はじめに
Elasticsearchにログやメトリクスを保存して利活用されている方は多いと思います。
ただデータには「鮮度」があります。当然ながら新しいデータほど価値があり、素早く解析すればするほど効果が出ます。例えばセキュリティインシデントなどはそれにあたります。
それに対して、長期間データを保存しなければいけないこともあります。しかしそれらのログはたまにしか参照しないためそこまで性能を必要とはしないこともあります。監査ログ等はそれにあたります。
上記の2つの要望を満たす方法として、Elasticsearchにはデータティアリングの考え方があります。本ブログではデータティアリングの使い方について基本的な解説をいたします。
Elasticsearchのバージョンは8.13.1をベースに記載しています
Data Stream
ログやメトリクスは次々に新しいデータが入ってきますが、上書きしたりすることはまずありません。そのようなデータを効率的に処理するためにElasticではData Streamという形式が使用されます。
ドキュメントが2つあります。
- Elasticsearchのドキュメント
https://www.elastic.co/guide/en/elasticsearch/reference/current/data-streams.html
これはData Streamをマニュアルで管理する方法です - Elastic Agentのドキュメント
https://www.elastic.co/guide/en/fleet/current/data-streams.html
Elastic Agentで自動生成されるData Streamについてのマニュアル
このブログではElastic Agentで生成されるData Streamについて解説します。
ログやメトリクスのインデックスは基本的にどんどん追記されていって、インデックスがある程度まで大きくなったりすると別の名前のインデックスを作っていきます。これをロールオーバーといいます。
例えば以下のような感じになります。
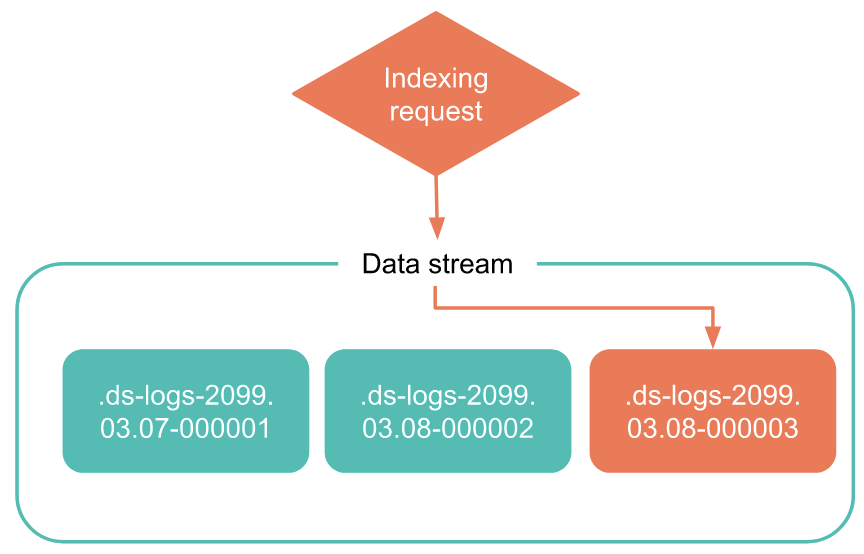
勿論ログを検索するときには全てのインデックスが検索対象となります。

