目的
英語の講演や会議に参加し録音した音源を文字データとして保管しておく手段の一つとしてGoogle Cloud Speech API を使った音声の文字起こしの記事が参考になったので、自分なりに下記に手順をまとめ直しておきます(手順メモ)。
事前準備
-
本手順では Google Cloud Platform を利用するため、Google Cloud Platform の簡単スタートアップガイドのサービス共通編(P9-P20)を終えて、プロジェクトが作成済みとします。
-
下記形式に変換済みの音源が作成済みとします(参考:音声変換サイト、 実際に利用した音源(PyConJP2017英語基調講演))。
- FLAC
- モノラル
- 16000Hz
- 16bit
手順
1. コンソール画面に入る
Google Cloud Platform URL にアクセスして[コンソールを開く]を押して、コンソール画面に入ります。
Google Cloud Platform コンソールログイン画面:
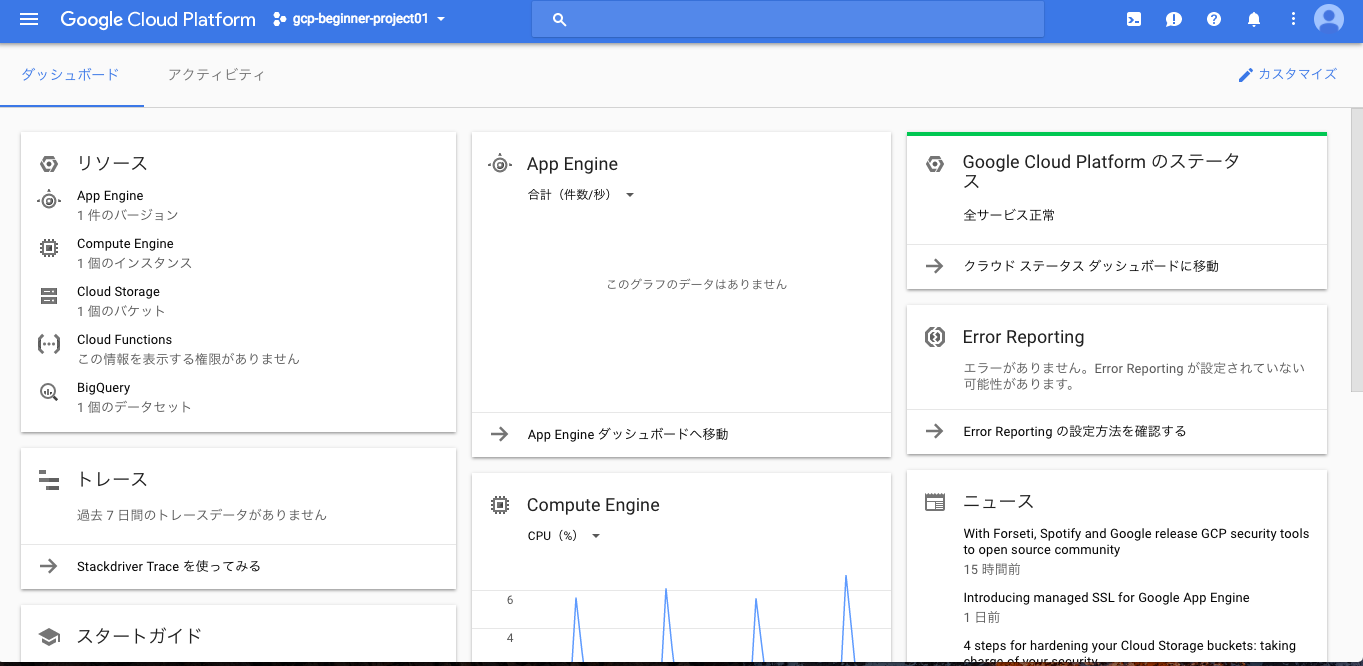
