本記事はNTTドコモR&Dアドベントカレンダー2021の8日目の記事です.
こんにちは、NTTドコモの橋本(@dcm_hashimotom)です.
業務ではレコメンド関連の技術開発・施策検討を行っており,主にPythonやBigQuery, Apache Sparkを触ってます.
SNSなどで投稿したコンテンツの検索性を上げるためには,そのコンテンツへのタグ(またはハッシュタグ)の付与が重要です.Qiitaではタグは5つまで付与することができ,タグを指定した絞り込み検索や,マイページでのプロフィールに使われております.しかし,タグの付与はユーザ手動なものが多く(要出典),検索性が高いものを選択するためには,ドメイン知識が必要です.なので,タグを付ける際に「このタグがついた投稿では他にこんなタグもついてます」的なレコメンドがあれば有用そうです.また,レコメンドということですが,近年レコメンド技術ではGraph Neural Network(GNN)を用いたものがホットですよね!!
というわけで本記事では、GNNを用いてQiitaタグをembeddingしたTech2Vecを作成し,さらに作成したベクトルを用いてタグ付けレコメンドエンジン(仮)を作ってみようと思います.
Word2Vecにおいて、意味が近い単語はそのベクトルも近傍にあるように、Tech2Vecでは似ている"技術"はそのベクトルも近傍にあるようになることを期待してます.
それでは早速やっていきましょう!
実行環境
今回の実行環境は下記のとおりです.
- macOS Big Sur 11.6 (x86)
- Python 3.7.6 / pytorch 1.5.1 / dgl 0.6.1
本記事ではGNNライブラリにDGL(pytorchバックエンド)を使っていきます.
グラフ構築
扱うデータは2021のQiita記事データになります.
Qiitaの投稿記事からデータセット作った
をもとにした得られたデータを使いました.
pandas DataFrameでデータを読み込むと下記のようになります.
import pandas as pd
df = pd.read_csv('2021_qiita.tsv', sep='\t')
df.head()
| created_at | updated_at | id | title | user | likes_count | comments_count | page_views_count | url | tags | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2021-01-01T09:09:17+09:00 | 2021-01-01T09:09:17+09:00 | 92cc0a5f54f766239da9 | エンベデッドシステムスペシャリストに合格しました | {'description': '', 'facebook_id': 'ryo.muta.9... | 6 | 0 | NaN | https://qiita.com/... | [{'name': 'ポエム', 'versions': []}, {'name': '情報... |
| 1 | 2021-01-01T09:10:42+09:00 | 2021-01-01T09:47:24+09:00 | 99e26397c3ae43a0cfc6 | JitsiMeet(Web会議サーバー)でAI(IBMWatson)と会話する | {'description': '関東在住のSE', 'facebook_id': '', ... | 11 | 0 | NaN | https://qiita.com/... | [{'name': 'asterisk', 'versions': []}, {'name'... |
| 2 | 2021-01-01T09:12:25+09:00 | 2021-01-01T09:12:25+09:00 | dc948d9558cf7612eba8 | WordpressのSearchRegexでリンクタグを全部消す正規表現 | {'description': '元アフィリエイター。現在は駆け出しプログラマーとして活動中... | 0 | 0 | NaN | https://qiita.com/... | [{'name': 'WordPress', 'versions': []}, {'name... |
| 3 | 2021-01-01T09:29:47+09:00 | 2021-01-02T09:44:06+09:00 | 6ad6aeed65fa71f92e1b | TensorFlowObjectDetectionAPIで物体検出モデルを簡易トレーニング | {'description': '機械学習/AR/SceneKit/iOS/Swift/Co... | 3 | 0 | NaN | https://qiita.com/... | [{'name': 'MachineLearning', 'versions': []}, ... |
| 4 | 2021-01-01T09:30:22+09:00 | 2021-06-14T22:51:10+09:00 | 34fd50aea330355b94c2 | SharePoint/OneDriveのファイルをデスクトップアプリで開くためのショートカッ... | {'description': 'エンジニアになりたい製造業勤務。Power Platfor... | 14 | 0 | NaN | https://qiita.com/... | [{'name': 'PowerShell', 'versions': []}, {'nam... |
今回は次の方針でグラフを定義してみます.
