はじめに
PyBullet (Python上で動く物理シミュレータ) を使用して,ロボットアームを可視化して,動かしたい.
前記事では,PyBullet (Python上で動く物理シミュレータ) で2軸ロボットアームにグリッパーと複数のカメラを追加して,干渉物が存在しない環境下にて,立方体を把持する経路生成のシミュレーションを実装した.
(https://qiita.com/haruhiro1020/items/e5252faeac3486ce4947)
本記事では,強化学習を実施するための環境作成を実装する.また,エージェントの動きはランダムとして,把持物体の位置へ移動させる.学習していくエージェントに関しては,次記事以降で説明する.
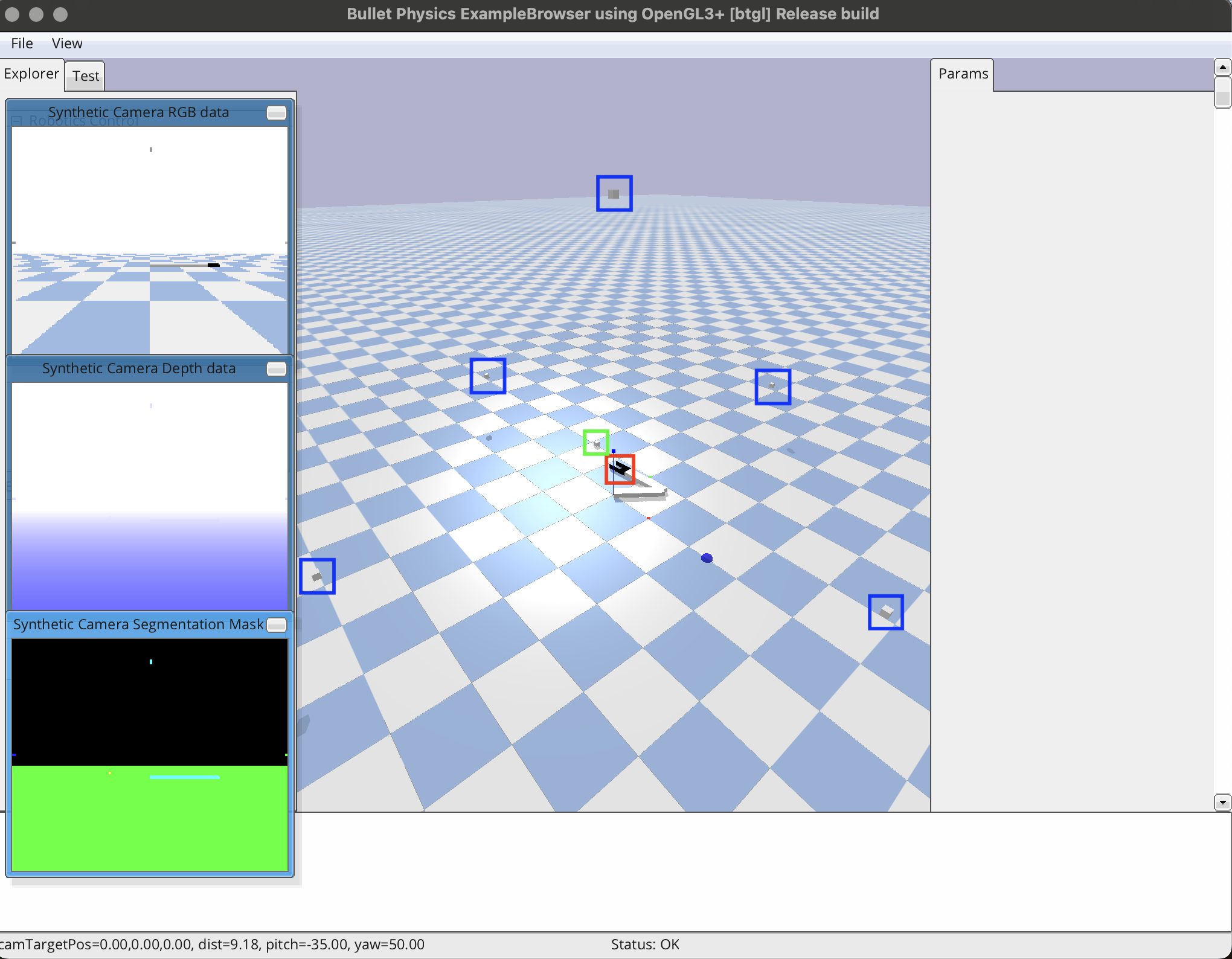
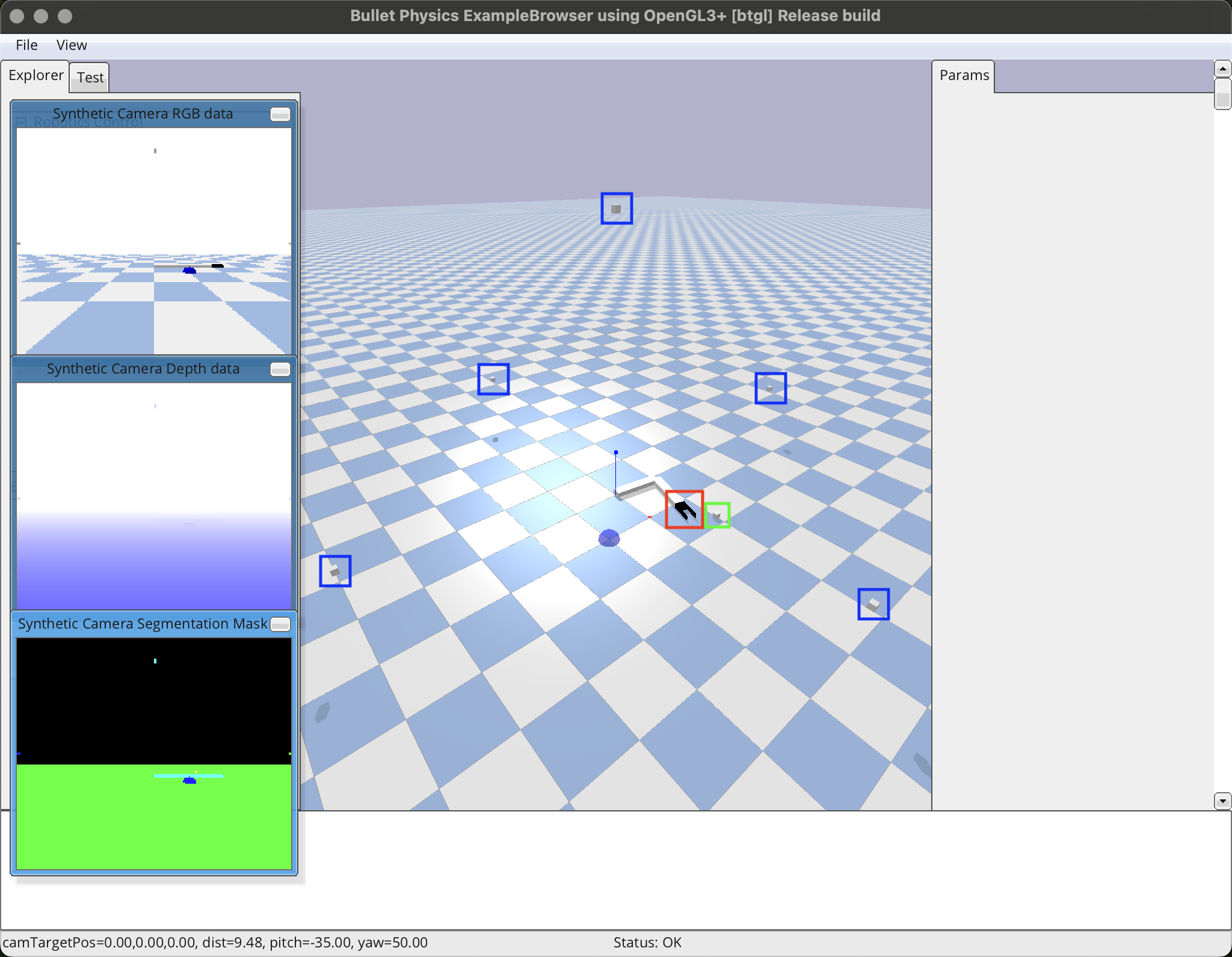
グリッパー付きの2軸ロボットアームを使用して,干渉物が存在しない環境下にて,複数のカメラから把持物体の位置を取得して,物体を把持する(下図はPyBullet上のグリッパー付き2軸ロボットアームである).赤枠がグリッパー,緑枠が把持したい物体,青枠がカメラ,青色の球が初期位置である.
本記事を実施してできる最終的なものは下記動画の通りである.エージェントは学習をせずに,ランダムに動く.
本記事で実装すること
・強化学習の環境を作成
・エージェントは学習せずにランダムな行動
本記事では実装できないこと (将来実装したい内容)
エージェントの学習手法
・モンテカルロ法
・SARSA
・Q学習
・DQN
・Actor-Critic
動作環境
・macOS Sequoia (バージョン15.5)
・Python3 (3.13.3)
・PyBullet (3.25) (物理シミュレータ)
・Numpy (2.3.0) (数値計算用ライブラリ)
PyBullet のインストール方法
PyBullet のインストール方法については前記事にて,説明したため,割愛する.
(前記事 https://qiita.com/haruhiro1020/items/ecc5215234350b663770)
PyBulletの使用方法
Pythonの物理シミュレータであるPyBulletの使用方法について説明する.
下記リンクのPyBullet公式で調べながら,PyBulletを使用している.
・https://pybullet.org/wordpress/
上記リンクを開くと,下図のようなサイトに飛ぶ.使用方法を調べるときは,下図の赤枠内の「PYBULLET QUICKSTART GUIDE」タグをクリックする.
「PYBULLET QUICKSTART GUIDE」タグをクリックすると,下図のようなドキュメントを見ることができる.基本的には,ドキュメントに記載されている関数の使用方法を見て,ソースコードを作成している.

PyBulletの関数の引数や戻り値をもっと知りたいのでしたら,上記ドキュメントを見た方がわかりやすいです.
2軸ロボットアームの定義
本記事で動かしたい,2軸ロボットアームについて説明する.
本記事では,下図のような2軸ロボットアームを考えている.
$\theta_{1}, \theta_{2}$ は,Z軸方向($X, Y$軸に直交する手前方向)へ回転する.
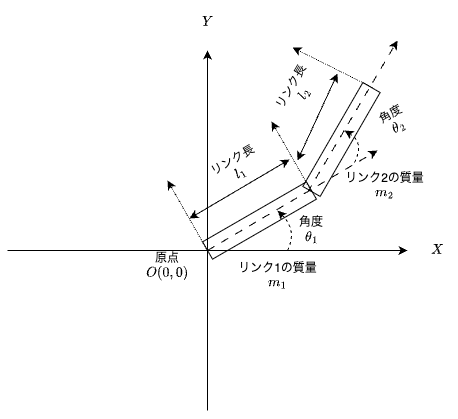
上図のパラメータ $l_{1}, l_{2}, m_{1}, m_{2}$ の値は下表として,考える(値は適当である).
| パラメータ名 | 概要 | 値 |
|---|---|---|
| $l_{1}$ | リンク$1$の長さ | 1.0 [m] |
| $l_{2}$ | リンク$2$の長さ | 1.0 [m] |
| $m_{1}$ | リンク$1$の質量 | 1.0 [kg] |
| $m_{2}$ | リンク$2$の質量 | 1.0 [kg] |
PyBulletで,上図のロボットを使用するために,URDF (Unified Robot Description Format)を作成する必要がある.
