はじめに
この記事ではpython で Web スクレイピングをする上で、scrapy という スクレイピングフレームワーク を使用します。
Scrapyのアーキテクチャ
フレームワークの概要について
データフロー
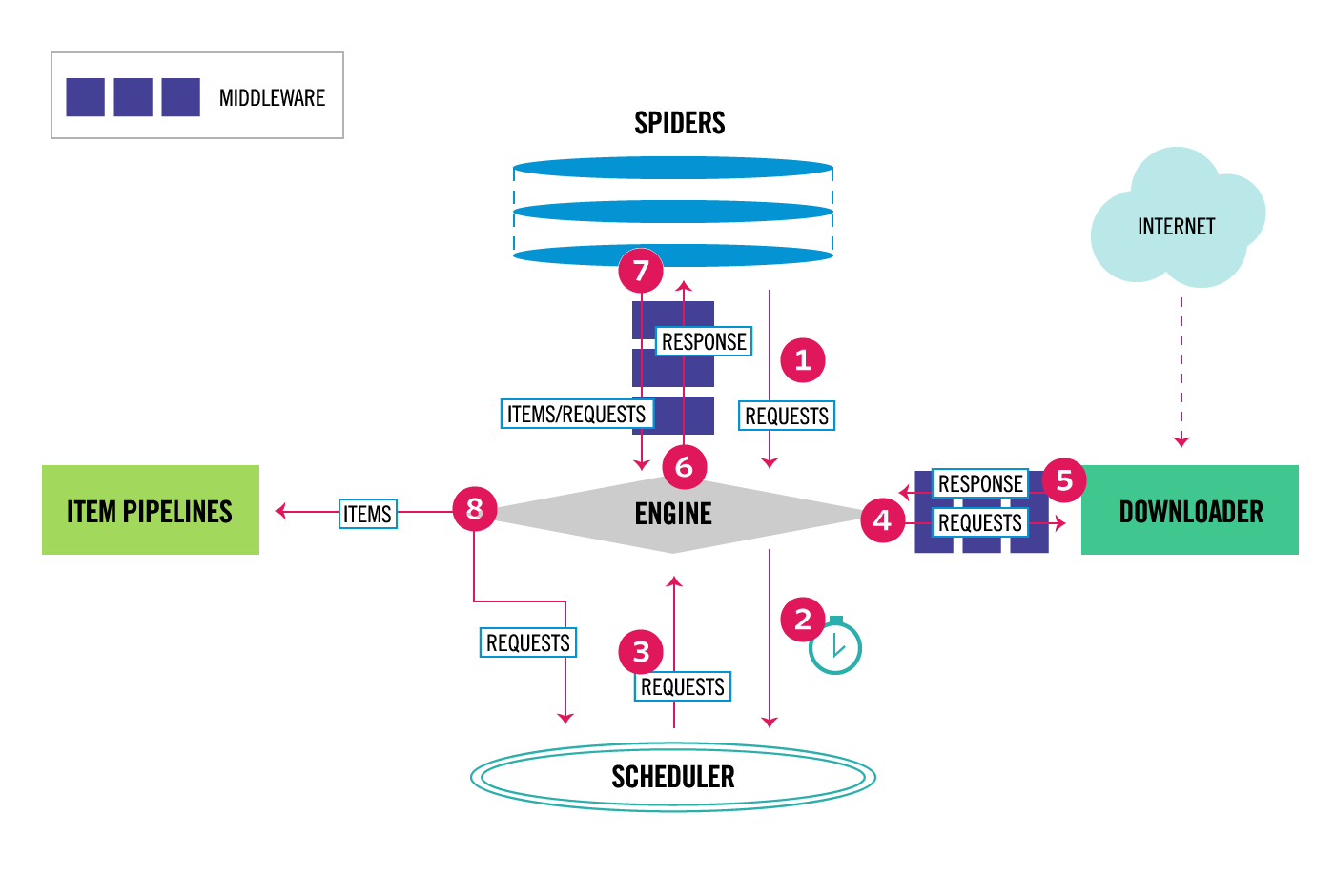
Components
Scrapy Engine
上部のデータフローの図のように各コンポーネントの制御を行います。
Scheduler
Scrapy Engineからの要求を受け取りキューに積み上げ、後のScrapy Engine からの要求から取り出せるようにします。
Downloader
Downloaderは、Webページを取得してScrapy Engineに供給し、Spiderに渡します。
Spiders
Spiders とは、Scrapyユーザーがレスポンスを解析し、Item(スクラップされたアイテム)またはそれに続く追加のリクエストを抽出するカスタムクラスです。
主にここを自分でカスタマイズします。
Item Pipeline
Item Pipeline は、Item がSpider によって抽出されると、Item の処理を行います。典型的なタスクには、クレンジング、検証、永続性(アイテムをデータベースに格納するなど)が含まれます。
json ファイルに書き出したりDBへ保存したりできます。
Downloader middlewares
Downloader middlewaresは、Scrapy EngineとDownloaderの間にあり、Scrapy EngineからDownloaderに渡されたリクエストと、DownloaderからScrapy Engineに渡されたレスポンスを処理する特定のフックです。
今回は特に使用しません。
Spider middlewares
Spider middlewaresは、Scrapy EngineとSpiderの間に位置し、Spiderの入力(応答)と出力(Itemと要求)を処理できる特定のフックです。
今回は特に使用しません。
Install Requirements
-
python-dev,zlib1g-dev,libxml2-devandlibxslt1-devare required forlxml -
libssl-devandlibffi-devare required forcryptography
お祭りスクレイピングAppの実装手順・イメージ
- Docker を使ってローカル開発環境の構築
