasp_pos(offset=offset, dim2=True)
# Numpy型に型変換
pos = np.array(pos)
return pos
def __get_grasp_pos_from_camera(self):
"""
カメラから把持物体の位置を取得
戻り値
numpy.ndarray: 把持物体の位置
"""
# カメラから物体位置(3次元)の取得
pos = self.__camera.get_pos(self.__grasp_obj.grasp_obj_id)
# 今回は2軸ロボットアームだけに対応するため,物体位置を2次元に変換する
pos = pos[:DIMENTION_2D]
# 探索方法に応じた終点に変換
if self.__interference == INTERPOLATION.JOINT:
# 逆運動学により,関節角度を取得
pos = self.__robot.convert_pos_to_theta(pos)
return pos
# メイン処理 ↑
# 運動学関連 ↓
def convert_pos_to_theta(self, pos):
"""
位置から関節角度に変換
パラメータ
pos(numpy.ndarray): 位置 / 関節角度
戻り値
thetas(numpy.ndarray): 関節角度
"""
thetas = self.__robot.convert_pos_to_theta(pos, force=True)
return thetas
# 運動学関連 ↑
p.connect()関数の引数である 'p.DIRECT' と 'p.GUI' に関して説明する.
公式ドキュメントから,'DIRECT'(p.DIRECT) と 'GUI'(p.GUI) の違いを説明している箇所を抜粋して,下図に示す.

違いをまとめると下表の通りとなる.
| モード | 概要 | 使い分け |
|---|---|---|
| DIRECT | 物理エンジンに直接コマンドを送信し,コマンド結果を直接に取得 | 学習フェーズなど,処理を軽くして高速に動かす |
| GUI | GUI(Graphical User Interface) を新規作成し,物理エンジンにコマンドを送信し,GUI上に結果を反映 | 推論フェーズなど,正しく動いているかの確認 (デバッグ) |
強化学習の学習フェーズでは,エピソード数が多いため,処理を軽くしたいために,'DIRECT' モードを採用した.推論フェーズでは,しっかり学習できているかの確認 (デバッグ) をしたいから,'GUI' モードを採用した.また,学習フェーズ時のデータを再現する際もロボットの動きを確認したいから,'GUI' モードを採用した.
PyBulletでロボットを動かす
上記にて,ソースコードを説明した.
main.py ファイルを実施することによって,PyBullet上のロボットを動かしていく.
経路生成の動画
モンテカルロ法に動くエージェントによる経路生成の動画を載せる.
動画1:学習時の経路生成の動画
動画2:学習完了後の経路生成の動画
学習時の経路生成は無駄な行動が多いけど,学習完了後になると無駄な行動が少なくなった.ただし,学習終了後であっても行動が最適とは限らない.
そのため,次回はモンテカルロ法ではなく,他アルゴリズムを採用することで,行動がより最適となるようにする.
おわりに
本記事では,Pythonを使用して,下記内容を実装しました
・エージェントの学習方法としてモンテカルロ法を採用して,PyBullet 内の2軸ロボットアームの強化学習
次記事では,下記内容を実装していきます.
・エージェントの学習方法としてSARSAを採用して,PyBullet 内の2軸ロボットアームの強化学習
参考文献
本記事を作成する上で参考にした内容を記載する.
参考にした記事
・https://qiita.com/pocokhc/items/785e7b021c7c15794dbc
・https://qiita.com/icoxfog417/items/242439ecd1a477ece312
・https://www.skillupai.com/blog/tech/reinforcement-learning/
参考にした書籍
・ゼロから作るDeep Learning ❹ ―強化学習編