- 技術タグをノードとする
- 同じ記事にあるタグはリンクを張る
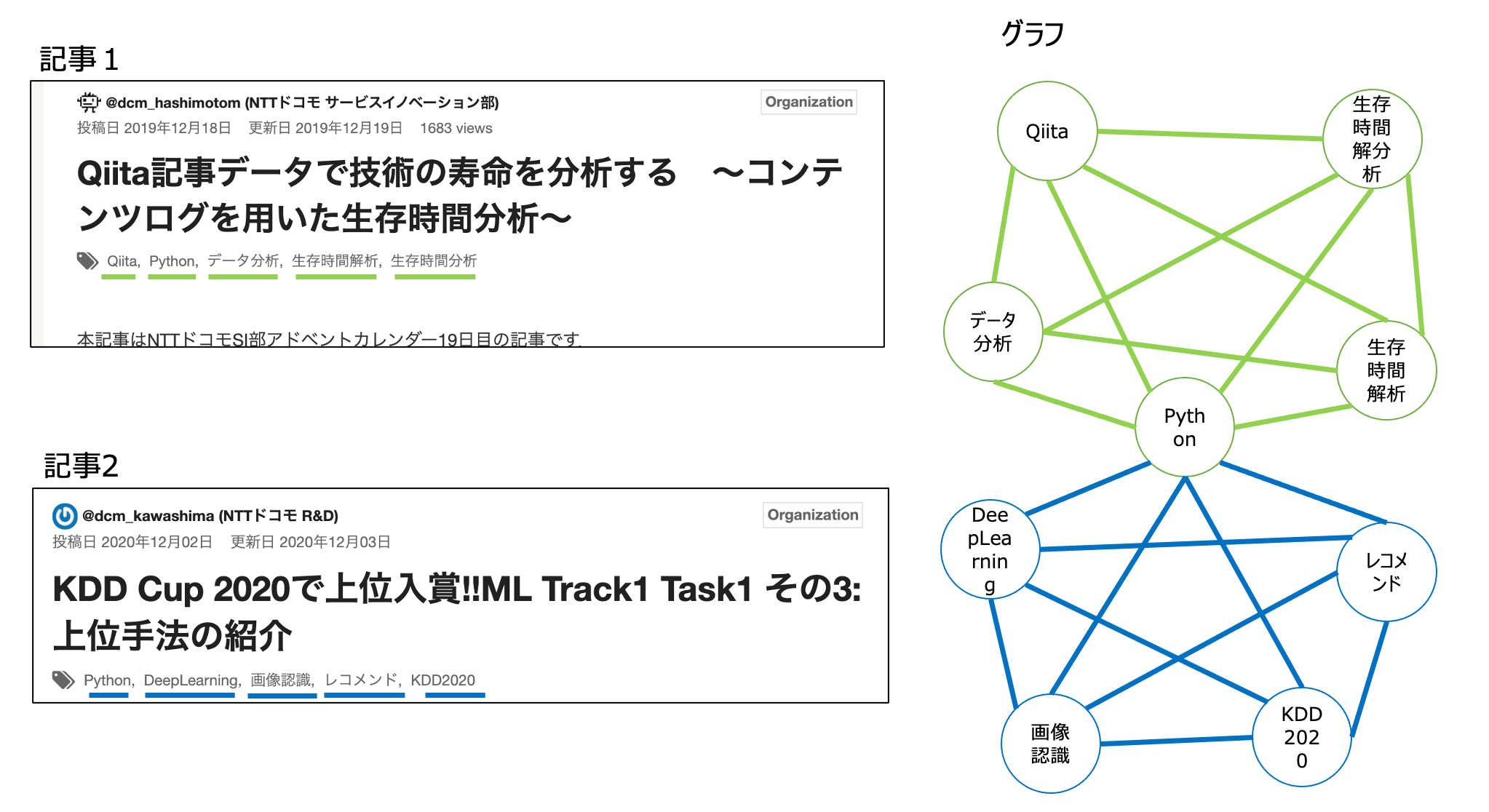
例えば、下画像の記事1には Qiita, Python, データ分析, 生存時間解析,生存時間分析 という5つのタグがついております.また,記事2には Python, DeepLearning, 画像認識,レコメンド,KDD2020の5つのタグがついております.これらを上記方針に沿ってグラフが作成をすると右図のグラフのようになります.
