はじめに
こんにちは。今年ももう終わりですね。
普段は記事を読むだけの僕ですが、初めて記事を書きたいと思います。
今回はQiitaのAPIを利用して、これまでのQiitaの記事について分析してみました。その過程で死ぬほどエラーでつまづいたので、二度とこんな無駄な作業が生まれないよう、ここにそのノウハウを共有します。
収集したデータセットも合わせて公開しますのでご査収ください。
やったこと
- QiitaAPIをPythonで扱う練習
- 月ごとの投稿数を調査
- Qiitaの投稿データに関するデータセットを作成
- 2011/9-2018/10までの全記事データを収集
Qiita APIの基本的な使い方
Qiita API v2ドキュメント - Qiita:Developer
PythonでAPIを扱うためにrequestモジュールを利用します。例えば投稿の一覧を取得してみます。1
import requests
url = 'https://qiita.com/api/v2/items'
params = {
'page' : 1,
'per_page' : 100
}
headers = {
'content-type' : 'application/json',
'charset' : 'utf-8'
}
r = requests.get(url, params=params, headers=headers)
print('Response={0}, Detail={1}'.format(r.status_code,r.headers))
print(r.json())
うまくいけばResponseが200で返ってきます。
Response=200,
Detail={
'Date':'Thu,
08 Nov 2018 11:30:05 GMT',
'Content-Type':'application/json; charset=utf-8',
'Transfer-Encoding':'chunked',
'Connection':'keep-alive',
'Server':'nginx',
'X-Frame-Options':'SAMEORIGIN',
'X-XSS-Protection':'1; mode=block',
'X-Content-Type-Options':'nosniff',
'Link':'<https://qiita.com/api/v2/items?page=1&per_page=100>; rel="first",
<https://qiita.com/api/v2/items?page=2&per_page=100>; rel="next",
<https://qiita.com/api/v2/items?page=3454&per_page=100>; rel="last"',
'Total-Count':'345301',
'ETag':'W/"b69bd1299e58ad6e0f3f0a54e937fae4"',
'Cache-Control':'max-age=0, private, must-revalidate',
'Rate-Limit':'60',
'Rate-Remaining':'59',
'Rate-Reset':'1541680205',
'Vary':'Origin',
'X-Runtime':'0.561610',
'Strict-Transport-Security':'max-age=2592000',
'X-Request-Id':'03beeecd-a39f-411c-9ad0-77e868584bea'
}
2018/11/8現在、Qiita上には345301件の記事が存在します。
レスポンスの中身はこんな感じです。
{'body': '# すべての開発者が学ぶべきたった一つの言語という記事\n\nなんかバズってるし、私もパクって駄文を一つ書いてみることにしました。\nヤマト運輸を待ってる最中なので暇なんですよねー。\nZOZOのジーンズ早く来ないかなー。\n\n## 職場でメインに使われてる言語\n\n例えば、日本国内の職場ならメインの言葉はたいてい日本語。\nそういう職場では日本語ができないと何もできない。\n仕事にならない、\n\n## 英語\n\n大半のライブラリーやプログラム言語の解説は英語。\nこの言語ができないと調べものもできない、知識の習得もできない。\n超重要な言語。\n\n## コミュニケーション能力\n\n言語能力についで必要な能力。言語が荷車の片輪だとするとこの能力はもう片方の車輪。\n\n上司がなにか言う前に忖度していろいろやる技術・・・・・ではもちろんない。\n\n**相手を尊重し、相手を理解し、その上で自分を理解してもらう能力である。**\n\n様々な書籍があり、さまざまな研究がなされているがこれ、ものすごく難しい。言語能力に加えてこの能力があれば最強である。\n\nプログラム言語だけできる人は多い。人間の言語がきちんと話せる人も多い。しかし、コミュニケーション能力がある技術者は少ない(ように思う、とくに某記事への叩き方を見ると)。\n\nこの能力があれば、\n\nなんの役にも立たない意見、人を馬鹿にしたような意見、があっても\n\n**よってたかって叩かず、ネタにせず、静かに笑っていられる人**\n\nになれます。(多分)\n\n',
'coediting': False,