コンソール画面:
2. Google Cloud Speech API を有効化する
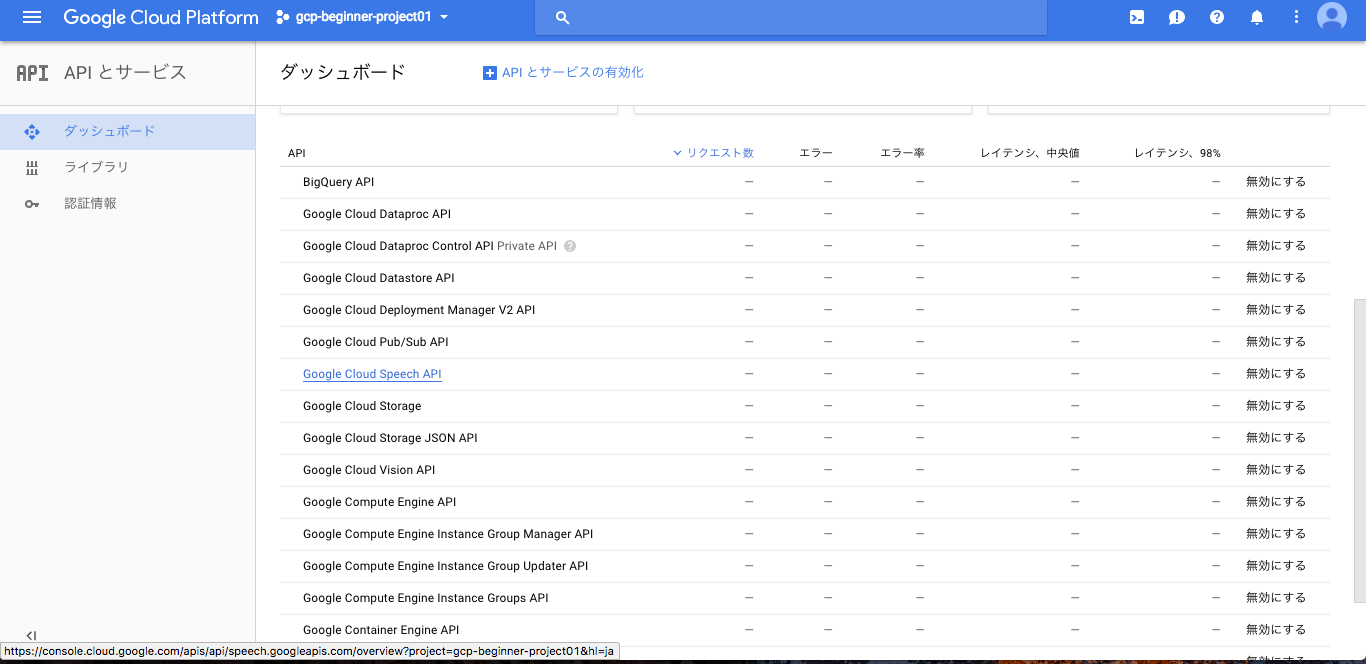
コンソール画面左上の[ツールとサービス] > [APIとサービス] > [ライブラリ] を選択し、APIの一覧から[Speech API]を選択し、[有効にする]を押して Google Speech API を有効にします。

API一覧画面

APIの有効化(既に有効化されているので[無効にする]が表示されている)

[APIとサービス] > [ダッシュボード] でGoogle Speech APIの有効化が確認できる:
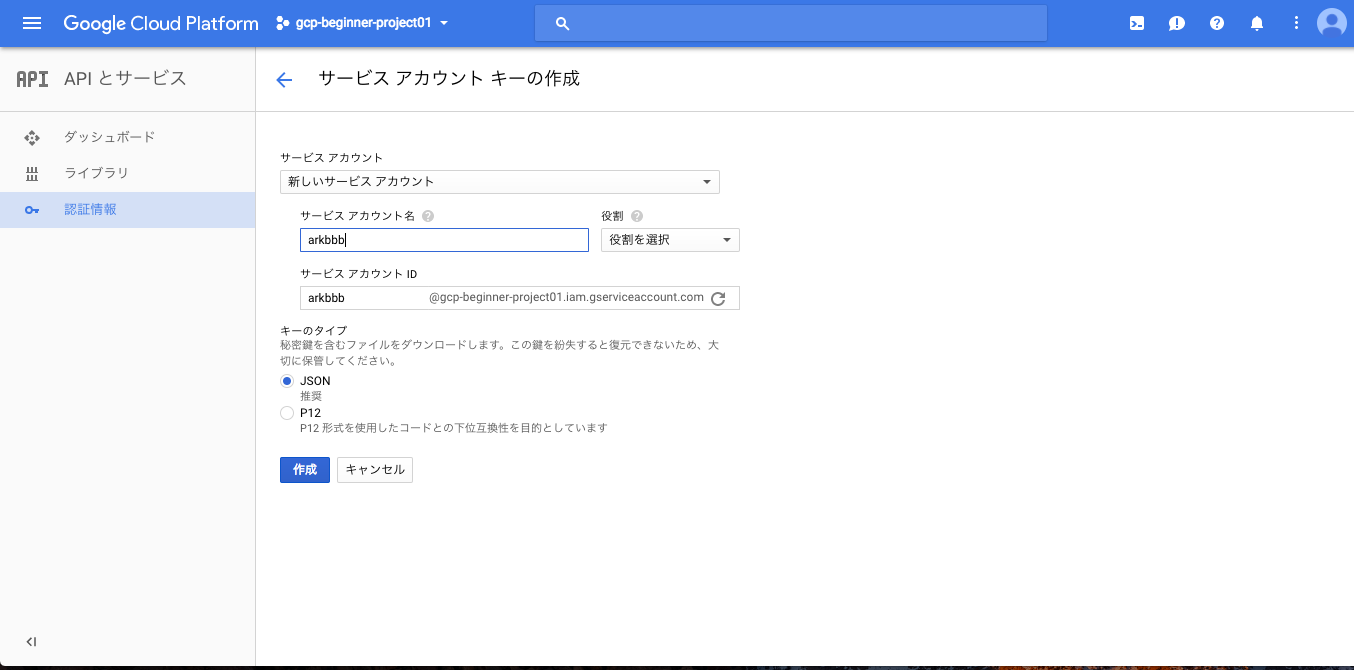
3. APIの認証情報の作成(サービスアカウントキーの作成)
左の[APIとサービス] > [認証情報] > [認証情報を作成] > [サービスアカウントキー]を選択し、適当な[サービスアカウント名](ここでは仮にarkbbbとした)を設定し、作成ボタンを押してJSONファイルをダウンロードする。