なぜこんな事をするかというと、一つのインデックスに書き込み続けるとそのインデックスが大きくなりすぎて効率が悪くなるからです。基本的には一つのインデックスが10-50GBぐらいになるように設計します。
詳しくはこのページに記載されています。
https://www.elastic.co/guide/en/elasticsearch/reference/8.13/size-your-shards.html#shard-size-recommendation
逆に小さいインデックスを大量に作成するのも効率が悪いです。
ここを効率的に制御する仕組みがData StreamとILMです。
Data Streamの名前とインデックス
名前
Data Streamと言っても結局は普通にElasticsearchのインデックスの集まりです。ログやメトリクスでは大量のインデックスが作成されるので、それらをわかりやすく管理するために名前がつけられます。
Data Streamの命名は決まりがあります。
<type>-<dataset>-<namespace>
- type
logとかmetricsなどです - dataset
nginxとかsystem.authなどです - namespace
何もしないとdefaultになりますが、自由に指定できます。
ただ上記のように決めればわかりやすいというだけで、ルールとしてハイフンで3つつなぐということだけです。
別にhoge-hoge-hogeとかでも大丈夫です。
インデックス
<type>-<dataset>-<namespace>という名前のインデックスが作られるわけではありません。これはエイリアスのようなものです。
何も設定をせずにElastic AgentをLinuxにインストールすると、/var/log/auth.logを勝手に集めてくれます。このときのインデックス名は.ds-logs-system.auth-default-<日付>-<通し番号>です。例えば.ds-logs-system.auth-default-2024.05.02-000001という感じです。
デフォルト設定
ではデフォルトでどのように動くのか見ていきます。
何も設定をせずにElastic AgentをLinuxにインストールする場合を見てみます。
Agent Policy
Agent Policyはどのようなログを集めるのかという設定です。何もしなければSystem Logを集める設定が自動的にONになっています。
Fleet -> Agent Policies -> Create Agent Policyとすると以下のような画面になります。
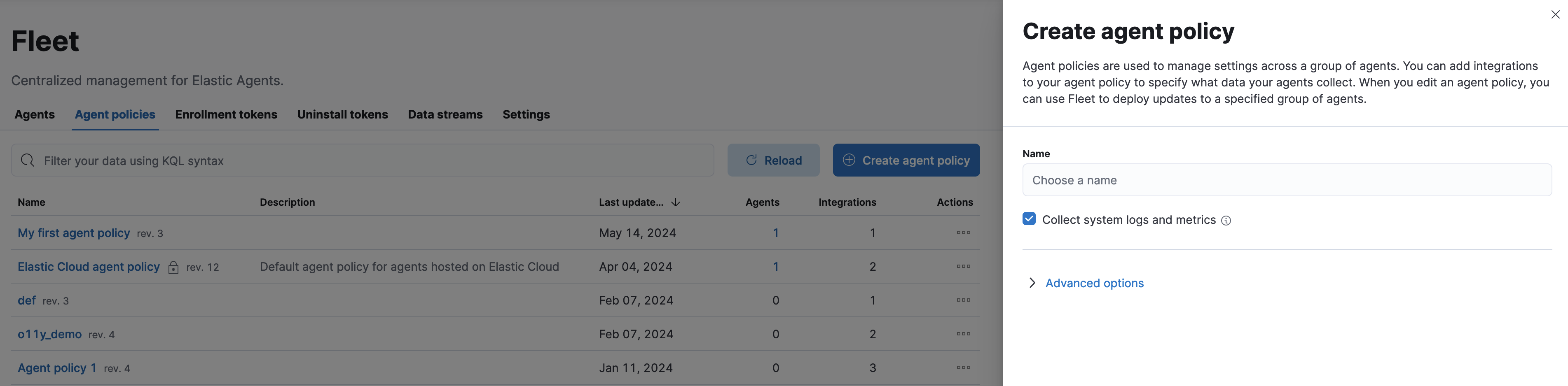
Collect system logs and metricsという部分にチェックボックスがついていますので、自動的に/var/log等を集める設定が行われます。
適当に名前を入れてAgent Policyを作ってみます。無事作り終わると一覧の部分に今作成したpolicyが表示されているので、それをクリックしてみます。

このようにSystemというものが自動的に設定されています。これがIntegrationsと呼ばれるもので、何を集めるかという設定です。とりあえず左端(ここではsystem-3)をクリックします。

これを見ると何を集めるのか一目瞭然です。
Data Streamの名前
設定はこれで終わるのですが、このままではData Streamの名前がわかりません。
Integrationsを使用すると一部を除き(Custom Logs等)Data Streamの名前は自動的に決まります。
<type>-<dataset>-<namespace>のうち、<type>はlogsやmetrics等が自動的に入ります。<dataset>はIntegraionsの種類によりますが、大体そのIntegraionsの名前が入っています。
今回のLinuxのデータだとsystem.authやsystem.syslog等です。NGINXだとnginx.accessとかになります。
<namespace>はdefaultになってますが、ここは変更できます。Integration settingsのAdvanced optionsをクリックして開くとNamespaceを変更できます。

