はじめに
Elasticsearch の進化に伴い、データ管理のベストプラクティスは変化してきました。しかしながら、コンサルの現場では古い情報、古いプラクティスを盲信していたり、新しい機能を把握していないがためにしなくても良い苦労をしていたり、傷口を広げていたりするケースをよく見かけます。
この記事では、Elasticsearch のデータ管理がどのような経緯で現在の形に至ったかを振り返り、現在の各種機能やプラクティスがどのような課題を解決するために生まれたのかを理解します。これにより、読者は自分の現在地を的確に理解し、目指すべき方向や取るべきアクションを判断できるようになります。
本稿執筆時点の最新バージョンは 9.3 です。
インデックス管理の変遷
v1.x
インデックス 1 本運用時代
Elasticsearch が普及し始めた頃、ログデータも単一インデックスに詰め込むシンプルな運用が一般的でした。
インデックスは 1 つ以上のシャードに分割され、各シャードがデータの一部を保持します。シャードにはデータの実体を持つプライマリと、その複製であるレプリカがあり、異なるノードに分散配置されることで冗長性と検索の並列性を確保します。そして各シャードの内部は、検索エンジンライブラリである Apache Lucene を利用しており、データはセグメントと呼ばれるイミュータブルな(変更できない)ファイル群として格納されています。

あれから 10 年以上が経ちましたが、現在のバージョンでもインデックスの基本構造は変わっていません。
図はプライマリシャード 2、レプリカシャード 1 の構成ですが、当時のデフォルトシャード数は プライマリ 5、レプリカ 1 でした。インデックスを 1 つ作ると、10 個のシャードが生まれていたんです。「5 ノードのクラスタに 1 シャードずつ均等分散できる」という設計思想が背景にあり、当時の一般的なクラスタ規模にはそれなりに合っていました。
また、この頃のインデックスには Mapping Types(_type) という仕組みがあり、1 つのインデックス内に複数の「型」を持たせることができました。例えば twitter インデックスに user type と tweet type を同居させるような使い方です。しかし実際には、異なる type の同名フィールドが内部的に同じフィールドオブジェクトを共有していたため、type が違っても同じマッピング定義が必要で、「別スキーマの同居」という目的は実質的に機能しませんでした。この仕組みは後の v6.0 で 1 インデックス 1 type に制限され、v7.0 で非推奨、v8.0 で完全に削除されました。現在の API で見かける _doc(例: POST /my-index/_doc)は、かつて任意の type 名だった部分が固定された名残りです。
v2.x
日付インデックス+手動管理

データ量の増加とともに「インデックスを時間で分割する」というプラクティスが定着しました。インデックスの作成時にマッピングやエイリアスなどの設定を毎回手で指定するのは非現実的なので、v1 から存在していた Index Template(_template)を使って、パターンに一致するインデックスに設定を自動適用するのが一般的でした。検索時には、logs-myapp のようなエイリアスを使用したり、logs-myapp-* のようにインデックスパターンにワイルドカードを使うことで、複数インデックスを横断して検索を行っていました。
「今日のインデックスを作る」Logstash
書き込み時にはエイリアス経由のルーティングはまだなく、書き込み先のインデックス名を自分で日付つきで指定する必要がありました。Logstash パイプラインにはこれを簡便にするためのマクロが用意されており、出力先インデックス名に logs-myapp-%{+YYYY.MM.dd} のようなパターンを指定するだけで、日付付きインデックスへの書き込みができました。
ただ、このマクロが参照するのはシステム日付ではなく @timestamp、つまりイベント発生時刻で、厳密には「今日」ではありませんでした。ログの収集や転送に遅延が生じると、イベントの @timestamp が昨日や数日前の日付になる場合があり、過去日付のインデックスにデータが書き込まれるという現象が発生していました。
これである程度スケールする仕掛けが整いましたが、「今日のインデックスを作る」「古くなったインデックスを削除する」といった作業はすべて手作業または自前スクリプトに頼っていました。
Curator の躍進
この時代の日付ベースのインデックス管理の運用負荷を軽減するために、ユーザーは Elastic が別プロセスとして無償で提供する Curator の運用を始めます。Curator にはアクションという概念があり、「30 日より古いインデックスを削除する」「60 日経過したインデックスをクローズする」といった日付インデックスの運用にかかるルール(アクション)を YAML で記述し、cron で定期実行できます。
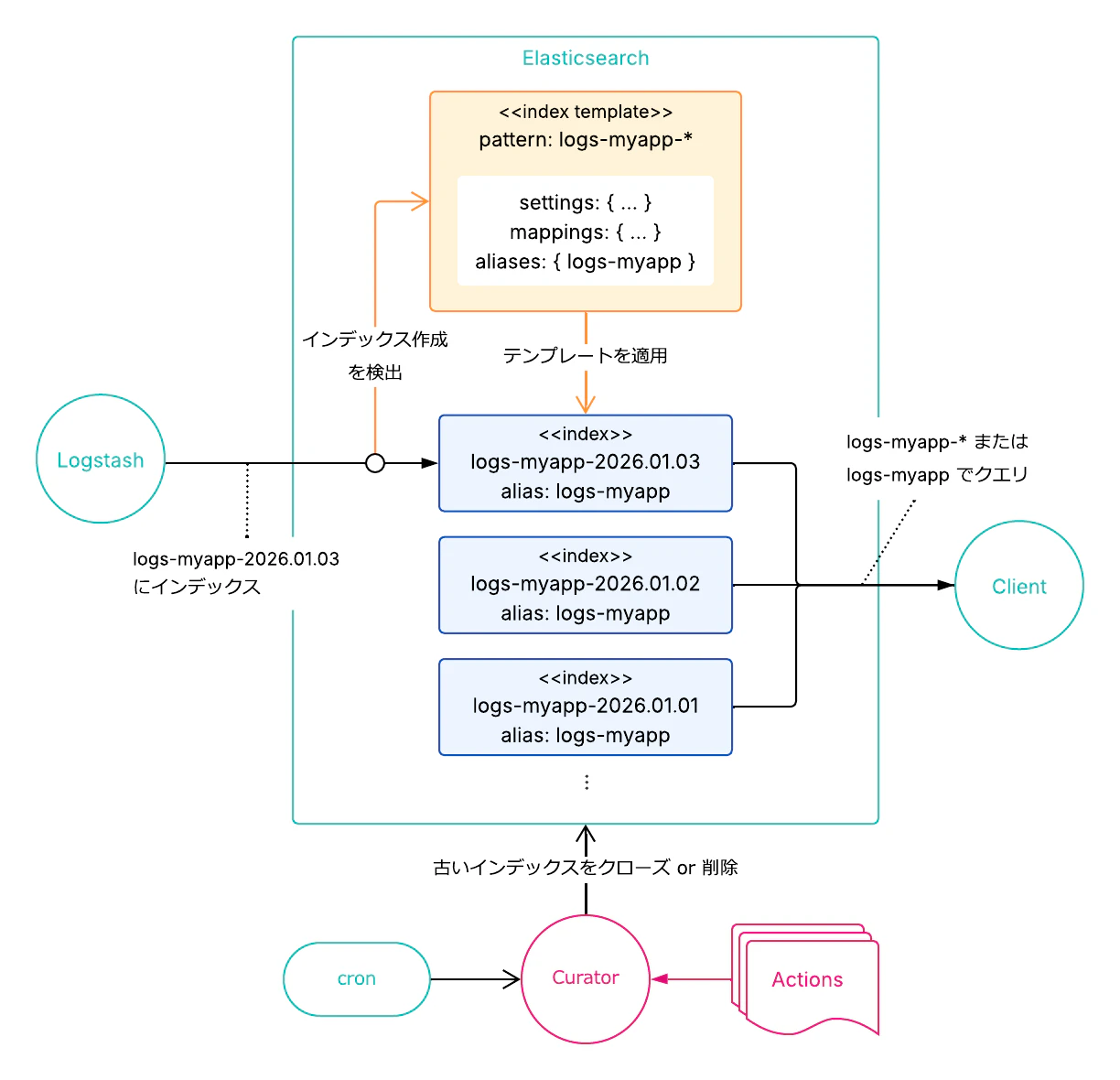
「インデックスのクローズ」は、当時よく使われたテクニックの一つです。クローズされたインデックスはシャードのメタデータを JVM ヒープ上に保持しないため、リソース消費を大幅に削減できます。ただし検索はできなくなるため、「もう検索しないが削除もしたくないデータ」の一時退避先として使われていました。ただし、クローズされたインデックスはディスクを消費し続け、移動もできない、スナップショットも取れないなどの制約があったため、あくまで一時的な措置で、最終的には削除することが前提でした。