Webサービスでのグラフ構築を調べると,userノードとitemノードを定義したuser-itemグラフが多いです.(userが利用(作成)したitem(記事のタグ)にエッジをはる.)
今回のようなitemノードのみでつくるグラフはあまり一般的でない気がしますが,本記事の目的ではuserのembeddingは不要なのでこの形で進めていこうと思います.
タスクとしてはGNNのリンク予測問題になります.リンク予測問題では,ある2つのノードが与えられた時に,その2つノードにリンク(エッジ)があればスコアが高く,なければスコアが低くなるように学習を進めます.ここでいうスコアはベクトルの近傍か否かで算出されます.「同じ記事におけるタグであるならば似たような技術である」という仮定のもと,類似技術は近傍のベクトルになることを期待します.
まずは上記のQiitaデータからタグの部分を抜き出した2次元のリストを作成します.なお,事前に登場回数が少ないタグ(今回は10以下)は処理対象から外しております.
>>> tag_list[:10]
[['ポエム', '情報処理技術者試験', 'エンベデッドシステムスペシャリスト', '合格体験記'],
['asterisk', 'AI', 'Watson', 'ibmcloud', 'Jitsi'],
['WordPress', 'Plugin', 'SearchRegex'],
['MachineLearning',
'TensorFlow',
'ObjectDetectionAPI',
'colaboratory',
'ObjectDetection'],
['PowerShell', 'SharePoint', 'OneDrive', 'Teams', 'Microsoft365'],
['Python', 'OpenCV', '顔認識', 'Keras', '表情認識'],
['SAP'],
['Python', 'R', 'math', '虚数', '数理考古学'],
['SublimeText', 'エラー対処', '初心者エンジニア'],
['lisp', 'ISLisp']]
これらリストの要素それぞれがノードになります.
まず,グラフを作るためsrcとdstにわけます.
ここではPythonの組み合わせ計算を使いました.
import itertools
edges = []
for tags in tag_list:
if len(tags) == 1:
continue
combs = itertools.combinations(tags, 2)
for c in combs:
edges.append(c)
df_edges = pd.DataFrame({"src": [e[0] for e in edges], "dst": [e[1] for e in edges]}) #便宜上DataFrameに変換
df_edges = df_edges.drop_duplicates().reset_index(drop=True) #重複を削除
df_edgesは下記のようになってます.
| src | dst | |
|---|---|---|
| 0 | ポエム | 情報処理技術者試験 |
| 1 | ポエム | エンベデッドシステムスペシャリスト |
| 2 | ポエム | 合格体験記 |
| 3 | 情報処理技術者試験 | エンベデッドシステムスペシャリスト |
| 4 | 情報処理技術者試験 | 合格体験記 |
| .. | ... | ... |
次にdgl.graphに対応させるため,ノードにIDを振ります.
# ノードIDを振る
src_list = df_edges["src"].unique().tolist()
dst_list = df_edges["dst"].unique().tolist()
tmp_list = list(set(src_list + dst_list))
df_nodeid = pd.DataFrame()
df_nodeid["nodes"] = tmp_list
df_nodeid["node_id"] = list(range(len(tmp_list)))
# src, dstの形式に整形
df_graph = df_edges.merge(df_nodeid[["nodes", "node_id"]], left_on="src", right_on="nodes", how="left")
df_graph = df_graph.merge(df_nodeid[["nodes", "node_id"]], left_on="dst", right_on="nodes", how="left")
df_graph = df_graph.drop(["nodes_x", "nodes_y"], axis=1)
df_graph = df_graph.rename(columns={"node_id_x": "src_id", "node_id_y": "dst_id"})
df_graphは次のようになります
| src | dst | src_id | dst_id | |
|---|---|---|---|---|
| 0 | ポエム | 情報処理技術者試験 | 4555 | 355 |
| 1 | 初心者 | 情報処理技術者試験 | 7379 | 355 |
| 2 | 初心者向け | 情報処理技術者試験 | 593 | 355 |
| 3 | tips | 情報処理技術者試験 | 8017 | 355 |
| 4 | 勉強法 | 情報処理技術者試験 | 4317 | 355 |
さて,dgl.graphへの入力となるデータが作成できました.