グリッパーの定義
本記事では,下図のようなパラレルグリッパーをロボットアームに追加する.
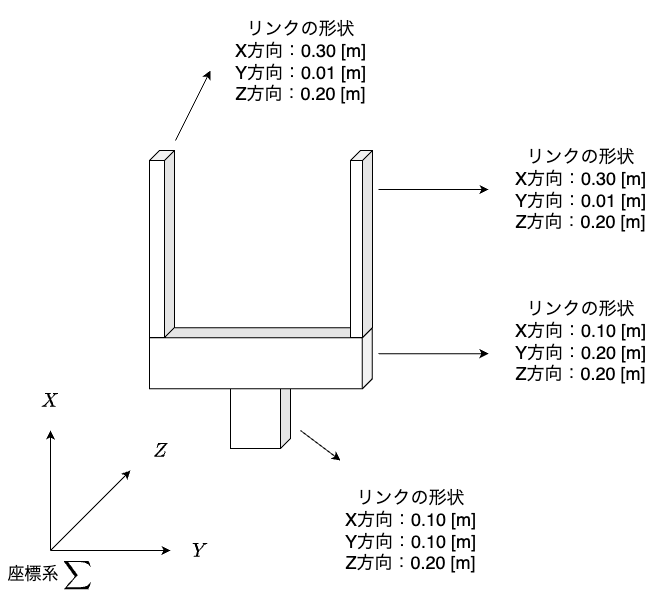
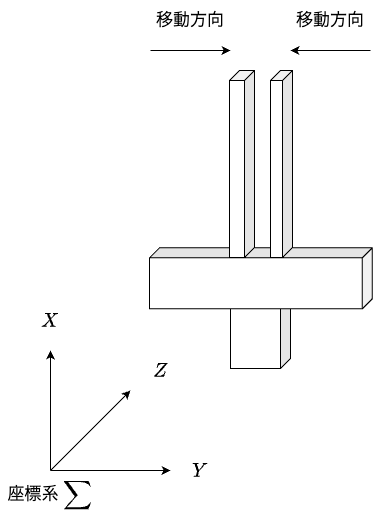
上図はグリッパーが開いた時の画像である.下図はグリッパーを閉じた時の画像である.2本の指の間に把持物体を置いた状態で,グリッパーを閉じることで,物体把持を実施する.
パラレルグリッパーを採用した理由は下記の通りである.
・URDFの作成および制御が容易
・立方体および直方体の場合,接触する面積が大きくなるため,摩擦力が大きくなり滑りにくい
人の手である "多指グリッパー" も存在するが,URDFを作成するのが困難であるため,採用しない.
グリッパー付き2軸ロボットアームのURDF作成
グリッパー付き2軸ロボットアームのURDFを作成する.URDFに関しては,前記事で説明したため,本記事では割愛する.
(前記事 https://qiita.com/haruhiro1020/items/01f661a571c6fe76c551)
カメラによる把持物体の2次元位置を取得
PyBulletでカメラ情報を取得する関数は "getCameraImage" である.関数情報は下図の通りである.

引数に関しての内容は下表の通りである.
| 引数名 | 内容 |
|---|---|
| width | カメラの水平(X軸)解像度のピクセル数 |
| hight | カメラの垂直(Y軸)解像度のピクセル数 |
| viewMatrix | カメラから見た空間(4*4の行列) |
| projectionMatrix | カメラ空間の座標をxyzが$-1~1$に収まるような空間(4*4の行列) |
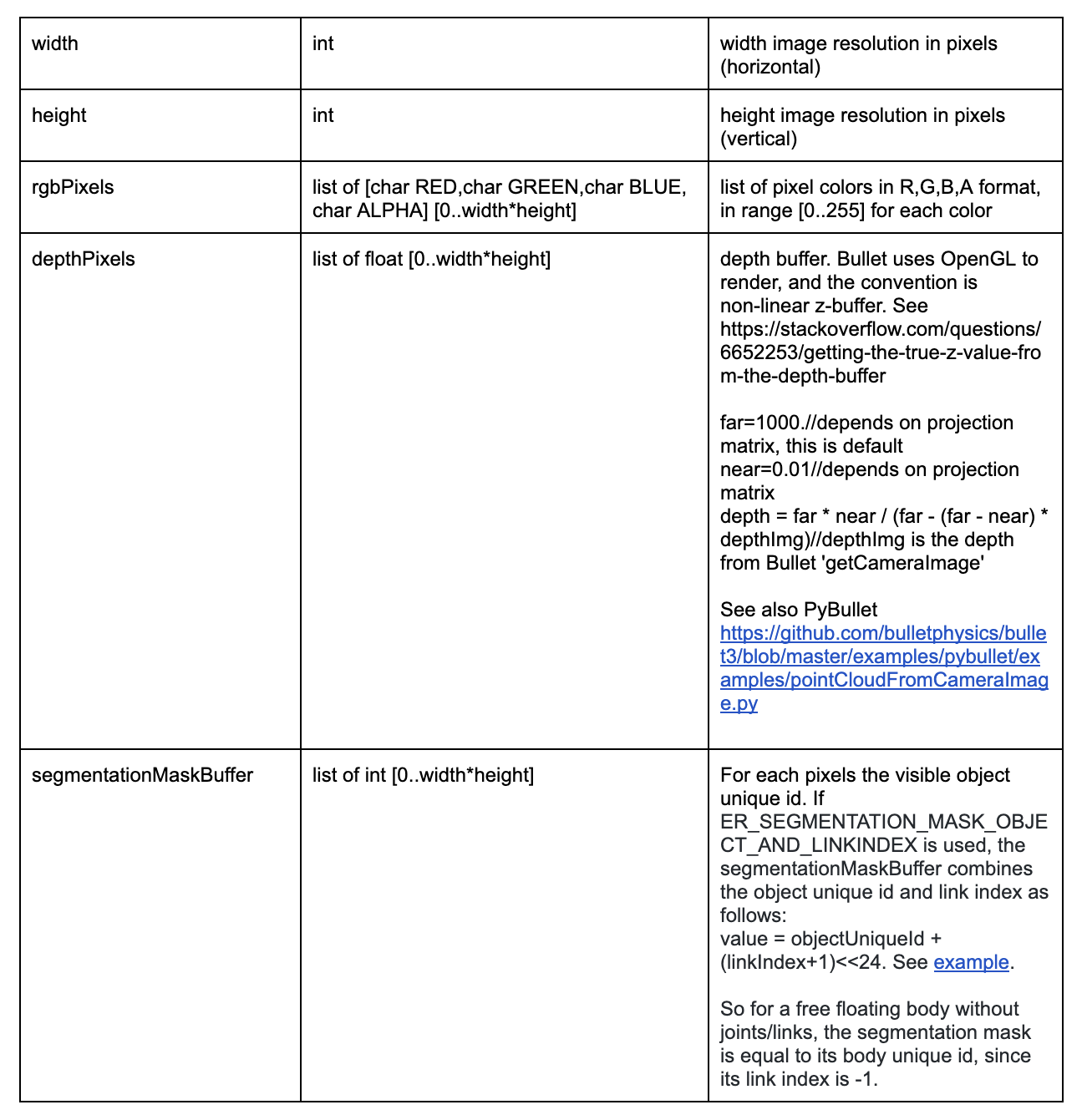
戻り値に関しての内容は下表の通りである.
| 戻り値 | 内容 |
|---|---|
| width | 画像幅(ピクセル) |
| height | 画像高さ(ピクセル) |
| rgbImg | RGB(Red・Green・Blue)画像 |
| depthImg | 深度画像(深度値は[0, 1]の範囲) |
| segImg | セグメンテーションマスク.各物体IDが取れるから,「どの物体の画素か」特定可能 |
viewMatrix(ビュー行列)・projectionMatrix(プロジェクション行列)に関しては,以下記事がわかりやすいです.以下記事に詳細な情報が記載されている.
https://light11.hatenadiary.com/entry/2019/01/27/160541
カメラから物体の位置(ピクセル)を取得するには,以下の順番で物体の座標変換を実装している.
1:モデル変換
物体のローカル座標(URDFなどで定義されたモデルの原点位置)をワールド座標系に変換する.
2:ビュー変換
ワールド座標系からカメラ座標系へ変換する.カメラがカメラ座標系の原点にいて,$-Z$方向を向いている状態に正規化される(PyBulletのcomputeViewMatrix()関数).
3:プロジェクション変換
カメラ座標系から正規化デバイス座標(NDC)へ変換する.正規化デバイス座標からビューポート変換をすることで,カメラからのピクセル座標へ変換される(PyBulletのcomputeProjectionMatrixFOV()関数).
逆に,カメラから物体の位置(ピクセル)を取得して,物体のワールド座標の2次元位置を取得する方法は以下の通りとなる.
1:ピクセル座標を正規化デバイス座標(NDC)へ変換
カメラから取得した物体の位置はピクセル座標になっているため,[-1, 1]の範囲である正規化デバイス座標(NDC)へ変換する.
2:プロジェクション逆変換
正規化デバイス座標(NDC)をカメラ座標系に変換する.プロジェクション行列の逆行列を使用して,カメラ座標系に変換する.
3:ビュー逆変換
カメラ座標系からワールド座標系に変換する.ビュー行列の逆行列を使用して,ワールド座標系に変換する.
物体の2次元位置を取得したら,光線を使って物体の3次元位置を取得する.本来であれば深度情報を使って,3次元位置を取得したかったが,上手くいかなかったため,光線を使用する方針とした.
光線による把持物体の3次元位置を取得
PyBulletで光線の照射による物体の情報を取得する関数は "rayTest" である.関数情報は下図の通りである.