'comments_count': 0,
'created_at': '2018-11-09T09:50:52+09:00',
'group': None,
'id': '75890603ac6e6c3b2328',
'likes_count': 0,
'page_views_count': None,
'private': False,
'reactions_count': 0,
'rendered_body': '\n<h1>\n<span id="すべての開発者が学ぶべきたった一つの言語という記事" class="fragment"></span><a href="#%E3%81%99%E3%81%B9%E3%81%A6%E3%81%AE%E9%96%8B%E7%99%BA%E8%80%85%E3%81%8C%E5%AD%A6%E3%81%B6%E3%81%B9%E3%81%8D%E3%81%9F%E3%81%A3%E3%81%9F%E4%B8%80%E3%81%A4%E3%81%AE%E8%A8%80%E8%AA%9E%E3%81%A8%E3%81%84%E3%81%86%E8%A8%98%E4%BA%8B"><i class="fa fa-link"></i></a>すべての開発者が学ぶべきたった一つの言語という記事</h1>\n\n<p>なんかバズってるし、私もパクって駄文を一つ書いてみることにしました。<br>\nヤマト運輸を待ってる最中なので暇なんですよねー。<br>\nZOZOのジーンズ早く来ないかなー。</p>\n\n<h2>\n<span id="職場でメインに使われてる言語" class="fragment"></span><a href="#%E8%81%B7%E5%A0%B4%E3%81%A7%E3%83%A1%E3%82%A4%E3%83%B3%E3%81%AB%E4%BD%BF%E3%82%8F%E3%82%8C%E3%81%A6%E3%82%8B%E8%A8%80%E8%AA%9E"><i class="fa fa-link"></i></a>職場でメインに使われてる言語</h2>\n\n<p>例えば、日本国内の職場ならメインの言葉はたいてい日本語。<br>\nそういう職場では日本語ができないと何もできない。<br>\n仕事にならない、</p>\n\n<h2>\n<span id="英語" class="fragment"></span><a href="#%E8%8B%B1%E8%AA%9E"><i class="fa fa-link"></i></a>英語</h2>\n\n<p>大半のライブラリーやプログラム言語の解説は英語。<br>\nこの言語ができないと調べものもできない、知識の習得もできない。<br>\n超重要な言語。</p>\n\n<h2>\n<span id="コミュニケーション能力" class="fragment"></span><a href="#%E3%82%B3%E3%83%9F%E3%83%A5%E3%83%8B%E3%82%B1%E3%83%BC%E3%82%B7%E3%83%A7%E3%83%B3%E8%83%BD%E5%8A%9B"><i class="fa fa-link"></i></a>コミュニケーション能力</h2>\n\n<p>言語能力についで必要な能力。言語が荷車の片輪だとするとこの能力はもう片方の車輪。</p>\n\n<p>上司がなにか言う前に忖度していろいろやる技術・・・・・ではもちろんない。</p>\n\n<p><strong>相手を尊重し、相手を理解し、その上で自分を理解してもらう能力である。</strong></p>\n\n<p>様々な書籍があり、さまざまな研究がなされているがこれ、ものすごく難しい。言語能力に加えてこの能力があれば最強である。</p>\n\n<p>プログラム言語だけできる人は多い。人間の言語がきちんと話せる人も多い。しかし、コミュニケーション能力がある技術者は少ない(ように思う、とくに某記事への叩き方を見ると)。</p>\n\n<p>この能力があれば、</p>\n\n<p>なんの役にも立たない意見、人を馬鹿にしたような意見、があっても</p>\n\n<p><strong>よってたかって叩かず、ネタにせず、静かに笑っていられる人</strong></p>\n\n<p>になれます。(多分)</p>\n',
'tags': [{'name': 'ポエム', 'versions': []},
{'name': 'ネタ', 'versions': []},
{'name': '駄文', 'versions': []},
{'name': 'ジョーク', 'versions': []}],
'title': 'すべての開発者が学ぶべき言語と技術',
'updated_at': '2018-11-09T09:50:52+09:00',
'url': 'https://qiita.com/TakaakiFuruse/items/75890603ac6e6c3b2328',
'user': {'description': '',
'facebook_id': '',
'followees_count': 83,
'followers_count': 13,
'github_login_name': 'TakaakiFuruse',
'id': 'TakaakiFuruse',