Data Streamの確認
Stack Management -> Index Management -> Data Streamとクリックします。
検索ボックスにsystemと入れるとlogs-system.auth-defaultが表示されるのでそれをクリックします。これが上記で設定したLinuxのSystem LogのData Streamです。
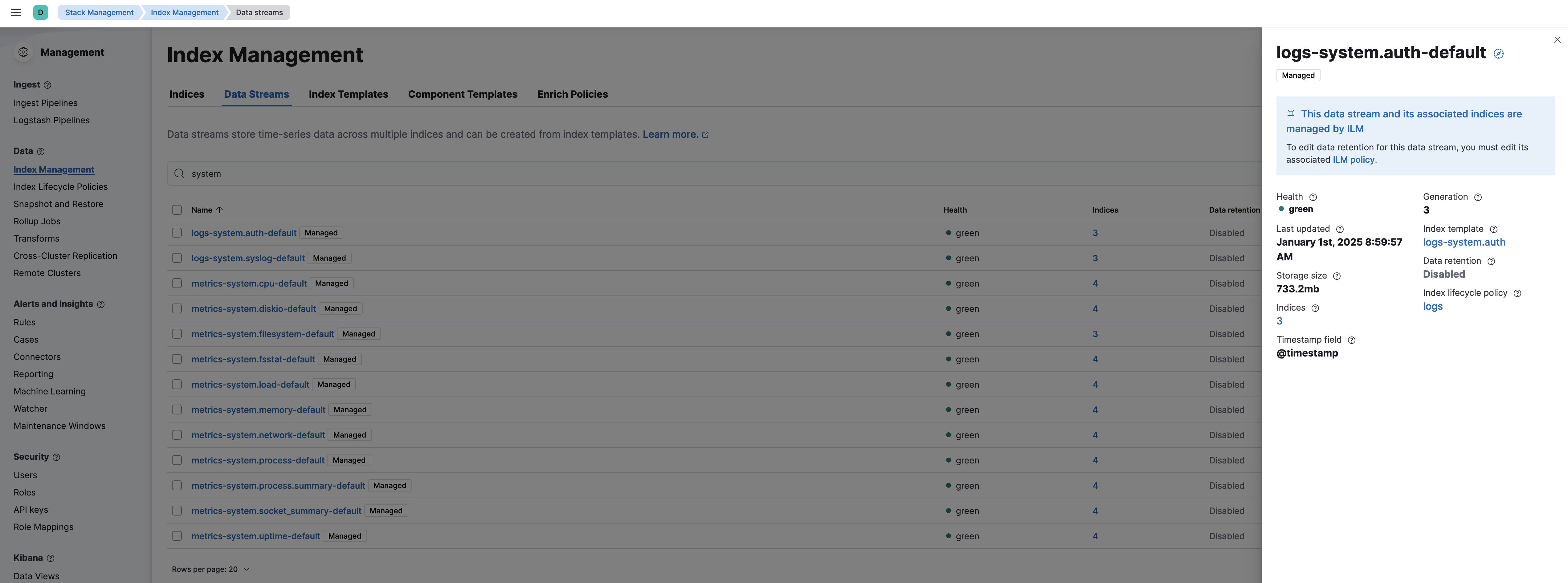
ではまずデータを見てみましょう。
logs-system.auth-defaultの右側にある方位磁石のようなアイコンをクリックするとDiscoverのページに飛べます。

Discoverでのログ表示

とりあえずデータが取れていることが確認できます。
世代管理
Data Streamの中身がわかったところで、次に世代管理について説明していきます。
ElasticにはHot-Warm-Cold-Frozenという4つのデータティアがあり、Frozenに近づくほどコストが下がりますが検索性能が落ちます(=検索に時間がかかる)。
検索性能は大体RAM:Storageの比率で決まります(RAMがStorageに比べて大きければ検索は早い)
性能面についてはこちらのブログに記載があります。
https://www.elastic.co/jp/blog/querying-a-petabyte-of-cloud-storage-in-10-minutes
- Hot
- RAM:Storage=1:30ぐらい。全てのデータは必ずHotに入る
- Warm
- RAM:Storage=1:160ぐらい。
- Cold
- ここから少し役割が変わります。Coldはデータの冗長性を無くしますので単純に倍のデータが入ります。もちろんノード障害が起きるとデータが消失しますが、Searchable Snapshotを設定しておくと、自動的にSnapshotからデータが復活します。
- Frozen
- 実データを全てオブジェクトストレージに入れておき、ローカルにはキャッシュしか持たないので、非常にコストは安い。アクセスが有ると必要な部分だけオブジェクトストレージから取ってくる。
https://qiita.com/nobuhikosekiya/items/dd2ce836b184730f8d70#%E3%81%AF%E3%81%98%E3%82%81%E3%81%AB
- 実データを全てオブジェクトストレージに入れておき、ローカルにはキャッシュしか持たないので、非常にコストは安い。アクセスが有ると必要な部分だけオブジェクトストレージから取ってくる。
これらのデータティアをどの用に使うかを設定するのがILMです。
まずは上記で設定したlogs-system.auth-defaultがどう設定しているか見てみます。
再度Data Streamの設定を見てみます。右下のIndex lifecycle policyにlogsとありますのでこれをクリックします。