以下は Curator のアクション設定ファイルの例です。インデックス作成から 30 日以上経過したものを削除する、というルールをこのように記述しました。
actions:
1:
action: delete_indices
description: "30日より古いインデックスを削除する"
options:
ignore_empty_list: True
filters:
- filtertype: pattern
kind: prefix
value: logs-myapp-
- filtertype: age
source: creation_date
direction: older
unit: days
unit_count: 30
Curator は Elasticsearch の外部ツールであることが根本的な問題でした。Curator のバージョン管理、設定ファイルの管理、実行環境の維持などはすべて運用者の責任になり、設定のミスがデータロストに直結するリスクを孕んだ仕組みでした。
スケーラビリティとコストの問題
この日付インデックスと Curator を利用した管理方式は、現在に至るまで広く利用されていますが、最大の問題はシャードの数が増えすぎることです。日付でインデックスを切るということは、その日のデータ量に関わらず毎日インデックスが増えていきます。データ量の少ない日には数 KB しかない小さなインデックスが量産され、プライマリシャード数をデフォルトの 5 のまま放置すると、クラスタ内のシャード総数が爆発的に増加していきます。後にオーバーシャーディングと呼ばれる問題で、Elasticsearch はシャード単位でメタデータを管理するため、シャード数が増えるほど JVM ヒープの消費量が増し、クラスタ全体のパフォーマンスが目に見えて低下していきました。
一部のインデックスをクローズすることでメモリの消費量を抑えることはできますが、クローズされたインデックスは検索できなくなること、またレプリカシャードを含めてローカルディスクを消費し続けることも問題でした。
また、当時はまだティアードアーキテクチャが発達していなかったため、大量のデータを保持するためには、現在の Hot ティアにあたる、比較的高性能なノードにすべてのインデックスを置いておく必要があり、そのコストも問題になりました。
ティアードアーキテクチャの発想
この頃から Hot / Warm / Cold という概念が使われ始めました。これはもともとデータへのアクセス頻度・書き込み頻度を指す概念で、「読み書きが活発なインデックスは Hot、ロールオーバー後に基本は読み取り専用となりつつも書き込みがたまに発生するのが Warm、ほとんどアクセスされないものが Cold」という意味です。
この概念が発展して、「たまにしかアクセスしないデータに、書き込みの多い Hot と同等のハードウェアを与えるのはもったいない。どうせたまにしかアクセスされないのだから読み取りが多少遅くてもいい。その部分は安いハードウェアを使って、より長期間保存できるようにすればいいじゃないか」という発想につながっていきます。現在の ILM によるティアード・アーキテクチャ(Tiered Architecture)の原点です。ただし当時はまだそのための仕組みがなかったため、本格的な運用はもう少し先になります。
v5.0
エイリアスの「ロールオーバー」機能の追加
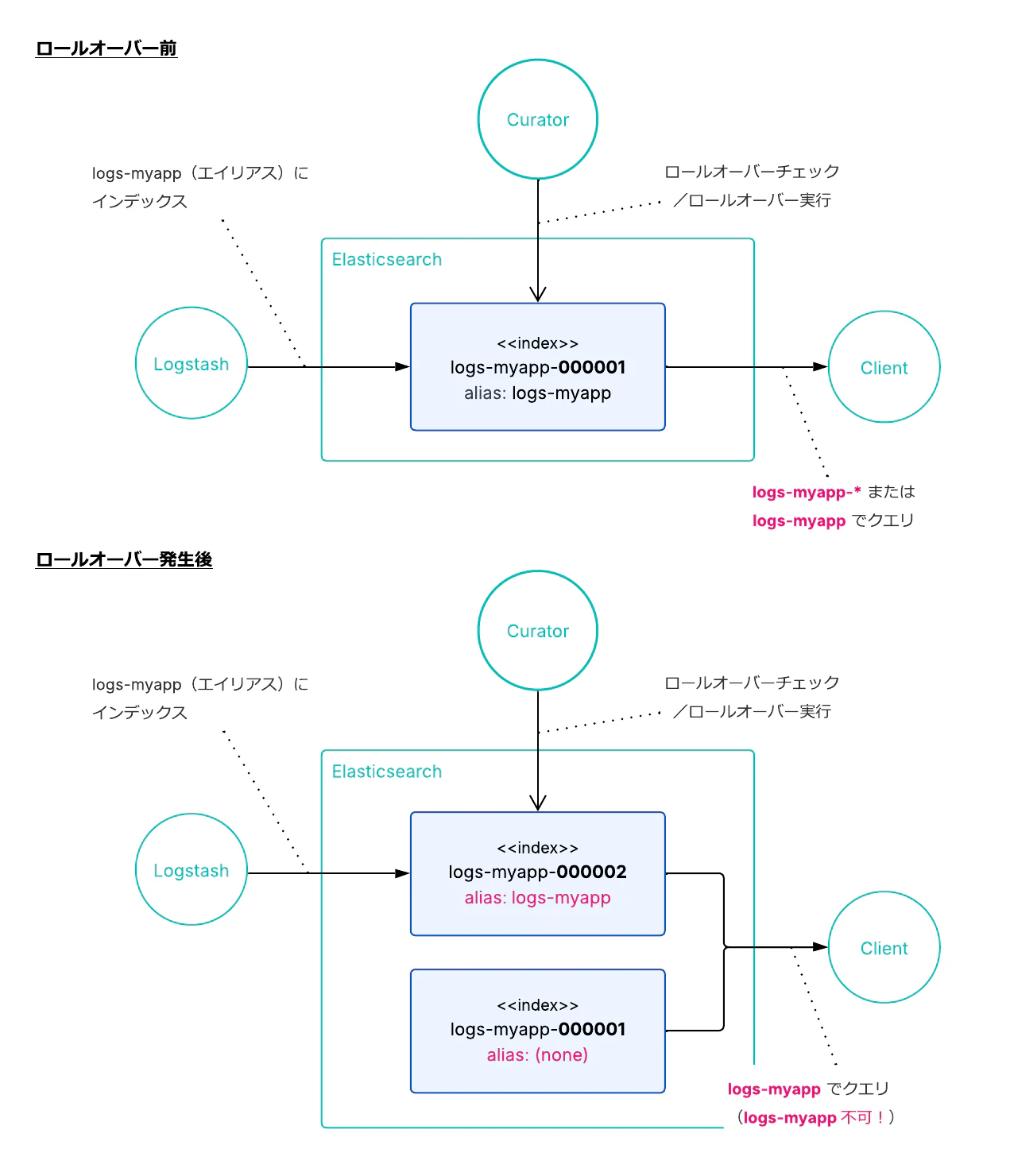
エイリアスをデータの書き込み先として使うこと自体は v5.0 以前から可能でしたが、エイリアスが指すインデックスを条件に応じて自動的に切り替える仕組みがなかったため、ユーザーは引き続き日付インデックスの運用を続けていました。
v5.0 で Rollover API が登場し、「指定した条件を満たしたら、エイリアスの背後にあるインデックスを新しいものに切り替える」というロールオーバー操作を Elasticsearch が担えるようになりました。
これにより、Logstash などのクライアントは日付付きのインデックス名を自分で生成する必要がなくなり、エイリアス logs-myapp に書き込むだけでよくなりました。ロールオーバーが発生すると、logs-myapp-000001 から logs-myapp-000002 のように数値サフィックスがインクリメントされた新しいインデックスが作成され、エイリアスの向き先が自動的に切り替わります。
以下は Curator などの外部ツールから Rollover API を呼び出す例です。インデックスの Age が 7 日、サイズが 50 GB を超えたらロールオーバーする、という条件を指定しています。
POST /logs-myapp/_rollover
{
"conditions": {
"max_age": "7d",
"max_size": "50gb"
}
}
ただし、この API は呼び出された時点で条件を評価してロールオーバーを実行するだけで、Elasticsearch が自律的に条件を監視して呼び出してくれるわけではありません。一見すると conditions を設定すればあとは自動で動きそうに見えますが、実際には前述の Curator などで定期的にこの API を呼び続ける必要がありました。
加えて、エイリアスはロールオーバーのたびに新しいインデックスだけを指すように付け替わる仕様になっていました。エイリアスのつけ先のインデックスが変わってしまうと、書き込みには便利でも、読み取りには不便です。このため全期間を横断して検索するには、logs-myapp-* のようなワイルドカードや、読み取り用のエイリアスが別途必要でした。また、ロールオーバーのトリガー自体は依然として Curator などの外部ツールから Rollover API を呼ぶ必要があり、完全な自律運用には至っていません。一言で言えば過渡期、エイリアスが書き込み・読み取り両方で使える自動化用ツールには到達していない状態でした。