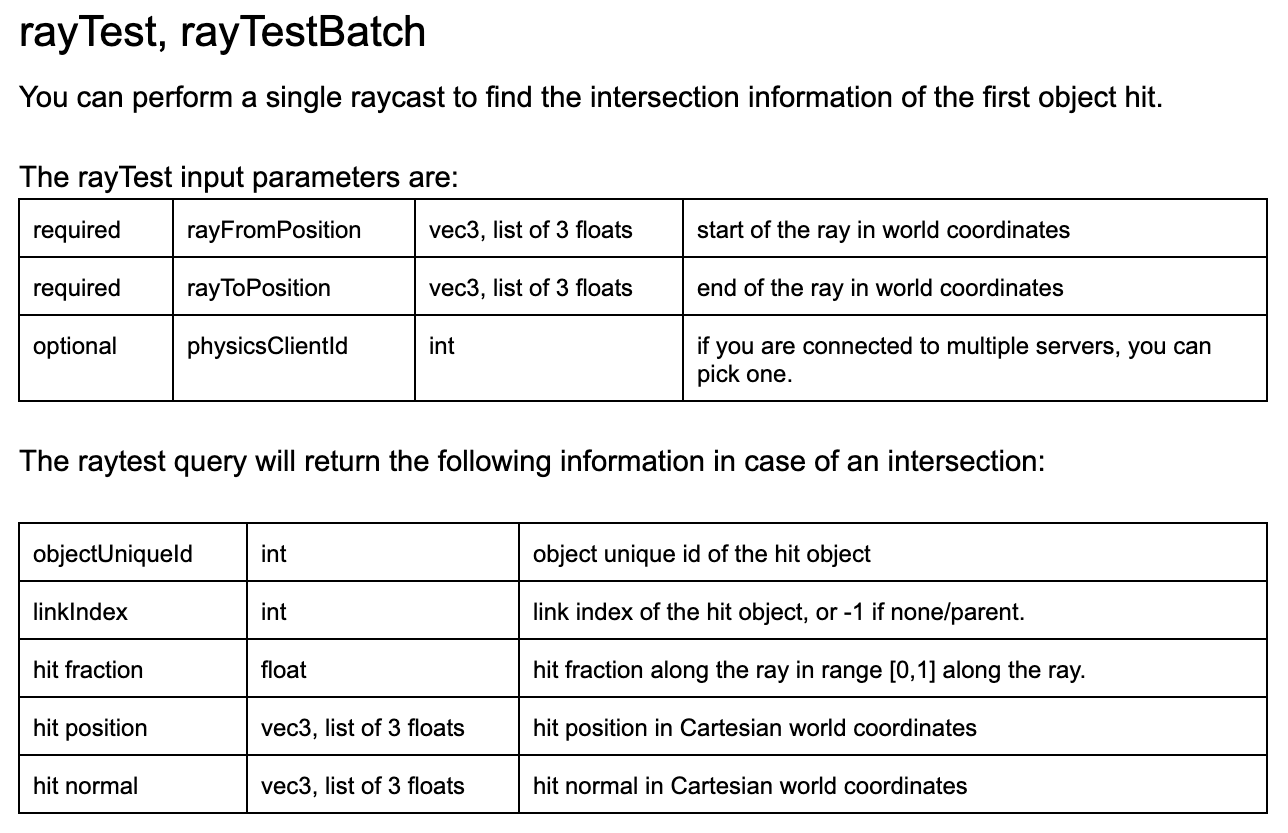
引数に関しての内容は下表の通りである.
| 引数名 | 内容 |
|---|---|
| rayFromPosition | 光線の照射元の位置(位置はワールド座標系で記載) |
| rayToPosition | 光線の照射先の位置(位置はワールド座標系で記載) |
戻り値に関しての内容は下表の通りである.
| 戻り値 | 内容 |
|---|---|
| objectUniqueId | 光線が当たった物体のID(物体に当たらなかったら,-1) |
| linkIndex | 光線が当たった物体のリンクの要素番号(リンクがない場合は,-1) |
| hit fraction | 光線の照射元から照射先までの距離に対する,当たった位置の割合(0.0 ... 照射元の位置,1.0 ... 照射先の位置) |
| hit position | 光線が当たった物体の位置(ワールド座標系から見た位置) |
| hit normal | 光線が当たった物体の法線ベクトル(ワールド座標系から見たベクトル) |
光線はカメラが照射していると考えると,カメラの位置をrayFromPosition(光源の照射元の位置)として与えて,カメラ座標系から見た物体の2次元位置の方向ベクトルをrayToPosition(光線の照射先の位置)として,与えることで,把持物体に向かって光線を照射でき,位置を取得することが可能となる.
ただ,光線が当たった物体の位置は,物体の中心位置ではなく,光線が当たった物体の表面上の位置である.そのため,把持物体が大きいほど把持する際に,物体の中心位置からのズレが大きくなってしまう.
本記事では,カメラを1台とするが,カメラを複数台にすることで,把持物体の位置をより正確に取得できると考えている.
光線に当たった物体に関する情報は,PyBulletの内部で実装するため,内部処理は不明である.
複数カメラによる把持物体の3次元位置を組み合わせる
複数のカメラから取得した,把持物体の3次元位置を組み合わせて一意の位置に変換する.本節では,変換方法についての説明をする.
下図は本記事で使用する PyBullet の環境である.青枠がカメラである.5台のカメラを使用することで,死角をなくし,把持物体の位置を計算する.
変換の順番は以下の通りである.
1:各カメラにて,把持物体の位置(ピクセル)を取得 + カメラ画像内の把持物体に関するピクセル数を計算
2:把持物体に向かって,光線を照射して,3次元位置を取得
3:各カメラ画像内の把持物体に関するピクセル数を使用して,重み付き平均により把持物体の3次元位置を一意に決定
上記の「1」,「2」は単一のカメラと同様の処理であるため,本節では割愛する.
上記の「3」は数式で表すと,以下のようになる.
\displaylines{
P = \sum_{i=1}^{n} (pixel_{i} * P_{i}) / \sum_{i=1}^{n} pixel_{i} \\
P ... 全カメラを組み合わせた把持物体の3次元位置 (ベクトル) \\
P_{i} ... カメラiから見た把持物体の3次元位置 (ベクトル) \\
n ... カメラ画像内に把持物体が存在するカメラ数 (スカラー) \\
pixel_{i} ... カメラiの把持物体に関するピクセル数 (スカラー) \\
\sum_{i=1}^{n} pixel_{i} ... カメラ画像内に把持物体が存在するピクセル数の総計 (スカラー) \\
}
把持物体の位置は,カメラ画像内のピクセル数で重み付き平均を取った値である.
複数カメラを使用して,3次元位置を計算する方法としては他手法もあるが,本記事では簡単な処理としたいから,上記の手法とした.
強化学習に関して
強化学習は機械学習の一つの種類である.強化学習とは,自分で試行錯誤をしてデータを集め,詰めたデータから良い行動を学習することである.
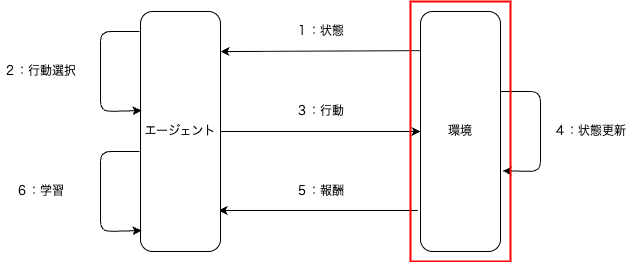
強化学習のイメージは下図の通りである.

1:「環境」から「エージェント」に対して,「状態」を渡す
2:「エージェント」が「状態」より,「行動」を選択する
3:「エージェント」から「環境」に対して,「行動」を実行する
4:「環境」が「行動」より,「状態」を更新する
5:「環境」から「エージェント」に対して,「報酬」を渡す
6:「エージェント」が「報酬」より,「学習」する
ここで,用語の定義をする.
| 用語 | 用語の定義 |
|---|---|
| エージェント | 行動の主体者 |
| 環境 | エージェントと相互作用を行う対象 |
| 状態 | エージェントの行動によって置かれるエージェントの状況 |
| 行動 | エージェントが起こすアクション |
| 報酬 | エージェントの行動に対する環境からのフィードバック |
本記事での "環境" は "PuBullet上のロボットと環境" である."エージェント" は "ロボットを動かすための頭脳" である.
以下では,本記事で使用する "環境" と "エージェント" を説明していく.
強化学習の環境に関して
強化学習の環境に関して説明する.強化学習の全体像の中で,下図の赤枠で囲んだ「環境」を説明する.
環境側で設計する情報(用語)は下表の通りである.
| 用語 |
|---|
| 環境 |
| 報酬 |
| 状態 |
| 行動 |
上表に記載した用語の設計を1つずつ,これから説明していく.
環境の定義
本記事では,環境を下図のように定義する.
ロボットアームはグリッパー付きの2軸ロボットアーム(上図の赤枠がグリッパー),把持物体(上図の緑枠)として立方体,複数のカメラ(上図の青枠)を使用して把持物体の位置を取得,干渉物は存在しない.
ロボットアームのグリッパーが把持物体に近づくことが目標である.ロボットアームのグリッパーと把持物体との距離が "0.1 [m]" 以下となれば,近いと判断して1エピソードを完了とする.
報酬の定義
本記事での報酬を定義する.ロボットアームのグリッパーが把持物体に近いかどうかで報酬を変える.
グリッパーが把持物体に遠い場合の報酬:グリッパー位置と把持物体の位置との距離に対してのマイナス値
グリッパーが把持物体に近い場合(ロボットのグリッパーと把持物体の距離が "0.1 [m]" 以下の場合)の報酬:+100
グリッパーが把持物体に遠いほど報酬を小さくし,近いときは報酬を大きくしたかったので,上記の報酬とした.
グリッパーが把持物体に近い場合の報酬として,「+100」とした理由は,報酬を試行錯誤した際に学習が上手くいったから.
色々なエージェントを使う中で,学習が上手くいかなくなったら,報酬を変える.
状態の定義
本記事での状態を定義する.2軸ロボットアームの各関節で状態を持つ.
ロボットアームの各軸の関節角度を 「$-180 ~ 180$ [deg] 」 として,考える.
今回は,関節角度を $5$[deg] 刻みの$73$分割で考える.具体的には,$-180, -175, ... , -5, 0, 5, 175, 180$ [deg] の$73$分割である.
関節$1$は$73$状態(分割),関節$2$も$73$状態(分割)と考えると,全状態が$5,329 (73 * 73)$となる.
関節角度の刻み幅を $1$[deg] 刻みの$361$分割と考えると,全状態が$130,321$となるため,$5$[deg] 刻みとした.
状態数が多い場合のメリット・デメリットに関して,下表にまとめた.
| メリット | デメリット |
|---|---|
| 様々な状態を保存できる | 状態数が爆発的に増加する |
| 表現力(精度)が高い | 表現力(精度)が小さい |
| - | 学習回数を大きくする必要がある |
本記事では,ロボットアームの関節角度を$5$[deg]刻みの離散値とした.
2軸ロボットアームの全状態が$5,329$のため,6軸ロボットアームで同様の状態を定義してしまうと全状態数が膨大になってしまうので,将来的には状態を変える必要がある.
将来的には,ロボットアームの関節角度を連続値とし,深層学習を採用することで,状態数の多さに対処する.
行動の定義
本記事での行動内容を定義する.環境側で行動できる種類を定義する.
行動内容は下表の9パターンとする.
| 関節2 | ||||
|---|---|---|---|---|
| 現在角度 + $5$[deg] | 現在角度 | 現在角度 - $5$[deg] | ||
| 関節1 | 現在角度 + $5$[deg] | パターン1 | パターン2 | パターン3 |
| 現在角度 | パターン4 | パターン5 | パターン6 | |
| 現在角度 - $5$[deg] | パターン7 | パターン8 | パターン9 | |
今回は2軸ロボットアームのため,行動数が$9(3 * 3)$であるが,6軸ロボットアームを使うと,行動数が$729(3 ** 6(3の6乗))$である.
将来的には,行動を連続値とし,深層学習を採用することで,行動数の多さに対処する.