以下の画面がILMを設定する画面です。赤線で囲った部分をクリックして詳細な情報を表示します。

デフォルトではHotにずっと残り続けます(=データ量が増え続ける)。右上にKeep data in this phase foreverとある部分がそれです。
Rolloverとありますが、これがインデックスを新しく作っていく部分です。
デフォルトでは以下の条件で新しいインデックスが作成されます。
- Maximum primary shard size: 50GB
- シャードのサイズが50GBを超える
- Maximum age: 30days
- インデックスが作成されてから30日経過する
上記のどちらかに引っかかると新しいインデックスが作成されて、今までのインデックスは読み込み専用になります。
1日に500GBの書き込みがあれば、1日に10個のインデックスが作成されることになります。
逆に1日に1MBの書き込みしかない場合、30MBのインデックスが1ヶ月毎に作成されます。
他にはドキュメントの数(=ログの数)でもRollover出来ます。
例) 毎日100GBの書き込みがある場合
最初に.ds-logs-system.auth-default-2024.05.02-000001が作成されます。12時間後に50GBに達するのでその時点で.ds-logs-system.auth-default-2024.05.02-000001は読み込み専用となり、新たに.ds-logs-system.auth-default-2024.05.02-000002が作成される。
データティア移動の設定
それでは、以下のような条件にする場合を説明します。
- RolloverしたらすぐにWarmへ移動
- 365日たったら消去
以下のような設定になります。

ここで保存すると全てのログにこのポリシーが適用されます
- Warm phaseを有効にする
- これはクリックするだけです
-
Move data into phase whenに0を入れる- ここが複雑な部分です。ここに入れる日数というのは「Rolloverしてからの日数」です
- 例えば毎日5GBのデータが書き込まれるとすると、Rolloverするまでに10日かかりますので、Warmに移るのはインデックスが作成されてから10日後です。もしここに3と入れればRolloverしてからHotに3日間滞在してからWarmへ移りますので、インデックスが作成されてから13日後にWarmへ移ります。
-
Delete data after this phaseのゴミ箱アイコンをクリック- これによりDelete phaseが追加されます
- Delete phaseの
Move data into phase whenは自動的に365になっています。これの意味するところも同じでRolloverしてから365日なので、Rolloverしてから365日でそのインデックスは消去されます。
デフォルト設定
logs-system.auth-defaultがlogsというポリシーを使うというのは特に設定する必要はありませんでした。これはIndex Templateという機能を使ってlogs-から始まるものは全てlogsポリシーを使うようになっているからです。
Index Template
https://www.elastic.co/guide/en/elasticsearch/reference/current/index-templates.html
Elasticsearchのインデックスにはいろいろな設定があります。ILMのポリシーもそうですが、レプリカを何個持つかとか、どのようなMappingにするか、日本語処理をどうするか、などです。
一つ一つ設定を入れていくのは面倒なので、似たようなインデックスは同じ設定にしたいですよね?それを実現するのはIndex Templateです。それでは実際にどういうものか見ていきましょう。
logs-system.auth-defaultの下記画面にあるIndex templateの下のlogs-system.authをクリックします。

するとこのような設定が出てきます。

少し解説します。
- Index pattern
-
logs-system.auth-*というパターンにマッチするインデックスは全てこのテンプレートにある設定が適用されます。
-
- Priority
- この値が大きいほど優先して適用されます。例えば
logs-system*っていうIndex Patternで別のテンプレートを作るとどっちを適用していいかわからなくなります。そういう場合にこのPriorityで使い分けます。デフォルトは200になっています。
- この値が大きいほど優先して適用されます。例えば
- Component templates
- テンプレートの部品です。同じ設定をいろんなテンプレートで使い回せるようになっています。
ecs@mappingsなんかはほぼ全てで使われています。
- テンプレートの部品です。同じ設定をいろんなテンプレートで使い回せるようになっています。
さて、ここまで見てもlogsというILMポリシーがどこで設定されているかがわかりません。その設定はComponent templatesのlogs@settingsに記載されています。Stack Management -> Index management -> Component Templatesとクリックして、"logs@settings"で検索します。