'items_count': 36,
'linkedin_id': 'tfuruse',
'location': '',
'name': '',
'organization': '',
'permanent_id': 52613,
'profile_image_url': 'https://qiita-image-store.s3.amazonaws.com/0/52613/profile-images/1473692788',
'twitter_screen_name': None,
'website_url': ''}},
月別投稿数を取得してみた
APIの練習として2011-20182の投稿数を月別にプロットしてみます。
import pandas as pd
dic={}
for year in range(2011,2019):
for month in range(1,13):
key = "{}-{}".format(year,month)
total_articles,total_pages = get_monthly_data(year,month)
dic[key]=[total_articles, total_pages]
print(year, month, total_articles, total_pages)
time.sleep(60)
x = list(dic.keys())
y = [cnt[0] for cnt in list(dic.values())]
df = pd.DataFrame({'time':x,'count':y},index=x)
df = df.drop(index=['2018-11','2018-12'])
df['count'].plot(figsize=(16,9),
title='The Number of Monthly Posts in Qiita',
xticks=range(0,len(x))[::3],
rot=45)
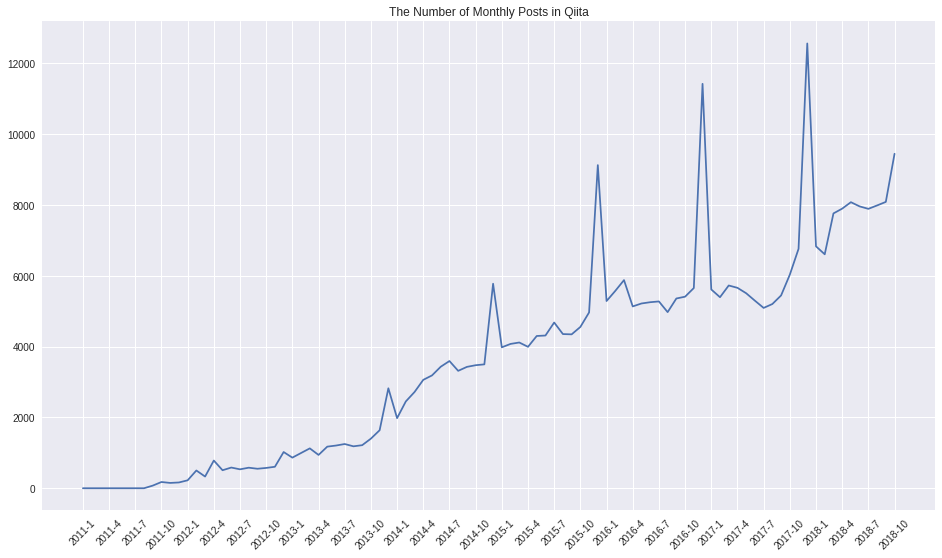
2013年から周期的にスパイクが発生しています。毎年12月頃…そう、みなさんご存知AdventCalendarの影響です。2018年は平均8000postで推移しているので今年のAdventCalendarも前年を超えてきそうですね。
Qiitaのデータセット
「いいねがたくさん欲しいんだけど、どんなタイトルにすればいいのかな?」
「閲覧数、いいね数、コメント数の相関はあるのだろうか?」
色々調べたくなったのでデータセットを作ってみました。3
ぱっと見はこんな感じです。

| ラベル | 内容 |
|---|---|
| created_at | データが作成された日時 |
| updated_at | データが最後に更新された日時 |
| id | 投稿の一意なID |
| title | 投稿のタイトル |
| user | ユーザ名4 |
| likes_count | この投稿への「いいね!」の数 |
| comments_count | この投稿へのコメントの数 |
| page_views_count | 閲覧数 |
| url | 投稿のURL |
| tags | 投稿に付いたタグ一覧 |
page_views_countは取得したのですが全部Noneでした。また、記事のタイトルに改行コード\rが混入しているため、少しハマりました。
11/30までのデータをQiita_dataset_1113 | Kaggleに置いておきます。練習用にどーぞ。
Qiita APIをうまく使うコツ
QiitaのAPIには色々と制約があります。ポイントは下記2点です。
APIの利用制限
認証している状態ではユーザごとに1時間に1000回まで、認証していない状態ではIPアドレスごとに1時間に60回までリクエストを受け付けます。
普通にループで繰り返し処理をするとすぐにエラーが返ってくるはずです。time.sleep(n)などで待ち時間を挿入することで解決しましょう。
参考に待ち時間の目安をまとめておきます。
| 制限対象 | 利用制限 | 待ち時間 | |
|---|---|---|---|
| 認証あり5 | ユーザ | 1000回/時間 | 3.6秒/リクエスト |
| 認証なし | ipアドレス | 60回/時間 | 60秒/リクエスト |
pageの上限が100
pageの初期値は1、pageの最大値は100に設定されています。
import math
# 全記事数
total_articles = int(r.headers['Total-Count'])
total_pages = math.ceil(total_articles/float(params['per_page']))
print(total_articles, total_pages)
上記のコードを実行してみると、Qiitaの全記事を取得するためには3000page以上リクエストを投げる必要があります。そんなの絶対無理やん。と思っていたところ、とあるブログ6で紹介されていた「queryを細かく投げてpage数を抑える」という技で何とかなりました。感謝。
まとめ
今回はQiitaのAPIから過去の投稿記事のデータセットを作成してみました。ちなみにLSTMで2018/12の投稿数を予測してみたところ〇〇件でした。答えはお正月にでも。