v6.5
is_write_index フラグ
エイリアスに is_write_index フラグが導入されました。これにより、エイリアスが複数のインデックスを指しつつ、書き込み先を 1 つだけ指定できるようになります。 v5.0 の Rollover API では、エイリアスが常に 1 つのインデックスだけを指す必要があったため検索と書き込みで別々のエイリアスやワイルドカードを使い分ける必要がありましたが、is_write_index によって 1 つのエイリアスが検索と書き込みの両方をカバーするようになりました。
ロールオーバー時には is_write_index フラグが新しいインデックスに移るだけで、古いインデックスもエイリアスに残り続けます。
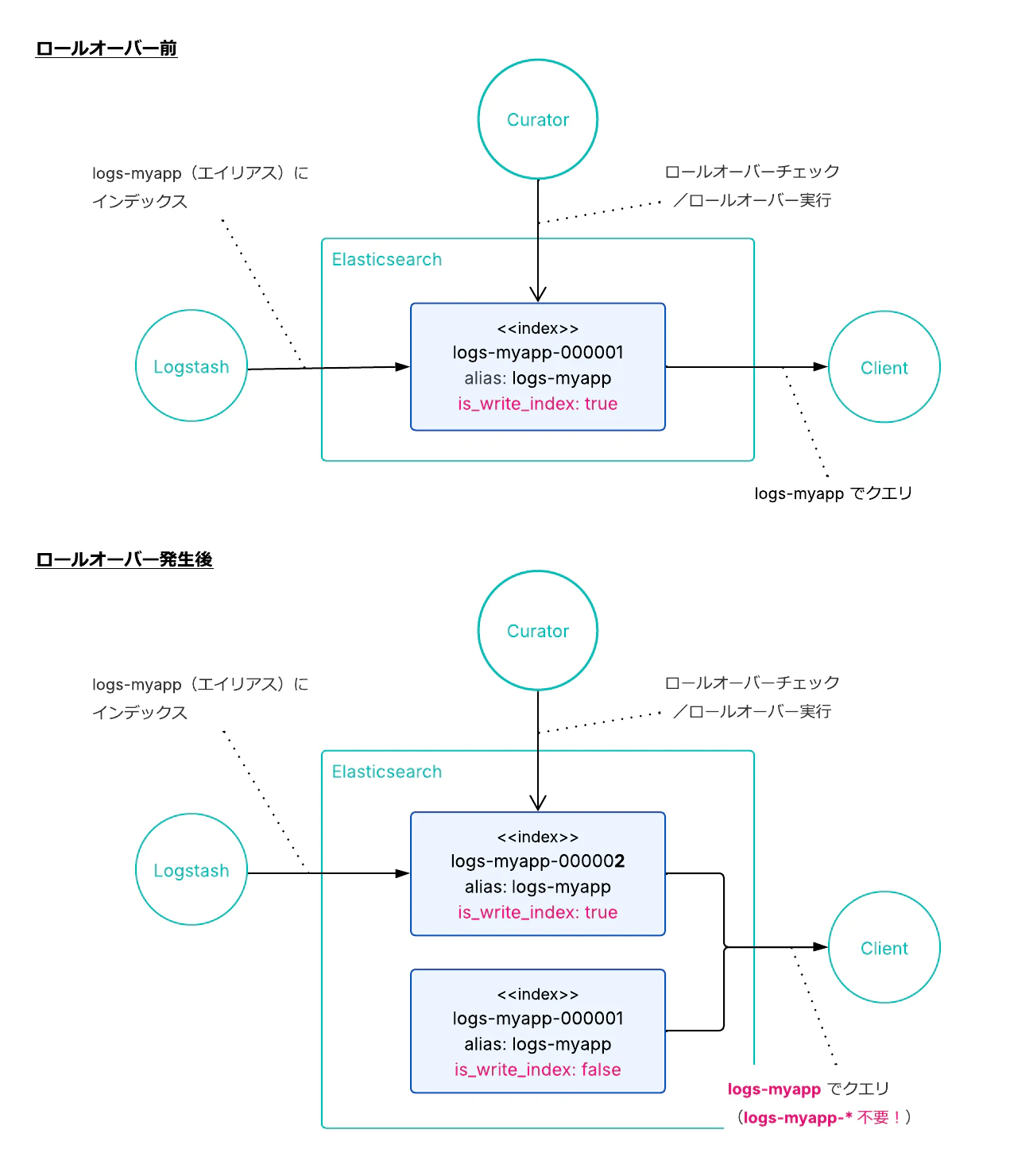
# インデックスを作成しエイリアスを書き込み先として設定
PUT logs-myapp-000001
{
"aliases": {
"logs-myapp": {
"is_write_index": true
}
}
}
この仕組みは、後に登場する ILM と Data Stream の基礎となりました。現在のバージョン(v9.3)でも、この is_write_index フラグは内部的に参照されており、ロールオーバーやエイリアス管理の基本的な仕組みとして使われ続けています。
v6.6
Index Lifecycle Management (ILM)
Index Lifecycle Management(ILM) が登場し、ロールオーバーからティア間のデータ移行まで一連のライフサイクル管理を Elasticsearch 内部で完結できるようになりました。Hot → Warm → Cold という段階的なフェーズ移行を定義し、インデックスに紐づけるだけで自動的に動作します。各ティアのノードはカスタム属性(node.attr.tier: hot など)で区別し、ILM がフェーズに応じてインデックスのシャードを適切なティアのノードに自動的に再配置します。
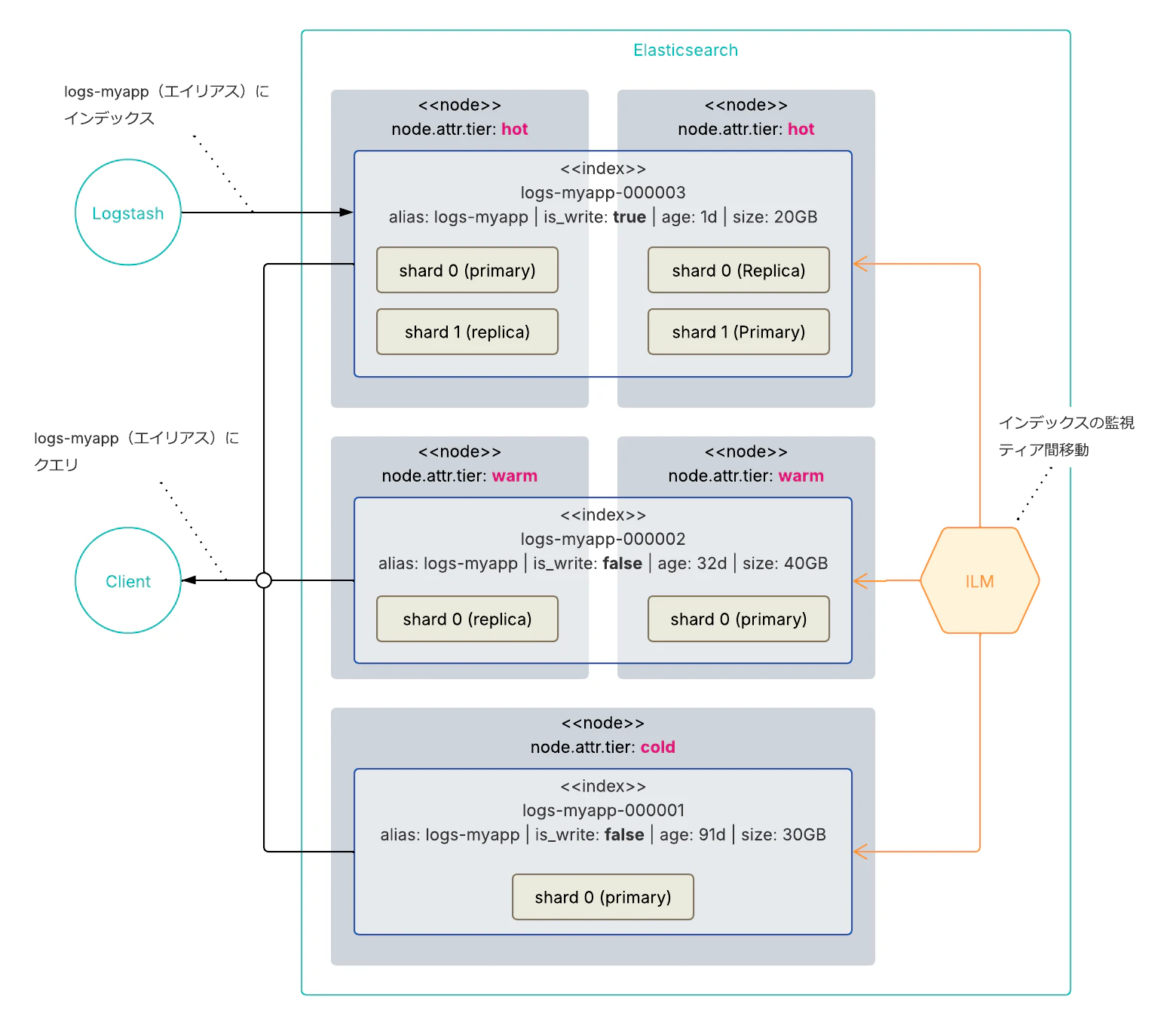
以下は ILM ポリシーの定義例です。このポリシーは次のような動作をします。
- Hot フェーズ: サイズが 40 GB を超えるか、インデックス作成から 14 日経過したらロールオーバー
- Warm フェーズ: ロールオーバーから 30 日後に移行し、プライマリシャードを 1 つに集約
- Cold フェーズ: ロールオーバーから 90 日後に移行し、レプリカシャードを 0 に
一度定義すれば、あとは Elasticsearch が自律的に管理します。
PUT _ilm/policy/logs-myapp-policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_primary_shard_size": "40gb",
"max_age": "14d"
}
}
},
"warm": {
"min_age": "30d",
"actions": {
"shrink": {
"number_of_shards": 1
},
"forcemerge": {
"max_num_segments": 1
}
}
},
"cold": {
"min_age": "90d",
"actions": {
"allocate": {
"number_of_replicas": 0
}
}
}
}
}
}
なお、上記の例で Warm フェーズに含まれている Force Merge(max_num_segments: 1)は、インデックス内のセグメントを強制的にマージして 1 つに統合するアクションです。ロールオーバー後のインデックスは書き込みが停止しているため、セグメントをマージすることで検索性能の向上とストレージ使用量の削減が見込めます。
各フェーズの min_age は、ロールオーバーが発生した時点から起算します。上記の例では、Cold フェーズの min_age: 90d は「ロールオーバーから 90 日後」であり、「Warm フェーズに入ってから 90 日後」ではありません。この挙動を誤解して min_age を設定してしまうケースが多いため、注意が必要です。
ILM の登場により、ロールオーバー、ティア間の移行、Shrink、Force Merge、インデックスの削除といった一連の操作がすべて Elasticsearch 内部で自律的に実行されるようになり、Curator のような外部ツールに頼る必要はなくなりました。ただしこの時点では、初期インデックスの作成やエイリアスの初期設定は利用者が手動で行う必要があり、セットアップの煩雑さは残っていました。
v7.0
プライマリシャードのデフォルト変更
v7.0 へのメジャーバージョンアップにあたり、オーバーシャーディング問題への対応として、プライマリシャードのデフォルト値が 5 から 1 に変更されました。「まず 1 シャードから始めてデータ量に応じて設計する」という現実的な方向への転換です。
シャードサイジングのガイダンス
この頃、Elastic の公式ブログ「How many shards should I have in my Elasticsearch cluster?」が公開され、シャード設計の指針が広く知られるようになりました。主なガイダンスは以下の 2 つです。
- ノードの JVM ヒープ 1 GB あたり 20 シャード以下: 例えばヒープが 30 GB のノードであれば、上限の目安は 600 シャード前後