- プロジェクトの作成
- スレイピングの実装
- 結果をjsonファイルで出力
スクレイピングにLet's, Enjoy Tokyoさんを対象とさせていただきました。
Dockerfile の作成
FROM python:3.6-alpine
RUN apk add --update --no-cache \
build-base \
python-dev \
zlib-dev \
libxml2-dev \
libxslt-dev \
openssl-dev \
libffi-dev
ADD pip_requirements.txt /tmp/pip_requirements.txt
RUN pip install -r /tmp/pip_requirements.txt
ADD ./app /usr/src/app
WORKDIR /usr/src/app
pip_requirements.txt は以下の感じ
# Production
# =============================================================================
scrapy==1.4.0
# Development
# =============================================================================
flake8==3.3.0
flake8-mypy==17.3.3
mypy==0.511
Docker イメージのビルド
docker build -t festival-crawler-app .
Docker コンテナの起動
# ワーキングディレクトリ直下で実行
docker run -itd -v $(pwd)/app:/usr/src/app \
--name festival-crawler-app \
festival-crawler-app
起動したコンテナに入ります
docker exec -it festival-crawler-app /bin/sh
プロジェクトの作成
# scrapy startproject <project_name> [project_dir]
scrapy startproject scraping .
作成されるディレクトリは以下のような感じになりました。
プロジェクト作成前
├── Dockerfile
├── app
└── pip_requirements.txt
プロジェクト作成後
.