ここからはDGLでグラフオブジェクトを作成していきます.
import dgl
import torch
g = dgl.graph((torch.tensor(df_graph["src_id"]), torch.tensor(df_graph["dst_id"])))
g = dgl.to_bidirected(g) #無向グラフに変換するため両方にエッジをもたせる
ここで注意点があります.
src, dstと表現してましたが,今回作りたいグラフは有向グラフではありません.今のままでは,先程の組み合わせ計算(itertool.combinations())でたまたま先頭に来たものがsrcに,後に来たものがdstになった有向グラフになってしまっています.そこで,dgl.to_bidirceted()の処理で両方のエッジを持たせた無向グラフに変換します.DGLでは無向グラフはsrc→dst, dst→src両方にエッジをもたせて表現します.
上記の処理でノード数は8866,エッジ数は210,984のグラフなりました.
>>> g.num_nodes()
8866
>>> g.num_edges() # src->dst, dst->src両方含む
210984
グラフの可視化
作成したグラフを可視化してみましょう.
全体のグラフを見てもよくわからないので,グラフの一部分をサンプルした可視化を試みます.
下記の関数では,指定したノードとその1-hop分隣接のノードをサンプルしたグラフを構築する処理を書いております.サンプルしたい隣接ノードの個数をfanoutパラメータで指定します.
def create_sample_graph(g, sample_nodes, fanout):
# グラフから指定したノードをサンプル(元グラフノードはそのまま残る)
sample_graph = dgl.sampling.sample_neighbors(g, sample_nodes, fanout=fanout)
# エッジを持つノードのみ取り出す.
src, dst = sample_graph.edges()
# ノードIDを振り直す
uniq_nodes, edges = np.unique((src.numpy(), dst.numpy()), return_inverse=True)
# srcとdstに分ける
relabeled_src, relabeled_dst = np.reshape(edges, (2, -1))
# グラフを再構築
sample_g = dgl.graph((relabeled_src,relabeled_dst))
return sample_g, uniq_nodes
実装は少しトリッキーになってます.
dgl.sampling.sample_neighbors()が指定したノードからサンプルグラフを作ってくれるのですが,この時点ではsample_graphとgのノード数は同じです.ノード数はサンプルされた部分はエッジをもち,それ以外はエッジをもたないグラフになっております.下記に例を示します.
>>> sample_graph = dgl.sampling.sample_neighbors(g, [8154], fanout=20) #1つのノードとその隣接ノード20個を指定
>>> sample_graph.num_nodes() #ノード数はそのまま
8866
>>> sample_graph.num_edges() #エッジはサンプルされている
20
なので,必要なノードで構成されるグラフを得るためにはエッジがあるノードのみ取り出し,それらにノードIDを振り直す必要があります.
ノードIDを振り直すのにnp.unique()を使っています.np.unique()ではsrc,dstのノードIDをユニークにします.さらに,return_inverseを指定することで,それらが登場したindexを返却します.indexは0から振られるのでちょうど新規のノードIDとして利用できます.ここで,入力はsrc,dstのタプルで渡しておりますが,それらがconcatされた形で処理されることに注意してください.
サンプリングする関数ができましたので,グラフを可視化してみましょう.
今回は「DeepLearning」, 「深層学習」,「ポエム」の3ノードを指定し,それらの1-hop先のノード20個までをサンプルしたグラフを描画してみます.最初に上記3つノードIDを調べます.
