はじめに
Elastic Stack v9.2のTech Previewとして登場したWired Streamsについて早速検証してみたので体験をお伝えします。Elastic Cloudはもちろん、Self-Managedでも利用可能です。なお、この機能はElasticオブザーバビリティの中の機能です。
Wired Streamsは少し前に出た"Classic" Streamsの新たな別モードです。
https://www.elastic.co/docs/solutions/observability/streams/streams
Classic versus wired streams
Streams can operate in two modes: wired and classic. Both manage data streams in Elasticsearch, but differ in configuration, inheritance, and field mapping.
Classic Streamsについては以下のQiitaブログもありますので、興味あればご覧ください。
https://qiita.com/tomo_s_el/items/1ac505b700fb4fde6f18
そもそもStreamsとは? については上記ブログから引用させていただきます。
Elasticsearch には インテグレーション という、データソース毎に定義されたフィールド情報や、抽出ロジックを活用してデータを収集する仕組みはありました。必要に応じてインテグレーションをカスタマイズしながら、Elasticsearch に情報を収集する事が一般的でした。インテグレーションのないデータソースは、イチからフィールド抽出ロジックを作成する必要がありました。
Streams では生成AI を活用してフィールド抽出ロジックを作成する事で、インテグレーションのないデータソースも簡単に取り込めるようになります。
よって、ログ取り込みはまずElastic AgentとIntegrationsを利用することを検討すべきですが、それでは対応できないような状況でStreamsを検討するのが良いと思います。
Wired Streamsとは?
Wired Streamsの説明は公式ドキュメントでは以下の通りです。和訳したものを掲載します。
https://www.elastic.co/docs/solutions/observability/streams/streams
Wired Streamsは、データを 1 つのエンドポイントに直接送信し、そこから手動または AI による提案に基づいて設定されたパーティションを使って子ストリームへデータを振り分けることができます。
Wired Streamsは:
• ストリームを親子階層で整理できるようにします。
• 子ストリームが、マッピング・ライフサイクル設定・プロセッサを自動的に継承できるようにします。
• ストリーム全体の一貫性を保つために、設定変更を階層全体へ伝播します。
Wired Streamsでは全てのログを logsエンドポイントに送れば良く、送る側としては非常にシンプルです。これが今までのログ投入方式との一番の大きな違いです。
StreamsのAIサジェスト機能を使う場合は、Enteprise Subscriptionが必要です。
AIサジェストを使わない場合は、無料のBasic版でも利用可能です。
今回の手順では、StreamsのAIサジェスト機能も使っています。同様の手順をするには、事前にKibanaにてLLMへの接続を設定するか、Elastic Cloudの場合は用意されているElastic Managed LLMを使ってください。(Elastic Managed LLMの利用はクレジットを消費します。)
まずはWired Streamsを使った結果から
この後の説明が長くなるので、まず結果から見せたいと思います。
今回は以下の3つのログファイルをElasticのlogs Data Streamにアップロードしました。
- openstack_abnormal.log
- openstack_normal1.log
- openstack_normal2.log
openstack_normal1.logを例に中身を見ると以下のような感じとなっています。このログは、別のログファイルのデータをマージしたログになっているようです。元々のログファイルの名前が行頭にあり、続いてログ本体があります。2017年頃のデータのようです。
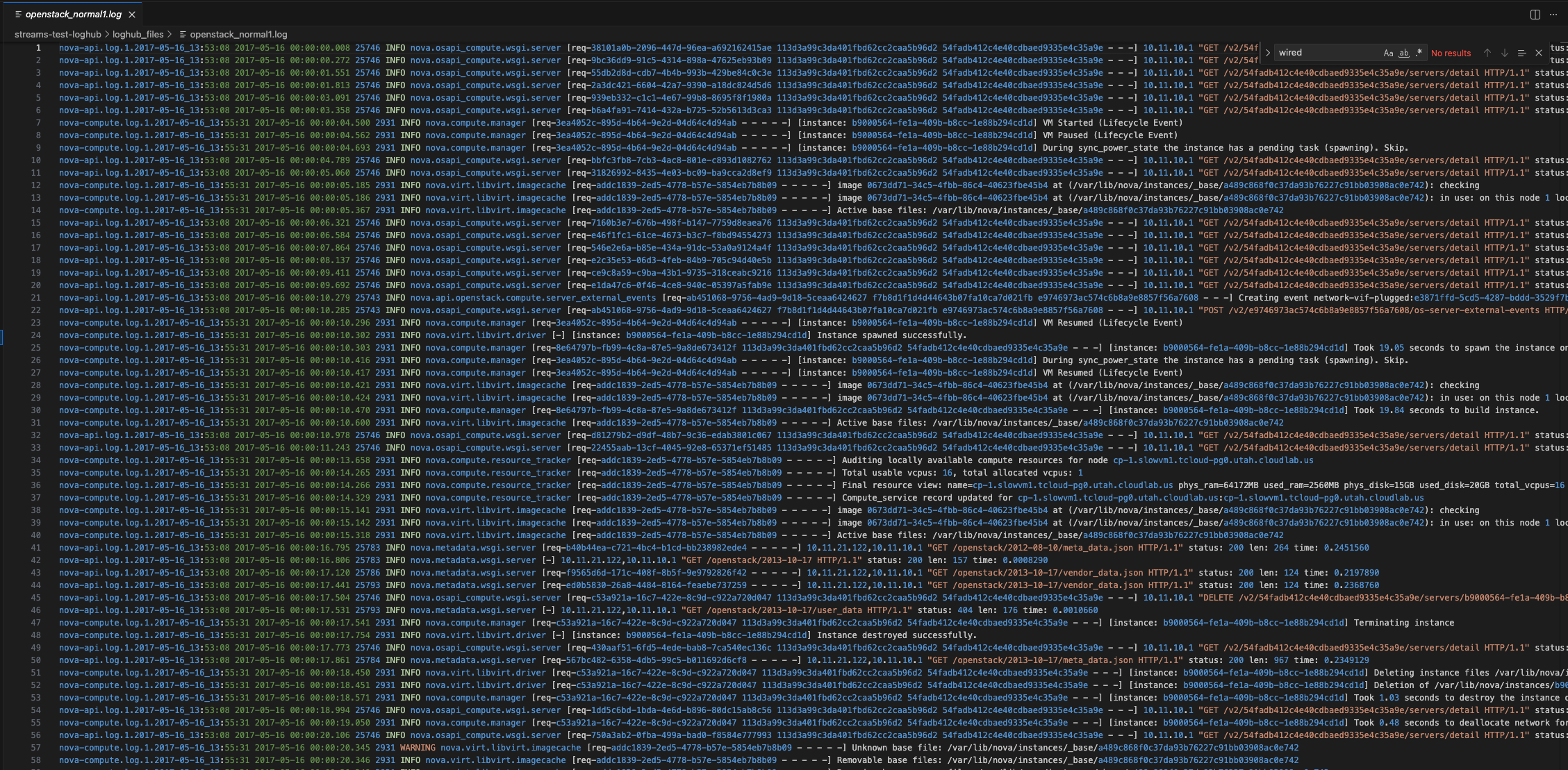
このように、複数タイプのログデータが含まれているという割と難しいシチュエーションのログファイルをアップしました。結果207820件のログ数。
📊 処理完了:
- 成功したファイル: 3/3
- 送信したログエントリ総数: 207820
Wired Streamsを使った結果、これが以下のように5つのパーティション(= 5つのData Stream)に分割され ..
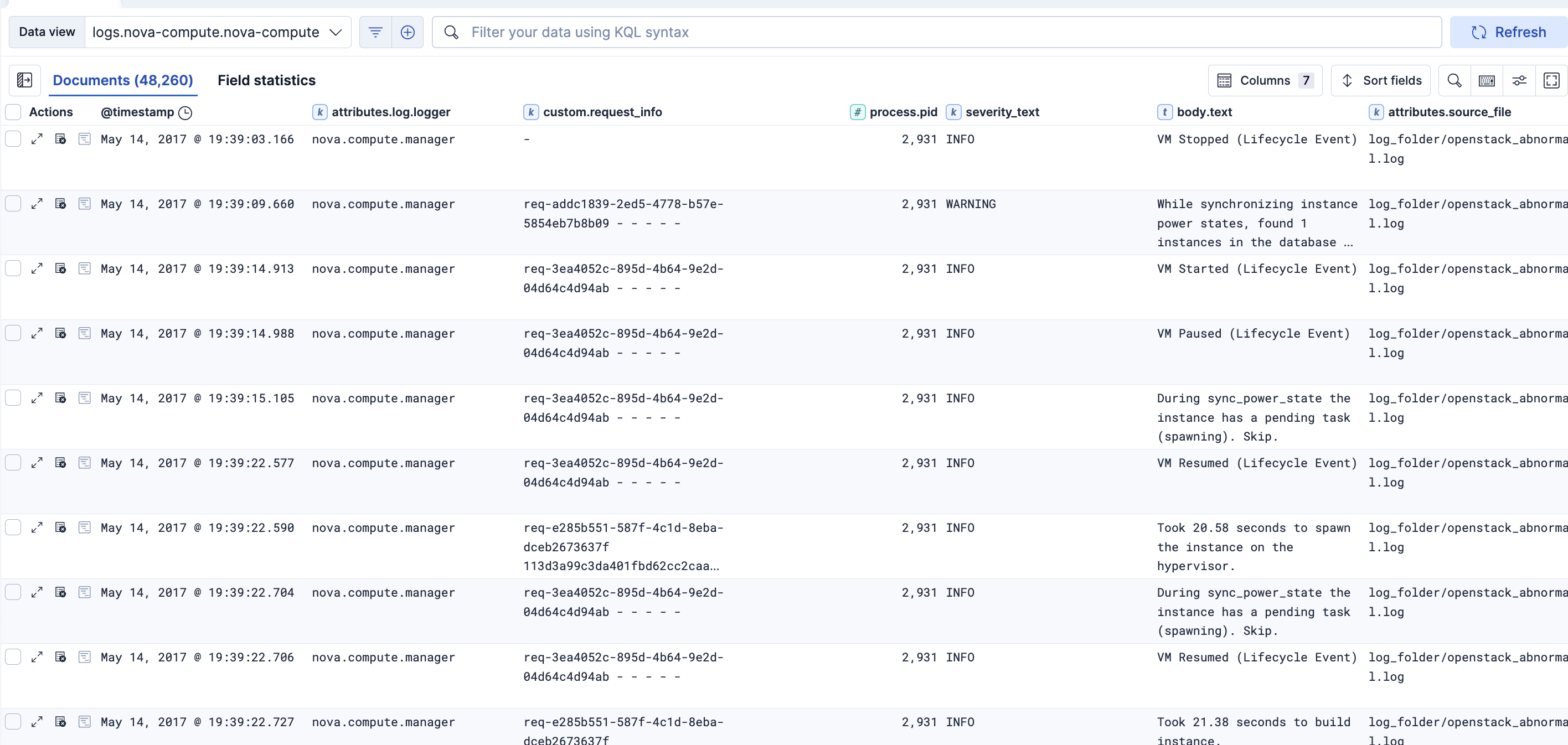
ログのパース処理にて、このようにログメッセージをフィールドとして認識し、分析可能となりました。
Wired Streams無しで同じ結果を得ようとすると、Elastic Ingest PipelineやGROKの達人にならないと実現できないレベルの設定が必要です。あるいはLogstashを駆使して対応するようなケースもあるでしょう。
従来は、ログ送信クライアント側でどのData Streamに送るかを事前に設定しておかないといけなかったのですが、それが不要となりました。
一つのlogsエンドポイントにログを送って、後で柔軟に扱い方を設定できるようになり、Elasticでのログ運用がもっと簡単になりそうです!
以降はこの結果を得るまでに行ったことをお伝えします。
Wired Streamsの有効化
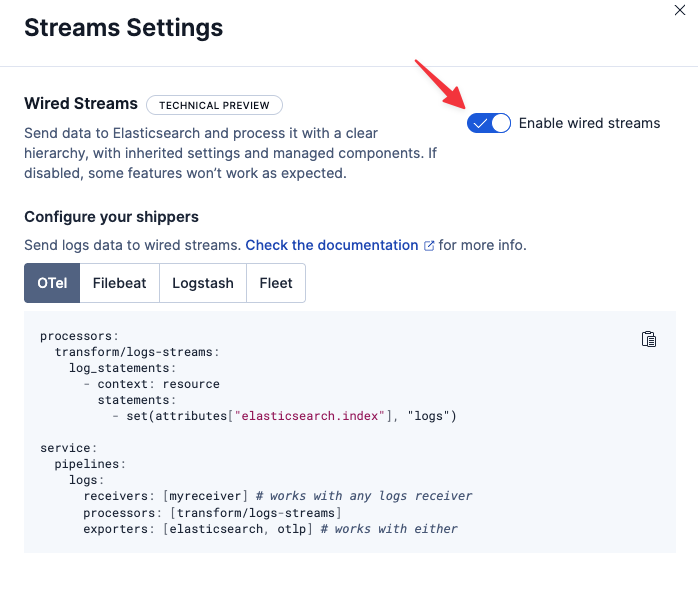
Streamsのメニューの右上にあるsettingsをクリックすると有効化のトグルがあります。
ログの準備とログの投入
今回使うログは、以下のGitHubから入手できるログを使用させていただきました。この中のOpenStackのログを使いました。
https://github.com/logpai/loghub
上記ログをElasticsearchにログ投入するにあたっては、以下の独自のPythonスクリプトを使っています。(ほとんど生成AIに作ってもらっています)
https://gist.github.com/nobuhikosekiya/ccb958e06200a5c07910a4af153c58b3
以下は実行時の出力例です。ログはlogsのData Streamに送っています。
python log_sender.py
🚀 Elastic Cloud Serverlessログ送信開始
エンドポイント: https://nobu-streams-test-b58b55.es.us-central1.gcp.cloud.es.io
Data Stream: logs
Data Stream使用: Yes
ログフォルダ: log_folder
ファイルパターン: *.log
📁 1個のファイルを処理します...
📄 処理中: log_folder/openstack_abnormal.log
/Users/nobuhikosekiya/lab/multi-project/streams-test-loghub/log_sender.py:145: DeprecationWarning: datetime.datetime.utcnow() is deprecated and scheduled for removal in a future version. Use timezone-aware objects to represent datetimes in UTC: datetime.datetime.now(datetime.UTC).