このテンプレートがlogs-から始まるインデックスに適用されていることがわかります。Settingsをクリックしてみます。

ようやく出てきました。ここでlogsというILMポリシーが適用されていること言うことがわかります。
面倒くさい??実はDev Toolsを使うと一発でこの情報が出てきます。Dev Toolsに
GET logs-system.auth-default
と入力してみてください。下の方に同じ情報が出てきます。(Mappingが長々と出てきます)
ILMポリシーの変更
当然ですが、ログの種類によって保存期間は変更したいですよね。メトリクスは3日で捨てていいけど、ログインとかのセキュリティ関係は監査に使うので1年保管、等です。
ではlogs-system.authだけ保存期間を変えてみましょう。logsポリシーを変えると他のログも全部変わってしまうので新しいポリシーを作る必要があります。この手順はこちらに記載があります。
https://www.elastic.co/guide/en/fleet/8.13/data-streams-ilm-tutorial.html
新しいILMポリシーの作成
ポリシーを作る時に、その情報をどう管理したいかを考えましょう。ポイントはその情報にどのぐらい頻繁にアクセスしてどう使いたいか?です。Hotに入っていれば一瞬で表示されますし、Frozenに入っていると少し時間がかかります。常に見ておきたい情報はその期間はHotに入れる、そうでなく監査目的で保存することが目的であればすぐにFrozenにいれる、などです。
今回はRolloverしてから、Hotに3日/Frozenに1年保管、としましょう。Stack Management -> Index Lifecycle PoliciesでCreate Policyをクリックします。
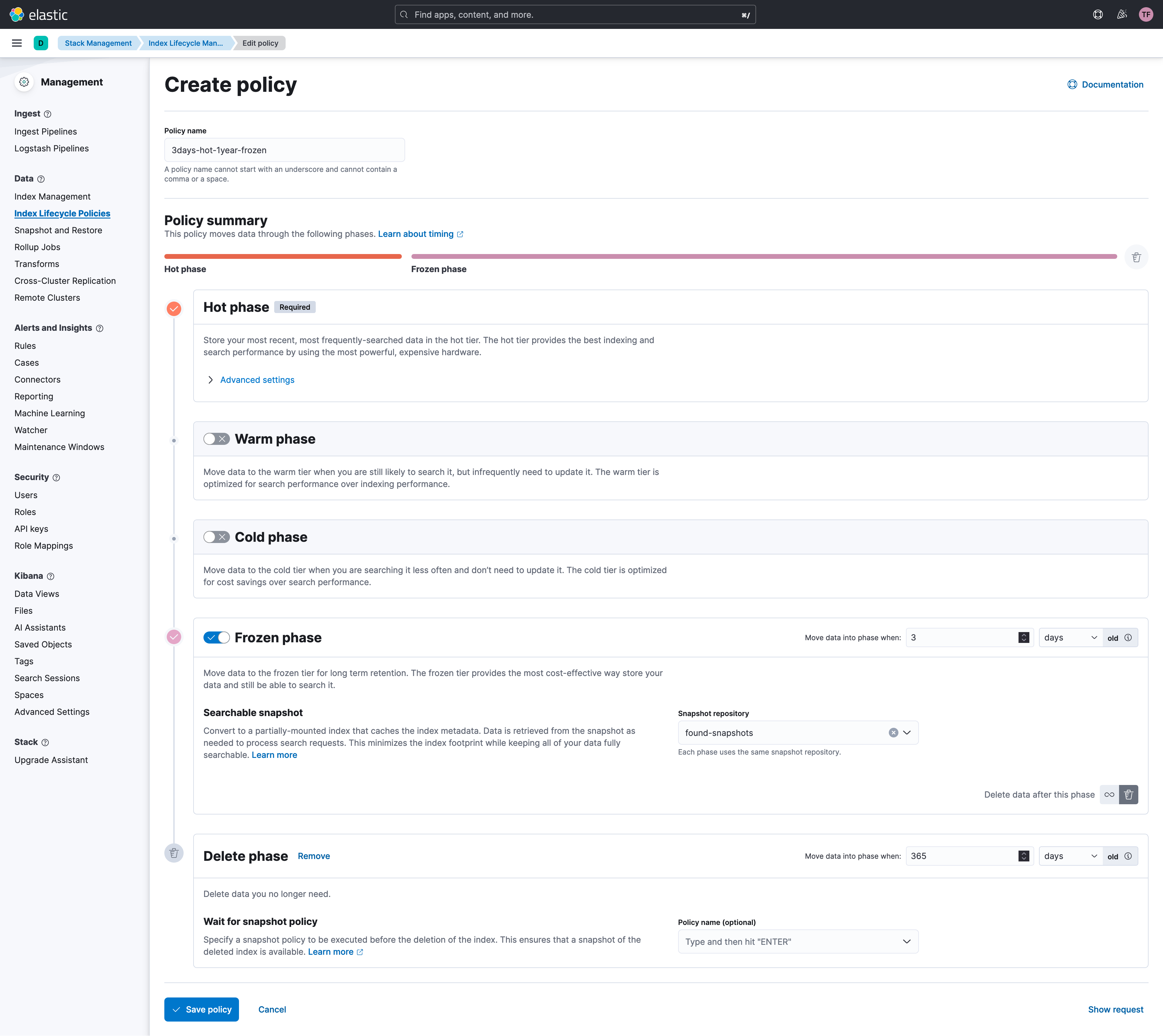
- Policy name
-
3day-hot-1year-frozenとでもしておきます。何でもよいです。
-
- Frozen
- クリックして有効にします。
- Move data into phase when:に3を入れます
- Keep data in this phase foreverの横のゴミ箱マークをクリックしてDelete Phaseを追加します
- Delete
- Move data into phase when:に365を入れます
Save Policyをクリックして保存します。
Component Template作成
3day-hot-1year-frozenというポリシーを使うテンプレートを作成します。
Stack Management -> Index management -> Component TemplatesからCreate component templateをクリックします。
Nameに適当な名前を入れて(ここでは3day-hot-1year-frozen)、Nextをクリック