強化学習のエージェントに関して
強化学習のエージェントに関して説明する.強化学習の全体像の中で,下図の赤枠で囲んだ「エージェント」を説明する.
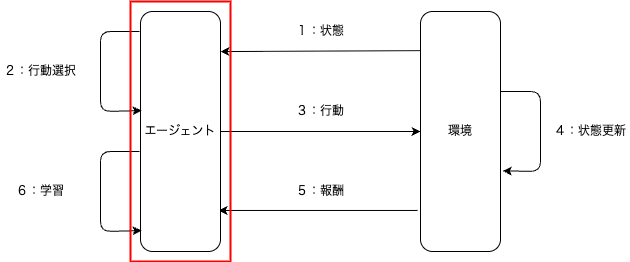
環境側で設計する情報(用語)は下表の通りである.
| 用語 | 設計内容 |
|---|---|
| 行動選択 | ランダム |
| 学習方法 | 学習なし |
本記事では,エージェントは学習せずに,常にランダムな行動を選択する.
環境作成をメインとしているため,次記事から学習するエージェントを使用する.数式も次以降で記載する.
URDFソースコード
今回使用する,URDFのソースコードについて説明する.
ソースコードとして,下表の9ファイルを作成する.
| ファイル名 | 概要 | リンク先 |
|---|---|---|
| camera_back_to_front.urdf | 手前方向(-Y方向)を向いているカメラの定義 | [PyBullet] [カメラ] 2軸ロボットアームを動かす Part7 (複数カメラによる把持物体の位置把握) |
| camera_front_to_back.urdf | 奥行き方向(+Y方向)を向いているカメラの定義 | [PyBullet] [カメラ] 2軸ロボットアームを動かす Part7 (複数カメラによる把持物体の位置把握) |
| camera_left_to_right.urdf | 右方向(+X方向)を向いているカメラの定義 | [PyBullet] [カメラ] 2軸ロボットアームを動かす Part7 (複数カメラによる把持物体の位置把握) |
| camera_right_to_left.urdf | 左方向(-X方向)を向いているカメラの定義 | [PyBullet] [カメラ] 2軸ロボットアームを動かす Part7 (複数カメラによる把持物体の位置把握) |
| camera_up_to_down.urdf | 下方向(-Z方向)を向いているカメラの定義 | [PyBullet] [カメラ] 2軸ロボットアームを動かす Part7 (複数カメラによる把持物体の位置把握) |
| environment_2dof.urdf | 2軸ロボットアームの環境を定義 | - |
| grasp_object.urdf | 把持物体の定義 | [PyBullet] 2軸ロボットアームを動かす Part5 (干渉物が存在する環境下にて物体把持) |
| robot_2dof_hand.urdf | グリッパー付き2軸ロボットアームの定義 | - |
| robot_2dof.urdf | グリッパーなし2軸ロボットアームの定義の定義 | [PyBullet] 2軸ロボットアームを動かす Part5 (干渉物が存在する環境下にて物体把持) |
上表内のファイルに関しては,以前の記事にて説明済のため,本記事では割愛する.表の列「リンク先」に記事のリンクを記載したため,参照してください.
本記事で説明するファイルは下表の通りである.
| ファイル名 | 概要 |
|---|---|
| environment_2dof.urdf | 2軸ロボットアームの環境を定義 |
| robot_2dof_hand.urdf | グリッパー付き2軸ロボットアームの定義 |
2軸ロボットアームの環境を定義 (environment_2dof.urdf)
2軸ロボットアームの環境を定義 environment_2dof.urdf について説明する.
<?xml version="1.0" ?>
<robot name="environment_2dof">
<link name="base">
<!-- 見た目,干渉判定,慣性はなし -->
</link>
<!-- 球を動かさないようのジョイント -->
<joint name="joint_sphere" type="fixed">
<parent link="base"/>
<child link="sphere"/>
<origin xyz="0 0 0" rpy="0 0 0"/>
</joint>
<!-- 球 -->
<link name="sphere">
<!-- 見た目 -->
<visual>
<origin xyz="2.4 0.0 0.0"/>
<geometry>
<sphere radius="0.1"/>
</geometry>
<material name="blue">
<color rgba="0 0 1.0 0.5"/>
</material>
</visual>
<!-- 干渉判定,慣性はなし -->
</link>
</robot>
2軸ロボットアームの関節角度が (joint1, joint2) = (0, 0) を初期角度としたため,初期角度時のグリッパー位置を表示するための URDF ファイルである.
グリッパー付き2軸ロボットアームの定義 (robot_2dof_hand.urdf)
グリッパー付き2軸ロボットアームの定義 robot_2dof_hand.urdf について説明する.
<? xml version="1.0" ?>
<robot name="robot_2dof_hand">
<!-- 色を先に定義 (共通化したいから) ↓ -->
<material name="black">
<color rgba="0 0 0 1"/>
</material>
<!-- 色を先に定義 (共通化したいから) ↑ -->
<!-- ベースリンク -->
<link name="base_link">
<!-- 見た目と干渉判定なし -->
</link>
<!-- ベースリンクとリンク1間の関節 -->
<joint name="joint1" type="revolute">
<parent link="base_link"/>
<child link="link1"/>
<origin xyz="0 0 0" rpy="0 0 0"/>
<axis xyz="0 0 1"/>
<limit lower="-3.14" upper="3.14" effort="1" velocity="1"/>
</joint>
<!-- リンク1 -->
<link name="link1">
<!-- 見た目 -->
<visual>
<origin xyz="0.5 0.0 0.0"/>
<geometry>
<box size="1.0 0.2 0.2"/>
</geometry>
</visual>
<!-- 干渉判定 -->
<collision>
<origin xyz="0.5 0.0 0.0"/>
<geometry>
<box size="1.0 0.2 0.2"/>
</geometry>
</collision>
<!-- 慣性行列 -->
<inertial>
<origin xyz="0.5 0.0 0.0"/>
<mass value="1.0" />
<inertia ixx="0.0067" iyy="0.0867" izz="0.0867" ixy="0.0" ixz="0.0" iyz="0.0"/>
</inertial>
</link>
<!-- リンク1とリンク2間の関節 -->
<joint name="joint2" type="revolute">
<parent link="link1"/>
<child link="link2"/>
<origin xyz="1.0 0 0" rpy="0 0 0"/>
<axis xyz="0 0 1"/>
<limit lower="-3.14" upper="3.14" effort="1" velocity="1"/>
</joint>
<!-- リンク2 -->
<link name="link2">
<!-- 見た目 -->
<visual>
<origin xyz="0.5 0.0 0.0"/>
<geometry>
<box size="1.0 0.2 0.2"/>
</geometry>
</visual>
<!-- 干渉判定 -->
<collision>
<origin xyz="0.5 0.0 0.0"/>
<geometry>
<box size="1.0 0.2 0.2"/>
</geometry>
</collision>
<!-- 慣性行列 -->
<inertial>
<origin xyz="0.5 0.0 0.0"/>
<mass value="1.0" />
<inertia ixx="0.0067" iyy="0.0867" izz="0.0867" ixy="0.0" ixz="0.0" iyz="0.0"/>
</inertial>
</link>
<!-- リンク2とグリッパー間の関節 -->
<joint name="gripper_joint" type="fixed">
<parent link="link2"/>
<child link="gripper_base_link"/>
<origin xyz="1.0 0 0" rpy="0 0 0"/>
</joint>
<!-- グリッパーのベース部分 -->
<!-- グリッパーはT字型とする -->
<!-- T字型の縦棒作成 -->
<link name="gripper_base_link">
<!-- 見た目 -->
<visual>
<origin xyz="0.05 0 0" rpy="0 0 0"/>
<geometry>
<box size="0.1 0.2 0.2"/>
</geometry>
<material name="black"/>
</visual>
<!-- 干渉判定 -->
<visual>
<origin xyz="0.05 0 0" rpy="0 0 0"/>
<geometry>
<box size="0.1 0.2 0.2"/>
</geometry>
<material name="black"/>
</visual>
<!-- 慣性 -->
<inertial>
<mass value="0.00625"/>
<origin xyz="0.05 0 0" rpy="0 0 0"/>
<inertia ixx="0.000026" iyy="0.000065" izz="0.000065" ixy="0.0" ixz="0.0" iyz="0.0"/>
</inertial>
</link>
<!-- グリッパーとフィンガー間の関節 -->
<joint name="finger_joint" type="fixed">
<parent link="gripper_base_link"/>
<child link="gripper_finger_link"/>
<origin xyz="0.1 0 0" rpy="0 0 0"/>
</joint>
<!-- T字型の横棒作成 -->
<link name="gripper_finger_link">
<!-- 見た目 -->
<visual>
<origin xyz="0 0 0" rpy="0 0 0"/>
<geometry>
<box size="0.1 0.2 0.2"/>
</geometry>
<material name="black"/>
</visual>
<!-- 干渉判定 -->
<collision>
<origin xyz="0 0 0" rpy="0 0 0"/>
<geometry>
<box size="0.1 0.2 0.2"/>
</geometry>
</collision>
<!-- 慣性 -->
<inertial>
<mass value="0.0125"/>
<origin xyz="0 0 0" rpy="0 0 0"/>
<inertia ixx="0.000443" iyy="0.000052" izz="0.000443" ixy="0.0" ixz="0.0" iyz="0.0"/>
</inertial>
</link>
<!-- フィンガーと右フィンガー間の関節 -->
<joint name="right_finger_joint" type="prismatic">
<parent link="gripper_finger_link"/>
<child link="right_finger_link"/>
<origin xyz="0.05 -0.095 0" rpy="0 0 0"/>
<axis xyz="0 1 0"/>
<limit lower="0.0" upper="0.090" effort="100.0" velocity="1.0"/>
</joint>
<!-- 右フィンガー -->
<link name="right_finger_link">
<!-- 見た目 -->
<visual>
<origin xyz="0.15 0.0 0.0"/>
<geometry>
<box size="0.3 0.01 0.2"/>
</geometry>
<material name="black"/>
</visual>
<!-- 干渉判定 -->
<collision>
<origin xyz="0.15 0.0 0.0"/>
<geometry>
<box size="0.3 0.01 0.2"/>
</geometry>
</collision>
<!-- 慣性行列 -->
<inertial>
<origin xyz="0.15 0.0 0.0"/>
<mass value="0.1"/>
<inertia ixx="0.000334" iyy="0.000751" izz="0.001083" ixy="0.0" ixz="0.0" iyz="0.0"/>
</inertial>
</link>
<!-- ハンドベースと左フィンガー間の関節 -->
<joint name="left_finger_joint" type="prismatic">
<parent link="gripper_finger_link"/>
<child link="left_finger_link"/>
<origin xyz="0.05 0.095 0" rpy="0 0 0"/>
<axis xyz="0 1 0"/>
<limit lower="-0.090" upper="0.0" effort="100.0" velocity="1.0"/>
</joint>
<!-- 左グリッパー -->
<link name="left_finger_link">
<!-- 見た目 -->
<visual>
<origin xyz="0.15 0.0 0.0"/>
<geometry>
<box size="0.3 0.01 0.2"/>
</geometry>
<material name="black"/>
</visual>
<!-- 干渉判定 -->
<collision>
<origin xyz="0.15 0.0 0.0"/>
<geometry>
<box size="0.3 0.01 0.2"/>
</geometry>
</collision>
<!-- 慣性行列 -->
<inertial>
<origin xyz="0.15 0.0 0.0"/>
<mass value="0.1"/>
<inertia ixx="0.000334" iyy="0.000751" izz="0.001083" ixy="0.0" ixz="0.0" iyz="0.0"/>
</inertial>
</link>
<!-- フィンガーと先端 (エンドエフェクター) 間の関節 -->
<joint name="ee_joint" type="fixed">
<parent link="gripper_finger_link"/>
<child link="ee_link"/>
<origin xyz="0.35 0 0" rpy="0 0 0"/>
</joint>
<!-- グリッパー先端 (エンドエフェクター) -->
<link name="ee_link">
<!-- 見た目,干渉判定,慣性はなし -->
</link>
</robot>
グリッパー先端位置を取得したいため,「エンドエフェクター」を作成した.
