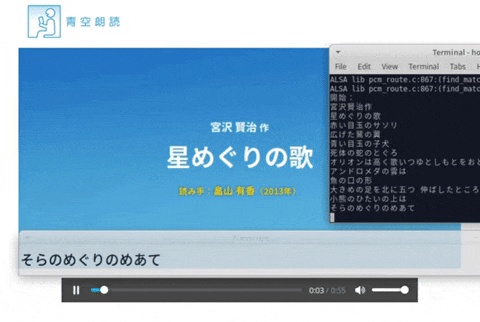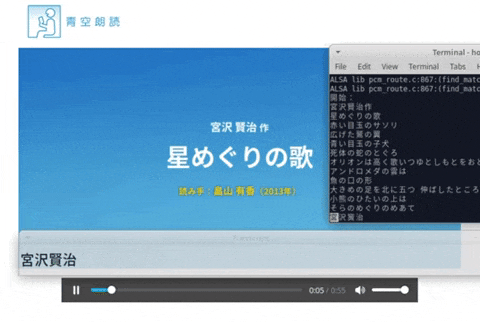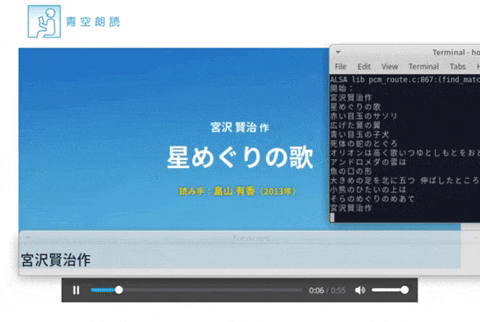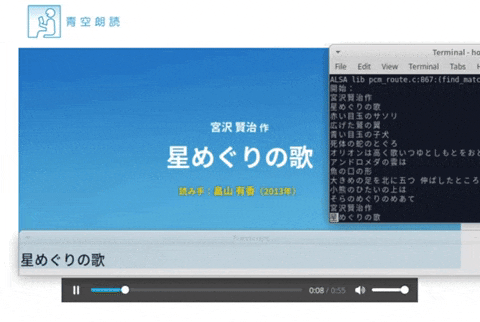
マイクなどからリアルタイムに聞き取って字幕を表示します。画像は朗読を聞き取った時の動作風景。
動機
今使っているノートパソコンはスピーカーから音が出なくなって困っています。直さずに使っているのですが、たまに図書館などで動画をみたいときなどに字幕があれば音なしでも視聴できるな、などと考えていました。Youtubeは字幕が表示できない動画もあるのです。そんな折、Google Cloud Speech-to-Textを使えば簡単に作成できそうというのがわかりましたので、Googleのドキュメントにあるサンプルプログラムを少し変更して試しに作ってみました。
Google Cloud Speech-to-Textとは
GoogleのHPには次のようにあります。
Cloud Speech-to-Text を使用すると、Google の音声認識技術をデベロッパーのアプリケーションに簡単に統合できます。Speech-to-Text API サービスに音声を送信すると、文字変換されたテキストを受け取ることができます。
非常に簡潔に書かれているので、もはや説明する必要はありませんね。
どうやって送信するのか
APIは様々な言語(C#, Go, Java, Node.js, PHP, Python, Ruby)に対応していますが、今回は手軽に使えそうなPythonを使用します。
下準備
もうすでにGoogle Cloud Speech-to-TextをPythonから使える場合は準備完了していますのでこちらへ
クライアントライブラリのインストール
まず、google cloudを使うためのクライアントライブラリをインストールします。
pip install --upgrade google-cloud-speech
現在わたしの環境では一発で入りましたが、依存関係でうまく入らないこともありました。
環境に寄っては苦労するかも知れません。
秘密鍵の設定
秘密鍵をjsonとして保存します。
プロジェクトを作成または選択します。
プロジェクトに Google Speech-to-Text API を有効にします。
サービス アカウントを作成します。
JSON として秘密鍵をダウンロードします。
GoogleのHPより
簡単に書いていますが、jsonのダウンロードするところは意外とわかりにくかったです。
APIとサービスのメニューの中に認証情報というページが有るのでそこで作れました。
その後、前例に従って環境変数に設定しました。
以下の一行を~/profileに書き加えました。ここではダウンロードしたものをsample.jsonとします
export GOOGLE_APPLICATION_CREDENTIALS="/home/(ユーザー名)/sample.json"
これで次回ログインした際には環境変数としてGOOGLE_APPLICATION_CREDENTIALSが設定されますので、クライントライブラリは自動で読み取り使えるようになります。
Google Cloud Speech-TextをPythonから使う
というわけで下準備ができましたら、いよいよPythonのコードを書きます。
GoogleのAPIのドキュメントページをみながらすこし変えて造ってみたものが次のものです。
マイクから音声を入力する部分
これはpyaudioを使ってやるようです。
# Copyright 2018 Google Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
class MicrophoneStream(object):
"""Opens a recording stream as a generator yielding the audio chunks."""
