はじめに
今までコールセンターへの音声認識システムの導入とかに携わってきました。
音声認識の方式には大きく2種類あります。
-
バッチ型
- 音声ファイルを渡すと認識した結果が返ってくる
- コールセンターの通話録音をテキスト化してビッグデータ分析とかで活用できる
- Youtube動画の自動字幕とかでも使われている。
-
リアルタイム型(またはストリーミング型)
- 喋っている音声がリアルタイムで認識されていく。
- コールセンターのスーパーバイザが複数のオペレータの音声をモニタリングしたりする場合に活用できる
- 最近だとAbemaTVで記者会見の生中継とかでAIポンが使われている
で、クラウド型の音声認識APIに関しては以下が4強と言われています。
ただ、2019年8月現在でAmazon Transcribeは日本語対応していません。
→ 2019年11月にAmazon Transcribeは日本語対応しました!
その場合、国内だとNTTコミュニケーションズのCOTOHA Voice Insight あたりと連携して実装している事例はできているようです。
今回は特に評判がよいGoogle Cloud Speech APIの日本語認識がどんなものかを試してみようと思います。
環境
WindowsのPCとPython3を使います。クラウド側はGCPです。
この辺のセットアップが済んでいる人や、ハンズオンに興味ない人は「使い物になる精度なのか?」まで飛んでください。
GCPのプロジェクト作成
まずはGCPコンソールにログインしてプロジェクトを作成します。
プロジェクト名は適当につけます。プロジェクトIDに関しては後で変更ができないので注意です。
次にコンソールの検索窓に「cloud speech api」と入れると対象のAPIが見つかります。
これを有効にします。

Cloud SDKの導入
ダウンロード
GCPのページからWindows版をダウンロードします。
インストール
ダウンロードしたらインストールしていきます。
インストールディレクトリもここではデフォルトにします。
- C:\Users\ユーザー名\AppData\Local\Google\Cloud SDK
インストールが終わったら以下のコマンドプロンプトがでてきます。
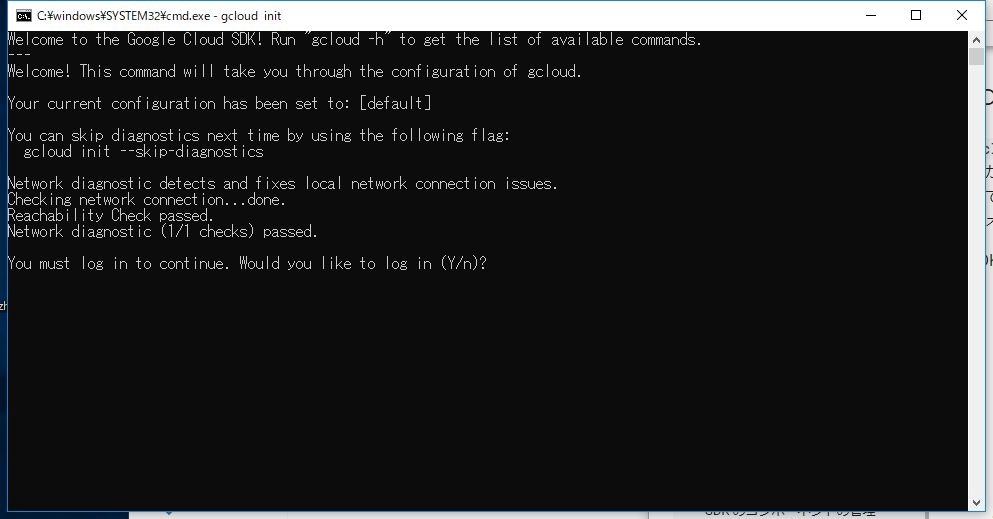
「Y」をおすとブラウザが開きGoogleアカウントにログインする画面が出てきます。
GCPのアカウントでログインして認証しましょう。
次にプロジェクトを選びます。
さきほど画面から作ったプロジェクトIDが表示されると思いますので番号を選択しましょう。
次にリージョンです
東京リージョンは「asia-northeast1」になります。
a.b.cはzoneの違いで、同じ東京でも違うデータセンターと考えてください(厳密にはちょっと異なりますが)
ここでは「37」の「asia-northeast1a」を選択します。
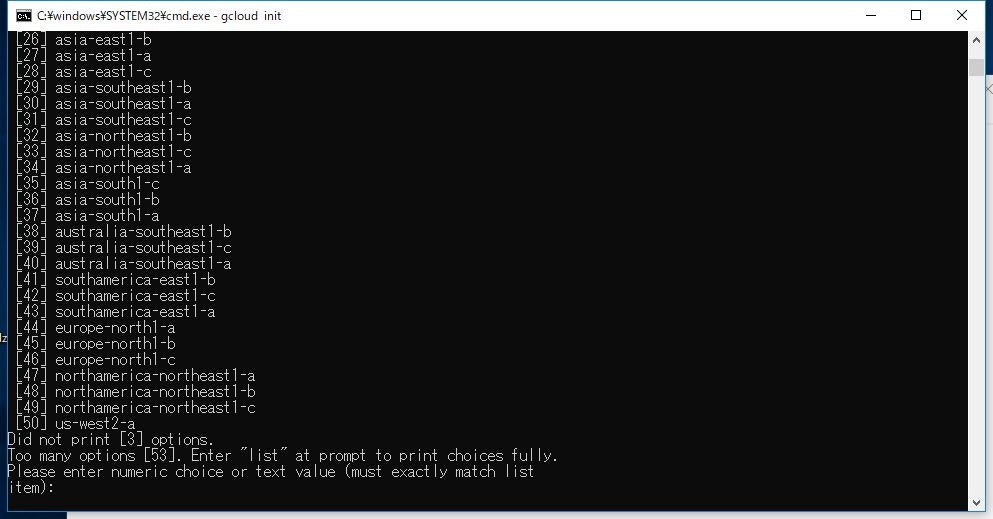
これでGCP CLIの初期設定が完了しました。
やりなおしたければ
gcloud init
で再設定できます。
デフォルト認証設定
GCPのアプリケーションで認証するためのデフォルト認証設定をします。
gcloud auth application-default login