全体のソースコード
はじめに,本記事で使用する全体のソースコードについて説明する.
その後,重要な箇所を抜粋して別途解説をしていく.
ソースコードとして,下表の14ファイルを作成する.
| ファイル名 | 概要 | 保存されているフォルダ名 | リンク先 |
|---|---|---|---|
| constant.py | 定数の定義 | - | - |
| main.py | 全体的なメイン処理 | - | - |
| pybullet_environment.py | PyBulletの環境 | - | [PyBullet] [カメラ] 2軸ロボットアームを動かす Part7 (複数カメラによる把持物体の位置把握) |
| pybullet_grasp.py | PyBulletの把持物体 | - | - |
| pybullet_gripper.py | PyBulletのグリッパー | - | [PyBullet] [カメラ] 2軸ロボットアームを動かす Part7 (複数カメラによる把持物体の位置把握) |
| pybullet_robot.py | PyBulletのロボット | - | [PyBullet] [カメラ] 2軸ロボットアームを動かす Part7 (複数カメラによる把持物体の位置把握) |
| pybullet_camera.py | PyBulletのカメラ | - | [PyBullet] [カメラ] 2軸ロボットアームを動かす Part7 (複数カメラによる把持物体の位置把握) |
| pybullet_agent_controller.py | PyBulletのエージェント制御 | - | - |
| BaseAgent.py | PyBulletのエージェントの抽象クラス | Agent | - |
| RandomAgent.py | PyBulletのランダムに動くエージェント | Agent | - |
| pybullet_environment_controller.py | PyBulletの強化学習用の環境制御 | - | - |
| BaseEnvironment.py | PyBulletの強化学習用の環境の抽象クラス | Environment | - |
| DiscretizeEnvironment.py | PyBulletの強化学習用の離散値環境 | Environment | - |
| pybullet_main.py | PyBulletのメイン処理 | - | - |
表の列「リンク先」に記事のリンクを記載したものは,本記事では説明しないため,リンク先を参照ください.表の列「保存されているフォルダ先」にフォルダ名が記載されているものは,フォルダを作成して,フォルダ内にファイルを保存してください.
本記事で説明するファイルは下表の通りである.
| ファイル名 | 概要 |
|---|---|
| constant.py | 定数の定義 |
| main.py | 全体的なメイン処理 |
| pybullet_grasp.py | PyBulletの把持物体 |
| pybullet_agent_controller.py | PyBulletのエージェント制御 |
| BaseAgent.py | PyBulletのエージェントの抽象クラス |
| RandomAgent.py | PyBulletのランダムに動くエージェント |
| pybullet_environment_controller.py | PyBulletの強化学習用の環境制御 |
| BaseEnvironment.py | PyBulletの強化学習用の環境の抽象クラス |
| DiscretizeEnvironment.py | PyBulletの強化学習用の離散値環境 |
| pybullet_main.py | PyBulletのメイン処理 |
定数の定義 (constant.py)
定数を定義する constant.py について説明する.
# 複数ファイルで使用する定数の定義
from enum import Enum
from enum import auto
# 次元数を定義
DIMENTION_NONE = -1 # 未定義
DIMENTION_2D = 2 # 2次元
DIMENTION_3D = 3 # 3次元
DIMENTION_6D = 6 # 6次元
# 重力
GRABITY_VALUE = 9.81
# 0割を防ぐための定数
EPSILON = 1e-6
# URDFを保存するフォルダ名
URDF_FOLDER_NAME = "URDF" # 全URDFを一つにまとめたフォルダ名
# 補間方法の定義
class INTERPOLATION(Enum):
"""
補間方法
"""
NONE = "none" # 未定義
JOINT = "joint" # 関節補間
POSITION = "pos" # 位置補間
# ロボットアームが保存されている URDF ファイル名
class ROBOTURDF(Enum):
"""
ロボットのURDFファイル名
"""
# 2軸ロボットアーム
DOF2 = f"{URDF_FOLDER_NAME}/robot_2dof.urdf" # ハンド(グリッパ)なし
DOF2_HAND = f"{URDF_FOLDER_NAME}/robot_2dof_hand.urdf" # ハンド(グリッパ)付き
# カメラが保存されている URDF ファイル名
class CAMERAURDF(Enum):
"""
カメラのURDFファイル名
"""
# X軸方向に向いているカメラ
RIGHT2LEFT = f"{URDF_FOLDER_NAME}/camera_right_to_left.urdf" # 左向き(-X方向)のカメラ
LEFT2RIGHT = f"{URDF_FOLDER_NAME}/camera_left_to_right.urdf" # 右向き(+X方向)のカメラ
# Y軸方向に向いているカメラ
FRONT2BACK = f"{URDF_FOLDER_NAME}/camera_front_to_back.urdf" # 奥向き(+Y方向)のカメラ
BACK2FRONT = f"{URDF_FOLDER_NAME}/camera_back_to_front.urdf" # 手前向き(-Y方向)のカメラ
# Z軸方向に向いているカメラ
UP2DOWN = f"{URDF_FOLDER_NAME}/camera_up_to_down.urdf" # 下向き(-Z方向)のカメラ
# カメラ数を定義する定数
class CAMERANUM(Enum):
"""
カメラ数
"""
SINGLE = 1 # 1つのカメラ
MULTI = 5 # 複数のカメラ
# 環境URDFに関する定数
class ENVURDF(Enum):
"""
環境のURDFに関する定数
"""
TWODOF = f"{URDF_FOLDER_NAME}/environment_2dof.urdf" # 2軸ロボットアーム
# 強化学習の環境に関する定数
class ENV(Enum):
"""
強化学習の環境に関する定数
"""
TWODOF = 0 # 2軸ロボットアーム
# 強化学習のエージェントを定義する定数
class AGENT(Enum):
"""
強化学習のエージェント
"""
RANDOM = 0 # ランダムに行動するエージェント
全体的なメイン処理 (main.py)
定数を定義する main.py について説明する.
# Pybullet (Pythonでの3次元物理シミュレータ) による2軸ロボットアームの可視化
# 標準ライブラリの読み込み
import numpy as np
# 自作モジュールの読み込み
from pybullet_main import MainPyBulletRobot
from constant import *
CONST_SEED = 1 # シード値 (常に同じ結果としたいから)
HAND_FLG = True # ハンドの装着有無
# ロボットの関節数 ↓
N_JOINTS = DIMENTION_2D # 2軸ロボットアーム
# ロボットの関節数 ↑
# PyBulletの環境 ↓
ENV_URDF = ENVURDF.TWODOF.value # 2軸ロボットアーム
# PyBulletの環境 ↑
# 強化学習のエージェント ↓
AGENT_TYPE = AGENT.RANDOM.value # ランダム法
# 強化学習のエージェント ↑
# 強化学習の環境 ↓
ENV_TYPE = ENV.TWODOF.value # 2軸ロボットアーム
# 強化学習の環境 ↑
def main():
"""
メイン処理
"""
# 把持対象物が保存されている URDF ファイル名
grasp_urdf = f"{URDF_FOLDER_NAME}/grasp_object.urdf"
# 探索空間を指定 (強化学習では,常に探索空間を関節空間とする.直交空間には対応していないから)
interpolation = INTERPOLATION.JOINT.value # 関節空間
# カメラ数を指定
n_cameras = CAMERANUM.MULTI.value # 複数台のカメラ
# Pybulletを使用するインスタンス作成
my_robot = MainPyBulletRobot(interpolation, DIMENTION_2D, ENV_URDF, grasp_urdf, n_cameras, hand=HAND_FLG)
# シード値の設定
np.random.seed(CONST_SEED)
# 強化学習の実行
my_robot.run(AGENT_TYPE, ENV_TYPE)
if __name__ == "__main__":
# 本ファイルがメインで呼ばれた時の処理
main()
PyBulletの把持物体 (pybullet_grasp.py)
PyBulletの把持物体を定義する pybullet_grasp.py について説明する.
