概要
AWS資格取得に向けて実際にAWSを利用してみるシリーズの投稿です。
今回はAWSサービスの中でAIサービスに分類されるサービスを使ってみる編です。
具体的には以下の6つのAIサービスをAWS Lambdaを使って実際に動かしてみます。
AWSアカウントがあればすべてAWS上で完結されることができるため、お試し簡単な実践編です(^^)
- Amazon Rekognition:画像ファイルをインプットにモノ・人・顔を抽出する
- Amazon Polly:テキストファイルをインプットに音声ファイルを生成する
- Amazon Transcribe:音声ファイルをインプットにテキストファイルを生成する
- Amazon Comprehend:テキストファイルをインプットにインサイトや関係性を検出する自然言語処理 (NLP) サービス
- Amazon Translate:テキストファイルをインプットに翻訳する
- Amazon Textract:画像ファイルをインプットにテキストを抽出する
資格勉強的にはAWSのAIサービスのサービス概要を掴める内容になっています。
興味がある方は読んでみて下さい。
資格試験の勉強法は記事は以下を参照。
AWS初心者がAWS 認定ソリューションアーキテクト – アソシエイト資格試験に合格した時の勉強法
AWS初心者がAWS 認定ソリューションアーキテクト – プロフェッショナル資格試験に合格した時の勉強法
想定読者
- AWSでAIサービスを使ってみたい
- AWSでAIサービスにどんなものがあるのか知りたい
参考書籍
使ってわかったAWSのAI ~まるごと試せば視界は良好 さあPythonではじめよう


Lambdaに使用するソースコードなど多くを参考にさせて頂きました。
解説も丁寧で読みやすく、今回の投稿で記載していない Amazon Lex、Amazon Forecast、Amazon Personalize、Amazon SageMaker も扱っているので興味のある方はぜひ読んでみることをオススメします(^^)
AWS AI/ML スタック全体像
