ふくだ学習録とは?
ふくだが学習したことの備忘録。
目に見える形で残すことによってやる気を出す個人的な作戦です。
他人に見せるように書いているわけではないので、すごく読みにくいです。
読了した本
データベースエンジニア養成読本 [DBを自由自在に活用するための知識とノウハウ満載!]
ゼロから作るDeepLearning
PHPフレームワーク CakePHP 3入門
SQLアンチパターン
Docker入門
今読んでいる本
なし
アプリ制作
スクレイピングできない。
今回取得したい要素は、画像赤枠部分。
YahooJapanのTOP右側広告部分の情報を取得したい。
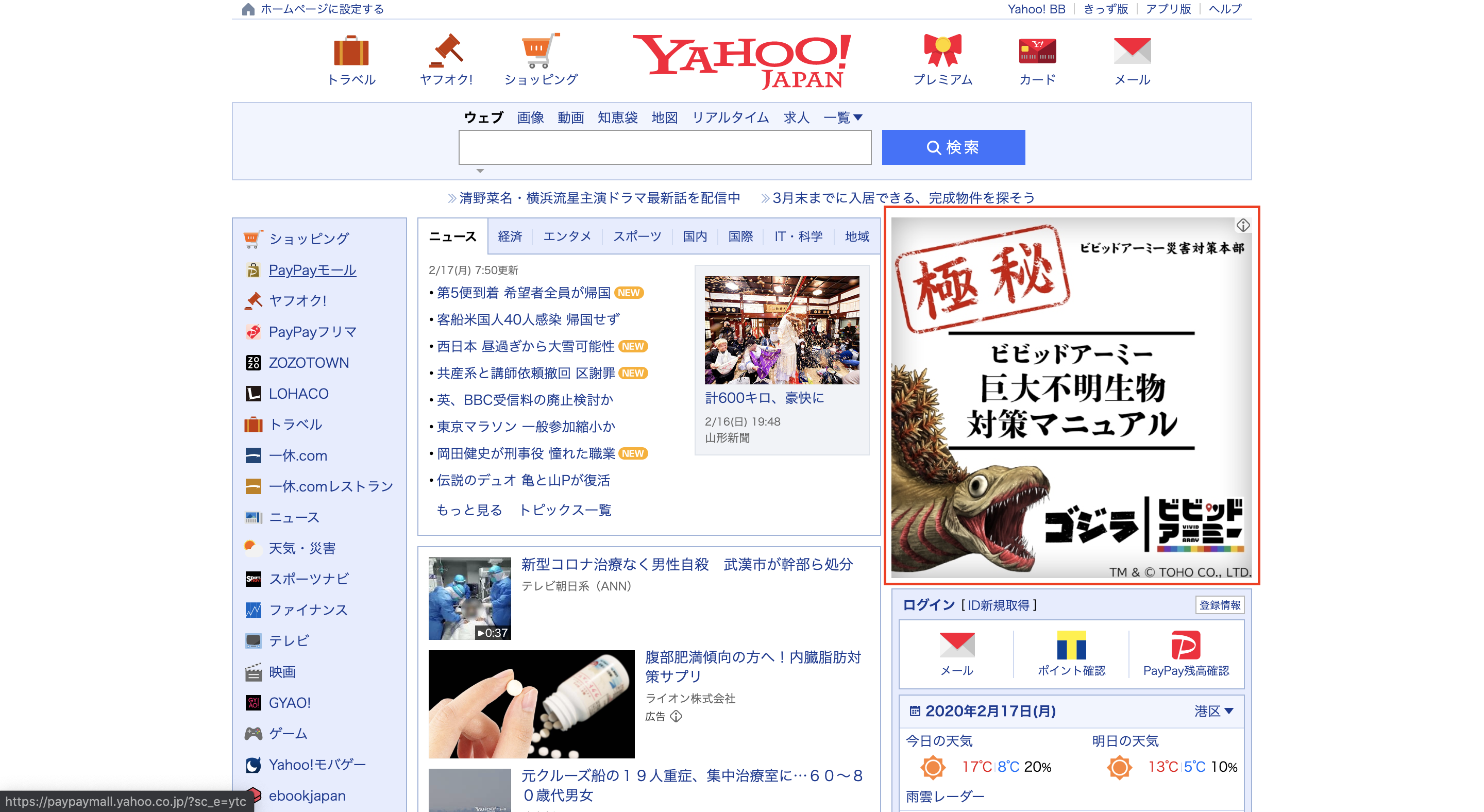
一旦下記の設定で取得できるかどうかスクレイピング実施。
scrapyを用いて、Python, scrapy でお祭りスクレイピングを参考に実施。
import scrapy
from scraping.items import Advertisement
class ScrapyYahoojapanSpiderSpider(scrapy.Spider):
name = 'scrapy_yahooJapan_spider'
allowed_domains = ['www.yahoo.co.jp']
start_urls = ['https://www.yahoo.co.jp/']
def parse(self, response):
# response.css で scrapy デフォルトの css セレクタを利用できる
for post in response.css('#TBP'):
# items に定義した Advertisement のオブジェクトを生成して次の処理へ渡す
yield Advertisement(
src=post.css('img.yjAdImage::attr(src)').extract_first().strip(),
href=post.css('a.yjAdLink::attr(href)').extract_first().strip(),
)
import scrapy
class Advertisement(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
src = scrapy.Field()
href = scrapy.Field()
実行結果は下記。
/src/app/scraping # scrapy crawl scrapy_yahooJapan_spider
2020-02-16 23:14:32 [scrapy.utils.log] INFO: Scrapy 1.8.0 started (bot: scraping)
2020-02-16 23:14:32 [scrapy.utils.log] INFO: Versions: lxml 4.5.0.0, libxml2 2.9.10, cssselect 1.1.0, parsel 1.5.2, w3lib 1.21.0, Twisted 19.10.0, Python 3.6.10 (default, Jan 18 2020, 02:57:08) - [GCC 9.2.0], pyOpenSSL 19.1.0 (OpenSSL 1.1.1d 10 Sep 2019), cryptography 2.8, Platform Linux-4.9.184-linuxkit-x86_64-with
2020-02-16 23:14:32 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'scraping', 'DOWNLOAD_DELAY': 10, 'NEWSPIDER_MODULE': 'scraping.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['scraping.spiders']}
2020-02-16 23:14:32 [scrapy.extensions.telnet] INFO: Telnet Password: edb17c2006230aa4
2020-02-16 23:14:32 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.memusage.MemoryUsage',
'scrapy.extensions.logstats.LogStats']
2020-02-16 23:14:32 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2020-02-16 23:14:32 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2020-02-16 23:14:32 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2020-02-16 23:14:32 [scrapy.core.engine] INFO: Spider opened
2020-02-16 23:14:32 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2020-02-16 23:14:32 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2020-02-16 23:14:32 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.yahoo.co.jp/robots.txt> (referer: None)
2020-02-16 23:14:47 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.yahoo.co.jp/> (referer: None)