current_timestamp = datetime.utcnow().isoformat() + "Z"
✓ log_folder/openstack_abnormal.logから18434行読み込みました
✓ 18434件のログエントリを一括送信しました
📊 処理完了:
- 成功したファイル: 1/1
- 送信したログエントリ総数: 18434
✅ 処理完了
今回は検証としてバッチスクリプトでログをアップロードしますが、本来のStreamsは、Wired Streamsを有効化した設定画面に表示されるConfigure your shippersの設定を使い、エージェントを使って継続的にログをlogs Data Streamに投入して使っていきます。その状況の方がStreamsの設定をしたらすぐにその反映が新し口取り込まれるログで確認できてやりやすいです。
ログのパーティション設定
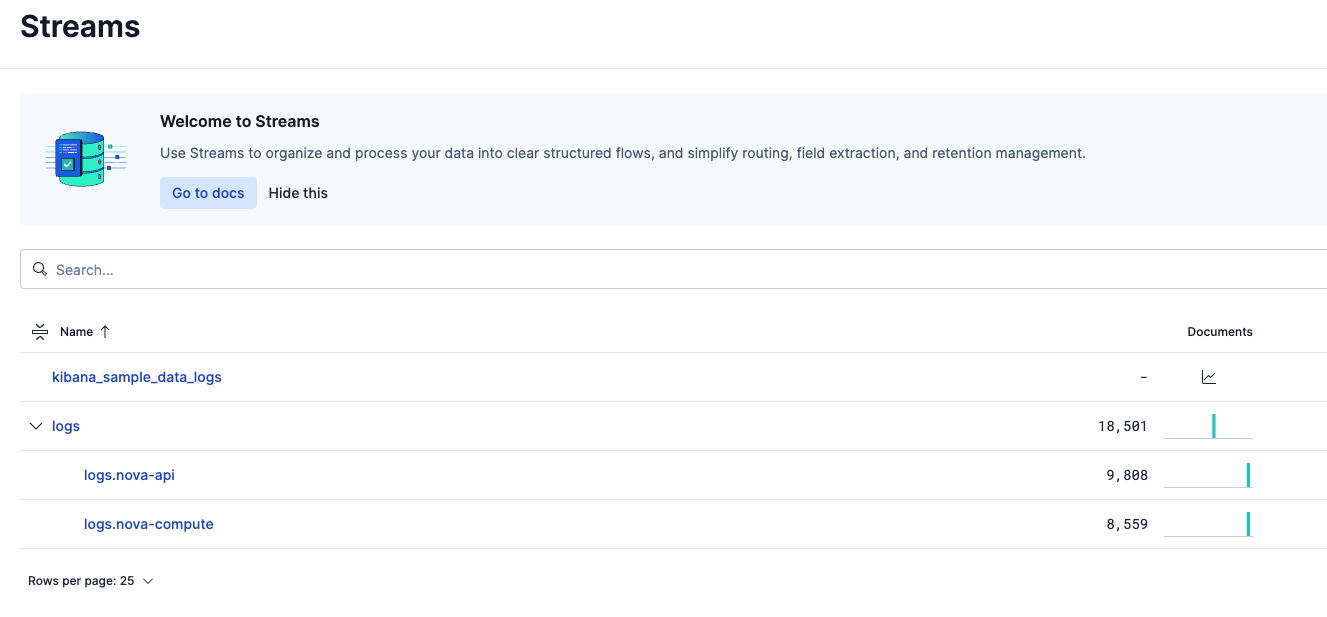
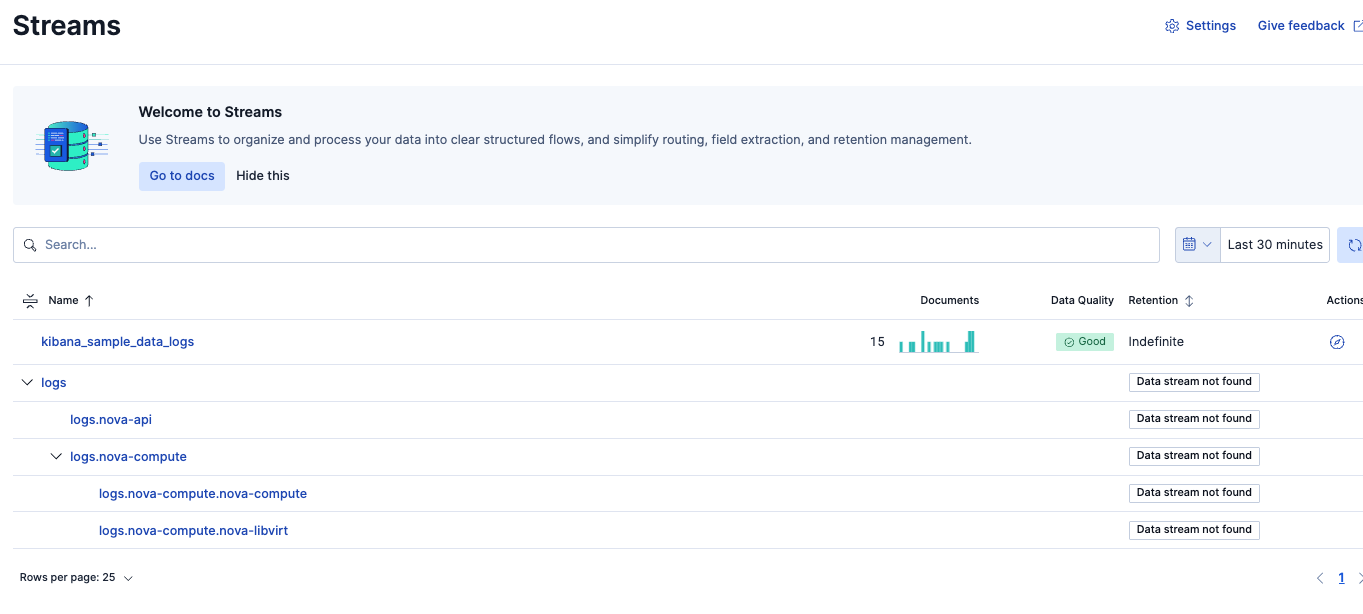
Streamsのlogsのページを開き、ログが入ってきていることを確認しました。
ログデータに含まれるタイムスタンプは2017年度のものですが、この時点ではログ投入の現在時刻がタイムスタンプとして認識されています。後のステップで2017年がタイムスタンプとして認識されるように設定を行います。
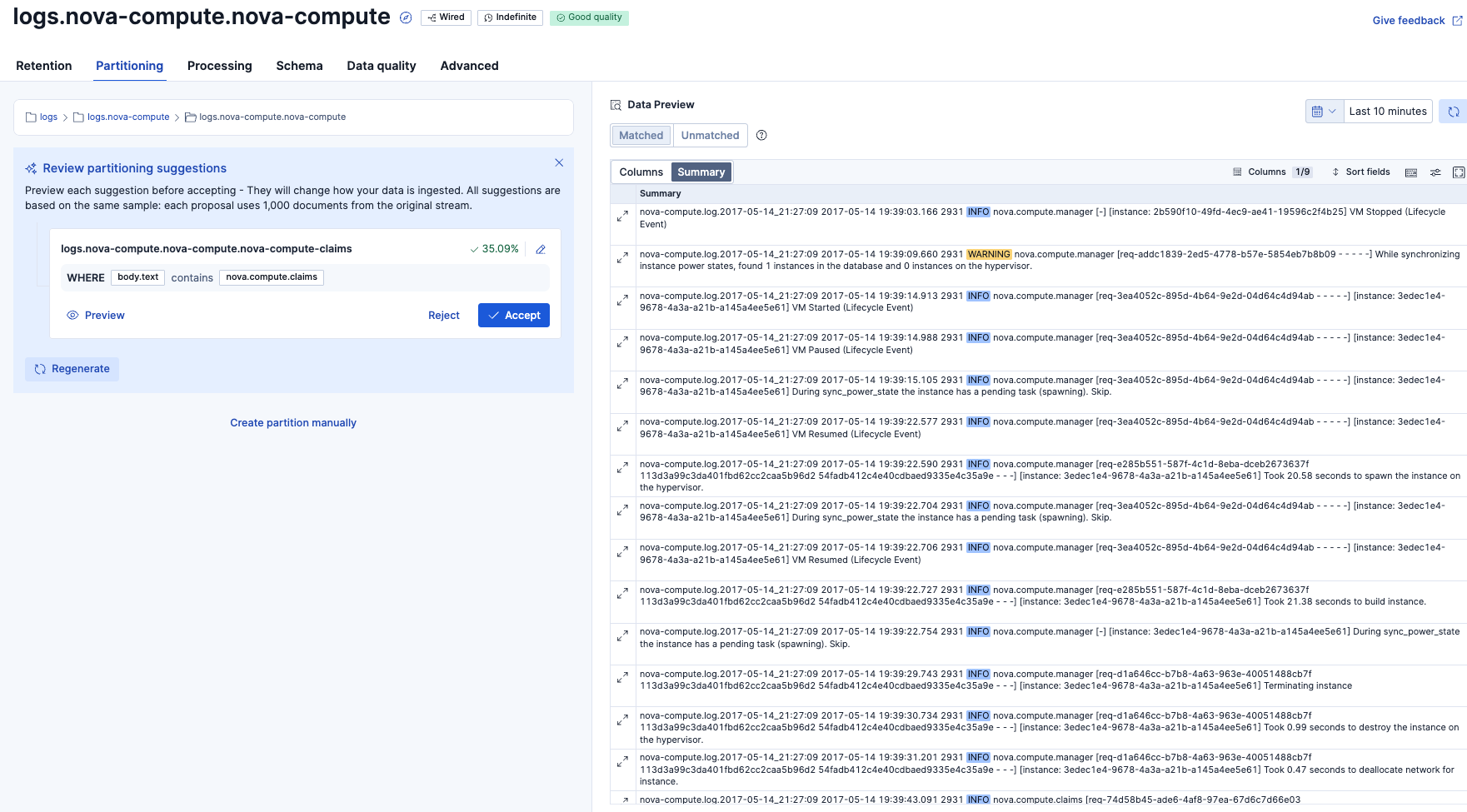
次にPartitioningタブを表示。Summary表示の状態です。
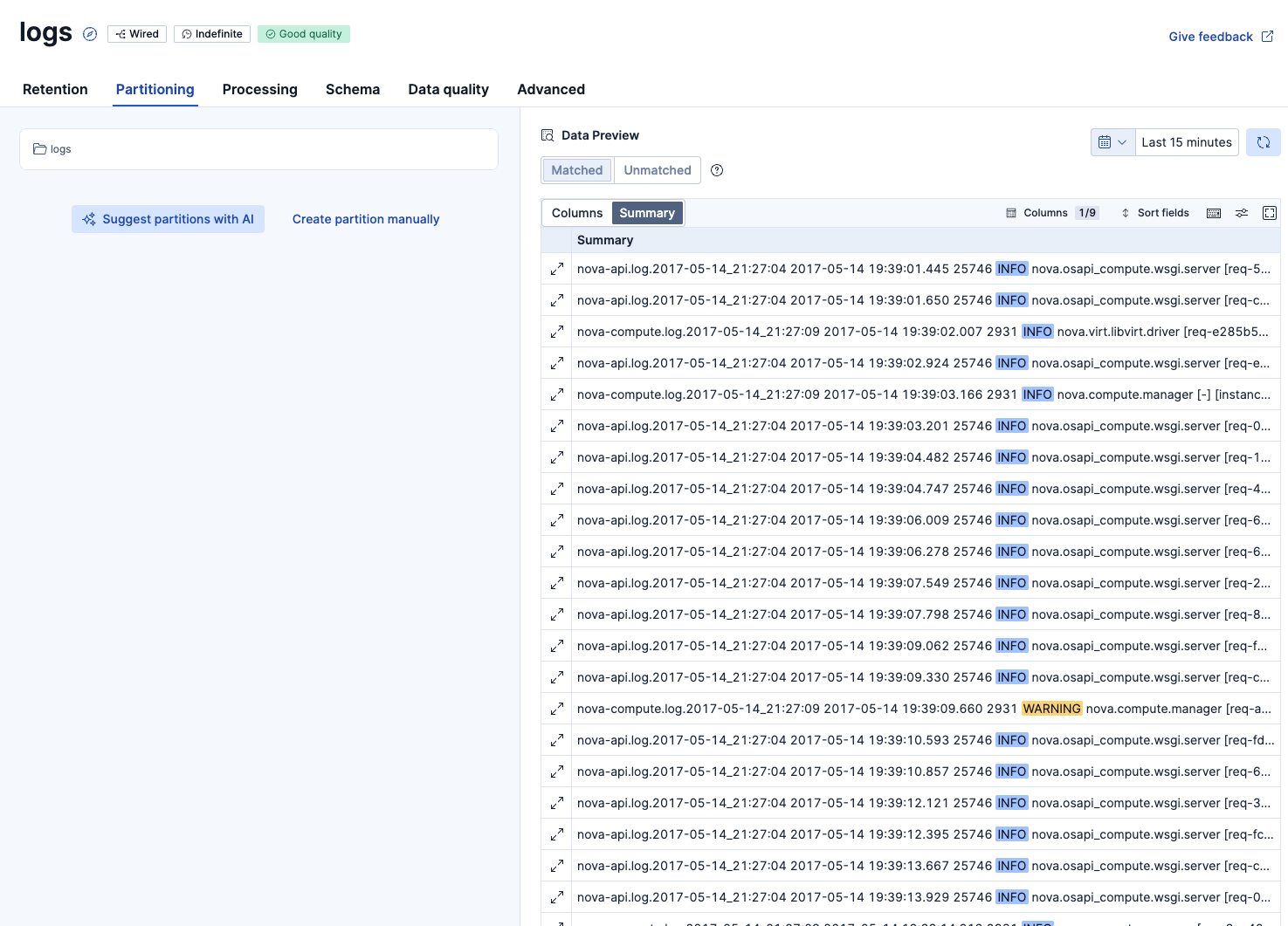
Columns別の表示にしました。最初はデータが見えにくかったので、右上の設定で表示を少し調整する必要がありました。取り込んだログ行はbody.textフィールドに入っていました。その他、いくつかログ取り込みの過程で追加されたと思われるメタデータのカラムがありました。
パーティションを実施するためにSuggest partitions with AI をクリックすると、このようなサジェストが出てきました。
ボタンを押すごとにサジェストが変わります。サジェストが気に入らなかったら、Regenerateボタンで別のサジェストをもらうことできます。
1回目:
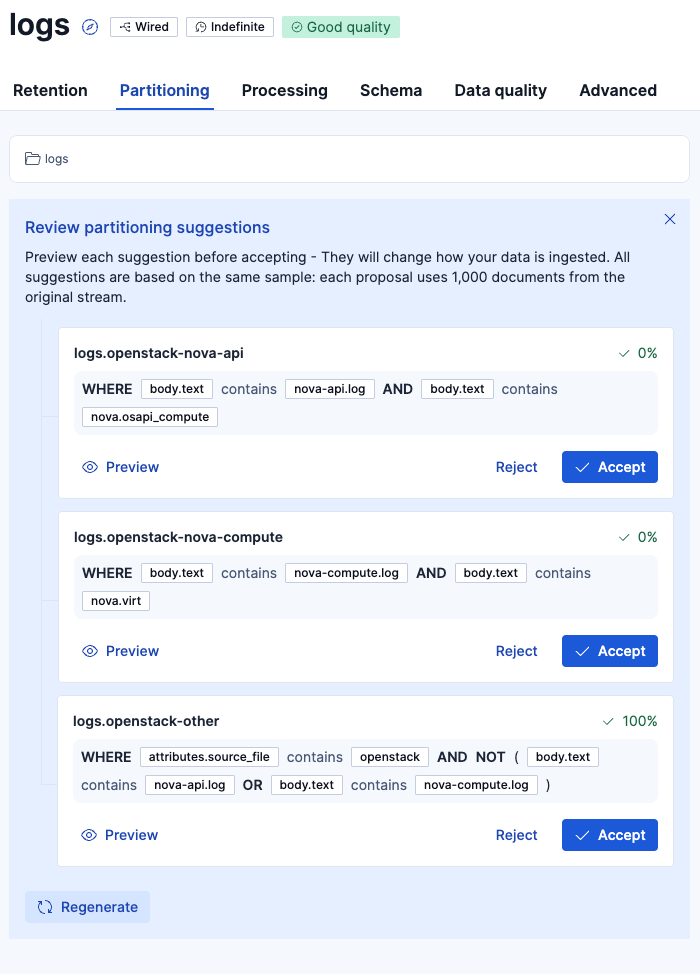
2回目:
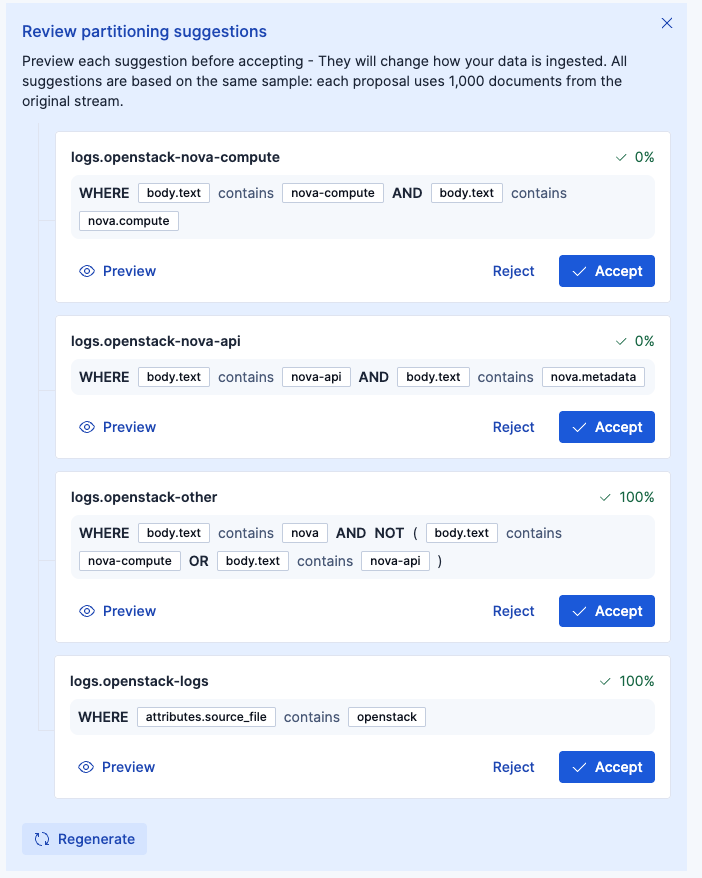
色々な提案が出てきて、どれが良いと思うかは人の判断が必要です。Wired Streamsをとりあえず練習するような場合は、適当にサジェストを受け入れて進めてみても良いですが、今回はパーティションの設計を頭に入れながらやっていくとどんな感じかをやっていきます。
今回アップしたログは以下のような形式のログでした。ログの頭にnova-api.logとnova-compute.logと2つのタイプのログが存在しています。まずはこの2つで分けるのが良さそうです。
nova-api.log.2017-05-14_21:27:04 2017-05-14 19:39:01.445 25746 INFO nova.osapi_compute.wsgi.server [req-5a2050e7-b381-4ae9-92d2-8b08e9f9f4c0 113d3a99c3da401fbd62cc2caa5b96d2 54fadb412c4e40cdbaed9335e4c35a9e - - -] 10.11.10.1 "GET /v2/54fadb412c4e40cdbaed9335e4c35a9e/servers/detail HTTP/1.1" status: 200 len: 1583 time: 0.1919448
nova-api.log.2017-05-14_21:27:04 2017-05-14 19:39:01.650 25746 INFO nova.osapi_compute.wsgi.server [req-c26a7d54-55ab-412e-947f-421a2cb934fc 113d3a99c3da401fbd62cc2caa5b96d2 54fadb412c4e40cdbaed9335e4c35a9e - - -] 10.11.10.1 "GET /v2/54fadb412c4e40cdbaed9335e4c35a9e/servers/3edec1e4-9678-4a3a-a21b-a145a4ee5e61 HTTP/1.1" status: 200 len: 1708 time: 0.2011580