- 1 シャードあたり 10〜50 GB: シャードが小さすぎるとオーバーシャーディング、大きすぎるとリカバリやリバランスに時間がかかる
その後、v8.5 までには公式ドキュメントの「Size your shards」として正式に整備されました。後述の通り、ノードあたりのシャード数に関しては後に緩和されますが、シャードサイズに関しては現在でも有効です。
v7.8
新しい Index Template
v1.0 の頃から存在する Index Template(_template、Legacy Template とも呼びます)は日付インデックス運用で広く使われてきましたが、テンプレート同士が暗黙的にマージされる挙動があり、複数のテンプレートが同じインデックスパターンに一致した場合にどの設定が優先されるかが分かりにくいという問題がありました。
これに代わる新しい Index Template(_index_template)が導入されました。設定の部品を Component Template として定義し、それらを明示的に組み合わせて Index Template を構成できます。優先順位も priority フィールドで明確に制御できるようになり、代わりにテンプレートのマージ機能を廃止しました。この仕組みは、次の v7.9 で登場する Data Stream の基盤となります。
v7.9
Data Stream の登場
Data Stream が登場し、ILM と組み合わせることで現在のメインストリームが確立しました。日付インデックスの命名規則、エイリアスの付け替え、書き込み先の管理 — これらをすべて Elasticsearch が内部的に抽象化して引き受けます。これにより利用者は外部スクリプトでのインデックス管理から解放され、「Data Stream から読む」「Data Stream に書く」だけでインデックスが最適化できるという、究極的にシンプルな運用が可能になりました。長い道のりでしたね。
また、v7.10 ではティアの管理方法も刷新され、カスタムノード属性(node.attr.tier)に代わり、data_hot、data_warm、data_cold、data_frozen といった正式なノードロールが導入されました。ILM がこれらのノードロールを自動的に認識するため、ティアの設定がよりシンプルになりました。
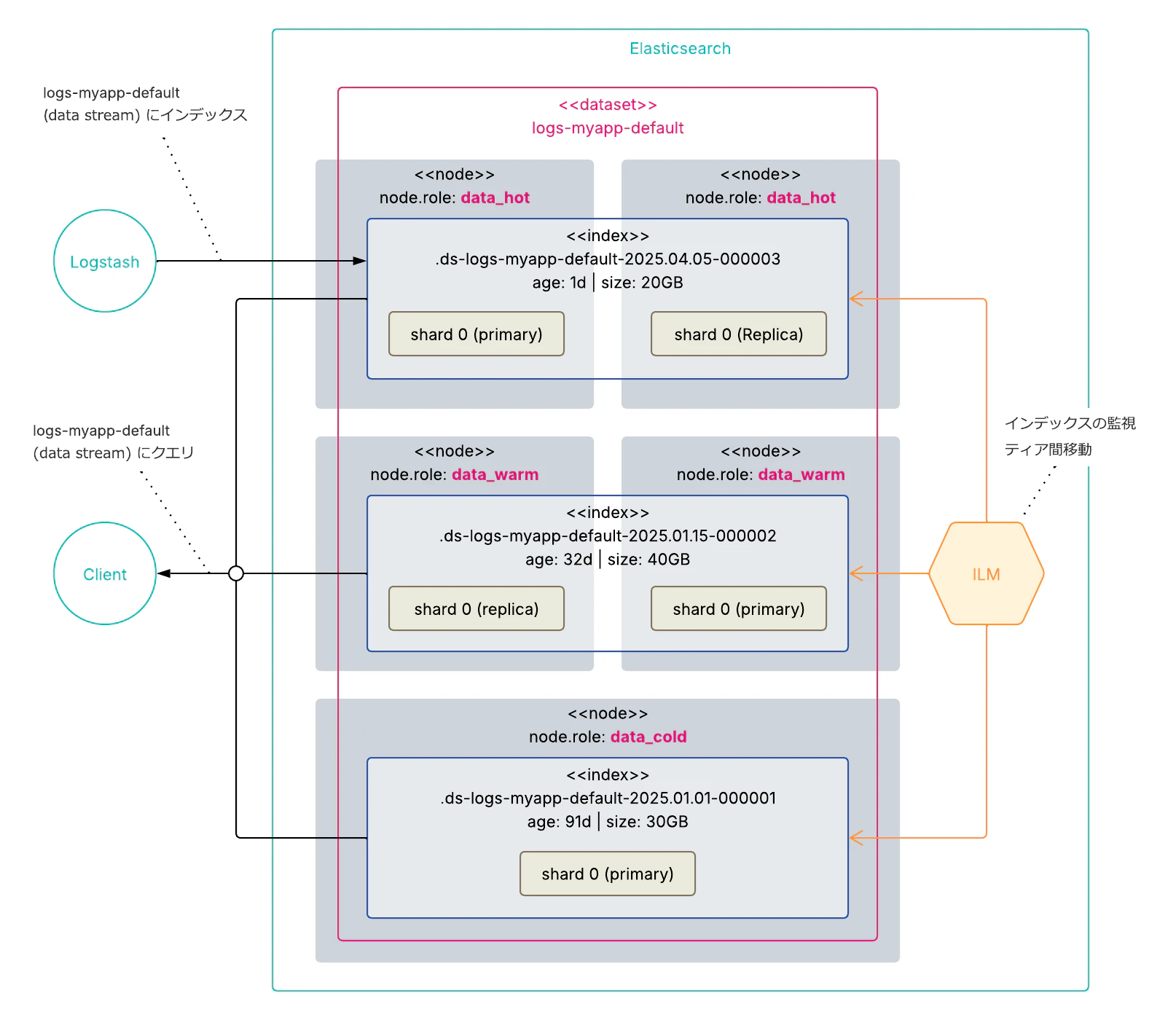
以下は Data Stream を有効にした Index Template の定義例です。data_stream キーを含めるだけで、このテンプレートのパターンに一致する名前へのインデックスリクエストが自動的に Data Stream として扱われます。
PUT _index_template/logs-myapp
{
"index_patterns": ["logs-myapp-*"],
"data_stream": {},
"template": {
"settings": {
"index.lifecycle.name": "logs-myapp-policy"
}
},
"priority": 200
}
Data Stream を作成してデータを書き込む場合は、通常のインデックスリクエストと同じ構文で送るだけです。
POST logs-myapp-default/_doc
{
"@timestamp": "2025-01-01T00:00:00Z",
"message": "application started"
}
Elasticsearch は内部的に バッキングインデックス(.ds-logs-myapp-default-2025.01.01-000001 のような隠れインデックス) を自動生成し、ILM ポリシーの条件に従ってロールオーバーや階層移行を行います。利用者からは常に logs-myapp-default という一つの名前でデータにアクセスでき、バッキングインデックスの存在を意識する必要はありません。
Data Stream と ILM の具体例については 弊社 SA 古久保の解説「Elasticsearch の Data Stream と ILM について」を参照いただければと思います。
なお、Data Stream には、「@timestamp フィールドが必須」「ドキュメントの Insert と Delete はできるが、Update はできない」という制約があるため、すべてのユースケースに適しているわけではありません。特に、更新が頻繁に発生するドキュメントや、時系列データ以外の用途には向いていないため、従来のインデックスを併用するケースも多くあります。
Data Stream の命名規則
Data Stream には {type}-{dataset}-{namespace} という標準の命名規則が定められました。
-
type — データの種類(
logs、metrics、traces、syntheticsのいずれか) -
dataset — データの出所や構造を示す名前(
nginx.access、system.syslogなど) -
namespace — 環境やチームなど、利用者が自由に設定するグループ名(
production、devなど。デフォルトはdefault)
例えば logs-nginx.access-production のような名前になります。この命名規則により、データが種類・出所・環境ごとに自然に分離され、それぞれの Data Stream が必要最小限のフィールドだけを持つことで、ストレージ効率とクエリ性能の向上にもつながっています。