Index settingsに下記の設定を貼り付けます。
"lifecycle": {
"name": "3day-hot-1year-frozen"
}
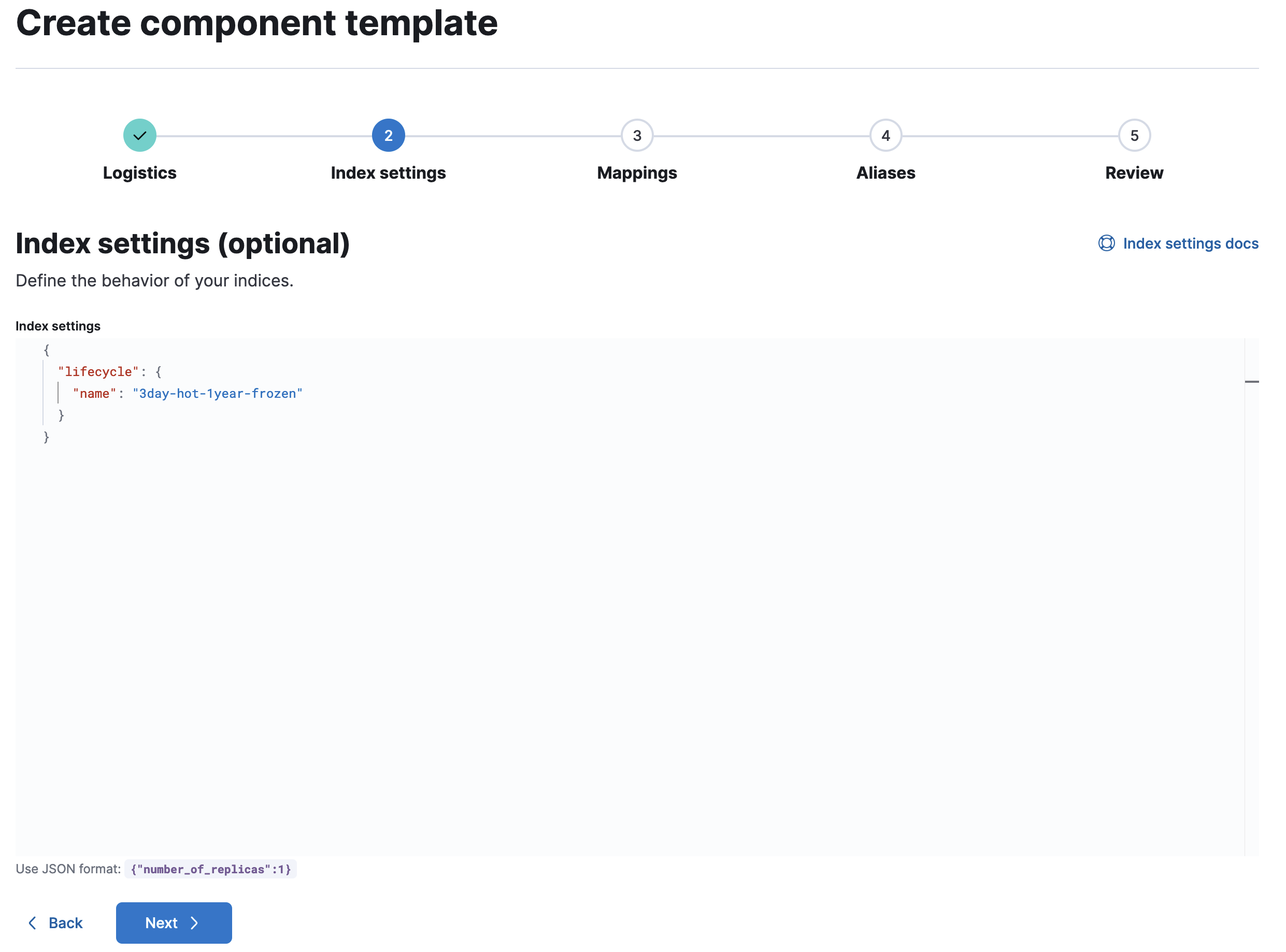
後はNextを3回クリックして最後にcreate componentを押して作成を完了します。
Index templateの作成
いちから作るのは面倒なので既存のものをクローンします。
Stack Management -> Index management -> Index Templatesからlogs-system.authをクリックして右下のManageからCloneを選びます。