AWSとしては、以下のようにAIサービスとMLサービス、MLフレームワーク/インフラストラクチャと3層構造でAI/ML関連サービスを分類しているようです。
その中で今回はAIサービスの中で基礎的?な6つのサービスを試してみます。
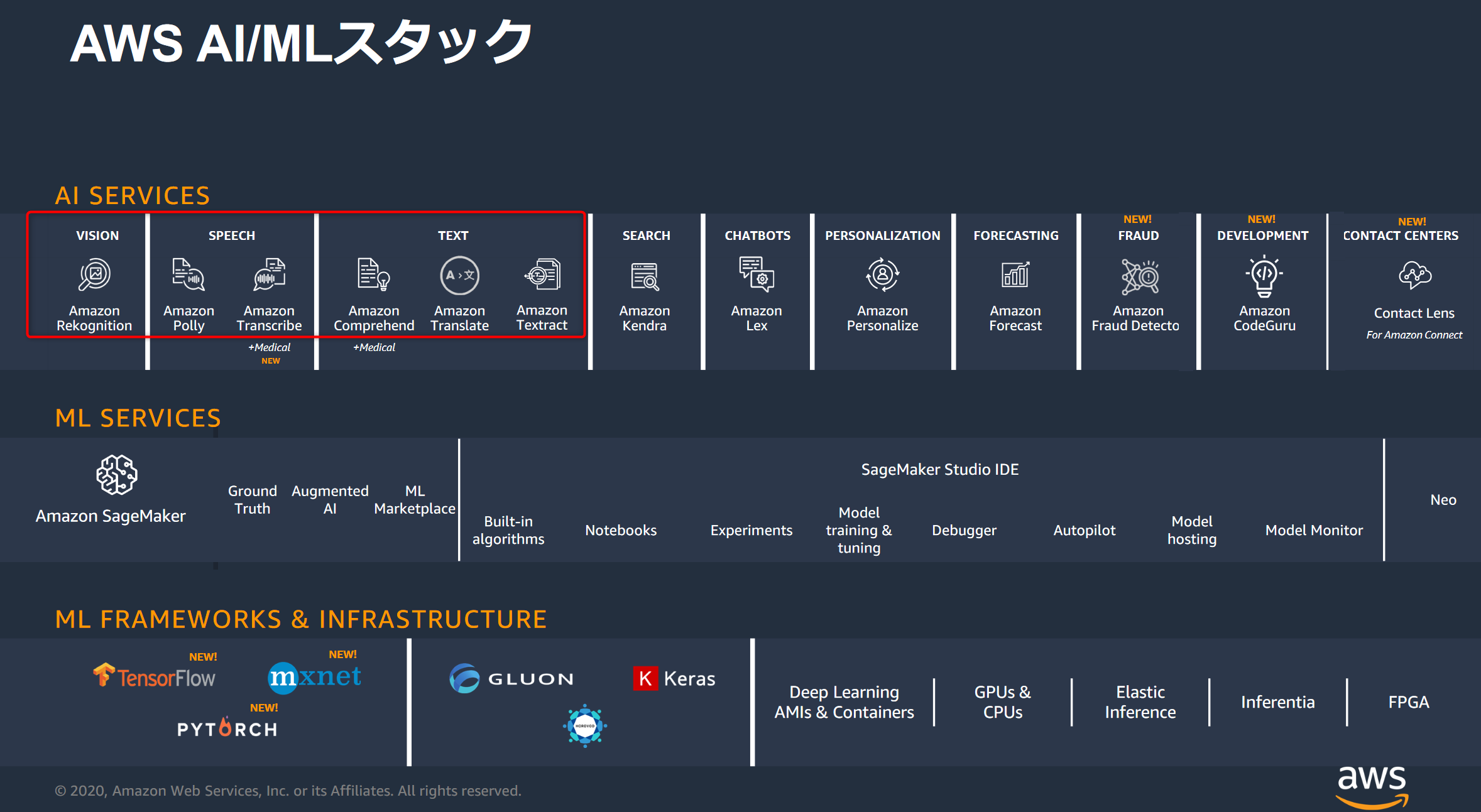
この図は、以下のブラックベルト資料から流用させて頂いています。
ちなみに以下の公式ページでもMachine-Learning として、AIサービスとMLサービス、フレームワーク、インフラストラクチャと分類されているので最新のサービスを確認したい場合は、この公式ページが良さそうです。
作業時間
- 1時間
- 事前準備1:10分
- 事前準備2:10分
- 事前準備3:5分
- Amazon Rekognition を使ってみる:5分
- Amazon Polly を使ってみる:5分
- Amazon Transcribe を使ってみる:10分
- Amazon Comprehend を使ってみる:5分
- Amazon Translate を使ってみる:5分
- Amazon Textract を使ってみる:5分
事前準備
各サービスを試す前に事前準備として以下の3点が必要になります。
1.Lambda関数の実行ロールの作成
2.ファイル格納用S3の準備
3.Lambda関数の作成
それぞれについて説明します。
1.Lambda関数の実行ロールの作成
今回の各AIサービスへの使用権限、およびいくつかのAIサービスのインプット/アウトプットファイルにS3を使用することがあるためS3へのアクセス、またLambda関数ログ出力用にCloudWatchのアクセス権限を与えます。お試しのためすべてFullAccess権限を与えていますが、実運用では適切な権限管理を行いましょう(^^;)
IAMロールの詳しい作成手順は省略しますが、完成形は以下になります。
今回はAIという名前のロールを作成しています。
↓アクセス権限に各サービスのFullAccess権限が与えられている
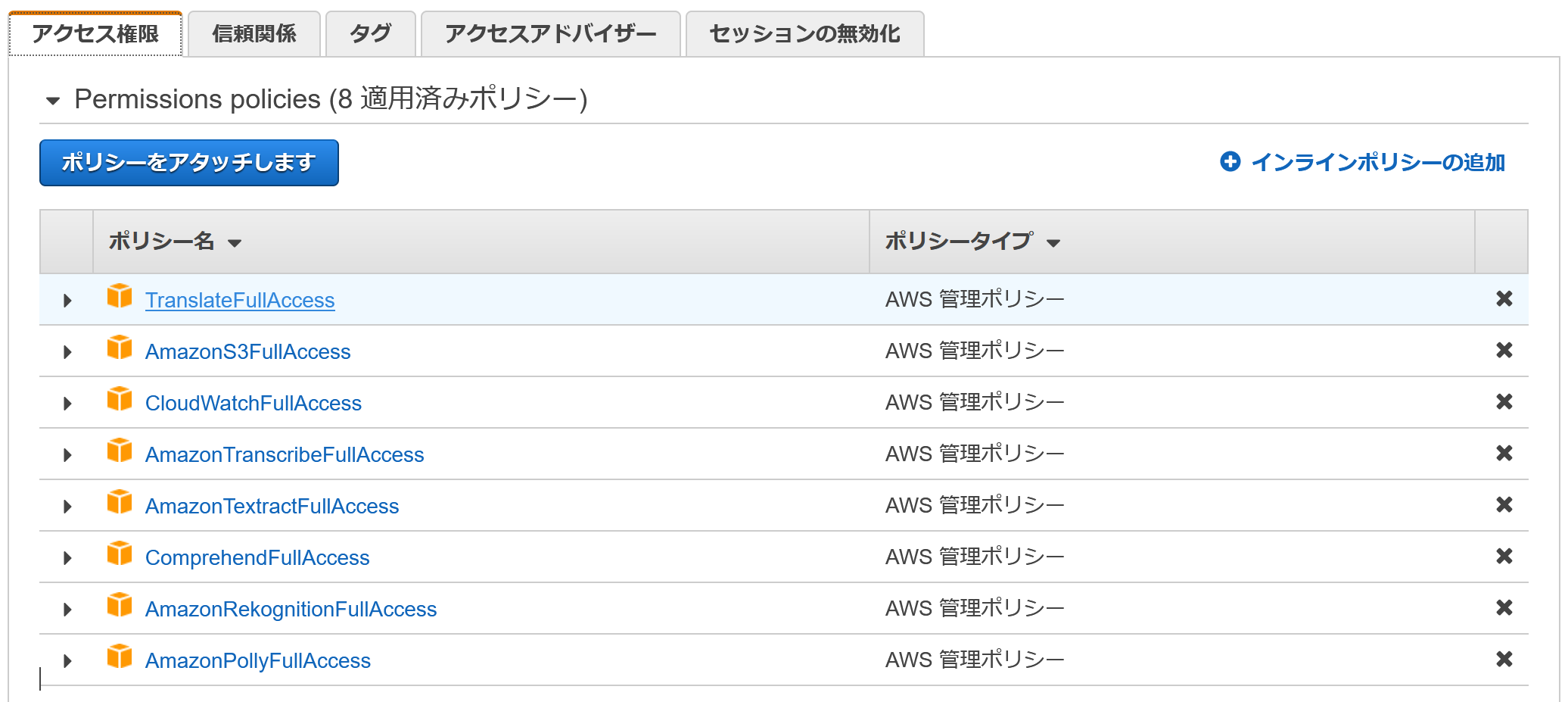