def __init__(self, rate, chunk):
self._rate = rate
self._chunk = chunk
# Create a thread-safe buffer of audio data
self._buff = queue.Queue()
self.closed = True
def __enter__(self):
self._audio_interface = pyaudio.PyAudio()
self._audio_stream = self._audio_interface.open(
format=pyaudio.paInt16,
# The API currently only supports 1-channel (mono) audio
# https://goo.gl/z757pE
channels=1, rate=self._rate,
input=True, frames_per_buffer=self._chunk,
# Run the audio stream asynchronously to fill the buffer object.
# This is necessary so that the input device's buffer doesn't
# overflow while the calling thread makes network requests, etc.
stream_callback=self._fill_buffer,
)
self.closed = False
return self
def __exit__(self, _type, value, traceback):
self._audio_stream.stop_stream()
self._audio_stream.close()
self.closed = True
# Signal the generator to terminate so that the client's
# streaming_recognize method will not block the process termination.
self._buff.put(None)
self._audio_interface.terminate()
def _fill_buffer(self, in_data, _frame_count, _time_info, _status_flags):
"""Continuously collect data from the audio stream, into the buffer."""
self._buff.put(in_data)
return None, pyaudio.paContinue
def generator(self):
"""Generator."""
while not self.closed:
# Use a blocking get() to ensure there's at least one chunk of
# data, and stop iteration if the chunk is None, indicating the
# end of the audio stream.
chunk = self._buff.get()
if chunk is None:
return
data = [chunk]
# Now consume whatever other data's still buffered.
while True:
try:
chunk = self._buff.get(block=False)
if chunk is None:
return
data.append(chunk)
except queue.Empty:
break
yield b''.join(data)
# [END audio_stream]
こちらは、Googleのサンプルをそのまま利用します。
普通に検索するとGoogleCloudのページが出てきますが、APIの使い方はgoogleapis.github.ioのほうが詳細に確認できますのでPython Client for Cloud Speech APIが非常に参考になりました。
今回のGoogleのサンプルのコードはGoogleの説明ページ:ストリーミング入力の音声文字変換
から拝借しています。
ストリーミングで変換をするためのクラスの作成
次に、このマイクロフォンの入力をGoogleに渡すためのクラスを作りました。
下記の通りサンプルをすこし変えたものになっています。
単純に使えるようにクラスにして、エラー時の例外とコールバックイベントを追加しました。
使い方が間違っているかも知れませんが、出来うるだけすぐに録音が開始されるようにAPIの設定の順番などをすこし変えています。
class GoogleCloudSpeech:
"""
Google Cloud Speechを使うためのクラス
使い方:
from streaming_transcript import GoogleCloudSpeech
SPEECH = GoogleCloudSpeech(callbacks={"transcript": callfunc})
SPEECH.listen()
コールバック関数の第一引数は聞き取ったテキスト
function callfunc(text)
"""
def __init__(self, callbacks=None, console=True, rate=16000):
"""Init."""
if isinstance(callbacks, dict):
for name in callbacks:
if not callable(callbacks[name]):
raise ValueError("Callback {} is not callable."
.format(name))
self.callbacks = callbacks
else:
self.callbacks = {}
self.rate = rate
self.console = console
def __print(self, text):
if self.console:
sys.stdout.write(text)
sys.stdout.flush()
def listen_print_loop(self, responses):
"""Iterate through server responses and prints them.