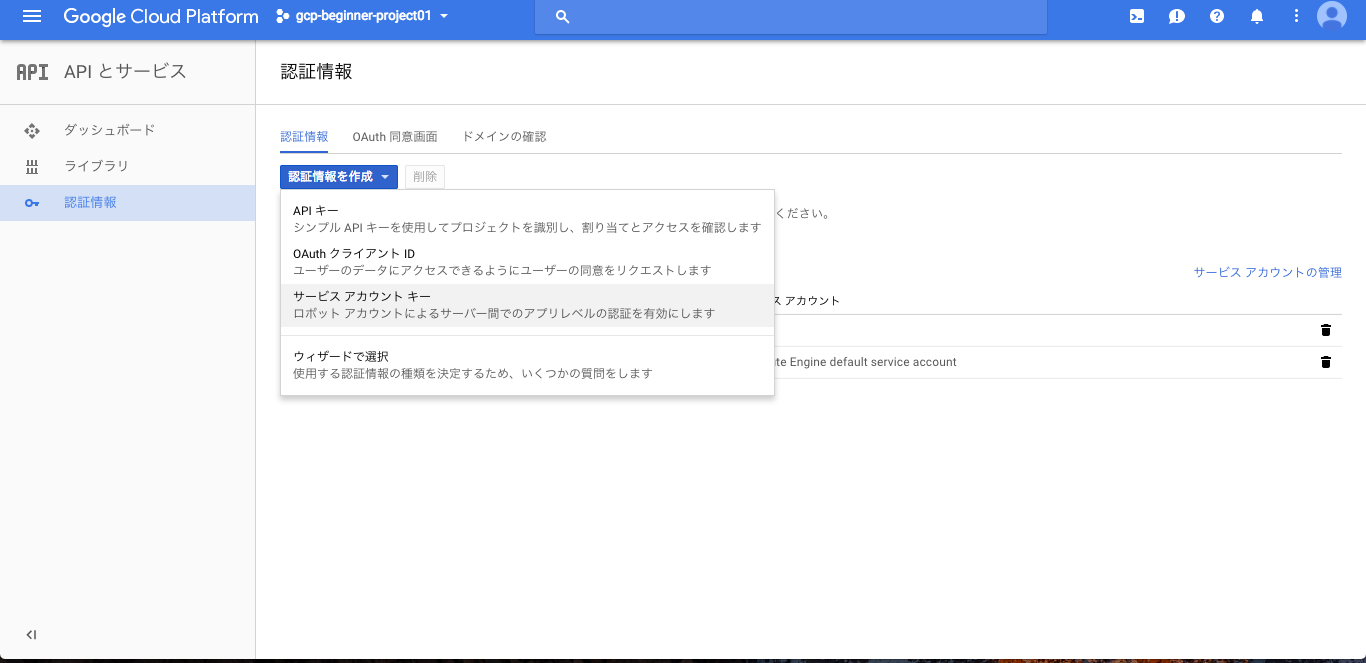
サービスアカウントキーの作成画面:
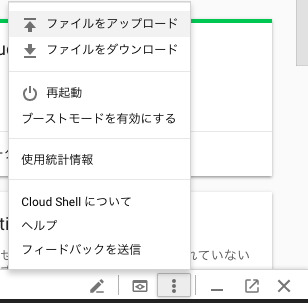
4. Google Cloud ShellでAPI認証する(サービスアカウントキーJSONのアップロード&環境変数登録)
Google Cloud Platform コンソール画面右上部の Google Cloud Shellボタンで Google Cloud Shell を起動し、3.で取得したJSONをアップロードし、環境変数に設定する
Google Cloud Shellボタン:

JSONのアップロード:
$ export GOOGLE_APPLICATION_CREDENTIALS=[3.で取得したJSON名].json
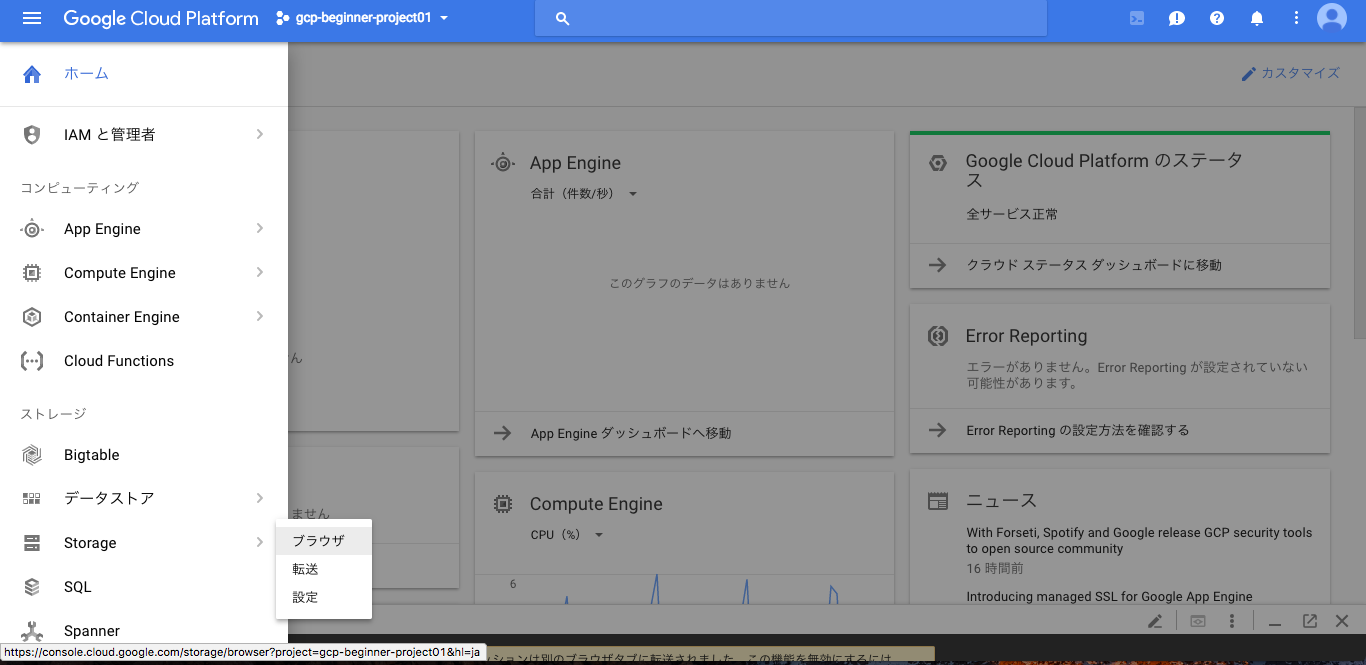
5. 音声データのアップロード