↓信頼関係にLambdaが設定されている

2.ファイル格納用S3の準備
S3の[バケットを作成]ボタンから新規バケットを作成します。
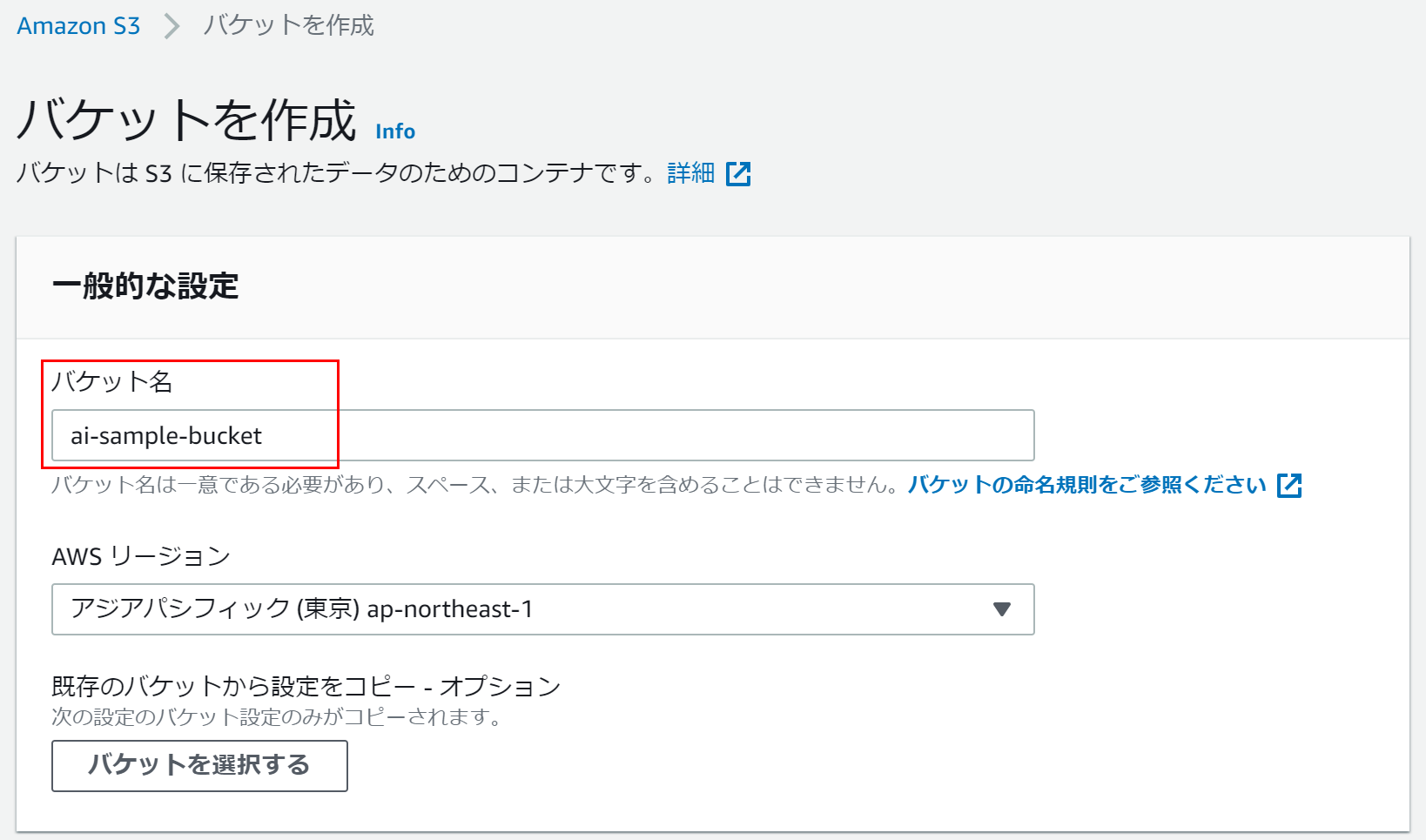
バケット名だけ他のバケットと被らない任意の名前で入力します。後はデフォルトでOKです。
以降で説明するLambda関数はai-sample-bucketというバケットを利用しています。
作成したバケットにAIサービスで利用するファイルを事前配置します↓

- voice.mp3:Amazon Transcribeで利用します。音声抽出のため聞き取りやすい音声が保存されているファイルが良いと思います。
- dog.jpg:Amazon Rekognitionで利用します。今回は犬の画像にしました。
- family.jpg:Amazon Rekognitionで利用します。顔認識でするため今回は複数の人物が写っている画像にしました。
- text.jpg:Amazon Textractで利用します。ファイル内容から文字列を抽出するため画像内に文字があるファイルを準備します。
3.Lambda関数の作成
Lambdaの[関数の作成]ボタンからLambda関数を作成します。
設定内容は↓になります。
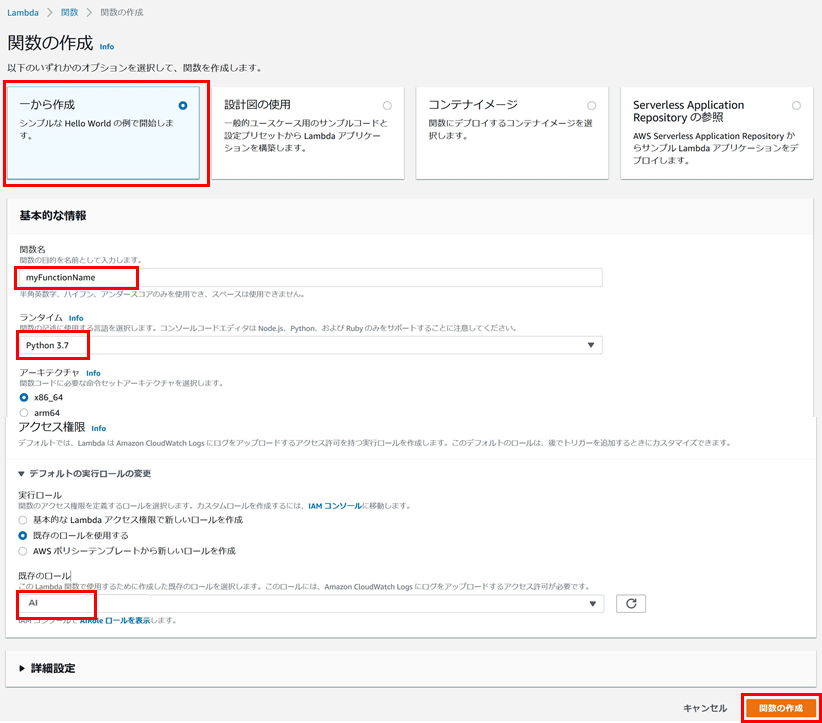
シンプルなLambda関数のため、一から作成で作成しますが、関数名、ランタイム、既存のロールを設定する必要があります。
- 関数名:任意の名前で大丈夫です。
- ランタイム:Python 3.7を選択します。
- 事前手順の1で作成したロール(今回はAIというロール)を設定します。
以上を入力したら画面下部の関数の作成をクリックします。
事前準備のLambda関数作成手順はここまでです。
後の手順で各AIサービスごとLambda関数を用意するので、この手順で各AIサービスごとLambda関数を作成することを覚えておいてください。
以上で事前準備は完了です。では、いろいろなAIサービスを動かしていきましょう!