詳細は Elastic の公式ブログ「An introduction to the Elastic data stream naming scheme」を参照してください。
v7.12
Searchable Snapshot と Frozen ティア
v7.10 でテクニカルプレビューリリースされていた Searchable Snapshot が GA になりました。Searchable Snapshot は、NAS や AWS S3 などの外部ストレージにバックアップとして保存されたスナップショットファイル内のインデックスを、そのまま検索できる画期的な仕組みです。
従来、コストを抑えてデータを長期保存するには、インデックスをクローズしてヒープ消費を減らすか、スナップショットに退避して検索を諦めるか、という二者択一でした。Searchable Snapshot はこのトレードオフを解消し、長期間データを検索可能な状態を維持しながら、ノードのローカルディスクやヒープの消費を大幅に抑えることを可能にしました。
この仕組みは、ILM の Cold フェーズ(ティア) と、新たに追加された Frozen フェーズ(ティア) に組み込まれました。
- Cold ティア: "Fully-mounted index" として、スナップショットからインデックスの完全なコピーをローカルに持ちます。検索性能は通常のインデックスとほぼ同等です。
- Frozen ティア: "Partially-mounted index" として、データの実体は外部ストレージに置いたまま、検索時にアクセスされた部分だけをローカルキャッシュに読み込みます。
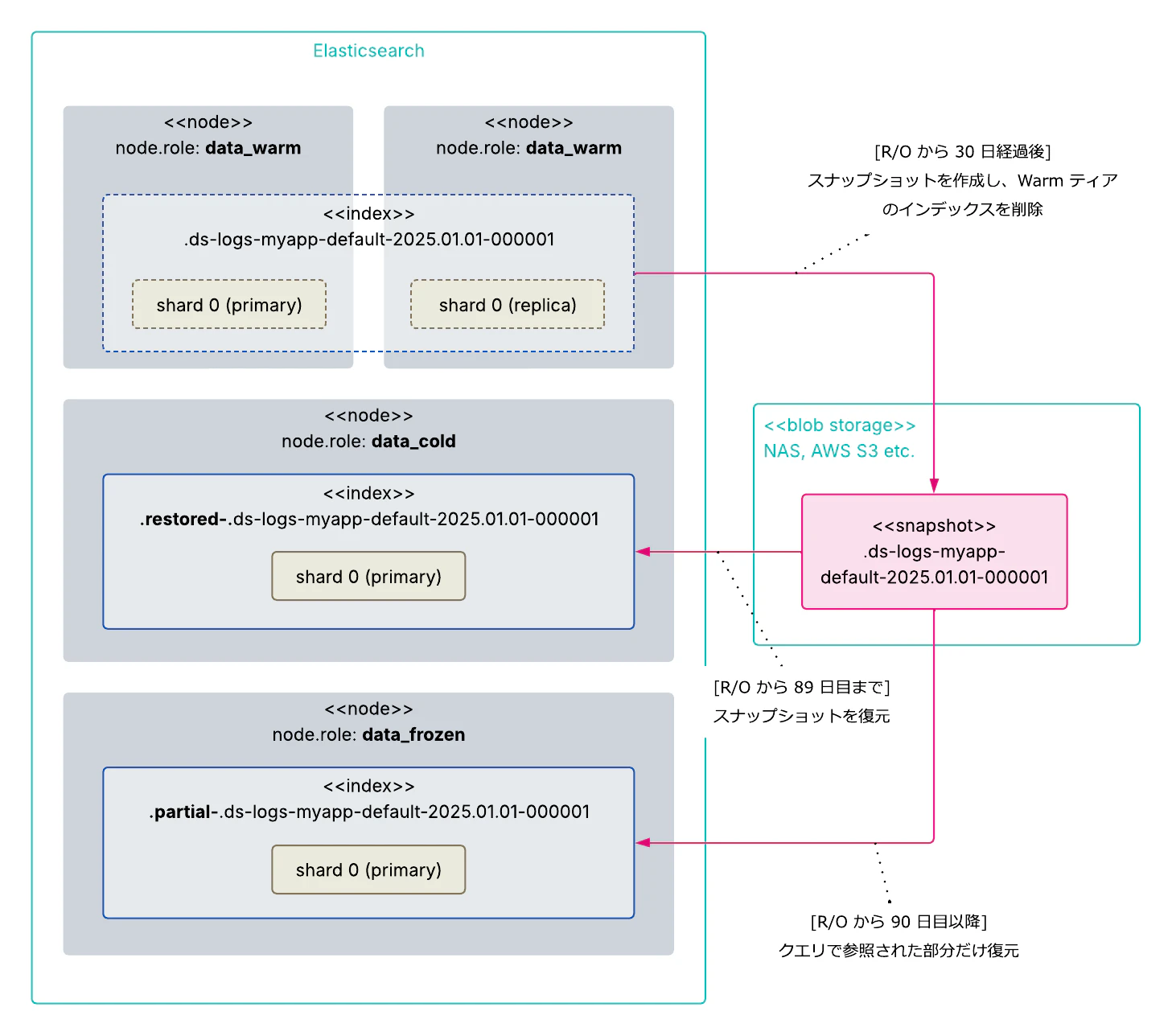
いずれもデータの実体がスナップショット側に存在するため、レプリカシャードが不要です。ノード障害時にはスナップショットから再マウントすれば復旧できるため、レプリカシャード分のリソースを丸ごと削減できます。Frozen に至っては、検索されない限りローカルディスクもヒープも消費しないため、データの長期保存に係るコストを劇的に下げることができます。考えた人すごいわという知る人ぞ知る絶品のパン屋がありますが、まさに。
これにより、Hot → Warm → Cold → Frozen → Delete というライフサイクルが完成し、コストを段階的に下げながらデータを長期間保持できるようになりました。また、インデックスのクローズによるメモリ利用量削減のテクニックは、Searchable Snapshot の登場によって役割を終えたと言えます。
v8.3
シャードあたりのヒープ消費量の改善
Elasticsearch の内部改良により、シャードあたりの JVM ヒープ消費量が大幅に削減されました。これにより、v7.0 時代に広く使われていた 「ノードの JVM ヒープ 1 GB あたり 20 シャード以下」というルールは緩和され、現在の公式ドキュメントではヒープ密度を主軸とした旧来のルールは前面に出ていません。代わりに、シャードサイズやクラスタ全体のシャード数を重視する方向に移行しています。
Archive Index
Elasticsearch はインデックスの内部に Apache Lucene を利用しており、メジャーバージョンアップのたびに内部の Lucene のバージョンが更新されるのですが、古いバージョンで作成されたインデックスには互換性の制約があります。通常、読み書き可能な状態で扱えるのは 1 世代前のメジャーバージョンで作成されたインデックスまでです(例: v8 では v7 で作成されたインデックスまで)。それより古いインデックスは、そのままでは読み込むことができず、v5 → v7、v6 → v8 など、2 メジャーバージョンを連続でアップグレードしたい場合、中間のバージョンですべてのインデックスを Reindex してからアップグレードする、という狂気の制約がありました。
Archive Index はこの制約を緩和する仕組みで、5.0 以降のスナップショットから古いインデックスを読み取り専用の Searchable Snapshot としてマウントできます。書き込みや Get API は使えませんが、検索や集計は可能です。コンプライアンスや過去データの調査など、古いデータへのアクセスが必要な場面で、Reindex なしにデータを参照できるようになりました。スナップショット経由でインデックスを読む場合のレイテンシーはあまりよろしくない、と聞いていますが、ユースケースによっては数百 TB にも登る大量のインデックスの Reindex が必要なくなることを考えると、有用な機能です。
v9 では v7 で作成されたインデックスも読み取り専用の Archive として扱われます。v7 インデックスを読み書き可能な状態で使い続けるには Reindex が必要です。
v8.4
Synthetic _source
通常、Elasticsearch はドキュメントの原文を _source フィールドにそのまま保存しています。Synthetic _source は、この _source を保存せず、インデックスされた各フィールドの値から検索時にドキュメントを再構築する仕組みです。v8.4 でテクニカルプレビューとして導入されました。
_source の保存を省くことでストレージ使用量を大幅に削減できます。ただし、再構築されたドキュメントはフィールドの順序や空白などが元の原文と異なる場合があるため、原文の完全な再現が必要なユースケースには適しません。ログやメトリクスのような機械生成データとの相性が良い機能です。
v8.7
Time Series Data Stream(TSDS)