├── Dockerfile
├── app
│ ├── scraping
│ │ ├── __init__.py
│ │ ├── items.py
│ │ ├── middlewares.py
│ │ ├── pipelines.py
│ │ ├── settings.py
│ │ └── spiders
│ │ └── __init__.py
│ └── scrapy.cfg
└── pip_requirements.txt
settings.py の設定
Downloaderが同じWebサイトから連続したページをダウンロードするまで待機する時間を設定できます。
この値は必ず設定し、スクレイピング対象のWebサイトに負荷をかけすぎないような値を設定してください。
対象のサイトの robots.txt を確認し、 Crawl-delay が指定してあればその値を指定するのが良さそう。
# DOWNLOAD_DELAY = 10 # sec
app/scraping/items.py の実装
# -*- coding: utf-8 -*-
import scrapy
from scrapy.loader.processors import (
Identity,
MapCompose,
TakeFirst,
)
from w3lib.html import (
remove_tags,
strip_html5_whitespace,
)
class FestivalItem(scrapy.Item):
name = scrapy.Field(
input_processor=MapCompose(remove_tags),
output_processor=TakeFirst(),
)
term_text = scrapy.Field(
input_processor=MapCompose(remove_tags, strip_html5_whitespace),
output_processor=TakeFirst(),
)
stations = scrapy.Field(
input_processor=MapCompose(remove_tags),
output_processor=Identity(),
)
Itemクラスではスクレイピングで取り扱うデータを定義します。
今回は以下のデータを定義します。
- お祭りの名前
- 開催期間
- 最寄り駅
input_processor, output_processor はそれぞれデータの受け入れ、出力時にデータの加工ができるのでとても便利です。
app/scraping/spider/festival.py ファイルの実装
# -*- coding: utf-8 -*-
from typing import Generator
import scrapy
from scrapy.http import Request
from scrapy.http.response.html import HtmlResponse
from scraping.itemloaders import FestivalItemLoader
class FestivalSpider(scrapy.Spider):
name: str = 'festival:august'
def start_requests(self) -> Generator[Request, None, None]:
url: str = (
'http://www.enjoytokyo.jp'
'/amuse/event/list/cate-94/august/'
)
yield Request(url=url, callback=self.parse)
def parse(
self,
response: HtmlResponse,
) -> Generator[Request, None, None]:
for li in response.css('#result_list01 > li'):
loader = FestivalItemLoader(
response=response,
selector=li,
)
loader.set_load_items()
yield loader.load_item()
ここの実装が実際のスクレイピングの記述です。
クラス変数 name: str = 'festival:august' はコマンドラインから実行するコマンド名です。上記を記述することで scrapy crawl festival:august でスクレイピングを実行することが出来ます。
app/scraping/itemloaders.py の実装
# -*- coding: utf-8 -*-
import scrapy
from scrapy.loader import ItemLoader
from scraping.items import FestivalItem
class FestivalItemLoader(ItemLoader):
default_item_class = FestivalItem
def set_load_items(self) -> None:
s: str = '.rl_header .summary'
self.add_css('name', s)
s = '.rl_main .dtstart::text'
self.add_css('term_text', s)
s = '.rl_main .rl_shop .rl_shop_access'
self.add_css('stations', s)
上記は正しい使用方法ではないかもしれませんが、css セレクタをfestival.pyに列挙するのがごちゃごちゃすると思ったので、ItemLoader で定義をしました。set_load_items メソッドは ItemLoader クラスに存在しない今回追加したメソッドです。
スクレイピングコマンド
output の指定は -o オプションで指定できます。
DBなどへ保存する場合は別途、実装が必要です。
scrapy crawl festival:august -o result.json
これで8月のお祭り情報が取得できました
[
{
"name": "ECO EDO 日本橋 アートアクアリウム 2017 ~江戸・金魚の涼~ & ナイトアクアリウム",
"stations": [
"新日本橋駅"
],
"term_text": "2017/07/07(金)"
},
{
"name": "天の川イルミネーション~青炎キャンぺーン~",
"stations": [
"赤羽橋駅(徒歩5分)"
],
"term_text": "2017/06/01(木)"
},
{
"name": "花火アクアリウム by NAKED",
"stations": [
"品川駅"
],
"term_text": "2017/07/08(土)"
}
...
]
本来ならページングや、日時データのパースなど、ちゃんと作る必要がありますが、ひとまずふんわりとお祭りスクレイピングができました。
以下にお祭りスクレイピングのソースがあるので参考にしてください。
以上です。