事前準備した音声データを Google Cloud Storage にアップロードします。
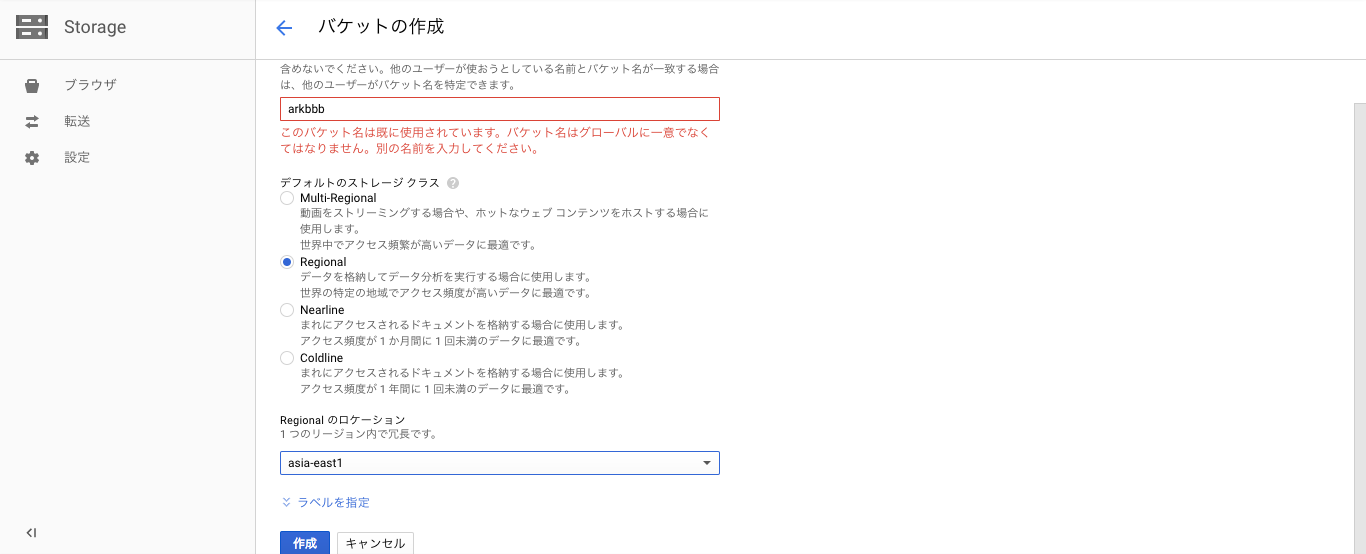
まず画面左上の[ツールとサービス] > [Storage] > [ブラウザ] を選択し、[バケットの作成]でバケットを作成し、その作成したバケットをダブルクリックして、[ファイルのアップロード]から音声データをアップロードする。
Google Cloud Storage画面へ移動する:
バケットの作成(バケット名、その他設定はテキトーに):
バケット内へのファイルのアップロード:

6. 文字起こし実行Pythonスクリプトの作成
Google Cloud Shell上で文字起こし実行用のPythonスクリプトを作成します。
$ nano transcribe.py
文字起こし用のPythonスクリプト(英語音声用):
# !/usr/bin/env python
# coding: utf-8
import argparse
import io
import sys
import codecs
import datetime
import locale
def transcribe_gcs(gcs_uri):
from google.cloud import speech
from google.cloud.speech import enums
from google.cloud.speech import types
client = speech.SpeechClient()
audio = types.RecognitionAudio(uri=gcs_uri)
config = types.RecognitionConfig(
sample_rate_hertz=16000,
encoding=enums.RecognitionConfig.AudioEncoding.FLAC,
language_code='en-US')
operation = client.long_running_recognize(config, audio)
print('Waiting for operation to complete...')