nova-compute.log.2017-05-14_21:27:09 2017-05-14 19:39:02.007 2931 INFO nova.virt.libvirt.driver [req-e285b551-587f-4c1d-8eba-dceb2673637f 113d3a99c3da401fbd62cc2caa5b96d2 54fadb412c4e40cdbaed9335e4c35a9e - - -] [instance: 3edec1e4-9678-4a3a-a21b-a145a4ee5e61] Creating image
nova-api.log.2017-05-14_21:27:04 2017-05-14 19:39:02.924 25746 INFO nova.osapi_compute.wsgi.server [req-eb681812-78ae-4a9f-9e2a-96e505285512 113d3a99c3da401fbd62cc2caa5b96d2 54fadb412c4e40cdbaed9335e4c35a9e - - -] 10.11.10.1 "GET /v2/54fadb412c4e40cdbaed9335e4c35a9e/servers/detail HTTP/1.1" status: 200 len: 1759 time: 0.2698390
nova-compute.log.2017-05-14_21:27:09 2017-05-14 19:39:03.166 2931 INFO nova.compute.manager [-] [instance: 2b590f10-49fd-4ec9-ae41-19596c2f4b25] VM Stopped (Lifecycle Event)
以下のようなサジェストに対して、さらに鉛筆マークのアイコンから追加の編集を行いました。
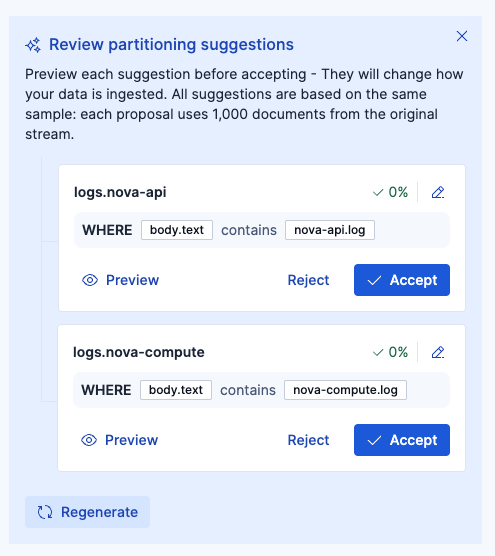
編集:contains -> starts withに変更。このようにAIサジェストをベースに使いつつ、仕上げは手動で調整可能です。
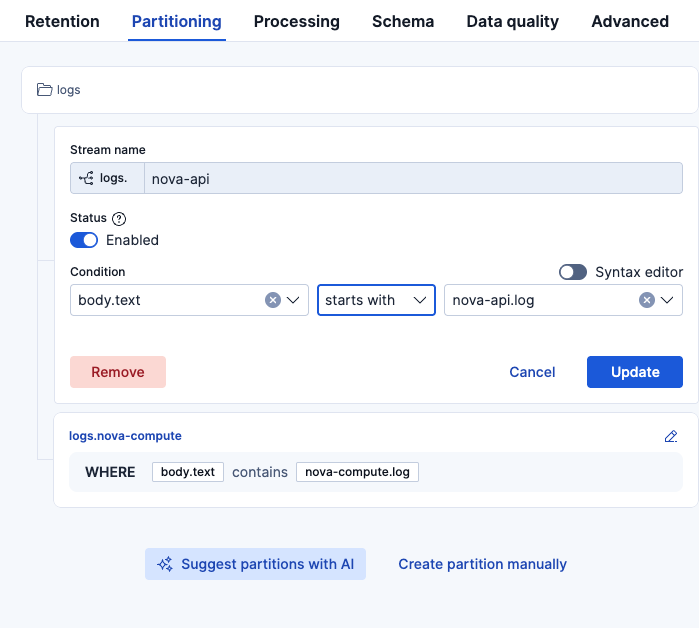
これでパーティションの設定を完了させましたが、即時ではパーティションが反映されませんでした。パーティションはあくまで今後入ってくるログに対しての設定であり、既に取り込まれたログをパーティションするものではないことに注意です。
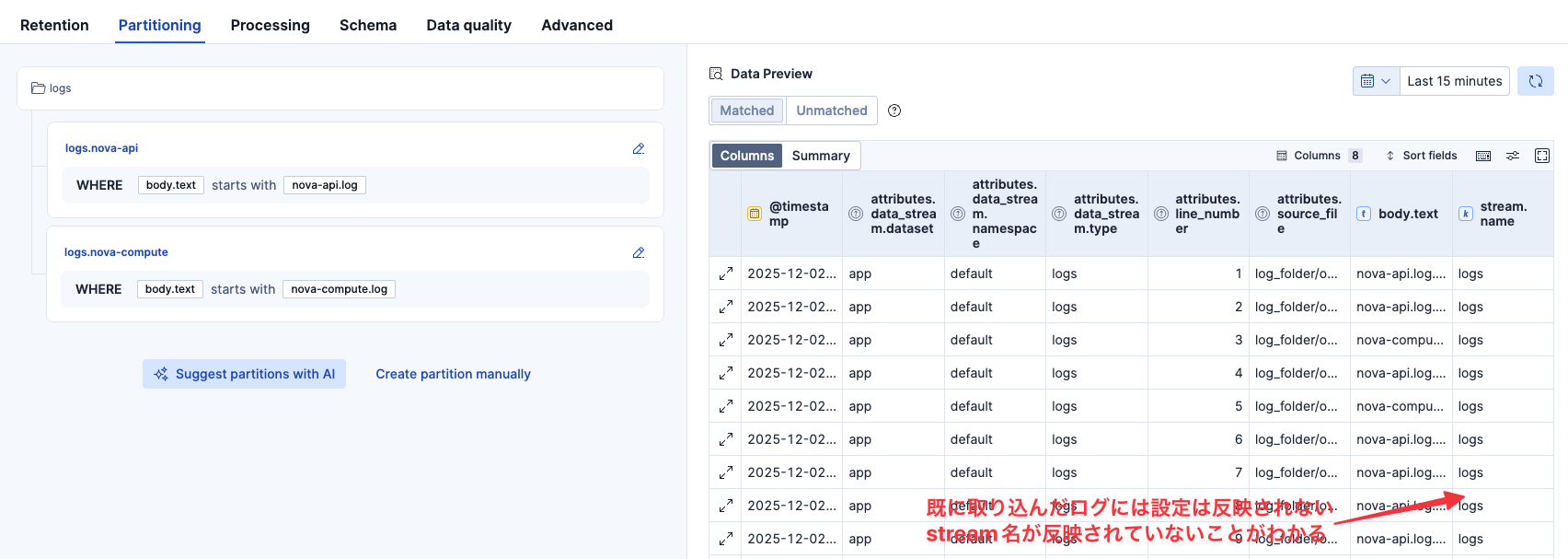
パーティション設定の反映を確認するために、もう一度同じログを取り込みます。
📊 処理完了:
- 成功したファイル: 1/1
- 送信したログエントリ総数: 18434
以下の画面から、1回目の取り込みはlogsに行き、2回目はさっきの2つのパーティション2つのいずれかに分けられたことがこれでわかりました。
さらに階層の子パーティションの作成
作ったパーティションは、どんどん階層化してさらにパーティションすることもできます。
さきほどのパーティション設定で新たに作られたlogs.nova-apiのデータを確認してみます。
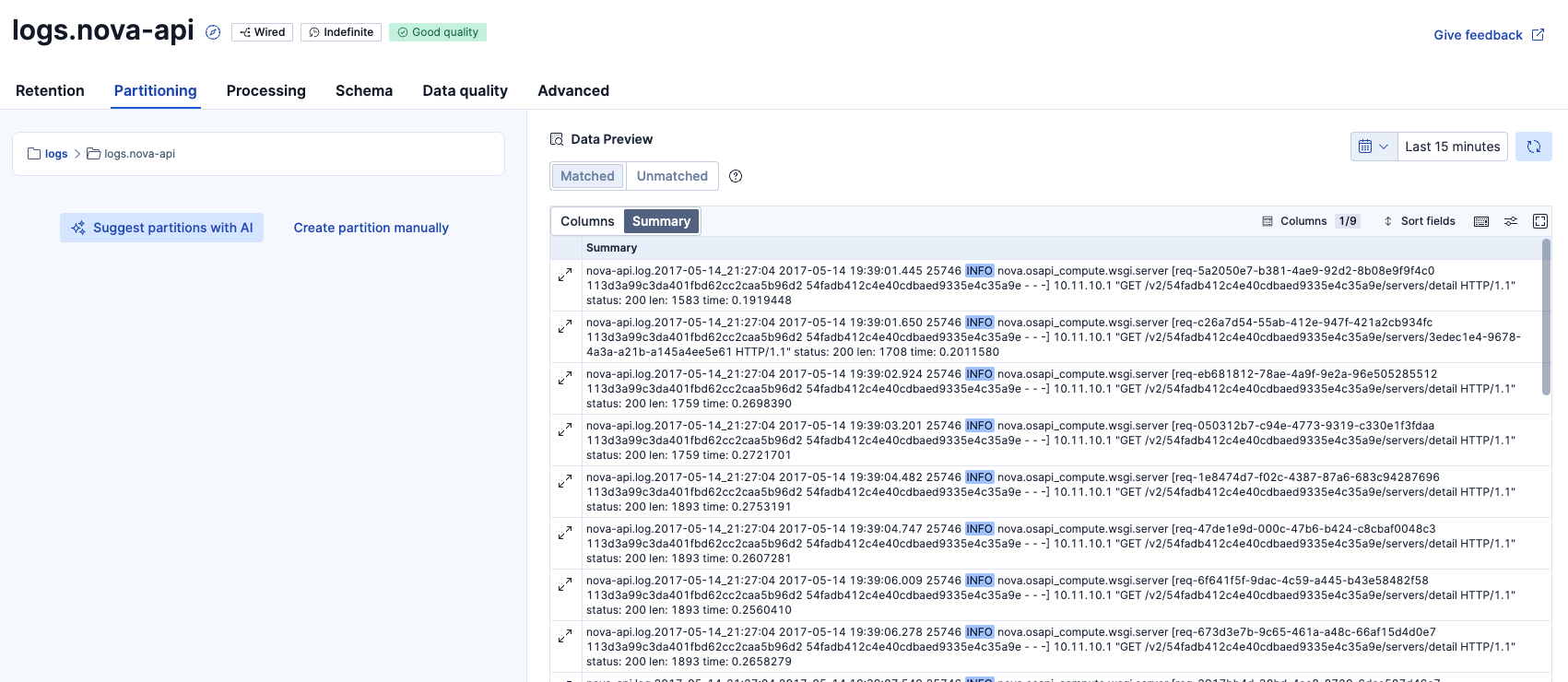
同じようなログフォーマットのデータで揃っていそうです。これ以上パーティションが必要かわかりませんが、何回かAIからサジェストをもらってみましょう。
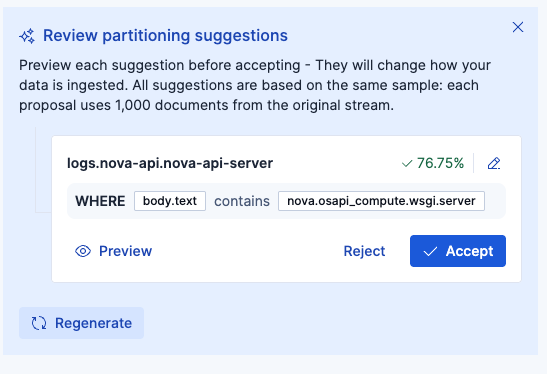
1回目:
2回目:
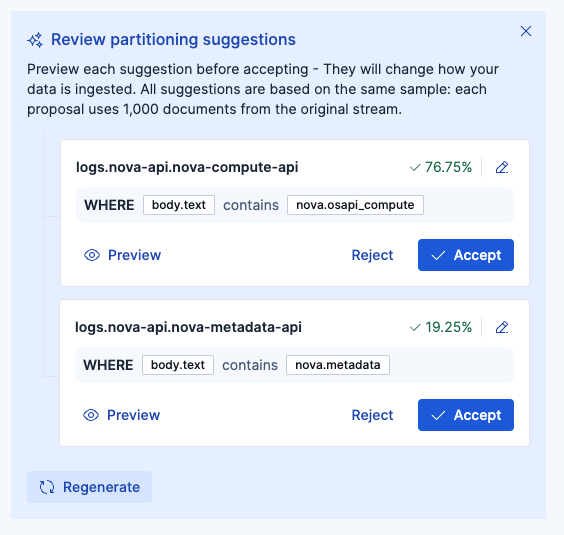
結局、logs.nova-apiログも同じフォーマットですし、これ以上はパーティション不要と判断しました。

次にlogs.nova-computeの方をパーティションする余地があるかみてみます。
ログはこのようなログです。
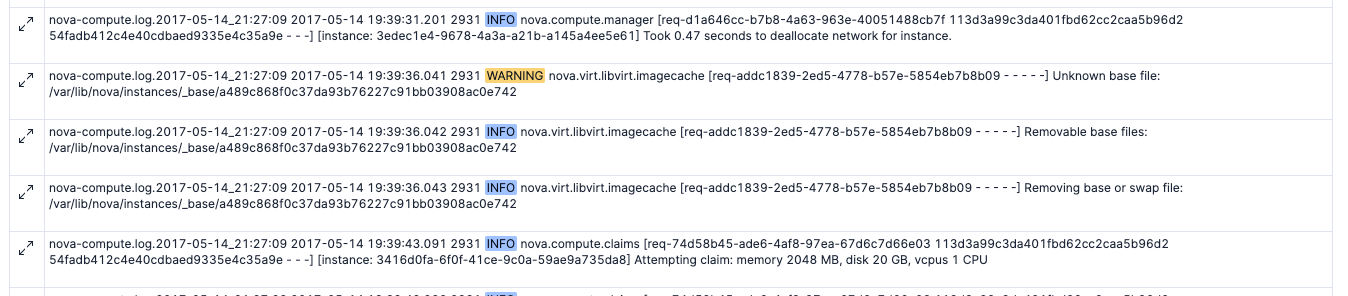
AIによるサジェストはこのような感じでした。
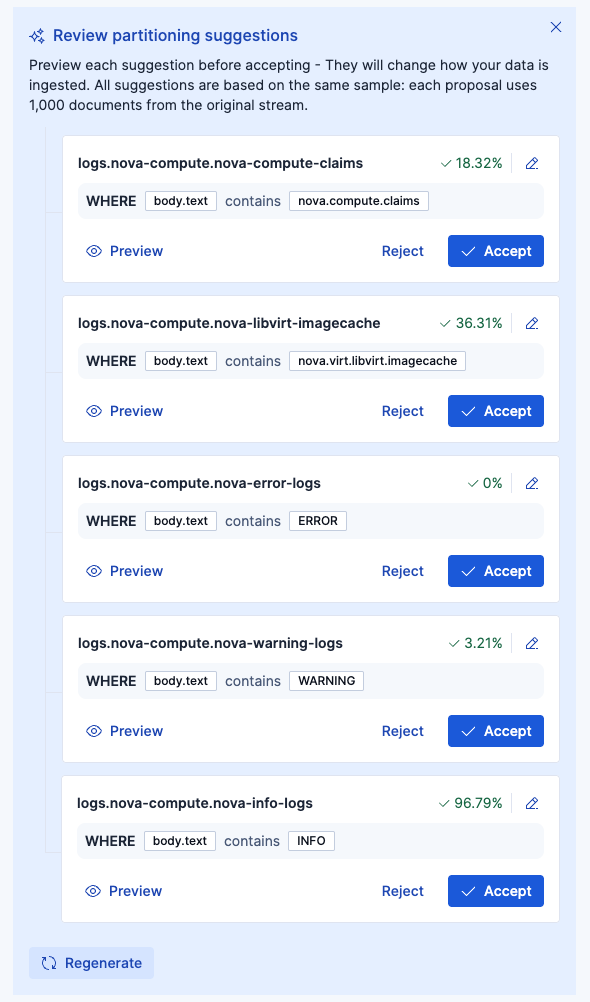
最終的には、以下の2つのパーティションに分けるように編集してからAcceptしました。
もう一度ログを取り込みます
📊 処理完了:
- 成功したファイル: 1/1
- 送信したログエントリ総数: 18434
意図通り、logs.nova-apiとlogs.nova-compute.nova-computeとlogs.nova-compute.nova-libvirtに分けられて取り込まれました。
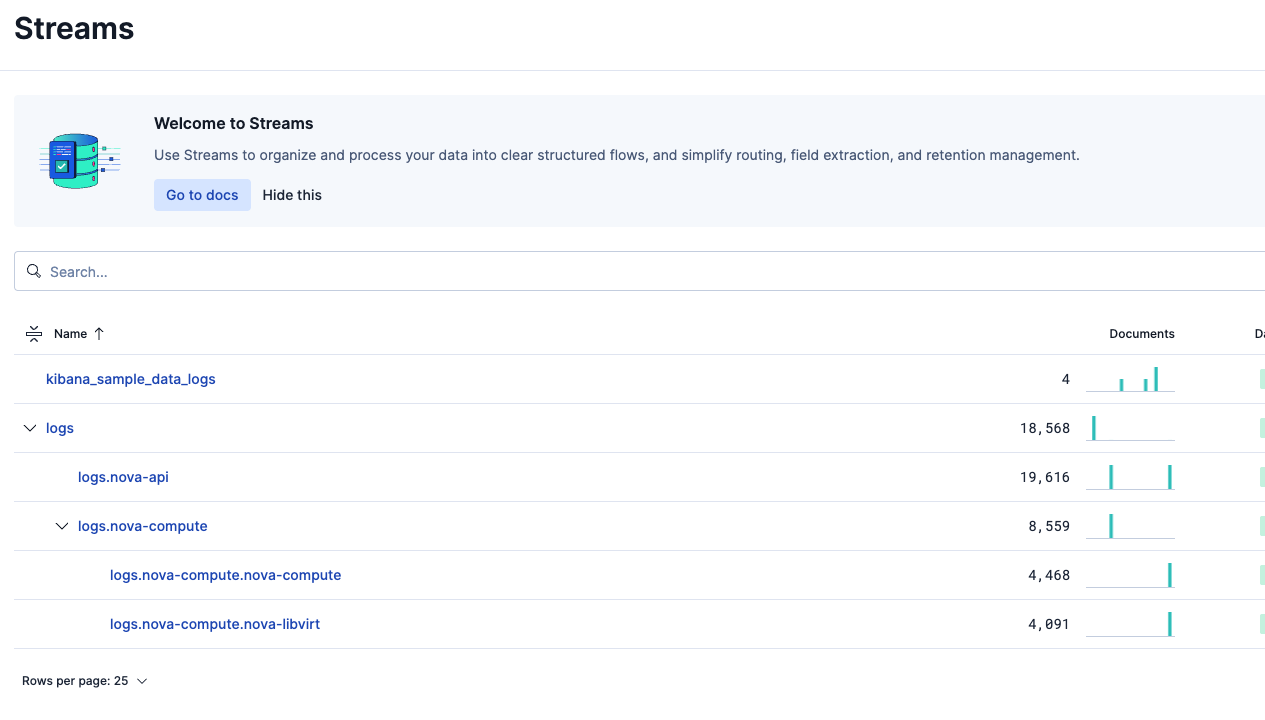
どのような単位でパーティションを作るかは疑問に思うところです。
現在公式ドキュメントには以下の通り書いてあります。和訳した物を記します。
https://www.elastic.co/docs/solutions/observability/streams/management/partitioning
パーティショニングの推奨事項
複数のシステムが 1 つの親ストリームにログを送信する場合、パーティショニングはデータ管理に役立ちます。
チームや関連する技術など、論理的なグルーピングに注目してください。
たとえば、Web サーバのログを 1 つのストリームに、カスタムアプリケーションのログを別のストリームに分けます。高カーディナリティのフィールドでパーティションを分けることは避けてください。
一般的な service.name のようなフィールドでも、管理が難しいほど多くのパーティションが作成される可能性があります。一般的なルールとしては、数百ではなく「数十」程度を目指してください。
各パーティションにはコストがかかり、内部的には Elasticsearch のデータストリームが作成されます。数多く作成できますが、無制限というわけではありません。パーティショニングが必要になるケース
データの一部だけ、他と異なるライフサイクルを適用したい場合にのみ、パーティショニングが必要です。
例えば、ノイズの多いファイアウォールと、静かなカスタムアプリケーションが同じストリームにログを送信している場合、ファイアウォールのログは長期間保持する必要がなく、ディスクを消費します。
このケースではストリームを分割し、各子ストリームに異なる ILM ポリシーや保持設定を割り当てることができます。logs - logs.firewall [7d] - logs.custom-app [30d]
ProcessingでのGrokパース設定
パーティションの後は、Processingでログのパースなどの処理を実装していきます。
logs.nova-apiのStreamを開き、Processingタブをクリックします。
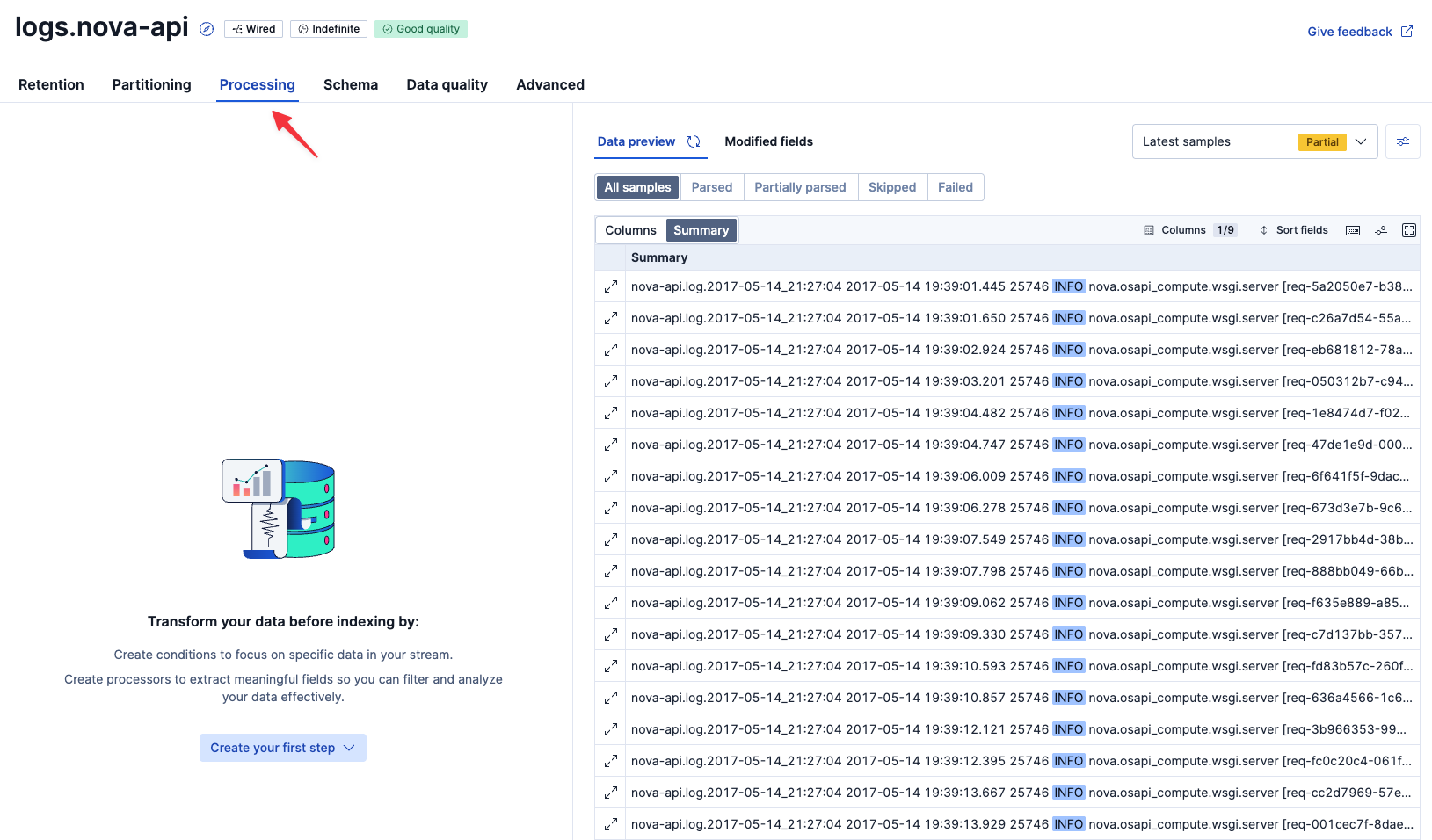
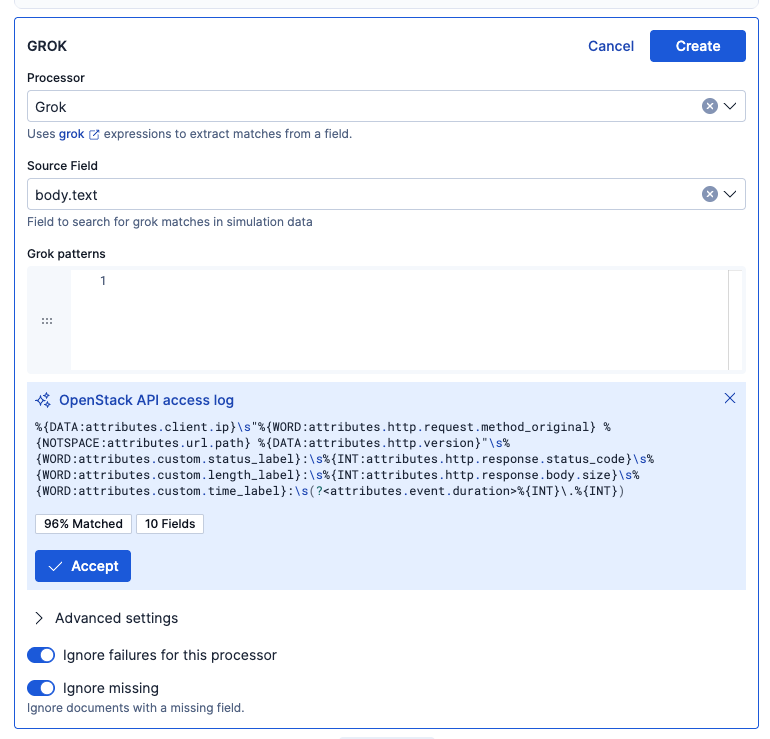
Grokとbody.textを選択し、Generate patternでAIにGrokパターンをサジェストしてもらいます。
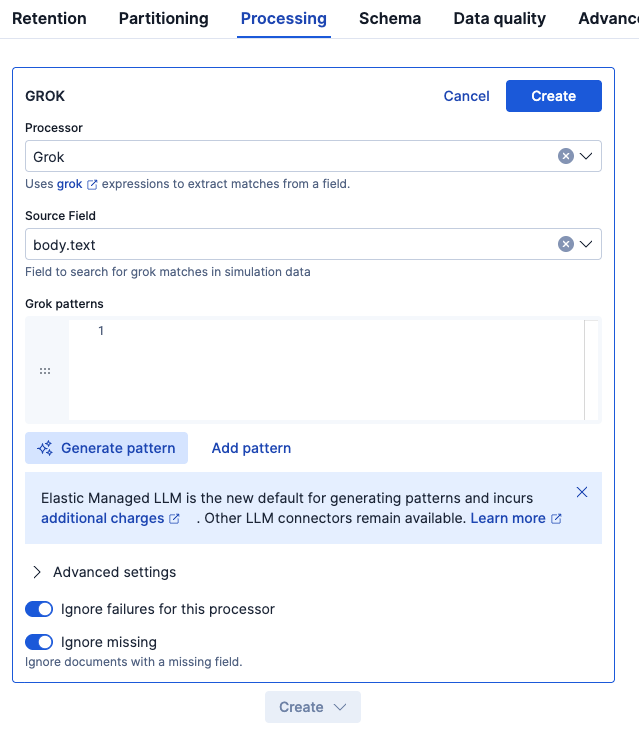
サジェスト結果の例です。
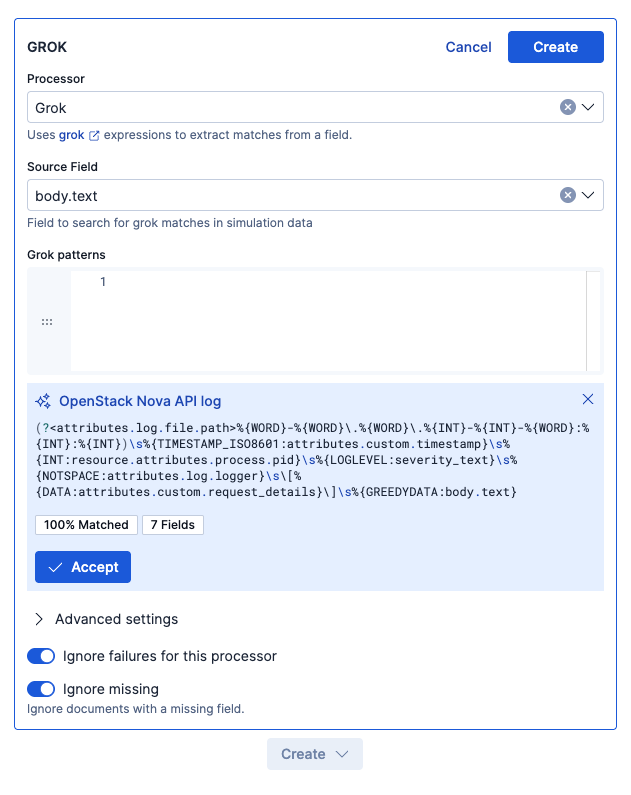
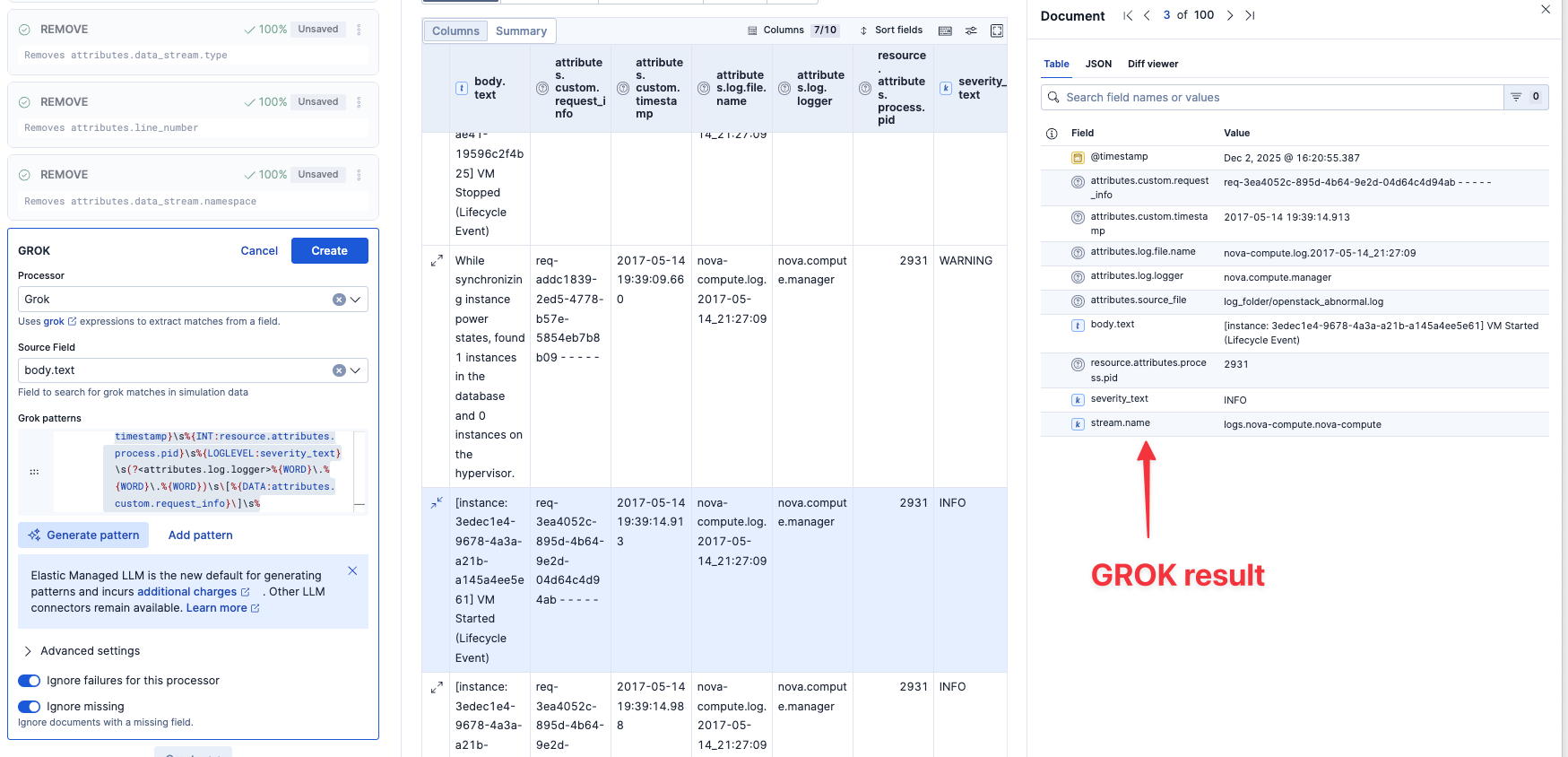
AIのサジェストをAcceptすると、Grok patterns欄に追加され、右のData previewにも即時反映されました。これでGROKパースの結果が確認できます。
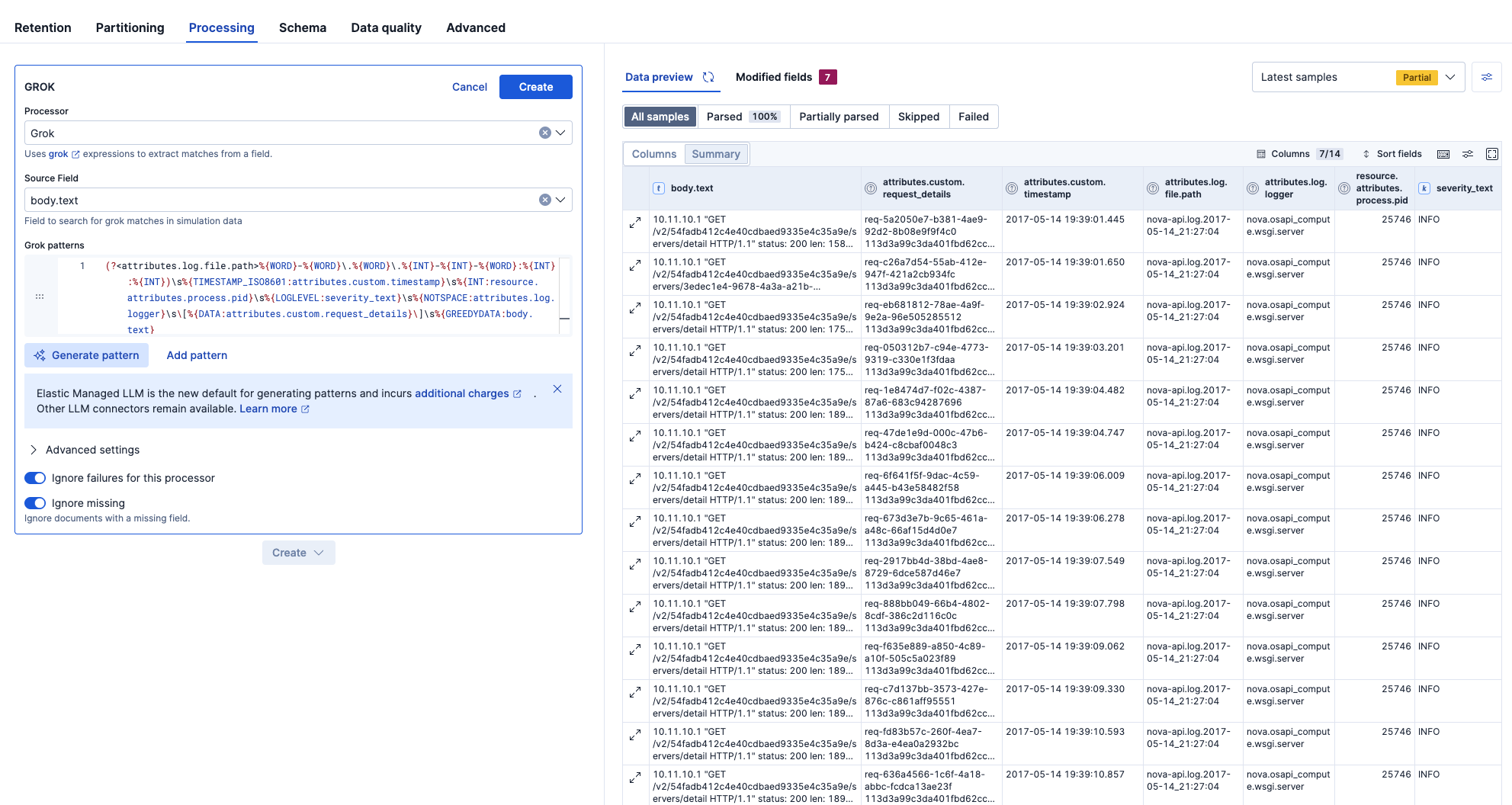
今回採用したGROKパターンを記しておきます。
(?<attributes.log.file.path>%{WORD}-%{WORD}\.%{WORD}\.%{INT}-%{INT}-%{WORD}:%{INT}:%{INT})\s%{TIMESTAMP_ISO8601:attributes.custom.timestamp}\s%{INT:resource.attributes.process.pid}\s%{LOGLEVEL:severity_text}\s%{NOTSPACE:attributes.log.logger}\s\[%{DATA:attributes.custom.request_details}\]\s%{GREEDYDATA:body.text}
Grokの結果が気に入らない場合はCancel、OKの場合はCreateを押します。今回はこれでCreateします。
次に、追加されて余計なフィールドは除去したいので、REMOVEをそこに適用しました。(残しておいても問題はないのですが、すっきりと見せたかったので..)