>>> df_nodeid[df_nodeid["nodes"].isin(["深層学習", "DeepLearning", "ポエム"])]
| nodes | node_id | |
|---|---|---|
| 2748 | DeepLearning | 2748 |
| 4555 | ポエム | 4555 |
| 8154 | 深層学習 | 8154 |
それでは描画してみましょう
# グラフのサンプリング
sample_g, uniq_nodes = create_sample_graph(g, [8154, 2748, 4555], 20)
label_dict= {i: label for i, (_id, label) in enumerate(zip(df_nodeid.iloc[uniq_nodes]["node_id"], df_nodeid.iloc[uniq_nodes]["nodes"]))}
# 描画処理
options = {
'node_color': [[.7, .7, .7]],
'width': 1,
'with_labels': True,
'labels': label_dict,
'font_family':'IPAexGothic'
}
G = dgl.to_networkx(sample_g).to_undirected()
pos = nx.kamada_kawai_layout(G)
plt.figure(figsize=[15,7])
nx.draw(G, pos, **options)
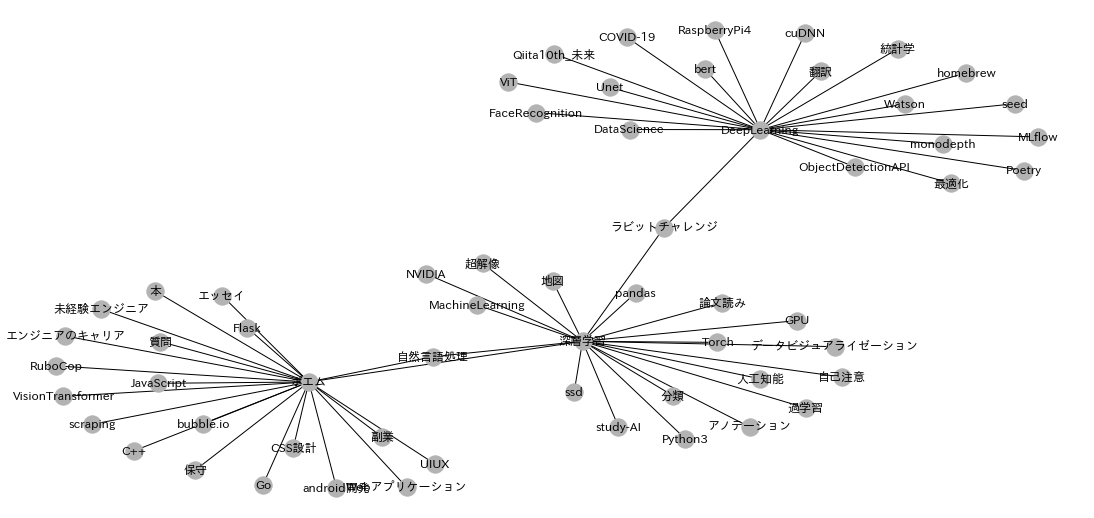
今回はあくまでサンプルであり,指定したノードの全ての隣接ノードやすべてのエッジでないことに注意してください.
指定した3つのノードに関して,同記事につけられたであろうタグのノードが隣接ノードとしてエッジがはられております.想定どおりのグラフができていそうです.
GNN(GraphSAGE)によるTech2Vecの作成
後の処理ではGNNを定義し学習をさせていきますが,DGLのチュートリアルに沿った形式で実装していきます.
コード(クリックして開く)
import torch
import dgl.nn as dglnn
import torch.nn as nn
import torch.nn.functional as F
import dgl.function as fn
class SAGE(nn.Module):
def __init__(self, in_feats, hid_feats, out_feats):
super().__init__()
self.conv1 = dglnn.SAGEConv(
in_feats=in_feats, out_feats=hid_feats, aggregator_type='mean')
self.conv2 = dglnn.SAGEConv(
in_feats=hid_feats, out_feats=out_feats, aggregator_type='mean')
def forward(self, graph, inputs):
h = self.conv1(graph, inputs)
h = F.relu(h)
h = self.conv2(graph, h)
return h
class DotProductPredictor(nn.Module):
def forward(self, graph, h):
with graph.local_scope():
graph.ndata['h'] = h
graph.apply_edges(fn.u_dot_v('h', 'h', 'score'))
return graph.edata['score']
class Model(nn.Module):
def __init__(self, in_features, hidden_features, out_features):
super().__init__()
self.sage = SAGE(in_features, hidden_features, out_features)
self.pred = DotProductPredictor()
def forward(self, g, neg_g, x):
h = self.sage(g, x)
return self.pred(g, h), self.pred(neg_g, h)
def construct_negative_graph(graph, k):
src, dst = graph.edges()
neg_src = src.repeat_interleave(k)
neg_dst = torch.randint(0, graph.num_nodes(), (len(src) * k,))
return dgl.graph((neg_src, neg_dst), num_nodes=graph.num_nodes())
def compute_loss(pos_score, neg_score):
# Margin loss
n_edges = pos_score.shape[0]
return (1 - pos_score + neg_score.view(n_edges, -1)).clamp(min=0).mean()
# 学習部分
node_features = torch.nn.functional.one_hot(torch.tensor(df_nodeid["node_id"]), num_classes=len(df_nodeid["node_id"])).float()
n_features = node_features.shape[1]
k = 5
model = Model(n_features, 100, 50)
opt = torch.optim.Adam(model.parameters())
for epoch in range(1000):
negative_graph = construct_negative_graph(g, k)
pos_score, neg_score = model(g, negative_graph, node_features)
loss = compute_loss(pos_score, neg_score)
opt.zero_grad()
loss.backward()
opt.step()
# Embedding
y = model.sage(g, node_features)
emb = y.detach().numpy()
df_emb = pd.DataFrame(emb, columns=[f"col_{i}" for i in range(emb.shape[1])])
df_emb_nodeid = pd.concat([df_nodeid.reset_index(drop=True), df_emb.reset_index(drop=True)], axis=1)
SAGE クラス
レイヤーは2層ありSAGEConvクラスを用いて実装されております.