operationResult = operation.result()
d = datetime.datetime.today()
today = d.strftime("%Y%m%d-%H%M%S")
fout = codecs.open('output{}.txt'.format(today), 'a', 'shift_jis')
for result in operationResult.results:
for alternative in result.alternatives:
fout.write(u'{}\n'.format(alternative.transcript))
fout.close()
if __name__ == '__main__':
parser = argparse.ArgumentParser(
description=__doc__,
formatter_class=argparse.RawDescriptionHelpFormatter)
parser.add_argument(
'path', help='GCS path for audio file to be recognized')
args = parser.parse_args()
transcribe_gcs(args.path)
日本語の文字起こしをしたい場合は下記1行を修正する:
language_code='en-US')
↓
language_code='ja-JP')
7. 音声文字起こしの実行
Google Cloud Console 上で下記コマンドにて文字起こしを実行します。
$ python transcribe.py gs://バケット名/音声データ名.flac
8. 実行結果
実行後にGoogle Cloud Console 上 ls コマンドで作成されたファイル確認すると[output*.txt]という名前のテキストファイルができているので、それを開いて結果が確認できます。最初の1~2分の結果は下記でした。音源と合わせて聞くとちょっとしたところは間違いもありますが、概ね文字起こしされている点確認できます。
and not.
We have just attended this big Tatum Outlet
and we held a pydata event it was actually the first I did it
and some of these slides are actually problem, says talk to and so at strata we saw many people talking about the Duke talking about Big Data there were looking at using Java in a management
and there was a whole lot of our versus Python language rewards on Facebook
the Travis and I were not content with the state of things we saw that python to play a very significant role Travis made the slide that's from The Little Prince that shows a snake swallowing the open
he was also talking about using compilers make python faster
it was also not that pilot event that we were very fortunate to have weido been awesome stopping by and we talked to him about things like the matrix multiplication operator we talked about coding expressions and things like that
and so this actually his picture show does Travis and West McKinney who's the greater pandas and Guido van Rossum
add
and we ask we don't fix the packaging problem he told us that we should do it ourselves
and so we did and that's how it came up with Honda and Anaconda which I think quite elegantly solves the difficult packaging problems for the Scientific Games
so we accepted the challenge and so for those who don't know what Anaconda is very quickly I'll give you it is basically a very simple way and very reliable way to get final versions of many very popular typical to build packages in libraries in the python ecosystem
ちなみに実際に結果データはこちら
注意点
- 無料で利用できる容量(月60分データ以内)という制限があり、それ以上は有料になる点注意が必要です。詳細参考
- 音声変換には25分あたり7-8分程度の時間がかかります(上記音声データは25分程度のデータ)。
- 上記結果を見れば明らかですが、音声をそのまま文字にするだけなので段落分け等はできないようです。
参考
- Google Cloud Speech API を使った音声の文字起こしの記事が情報として比較的最近(2017年9月現在)で参考になりました。
所感
- Google Cloud Speech API を使えばある程度の精度で音声(英語)の文字起こしができることが確認できた(あくまで1例のみだが)
- Google Cloud Platform自体は使い慣れてくればそれほど気にならないが上記のように一から説明しようとすると色々ステップが多い印象を受けた
- Google Cloud Speech API 自体ベータ版なので、今後利用制限や料金プランが変わる可能性もあるので使うたびごとにそれらはチェックした方が良さそう