The responses passed is a generator that will block until a response
is provided by the server.
Each response may contain multiple results, and each result may contain
multiple alternatives; for details, see https://goo.gl/tjCPAU. Here we
print only the transcription for the top alternative of the top result.
In this case, responses are provided for interim results as well. If the
response is an interim one, print a line feed at the end of it, to allow
the next result to overwrite it, until the response is a final one. For the
final one, print a newline to preserve the finalized transcription.
"""
num_chars_printed = 0
for response in responses:
if not response.results:
continue
# The `results` list is consecutive. For streaming, we only care about
# the first result being considered, since once it's `is_final`, it
# moves on to considering the next utterance.
result = response.results[0]
if not result.alternatives:
continue
# Display the transcription of the top alternative.
transcript = result.alternatives[0].transcript
# Display interim results, but with a carriage return at the end of the
# line, so subsequent lines will overwrite them.
#
# If the previous result was longer than this one, we need to print
# some extra spaces to overwrite the previous result
overwrite_chars = " " * (num_chars_printed - len(transcript))
if not result.is_final:
self.__print(transcript + overwrite_chars + '\r')
num_chars_printed = len(transcript)
self.callbacks.get("middle", lambda x: True)(transcript)
else:
self.__print(transcript + overwrite_chars + "\n")
self.callbacks.get("transcript", lambda x: True)(transcript)
num_chars_printed = 0
break
def listen(self, language_code='ja-JP'):
"""Listen."""
# See http://g.co/cloud/speech/docs/languages
# for a list of supported languages.
client = speech.SpeechClient()
config = types.RecognitionConfig(
encoding=enums.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=self.rate,
model=None,
speech_contexts=[types.SpeechContext(
)],
language_code=language_code)
streaming_config = types.StreamingRecognitionConfig(
config=config,
single_utterance=True,
interim_results=True
)
self.callbacks.get("ready", lambda: True)()
with MicrophoneStream(self.rate, int(self.rate/10)) as stream:
self.callbacks.get("start", lambda: True)()
while True:
try:
audio_generator = stream.generator()
requests = (types.StreamingRecognizeRequest(audio_content=content)
for content in audio_generator)
responses = client.streaming_recognize(streaming_config, requests)
self.listen_print_loop(responses)
except exceptions.OutOfRange:
print("Time exceeded.(OutOfRange)")
except exceptions.ServiceUnavailable:
print("Connection closed.(ServiceUnavailable)")
except KeyboardInterrupt:
print("KeyboardInterrupt.")
break
except:
print("Unexpected error:", sys.exc_info()[0])
raise
self.callbacks.get("end", lambda: True)()
def on(self, name, callfunc):
"""On."""
if callable(callfunc):
self.callbacks[name] = callfunc
return True
return False
def off(self, name):
"""Off."""
if name in self.callbacks:
self.callbacks.pop(name)
return True
return False
javascriptのように
SPEECH.on("transcript", lambda x: print(x))
というような表記でイベントを登録できるようにしています。
作成してみたイベントは以下の通り
- ready 録音前の状態に呼び出されるイベント 引数なし
- start 録音開始した時に呼び出されるイベント 引数なし
- middle 聞き取り中の文字列を返すイベント 引数1
- transcript 聞き取り結果の文字列を返すイベント 引数1
- end 録音が終了したときに呼び出されるイベント 引数なし
ソースの中で
self.callbacks.get("ready", lambda: True)()
こんな感じで呼び出しています。
dictのgetメソッドで対応する名前を呼び出してなかったら、無名のTrueを返すだけの関数を実行しますので何もしないです。
あとは必要なライブラリをインポートして
import sys
import pyaudio
from six.moves import queue
from google.api_core import exceptions
from google.cloud import speech_v1p1beta1 as speech
、メイン関数を
if __name__ == '__main__':
SPEECH = GoogleCloudSpeech()
SPEECH.listen()
などとすれば、日本語で喋りかけると喋った内容がコンソールに表示されるはずです
これはgoogleのHPにあるサンプルと同じ動作です。