Amazon Rekognition を使ってみる
ここからは実際にサービスを使ってみます。
Lambda関数に使用するサンプルソースが違うだけで基本的には同じ手順で試すことができます。
最初はAmazon Rekognitionです。Rekognition は、画像ファイルをインプットにモノ・人・顔を抽出するサービスになります。その中で、今回はモノの判定と顔の判定を試してみます。
事前手順の通り、Lambda関数を作成するとコードソースのエディタが開かれるので、以下のソースをコピーしてLambda関数に貼り付けます。
import json
import boto3
client = boto3.client('rekognition', region_name='ap-northeast-1')
s3 = boto3.resource('s3')
# バケット名,オブジェクト名
BUCKET_NAME = 'ai-sample-bucket'
OBJECT_KEY_NAME_dog = 'dog.jpg'
OBJECT_KEY_NAME_family = 'family.jpg'
def lambda_handler(event, context):
bucket = s3.Bucket(BUCKET_NAME)
# モノ認識
print('=============================')
print(' モノ認識')
print('=============================')
obj = bucket.Object(OBJECT_KEY_NAME_dog)
response = obj.get()
body = response['Body'].read()
response = client.detect_labels(Image={'Bytes': body})
print(json.dumps(response, indent=2))
# 顔認識
print('=============================')
print(' 顔認識')
print('=============================')
obj = bucket.Object(OBJECT_KEY_NAME_family)
response = obj.get()
body = response['Body'].read()
response = client.detect_faces(Image={'Bytes': body}, Attributes=['ALL'])
print(json.dumps(response, indent=2))
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}
BUCKET_NAME(S3のファイル名を変えた場合はOBJECT_KEY_NAME_dog、OBJECT_KEY_NAME_family)は、適宜変えてください。
準備ができたらDeployして、Testしてみましょう。(Testは初回のみテストイベントの作成が必要なので任意の名前でテストイベントを作成します)

以下のような結果が表示されたら成功です。
Function Logs
gh": 50
},
"Smile": {
"Value": true,
"Confidence": 91.94837951660156
},
"Eyeglasses": {
"Value": false,
"Confidence": 98.53036499023438
},
Function Logs部分が実際の実行結果になります。
Lambdaの Function Logs で全量が確認できない場合はCloudWatchで確認します。
CloudWatchのLambda関数名のロググループを開くと以下のような内容が確認できると思います。
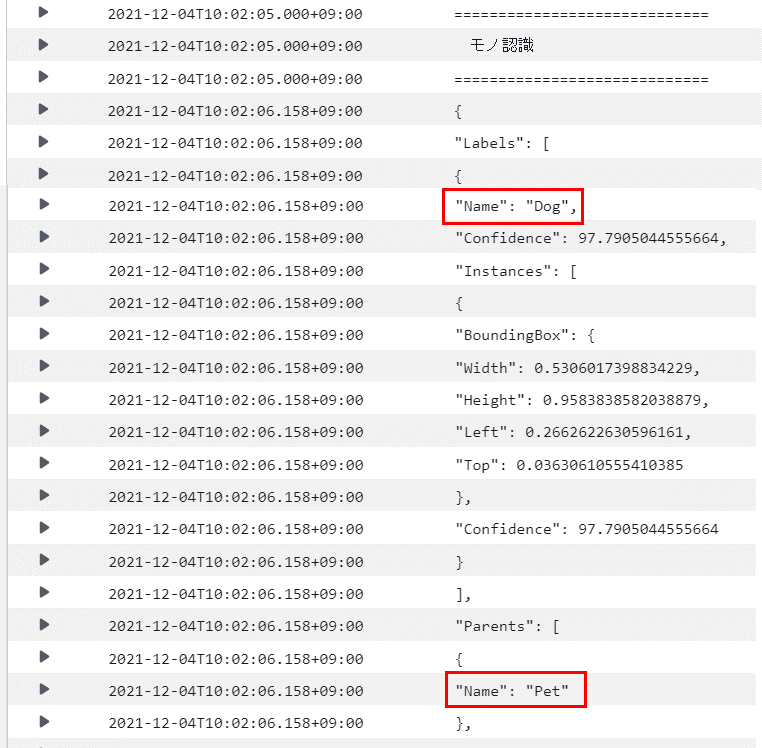
これはモノの認識結果になります。画像ファイルからDog、Petであることが認識できていることが確認できます。
内容の詳細は以下の公式ドキュメントを見てください(^^;)
モノの認識はdetect_labelsというメソッドで実行しています。
もう一つは顔の認識結果です。推定年齢、性別等を判定してくれるみたいですね。
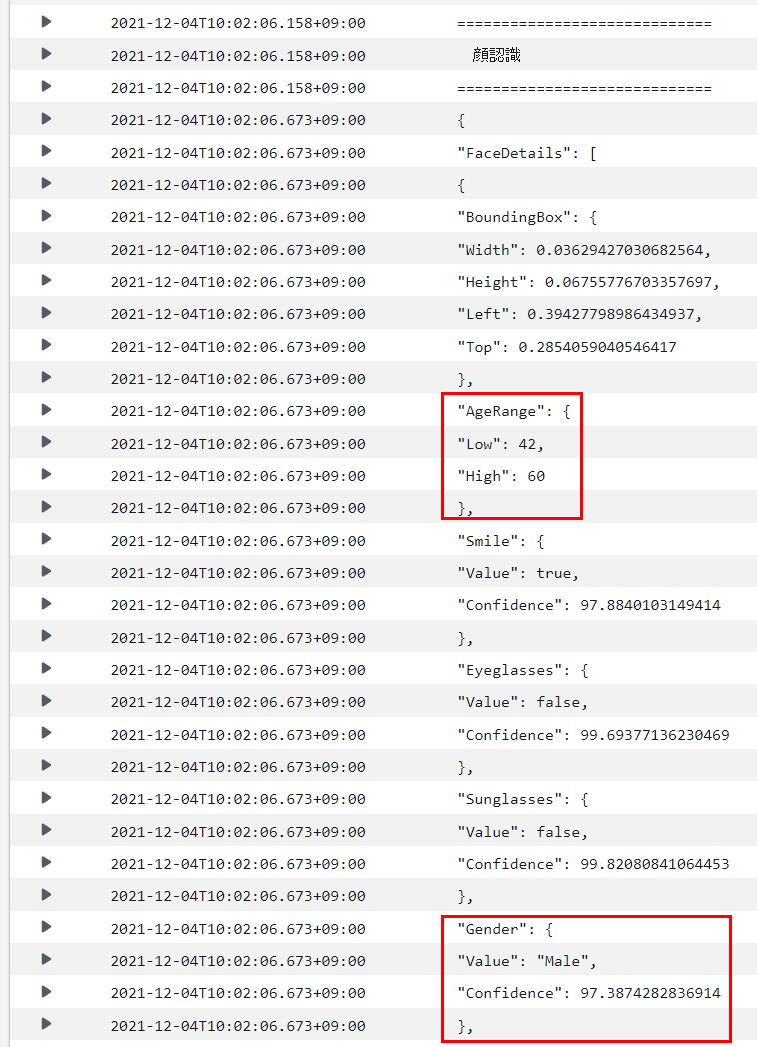
こちらの公式ドキュメントは以下です。
顔の認識はdetect_facesというメソッドで実行しています。
以上で Amazon Rekognition は終了です。かなり簡単だったのではないでしょうか。
今回試してみるサービスはまだまだあるのでサクサクいきます(^^)
Amazon Polly を使ってみる
次は、Amazon Polly です。Polly は、テキストファイルをインプットに音声ファイルを生成するサービスになります。
使用するAIサービスが変わりますが手順は同じです。Lambda関数を作成しコードソースにコピー、Deployして、Testします。
import boto3
import json
client = boto3.client('polly', region_name='ap-northeast-1')
# バケット名
BUCKET_NAME = 'ai-sample-bucket'
def lambda_handler(event, context):
text = 'こんにちは。私はAmazon Pollyのミズキです。'
response = client.start_speech_synthesis_task(
OutputFormat='mp3',
OutputS3BucketName=BUCKET_NAME,
Text=text,
VoiceId='Mizuki'
)
print(response)
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}
BUCKET_NAMEは、適宜変えてください。
以下のような結果が表示されたら成功です。
Function Logs
START RequestId: 2ad58391-ddba-4a75-aaa2-cc5cc9838c7c Version: $LATEST