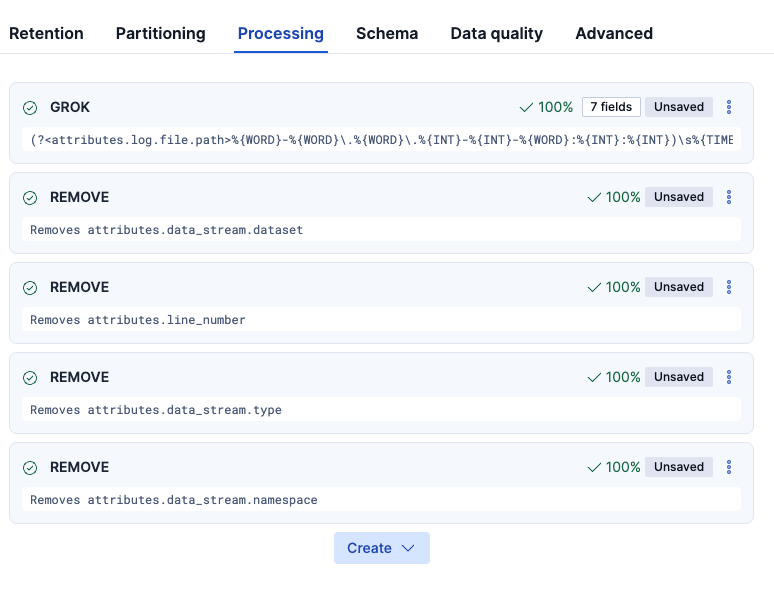
body.textの中身はさらにフィールド分けられるので、追加のGROKを作ります。つまり、Grokは任意に何段階かに分けて設定することもできます。
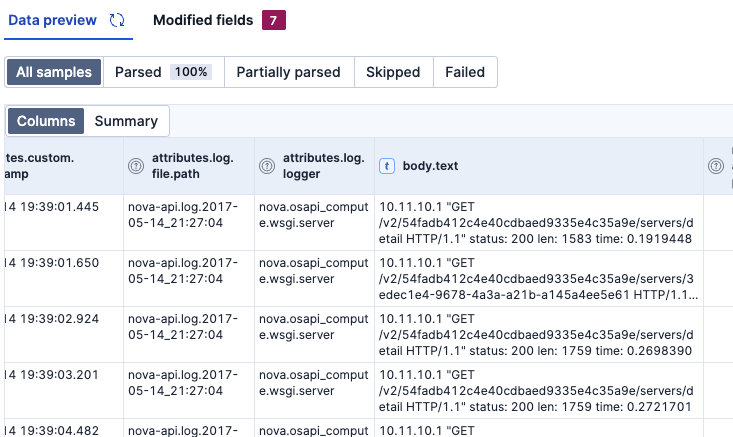
AIのサジェストのGROKをAcceptするとこういう感じになりました。GROKのパース具合がわかりやすいです。
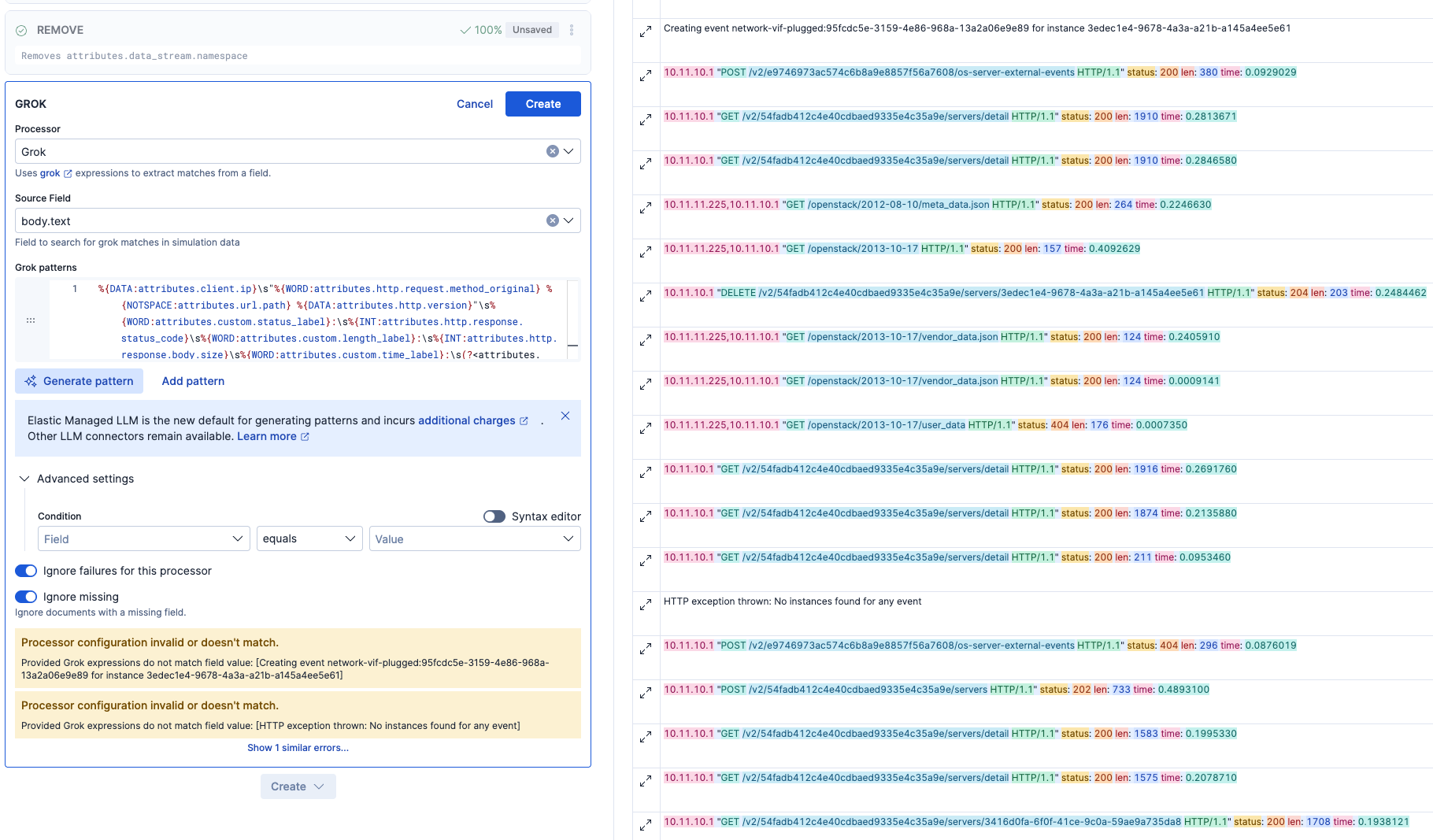
ここで調整します。len、time,statusのラベルは残す必要ないので、そこは取り込まないようにするために以下のように変更しました。
変更前
%{DATA:attributes.http.version}"\s%{WORD:attributes.custom.status_label}:\s%{INT:attributes.http.response.status_code}\s
変更後
%{DATA:attributes.http.version}"\sstatus:\s%{INT:attributes.http.response.status_code}\s
この段階では下のようになりました。body.textの内容がパースされ、attributes.client.ipやattributes.http.request.method_originalといったフィールドが追加されました。
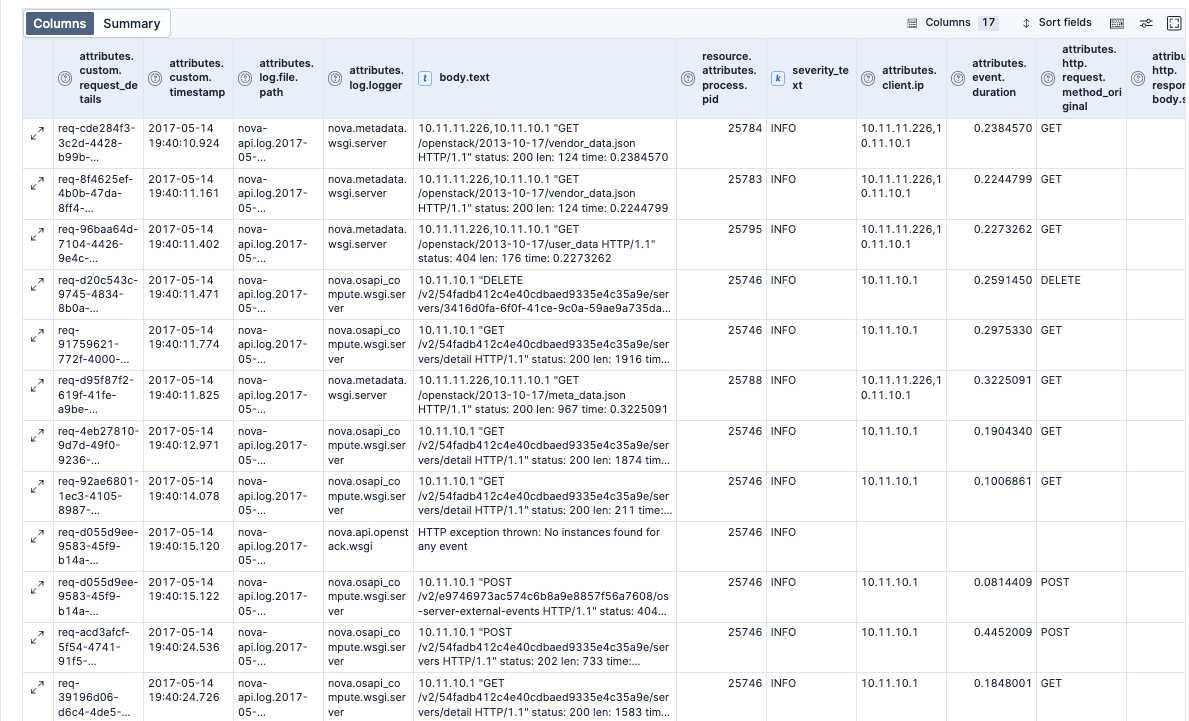
うまくパースされたログに関しては、body.textは不要なのでREMOVEすることにしてみました。ただし、数行パースがうまくいっていない行もあったので、このようにconditionsをつけて、パースされた行だけから除去しています。
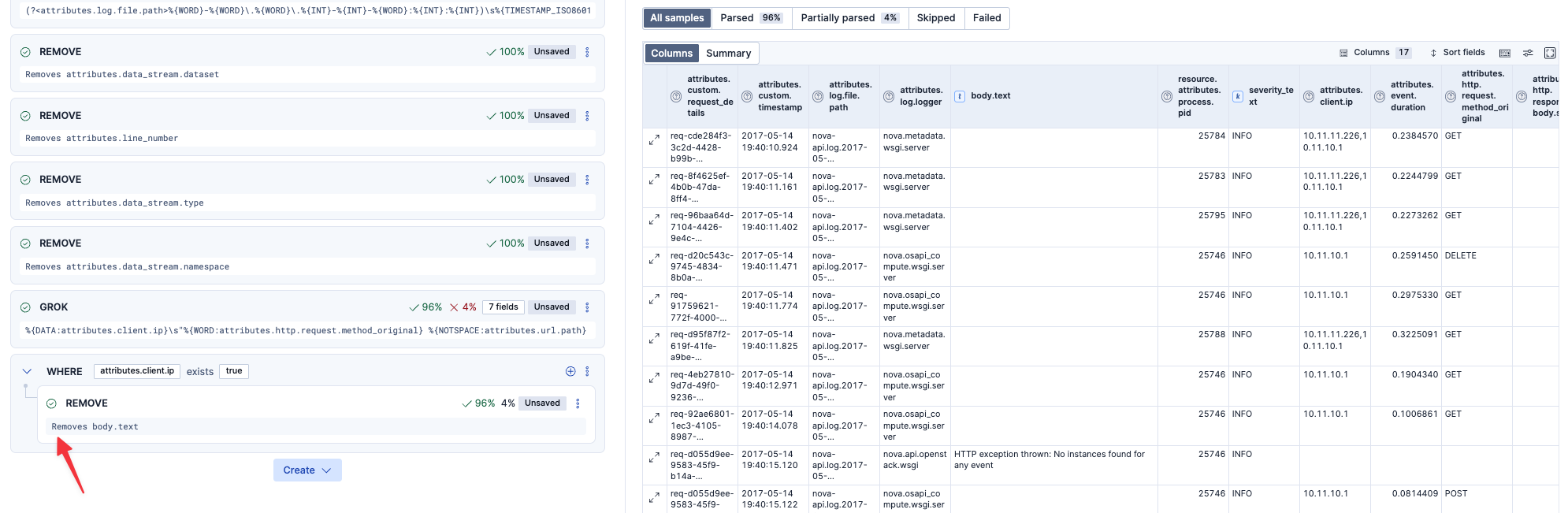
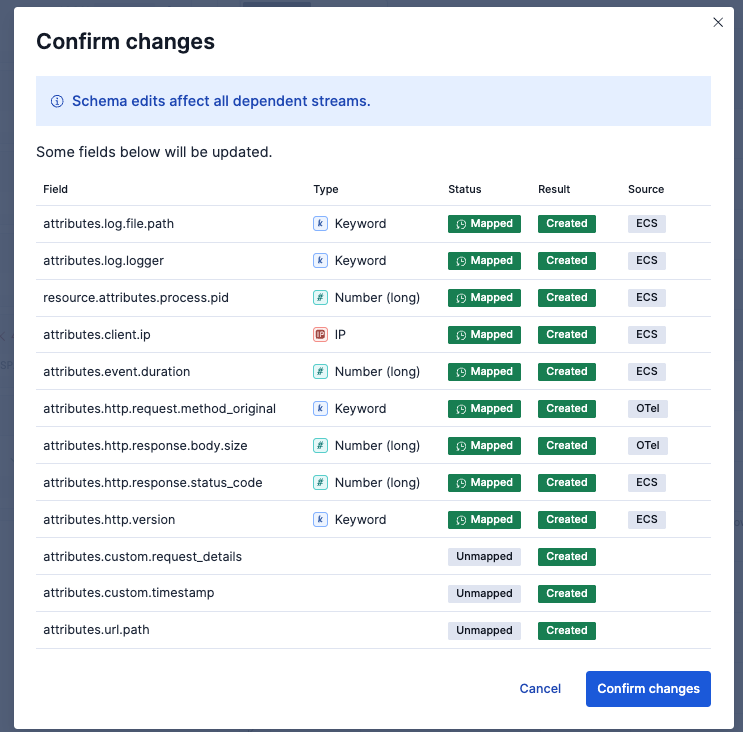
これで一旦Save changesします。
Data quality - Poor qualityデータの検知
再度ログを取り込みます。
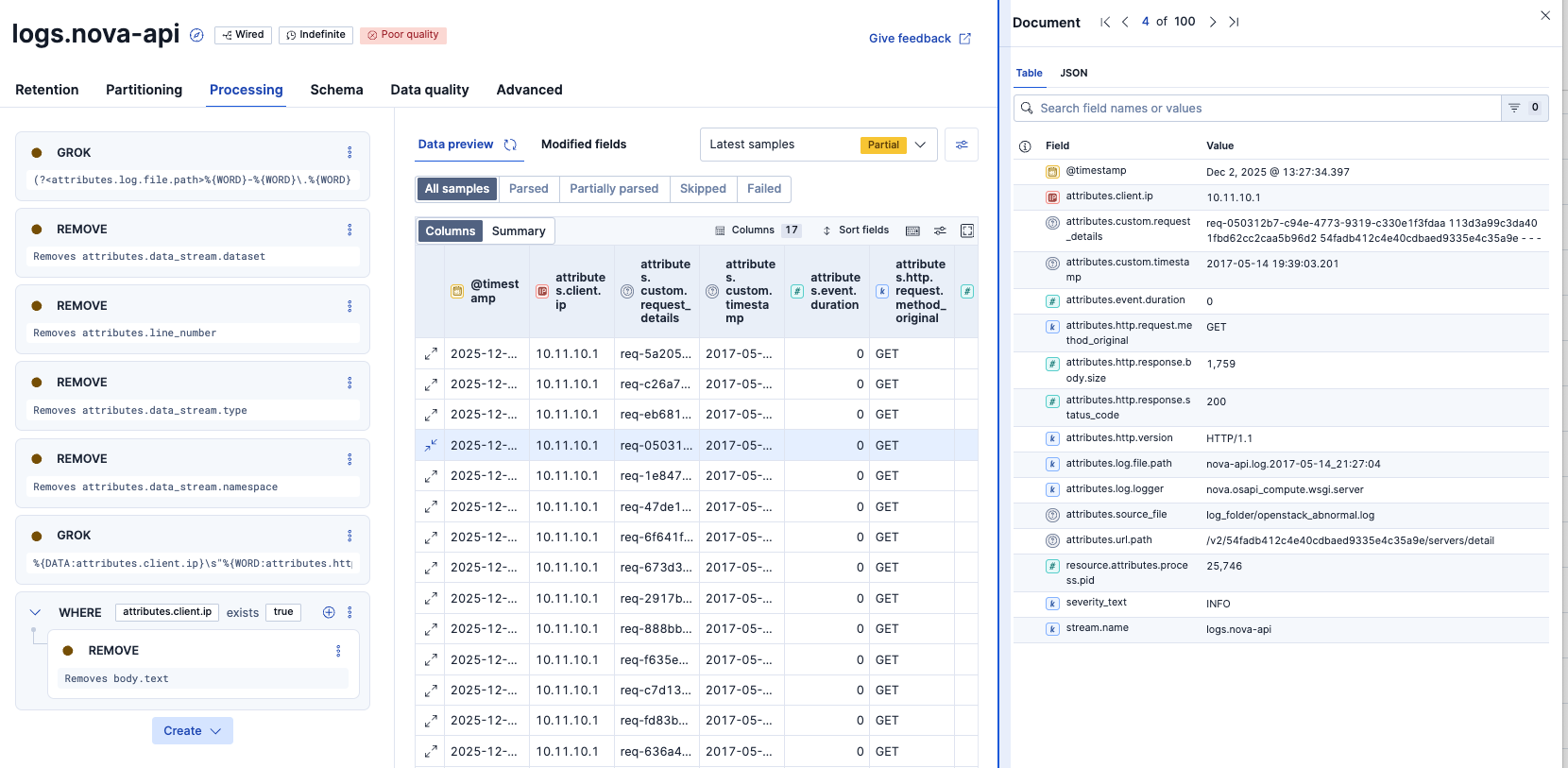
すると、Poor qualityの赤マークが出ていました。
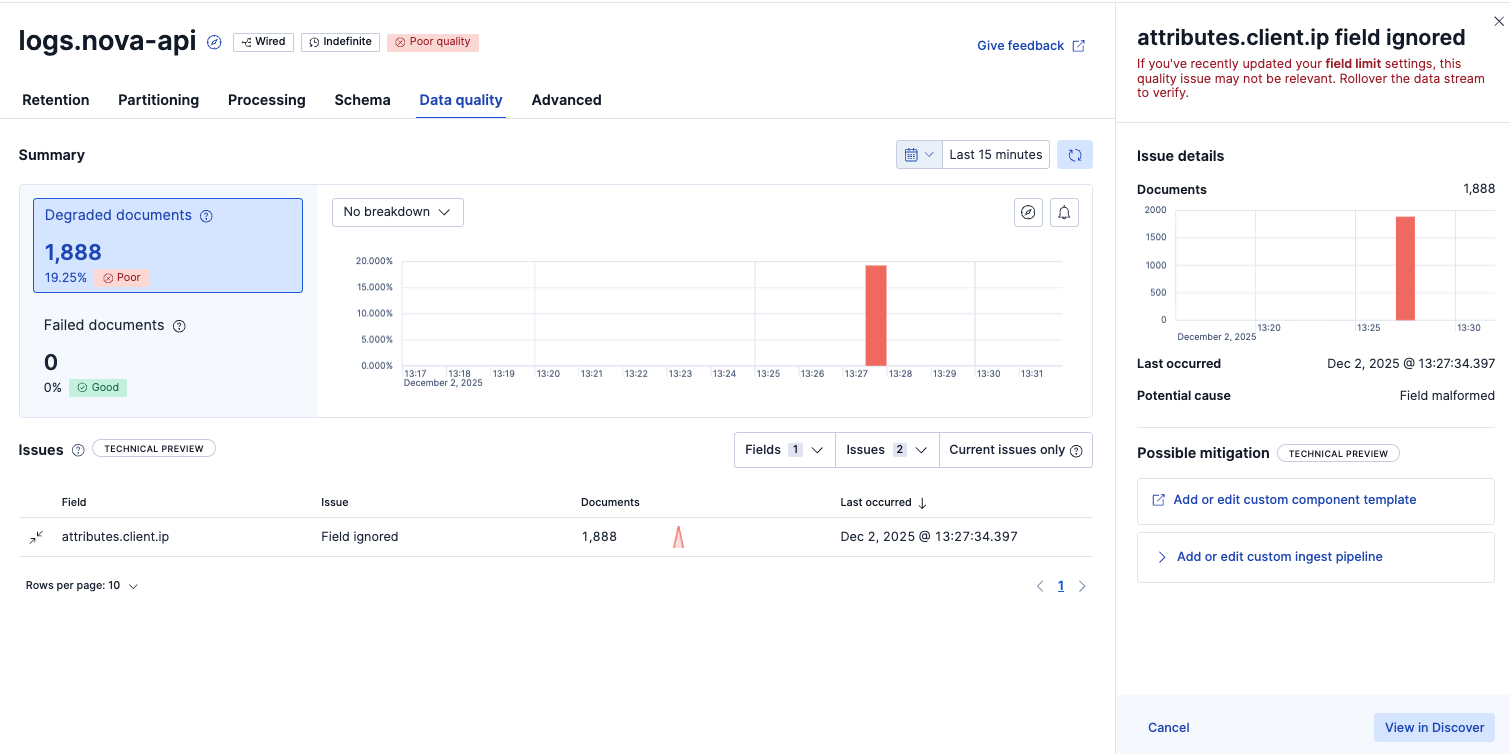
Poor qualityのView in Discoverをクリックすると対象のデータが確認できました。IPアドレスがカンマ区切りで複数あるログが問題でした。このようにデータ型が想定されたデータではない場合、Poor qualityとして検知できます。
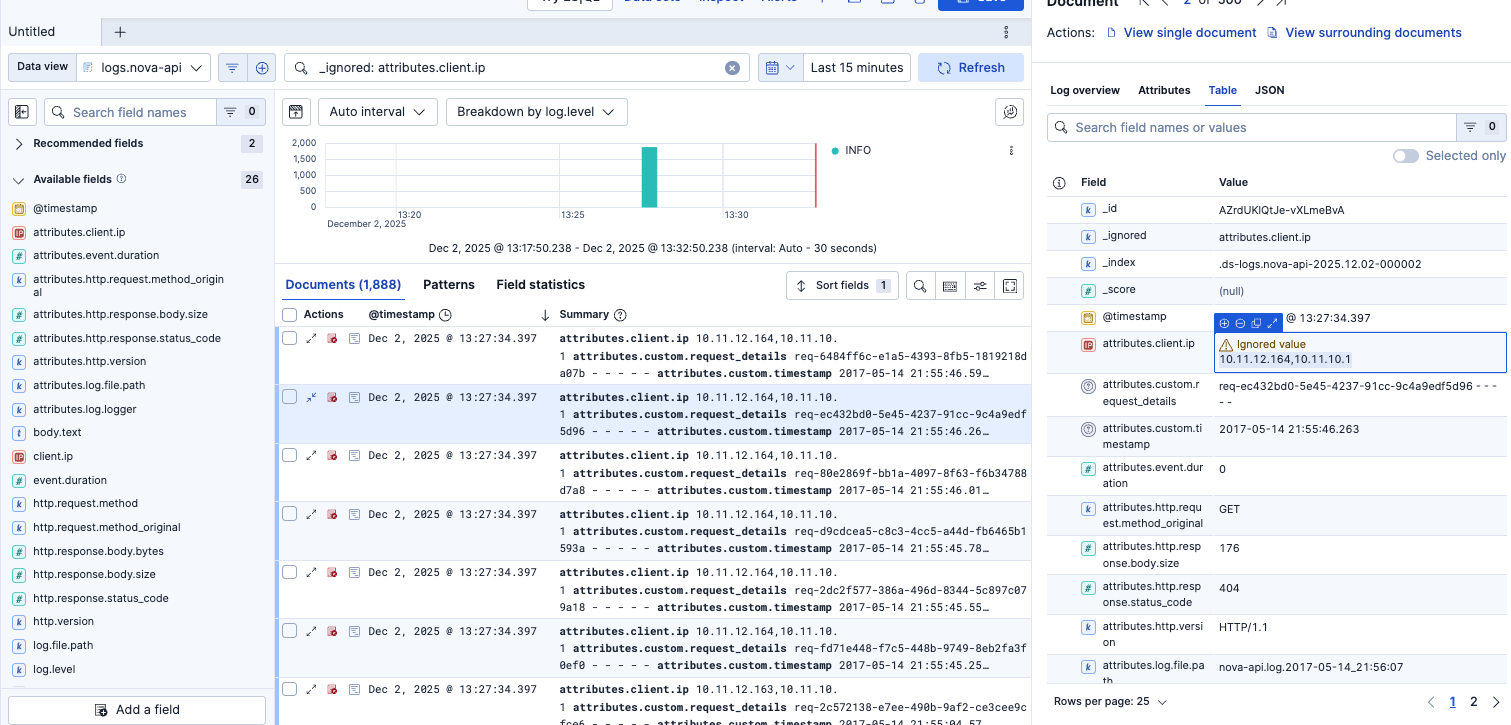
最善ではないかもしれませんが一旦textタイプとして扱われるように、別のフィールド名attributes.client.ip_strとしました。(attributes.client.ip.strとすると後のフィールタイプの設定でエラーしまたので、_を採用)