ブラウザが開きGoogleの認証を求められます。
実際のアプリケーションを動作させる場合はサービスアカウントキーなどを作りますが、ここではちょっと動作確認したい程度なのでそのままGCPのアカウントで認証をします。
python3のインストール
ダウンロード
Pythonのページよりダウンロードしましょう。
Windowsの64bitOSなら「Windows x86-64 executable installer」にしておきましょう。
※ バージョンは3.6系を選んでください。2018年7月現在、3.7系だとこのあとのpyaudioのインストールで失敗します。(portaudioのライブラリが含まれていないため)
pip will fetch and install PyAudio wheels (prepackaged binaries). Currently, there are wheels compatible with the official distributions of Python 2.7, 3.4, 3.5, and 3.6. For those versions, both 32-bit and 64-bit wheels are available.
These binaries include PortAudio v19 v190600_20161030, built with MinGW. They support only the Windows MME API and do not include support for DirectX, ASIO, etc. If you require support for APIs not included, you will need to compile PortAudio and PyAudio.
インストール
一番下の「Add Python 3.6 to PATH」はチェックしておきましょう。
動作確認
インストールが終わったらコマンドプロンプトから
python
と打ってパスが通っていることを確認しましょう。
必要なパッケージのインストール
コマンドプロンプトからPIPで必要なパッケージをインストールします。
python -m pip install --upgrade pip
pip install google gcloud google-auth google-cloud-speech grpc-google-cloud-speech-v1beta1
pip install pyaudio
音声認識してみる
※2019/9/10追記:beta版APIのサポート終了によりコードが動作しなくなっています。正式版APIで動作させる方法を「Google Cloud Speech-to-Text APIでマイク入力からストリーミング音声認識をする」として別記事に書きましたので、そちらを参照していただけると幸いです。
Qiitaに投稿するならまさにここをメインにすべきなんでしょうが、あくまで精度を試してみたいということで、
こちらの記事にあるGitHubのコードをほぼそのまま使わせていただきました。
記事の環境はubuntuで確認していますがWindowsでも動きます。
適当なディレクトリに解凍しコマンドプロンプトから実行すると、マイク入力で認識が始まります。
py mic.py
使い物になる精度なのか?