例外の定義はgoogle.apiのexceptionsをインポートすれば良いみたいです。
今回はイベントを追加できるようにしたので、これにtkinterですこしだけGUIを追加してみました。
Tkinterで透過ウィンドウに表示する
# 追加のインクルードです。
import tkinter
import threading
def wait():
if sys.version_info[0] == 2:
raw_input("PRESS ENTER AND TALK\n")
else:
input("PRESS ENTER AND TALK\n")
def create_window(width=800, height=50):
root = tkinter.Tk()
root.title("Transcript ")
root.wait_visibility(root)
root.wm_attributes('-alpha', 0.8)
root.geometry("{}x{}".format(width, height))
frame = tkinter.Frame(root, width=width, height=height)
val_text1 = tkinter.StringVar()
text1 = tkinter.Label(text="Init.", font=("", 17), textvariable=val_text1)
text1.pack(fill="both", side="left")
frame.pack()
return root, val_text1
def change_text(text):
TEXT.set("{}".format(text))
if __name__ == '__main__':
# speechモジュールの設定
SPEECH = GoogleCloudSpeech()
# 録音開始する前に実行されるイベント
SPEECH.on("ready", wait)
# 聞き取りが開始されたときに実行されるイベント
SPEECH.on("start",
lambda: print("開始:"))
# 聞き取り中の結果を受信したときに実行されるイベント
SPEECH.on("middle", change_text)
# 一文の聞き取りが確定したときに実行されるイベント
SPEECH.on("transcript", change_text)
# 何らかの原因で聞き取りが終了したときに実行されるイベント
SPEECH.on("end",
lambda: print("終了:"))
# mainスレッドでtkinterを実行するため、speechはthreadにて起動する
TH = threading.Thread(target=SPEECH.listen, daemon=True)
TH.start()
# guiの準備
ROOT, TEXT = create_window()
ROOT.protocol("WM_DELETE_WINDOW", ROOT.destroy)
TEXT.set("Ready.")
# tkinterのメインループ開始
ROOT.mainloop()
tkinterのrootはメインスレッドで実行しないといけないみたいなので、GoogleCloudSpeechをthreadingで実行しています。
ソースコード全体
speech.enumsとspeech.typesはGoogleCloudSpeechの仕様変更によって廃止され、speechへ統一されたので該当部分を修正しました。(2020年10月25日)
# !/usr/bin/env python
# coding: UTF-8
# Copyright 2018 Hideto Manjo.
# Classes:
# GoogleCloudSpeech
# are wrote by Hideto Manjo
# This program include following lincense code.
# Copyright 2018 Google Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Google Cloud Speech and Text-to-Speak API sample application
using the streaming API.
NOTE: This module requires the additional dependencies. To install
using pip:
pip install pyaudio
pip install pydub
Example usage:
python streaming_transcript.py
"""
import sys
import tkinter
import threading
import pyaudio
from six.moves import queue
from google.api_core import exceptions
from google.cloud import speech_v1p1beta1 as speech
# Due to Google's spec changes, types and enums are no longer used.
# Google Cloud Speechの仕様変更によってenumsとtypesは廃止されました
# speech.enums -> speech
# speech.types -> speech
# from google.cloud.speech_v1p1beta1 import enums
# from google.cloud.speech_v1p1beta1 import types
class MicrophoneStream(object):
"""Opens a recording stream as a generator yielding the audio chunks."""
def __init__(self, rate, chunk):
self._rate = rate
self._chunk = chunk
# Create a thread-safe buffer of audio data
self._buff = queue.Queue()
self.closed = True
def __enter__(self):
self._audio_interface = pyaudio.PyAudio()
self._audio_stream = self._audio_interface.open(
format=pyaudio.paInt16,
# The API currently only supports 1-channel (mono) audio
# https://goo.gl/z757pE
channels=1, rate=self._rate,
input=True, frames_per_buffer=self._chunk,
# Run the audio stream asynchronously to fill the buffer object.
# This is necessary so that the input device's buffer doesn't
# overflow while the calling thread makes network requests, etc.
stream_callback=self._fill_buffer,
)
self.closed = False
return self
def __exit__(self, _type, value, traceback):
self._audio_stream.stop_stream()
self._audio_stream.close()
self.closed = True
# Signal the generator to terminate so that the client's
# streaming_recognize method will not block the process termination.
self._buff.put(None)
self._audio_interface.terminate()
def _fill_buffer(self, in_data, _frame_count, _time_info, _status_flags):
"""Continuously collect data from the audio stream, into the buffer."""