Priorityを200より大きい値にします(ここでは300)
名前は勝手にlogs-system.auth-copyとなってますので、適宜変更してください(今回はそのままにしています)
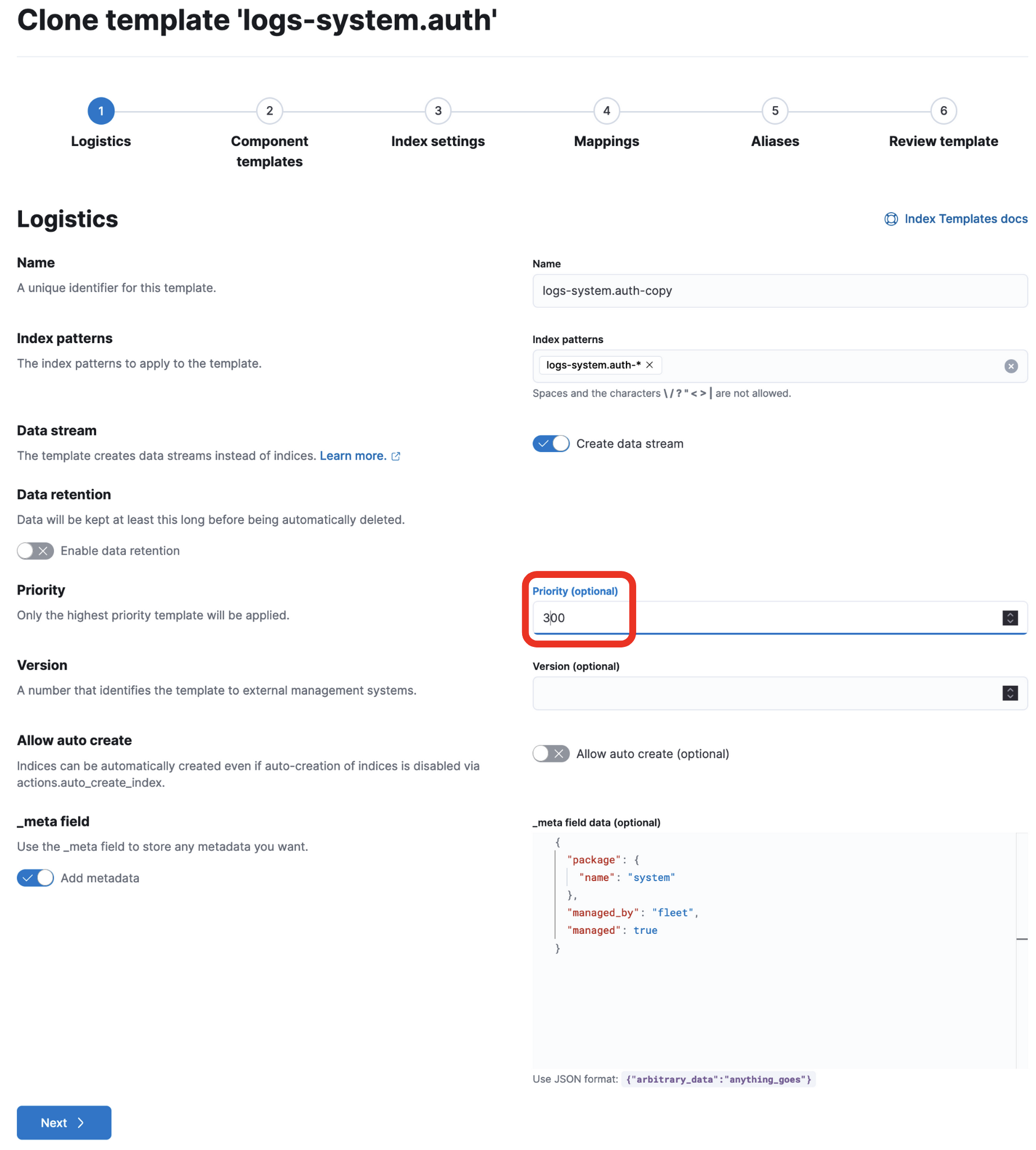
Nextをクリックして、Component Template選択画面に行きます。
右側に3day-hot-1year-frozenがあるので、**+**をクリックして追加します。
下にあるほどその設定が優先されます(上書きされる)。
Preview index templateをクリックして正しく追加されていることを確認します。