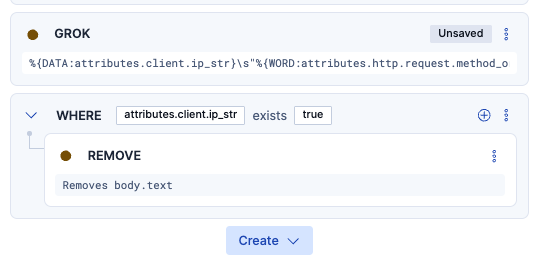
ここまで設定した上でログを取り込むとこのようになっています。
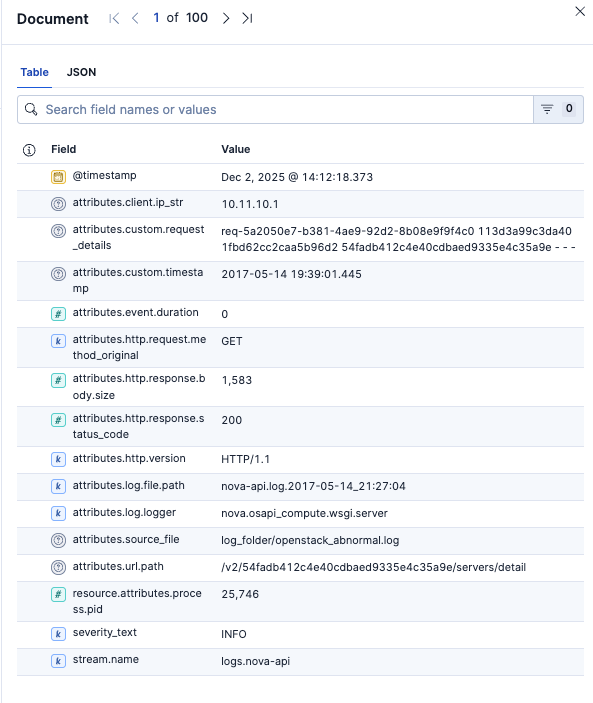
Schema - データ型の設定
さらに以下のことを行なっていきます。
- mappingのタイプが不明なものを設定
- attirbutes.custom.timestampを@timesampのフィールドに移行する(現在@timestampはログ投入時にフィールドとなっているので、ログに記録されたタイムスタンプとなるようにしたい)
timestampはフォーマット指定が必要でした。
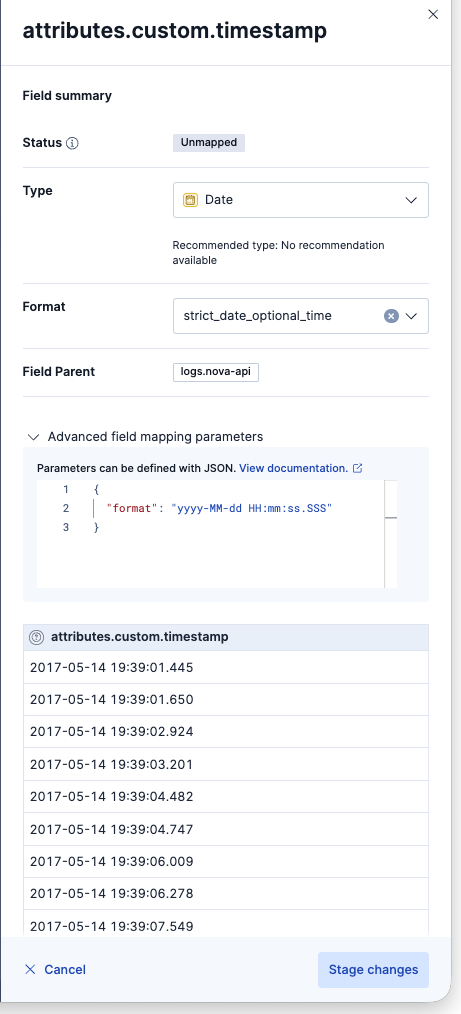
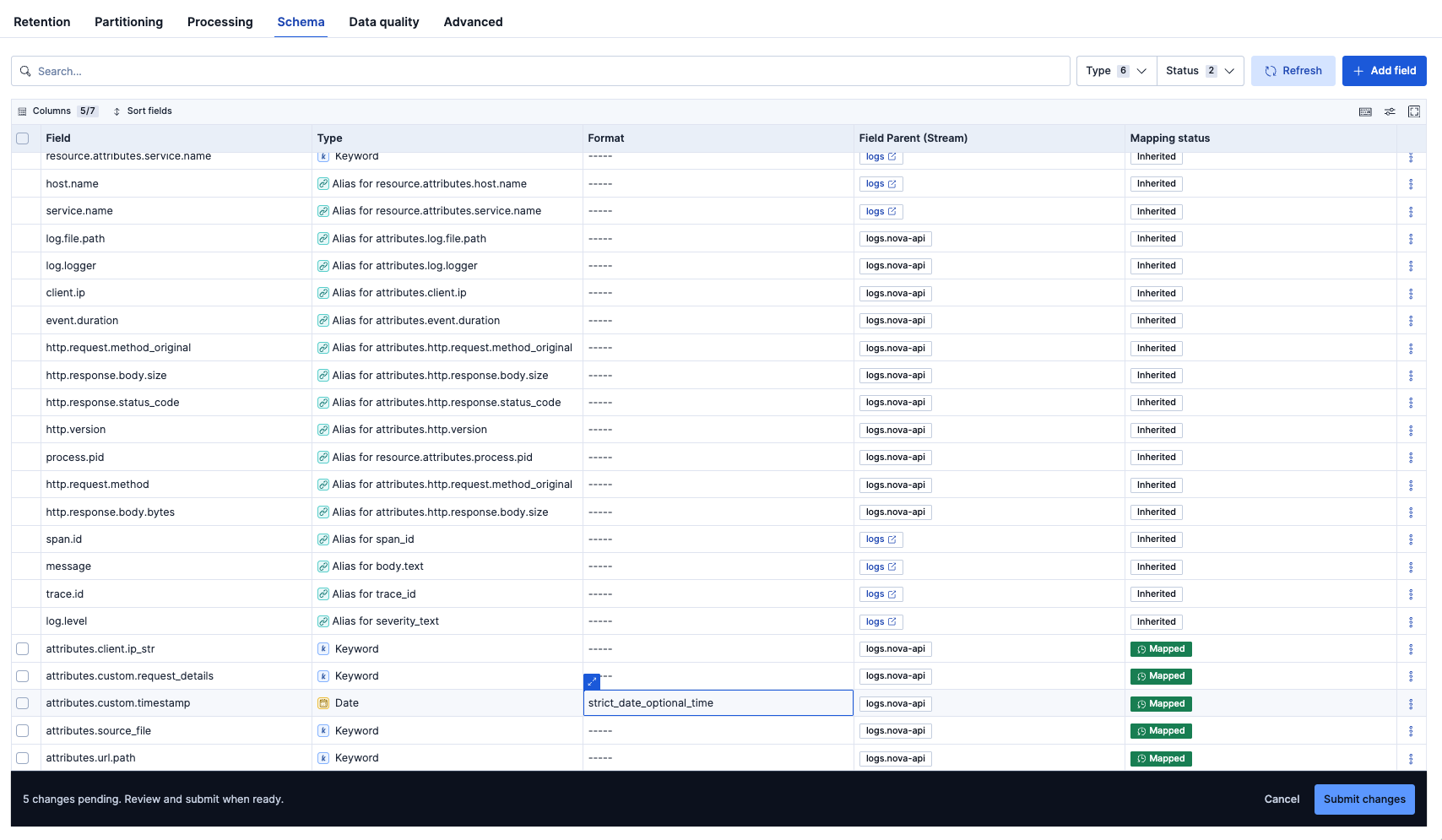
Schemaタブで、型がUnmappedの5つのmappingsに対して型の設定をしました(Mappedと緑に表示されているところ)。基本的にはbody.text以外のテキスト型はKeywordにすると良いでしょう。
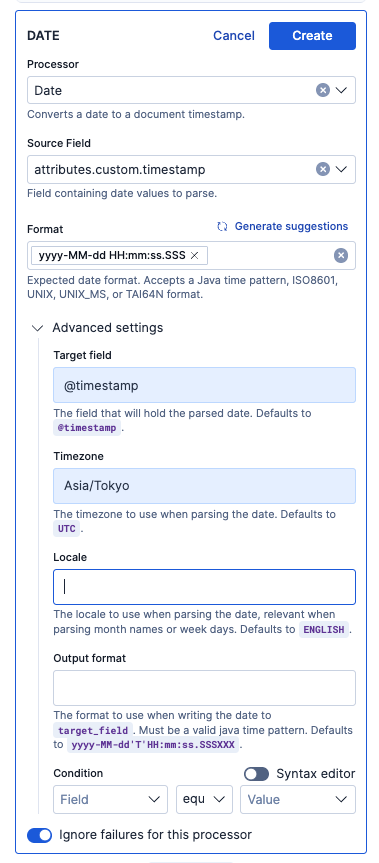
Dateプロセッサーを使い、タイムスタンプをdate型として認識し、さらに日本のタイムゾーンベースとして認識されるように設定を追加します。
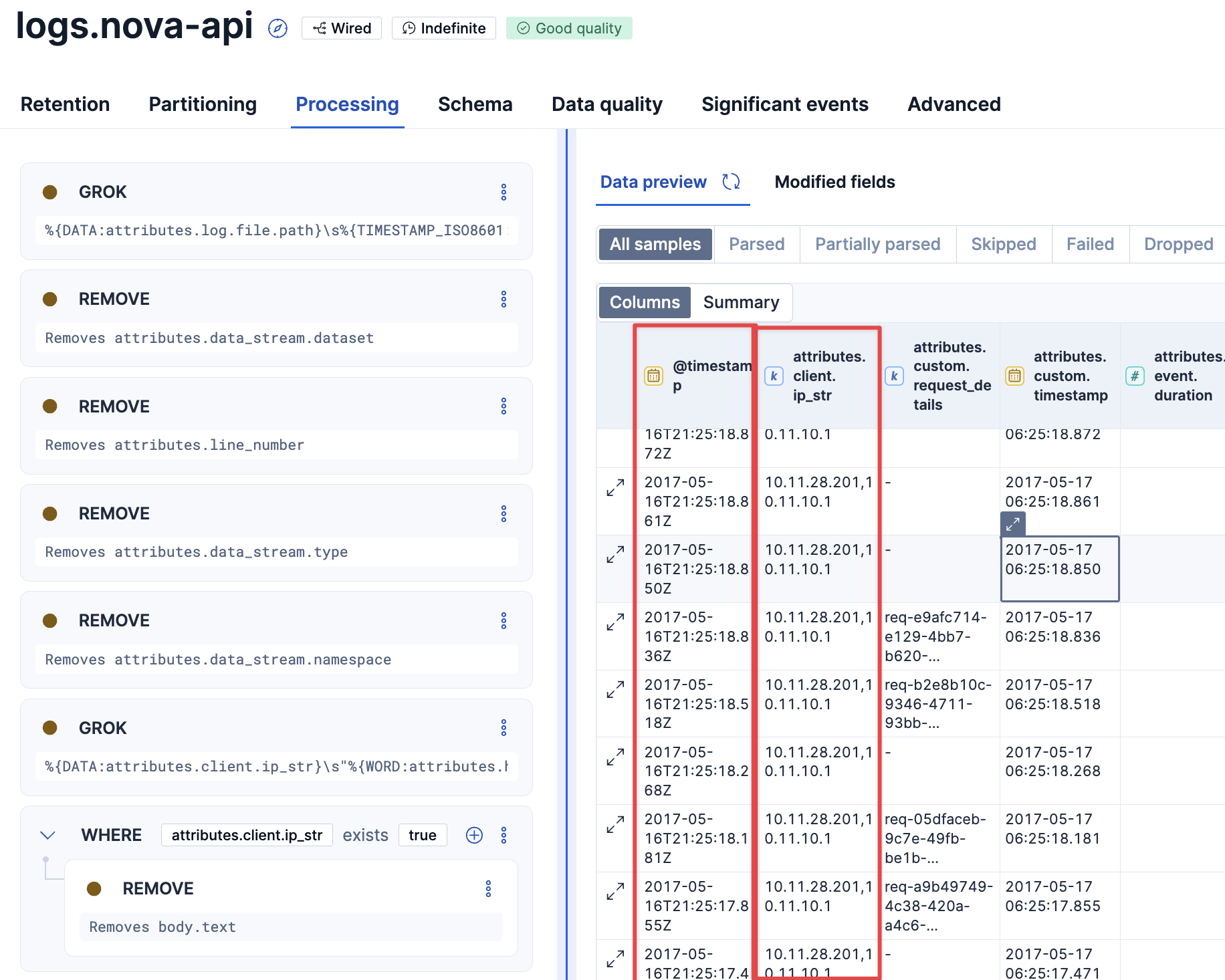
ここでまた設定の反映を確認するために、同じログをアップしました。
📊 処理完了:
- 成功したファイル: 1/1
- 送信したログエントリ総数: 18434
うまく反映されました。
次に、もうひとつのlogs.nova-compute.nova-computeを設定していきます。
もう一つのパーティションlogs.nova-compute.nova-computeも設定
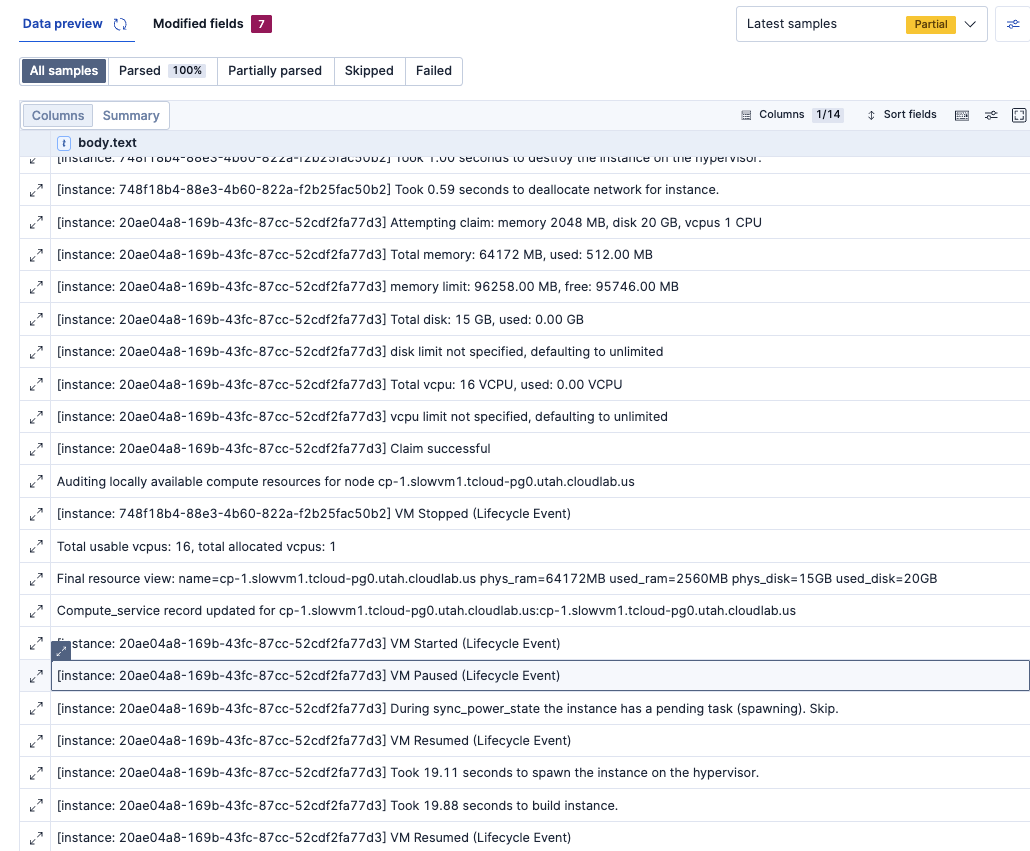
このログには、いくつか異なるログパターンが含まれていそうです。
一旦これ以上はPartitionはせず、同じようにProcessingでGrokにてパースしていきます。
今回採用したGrokパターンはこれです。
(?<attributes.log.file.name>%{WORD}-%{WORD}\.%{WORD}\.%{INT}-%{INT}-%{WORD}:%{INT}:%{INT})\s%{TIMESTAMP_ISO8601:attributes.custom.timestamp}\s%{INT:resource.attributes.process.pid}\s%{LOGLEVEL:severity_text}\s(?<attributes.log.logger>%{WORD}\.%{WORD}\.%{WORD})\s\[%{DATA:attributes.custom.request_info}\]\s%{GREEDYDATA:body.text}
さらにbody.textを細分化できるかやってみます。3つのGROK パターンをAIが提案してきたので、一旦Acceptしてみます。
Before:
After: これだと少しエラーしています。
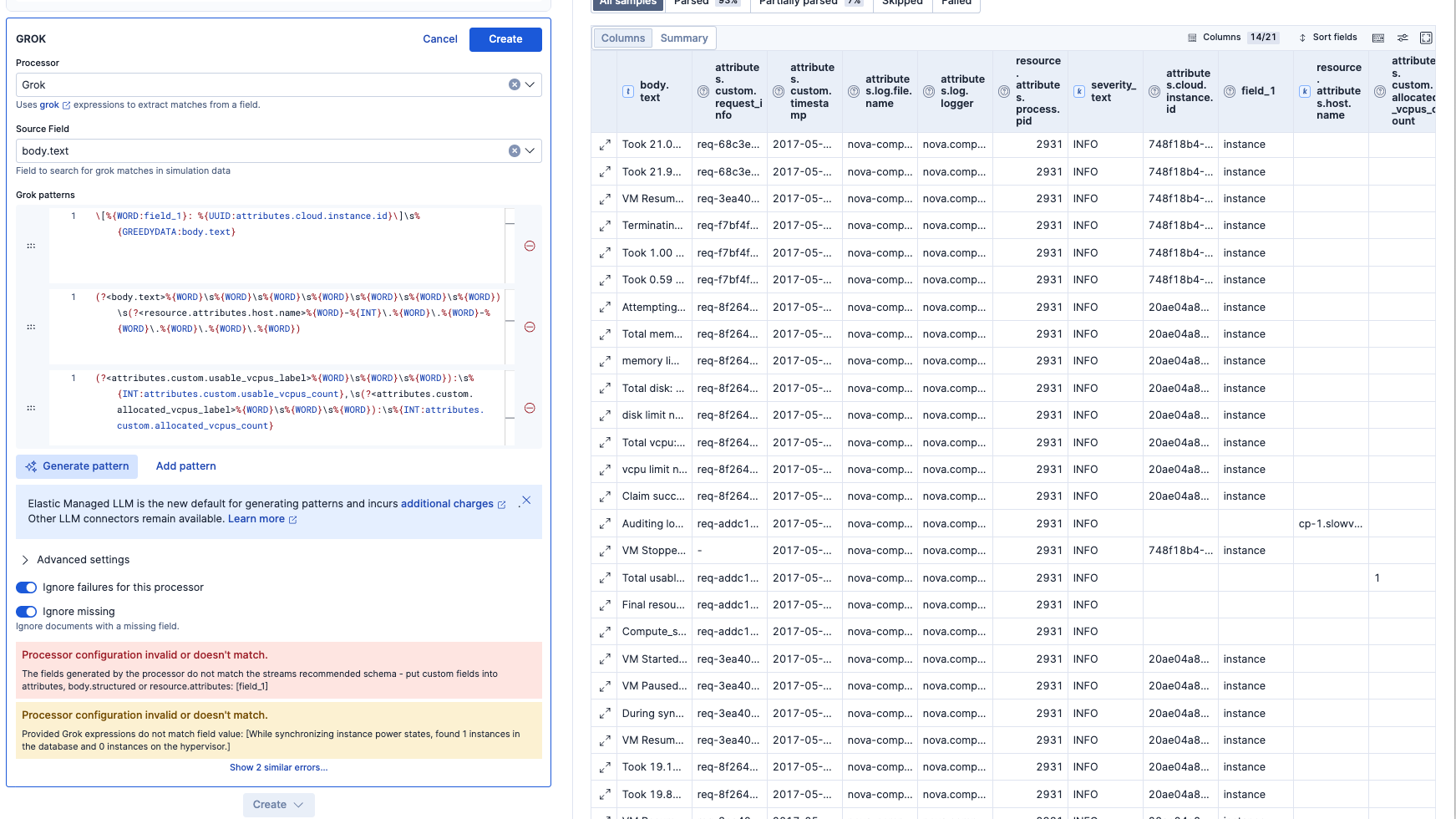
After手動調整後: 結局もっとシンプルなこちらのGrok設定に手動編集して進めました。
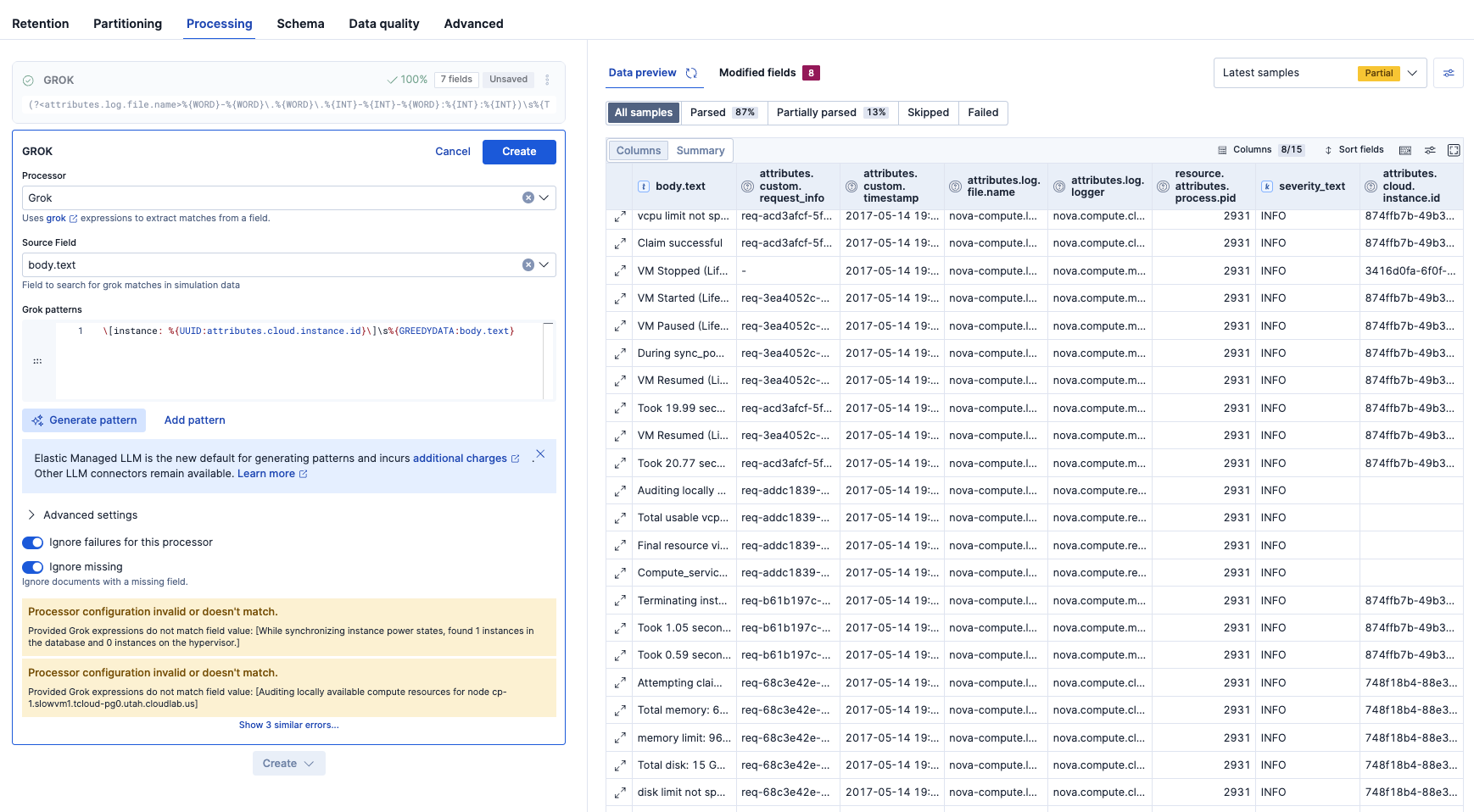
パース結果はこのようになりました。これでattributes.cloud.instance.idやattributes.custom.request_infoといったデータで検索や集計ができるようになります。
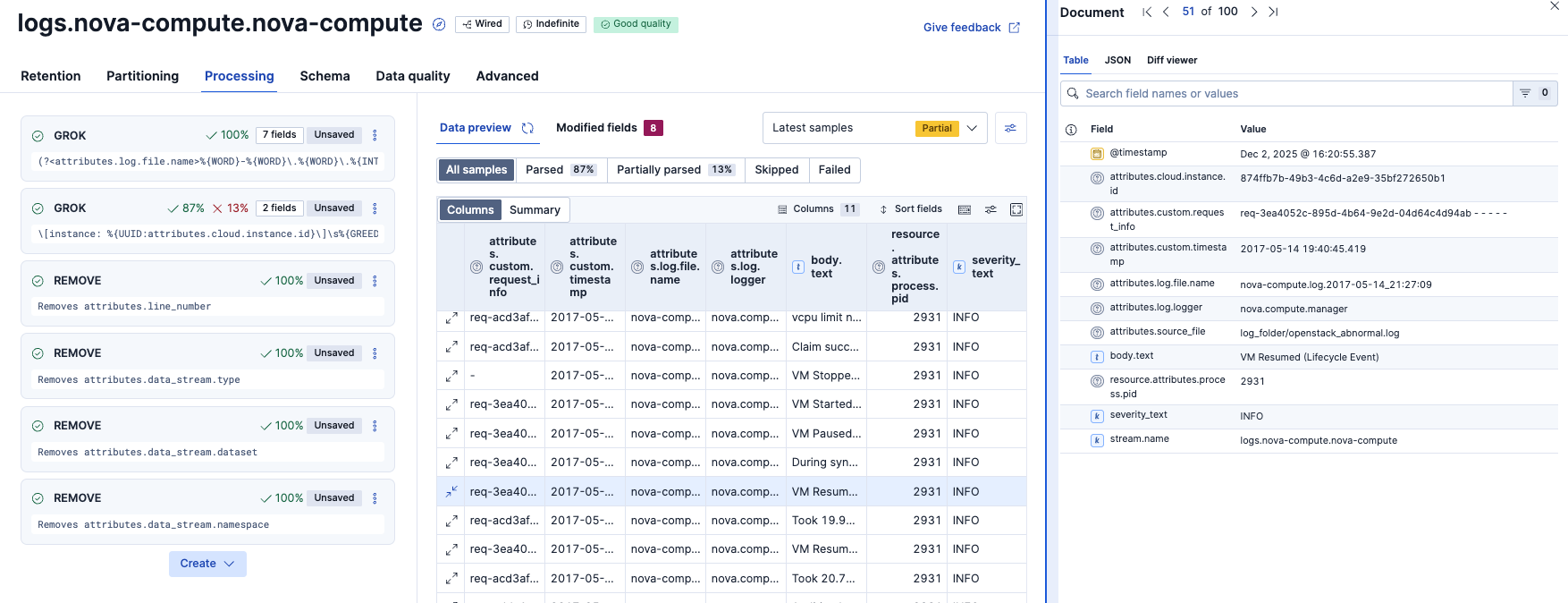
まだ全てのログのProcessing終わっていないですが、一旦ここまでにしたいと思います。
StreamsのData StreamをDeleteしてみる
Index Managementから見るとパーティションごとにData Streamとして作成されているのがわかります。
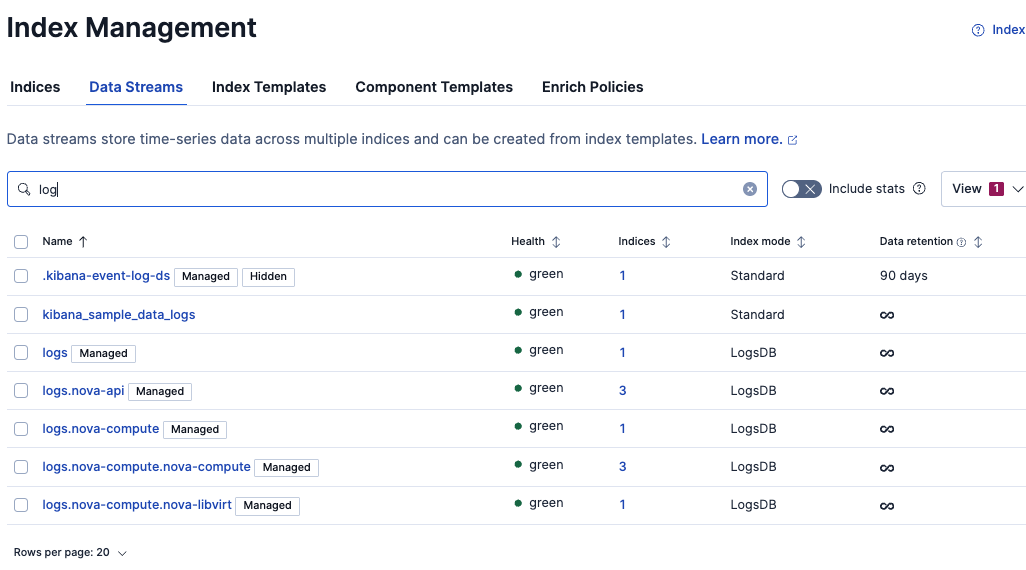
Deleteするとどうなるでしょう?Streams設定も消えるでしょうか?やってみます。
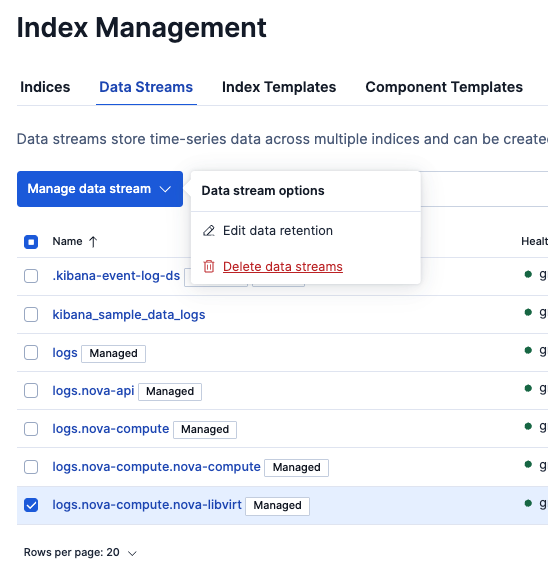
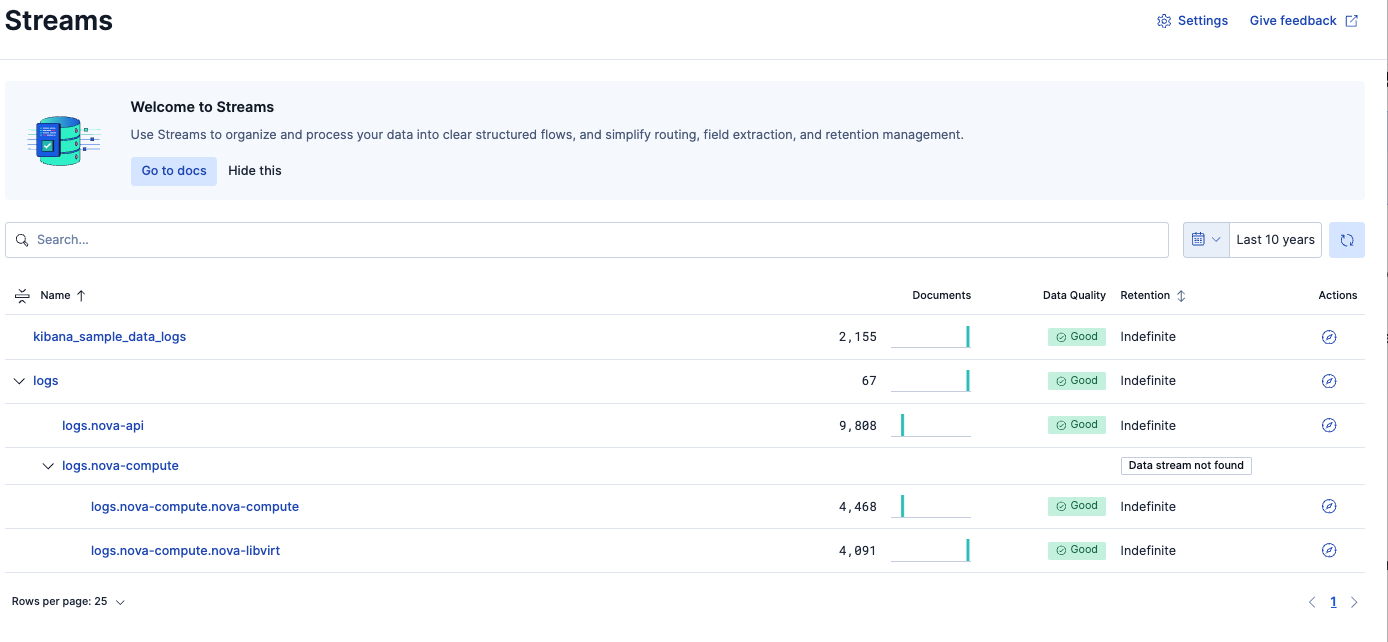
今回のlogs系のData Streamは全てDeleteしましたが、Streamsの設定は消えないですが、バーチャートからデータが消えたのがわかります。
Delete後に再度データを取り込み直します。
📊 処理完了:
- 成功したファイル: 1/1
- 送信したログエントリ総数: 18434
データを綺麗にしたい場合、一旦全部Deleteして再度データをアップすることで綺麗な状態で取り込むことができました。
現在のStreamsは、ログが継続的に入ってくる状態の中で設定を追加していくことが想定されています。設定は新しいデータにだけ反映され、その前のデータは加工されずそのままです。過去のデータに対しても適用したい場合は、別途手動でそのログをアップするか、うまくreindexでコピーによる反映をしないといけないでしょう。
さらに.. パーティションするべきログがまだありました。
ここまででログデータはlogs配下に2つの子ストリームlogs.nova-apiとlogs.nova-computeを設けて、それで全て仕分けできたと思っていたのですが、再度logsのパーティションするべきログが見つかりました。
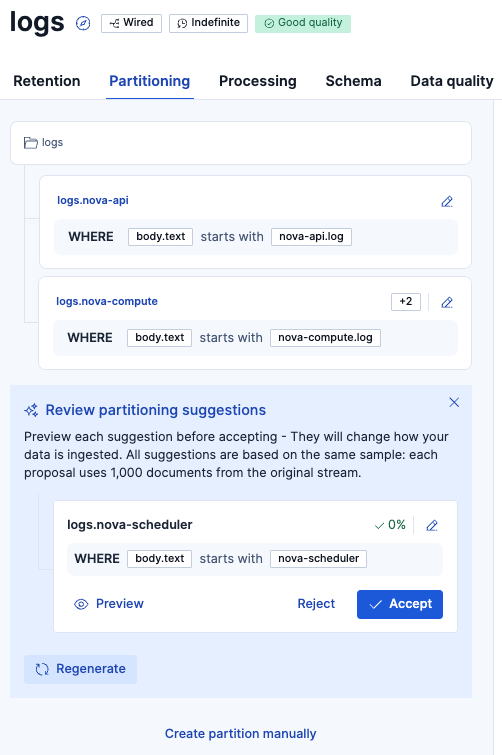
以下の説明の通り、このAIサジェストではサンプリングで1000ドキュメントを元にAIがサジェストしているので、一度で全てのパーティションパターンを網羅できない場合があります。よって、何回かこのようにパーティションー>確認を複数回行う必要があるかもしれません。
All suggestions are based on the same sample: each proposal uses 1,000 documents from the original stream.