{'ResponseMetadata': {'RequestId': 'a38625d7-a2ea-4918-ae84-49a2bb198e0f', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amzn-requestid': 'a38625d7-a2ea-4918-ae84-49a2bb198e0f', 'content-type': 'application/json', 'content-length': '455', 'date': 'Sun, 05 Dec 2021 00:17:20 GMT'}, 'RetryAttempts': 0}, 'SynthesisTask': {'TaskId': 'aa795e63-a638-4f44-8b89-acc5dd28d13e', 'TaskStatus': 'scheduled', 'OutputUri': 'https://s3.ap-northeast-1.amazonaws.com/ai-sample-bucket/d9eb766c-501f-4831-8a7d-22da2ce08ec2.mp3', 'CreationTime': datetime.datetime(2021, 12, 5, 0, 17, 20, 731000, tzinfo=tzlocal()), 'RequestCharacters': 27, 'OutputFormat': 'mp3', 'TextType': 'text', 'VoiceId': 'Mizuki'}}
END RequestId: 2ad58391-ddba-4a75-aaa2-cc5cc9838c7c
実際の音声ファイルはS3バケットに保存されています。うまく音声が聞けれるか聞いてみてください(^^)

Polly の公式ドキュメントは以下です。
音声ファイルの生成はstart_speech_synthesis_taskというメソッドで実行しています。
Amazon Transcribe を使ってみる
次は Amazon Transcribe です。Transcribe は、Polly とは逆に音声ファイルをインプットにテキストファイルを生成するサービスになります。
手順は同じです。Lambda関数を作成しコードソースにコピー、Deployして、Testします。
ただ Transcribe は今回使用するサービスの中で唯一非同期処理になっています。
他のサービスは実行と同時に結果が確認できるのですが、Transcribe は結果が出るまでに時間がかかることがあります。そのため、状況確認用の処理もあるのでそれも紹介します。
まず、音声ファイルをインプットにテキストファイルを生成する処理は以下の通りです。
import boto3
import json
client = boto3.client('transcribe', region_name='ap-northeast-1')
# 音声ファイル名
FILE_NAME = 'https://ai-sample-bucket.s3.ap-northeast-1.amazonaws.com/voice.mp3'
# ジョブ名(アカウント内で一意にすること)
JOB_NAME = 'TranscribeJob20211205v1'
# 出力バケット名
BUCKET_NAME = 'ai-sample-bucket'
def lambda_handler(event, context):
response = client.start_transcription_job(
TranscriptionJobName=JOB_NAME,
LanguageCode='ja-JP',
MediaFormat='mp3',
Media={
'MediaFileUri': FILE_NAME
},
OutputBucketName=BUCKET_NAME
)
print(response)
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}
FILE_NAME、BUCKET_NAMEは、適宜変えてください。
またJOB_NAMEはアカウント内で一意にする必要があるため、繰り返し実行する場合は変更する必要があります。
以下のような結果が表示されたら成功です。
Function Logs
START RequestId: a8ce1ba2-a370-43de-bb1c-54a8b0503648 Version: $LATEST
{'TranscriptionJob': {'TranscriptionJobName': 'TranscribeJob20211205v1', 'TranscriptionJobStatus': 'IN_PROGRESS', 'LanguageCode': 'ja-JP', 'MediaFormat': 'mp3', 'Media': {'MediaFileUri': 'https://ai-sample-bucket.s3.ap-northeast-1.amazonaws.com/voice.mp3'}, 'StartTime': datetime.datetime(2021, 12, 5, 0, 29, 15, 17000, tzinfo=tzlocal()), 'CreationTime': datetime.datetime(2021, 12, 5, 0, 29, 14, 964000, tzinfo=tzlocal())}, 'ResponseMetadata': {'RequestId': 'a2d9b664-ad29-498e-b94d-8bc937ce9803', 'HTTPStatusCode': 200, 'HTTPHeaders': {'content-type': 'application/x-amz-json-1.1', 'date': 'Sun, 05 Dec 2021 00:29:14 GMT', 'x-amzn-requestid': 'a2d9b664-ad29-498e-b94d-8bc937ce9803', 'content-length': '308', 'connection': 'keep-alive'}, 'RetryAttempts': 0}}
END RequestId: a8ce1ba2-d370-a3de-bb1c-54a8b0503648
次は、処理状況を確認するためのソースコードです。
import boto3
import json
client = boto3.client('transcribe', region_name='ap-northeast-1')
# ジョブ名
JOB_NAME = 'TranscribeJob20211205v1'
def lambda_handler(event, context):
# ジョブステータス確認
response = client.get_transcription_job(
TranscriptionJobName=JOB_NAME
)
# 結果表示
print(response)
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}
JOB_NAMEにテキストファイルを生成する処理で指定したジョブ名を指定することで状況確認ができるようになっています。
以下のような結果が表示されたら成功です。
START RequestId: a4f2da07-a7f7-4849-9178-faa39d0fb17d Version: $LATEST