メトリクスデータに特化した Data Stream である TSDS(Time Series Data Stream) が GA になりました。Index Template で index.mode: time_series を設定することで有効になります。同じ時系列のドキュメントが同一シャード上に集約・ソートされ、ディスク上で隣接して配置されることで圧縮効率が大幅に向上し、ストレージ使用量を平均で約 30% 削減できます。

TSDS は名前の通り依然として Data Stream の一種であり、利用者から見える API や使い方は通常の Data Stream と変わりません。違いは index.mode: time_series を設定することで、バッキングインデックス内のドキュメント配置が _tsid(次元の組み合わせ)でグルーピングされ、さらに時刻順にソートされるという点です。隣接するドキュメントの値が似通うことで圧縮アルゴリズムが効きやすくなり、ストレージ使用量が削減されます。
TSDS では Synthetic _source がデフォルトで有効になっており、TSDS 向けには Synthetic _source もここで GA となりました。
v8.17
logsdb
ログデータに特化した Index Mode、logsdb(index.mode: logsdb)が GA になりました。logsdb は新しい技術ではなく、既存のデータ圧縮機能の「おまとめ機能」 です。前述の Synthetic _source、v2.0 から利用可能だった best_compression インデックスコーデック(DEFLATE 圧縮アルゴリズム)、そして TSDS で確立したインデックス内のソート順の最適化 — これらを最適な構成で組み合わせることで、ログデータのストレージ使用量を最大 65% 削減できることが分かっています。
詳細は以下のブログを併せて参照いただければと思います。
- Elastic logsdb: Elasticsearch's specialized logsdb Index Mode(Elastic 公式ブログ)
- Elasticsearch v8.17 GAの新機能LogsDBモードによるログ容量の削減度合いについて検証(弊社 SA 関屋の投稿)【必読!】
v8.19 / v9.1
Failure Store
Data Stream に Failure Store 機能が GA として追加されました。インジェスト時にマッピングエラーなどで取り込みに失敗したドキュメントを、破棄せずに専用のバッキングインデックスに自動的に隔離・保持する仕組みです。
従来、Ingest Pipeline やマッピングの不整合でドキュメントの取り込みが失敗した場合、そのデータは静かに失われるか、送信側の Dead Letter Queue などの別の仕組みで個別に対処する必要がありました。Failure Store はこれを Data Stream の標準機能として組み込み、失敗したドキュメントの原因調査、修正、再取り込みを一貫したワークフローで行えるようにした仕組みです。
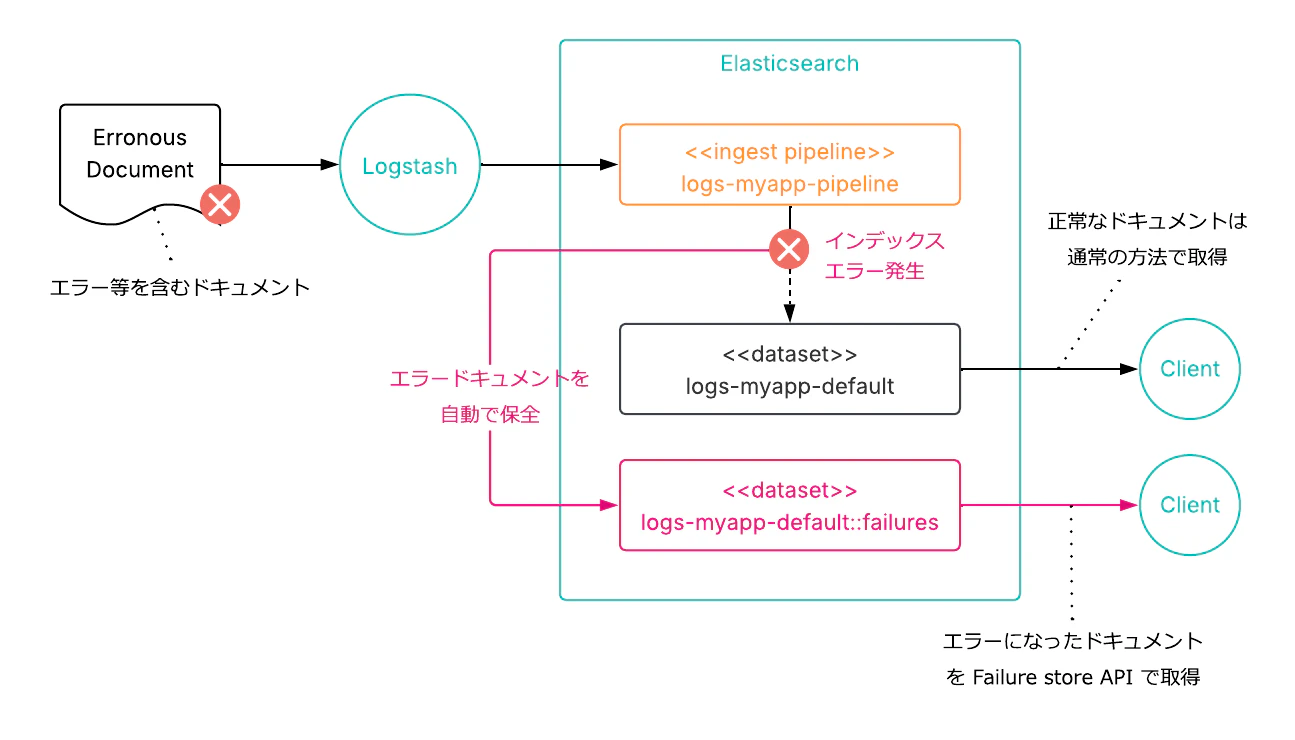
Failure Store を有効にするには、Index Template の data_stream に failure_store を設定します。
PUT _index_template/logs-myapp
{
"index_patterns": ["logs-myapp-*"],
"data_stream": {
"failure_store": {
"enabled": true
}
}
}
失敗したドキュメントは、Data Stream 名に ::failures サフィックスをつけることで検索できます。
GET logs-myapp-default::failures/_search
注意点として、すべてのエラーが Failure Store にリルートされるわけではありません。このあたりの詳細は弊社 CA 杉本の解説「Elasticsearch の Data Streams の Failure Store について」を参照していただければと思います。
recover_failure_document プロセッサによる再取り込み
recover_failure_document プロセッサは、Failure Store に保全されたドキュメントを復旧するための、Ingest Pipeline のプロセッサです。
具体的には以下のように利用します。

PUT _ingest/pipeline/failure-recovery
{
"processors": [
{ "recover_failure_document": {} },
{ "reroute": {} }
]
}
POST _reindex
{
"source": {
"index": "logs-myapp-default::failures"
},
"dest": {
"index": "logs-myapp-default",
"pipeline": "failure-recovery"
}
}
recover_failure_document は入力されたドキュメントのエラーメタデータを除去して元のドキュメント形式に復元します。続く reroute プロセッサで元の Data Stream のデフォルトパイプライン(修正済み)に再投入します。
この機構のポイントは、エラーの原因である Ingest Pipeline やマッピングに恒久処置をしてから再投入するというアプローチを採っている点です。このためには、まずエラーの原因を解消する必要があります。Failure Store のドキュメントにはエラーメタデータ(失敗理由、元のパイプライン名など)が付与されているので、それを手がかりに、マッピングの修正や Ingest Pipeline の grok パターン修正など、根本原因を先に直します。原因を修正せずにそのまま再投入しても同じエラーで再び Failure Store に戻るだけなので、必ず先に原因を解消してください。