さらに.. 一部のログでGrokがうまくいかないのが見つかり、修正。
行頭にあるファイルが、nova-api.logからnova-api.1.logになった途端Grokが効かなくなってしまったので、Grokの許容パターンをもっとシンプルなものにして緩める必要がありました。
変更前:
(?%{WORD}-%{WORD}.%{WORD}.%{INT}-%{INT}-%{WORD}:%{INT}:%{INT})\s%{TIMESTAMP_ISO8601:attributes.custom.timestamp}\s%{INT:resource.attributes.process.pid}\s%{LOGLEVEL:severity_text}\s%{NOTSPACE:attributes.log.logger}\s[%{DATA:attributes.custom.request_details}]\s%{GREEDYDATA:body.text}
変更後:
%{DATA:attributes.log.file.path}\s%{TIMESTAMP_ISO8601:attributes.custom.timestamp}\s%{INT:resource.attributes.process.pid}\s%{LOGLEVEL:severity_text}\s%{NOTSPACE:attributes.log.logger}\s[%{DATA:attributes.custom.request_details}]\s%{GREEDYDATA:body.text}
さらに.. ピンポイントで処理秒数をログから抽出してみた。
以下のようなフォーマットのログから、秒数の処理時間を統計化したいので、そのための設定をしてみました。
Took 19.14 seconds to spawn the instance on the hypervisor.
色々なログがある場合、この画面で対象のフォーマットのログが表示されない場合があります。
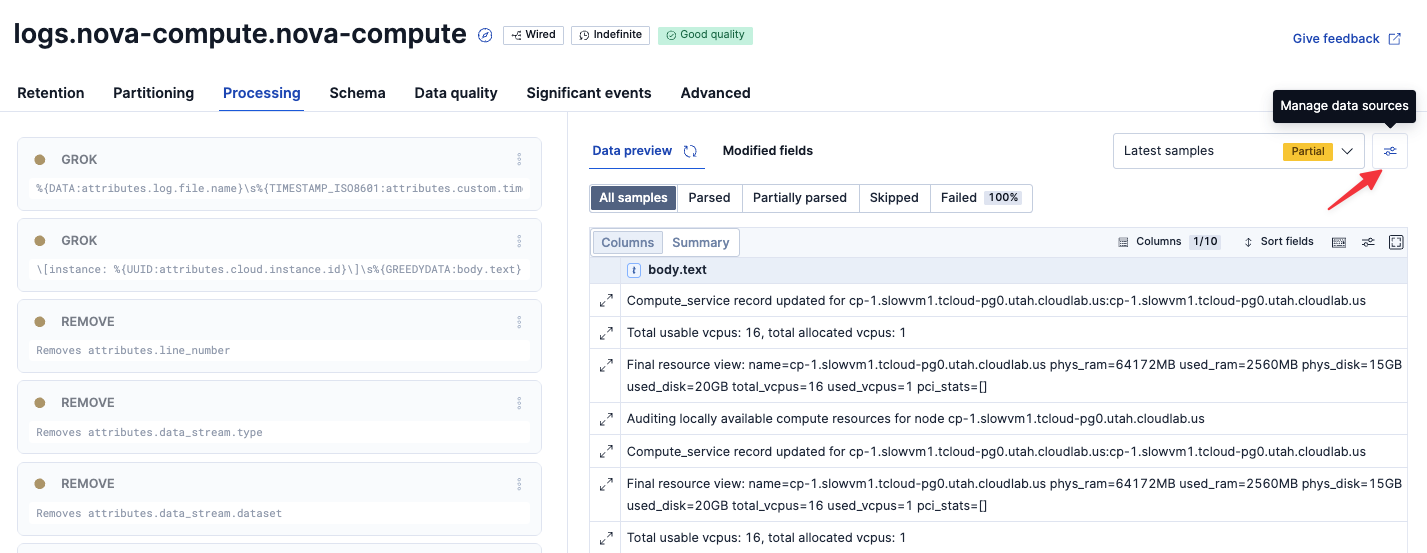
その場合は、右上の設定からこの画面で表示されるログをフィルターで選択することができます。(この例ではbody.text: Tookをフィルタに設定)
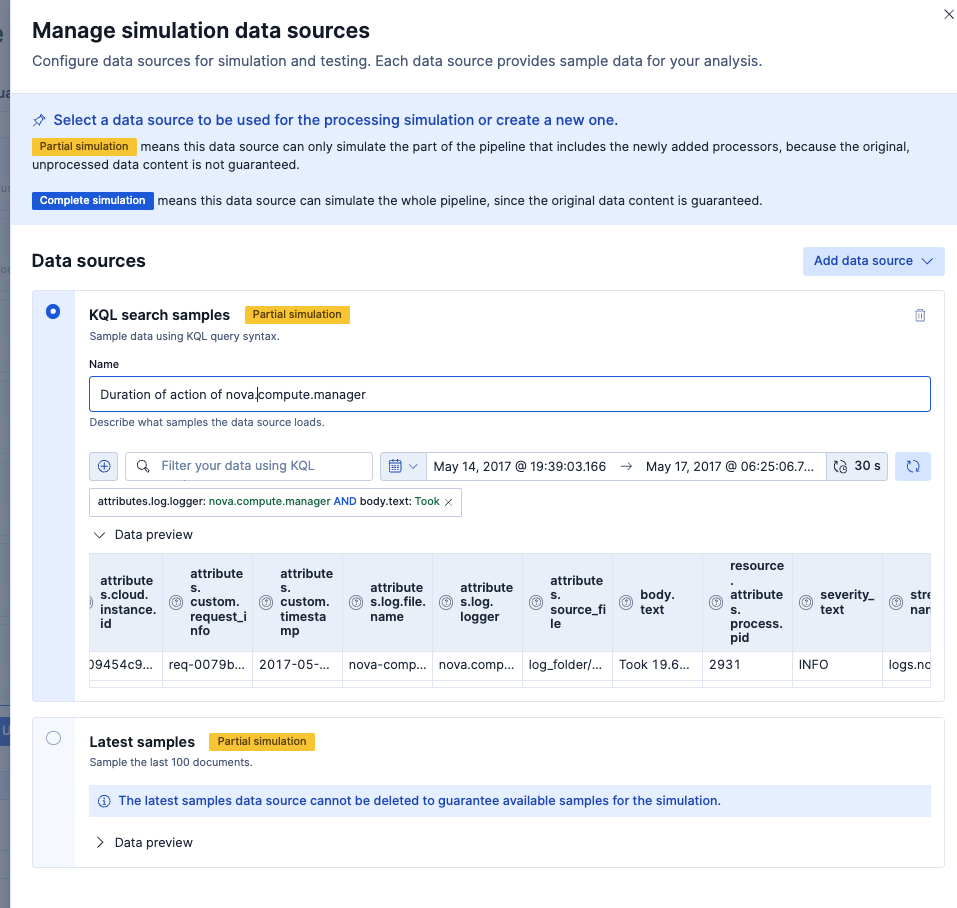
パース設定したい対象行だけの表示にすることができました。
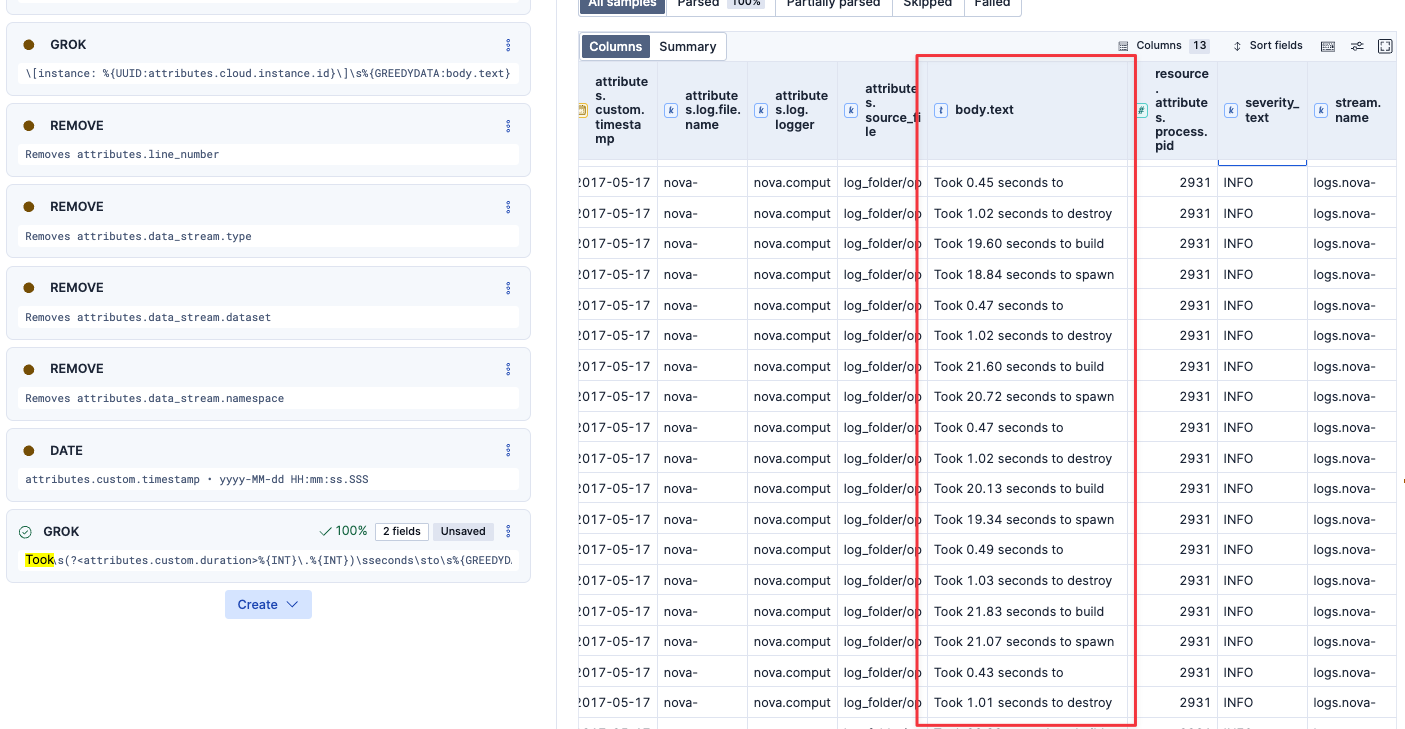
Grok設定を行います。
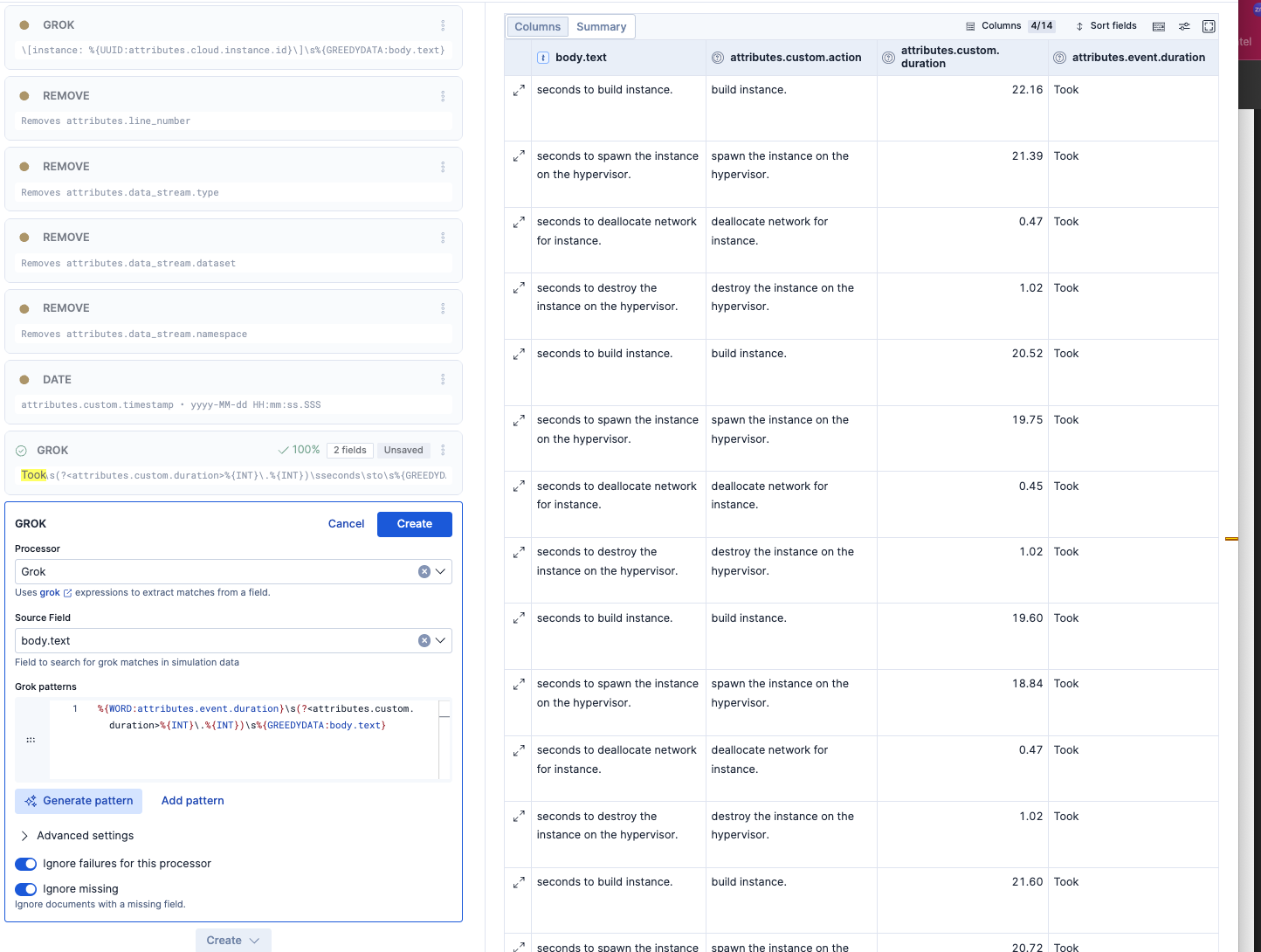
今回のGrokパターンはこちら。
Took\s(?<attributes.custom.duration>%{INT}\.%{INT})\sseconds\sto\s%{GREEDYDATA:attributes.custom.action}
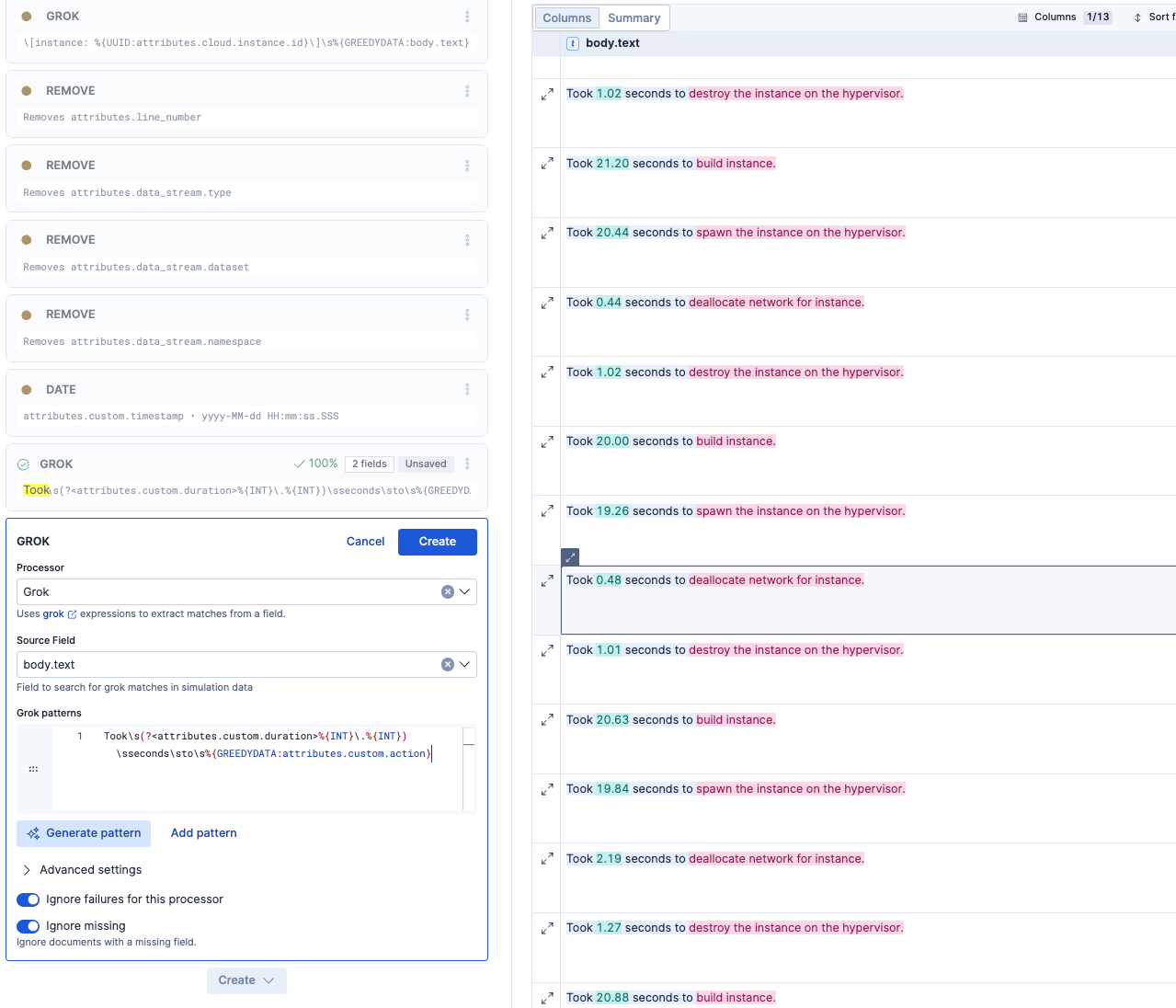
これで数字の秒数部分と、ピンクの部分をアクションの説明として別フィールドに入れ、アクション別の処理時間として、集計や分析ができるようになりました。
おわり
Wired Streamsを使うと従来では対応できないようなログ取り込みのケースも対応できる世界観が見えてきました。どのようなログであっても、とりあえず送る先は一つのlogs Data Streamで良いというのはログを送る側としては非常にシンプルで助かります。
まだ設定の手数はありますが、従来のGrokやmappingsのための設定と比べると、今回のWired Streamsでそれらが大幅に楽になる可能性を感じられました。
とはいえ、まだ手動で設定することや、人による設計考慮が必要なことも今回わかりました。Wired StreamsはまだTech Previewであり、今後より楽になることを期待したいです。