{'TranscriptionJob': {'TranscriptionJobName': 'TranscribeJob20211205v1', 'TranscriptionJobStatus': 'COMPLETED', 'LanguageCode': 'ja-JP', 'MediaSampleRateHertz': 22050, 'MediaFormat': 'mp3', 'Media': {'MediaFileUri': 'https://ai-sample-bucket.s3.ap-northeast-1.amazonaws.com/voice.mp3'}, 'Transcript': {'TranscriptFileUri': 'https://s3.ap-northeast-1.amazonaws.com/ai-sample-bucket/TranscribeJob20211205v1.json'}, 'StartTime': datetime.datetime(2021, 12, 5, 0, 29, 15, 17000, tzinfo=tzlocal()), 'CreationTime': datetime.datetime(2021, 12, 5, 0, 29, 14, 964000, tzinfo=tzlocal()), 'CompletionTime': datetime.datetime(2021, 12, 5, 0, 29, 37, 631000, tzinfo=tzlocal()), 'Settings': {'ChannelIdentification': False, 'ShowAlternatives': False}}, 'ResponseMetadata': {'RequestId': 'a4c35e48-a992-49f0-a9a5-2046187f0ada', 'HTTPStatusCode': 200, 'HTTPHeaders': {'content-type': 'application/x-amz-json-1.1', 'date': 'Sun, 05 Dec 2021 00:39:51 GMT', 'x-amzn-requestid': 'a4c35e48-a992-49f0-a9a5-2046187f0ada', 'content-length': '560', 'connection': 'keep-alive'}, 'RetryAttempts': 0}}
END RequestId: a4f2da07-a7f7-4849-9178-faa39d0fb17d
**'TranscriptionJobStatus': 'COMPLETED'**が処理が完了していることを示しています。
この状態となったら、実際のテキストファイルはS3バケットに {ジョブ名}.json とjsonファイル形式で保存されているので、正しくテキスト化できているか確認してみてください。

(処理の中間ファイルとして「write_access_check_file.temp」というファイルは自動作成されて残るようです^^;)
Transcribe はひと手間ありましたが説明は以上です。
Transcribe の公式ドキュメントは以下になります。
テキストファイルの生成はstart_transcription_job、状況確認はget_transcription_jobというメソッドで実行しています。
Amazon Comprehend を使ってみる
次は、Amazon Comprehend です。Comprehend は、テキストファイルをインプットにインサイトや関係性を検出する自然言語処理 (NLP) サービスになります。
ちょっとどんなサービスか???ですね(^^;)
実際やってみるとなんとなくあぁそういうことかとわかるので早速やってみましょう。
今回は言語の識別とエンティティ抽出を試してみます。
手順は同じです。Lambda関数を作成しコードソースにコピー、Deployして、Testします。
import json
import boto3
client = boto3.client('comprehend', region_name='ap-northeast-1')
def lambda_handler(event, context):
# 自然言語識別
print('=============================')
print(' 自然言語識別')
print('=============================')
text = 'おはようございます。今日の天気は晴れです。'
response = client.detect_dominant_language(Text=text)
print(json.dumps(response, indent=2))
# エンティティ抽出
print('=============================')
print(' エンティティ抽出')
print('=============================')
text = 'Amazon Comprehend は、機械学習を使用してテキスト内でインサイトや関係性を検出する自然言語処理 (NLP) サービスです。機械学習の経験は必要ありません。構造化されていないデータには膨大な量の潜在的な宝物があります。お客様の E メール、サポートチケット、製品レビュー、ソーシャルメディア、広告コピーが、ビジネスの役に立つ顧客感情のインサイトを表します。問題はそれをどのようにして手に入れるかです。 このように、機械学習は、膨大な数のテキスト内の特定の関心項目 (アナリストレポートで会社名を見つけるなど) を正確に特定することに特に優れており、言語の中に隠された感情 (マイナスのレビューやカスタマーサービスエージェントと顧客の積極的なのやりとりの特定) をほぼ無限の規模で学習することができます。'
response = client.detect_entities(Text=text, LanguageCode='ja')
print(json.dumps(response, indent=2, ensure_ascii=False))
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}
以下のような結果が表示されたら成功です。
Function Logs
START RequestId: ab5def28-a536-494d-babb-1d861bf8e50d Version: $LATEST
=============================
自然言語識別
=============================
{
"Languages": [
{
"LanguageCode": "ja",
"Score": 1.0
}
],
"ResponseMetadata": {
"RequestId": "acbd0b25-a568-4d99-9f71-420658d33b48",
"HTTPStatusCode": 200,