2020-02-16 23:14:48 [scrapy.core.engine] INFO: Closing spider (finished)
2020-02-16 23:14:48 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 438,
'downloader/request_count': 2,
'downloader/request_method_count/GET': 2,
'downloader/response_bytes': 5984,
'downloader/response_count': 2,
'downloader/response_status_count/200': 2,
'elapsed_time_seconds': 15.463008,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2020, 2, 16, 23, 14, 48, 32600),
'log_count/DEBUG': 2,
'log_count/INFO': 10,
'memusage/max': 48648192,
'memusage/startup': 48648192,
'response_received_count': 2,
'robotstxt/request_count': 1,
'robotstxt/response_count': 1,
'robotstxt/response_status_count/200': 1,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2020, 2, 16, 23, 14, 32, 569592)}
2020-02-16 23:14:48 [scrapy.core.engine] INFO: Spider closed (finished)
取得できない。。。
スクレイピングできない理由:推測
YahooJapanのトップページのセレクタをみる限り、クラスメイなど動的に生成されている。
つまり「必要な情報がページにアクセスしてから描画されているから、scrapyではそのままでは取得できない」のだと思う。
下記の記事を参考に、seleniumでHeadlessChromeを用いて取得できるか試していく。
JavaScriptによる描画に対応する
Scrapyとseleniumでダウンロード
pipでseleniumとchromedriverをインストール
下記記事を参考にした。
pipでSelenium&chrome driverのインストール
ただし今回はdocker環境下で、本番配布することを想定して、下記の手順でpip_requirements.txtに記載した。
①
pip install chromedriver-binary==79.0.3945.130(自分のChromeバージョンを確認して入力)
②
ERROR: Could not find a version that satisfies the requirement chromedriver-binary==79.0.3945.130 (from versions: 2.29.1, 2.31.1, 2.33.1, 2.34.0, 2.35.0, 2.35.1, 2.36.0, 2.37.0, 2.38.0, 2.39.0, 2.40.1, 2.41.0, 2.42.0, 2.43.0, 2.44.0, 2.45.0, 2.46.0, 70.0.3538.16.0, 70.0.3538.67.0, 70.0.3538.97.0, 71.0.3578.30.0, 71.0.3578.33.0, 71.0.3578.80.0, 71.0.3578.137.0, 72.0.3626.7.0, 72.0.3626.69.0, 73.0.3683.20.0, 73.0.3683.68.0, 74.0.3729.6.0, 75.0.3770.8.0, 75.0.3770.90.0, 75.0.3770.140.0, 76.0.3809.12.0, 76.0.3809.25.0, 76.0.3809.68.0, 76.0.3809.126.0, 77.0.3865.10.0, 77.0.3865.40.0, 78.0.3904.11.0, 78.0.3904.70.0, 78.0.3904.105.0, 79.0.3945.16.0, 79.0.3945.36.0, 80.0.3987.16.0, 80.0.3987.106.0, 81.0.4044.20.0)
ERROR: No matching distribution found for chromedriver-binary==79.0.3945.130
コンソール上で「そんなバージョンは無いよ。この中からバージョン選んでね」と言われる。、
③自分のバージョンより若い、かつ出来るだけ新しいバージョンを確認し、pip_requirements.txtに記載してインストールするようにする。
chromedriver-binary==79.0.3945.36.0
今日の一言
環境構築(docker設定)とアプリケーションコードをいったりきたりしてる。。
前述しているpipでseleniumとchromedriverをインストールしたけど、
selenium.common.exceptions.WebDriverException: Message: 'chromedriver' executable needs to be in PATH. Please see https://sites.google.com/a/chromium.org/chromedriver/home
って言われた、パス通してねと。
まぁ当たり前やけど、dockerコンテナ内でChromeインストールさせてパス通さなあかんよねと。
次から下記記事を参考に、dockerでheadlessChrome動かせるようにしていく!
Headless ChromeをDocker上で動かして、E2Eのテスト