# PyBulletの把持物体に関するクラス
# ライブラリの読み込み
import pybullet as p # PyBullet
import numpy as np # 数値計算
# 自作モジュールの読み込み
from constant import * # 定数
class PyBulletGraspObject:
"""
PyBulletの把持物体クラス
プロパティ
__grasp_obj_id(int): PyBulletでの把持物体に関するID番号
__grasp_obj_offset(list): 把持物体のオフセット
__constraint_id(int): PyBulletでの把持物体の拘束に関するID番号
メソッド
public
grasp_obj_id(): _grasp_obj_idプロパティのゲッター
set_constraint(): 拘束条件の設定
release_constraint(): 拘束条件の解除
get_grasp_pos(): 把持物体の位置を取得
"""
# 定数の定義
# 各ロボットアームに応じた把持物体のベース位置
__GRASP_OBJ_POS_2DOF = [-1.8 , 1.0, 0.05] # 2軸ロボットアームの把持物体のベース位置
__GRASP_OBJ_POS_3DOF = [ 1.25, 0.4, 0.55] # 3軸ロボットアームの把持物体のベース位置
__GRASP_OBJ_POS_6DOF = [ 1.5 , 0.4, 1.05] # 6軸ロボットアームの把持物体のベース位置
# 各ロボットアームに応じた把持物体のオフセット位置
__GRASP_OBJ_OFFSET_2DOF = [-0.4 , 0 ] # 2軸ロボットアームの把持物体のオフセット
__GRASP_OBJ_OFFSET_3DOF = [-0.15, 0, 0.15] # 3軸ロボットアームの把持物体のオフセット
__GRASP_OBJ_OFFSET_6DOF = [-0.2 , 0, 0.2 ] # 6軸ロボットアームの把持物体のオフセット
# 把持物体のパラメータ
__LATERAL_FRICTION = 1.0 # 床との摩擦係数
__SPINNING_FRICTION = 1.0 # 回転摩擦係数
__ROLLING_FRICTION = 1.0 # 転がり摩擦係数
__GRASP_OBJ_OFFSET_PITCH = np.pi / 2
def __init__(self, grasp_obj_urdf, n_robot_joint):
"""
コンストラクタ
パラメータ
grasp_obj_urdf(str): 把持物体が保存されているファイル名
n_robot_joint(int): ロボットの関節数 (グリッパーは含まない)
"""
# ロボットアームに応じて,把持物体のベース位置・オフセットを変える
if n_robot_joint == DIMENTION_2D:
# 2軸ロボットアーム
basePosition = self.__GRASP_OBJ_POS_2DOF
self.__grasp_obj_offset = self.__GRASP_OBJ_OFFSET_2DOF
else:
# 異常
raise ValueError(f"n_robot_joint is abnormal. n_robot_joint is {n_robot_joint}")
# 把持物体を読み込む
self.__grasp_obj_id = p.loadURDF(grasp_obj_urdf, basePosition=basePosition, useFixedBase=True)
# 把持対象物に摩擦を付与する
p.changeDynamics(self.__grasp_obj_id, # 把持物体ID
-1, # ベースに対して
lateralFriction=self.__LATERAL_FRICTION, # 床との摩擦係数
spinningFriction=self.__SPINNING_FRICTION, # 回転摩擦係数
rollingFriction=self.__ROLLING_FRICTION) # 転がり摩擦
# 把持物体の位置・姿勢を取得
grasp_pos, grasp_ori = self.get_grasp_pos(offset=False)
# 把持物体に拘束条件を付与
self.__constraint_id = None
def set_constraint(self, pos, ori):
"""
拘束条件の設定
パラメータ
pos(list): 拘束したい位置
ori(list): 拘束したい姿勢
"""
if self.__constraint_id is not None:
# 拘束条件を2重に設定しようとしている
raise ValueError("set_constrant() is double exection. please run release_constraint()")
self.__constraint_id = p.createConstraint(
self.__grasp_obj_id, # 親番号(拘束したい対象物ID)
-1, # 親リンクの要素番号("-1"はベース)
-1, # 子番号("-1"はなし)
-1, # 子リンクの要素番号("-1"はベース)
p.JOINT_FIXED, # 関節タイプ(今回は固定"JOINT_FIXED")
[0, 0, 0], # 関節軸
[0, 0, 0], # 親の中心からの位置
pos, # 子の中心からの位置 (今回は子を設定していないから,ワールド座標系から見た関節位置)
parentFrameOrientation=ori, # 親の中心からの姿勢
childFrameOrientation=[0, 0, 0, 1]) # 子の中心からの姿勢 (今回は,子を設定していないから,ワールド座標系から見た姿勢)
def release_constraint(self):
"""
拘束条件の解除
"""
if self.__constraint_id is not None:
# 拘束条件を解除
p.removeConstraint(self.__constraint_id)
self.__constraint_id = None
def get_grasp_pos(self, offset=True, dim2=False):
"""
把持対象物の位置・姿勢を取得
パラメータ
offset(bool): 把持対象物へのオフセットを設定するかどうか
dim2(bool): 2次元位置として取得するかどうか
戻り値
list: 把持対象物の位置 [m]
list: 把持対象物の姿勢 (ロール・ピッチ・ヨー [rad])
"""
# 把持対象物の位置[m]・姿勢[rad]を取得
grasp_pos, grasp_ori = p.getBasePositionAndOrientation(self.__grasp_obj_id)
# 位置をタプルからリストへ変換
grasp_pos = list(grasp_pos)
# 姿勢をクォータニオンからロール・ピッチ・ヨーへ変換
roll, pitch, yaw = p.getEulerFromQuaternion(grasp_ori)
# ピッチ角を90度回転させる → 把持対象物の正面(x方向)から把持したいから
pitch += self.__GRASP_OBJ_OFFSET_PITCH
grasp_ori_rpy = [roll, pitch, yaw]
if offset:
# オフセット量の考慮
grasp_pos = [pos + off for pos, off in zip(grasp_pos, self.__grasp_obj_offset)]
if dim2:
grasp_pos = grasp_pos[:DIMENTION_2D]
return grasp_pos, grasp_ori_rpy
@property
def grasp_obj_id(self):
"""
_grasp_obj_idプロパティのゲッター
"""
return self.__grasp_obj_id
PyBulletのエージェント制御 (pybullet_agent_controller.py)
定数を定義する pybullet_agent_controller.py について説明する.
# エージェント制御クラスの作成
# 自作モジュールの読み込み
from constant import AGENT # エージェント定数
from Agent.BaseAgent import BaseAgent # ベースエージェントクラス (抽象クラス)
from Agent.RandomAgent import RandomAgent # ランダムエージェントクラス
class PyBulletAgentController:
"""
エージェント制御クラス
プロパティ
メソッド
public
protected
private
"""
# 定数の定義
def __init__(self, agent_type: AGENT, n_action, state_dim):
"""
コンストラクタ
パラメータ
agent_type(AGENT): エージェント
n_action(int): 行動数
state_dim(int): 状態の次元数
"""
# エージェントクラスの取得
agent_cls = self.__get_agent_class(agent_type)
# エージェントクラスのインスタンス作成
self.__agent: BaseAgent = agent_cls(n_action)
# エージェントタイプをプロパティに保存
self.__agent_type = agent_type
def __get_agent_class(self, agent_type: AGENT):
"""
エージェントクラスの取得
パラメータ
agent_type(AGENT): エージェントタイプ
戻り値
エージェントに応じたクラス
"""
# エージェント番号とエージェントクラスを保存する辞書型データの定義
agents = {
AGENT.RANDOM.value: RandomAgent
}
# エージェントクラスの定義
agent_cls = None
for key, value in agents.items():
if agent_type == key:
# エージェント番号が一致
agent_cls = value
break
if agent_cls is None:
# エージェント番号が一致しなかった
raise ValueError(f"agent is abnormal. agent is {agent_type}")
return agent_cls
def set_epsilon(self, value):
"""
探索確率である ε の設定
パラメータ
value(float): 設定値
"""
self.__agent.set_epsilon(value)
def get_action(self, state):
"""
行動の取得
パラメータ
state(tuple): 状態
戻り値
int: 行動
"""
return self.__agent.get_action(state)
def reset(self):
"""
初期化
"""
self.__agent.reset()
def update(self):
"""
1エピソード分のデータで更新
"""
self.__agent.update()
def add(self, state, action, reward):
"""
データの追加
パラメータ
state(tuple): 状態
action(int): 行動
reward(float): 報酬
"""
self.__agent.add(state, action, reward)
def eval(self, state, action, reward, done, next_state):
"""
1ステップ分のデータで更新
パラメータ
state(tuple): 状態
action(int): 行動
reward(float): 報酬
done(bool): 完了フラグ
next_state(tuple): 次状態
"""
self.__agent.eval(state, action, reward, done, next_state)
PyBulletのエージェントの抽象クラス (BaseAgent.py)
定数を定義する BaseAgent.py について説明する.
# 強化学習の全エージェントのベースを定義
# 外部ライブラリの読み込み
from abc import ABC, abstractmethod
class BaseAgent(ABC):
"""
全エージェントのベースクラス (抽象クラス)
プロパティ
メソッド
public
get_action(): 行動の取得
reset(): 初期化
update(): 更新
add(): データの追加
set_epsilon(): 探索確率の設定
"""
# 定数の定義
@abstractmethod
def set_epsilon(self, value):
"""
探索確率である ε の設定
パラメータ
value(float): 設定値
"""
pass
@abstractmethod
def get_action(self, state):
"""
行動の取得
パラメータ
state(numpy.ndarray): 状態
戻り値
int: 行動
"""
pass
@abstractmethod
def reset(self):
"""
初期化
"""
pass
@abstractmethod
def update(self):
"""
データの更新
"""
pass
@abstractmethod
def add(self, state, action, reward):
"""
データの追加
パラメータ
state(numpy.ndarray): 状態
action(int): 行動
reward(float): 報酬
"""
pass
@abstractmethod
def eval(self, state, action, reward, done):
"""
1ステップ分のデータで更新
パラメータ
state(numpy.ndarray): 状態
action(int): 行動
reward(float): 報酬
done(bool): 完了フラグ
"""
pass
PyBulletのランダムに動くエージェント (RandomAgent.py)
定数を定義する RandomAgent.py について説明する.
# ランダムエージェントの作成
# 外部ライブラリの読み込み
import numpy as np
# 自作モジュールの読み込み
from .BaseAgent import BaseAgent
class RandomAgent(BaseAgent):
"""
ランダムエージェントのクラス
プロパティ
メソッド
public
get_action(): 行動の取得
reset(): 初期化
update(): データの更新
add(): データの追加
"""
# 定数の定義
def __init__(self, n_action):
"""
コンストラクタ
パラメータ
n_action(int): 行動数
"""
self.__n_action = n_action
def set_epsilon(self, value):
"""
探索確率である ε の設定
パラメータ
value(float): 設定値
"""
# 何もしない
pass
def get_action(self, state):
"""
行動の取得
パラメータ
state(tuple): 状態
戻り値
int: 行動
"""
# 行動をランダムに選択
action = np.random.choice(range(self.__n_action))
return int(action)
def reset(self):
"""
初期化
"""
# 何もしない
pass
def update(self):
"""
データの更新
"""
# 何もしない
pass
def add(self, state, action, reward):
"""
データの追加
パラメータ
state(numpy.ndarray): 状態
action(int): 行動
reward(float): 報酬
"""
# 何もしない
pass
def eval(self, state, action, reward, done, next_state):
"""
1ステップ分のデータで更新
パラメータ
state(numpy.ndarray): 状態
action(int): 行動
reward(float): 報酬
done(bool): 完了フラグ
next_state(numpy.ndarray): 次状態
"""
# 何もしない
pass
PyBulletの強化学習用の環境制御 (pybullet_environment_controller.py)
定数を定義する pybullet_environment_controller.py について説明する.
# 環境制御クラスの作成
# 外部ライブラリの読み込み
import pybullet as p
# 自作モジュールの読み込み
from constant import ENV, ENVURDF # 環境
from Environment.BaseEnvironment import BaseEnvironment
from Environment.DiscretizeEnvironment import TwoDOFEnv # 2軸ロボットアーム環境
from pybullet_robot import PyBulletRobotController
class PyBulletEnvironmentController:
"""
環境制御クラス
プロパティ
メソッド
public
protected
private
"""
# 定数の定義
__PLANE_URDF = "plane.urdf" # 地面に関する urdf ファイル
# 各ロボットアームに応じた環境のベース位置
__ENVIRONMENT_POS_2DOF = [0 , 0, 0 ] # 2軸ロボットアームの環境のベース位置
__ENVIRONMENT_POS_3DOF = [1.5 , 0, -0.5] # 3軸ロボットアームの環境のベース位置
__ENVIRONMENT_POS_6DOF = [1.75, 0, 0 ] # 6軸ロボットアームの環境のベース位置
def __init__(self, env: ENV, robot: PyBulletRobotController, state_goal):
"""
コンストラクタ
パラメータ
env(ENV): 環境
robot(PyBulletRobotController): ロボット制御クラス
state_goal(numpy.ndarray): 目標状態
"""
# 環境に応じたクラスの取得
env_cls = self.__get_environment_cls(env)
# 環境クラスのインスタンス作成
self.__env: BaseEnvironment = env_cls(robot, state_goal)
def __get_environment_cls(self, env: ENV):
"""
環境に応じたクラスの取得
パラメータ
env(ENV): 環境
戻り値
環境に応じたクラス
"""
# 環境番号と環境クラスを保存する辞書型データの定義
envs = {
ENV.TWODOF.value: TwoDOFEnv
}
# 環境クラスとURDF定義
env_cls = None
for key, value in envs.items():
if env == key:
# 環境番号が一致
env_cls = value
break
if env_cls is None:
# 環境番号が一致しなかった
raise ValueError(f"env is abnormal. env is {env}")
return env_cls
# 定数のゲッター ↓
@property
def n_action(self):
"""
行動数の取得
"""
return self.__env.n_action
@property
def state_goal(self):
"""
目標位置[m]の取得
"""
return self.__env.state_goal
@property
def state_start(self):
"""
初期位置[m]の取得
"""
return self.__env.state_start
@property
def state_dimention(self):
"""
状態の次元数の取得
"""
return self.__env.state_dimention
# 定数のゲッター ↑
# public ↓
def reset(self):
"""
初期化
戻り値
tuple: 初期関節状態
"""
return self.__env.reset()
def step(self, action):
"""
1ステップ実行
パラメータ
action(int): 行動
戻り値
numpy.ndarray: 次状態
float: 報酬
bool: 完了フラグ
"""
return self.__env.step(action)
# public ↑
PyBulletの強化学習用の環境の抽象クラス (BaseEnvironment.py)
定数を定義する BaseEnvironment.py について説明する.