aggregator_type='mean'ですので,近傍ノードの集約の際は自身のノードと近傍のノードの平均ベクトルを算出し重みを掛け合わせたものを次のレイヤにforwardさせてます.
DotProductPredictor クラス
リンク予測タスクにおいては2つのノードのスコア(距離など)を算出し,リンクの有無を数値で表します.DotProductPredictorクラスは与えたグラフ構造とノードベクトル(hはここではembeddingされたもの)をもとに,エッジのある2つのノードのスコアを算出します.ここでは単純にベクトル同士の内積を計算しております.
Model クラス
上記2つのクラスをModelクラスで呼べるように定義します.
forwardでは,与えられた正グラフと負例グラフそれぞれのスコアを算出してます.
construct_negative_graph 関数
この関数では与えられたグラフをもとに,本来はエッジ(リンク)がない負例グラフを構築しております.srcノード, dstノードとあったとき,srcはそのままで,dstをグラフ内のノードから乱数で設定することで,本来はエッジ(リンク)がない負例グラフを定義しております.乱数で設定しているが故に正のエッジ(もともとのグラフでも存在する)が含まれる場合もありますが,ここでは簡単のためそれらを取り除く処理を実施しておりません.
compute_loss 関数
lossの関数の定義については,あまり深く追えてませんが,正例グラフのスコアが負例のスコアより大きい場合はlossが小さく,また逆の場合はlossが大きくなるように定義されております.
学習部分
各ノードの初期ベクトルはノード数8866次元のone-hotベクトルにしました.NNの隠れニューロン数は100, 出力ベクトル次元数は50,負例のサンプルノード数は5に設定しました.また,epoch数は決めで1000を設定しました.epochの中で都度負例グラフを作成しbackpropの処理をしております.
Embedding部分
df_emb_nodeidの中身をみてみましょう.
| nodes | node_id | col_0 | col_1 | ... | col_48 | col_49 | |
|---|---|---|---|---|---|---|---|
| 0 | バイナリ | 0 | -0.177811 | -1.879942 | ... | -1.136763 | 1.127163 |
| 1 | container | 1 | 0.027849 | -1.223250 | ... | -0.766427 | 1.096907 |
| 2 | headタグ | 2 | -0.174102 | -1.204872 | ... | -0.576451 | 1.021932 |
| 3 | 組み込みOS | 3 | -0.885491 | -0.635641 | ... | 0.294162 | 0.730181 |
| 4 | maxima | 4 | -0.309023 | -1.341024 | ... | -1.186237 | 2.255011 |
ちゃんとembeddingできてそうです.
近傍探索モデルによるレコメンド
では,期待通りに似ている技術タグが近傍のベクトルになってレコメンドができるか確認していきましょう.今回は近傍探索にAnnoyをつかっていこうと思います.Oh Yeah!
cols = [col for col in df_tmp.columns if "col" in col]
t = AnnoyIndex(50, 'angular')
for i in range(len(df_emb_nodeid)):
v = df_emb_nodeid[cols].iloc[i, :]
t.add_item(i, v)
t.build(10)
AnnoyIndexで対象ノードまたはベクトルを入力をすることでその近傍のノードを探索し出力してくれます.