"HTTPHeaders": {
"x-amzn-requestid": "acbd0b25-a568-4d99-9f71-420658d33b48",
"content-type": "application/x-amz-json-1.1",
"content-length": "49",
"date": "Sun, 05 Dec 2021 00:56:41 GMT"
},
"RetryAttempts": 0
}
}
=============================
エンティティ抽出
=============================
{
"Entities": [
{
"Score": 0.8411812782287598,
"Type": "ORGANIZATION",
"Text": "Amazon",
"BeginOffset": 0,
"EndOffset": 6
},
{
"Score": 1.0,
"Type": "COMMERCIAL_ITEM",
"Text": "Comprehend",
"BeginOffset": 7,
"EndOffset": 17
},
{
"Score": 0.512094259262085,
"Type": "OTHER",
"Text": "自然言語",
"BeginOffset": 49,
"EndOffset": 53
},
{
言語の識別は簡単です。"LanguageCode": "ja"部分が入力テキストが日本語であったことを示しています。
エンティティ抽出の方は、Text部分の入力テキストの単語が設定されていることがわかります。また、Typeに単語が何かを示していることがわかります。例えば、Amazonは組織と判定され、Comprehendはブランド商品と判定されたようです。(これをエンティティと呼んでいるようです)
エンティティの説明は以下が公式ページのようです。
なんとなく Comprehend のサービス内容がわかったのではないでしょうか?
実は Comprehend は試した内容がごく一部なのでまだまだ面白い機能がありそうです(^^)
最後に公式ドキュメントは以下です。
言語の識別はdetect_dominant_language、エンティティ抽出はdetect_entitiesというメソッドで実行しています。
Amazon Translate を使ってみる
次は、Amazon Translate です。Translate は、テキストファイルをインプットに翻訳するサービスになります。
手順は同じです。Lambda関数を作成しコードソースにコピー、Deployして、Testします。
import json
import boto3
client = boto3.client('translate', region_name='ap-northeast-1')
def lambda_handler(event, context):
print('=============================')
print(' テキスト翻訳')
print('=============================')
text = 'Amazon Translate is a text translation service that uses advanced machine learning technologies to provide high-quality translation on demand. You can use Amazon Translate to translate unstructured text documents or to build applications that work in multiple languages.'
response = client.translate_text(
Text=text,
SourceLanguageCode='en',
TargetLanguageCode='ja'
)
print(json.dumps(response, ensure_ascii=False, indent=2))
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}
以下のような結果が表示されたら成功です。
Function Logs
START RequestId: aaa8c087-aa47-489f-b9db-726f302d6918 Version: $LATEST
=============================
テキスト翻訳
=============================
{
"TranslatedText": "Amazon Translate は、高度な機械学習テクノロジーを使用して、オンデマンドで高品質の翻訳を提供するテキスト翻訳サービスです。Amazon Translate を使用すると、非構造化テキストドキュメントを翻訳したり、複数の言語で動作するアプリケーションを構築したりできます。",
"SourceLanguageCode": "en",
"TargetLanguageCode": "ja",
"ResponseMetadata": {
"RequestId": "a6ea33ee-aef0-4f7b-a6a7-f2aa0cfd7d7f",
"HTTPStatusCode": 200,
"HTTPHeaders": {
"x-amzn-requestid": "a6ea33ee-aef0-4f7b-a6a7-f2aa0cfd7d7f",
"cache-control": "no-cache",
"content-type": "application/x-amz-json-1.1",
"content-length": "434",
"date": "Sun, 05 Dec 2021 01:28:48 GMT"
},
"RetryAttempts": 0
}
}
END RequestId: aaa8c087-aa47-489f-b9db-726f302d6918
今回試したサービスで一番シンプルだったかもしれないですね。TranslatedTextに翻訳結果が確認できると思います。
Translate の公式ドキュメントは以下です。
翻訳はtranslate_textというメソッドで実行しています。
Amazon Textract を使ってみる
いよいよ最後です。最後は Amazon Textract です。Textract は、画像ファイルをインプットにテキストを抽出するサービスになります。
手順は同じです。Lambda関数を作成しコードソースにコピー、Deployして、Testします。
このサービスは少し注意事項があります。
まず東京リージョンはまだ対応していないようです。そのため、サンプルソースはus-east-1を指定しています。
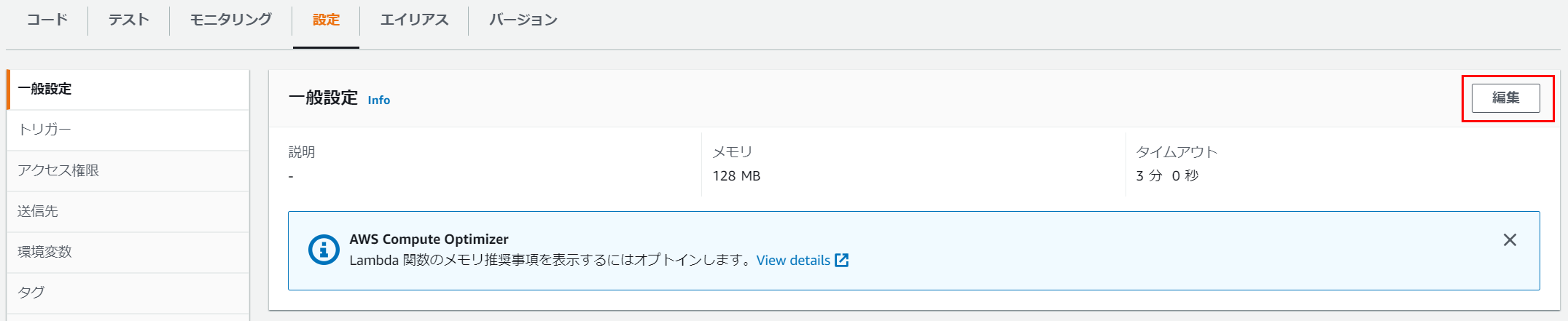