# 強化学習の全環境のベースを定義
# 外部ライブラリの読み込み
from abc import ABC, abstractmethod
class BaseEnvironment(ABC):
"""
全環境のベースクラス (抽象クラス)
プロパティ
メソッド
public
reset(): 初期化
step(): 1ステップ実行
"""
# 定数の定義
@abstractmethod
def reset(self):
"""
初期化
戻り値
numpy.ndarray: 初期状態
"""
pass
@abstractmethod
def step(self, action):
"""
1ステップ実行
パラメータ
action(numpy.ndarray): 行動
戻り値
numpy.ndarray: 次の状態
float: 報酬
bool: 完了フラグ
"""
pass
PyBulletの強化学習用の離散値環境 (DiscretizeEnvironment.py)
定数を定義する DiscretizeEnvironment.py について説明する.
# 強化学習の全環境のベースを定義
# 外部ライブラリの読み込み
import numpy as np
from enum import Enum
from enum import auto
from abc import ABC, abstractmethod
import pybullet as p # PyBullet
import time
# 自作モジュールの読み込み
from constant import *
from pybullet_robot import PyBulletRobotController
class _DiscretizeBaseEnvironment(ABC):
"""
状態が離散値のベースクラス (抽象クラス)
プロパティ
メソッド
public
reset(): 初期化
step(): 1ステップ実行
"""
# 定数の定義
# シミュレーションに関する定数 ↓
_SIMULATION_SLEEP_TIME = 0.0001 # シミュレーションの待機時間 [sec]
# シミュレーションに関する定数 ↑
# ロボットに関する定数 ↓
_ROBOT_MOVE_VAL = round(np.deg2rad(5), 2) # 関節角度の移動量 [rad]
_ROBOT_JOINT_MAX = np.pi # 関節の最大値 [rad]
_ROBOT_JOINT_MIN = -np.pi # 関節の最小値 [rad]
# ロボットに関する定数 ↑
# オーバーライド必須の定数 ↓
_DIMENTION = DIMENTION_NONE # 次元数
# 行動に関する定数 ↓
_N_ACTION = 0 # 行動数
class _ACTION(Enum):
"""
行動に関する定数
"""
pass
# 行動に関する定数 ↑
# 状態に関する定数 ↓
_STATE_START = (0.0, 0.0) # 初期関節状態
# 状態に関する定数 ↑
# オーバーライド必須の定数 ↑
# 状態に関する定数 ↓
_STATE_NUM = 73 # 状態数 (73は5度刻みになる)
_STATE_GRID = np.linspace(_ROBOT_JOINT_MIN, _ROBOT_JOINT_MAX, _STATE_NUM)
# 状態に関する定数 ↑
_THRESHOLD_GOAL = 0.1 # 手先位置と目標位置との閾値 [m]
def __init__(self, robot: PyBulletRobotController, state_goal):
"""
コンストラクタ
パラメータ
robot(PyBulletRobotController): ロボット制御クラス
state_goal(numpy.ndarray): 目標状態(関節角度 [rad])
"""
# 定数のオーバーライド確認
self.__chk_override_constant()
# 引数の次元数確認
if len(state_goal) != self._DIMENTION:
# 引数が異常
raise ValueError(f"len(state_goal) is abnormal. len(state_goal) is {len(state_goal)}")
# 目標状態の更新
self._state_goal = state_goal
# 初期状態の更新
self._state_start = self._STATE_START
# ロボットの更新
self._robot = robot
# 状態の初期化
self.reset()
def __chk_override_constant(self):
"""
定数のオーバーライド確認
"""
# 比較元と比較先が一致していたら,異常とする辞書型データの作成
compare_match_datas = {
"self._DIMENTION": [self._DIMENTION, DIMENTION_NONE],
"self._N_ACTION": [self._N_ACTION, 0]
}
# 比較元と比較先が不一致なら,異常とする辞書型データの作成
compare_not_match_datas = {
"len(self._ACTION)": [len(self._ACTION), self._N_ACTION]
}
# オーバーライドが正しいかの確認
for tag, datas in compare_match_datas.items():
# データから,比較元と比較先を取得
sorce, target = datas
if sorce == target:
# オーバーライドしていないから,エラー発報
raise NotImplementedError(f"{tag} is abnormal. {tag} is {sorce}.")
# オーバーライドが正しいかの確認
for tag, datas in compare_not_match_datas.items():
# データから,比較元と比較先を取得
sorce, target = datas
if sorce != target:
# オーバーライドしていないから,エラー発報
raise NotImplementedError(f"{tag} is abnormal. {tag} is {sorce}.")
# プロパティのゲッター ↓
@property
def n_action(self):
"""
行動数を取得
"""
return self._N_ACTION
@property
def state_goal(self):
"""
目標状態(関節角度[rad])を取得
"""
return self._state_goal
@property
def state_start(self):
"""
初期状態(関節角度[rad])を取得
"""
return self._state_start
@property
def state_dimention(self):
"""
状態の次元数を取得
"""
return self._DIMENTION
# プロパティのゲッター ↑
# public ↓
@abstractmethod
def reset(self):
"""
初期化
戻り値
numpy.ndarray: 初期状態
"""
pass
@abstractmethod
def step(self, action):
"""
1ステップ実行
パラメータ
action(numpy.ndarray): 行動
戻り値
numpy.ndarray: 次の状態
float: 報酬
bool: 完了フラグ
"""
pass
class TwoDOFEnv(_DiscretizeBaseEnvironment):
"""
2軸ロボットアームの環境クラス
プロパティ
メソッド
public
protected
private
"""
# 定数の定義
# オーバーライド必須の定数 ↓
# シミュレーションに関する定数 ↓
_SIMULATION_SLEEP_TIME = 0.001 # シミュレーションの待機時間 [sec]
# シミュレーションに関する定数 ↑
_DIMENTION = DIMENTION_2D # 次元数
# 行動に関する定数 ↓
_N_ACTION = 9 # 行動数
class _ACTION(Enum):
"""
行動に関する定数
"""
# 定数名は "関節1の移動角度_関節2の移動角度" で定義
# 関節1の角度をプラス ↓
PLUS_PLUS = 0
PLUS_NONE = auto()
PLUS_MINUS = auto()
# 関節1の角度をプラス ↑
# 関節1の角度は変わらない ↓
NONE_PLUS = auto()
NONE_NONE = auto()
NONE_MINUS = auto()
# 関節1の角度は変わらない ↑
# 関節1の角度をマイナス ↓
MINUS_PLUS = auto()
MINUS_NONE = auto()
MINUS_MINUS = auto()
# 関節1の角度をマイナス ↑
# 行動に関する定数 ↑
# オーバーライド必須の定数 ↑
# 状態に関する定数 ↓
_STATE_START = (0, 0) # 初期関節状態
# 状態に関する定数 ↑
def __init__(self, robot: PyBulletRobotController, state_goal):
"""
コンストラクタ
パラメータ
robot(PyBulletRobotController): ロボット制御クラス
state_goal(numpy.ndarray): 目標状態(関節角度 [rad])
"""
# 親クラスのコンストラクタ
super().__init__(robot, state_goal)
# 初期関節角度から,初期状態を取得
self._state_start = self.__cnvrt_state_to_joints(self._STATE_START)
def reset(self):
"""
初期化
戻り値
tuple: 初期状態
"""
# 状態から関節角度を計算してロボットに設定
self.__set_thetas_from_state(self._STATE_START)
# エージェント位置の初期化
# 初期関節角度を初期状態へ変換
self._agent_state = self.__discretize_state(self._STATE_START)
return self._agent_state
def __cnvrt_state_to_joints(self, state):
"""
状態から関節角度に変換
パラメータ
state(tuple): 状態
戻り値
numpy.ndarray: 関節角度
"""
# 戻り値を定義
joints = np.zeros(self._DIMENTION)
for i in range(len(state)):
# 状態から関節角度へ変換
joints[i] = self._STATE_GRID[state[i]]
return joints
def __set_thetas_from_state(self, state):
"""
状態から関節角度を計算してロボットに設定
パラメータ
state(tuple): 状態
"""
# 状態から関節角度に変換
joints = self.__cnvrt_state_to_joints(state)
# ロボットに次状態を渡し,動かす
self._robot.set_joint(joints)
# グリッパーの実行
self._robot.run_gripper(open=True)
# 実行
p.stepSimulation()
# シミュレーション実行の待機時間
time.sleep(self._SIMULATION_SLEEP_TIME)
def step(self, action):
"""
1ステップ実行
パラメータ
action(int): 行動
戻り値
tuple: 次の状態
float: 報酬
bool: 完了フラグ
"""
# 行動後の次状態を取得
next_state = self.__next_state(action)
# 状態から関節角度を取得して,ロボットを動かす
self.__set_thetas_from_state(next_state)
# 手先位置と目標位置との距離を計算
dist = self.__calc_dist()
# 報酬の計算
reward = self.__calc_reward(dist)
# 距離が近傍であるかの確認
done = self.__is_closed(dist)
if done:
# 近傍なら,報酬を更新
reward += 100
# エージェント位置の更新
self._agent_state = next_state
# print(f"ee_pos = {self._robot.get_ee_pos()}")
# print(f"self._agent_state = {self._agent_state}")
# print(f"reward = {reward}")
return next_state, reward, done
def __next_state(self, action):
"""
次状態の取得
パラメータ
action(int): 行動
戻り値
tuple: 次状態
"""
# 関節角度の差分を計算
delta_thetas = self.__get_delta_thetas(action)
# 現在の状態から関節角度を取得
thetas = self.__cnvrt_state_to_joints(self._agent_state)
# 次状態の関節角度を計算
next_thetas = thetas + delta_thetas
# 次状態を離散化
next_state = self.__discretize_state(next_thetas)
return next_state
def __get_delta_thetas(self, action):
"""
関節角度の差分を計算
パラメータ
action(int): 行動
戻り値
numpy.ndaray: 関節角度の差分
"""
# 行動をキー,行動内容をバリューとして,辞書型データにまとめる
actions = {
self._ACTION.PLUS_PLUS.value: np.array([ self._ROBOT_MOVE_VAL, self._ROBOT_MOVE_VAL]),
self._ACTION.PLUS_NONE.value: np.array([ self._ROBOT_MOVE_VAL, 0.0 ]),
self._ACTION.PLUS_MINUS.value: np.array([ self._ROBOT_MOVE_VAL, -self._ROBOT_MOVE_VAL]),
self._ACTION.NONE_PLUS.value: np.array([ 0.0 , self._ROBOT_MOVE_VAL]),
self._ACTION.NONE_NONE.value: np.array([ 0.0 , 0.0 ]),