ニュースを読み上げてみる。
以下の文章をマイクに向かって読み上げてみました
強い台風12号は28日20時現在、御前崎市の南東約90kmの海上を西に時速35kmで進んでいます。
中心気圧は965hPa、中心付近の最大風速は35m/sで強い勢力を保ったままです。
静岡県と愛知県、それに伊豆諸島の一部が台風の暴風域に入っています。引用元:ウェザーニュース(2018年7月28日)
認識結果は以下の通りです
強い台風12号は28日 20時 現在 御前崎市の南東約90 km の海上 西に時速35 kmで進んでいます(confidence: 94 %)
地震 気圧は 965 ヘクトパスカル 中心付近の最大風速は35 M 毎秒で強い勢力を保ったままです(confidence: 94 %)
静岡県と愛知県 それに 伊豆諸島の一部が台風の暴風域に入っています(confidence: 92 %)
かなり素晴らしい精度です。ちなみにconfidenceは確からしさを表します。
「御前崎市(おまえさきし)」とか地名も認識していますし、「キロメートル」を「km」と単位の読み上げも変換してたりします。
ちなみに仕様上、句読点(「、」や「。」)は入らないです。
マンガのセリフを読み上げてみる
おれのグローブボロボロ。
のび太のはピカピカ。
それは、ぼくが大事に扱ってるから。
うそだもんね。
エラーばっかりで、ボールにさわらないからだよ。
もったいないジャイアンとりかえたほうがいいよ。
そりゃいい考え。
グローブもやくにたてばよろこぶさ。
ドラえも~ん。
のび太~~~。引用元:ドラえもん36巻「きこりの泉」より冒頭部分
認識結果がこちら
俺のグローブ ボロボロのび太のはピカピカ(confidence: 92 %)
大事に扱ってるから嘘だもんね(confidence: 95 %)
ばっかりでボールに触らないからだよ(confidence: 94 %)
もったいない ジャイアン 取り替えた方がいいよ(confidence: 90%)
考え グローブも役に立てば 喜ぶさ(confidence: 91 %)
ドラえもん のび太(confidence: 95 %)
ところどころ抜けちゃってる部分がありますが、私の読み方が悪いのかもしれません。
「のび太」「ジャイアン」「ドラえもん」という単語を正確に認識しています。
Googleはもしかするとドラえもんの話だと理解している??
アニメのセリフを読み上げてみる
なるべく日本語になってなくて、認識しなそうなやつということでこんなのを選んでみました。
にっこにっこにー。あなたのハートににこにこにー。
笑顔を届ける矢澤にこにこー。
あっ、だめだめだめぇ~ にこにーは、みんなのも・のっ!引用元:ラブライブ!二期の矢沢にこより
すいません。ラブライブは詳しくありません。。ただこのセリフは聞いたことありました!
妻の横でマイクに向かって読み上げるのは恥ずかしかったです。。
で認識結果はこちら
にっこにっこにーあなたのハートににこにこにー 笑顔届ける矢澤にこにこ(confidence: 92 %)
だめだめだめー にこにーはみんなのもの(confidence: 89 %)
素晴らしいですね!こんなアニメのセリフでもほぼ完璧に認識してます。
Google Cloud Speech APIには辞書登録機能がありません。
とはいえ、「にっこにっこにー」とか多くの人が検索しているからこそ単語として認識するのでしょう。
さすが世界のGoogleです。
双方向の音声認識をやりたかったのだが
もともとコールセンターでの利用シーンを想定し、マイクとスピーカー双方向での音声認識を実現したいと考えていました。
ところが、スピーカー出力でつかっている"PyAlsaAudio"がWindowsに対応しておらず使えないようです。
他の代替モジュールを探したのですが見つからず。一旦ここまでとさせていただきます。
さいごに
冒頭述べたとおりリアルタイムの音声認識は今後様々なシーンでの活用が期待できます。
英語に比べて日本語は
- 単語の区切りがない(活用により変化する)
- カナ、漢字への変換が必要(文脈から判断が必要なのでリアルタイムは特に難しい)
- 同音異義語が多い(同上)
といったところから難易度が高いと思われます。
4強はすべてアメリカの企業ということもありなかなか力を入れてこないのではないかと。
なので精度向上には日本人エンジニアの貢献がかかせない分野だと思います。