v9.2
Streams
Elastic Observability 向けに Streams という上位レイヤーが登場しました。超単純化すると、Streams はログの自動仕分けの仕組みです。新しいデータの箱ではありません。Streams の目的は Integration ではカバーしきれない領域 — 特に Kubernetes コンテナログのような「行ごとにフォーマットが違うログ」を、AI の力を借りて整理・パース・分類することにあります。
定番ミドルウェア(nginx、MySQL など)のログ収集には組み込みの Integration が用意されており、これらはインストールするだけでパース・マッピング・ダッシュボードまで行ってくれます。しかし Integration が用意されていないカスタムアプリや、Kubernetes コンテナログのように雑多なログが混在する領域では、Integration はデータを「取り込む」ことしかできず、その先の構造化は SRE の手作業に依存しているのが実情です。
自社の Kubernetes クラスタに 100 を超えるマイクロサービスが動いていて、それぞれが独自のフォーマットでログを吐き出しているケースを想定してみてください。あるサービスは JSON、別のサービスは独自のテキストフォーマット、さらに別のサービスはマルチラインのスタックトレースが混在しています。Elastic の組み込みの Integration でこれを取り込むと、これらはすべて kubernetes.container_logs という単一の Data Stream に流れ込んでいきます。message フィールドには生ログがそのまま入っており、構造化されていません。
障害が起きると、SRE は Kibana を開いて message フィールドを目で grep します。しかしフィールドが切られていないのでメッセージは見難く、エラーレートを測ろうにも集計ができません。「これは grok パターンを書かないとダメだな」と腰を上げ、Ingest Pipeline を作り、Index Template を更新し、Reindex を流し、また別のサービスのフォーマットが違うことに気づき……気がつけば半日が溶けています。翌週には新しいサービスがデプロイされ、また新しいログフォーマットがカオスに加わります。
Streams の Wired Streams はこのような状況下で SRE を救出するための機能です。利用者は全ログを logs という親 Stream に放り込むだけ。Streams が以下を AI の支援のもとで自動化してくれます。
- 自動パーティショニング: 流れてくるログを観察して「これは別のシステムから来ている」と判別し、子 Stream に自動的に分割する
- 自動パース: ログのフォーマットを自動検出し、パースルール(Ingest Pipeline)を生成する。grok パターンを手で書く必要がなくなる
- Significant Events の検出: Java の OutOfMemoryError や Exception のような「重要そうなイベント」を自動抽出し、調査の起点として浮かび上がらせる
内部的には、子 Stream(パーティション)ごとに Data Stream が自動生成され、それに紐づく Index Template や Ingest Pipeline も Streams が裏側で組み立てます。子 Stream はドット区切りの階層構造(例: logs.myapp.order、logs.myapp.order.errors)で管理され、設定は親から子へ継承されます。
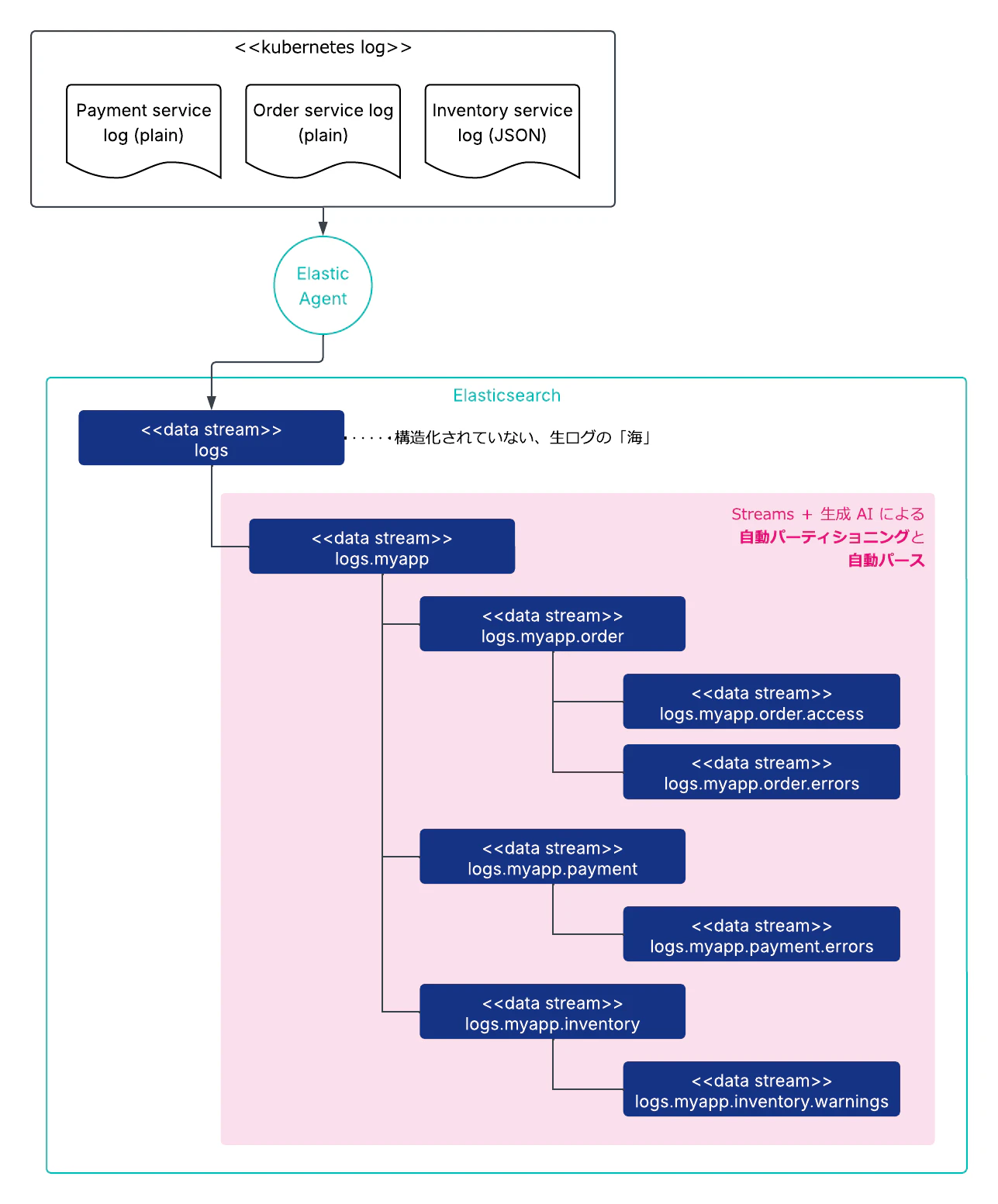
つまり Streams は、組み込みの Integration の手が届かない、1 つのログインプットに複数のログが混在するカオス的状況で、AI を活用して grok パターンの保守や Ingest Pipeline の手動定義のための人的コストを削減するための仕組みです。Elastic 公式が明言している通り、Streams は既存の Integration を置き換えるためのものではありません。Integration が用意されている定番ミドルウェアや SaaS については、引き続き Integration を使い、上記のような状況でのみ、Streams を活用するのがベストです。
Streams の詳細については、以下の投稿をご参照いただければと思います。
- AI × Elasticsearch:ログの取り込みをもっとスマートにする「Streams」を試す(弊社 CA 杉本の解説)
- v9.2 Tech Previewの新機能Wired Streamsでどこまでログのパースが楽になるかをやってみた(弊社 SA 関屋の解説)
まとめ
最新のインデックス管理手法
v9.3 現在のベストプラクティスをまとめると、おおよそ以下のようになります。
- インデックスのプライマリとレプリカは基本的に 1 にする: プライマリシャードは 1 つ、レプリカシャードも 1 つにするのが現在のスタンダードです。
- シャードを推奨サイズに収める: 前述の通り、シャードあたりのサイズは 10〜50 GB を目安に設計するのが一般的なベスト・プラクティスです。1 つのシャードサイズをできるだけ大きくすることで、シャード数を最適な数に自然に収束させます。