self._ACTION.NONE_MINUS.value: np.array([ 0.0 , -self._ROBOT_MOVE_VAL]),
self._ACTION.MINUS_PLUS.value: np.array([-self._ROBOT_MOVE_VAL, self._ROBOT_MOVE_VAL]),
self._ACTION.MINUS_NONE.value: np.array([-self._ROBOT_MOVE_VAL, 0.0 ]),
self._ACTION.MINUS_MINUS.value: np.array([-self._ROBOT_MOVE_VAL, -self._ROBOT_MOVE_VAL])
}
# 行動内容を保存
delta_thetas = None
# 辞書型データから,行動に応じた行動内容を取得
for key, value in actions.items():
if action == key:
# 行動が辞書型データに保存されている
delta_thetas = value
break
if delta_thetas is None:
# 行動が辞書型データに保存されていないため,異常
raise ValueError(f"action is abnorma. action is {action}")
return delta_thetas
def __discretize_state(self, state):
"""
状態の離散化
パラメータ
state(numpy.ndarray): 状態
戻り値
tuple: 離散化した状態
"""
# 関節分のデータを保存する領域を確保
joints_idx = [0 for _ in range(self._DIMENTION)]
# 各関節に離散化した状態を保存
for i in range(self._DIMENTION):
joints_idx[i] = int(np.argmin(np.abs(self._STATE_GRID - state[i])))
# print(f"joints_idx = {joints_idx}")
return tuple(joints_idx)
def __calc_dist(self):
"""
手先位置と目標位置との距離[m]を計算
戻り値
float: 手先位置と目標位置との距離 [m]
"""
# 手先位置を取得
ee_pos, ee_ori = self._robot.get_ee_pos()
# 手先位置と目標位置との差分を計算
difference = self._state_goal - ee_pos
# 手先位置と目標位置との距離を計算
dist = np.linalg.norm(difference)
return dist
def __calc_reward(self, dist):
"""
報酬の取得
パラメータ
dist(float): 手先位置と目標位置との距離
戻り値
float: 報酬(手先位置と目標位置との距離のマイナス値)
"""
# 報酬案1 ↓
# 報酬は手先位置と目標位置との距離のマイナス値とする
reward = -dist
# 報酬案1 ↑
# # 報酬案2 不採用 ↓
# # 報酬は手先位置と目標位置との距離の逆数
# reward = 1 / (abs(dist) + self.__ZERO_DIV_EPSILON)
# # 報酬案2 不採用 ↑
return reward
def __is_closed(self, dist):
"""
手先位置と目標位置との距離が近傍であるかの判定
パラメータ
dist(float): 手先位置と目標位置との距離
戻り値
bool: True / False = 近傍である / 近傍ではない
"""
return dist <= self._THRESHOLD_GOAL
PyBulletのメイン処理 (pybullet_main.py)
定数を定義する pybullet_main.py について説明する.
# PyBulletのメイン処理を記載
# ライブラリの読み込み
import pybullet as p # PyBullet
import pybullet_data # PyBulletで使用するデータ
import numpy as np # 数値計算ライブラリ
# サードパーティの読み込み
# 自作モジュールの読み込み
from constant import *
from pybullet_environment import PyBulletEnvironment # PyBulletの環境に関して
from pybullet_grasp import PyBulletGraspObject # 把持物体に関して
from pybullet_robot import PyBulletRobotController # ロボットに関して
from pybullet_camera import PyBulletCameraContoller # カメラに関して
from pybullet_agent_controller import PyBulletAgentController # 強化学習のエージェントに関して
from pybullet_environment_controller import PyBulletEnvironmentController # 強化学習の環境に関して
class MainPyBulletRobot:
"""
PyBulletのメインクラス
プロパティ
__robot(PyBulletRobotController): ロボットアームの制御クラス
__interpolation(str): 探索空間 (直交空間/関節空間)
__environment(PyBulletEnvironment): 環境クラス
__camera(PyBulletCamera): カメラクラス
__env(PyBulletEnvironmentController): 強化学習の環境制御クラス
__agent(PyBulletAgentController): 強化学習のエージェント制御クラス
メソッド
public
メイン処理関連
run(): 実行 (始点から終点まで,干渉しない経路を生成)
運動学関連
convert_pos_to_theta(): 位置から関節角度に変換 (クラス外で使う用)
private
メイン処理関連
__path_planning(): 始点から終点までの経路生成
__post_path_planning(): 経路生成の後処理 (経路生成成功時だけ実装)
"""
# 定数の定義
__MAX_EPISODES = 1 # 強化学習のエピソード数
def __init__(self, interpolation, n_robot_joint, environment_urdf, grasp_urdf, n_cameras, hand=False):
"""
コンストラクタ
パラメータ
interpolation(str): 補間方法 (関節空間/位置空間)
n_robot_joint(int): ロボットアームの関節数(2, 3, 6だけ)
environment_urdf(str): 環境のファイル名 (urdf)
grasp_urdf(str): 把持物体のファイル名 (urdf)
n_cameras(CAMERANUM): カメラの数
hand(bool): ハンドの装着有無 True/False = 装着/未装着
"""
# PyBulletの初期化
p.connect(p.GUI)
# パスの追加
p.setAdditionalSearchPath(pybullet_data.getDataPath())
# シミュレーションの初期化
p.resetSimulation()
# 重力の設定 (下(-z軸)方向の加速度)
p.setGravity(0, 0, -GRABITY_VALUE)
# ロボットの初期化
self.__robot = PyBulletRobotController(n_robot_joint, interpolation, hand)
# 環境の初期化
self.__environment = PyBulletEnvironment(environment_urdf, self.__robot.n_robot_joint)
# 把持物体の初期化
self.__grasp_obj = PyBulletGraspObject(grasp_urdf, self.__robot.n_robot_joint)
# カメラの初期化
self.__camera = PyBulletCameraContoller(n_cameras)
# メイン処理 ↓
def run(self, agent_type: AGENT, env_type: ENV):
"""
実行
始点から終点まで,干渉しない経路を生成
パラメータ
agent_type(AGENT): エージェントタイプ
env_type(ENV): 環境タイプ
戻り値
result(bool): True/False = 経路生成に成功/失敗
"""
# 把持物体の位置をカメラから取得
end_pos = self.__get_grasp_pos_from_camera()
# 強化学習の環境の設定
self.__env = PyBulletEnvironmentController(env_type, self.__robot, end_pos)
# 強化学習のエージェントの設定
self.__agent = PyBulletAgentController(agent_type, self.__env.n_action, self.__env.state_dimention)
# 強化学習の学習フェーズ
self.__learning()
return True
def __learning(self):
"""
強化学習の学習フェーズ
"""
# 全エピソードの報酬
rewards_history = []
# エピソード分ループ
for episode in range(self.__MAX_EPISODES):
# 強化学習用の環境とエージェントを初期化
state = self.__env.reset()
self.__agent.reset()
# 完了フラグ
done = False
# 1エピソード分の報酬の合計
total_reward = 0
# ループ数の保存
count = 0
print(f"episode = {episode} is start.")
# 完了するまでループ
while not done:
# デバッグ
# print(f"state = {state}")
# 状態から行動を取得
action = self.__agent.get_action(state)
# 1ステップ実行
next_state, reward, done = self.__env.step(action)
# データの追加
self.__agent.add(state, action, reward)
# 報酬の更新
total_reward += reward
# 状態の更新
state = next_state
# カウンタの更新
count += 1
# 1エピソード分の情報を使って,データの更新
self.__agent.update()
# 報酬を履歴に追加
rewards_history.append(total_reward)
print(f"count = {count}")
print(f"total_reward = {total_reward}")
print(f"episode = {episode} is fin.")
print()
def __get_grasp_pos_from_direct(self, offset=False):
"""
把持物体の位置を取得 (直接)
パラメータ
offset(bool): オフセットの有無
戻り値
numpy.ndarray: 把持物体の位置
"""
# 把持物体の位置を取得
pos, _ = self.__grasp_obj.get_grasp_pos(offset=offset, dim2=True)
# Numpy型に型変換
pos = np.array(pos)
return pos
def __get_grasp_pos_from_camera(self):
"""
カメラから把持物体の位置を取得
戻り値
numpy.ndarray: 把持物体の位置
"""
# カメラから物体位置(3次元)の取得
pos = self.__camera.get_pos(self.__grasp_obj.grasp_obj_id)
# 今回は2軸ロボットアームだけに対応するため,物体位置を2次元に変換する
pos = pos[:DIMENTION_2D]
# 探索方法に応じた終点に変換
if self.__robot.interpolation == INTERPOLATION.JOINT.value:
# 逆運動学により,関節角度を取得
pos = self.__robot.convert_pos_to_theta(pos)
return pos
# メイン処理 ↑
# 運動学関連 ↓
def convert_pos_to_theta(self, pos):
"""
位置から関節角度に変換
パラメータ
pos(numpy.ndarray): 位置 / 関節角度
戻り値
thetas(numpy.ndarray): 関節角度
"""
thetas = self.__robot.convert_pos_to_theta(pos, force=True)
return thetas
# 運動学関連 ↑
PyBulletでロボットを動かす
上記にて,ソースコードを説明した.
main.py ファイルを実施することによって,PyBullet上のロボットを動かしていく.
経路生成の動画
ランダムに動くエージェントによる経路生成の動画を載せる.
動画1:ロボットが始点から終点まで動く動画
今回は環境作成に重きを置いたため,強化学習のエージェントは常にランダムで動く方針としたため,無駄な動きが多くなった.
次回以降は,エージェントに重きを置くため,エージェントが試行錯誤しながら学習する.
おわりに
本記事では,Pythonを使用して,下記内容を実装しました
・PyBullet 内の2軸ロボットアームの強化学習 (環境作成をメイン)
次記事では,下記内容を実装していきます.
・モンテカルロ法によって学習していくエージェントを採用して,PyBullet 内の2軸ロボットアームの強化学習 (モンテカルロ法によるエージェント)
参考文献
本記事を作成する上で参考にした内容を記載する.
参考にした記事
・https://qiita.com/pocokhc/items/785e7b021c7c15794dbc
・https://qiita.com/icoxfog417/items/242439ecd1a477ece312
・https://www.skillupai.com/blog/tech/reinforcement-learning/
参考にした書籍
・ゼロから作るDeep Learning ❹ ―強化学習編