また今回試したサービスの中で、このサービスだけLambda関数のデフォルトタイムアウト3秒で処理が終わらなかったため、タイムアウト時間の変更をしています。(もちろんインプット情報量に依存するので他サービスでもタイムアウトするかもしれないし、Textract でも3秒で終わるかもしれないです)
参考までにLambdaのタイムアウト時間変更は以下から可能です。
Lambda関数の「設定」>「一般設定」>「編集」
それではソースコードの内容に移ります。
import json
import boto3
client = boto3.client('textract', region_name='us-east-1')
s3 = boto3.resource('s3')
# バケット名,オブジェクト名
BUCKET_NAME = 'ai-sample-bucket'
OBJECT_KEY_NAME_text = 'text.jpg'
def lambda_handler(event, context):
print('=============================')
print(' テキスト抽出')
print('=============================')
bucket = s3.Bucket(BUCKET_NAME)
obj = bucket.Object(OBJECT_KEY_NAME_text)
response = obj.get()
body = response['Body'].read()
response = client.analyze_document(
Document={'Bytes': body},
FeatureTypes=['FORMS']
)
print(json.dumps(response, indent=2))
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}
BUCKET_NAME(S3のファイル名を変えた場合はOBJECT_KEY_NAME_text)は、適宜変えてください。
以下のような結果が表示されたら成功です。
Function Logs
68484,
"Left": 0.17423224449157715,
"Top": 0.9334113001823425
},
"Polygon": [
~(省略)~
]
},
"Id": "ad4f2c52-ad54-45d0-aa8f-4e7310fa967c"
},
{
"BlockType": "WORD",
"Confidence": 99.96102142333984,
"Text": "use",
"TextType": "PRINTED",
"Geometry": {
"BoundingBox": {
"Width": 0.028960878029465675,
"Height": 0.027387404814362526,
"Left": 0.2535151541233063,
"Top": 0.9335477948188782
},
"Polygon": [
~(省略)~
]
},
"Id": "a1571d05-a272-4522-90e3-a7066941f181"
},
{
"BlockType": "WORD",
"Confidence": 99.79456329345703,
"Text": "cases",
"TextType": "PRINTED",
"Geometry": {
"BoundingBox": {
"Width": 0.044430650770664215,
"Height": 0.027736730873584747,
"Left": 0.2874112129211426,
"Top": 0.9332870841026306
},
"Polygon": [
~(省略)~
]
},
"Id": "a5a2cd44-adbb-4264-972f-16fde33dbf68"
},
Text部分に画像ファイルから抽出したテキスト内容が設定されます。
こちらの公式ドキュメントは以下です。
テキスト抽出はanalyze_documentというメソッドで実行しています。
まとめ
お疲れ様でした!
以上でAWSサービスのAIサービスを試してみる編は完了です。
予想よりずっと簡単にAIサービスを試すことができたのではないでしょうか?
今回紹介した機能はほんの一部なので興味を持ったサービスがあればいろいろ使ってみると楽しいと思います。
また今回はアウトプットに対する確認を一切この投稿の中では載せていないのでAWSのAIサービスの精度については実際に試してみて確認してみてください。
個人的な感想としてはこんなに簡単にできて凄い(^^)と、日本語って難しいなぁ(^^;)という感想でした。
それでは今回は少し長くなりましたが、最後まで読んでくれた方、本当にありがとうございました!
ぜひ試してみて面白い発見があった教えてください!!
最後に今後の深掘りのためにAPIリファレンスをまとめて記載しておきます。
APIリファレンス
各サービスのところで個別に載せてきましたが、今回扱ったサービスの利用するための boto3 のSDKのAPIリファレンスの一覧になります。
API一覧を眺めているとまだまだ面白い機能がありそうです(^^)
boto3
Amazon Rekognition:画像ファイルをインプットにモノ・人・顔を抽出する
Amazon Polly:テキストファイルをインプットに音声ファイルを生成する
Amazon Transcribe:音声ファイルをインプットにテキストファイルを生成する
Amazon Comprehend:テキストファイルをインプットにインサイトや関係性を検出する自然言語処理 (NLP) サービス
Amazon Traslate:テキストファイルをインプットに翻訳する
Amazon Textract:画像ファイルをインプットにテキストを抽出する
資格取得に向けてAWSサービスを実際に利用してみるシリーズの投稿一覧
とりあえず30分でAWS利用料金の高額請求に備える~予算アラート設定・MFA・料金確認~
AWS ECSでDocker環境を試してみる
Amazon Cognitoを使ってシンプルなログイン画面を作ってみる
AWS NATゲートウェイを使ってプライベートサブネットからインターネットにアクセスする
API GatewayをPrivateで作成してみる
AWSのAI(Rekognition/Polly/Transcribe/Comprehend/Translate/Textract)サービスを試してみる(本記事)
AWS Lambda 同時実行数、エイリアス、環境変数とか実際の現場で使える機能を勉強してみる
AWS Lambda SAMとは?~AWS SAMを使ってPythonのLambdaプログラムを簡単に作成する~
Cloud9でAWS Amplifyの公式チュートリアルGetting startedをやってみる