Nextを4回クリックして最後の画面でSave templatesで保存します。
保存すると適用されています。
確認
Stack Management -> Index management -> Data Streamでlogs-system.auth-defaultを確認してみましょう。変わってますね。

いつから適用されるか
ここで終わっても問題はないですが、実はこの作成したILMポリシーは現在書き込み中のインデックスには適用されません。
上記画像のIndicesの下の数字(ここでは3)をクリックしてみてください。

一番下に今書き込んでいるインデックスが表示されます。ここでは.ds-logs-system.auth-default-2024.01.31-000003をクリックします。

Index lifecycleをクリックしてみると、まだlogsになっています。
これを変更するにはまず一回ILMポリシーを外します。
Manage Index -> Remove lifecycle policyとクリックします。
(本当に外していいか、と聞いてきますが、外しましょう)

自動的にOverviewに戻されます(Index lifecycleのタブがなくなっている)。再びManage IndexをクリックするとAdd lifecycle policyというメニューに変わっていますので、それをクリックします。

ILMポリシーを選ぶ画面が出てくるので3day-hot-1year-frozenを選びます。

その後こんな感じでWarningが出ますが気にせず追加します。

先程のページに戻りますが、少し表記が変わっています。

確かにILMポリシーは3day-hot-1year-frozenになってますね。
ただ見かけない言葉があります。Current actionにunfollowとあります。ここは通常はrolloverとなっています。
こうなっている理由はILMポリシーをチェックする頻度にあります。実は10分に一回チェックをしているので、しばらく待ってみてください。最終的にはこうなります。

チェックする周期である10分というのは変更することは可能です。
この変更はManagement -> Dev Toolsからのみ行えます。
以下のようにすると1分間隔でチェックします。
PUT _cluster/settings
{
"persistent": {
"indices.lifecycle.poll_interval": "1m"
}
}
まとめ
ILMをうまく利用すればLogやメトリクスの保管コストを下げることができます。特にFrozenはうまく使えば驚異的にコストを下げられます。
ElasticはObservabilityにもセキュリティにも使えます。Observabilityで使っているところをILMをうまく使ってコスト削減頂いて、空いた部分でセキュリティを試す、など柔軟な使い方ができます。
Elasticsearchの豊富な機能を適切なコストでご利用いただける一助になれば幸いです。