はじめに
2018年に以下の記事を投稿しました。
おかげさまで結構なアクセス数や「いいね」をいただいたのですが、先日**「同じ手順を踏んでもエラーが出て動作しない」**とコメントいただきました。
調べてみたところ、コードでインポートしているライブラリ(grpc-google-cloud-speech-v1beta1)が2019年4月ごろにサポート終了していることが原因なようです。
ということで、マイク入力でストリーミング音声認識を行う方法を再度記事としてまとめました。
動作環境
以下の環境で試しています
- Windows 10
- Python 3.6.8 (64bit)
- Google Cloud SDK
GCPでプロジェクトを作成したり、gcloudの初期設定をしたり、Pythonのセットアップしたり、必要なパッケージをpipでインストールしたりは、前述の記事とほぼ変わりませんので参考にしてください。
Speech APIとCloud Speech-to-Textは別物??
GCPのコンソールから「speech」で検索すると、以下のように3種類のAPIが見つかります。
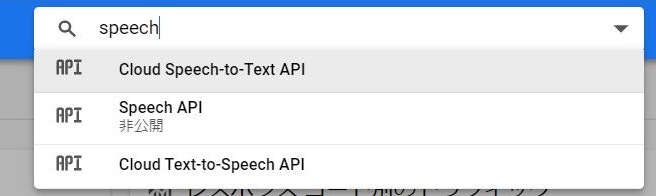
以前は「Speech API」を使っていたのですが、どうやら現在は非公開になっているようで、「Cloud Speech-to-Text API」に名称も機能も変わっているようです。
今回はこちらを使うのでこれを有効化します。
もう1つの「Cloud Text-to-Speech API」は文字を音声にするAPIなので今回は説明しません。
公式のサンプルコードで試す
公式サイトに Pythonでストリーミング音声認識するためのサンプルコード があります
まずはこれをコピペして適当な名前(この記事ではtranscribe_streaming_mic.py)と名前をつけてしてローカル(この記事ではCドライブ直下)に保存します。
このままだと英語用になってますので、途中の
language_code = 'en-US'
となっている部分を
language_code = 'ja-JP'
と日本語を認識する設定になるように書き換えます。
これでコマンドプロンプトからstreamオプションをつけて実行してみます。
c:\>transcribe_streaming_mic.py stream
Traceback (most recent call last):
File "C:\transcribe_streaming_mic.py", line 7, in <module>
from google.cloud.speech import enums
ImportError: cannot import name 'enums'
enumsがインポートできないというエラーが出てしまいました(汗・・
speech-v1を使うように変更
pipでgrpc.google.cloud.speech-v1を追加インストールします。
pip install grpc.google.cloud.speech-v1
そして、サンプルコードで以下のようにライブラリをインポートしている部分があります。
from google.cloud import speech
from google.cloud.speech import enums
from google.cloud.speech import types
これを以下のようにspeech_v1をインポートするように書き換えます。
from google.cloud import speech_v1 as speech
from google.cloud.speech_v1 import enums
from google.cloud.speech_v1 import types
これで準備が整ったので再度実行してます。
c:\>transcribe_streaming_mic.py stream
(中略)
warnings.warn(_CLOUD_SDK_CREDENTIALS_WARNING)
今度は認証のエラーが出てしまいました(汗・・
サービスアカウントキーの作成
GCPコンソールの「APIとサービス > 認証情報」からサービスアカウントキーを作成します。
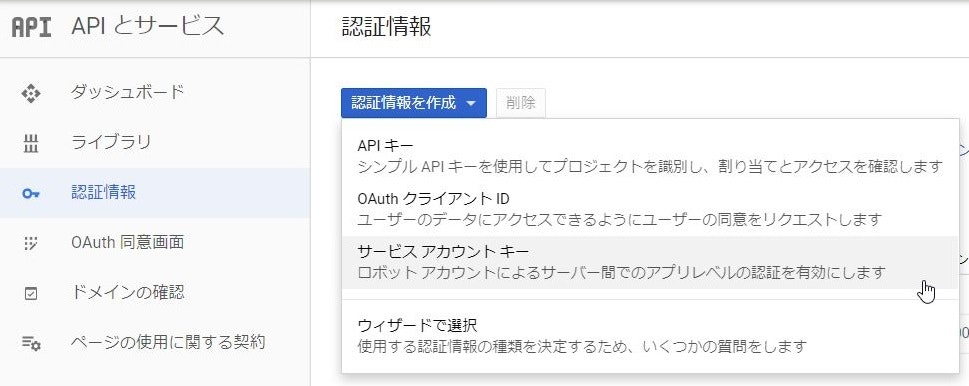
サービスアカウントキーに適当な名前(この記事ではspeech-to-text)をつけます。
役割は何が最低限必要かよくわからなかったのですが、Projectの「閲覧者」を与えれば結果的に動作しました。
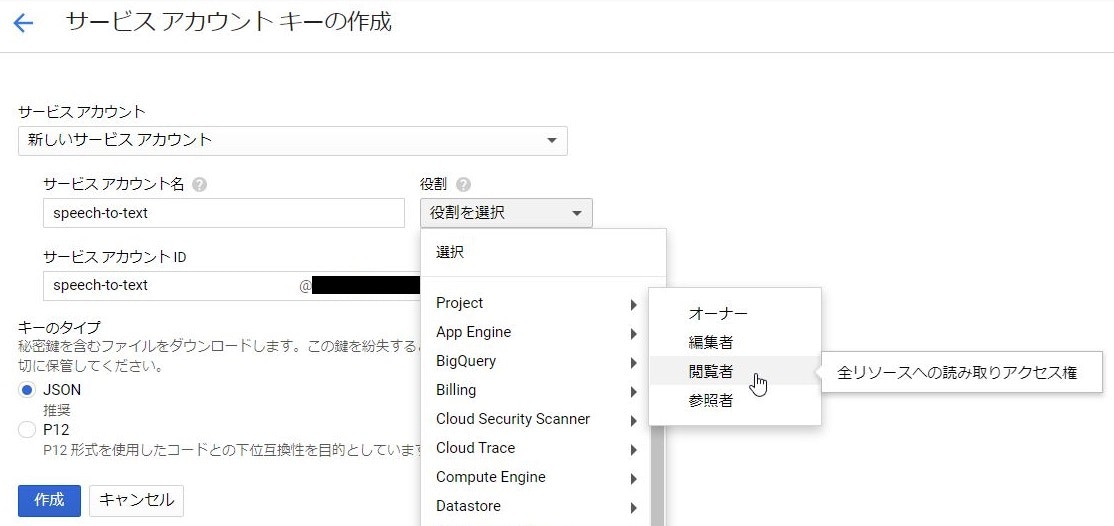
これでjsonファイルを作成します。(この記事ではcredential.jsonとしてCドライブ直下に保存します)
そしてコマンドプロンプトから、環境変数としてこのjsonを指定します。
set GOOGLE_APPLICATION_CREDENTIALS=C:\credential.json
準備完了
こんどこそ準備が整ったので実行します。
PCのマイクに向かって喋ると認識された文字が出てくるはずです。