self._buff.put(in_data)
return None, pyaudio.paContinue
def generator(self):
"""Generator."""
while not self.closed:
# Use a blocking get() to ensure there's at least one chunk of
# data, and stop iteration if the chunk is None, indicating the
# end of the audio stream.
chunk = self._buff.get()
if chunk is None:
return
data = [chunk]
# Now consume whatever other data's still buffered.
while True:
try:
chunk = self._buff.get(block=False)
if chunk is None:
return
data.append(chunk)
except queue.Empty:
break
yield b''.join(data)
# [END audio_stream]
class GoogleCloudSpeech:
"""
Google Cloud Speechを使うためのクラス
使い方:
from streaming_transcript import GoogleCloudSpeech
SPEECH = GoogleCloudSpeech(callbacks={"transcript": callfunc})
SPEECH.listen()
コールバック関数の第一引数は聞き取ったテキスト
function callfunc(text)
(例)
音声で入力したテキストをそのままGoogle Cloud Text-to-Speakで発声する場合
GoogleCloudSpeak.listen(callbacks={"transcript":GoogleCloudSpeak.speak})
"""
def __init__(self, callbacks=None, console=True, rate=16000):
"""Init."""
if isinstance(callbacks, dict):
for name in callbacks:
if not callable(callbacks[name]):
raise ValueError("Callback {} is not callable."
.format(name))
self.callbacks = callbacks
else:
self.callbacks = {}
self.rate = rate
self.console = console
def __print(self, text):
if self.console:
sys.stdout.write(text)
sys.stdout.flush()
def listen_print_loop(self, responses):
"""Iterate through server responses and prints them.
The responses passed is a generator that will block until a response
is provided by the server.
Each response may contain multiple results, and each result may contain
multiple alternatives; for details, see https://goo.gl/tjCPAU. Here we
print only the transcription for the top alternative of the top result.
In this case, responses are provided for interim results as well. If the
response is an interim one, print a line feed at the end of it, to allow
the next result to overwrite it, until the response is a final one. For the
final one, print a newline to preserve the finalized transcription.
"""
num_chars_printed = 0
for response in responses:
if not response.results:
continue
# The `results` list is consecutive. For streaming, we only care about
# the first result being considered, since once it's `is_final`, it
# moves on to considering the next utterance.
result = response.results[0]
if not result.alternatives:
continue
# Display the transcription of the top alternative.
transcript = result.alternatives[0].transcript
# Display interim results, but with a carriage return at the end of the
# line, so subsequent lines will overwrite them.
#
# If the previous result was longer than this one, we need to print
# some extra spaces to overwrite the previous result
overwrite_chars = " " * (num_chars_printed - len(transcript))
if not result.is_final:
self.__print(transcript + overwrite_chars + '\r')
num_chars_printed = len(transcript)
self.callbacks.get("middle", lambda x: True)(transcript)
else:
self.__print(transcript + overwrite_chars + "\n")
self.callbacks.get("transcript", lambda x: True)(transcript)
num_chars_printed = 0
break
def listen(self, language_code='ja-JP'):
"""Listen."""
# See http://g.co/cloud/speech/docs/languages
# for a list of supported languages.
client = speech.SpeechClient()
config = speech.RecognitionConfig(
encoding=speech.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=self.rate,
model=None,
speech_contexts=[speech.SpeechContext(
)],
language_code=language_code)
streaming_config = speech.StreamingRecognitionConfig(
config=config,
single_utterance=True,
interim_results=True
)
self.callbacks.get("ready", lambda: True)()
with MicrophoneStream(self.rate, int(self.rate/10)) as stream:
self.callbacks.get("start", lambda: True)()
while True:
try:
audio_generator = stream.generator()
requests = (speech.StreamingRecognizeRequest(audio_content=content)
for content in audio_generator)
responses = client.streaming_recognize(streaming_config, requests)
self.listen_print_loop(responses)
except exceptions.OutOfRange:
print("Time exceeded.(OutOfRange)")
except exceptions.ServiceUnavailable:
print("Connection closed.(ServiceUnavailable)")
except KeyboardInterrupt:
print("KeyboardInterrupt.")