結果
「機械学習」
「機械学習」の近傍の技術タグTop10をみてみましょう.レコメンドでいうと「機械学習」とタグ付けした際に推薦してもらえる候補Top10になります.
i = df_emb_nodeid[df_emb_nodeid["nodes"] == "機械学習"].node_id.values[0]
nns = t.get_nns_by_item(i, 10, search_k=-1, include_distances=False)
# 抽出されたindexを表示
df_emb_nodeid[["nodes", "node_id"]].iloc[nns, :]
| nodes | node_id | |
|---|---|---|
| 7859 | 機械学習 | 7859 |
| 8154 | 深層学習 | 8154 |
| 2748 | DeepLearning | 2748 |
| 5120 | MachineLearning | 5120 |
| 1873 | 混同行列 | 1873 |
| 7066 | DALLE | 7066 |
| 995 | MLP | 995 |
| 6868 | 異常検知 | 6868 |
| 7347 | 前処理 | 7347 |
| 1416 | セグメンテーション | 1416 |
お,なんかうまくいってそうです! 👍
他のいくつかのタグもみてみましょう.
「Python」
| nodes | node_id | |
|---|---|---|
| 8599 | Python | 8599 |
| 4681 | LCAO | 4681 |
| 7488 | nnmnkwii | 7488 |
| 8460 | OnlineMathContest | 8460 |
| 1279 | music21 | 1279 |
| 7501 | 実行環境 | 7501 |
| 8509 | Newton法 | 8509 |
| 3568 | numerai | 3568 |
| 4109 | 共役勾配法 | 4109 |
| 4448 | peewee | 4448 |
Pythonのライブラリや,数値計算の用語が並んでます.
同記事のタグはリンクを貼っているので,Python, Ruby, Perl..ではなく,
関連ライブラリが並ぶのかと思います.
本記事の実装のレコメンドとしては正しそうです🤔
「JavaScript」
| nodes | node_id | |
|---|---|---|
| 4194 | JavaScript | 4194 |
| 2056 | c3.js | 2056 |
| 2190 | ECMAScript6 | 2190 |
| 7984 | 実況中継 | 7984 |
| 1942 | 卒業研究 | 1942 |
| 747 | dotinstall | 747 |
| 6423 | aspida | 6423 |
| 8549 | monigate | 8549 |
| 2976 | VimeoAPI | 2976 |
| 4141 | prismjs | 4141 |
ちょっと謎なタグもありますが,雰囲気はあります.
「Emacs」
| nodes | node_id | |
|---|---|---|
| 8486 | Emacs | 8486 |
| 8473 | ido | 8473 |
| 210 | Vim | 210 |
| 8310 | neovim | 8310 |
| 2041 | Markdown | 2041 |
| 4303 | Terminal | 4303 |
| 1395 | org-mode | 1395 |
| 7757 | マージ | 7757 |
| 5247 | Spacemacs | 5247 |
| 3184 | commandline | 3184 |
EmacsプラグインやVimなどそれっぽいのがならんでますね.
個人的にorg-modeはお世話になってます.
「ポエム」
| nodes | node_id | |
|---|---|---|
| 4555 | ポエム | 4555 |
| 2440 | 非エンジニア | 2440 |
| 7275 | 初投稿 | 7275 |
| 1616 | 初心者エンジニア | 1616 |
| 6581 | 独学プログラマー | 6581 |
| 6205 | 新人教育 | 6205 |
| 6616 | オフショア開発 | 6616 |
| 7402 | テレワーク | 7402 |
| 6932 | DMMWEBCAMP | 6932 |
| 2870 | 未経験エンジニア | 2870 |
入門感があります.
まとめ
本記事ではQiitaタグデータのグラフを構築し,GNNを用いて技術タグの分散表現Tech2Vecを作成しました.さらに作成したベクトルを用いて近傍探索モデルを構築し,類似タグの算出(レコメンド)できるかを確認しました.定量的な評価ではありませんが,まぁまぁ良いemmbeddingができているように感じます.
また,以下の工夫をすることで,精度があげらるかと思います.
- 前処理の名寄せ処理を行う
- 特徴ベクトルをone-hotデータでなく工夫したものを入れる
- モデルのレイヤーやパラメータを調整する
- src, dstに分けた時にユニークにしないで,出現回数などで重み付けをする
- レコメンド時にタグの出現回数を考慮する
最後に
本記事のタグもレコメンドしてもらおうと「GNN」を入力してみましたが,登場回数を消す前処理で削られてしまってノードとして入っておりませんでした...もっとGNNの記事が必要ですね..今回利用したデータでは「GNN」の登場回数は7回でした.
Qiitaに限らず投稿コンテンツにタグをつけるという行動はさまざまなSNSで行われるので,本取り組みの汎用性があるように思っております.それでは,良いお年を〜 👍👍👍