- Data Stream と ILM をデフォルトにする: データ管理を最大限効率化するために、Data Stream と ILM を積極的に活用することを推奨します。日付付きインデックスの運用は現在では非推奨です。
-
インデックスの圧縮率を上げる: インデックスに
index.codec: best_compressionを設定することで、Lucene の圧縮率の高いアルゴリズムを利用します。これにより、ストレージ使用量をさらに削減できます。 - Synthetic _source、TSDS、logsdb を有効にする: これらのストレージ効率化機能を活用し、ストレージ利用量を最小化します。これらの機能は、特にログやメトリクスのような機械生成データとの相性が良く、ストレージコストを大幅に削減できます。
- Force merge: ロールオーバー後読み取り専用になったインデックスに対して Force merge を実行してセグメント数を減らし、検索性能の向上とストレージ使用量の削減を図ります。
- Failure Store を有効にする: データの取り込み失敗を自動的に隔離・保持することで、データロストのリスクを減らし、失敗したドキュメントの原因調査や再取り込みを容易にします。
- Searchable Snapshot と Frozen ティアを活用する: Searchable Snapshot と Frozen ティアを積極的に活用して、インフラコストを抑えつつ、これまでスペースの都合で諦めていた古いデータを最小のコストで維持できるクラスタを構築します。そのコスト効率の良さから、近年では Hot と Frozen ティアのみで運用するケースも増えています。
おわりに
今回は Elasticsearch のデータ管理方式の歴史を振り返りながら、現在の機能やプラクティスがどうなっており、それがどのような経緯で生まれてきたのかを解説してみました。
元々は前回の投稿の続きとして、データストア設計手法を解説する予定でした。が、ユーザーの皆さまの現在位置はバラバラなので、「現行ではこれがベスプラです」という結論だけを提示しても、必ずしも全員に等しく理解・受容いただけるわけではありません。
そこで今回のように、各機能について、これまでの経緯を説明することで、現在のプラクティスの位置、目的、理由が等しく明確になり、自分の現状とベスプラとの距離やアップグレード・パスを把握したり、機能の取捨選択、ワークアラウンドなどを納得して選択できるようになったり、今後の機能拡張にも柔軟に対応できるようになるだろう、なるはず、という目論見のもと、本稿を執筆しました。
かく言う自分も v5.6 で初めて ELK に触れ、その後 v6 と v7 をほぼほぼスキップして v7.17/8.3 から再び学び始めたので、v6 から v8 にアップグレードするプロジェクトでは度々罠に落ちました。その苦労の一部は当記事に織り込まれております。
皆様の Elastic ライフの一助になれば幸いです。
参考資料
Elastic 公式ブログ
- Removal of mapping types in Elasticsearch 6.0 — Mapping Types 廃止の背景
- How many shards should I have in my Elasticsearch cluster? — シャードサイジングのガイダンス
- Improving node resiliency with the real memory circuit breaker — v7.0 の Real Memory Circuit Breaker
- An introduction to the Elastic data stream naming scheme — Data Stream の命名規則
- What's new in Elasticsearch 8.3 — Archive Index の紹介
- Elastic logsdb: Elasticsearch's specialized logsdb Index Mode — logsdb Index Mode の解説
- Schema on write vs. schema on read with the Elastic Stack — Schema-on-Write と Schema-on-Read の比較
Elastic 公式ドキュメント
- Size your shards — シャードサイズの設計指針
- Data streams — Data Stream の概要
- Time series data stream (TSDS) — TSDS の概要
- Searchable snapshots — Searchable Snapshot の概要
- Reading indices from older Elasticsearch versions — Archive Index と互換性
- Streams — Streams の概要
弊社メンバーの投稿
- Elasticsearch の Data Streams の Failure Store について
- AI × Elasticsearch:ログの取り込みをもっとスマートにする「Streams」を試す
- ElasticsearchのData StreamとILMについて
- ElasticsearchのFrozenデータティアにデータが入るのをテストしてみた (1)
- ElasticsearchのFrozenデータティアにデータが入るのをテストしてみた (2)
- v9.2 Tech Previewの新機能Wired Streamsでどこまでログのパースが楽になるかをやってみた
- 弊社関屋による logsdb の検証記事