break
except:
print("Unexpected error:", sys.exc_info()[0])
raise
self.callbacks.get("end", lambda: True)()
def on(self, name, callfunc):
"""On."""
if callable(callfunc):
self.callbacks[name] = callfunc
return True
return False
def off(self, name):
"""Off."""
if name in self.callbacks:
self.callbacks.pop(name)
return True
return False
def wait():
if sys.version_info[0] == 2:
raw_input("PRESS ENTER AND TALK\n")
else:
input("PRESS ENTER AND TALK\n")
def create_window(width=800, height=50):
root = tkinter.Tk()
root.title("Transcript ")
root.wait_visibility(root)
root.wm_attributes('-alpha', 0.8)
root.geometry("{}x{}".format(width, height))
frame = tkinter.Frame(root, width=width, height=height)
val_text1 = tkinter.StringVar()
text1 = tkinter.Label(text="Init.", font=("", 17), textvariable=val_text1)
text1.pack(fill="both", side="left")
frame.pack()
return root, val_text1
def change_text(text):
TEXT.set("{}".format(text))
if __name__ == '__main__':
# speechモジュールの設定
SPEECH = GoogleCloudSpeech()
# 録音開始する前に実行されるイベント
SPEECH.on("ready", wait)
# 聞き取りが開始されたときに実行されるイベント
SPEECH.on("start",
lambda: print("開始:"))
# 聞き取り中の結果を受信したときに実行されるイベント
SPEECH.on("middle", change_text)
# 一文の聞き取りが確定したときに実行されるイベント
SPEECH.on("transcript", change_text)
# 何らかの原因で聞き取りが終了したときに実行されるイベント
SPEECH.on("end",
lambda: print("終了:"))
# mainスレッドでtkinterを実行するため、speechはthreadにて起動する
TH = threading.Thread(target=SPEECH.listen, daemon=True)
TH.start()
# guiの準備
ROOT, TEXT = create_window()
ROOT.protocol("WM_DELETE_WINDOW", ROOT.destroy)
TEXT.set("Ready.")
# tkinterのメインループ開始
ROOT.mainloop()
動作風景
実際に動かしてみて朗読を聞き取ってみました。
動画リンクをクリックするとyoutubeのビデオへ飛びます。
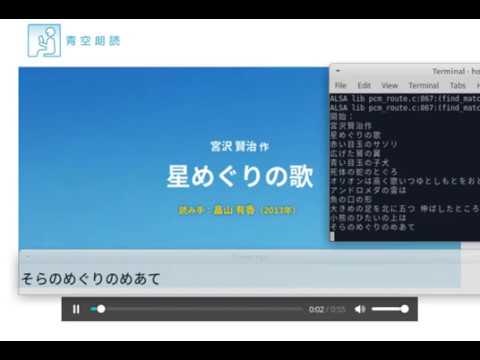
朗読は下記のものを使わせていただきました。
星めぐりの歌 著者:宮沢 賢治 読み手:畠山 有香 時間:54秒
ベータ版のAPIについて
importの記述:
from google.cloud import speech_v1p1beta1 as speech
今回はspeechの部分をspeech_v1p1beta1と書き換えベータ版使用していますが、使ってみた感じですとベータ版ということですが、しっかり使えますしこちらのほうがオプションが豊富なので可能性が広がると思います。
仕様もどんどん変わっていってるみたいなので、最新の使い方はGoogleのAPIのページを参考になさってください。
まとめ
ボタンとかをつけたらこのままでもそれなりに使えるものになりそうです。
今回の例では単純に表示するだけですが、コールバックにgoogle cloud text-to-speechを使えば、日本語を聞き取ってそのまま機械の音声にしたりいろいろできそうです。
聞き取りの精度もかなり強力なので単純にテキストをファイルとして保存したり、いろいろ使えると思います。
聞き取り時間が60分までは無料ですが、その後は有料サービスですので
それなりの料金が発生します。このサンプルを使って、とんでもない請求がこないようにしっかりプロセスは切れたことをご確認ください。この記事が何かの参考になれば幸いです。